01 崩溃优化(上):关于“崩溃”那些事儿
在各种场合遇到其他产品的开发人员时,大家总忍不住想在技术上切磋两招。第一句问的通常都是“你们产品的崩溃率是多少?”
程序员A自豪地说: “百分之一。”
旁边的程序员B鄙视地看了一眼,然后喊到: “千分之一!”
“万分之一” ,程序员C说完之后全场变得安静起来。
崩溃率是衡量一个应用质量高低的基本指标,这一点是你我都比较认可的。不过你说的“万分之一”就一定要比我说的“百分之一” 更好吗?我觉得,这个问题其实并不仅仅是比较两个数值这么简单。
今天我们就来聊一聊有关“崩溃”的那些事,我会从Android的两种崩溃类型谈起,再和你进一步讨论到底该怎样客观地衡量崩溃这个指标,以及又该如何看待和崩溃相关的稳定性。
Android 的两种崩溃
我们都知道,Android崩溃分为Java崩溃和Native崩溃。
简单来说,Java崩溃就是在Java代码中,出现了未捕获异常,导致程序异常退出。那Native崩溃又是怎么产生的呢?一般都是因为在Native代码中访问非法地址,也可能是地址对齐出现了问题,或者发生了程序主动abort,这些都会产生相应的signal信号,导致程序异常退出。
所以,“崩溃”就是程序出现异常,而一个产品的崩溃率,跟我们如何捕获、处理这些异常有比较大的关系。Java崩溃的捕获比较简单,但是很多同学对于如何捕获Native崩溃还是一知半解,下面我就重点介绍Native崩溃的捕获流程和难点。
1.Native崩溃的捕获流程
如果你对Native崩溃机制的一些基本知识还不是很熟悉,建议你阅读一下《Android平台Native代码的崩溃捕获机制及实现》。这里我着重给你讲讲一个完整的Native崩溃从捕获到解析要经历哪些流程。
- 编译端。编译C/C++代码时,需要将带符号信息的文件保留下来。
- 客户端。捕获到崩溃时候,将收集到尽可能多的有用信息写入日志文件,然后选择合适的时机上传到服务器。
- 服务端。读取客户端上报的日志文件,寻找适合的符号文件,生成可读的C/C++调用栈。
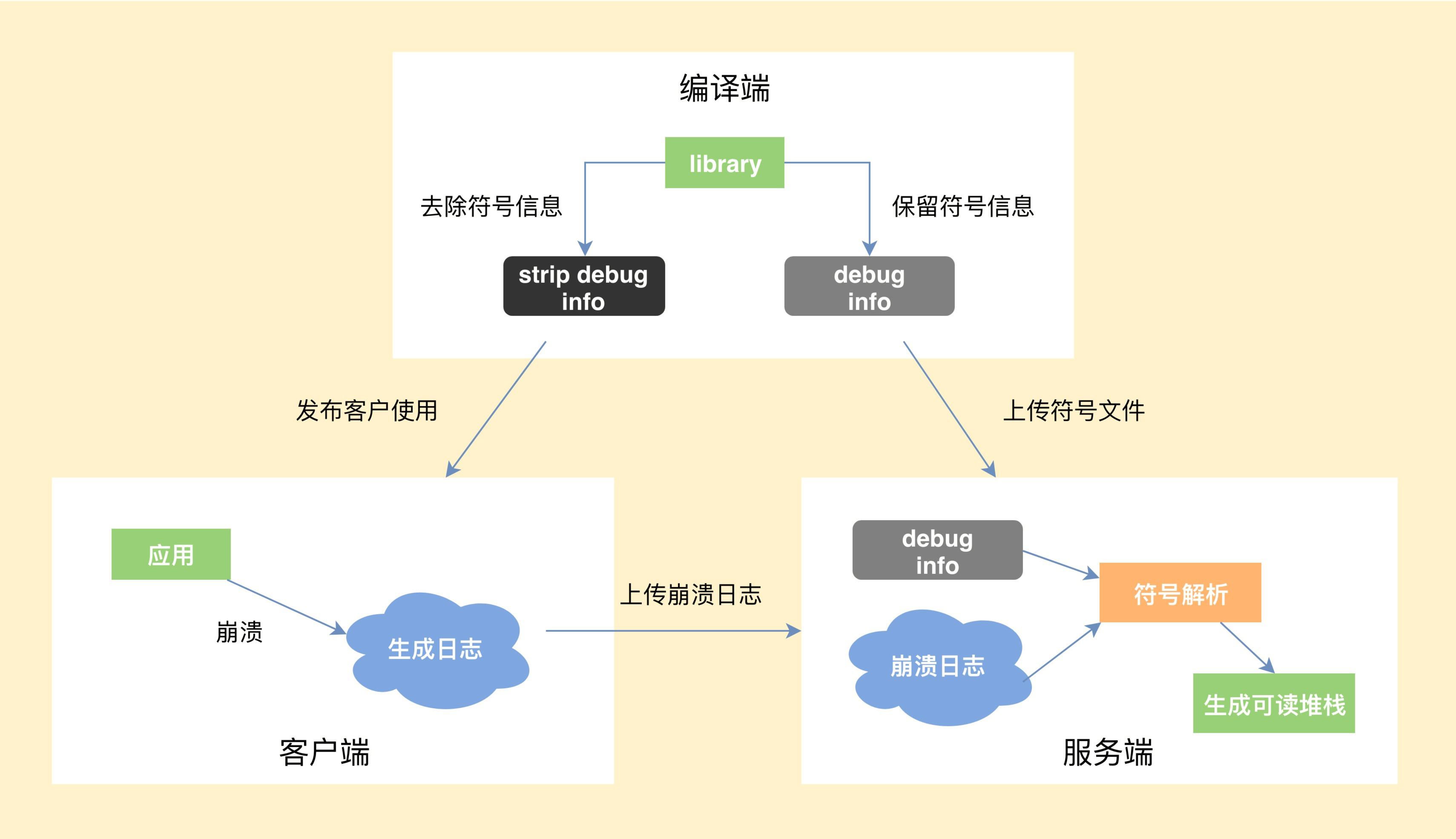
2.Native崩溃捕获的难点
Chromium的Breakpad是目前Native崩溃捕获中最成熟的方案,但很多人都觉得Breakpad过于复杂。其实我认为Native崩溃捕获这个事情本来就不容易,跟当初设计Tinker的时候一样,如果只想在90%的情况可靠,那大部分的代码的确可以砍掉;但如果想达到99%,在各种恶劣条件下依然可靠,后面付出的努力会远远高于前期。
所以在上面的三个流程中,最核心的是怎么样保证客户端在各种极端情况下依然可以生成崩溃日志。因为在崩溃时,程序会处于一个不安全的状态,如果处理不当,非常容易发生二次崩溃。
那么,生成崩溃日志时会有哪些比较棘手的情况呢?
情况一:文件句柄泄漏,导致创建日志文件失败,怎么办?
应对方式:我们需要提前申请文件句柄fd预留,防止出现这种情况。
情况二:因为栈溢出了,导致日志生成失败,怎么办?
应对方式:为了防止栈溢出导致进程没有空间创建调用栈执行处理函数,我们通常会使用常见的signalstack。在一些特殊情况,我们可能还需要直接替换当前栈,所以这里也需要在堆中预留部分空间。
情况三:整个堆的内存都耗尽了,导致日志生成失败,怎么办?
应对方式:这个时候我们无法安全地分配内存,也不敢使用stl或者libc的函数,因为它们内部实现会分配堆内存。这个时候如果继续分配内存,会导致出现堆破坏或者二次崩溃的情况。Breakpad做的比较彻底,重新封装了Linux Syscall Support,来避免直接调用libc。
情况四:堆破坏或二次崩溃导致日志生成失败,怎么办?
应对方式:Breakpad会从原进程fork出子进程去收集崩溃现场,此外涉及与Java相关的,一般也会用子进程去操作。这样即使出现二次崩溃,只是这部分的信息丢失,我们的父进程后面还可以继续获取其他的信息。在一些特殊的情况,我们还可能需要从子进程fork出孙进程。
当然Breakpad也存在着一些问题,例如生成的minidump文件是二进制格式的,包含了太多不重要的信息,导致文件很容易达到几MB。但是minidump也不是毫无用处,它有一些比较高级的特性,比如使用gdb调试、可以看到传入参数等。Chromium未来计划使用Crashpad全面替代Breakpad,但目前来说还是 “too early to mobile”。
我们有时候想遵循Android的文本格式,并且添加更多我们认为重要的信息,这个时候就要去改造Breakpad的实现。比较常见的例如增加Logcat信息、Java调用栈信息以及崩溃时的其他一些有用信息,在下一节我们会有更加详细的介绍。
如果想彻底弄清楚Native崩溃捕获,需要我们对虚拟机运行、汇编这些内功有一定造诣。做一个高可用的崩溃收集SDK真的不是那么容易,它需要经过多年的技术积累,要考虑的细节也非常多,每一个失败路径或者二次崩溃场景都要有应对措施或备用方案。
3.选择合适的崩溃服务
对于很多中小型公司来说,我并不建议自己去实现一套如此复杂的系统,可以选择一些第三方的服务。目前各种平台也是百花齐放,包括腾讯的Bugly、阿里的啄木鸟平台、网易云捕、Google的Firebase等等。
当然,在平台的选择方面,我认为,从产品化跟社区维护来说,Bugly在国内做的最好;从技术深度跟捕获能力来说,阿里UC浏览器内核团队打造的啄木鸟平台最佳。
如何客观地衡量崩溃
对崩溃有了更多了解以后,我们怎样才能客观地衡量崩溃呢?
要衡量一个指标,首先要统一计算口径。如果想评估崩溃造成的用户影响范围,我们会先去看UV崩溃率。
只要用户出现过一次崩溃就会被计算到,所以UV崩溃率的高低会跟应用的使用时长有比较大的关系,这也是微信UV崩溃率在业界不算低的原因(强行甩锅)。当然这个时候,我们还可以去看应用PV崩溃率、启动崩溃率、重复崩溃率这些指标,计算方法都大同小异。
这里为什么要单独统计启动崩溃率呢?因为启动崩溃对用户带来的伤害最大,应用无法启动往往通过热修复也无法拯救。闪屏广告、运营活动,很多应用启动过程异常复杂,又涉及各种资源、配置下发,极其容易出现问题。微信读书、蘑菇街、淘宝、天猫这些“重运营”的应用都有使用一种叫作“安全模式”的技术来保障客户端的启动流程,在监控到客户端启动失败后,给用户自救的机会。
现在回到文章开头程序员“华山论剑”的小故事,我来揭秘他们解决崩溃率的“独家秘笈”。
程序员B对所有线程、任务都封装了一层try catch,“消化”掉了所有Java崩溃。至于程序是否会出现其他异常表现,这是上帝要管的事情,反正我是实现了“千分之一”的目标。
程序员C认为Native崩溃太难解决,所以他想了一个“好方法”,就是不采集所有的Native崩溃,美滋滋地跟老板汇报“万分之一”的工作成果。
了解了美好数字产生的“秘笈”后,不知道你有何感想?其实程序员B和C都是真实的案例,而且他们的用户体量都还不算小。技术指标过于KPI化,是国内比较明显的一个现象。崩溃率只是一个数字,我们的出发点应该是让用户有更好的体验。
如何客观地衡量稳定性
到此,我们讨论了崩溃是怎么回事儿,以及怎么客观地衡量崩溃。那崩溃率是不是就能完全等价于应用的稳定性呢?答案是肯定不行。处理了崩溃,我们还会经常遇到ANR(Application Not Responding,程序没有响应)这个问题。
出现ANR的时候,系统还会弹出对话框打断用户的操作,这是用户非常不能忍受的。这又带来另外一个问题,我们怎么去发现应用中的ANR异常呢?总结一下,通常有两种做法。
1. 使用FileObserver监听/data/anr/traces.txt 的变化。非常不幸的是,很多高版本的ROM,已经没有读取这个文件的权限了。这个时候你可能只能思考其他路径,海外可以使用Google Play服务,而国内微信利用Hardcoder框架(HC框架是一套独立于安卓系统实现的通信框架,它让App和厂商ROM能够实时“对话”了,目标就是充分调度系统资源来提升App的运行速度和画质,切实提高大家的手机使用体验)向厂商获取了更大的权限。
2. 监控消息队列的运行时间。这个方案无法准确地判断是否真正出现了ANR异常,也无法得到完整的ANR日志。在我看来,更应该放到卡顿的性能范畴。
回想我当时在设计Tinker的时候,为了保证热修复不会影响应用的启动,Tinker在补丁的加载流程也设计了简单的“安全模式”,在启动时会检查上次应用的退出类型,如果检查连续三次异常退出,将会自动清除补丁。所以除了常见的崩溃,还有一些会导致应用异常退出的情况。
在讨论什么是异常退出之前,我们先看看都有哪些应用退出的情形。
- 主动自杀。
Process.killProcess()、exit()等。 - 崩溃。出现了Java或Native崩溃。
- 系统重启;系统出现异常、断电、用户主动重启等,我们可以通过比较应用开机运行时间是否比之前记录的值更小。
- 被系统杀死。被low memory killer杀掉、从系统的任务管理器中划掉等。
- ANR。
我们可以在应用启动的时候设定一个标志,在主动自杀或崩溃后更新标志,这样下次启动时通过检测这个标志就能确认运行期间是否发生过异常退出。对应上面的五种退出场景,我们排除掉主动自杀和崩溃(崩溃会单独的统计)这两种场景,希望可以监控到剩下三种的异常退出,理论上这个异常捕获机制是可以达到100%覆盖的。
通过这个异常退出的检测,可以反映如ANR、low memory killer、系统强杀、死机、断电等其他无法正常捕获到的问题。当然异常率会存在一些误报,比如用户从系统的任务管理器中划掉应用。对于线上的大数据来说,还是可以帮助我们发现代码中的一些隐藏问题。
所以就得到了一个新的指标来衡量应用的稳定性,即异常率。
前不久我们的一个应用灰度版本发现异常退出的比例增长不少,最后排查发现由于视频播放存在一个巨大bug,会导致可能有用户手机卡死甚至重启,这是传统崩溃收集很难发现的问题。
根据应用的前后台状态,我们可以把异常退出分为前台异常退出和后台异常退出。“被系统杀死”是后台异常退出的主要原因,当然我们会更关注前台的异常退出的情况,这会跟ANR、OOM等异常情况有更大的关联。
通过异常率我们可以比较全面的评估应用的稳定性,对于线上监控还需要完善崩溃的报警机制。在微信我们可以做到5分钟级别的崩溃预警,确保能在第一时间发现线上重大问题,尽快决定是通过发版还是动态热修复解决问题。
总结
今天,我讲了Android的两种崩溃,重点介绍了Native崩溃的捕获流程和一些难点。做一个高可用的崩溃收集SDK并不容易,它背后涉及Linux信号处理以及内存分配、汇编等知识,当你内功修炼得越深厚,学习这些底层知识就越得心应手。
接着,我们讨论了崩溃率应该如何去计算,崩溃率的高低跟应用时长、复杂度、收集SDK有关。不仅仅是崩溃率,我们还学习了目前ANR采集的方式以及遇到的问题,最后提出了异常率这一个新的稳定性监控指标。
作为技术人员,我们不应该盲目追求崩溃率这一个数字,应该以用户体验为先,如果强行去掩盖一些问题往往更加适得其反。我们不应该随意使用try catch去隐藏真正的问题,要从源头入手,了解崩溃的本质原因,保证后面的运行流程。在解决崩溃的过程,也要做到由点到面,不能只针对这个崩溃去解决,而应该要考虑这一类崩溃怎么解决和预防。
崩溃的治理是一个长期的过程,在专栏下一期我会重点讲一些分析应用崩溃的方法论。另外,你如果细心的话,可以发现,在这篇文章里,我放了很多的超链接,后面的文章里也会有类似的情况。所以,这就要求你在读完文章之后,或者读的过程中,如果对相关的背景信息或者概念不理解,就需要花些时间阅读周边文章。当然,如果看完还是没有明白,你也可以在留言区给我留言。
课后作业
Breakpad是一个跨平台的开源项目,今天的课后作业是使用Breakpad来捕获一个Native崩溃,并在留言区写下你今天学习和练习后的总结与思考。
当然我在专栏GitHub的Group里也为你提供了一个Sample方便你练习,如果你没使用过Breakpad的话,只需要直接编译即可。希望你可以通过一个简单的Native崩溃捕获过程,完成minidump文件的生成和解析,在实践中加深对Breakpad工作机制的认识。
我要再次敲黑板划重点了,请你一定要坚持参与我们的课后练习,从最开始就养成学完后立马动手操作的好习惯,这样才能让学习效率最大化,一步步接近“成为高手”的目标。当然了,认真提交作业的同学还有机会获得学习加油礼包。接下来,就看你的了!
欢迎你点击“请朋友读”,把今天的内容分享给好友,邀请他一起学习。最后别忘了在评论区提交今天的作业,我也为认真完成作业的同学准备了丰厚的“学习加油礼包”,期待与你一起切磋进步哦。

 }{:referrerpolicy="no-referrer"
}{:referrerpolicy="no-referrer"
- Owen 👍(17) 💬(0)
关于breakpad的学习,结合老师的讲解和自己的爬坑,参照老师的demo,自己写了个自己觉得理解比较通透的总结,欢迎各位大佬指导和建议https://github.com/devzhan/Breakpad
2018-12-24 - 周大军 👍(9) 💬(1)
首先感谢下前面同学的优质评论,我遇到一些问题实在搞不定时候,参考评论解决了一些问题。以下是我具体遇到的一些问题,希望能够给用Ubuntu作为开发环境的同学一点帮助。 PC操作系统:Ubuntu18.04 X64 AS版本:3.1 手机:华为V8 8.0系统 遇到的问题: 1. 导入项目编译不过: Build command failed. Error while executing process /home/jayden/Android/Sdk/cmake/3.6.4111459/bin/cmake with arguments {-H/mnt/D..... CMake Error: CMAKE_C_COMPILER not set, after EnableLanguage CMake Error: CMAKE_CXX_COMPILER not set, after EnableLanguage -- Configuring incomplete, errors occurred! 解决方法: 下载cmake 3.6对应的ndk版本,下载ndk12版本( https://dl.google.com/android/repository/android-ndk-r12b-linux-x86_64.zip)解压到sdk路径下,并在local.properties配置上对应的ndk.dir路径。 2. minidump_stackwalk dump对应的 crash文件时候,报错,如上老师说的,需要自己编译对应环境的源码,所以我选择下载https://github.com/google/breakpad里的depot_tools,然后make install出来自己用。也可以借鉴其他人下载缺失的头文件来编译github上的源码。 3. addr2line的时候,报错 File format not recognized, Linux的话需要用aarch64-linux-android-4.9,而不是arm-linux-androideabi-4.9 。 ~/Android/Sdk/android-ndk-r12b/toolchains/aarch64-linux-android-4.9/prebuilt/linux-x86_64/bin/aarch64-linux-android-addr2line -f -C -e sample/build/intermediates/transforms/mergeJniLibs/debug/0/lib/arm64-v8a/libcrash-lib.so 0x5a0 Crash() /mnt/Data/github/Geek_Android_Improve/Chapter01/sample/src/main/cpp/crash.cpp:10
2018-12-06 - 永远年轻 👍(7) 💬(3)
虽然历经阻碍,最终没有 dump 成功,但可以给还没操作的同学一点建议 1.最好自备梯子,导入工程会很顺利 2.Smaple 里「补充内容」那几行代码是加到 build.gradle -> andoroid -> defaultConfig 里的 3.装在 ARM 设备上时提示找不到 "libbreakpad-core.so" , build 一个 apk 就好了 4.macOS 10.14 删除了 libstdc++.6.dylib 和 libstdc++.dylib 两个动态库,/usr/lib 里的同名文件都是 libstdc++.6.0.9.dylib 的替身,用 minidump_stackwalk 时会提示 「__ZTTNSt7__cxx1118basic_stringstreamIcSt11char_traitsIcESaIcEEE」这个方法找不到,通过 google 搜索都是 Xcode 开发相关的解决方案 ps 试着下 depot_tools 自己编译,要下载好几个 G 的数据,放弃了。
2018-12-04 - 孙鹏飞 👍(20) 💬(1)
关于x86模拟器下无法生成日志的问题是由于clang导致的,需要使用gcc编译,例子的readme里已经补上了解决方法
2018-12-01 - 答案 👍(34) 💬(7)
文哥~我发现其实可以不用重新编译minidump_stackwalk,Android自带就有!我是windows系统,在AS安装目录下bin\lldb\bin下。我写了篇文章,亲自试过,也完成了作业!我看大家在评论区都是先编译然后再解析,而且有些学员还碰到各种问题,花了很多时间,所以希望我的经验能够帮助到其他学员,https://www.jianshu.com/p/0bfe7800bdef
2019-01-15 - 东方 👍(21) 💬(1)
try catch 被滥用,藏的很深,吃掉了异常。曾经因为这个问题,整个团队花了两天时间才挖出来。非常愤怒。想从Java虚拟机异常机制入手,拦截所有的Java异常,然后过滤自己感兴趣的信息。但是虚拟机复杂,无从下手。 想问一下张老师有什么好的建议?
2018-12-01 - 二两五花肉 👍(10) 💬(1)
老师您好,学习这里的native崩溃处理,是不是得先学习c++,战五渣表示完全看不懂这些
2018-12-03 - X 👍(6) 💬(2)
你好张老师: 1.请问像微信这种大项目灰度测试一般是怎么做的? 是开发了专门的sdk么,我所知的一般是给某些渠道包作为灰度包,或者客户端根据服务器的配置来决定启用新功能,但感觉都挺麻烦的。 2.另外想问张老师个与本节无关的,就是以前做跑步App,发现进程保活很痛苦,想了解下微信的保活手段有哪些,是否真的有白名单这东西?
2018-12-03 - wmj 👍(6) 💬(1)
bugly里都是native的崩溃,要怎么处理?都是一些信号啥的,无从下手
2018-12-03 - 二两五花肉 👍(4) 💬(3)
我们项目bugly上的native crash太多了 基本都是第三方so库导致的 请问老师该怎么处理
2018-12-03 - GoghVin 👍(3) 💬(2)
老师,您好,我有个问题想咨询下,我看了Breakpad的源码,发现在生成minidump的时候,其获取的是线程栈顶32K的内存区域(BreakPad注释(linux_dumper.cc:/LinuxDumper::GetStackInfo) // Get information about the stack, given the stack pointer. We don't try to // walk the stack since we might not have all the information needed to do // unwind. So we just grab, up to, 32k of stack.), 请问这个理解是正确的吗?如果是正确的,那么只要运行时的栈空间大于32k,那么在服务端进行堆栈回溯的时候,就会有问题,为了验证这个猜测,我在您给的demo基础上进行了测试,代码如下: //==========Code 1=========== int frame[1024]; memset(frame, 0, sizeof(int)*1024); volatile int *a = (int *) (NULL); *a = 1; //==========Code 2=========== int frame[40*1024]; memset(frame, 0, sizeof(int)*40*1024); volatile int *a = (int *) (NULL); *a = 1; Code 1和Code2的堆栈是不一致的,Code1中可以看到函数的调用关系,而Code2中只能看到最后crash的函数,没有调用关系。
2019-03-26 - Stefan 👍(2) 💬(1)
换了aarch64-linux-android-4.9下面的addr2line就可以了 $NDK_HOME/toolchains/aarch64-linux-android-4.9/prebuilt/darwin-x86_64/bin/aarch64-linux-android-addr2line -f -C -e sample/build/intermediates/transforms/mergeJniLibs/release/0/lib/arm64-v8a/libcrash-lib.so 0x5e4
2018-12-06 - 百岁无忧 👍(1) 💬(1)
第一次动手尝试,发现windows下的tools/mac minidump不能用,自己编译了libbreakpad ,生成的各种不同品台的tools ,但是不知道怎么用
2019-03-23 - 松原 👍(1) 💬(1)
请问老师 Dump日志分析中的第1步要如何将抓取到的日志拉取到本地中呢?
2018-12-12 - HI 👍(1) 💬(1)
目前在搞NDK项目,对于Native的错误也很无奈,还好Android Studio在断点调试的模式下,出现cash的时候自动能定位到那个地方,但是这个要复现出来,还有就是有些时候定位的地方并不准确,比如对于虚函数并不能定位到准确的地方,对于内存非法访问闪退,也只能定位到系统的函数,缺少完整的堆栈信息
2018-12-03