23 低代码平台如何帮助应用做测试?配置即测试
你好,我是陈旭。
在前面的两节课中,最开始我们讲了被测功能的定义和自动发现的算法,然后我们又给出了被测功能的副作用的定义,以及自动发现副作用的算法。副作用是用于生成测试用例的断言的,断言是自动化测试的核心,没有断言的测试用例毫无意义。
前面的两讲,基本都是以理论和算法为主,都是在为今天这讲做铺垫。现在,我们有了理论,有了算法,终于可以来说说测试用例如何被生成出来了。
被测功能的顺序

从被测功能的定义图中,我们可以发现一个有趣的地方:似乎被测功能之间没有任何关系,先执行哪个、后执行哪个都没有区别。但是,一旦一个功能点执行了以后,它产生的副作用就有可能影响其他功能点的执行,因此,为了避免这些功能点相互影响,我们需要在每个功能执行完成之后,驱动浏览器刷新,重置一下页面状态,从而避免功能点的副作用产生不必要的干扰。
不过,实际上,并不是所有的被测功能之间都没有任何关系,我来举个例子你就知道了。还记得第21讲我们举了一个非常简单的交互例子吗?示意图如下:
 点击按钮后,一个HTTP请求被发送给服务器,得到了数据后,对应表格就更新了。现在我们来稍微拓展一下这个示例的功能,在表格更新了数据后,我们还要求点击一下表格的某一行,更新一下附近的一个图形,示意图如下:
点击按钮后,一个HTTP请求被发送给服务器,得到了数据后,对应表格就更新了。现在我们来稍微拓展一下这个示例的功能,在表格更新了数据后,我们还要求点击一下表格的某一行,更新一下附近的一个图形,示意图如下:

这依然是一个很常见的界面交互的示例,但是这个例子却展示了被测功能之间的一个特性,那就是两个被测功能可能有先后顺序!
那是否所有的被测功能之间都是有先后顺序的呢?答案是可以有、也可以没有。一个正常的页面上的所有功能,都不是孤立存在的,所有功能在一起会组成一棵功能树。
 但是,所有功能都组成单独的一棵功能树,实在太复杂了,最要命的是,不好单独调试某个用例,这些功能的运行只能串行执行,跑完这样一棵树需要大量时间,甚至一个晚上都跑不完一遍。在这个情况下,如果要调试其中一个功能,则只能全量跑一次,试错周期太长,以至于几乎无法调试。
但是,所有功能都组成单独的一棵功能树,实在太复杂了,最要命的是,不好单独调试某个用例,这些功能的运行只能串行执行,跑完这样一棵树需要大量时间,甚至一个晚上都跑不完一遍。在这个情况下,如果要调试其中一个功能,则只能全量跑一次,试错周期太长,以至于几乎无法调试。
解决这个问题的一个简单又直接的方法就是,让这些功能的测试并行执行,没有先后顺序的功能天然就可以并行执行。因此,我们需要尽可能拆散被测功能,能不要有先后顺序的,就让它们相互独立。这就走向了另一个极端,从纯技术上说,只要能提供所需的输入数据,那么所有功能都可以相互独立。说到这里,估计你已经看出来了,但我还是提示一下,功能之间是否可以独立的根本在于是否可以提供所需的输入数据。
经过前面的讨论,我们发现被测功能的顺序弹性很大,可以全部有先后顺序,也可以是另一个极端,那么作为低代码平台,如何决定功能的顺序呢?我们先不着急回答这个问题,但是我们试着站在开发人员的角度来看这个问题。
一般来说,开发人员是从业务的角度来看待各个功能点的。从业务角度来看,某个业务功能一般都是由多个功能点组合而成的,在这个情况下,让这些功能保持先后顺序执行,看似复杂了,但是对已经理解了业务的开发人员来说,却是更友好的,对每个功能点的调试也更便捷。也就是说,从业务角度来确定哪些功能要串行执行,才是最合理的。
那前面如何决定被测功能顺序的问题,就基本等价于“哪些功能属于同一个业务”。属于同一个业务的功能,就要保持先后顺序,两个业务之间的功能,就可以没有顺序。低代码平台难以解决这个问题,因此,功能点的顺序问题,需要由开发人来自行配置。
当两个功能之间有先后顺序时,在前一个用例执行后,要保持页面的状态不变,从而保持它所产生的副作用不变,并以此状态为起点,作为下一个功能点的初始状态。以此类推,所有有先后顺序的功能点就会形成一个功能串,一个挨着一个,前一个功能的副作用是下一个功能的输入数据的基础。
这就是被测功能的顺序关系,有一部分功能之间是没有先后顺序的,但有另一部分功能则相反,后一个功能需要前一个功能的副作用作为其输入数据的一部分。正如前面的例子,如果表格不更新,那么就无法点击表格的一行,那就是说表格不更新,那更新图形的功能就无从触发了。
和前面相似,在了解了被测功能的顺序后,我们再来找找传统开发测试用例代码中,有哪些概念和被测功能的顺序相近。估计你已经想到了,那就是用例集这个概念了,在一个用例集中的各个功能都是按照顺序执行的,同时,在手工开发测试用例时,我们往往会保持各个用例集之间没有耦合。当然这不是必须的,但最佳实践是保持用例集之间无耦合,从而可以很容易以用例集为单位并行执行这些测试用例。
我们的目的是要自动生成测试用例代码,而讲到这里,我们也就很清楚地知道了采用什么样的方式来自动生成测试用例和用例集了。
此时生成的代码类似这样:
describe('串行测试集:测试 RAT=5G,area=江苏省,IMSI=310150123456789', () => {
it('基础数据查询测试', () => {
...
})
it('表-图联动测试', () => {
...
})
})
describe('并行测试', () => {
...
})
提示:我们底层使用了Cypress作为浏览器驱动,所以上面这段代码用的都是Cypress的API。
代码中的文字,有一部分是要求开发人员填写的,这些文本显示在界面上,有助于他们自己记忆这些用例的主要目的,另一部分文字是自动生成的,这样在用例出错时,可以帮助开发人员定位问题。
输入数据与副作用配置
这一步可能是应用开发人员在低代码平台上“编写”测试用例的最大工作量所在了。你可以回顾一下被测功能的定义图。
在一个被测功能中,一组输入数据就会对应一个副作用,所谓副作用实际上就是受波及的组件在更新后的数据。掐住一头一尾,无视中间环节,就等于说,给定一笔数据,预期就要得到另一笔数据,这一头一尾两笔数据,必须由开发人员来配置。
下图是我们的低代码平台Awade在这里的配置界面,主要由前置条件和验证数据两个Tab卡组成,对应着一头一尾两笔数据的配置。下面先看前置条件,也就是输入数据的配置。选定一个组件后,在“值”框里,填上预期数据,示意图中的输入数据是“江苏”,然后就没有然后了。
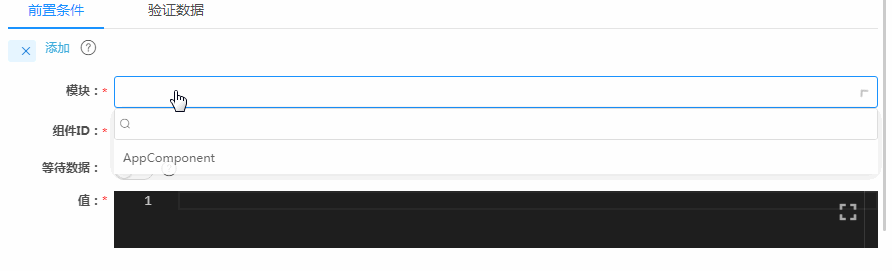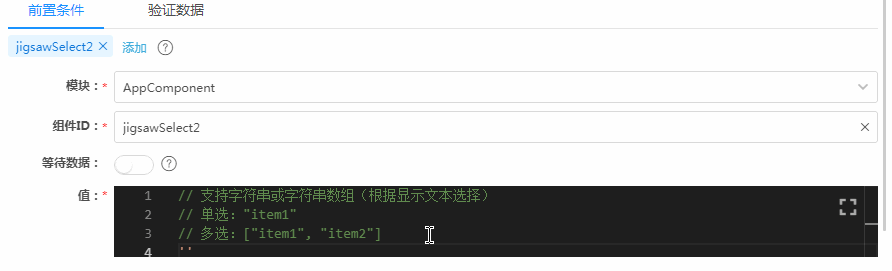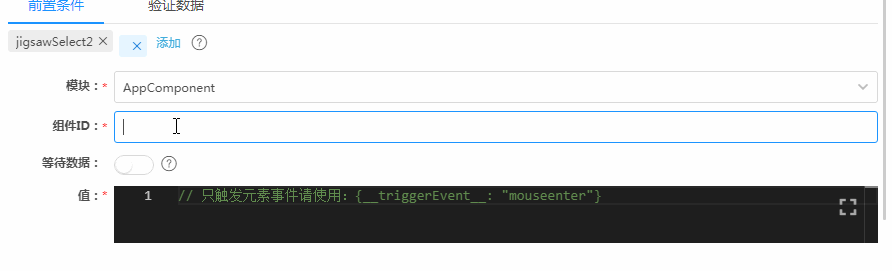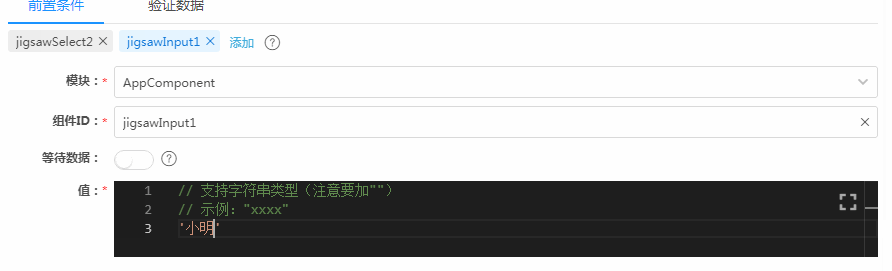
如果你没手写过UI自定义测试用例,你可能觉得这个过程很自然,但如果你有手写过测试代码,你可能会惊呼:这不科学。为啥呢?因为整个过程,看不到任何技术细节,包括目标组件的Selector,还包括测试框架的API调用。这些技术细节正是传统开发和维护UI测试用例代码所有问题的根源,而现在这些细节一个都不存在了,这就是要惊呼的原因。
仔细观察前面的配置过程,你可以发现,图中一共配置了2个组件的输入数据,一个是文本输入框、一个是下拉选择框。在这个配置完成之后,类似下面这样的代码就会被低代码平台生成出来了:
it('基础数据查询测试', () => {
// 前置条件配置
cy.get('#jigsawInput11').type('小明');
cy.get('#jigsawSelect12').select('江苏');
})
提示:我们底层使用了Cypress作为浏览器驱动,所以上述这段代码用的都是Cypress的API。
不过你可能会有这样的疑问:代码中的Selector是哪来的?当你选定了一个组件时,低代码平台就已经知道它的Selector了,我们用的是ID选择器,低代码平台的其他功能会确保每个组件都有唯一的ID。
下面来看看验证数据的配置。
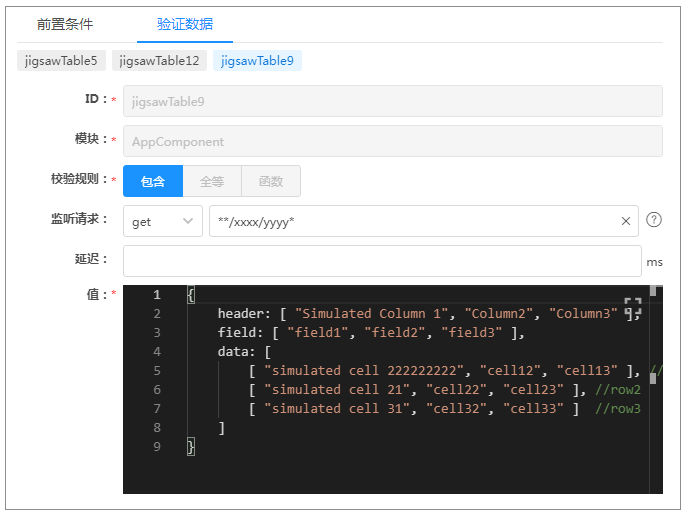
首先看到的第一栏是所有受到这个功能波及的组件,虽然就这么几个不起眼的文本,在上一讲中,我们可是花了那么多力气,通过装饰器还有AST分析等手段来寻找它们!每个受波及的组件都可以配置对应的预期数据,当然,你也可以选择某些不配置。在“值”框里输入它受被测功能影响后的数据就好了。
下面是生成的测试用例代码示例:
it('基础数据查询测试', () => {
// 数据校验
const expectData = {
header: [ "...", "...", "...", "..." ],
field: [ "...", "...", "...", "..." ],
data: [
[ "...", "...", "...", "..." ],
[ "...", "...", "...", "..." ]
]
}
// 其中 contains 是根据界面的“校验规则”选项生成的
checkData(this.jigsawTable1.data, expectData, 'contains');
})
提示:如果配置了多个受波及组件的校验数据,则这里会有多个类似的代码段会被自动生成出来。
其中,checkData的定义类似这样:
function checkData(currentData, expectData, rule) {
// 上一讲我的最后,我留了一个名为assertJsonEquality函数的示例代码
// 就将在这里被调用
}
至此,一个被测功能的测试用例代码就被完整地生成出来了。写到这里,我感到一阵唏嘘,前面我们绕了那么大一个弯,阐述了许多概念,设计了许多算法,铺了一段又一段的路,填平了路上一个又一个的坑,终于在只需要开发人员填写一头一尾两笔数据的前提下,自动把测试用例的代码完完整整给生成出来了。
真可以说是:把简单留给别人,把复杂留给自己。
HTTP拦截器
同学等一等,还没下课,还有一些收尾的工作要做。
对于一个Web App来说,HTTP请求就如同呼吸一样与我们如影随形,几乎每个功能都要与HTTP请求打交道,所以几乎每个功能都要有HTTP配置,但是,大多数HTTP配置都是相似的,我们有必要进一步简化这方面的配置。
许多页面在一打开就会去请求初始化数据,如果页面打开后,不等待这些服务返回就执行操作,用例肯定会失败。于是,我们做了一个这样的配置:
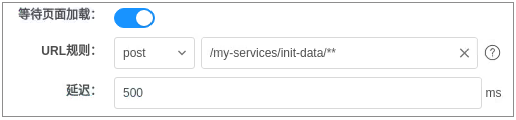
如果页面有初始化数据服务,只要点亮等待的开关,并配置URL规则,就可以自动拦截了。此时,我们生成的代码示例如下:
// 在测试文件中的 beforeEach 钩子中设置拦截器
beforeEach(() => {
cy.intercept('POST', '/my-services/init-data/**', (req) => {
// 设置超时
const timeout = 30000; // 30 秒
const timeoutId = setTimeout(() => {
throw new Error('服务请求超时');
}, timeout);
// 在拦截器中修改请求
req.continue((res) => {
clearTimeout(timeoutId); // 如果请求成功,则清除超时定时器
});
}).as('interception');
});
// 编写你的测试用例
it('测试拦截的服务请求超时', () => {
// 发起服务请求
cy.visit('https://example.com');
// 等待拦截器触发
cy.wait('@interception').then(() => {
// 在这里进行其他操作
});
});
类似的配置其实在上面就出现过了,只是你可能没注意到而已,我们在配置验证数据时的界面如下:
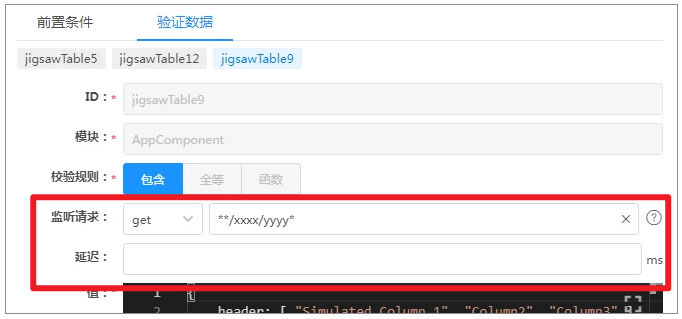
注意到“监听请求”这个配置,它干了相似的事情,和拦截页面初始化数据请求的不同点在于触发的时机,其他配置项的功能基本一样,最终生成的代码也基本一样。所以,如果初始化数据的服务和这里的更新组件数据使用的服务规则相同,那这里就可以不用配置了。
一键测试与反馈
自动生成测试用例代码这么难的事情,我们都已经做了,现在离完整的自动化测试的闭环,就只剩下了一键执行自动化测试了。接下来就讨论一下这最后一公里。
如果你的低代码平台已经支持预览应用最终效果,那么一键执行自动化测试,实际上就是一哆嗦的事情。因为一键执行测试用例的最大难点在于应用执行环境的搭建,而应用已经能在低代码平台里预览了,意味着应用执行环境已经就绪。至于那些集成测试驱动框架(如Cypress)和浏览器驱动等事情,都不算太难,根据测试框架的操作手册,一般都可以顺利安装。
反之,如果你的低代码平台现在还未支持预览应用最终效果,那么,要实现一键执行自动化测试恐怕就没那么容易了,这几乎等于要先实现低代码平台自动搭建应用执行环境这一大功能。但是即使如此,也不意味着没有办法。
既然应用无法在低代码平台上直接运行,那么,我们就想办法自动在应用的运行时上部署自动化测试所需的功能算了,包括测试框架、浏览器驱动等。可以在导出应用时,连同测试用例代码一起,同时导出一个一键部署和启动测试的脚本,引导应用开发人员执行这个脚本来执行自动化测试。
可想而知,这个脚本内部会有一点复杂,但是应用开发人员看不到,对他来说,就是执行一个启动测试脚本,然后等着看结果而已。我们将这样的操作称为一键启动,也不是不可以。
这样,我们就完成了自动生成测试用例代码一键执行的闭环了。
小结
这一讲的内容相对轻松一些,没有那么多的概念和算法要学。
前面两节课我们做了大量铺垫,给出了被测功能的定义,一些概念和一些算法,基于这些铺垫,我们终于在这讲中完成了通过简单配置来生成测试用例代码的目的。
我们从一个普通的页面交互功能开始归纳,不断抽象,隐藏掉了与交互功能无关的许多细节,最终得到了被测功能的定义。这个定义实际上保留了一个被测功能生命周期中的4个主要动作,按顺序分别是:输入数据、触发功能、发生一些事情和最后的产生副作用。
有了这个定义,我们就进而设计了一个自动发现被测功能的算法,我们抓住了触发功能这个环节,因为在页面上几乎只有一种情况会触发功能,那就是交互事件。单一的来源使得我们可以更容易跟踪和分析它,然后按图索骥,找到被测功能所波及到的组件,也就是找到了被测功能的副作用。
对于事件的跟踪和分析,我们采用了两个重要手段,一个是装饰器、一个是AST。
其实,装饰器不是必须的,但是,在低代码平台上,一个App的配置数据需要分析的节点数量是数以千计的,简单粗暴的if else不是好手段。装饰器可以很好地解决if else的问题,甚至还能保证平台在日后的迭代过程中,新增的属性节点依旧可以被有效覆盖,而删除时节点,可顺带清理掉已覆盖的分析逻辑。
AST是健壮地分析和处理代码块的唯一手段。在低代码平台上,事件的处理逻辑,也有可能是一整块代码,在这个情况下,只能用AST来分析和处理它们。
对于事件的跟踪和分析的目的,是为了找出受波及的组件,也就是找出被测功能的副作用。为啥一定要找出被测功能的副作用呢?那是因为我们要生成测试用例核心目的——断言的代码,没有断言的测试用例毫无意义。
在完成了这许多的工作之后,我们终于可以通过简单配置来生成测试用例代码了,下面这个图展示了几个关键的配置点。

- 用例的串行并行配置来自于被测功能的顺序,实际上,被测功能的顺序更主要是由业务决定的,因此需要由开发人员通过配置来设置各个功能点的执行顺序。
- 输入数据和副作用的配置,实际上就是要求开发人员给出一个功能点的初始化数据和预期数据,这一头一尾两笔数据。初始化数据用于生成模拟人工操作来选定与此功能相关的界面上的组件的数据,而预期数据则是用于生成断言代码。
- 由于HTTP请求几乎每个被测功能都会涉及,因此为了避免重复劳动,我们做了一个统一的配置,由开发人员填写URL规则,一次性完成所有HTTP请求的配置和自动等待。
每一个配置项的背后,都对应着需要生成的代码,开发人员在无感知情况下,就获得了非常专业的自动化测试代码,这就是近期这3讲内容的终极目标。
思考题
我在第21讲中提到,在传统手工开发自动化测试用例的实践中,正是由于页面自动化测试用例的长期维护成本非常高,导致了页面自动化测试是笑着进去哭着出来。现在,我们实现了自动生成自动化测试用例的代码了,为啥说,这个问题就可以得到根本性的改变了呢?
期待你的分享!那么随着这节课的结束,我们今年的动态更新内容就基本交付完了,期间如果你有更加感兴趣的话题,欢迎给我留言,我们找机会探讨。当然,在低代码这块,如果有重大的发展,我还是会及时同步给你的。
- 静心 👍(0) 💬(0)
没太明白,装饰器和AST是怎么使用的?是说已经隐藏到Cypress测试框架中了吗?
2023-11-22 - 杨春寅 👍(0) 💬(0)
学习打卡
2023-10-27 - ifelse 👍(0) 💬(0)
从业务角度来确定哪些功能要串行执行,才是最合理的。 --记下来
2023-07-31 - ifelse 👍(0) 💬(0)
学习打卡
2023-07-31