Node.js内存与流:从今天开始忘记字符串吧
你好,我是winter。
在本节课,我们将会学习一些 Node.js 的基本机制,通过了解这些基本机制,我们可以更好地理解 Node.js 其它 API 的使用,也能够帮助我们进一步把思维过渡到系统编程,处理输入输出、文件、内存等系统时更加得心应手。
Buffer
上节课我们已经了解了进程的基础知识。在操作系统中,进程的核心特性就是它们拥有独立的内存空间。尽管我们的计算机中只有一组硬件内存设备,但是现代操作系统通过内存虚拟化技术,让每个进程看上去都拥有一块独立的内存空间。
在多数现代编程模型中,内存空间对数据的存取是以字节(Byte)为单位,一个字节由 8 个比特位(Bit)组成。
每个比特位可以是 0 或者 1,所以一个字节最多有 256 个不同状态。
通常字节中存储的信息会被理解成无符号整数类型,此时它的范围是 0~255。这个无符号整数,程序员的惯例是用十六进制来表示,刚好占据两个十六进制位,如 F0。
尽管硬件每次能够处理的内存信息可能多于一个字节,但在编程层面,我们无需过多关心,交给操作系统和编译/解释引擎即可。
在进程中,我们可以通过一个整数型(在64位系统中,是64位无符号整数类型)的内存地址来访问对应位置的数据。
在 Node.js 中并没有开放完全的内存访问能力,但是对于对性能要求较高的场景,我们可以通过 Buffer 来管理小段的内存。
1. Buffer与字符串
Buffer 最常见的用法是存储文本信息,所以与字符串互相转换就非常重要了。
但是,要知道,字符串本身是一种抽象的表示,我们无法把字符直接对应到字节数据。这里我们需要了解字符串编码的一些相关知识。
字符集(Character Set, Charset):字符集规定了一系列字符和它们对应的整数,与字符对应的整数被称作码点(Code Point)。
编码(Encoding):编码规定了字符集中码点如何被转换到字节,通常与字符集是一一对应关系,只有 Unicode 对应了多种编码方式。
一些重要的字符集和编码:
- ASCII:计算机世界最早的字符集,由美国国家标准协会(ANSI)制定,所以有时也被称作 ANSI 字符集。其中包含 127 个字符,涵盖了英文字母、数字、符号和一些排版控制字符。几乎所有的字符集前 127 个字符都与 ASCII 字符集保持一致。
ASCII 既是字符集,也是编码方式,它的每个字符码点对应了一个字节。因为影响太过深远,所以有时其它字符集的码点会被误称为“ASCII 码”。 - Unicode: 最重要、最全面、最权威的字符集,包含了全球所有语言和大量符号,现在还包括大量的 emoji 表情图。
Unicode的码点范围很大,从 0 到 0x10FFFF,每 65536 个字符(即四位十六进制)被划分为一个平面(Plain)。其中,从 0 到 0xFFFF 最常用,被称作基本多文种平面(BMP)。
Unicode 支持 3 种编码方式:
编码方式1: UTF8
UTF8 最少用 8 个比特(1个字节)表示一个字符,它是编码层面与 ASCII 兼容的,即,如果我们只使用 ASCII 字符集中的字符,那么 UTF8 与 ASCII 编码产生的字节序列完全一致。
这种编码在英文字母和数字较多的情况下最省空间,但是每个字符占据的空间不固定,如果读取特定位置字符,必须要从头开始访问之前的每一个字符。
编码方式2: UTF16
UTF16 最少用 16 个比特(2 个字节)表示一个字符,它也是不固定位数编码,但如果只使用 BMP 中的字符,则可以视为固定位数编码。
编码方式3:UTF32
UTF32 用 32 个比特(4 个字节)表示一个字符,它的缺点是占据空间较大,它的优势是固定字节数表示的,我们可以通过编码占用的空间直接推算出字符数,当我们要截取或者访问某个特定位置的字符时,可以直接找到对应的偏移量,而无需读取前面的字符。
- GB2312,GBK,GB18030:中国国家标准,现行为 GB18030,收录汉字较全,与Unicode 不兼容,在纯汉字和英文环境下比 Unicode 更节省空间,如果不能确保纯汉字和英文环境,建议使用 Unicode。
- UCS2:特定历史时期的产物,字符集与 Unicode 的 BMP 一致,编码与 UTF16 一致,任何情况下不建议使用。
- latin1:ISO-8859-1 标准规定的拉丁字符集,扩展了 ASCII 字符集到 256 位刚好占满一个字节,加入了一些欧洲各国的拉丁字符,它字符集与 Unicode 兼容,编码与 UTF8 兼容。某些仅仅需要西文的场景下可以用于无损替代 ASCII。
JavaScript 中字符串实际采用 UTF16 编码,并且把每个 Unicode 编码单元视为一个“字符”。BMP 之外的字符在 JavaScript 字符串中会被视为两个“字符”,所以其实 JavaScript 字符串的长度、charAt 等如果涉及 BMP 之外的字符,都是不准确的。
当我们把字符串存入 Buffer 时,或者从 Buffer 中的字节数据读取出字符串时。必须要指定编码方式,如:
Node.js 中支持以下字符串编码方式:
- utf8
- ascii
- utf16le
- latin1
- ucs2
此外,Node.js 中还支持以一定编码算法处理字符串,之后存入 Buffer,它们也可以以编码名称的方式使用:
- hex
- base64
- base64url
2. Buffer 与 ArrayBuffer、TypedArray
Node.js 设计 Buffer 机制时,JS 语言规范还没有制定二进制相关的基础库。所以 Buffer 与 JS 语言原生提供的二进制操作并不兼容。后续 Node.js 的版本更新中,引入了若干 API,使得二者可以互相转换。
尽管名字与 ArrayBuffer 相似,但是 Node.js 中的 Buffer 实际上与 JS 原生的 TypedArray 更为接近,Node.js 较新版本中,Buffer 会继承 TypedArray(Uint8Array)作为其子类。
Buffer 的 buffer 属性可以获取到其底层的 ArrayBuffer,但是注意,这个 ArrayBuffer 实际上指向了操作系统分配的一块内存,它可能尺寸远大于 Buffer 本身的内存。
实际上,我们可以用三要素来确定 Node.js 的 Buffer 与其所在 ArrayBuffer 的关系,分别是:
buffer.buffer(ArrayBuffer类型)buffer.offsetbuffer.length
如果我们要从 ArrayBuffer 创建一个 Buffer,则可以通过 Buffer.from 方法。
import {Buffer} from "node:buffer";
const buffer = Buffer.from([1, 2, 3, 4]);
const buffer2 = Buffer.from(buffer.buffer, buffer.offset, buffer.length);
console.log(buffer == buffer2); //false,两个Buffer是不同对象
buffer[0] = 5; //修改原始的buffer
console.log(buffer2); //buffer2跟着变化,说明两者指向同一内存
我们永远无法创建两个指向同一块内存或者互相交叠的 ArrayBuffer,但是我们可以创建两个指向同一块内存或者部分交叠的 Buffer。因此我们在操作 Buffer 时,必须特别小心,我们编写代码逻辑时不能假设 Buffer 是被独占的。
我们也可以使 TypedArray 跟 Buffer 指向同一块内存区域,用于操作 Buffer 中的字节。 TypedArray 有多种类型,请参考下面表格:
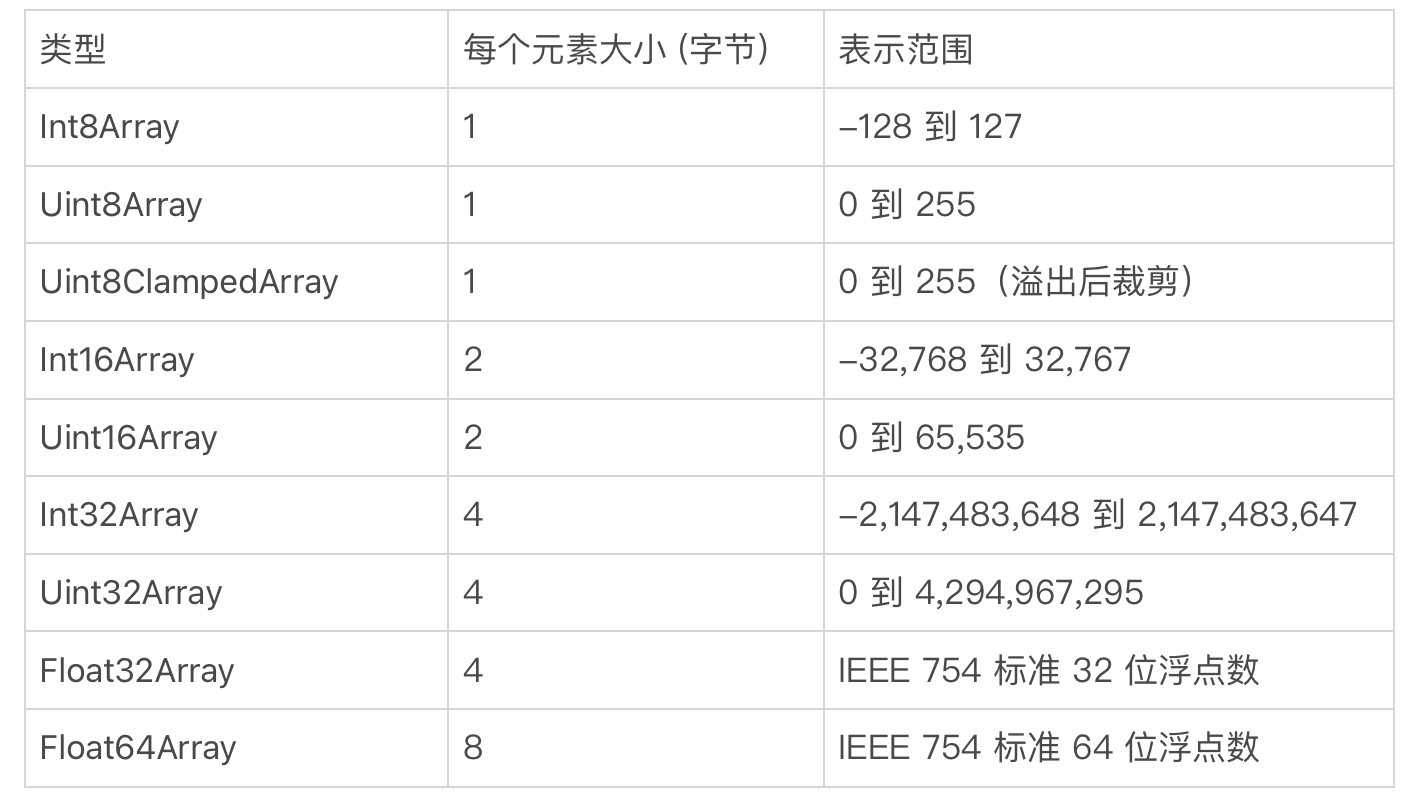
比较常见的操作是使用 Uint8Array,其中每个无符号整型刚好是一个字节。
有符号的整数采用补码的形式表示,正整数的补码与其二进制原码相同,负整数的补码是其对应正数的二进制取反(按位取反),然后加 1。
浮点数的表示则较为复杂,分为单精度浮点数(32 位)和双精度浮点数(64 位)。整体来讲,使用的是二进制科学计数法来表示,一个浮点数的比特位被分成三个部分:
- 符号位(S):1 位,0 表示正数,1 表示负数。
- 指数位(E):用于存储移码(偏移的二进制数),等于偏移量加上指数。
- 单精度8位,偏移量 0b1111111 (255)。
- 双精度11位,偏移量 0x111111111 (1023)。
- 尾数位(M):用于存储有效数字,有效数字一定小于 1,所以这里存储的是小数部分,又因为有效数字一定以 1 开头,所以这隐含一个开头的 1。
例如,0.1的双精度浮点数表示:

0.1 的二进制表示是:
0.000110011001100110011…
其中,有效数字是从 1100 开始的无限循环。
- 0.1 是正数,所以符号位是 0。
- 有效数字前有三位,所以指数是 -4,移码后得到 1019,所以指数位是 01111111011。
- 尾数位去掉最前面一个 1,得到 100110011001… 因为是无限循环,所以填满尾数位,最后一位做 0 舍 1 入。
我们可以在 Float64Array 中填入 0.1,再把它转换为 Uint8Array 来观测浮点数的表示:
// 1. 创建一个 Float64Array,并填入 0.1
let float64Array = new Float64Array(1);
float64Array[0] = 0.1;
// 2. 创建一个 Uint8Array,视图指向 Float64Array 的内存位置
let uint8Array = new Uint8Array(float64Array.buffer);
// 3. 打印 Uint8Array 的每个字节的二进制表示
let binaryRepresentation = Array.from(uint8Array).map(byte => byte.toString(2).padStart(8, '0')).reverse().join(' ');
console.log(binaryRepresentation);
//输出:00111111 10111001 10011001 10011001 10011001 10011001 10011001 10011010
注意,这里可以看到浮点数字节序是高位在后,低位在前,所以字节顺序需要反转才能得到正确结果。实际上多字节表示的整数类型也是如此,大家可以自行编写代码查看。
通过对底层内存的观察,我们也可以更好地回答 0.1+0.2 不等于 0.3 这样的问题。
配合 JavaScript 中的位运算操作,还可以实现对内存更精准的位级操作,以应对一些极端的性能需求。
3. 内存共享
Buffer 这样对内存的直接抽象还有一个重要的优势,那就是几乎所有语言对内存和字节的定义都能够互相兼容,并且在同一进程内传递内存块完全没有性能损失。
比如,因为 JavaScript 对象和 C++ 对象的内存表示完全不同,所以在 Node.js 的 C++ 扩展中,如果要跟实现与 JS 的对象通讯,那么往往需要序列化和反序列化。而内存块的概念在所有语言中是一致的,所以如果要传递一块内存,就完全无需任何转换,直接传递内存地址和大小即可,非常简单高效。
JavaScript 中有 SharedArrayBuffer,能够允许我们在不同的 Worker 中访问同一块内存区域。
SharedArrayBuffer 也可以作为 Buffer 的来源,可以创建底层指向 SharedArrayBuffer 的Buffer 实例。
我们来看一个简单的例子:
//主线程
const { Worker } = require('worker_threads');
// 创建一个 4 字节的共享内存
const sharedBuffer = new SharedArrayBuffer(4);
const buffer = Buffer.from(sharedBuffer, 0, 4);
// 启动 Worker 线程
const worker = new Worker('./worker.js', { workerData: sharedBuffer });
// 每秒打印 buffer 的内容
setInterval(() => {
console.log(buffer);
}, 1000);
//worker.js
const { workerData } = require('worker_threads');
// 连接到共享内存
const sharedView = new Int32Array(workerData);
// 每秒计数器加 1
setInterval(() => {
sharedView[0]++;
}, 1000);
但是要注意,这种 worker 通讯的方式虽然高效,但是会产生临界区(多线程编程领域的概念),所以一般要用到 Atomic 这个包来控制内存资源的竞争。
JavaScript 的语言设计刻意规避了多线程内存竞争的场景,所以多数前端工程师无需关心多线程内存竞争的问题。这也导致了,一般前端团队都缺少擅长多线程编程的工程师。
在实践中,建议控制好 SharedArrayBuffer的使用场景,确保仅仅在确实需要大规模传递数据或者高性能要求的场景使用它,并且应该由团队内较为资深的、有多线程开发经验的工程师做好代码评审。
如果要在不同进程间共享内存,实现高效 IPC,则需要使用第三方 C++ 扩展,如 mmap,或者自研 C++ 扩展。其原理与 SharedArrayBuffer 相似,此处就不过多展开了。
Event
事件的概念对于前端工程师来说并不陌生。Node.js 中的事件机制与 Web 差异并不大,主要区别是一些 API 设计上的。
Node.js 的事件以 EventEmiter 为核心。我们可以了解一下基本用法:
const EventEmitter = require('events');
// 创建一个 EventEmitter 实例
const eventEmitter = new EventEmitter();
// 注册一个 'greet' 事件监听器
eventEmitter.on('greet', (name) => {
console.log(`Hello, ${name}!`);
});
// 触发 'greet' 事件
eventEmitter.emit('greet', 'Alice');
eventEmitter.emit('greet', 'Bob');
更常见的做法是继承 EventEmitter,使得我们的某个类具有通过事件来对外通知的能力。
const EventEmitter = require('events');
// 自定义类继承 EventEmitter
class MyClass extends EventEmitter {
constructor() {
super(); // 调用父类的构造函数
}
startTask() {
console.log('Task started...');
// 触发自定义事件
this.emit('taskStarted');
setTimeout(() => {
console.log('Task completed.');
this.emit('taskCompleted', { result: 'success' });
}, 2000); // 模拟异步任务
}
}
// 创建实例
const myInstance = new MyClass();
// 注册事件监听器
myInstance.on('taskStarted', () => {
console.log('Event received: taskStarted');
});
myInstance.on('taskCompleted', (data) => {
console.log(`Event received: taskCompleted with result: ${data.result}`);
});
// 触发方法,启动任务
myInstance.startTask();
// 输出:
// Task started...
// Event received: taskStarted
// (2秒后)
// Task completed.
// Event received: taskCompleted with result: success
EventEmiter 可以用 off 或者 removeListener 来移除事件监听器,这两个 API 没有任何区别,仅仅是命名风格不同,使用 Node.js 的团队应该用内部规范来约束统一使用其中之一。
与 Web API 相比,EventEmiter还提供了更精细地操作事件响应序列的能力:
- .listenerCount() 获取指定事件的监听器数量。
- .listeners() 获取所有监听器。
- .removeAllListeners() 移除所有监听器。
- .once() 注册一次性监听器,响应后将被移除。
- .setMaxListeners() 设定监听器最大数量。
- .prependListener() 使得监听器添加到队列最前。
- .prependOnceListener() 添加一次性监听器到队列最前。
但通常我们并不需要这些操作,在任何场景下,也不推荐使得事件监听器代码依赖监听器执行顺序或者直接操作已经注册的监听器队列。在编码中,我们应该遵循“谁注册事件,谁移除事件”的原则。
Node.js 中还提供了 NodeEventTarget 和 EventTarget,这两个类的 API 风格比较接近于 Web 标准中的 EventTarget。
但是考虑到它的实现并不完全遵循 Web 标准,其功能也少于 EventEmiter,并且与多数 Node.js 的 API 互相不能协作,因此在当前 Node.js 版本中,任何场景下都不建议使用它们。
注意,此处的事件,实际上是同步执行的代码,在调用完成 emit() 时,所有监听器已经被执行。请注意不要与“事件循环”中的事件相混淆。
Stream
当我们在做 Web 编程时,非常习惯用字符串等基础数据类型来处理数据,考虑到单个网页的信息容量是有限的,所以多数情况下这已经足够用。
但是当我们做系统编程时,需要处理的数据通常是以 M 来计量,这时候,如果要把它们作为字符串处理,就会导致巨大的性能开销,因此我们做系统编程时常用的数据结构是“流”。
“流”不但是 Node.js 中的一种数据结构,也是操作系统中广泛使用的概念,比如我们前文接触过的标准输入输出,就是流。
我们可以把流想象成一个管道,其中流淌的液体就是数据。Node.js 的流分为可读流(Readable Stream)和可写流(Writeable Stream)。当然,也可以二者皆是,因为 JS 中不支持多继承,所以有一个专门的双工流(Duplex Stream)来表示它。
1. Stream API
我们首先以最常见的可读流——文件为例,了解一下基本的用法。
const fs = require('fs');
// 创建一个可读流,从文件中读取数据
const readableStream = fs.createReadStream('input.txt', { encoding: 'utf8' });
// 使用 .on('data') 逐块接收数据
readableStream.on('data', (chunk) => {
console.log('Received chunk:', chunk);
});
// 使用 .on('end') 在流结束时触发
readableStream.on('end', () => {
console.log('No more data to read.');
});
我们看到,'data' 和 'end' 两个事件是操作可读流的核心。
const fs = require('fs');
// 创建一个可写流,指定文件路径
const writeStream = fs.createWriteStream('output.txt');
// 使用 write 向文件中写入数据
writeStream.write('Hello, this is the first line of the file.\n');
writeStream.write('Here is the second line.\n');
// 使用 end 来结束写入操作,并可以传入最后的数据
writeStream.end('This is the final line in the file.');
我们看到,write 和 end 两个方法是操作可写流的核心。
我们这样看,整个的 API 设计一点都不吸引人,但是我们还有 pipe。当我们使用 pipe 时,这些 API 看起来就非常好用了。
const fs = require('fs');
// 创建一个可读流,读取文件 input.txt
const readStream = fs.createReadStream('input.txt');
// 创建一个可写流,将数据写入 output.txt
const writeStream = fs.createWriteStream('output.txt');
// 使用 pipe() 将读取流的数据传递给写入流
readStream.pipe(writeStream);
我们也可以连续使用 pipe,比如:
const fs = require('fs');
const zlib = require('zlib');
// 创建一个可读流,读取文件 input.txt
const readStream = fs.createReadStream('input.txt');
// 创建一个可写流,指定输出的压缩文件 output.gz
const writeStream = fs.createWriteStream('output.gz');
// 使用 zlib 压缩流
const gzip = zlib.createGzip();
// 使用 pipe() 将读取流数据压缩后写入输出流
readStream.pipe(gzip).pipe(writeStream);
2. 常见的 Stream
流不但是 Node.js 提供的基础库,它的概念本身也贯穿 Node.js API 的设计,我们简单总结如下:
fs.createReadStream(path[, options]):生成一个可读流,用于从文件中读取数据。fs.createWriteStream(path[, options]):生成一个可写流,用于向文件写入数据。http.createServer((request, response) => {}): http 模块,回调参数中的 request 是可读流,response 是可写流。net.createServer(socket => {}):net 模块,回调参数中的 socket 是双工通讯流。zlib.createGzip():zlib 模块,是双工通讯流。process.stdin:process 模块,标准输入流,是可读流。process.stdout:process 模块,标准输出流,是可写流。process.stderr:process 模块,标准错误输出流,是可写流。child_process.spawn:child_process 模块,创建的子进程,同样有标准输入、标准输出、标准错误输出。
我们可以看到,Node.js 自带的原生模块中,有大量基于 Stream 设计的 API,通过 pipe,我们可以很方便地把它们互相之间连接起来。
尽量基于 pipe 来使用这些 API,也是 Node.js 中的最佳实践模式。
3. 自建 Stream
pipe 虽然好用,但是有时候,我们无法直接把两个流用 pipe 相连接,需要对流进行一定的处理。
这种情况下,如果我们回到 'data' 和 'end' 事件,以及 write和 end 方法这样的写法,那么代码势必会变得冗繁。幸好 Node.js 中提供了非常好的一系列工具来处理它们。
我们可以通过直接创建实例的方式来临时性创建一个流,只需要传入关键的方法实现即可:
const fs = require('fs');
const { Writable } = require('stream');
// 创建 Readable 流从文件读取数据
const fileStream = fs.createReadStream('input.txt');
// 将文件流通过 pipe() 传输到 Writable 流
fileStream.pipe(new Writable({
write(chunk, encoding, callback) {
console.log(chunk.toString());
callback(); //写操作是异步的
}
}));
我们可以以实例的方式来创建 Readable、Writable 和
Duplex。如果我们希望复用,也可以以继承它们的方式使用。
const fs = require('fs');
const { Readable } = require('stream');
// 创建 Writable 流向文件写入数据
const fileStream = fs.createWriteStream('output.txt');
class BufferStream extends Readable {
constructor(buffer){
super();
this.buffer = buffer;
}
_read(size) {
console.log(size); //size 是期望读取的字节数,push 的内存大小一般不要超过这个值
this.push(this.buffer.slice(0, size)); //this.push 是 Readable 的核心方法,用于把数据输出到下游
this.buffer = this.buffer.slice(size);
}
}
// 将文件流通过 pipe() 传输到 Writable 流
new BufferStream(Buffer.from("Hello world!", 'utf8')).pipe(fileStream);
为了方便,Node.js 还提供了一种更简单的双工通讯流
Transform ,顾名思义,它是用于对输入的流做转换后变成输出流。这是一种简化的 Duplex 模型。
const { Transform } = require('stream');
// 创建一个 Transform 流实例,直接传入一个对象,定义 transform 方法
const uppercaseTransform = new Transform({
// 处理每个数据块
transform(chunk, encoding, callback) {
// 将数据转换为字符串,处理为大写,并推送到下游
const uppercased = chunk.toString().toUpperCase();
this.push(uppercased);
callback(); // 通知转换完成
}
});
// 从标准输入读取数据,经过 Transform 流处理后,输出到标准输出
process.stdin.pipe(uppercaseTransform).pipe(process.stdout);
对于 Readable 和 Duplex,我们需要理解稍微复杂一点的概念:背压(Backpressure)。
背压是一个流式数据处理中的重要机制,如果一个 Writable 流的消费速度跟不上生产速度,就会产生背压,以通知生产者减慢生产速度。
它的目的是避免数据过快地生产或传输,超过消费者的处理能力,从而避免内存溢出或过载。具体到代码层面,可以使 Writable 的 _write 返回 false 来产生背压,通过触发 drain事件来消除背压。
而对于上游的 Readable 流,则应该检查 push 的返回值,当其返回 false 时,保留缓冲区中的数据。
pipe 会自动处理背压,所以只需要正确实现 _write,就能享受 pipe 自动化管理的背压。
在我们上面的所有例子中,因为处理的数据规模都非常小,所以完全没有考虑背压问题,当我们处理较大规模的数据时,背压处理就变得非常重要了。
小结
本课我们介绍了 Node.js 的三种重要机制:内存、事件和流。它们虽然对应着三个 API 模块,但是理解其中的机制比理解表面的 API 重要得多。
对于内存,我们应该理解字符串和整数、浮点数等基本类型的内存表示,以及在多线程间共享内存。
事件机制对多数前端工程师并不陌生,只需要熟悉 EventEmmiter 即可。
流是一个比较复杂的概念,我们可以围绕 pipe 去理解流的机制,习惯用 pipe 去处理流,为 pipe 设计流式 API。