06 卡顿优化(下):如何监控应用卡顿?
“我在秒杀iPhone XS的支付页面卡了3秒,最后没抢到”,用户嘶声力竭地反馈了一个卡顿问题。
“莫慌莫慌”,等我打开Android Studio, 用上一讲学到的几个工具分析一下就知道原因了。
“咦,在我这里整个支付过程丝滑般流畅”。这个经历让我明白,卡顿跟崩溃一样需要“现场信息”。因为卡顿的产生也是依赖很多因素,比如用户的系统版本、CPU负载、网络环境、应用数据等。
脱离这个现场,我们本地难以复现,也就很难去解决问题。但是卡顿又非常影响用户体验的,特别是发生在启动、聊天、支付这些关键场景,那我们应该如何去监控线上的卡顿问题,并且保留足够多的现场信息协助我们排查解决问题呢?
卡顿监控
前面我讲过监控ANR的方法,不过也提到两个问题:一个是高版本的系统没有权限读取系统的ANR日志;另一个是ANR太依赖系统实现,我们无法灵活控制参数,例如我觉得主线程卡顿3秒用户已经不太能忍受,而默认参数只能监控至少5秒以上的卡顿。
所以现实情况就要求我们需要采用其他的方式来监控是否出现卡顿问题,并且针对特定场景还要监控其他特定的指标。
1. 消息队列
我设计的第一套监控卡顿的方案是基于消息队列实现,通过替换Looper的Printer实现。在2013年的时候,我写过一个名为WxPerformanceTool的性能监控工具,其中耗时监控就使用了这个方法。后面这个工具在腾讯公共组件做了内部开源,还获得了2013年的年度十佳组件。

还没庆祝完,很快就有同事跟我吐槽一个问题:线上开启了这个监控模块,快速滑动时平均帧率起码降低5帧。我通过Traceview一看,发现是因为上面图中所示的大量字符串拼接导致性能损耗严重。
后来很快又想到了另外一个方案,可以通过一个监控线程,每隔1秒向主线程消息队列的头部插入一条空消息。假设1秒后这个消息并没有被主线程消费掉,说明阻塞消息运行的时间在0~1秒之间。换句话说,如果我们需要监控3秒卡顿,那在第4次轮询中头部消息依然没有被消费的话,就可以确定主线程出现了一次3秒以上的卡顿。
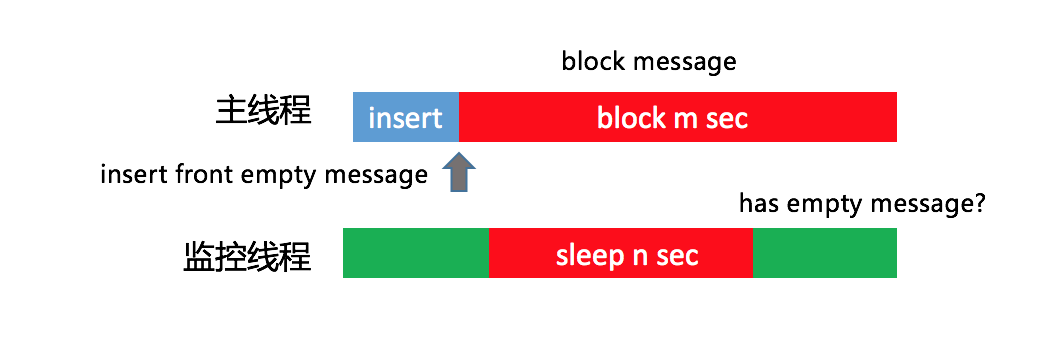
这个方案也存在一定的误差,那就是发送空消息的间隔时间。但这个间隔时间也不能太小,因为监控线程和主线程处理空消息都会带来一些性能损耗,但基本影响不大。
2. 插桩
不过在使用了一段时间之后,我感觉还是有那么一点不爽。基于消息队列的卡顿监控并不准确,正在运行的函数有可能并不是真正耗时的函数。这是为什么呢?
我画张图解释起来就清楚了。我们假设一个消息循环里面顺序执行了A、B、C三个函数,当整个消息执行超过3秒时,因为函数A和B已经执行完毕,我们只能得到的正在执行的函数C的堆栈,事实上它可能并不耗时。
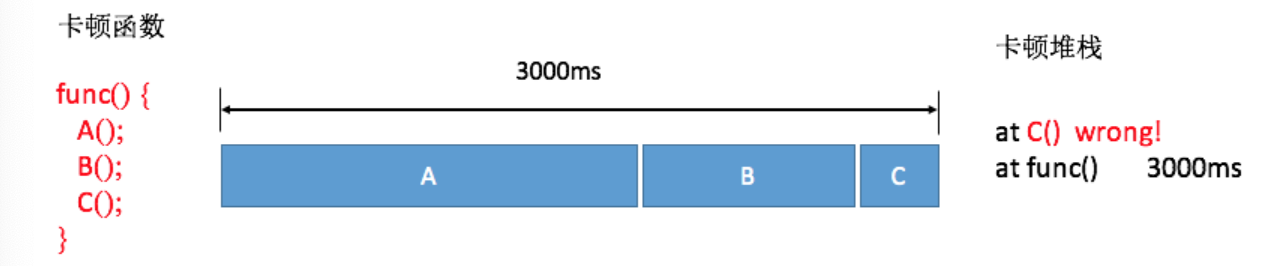
不过对于线上大数据来说,因为函数A和B相对比较耗时,所以抓取到它们的概率会更大一些,通过后台聚合后捕获到函数A和B的卡顿日志会更多一些。
这也是我们线上目前依然使用基于消息队列的方法,但是肯定希望可以做到跟Traceview一样,可以拿到整个卡顿过程所有运行函数的耗时,就像下面图中的结果,可以明确知道其实函数A和B才是造成卡顿的主要原因。

既然这样,那我们能否直接利用Android Runtime函数调用的回调事件,做一个自定义的Traceview++呢?
答案是可以的,但是需要使用Inline Hook技术。我们可以实现类似Nanoscope先写内存的方案,但考虑到兼容性问题,这套方案并没有用到线上。
对于大体量的应用,稳定性是第一考虑因素。那如果在编译过程插桩,兼容性问题肯定是OK的。上一讲讲到systrace可以通过插桩自动生成Trace Tag,我们一样也可以在函数入口和出口加入耗时监控的代码,但是需要考虑的细节有很多。
- 避免方法数暴增。在函数的入口和出口应该插入相同的函数,在编译时提前给代码中每个方法分配一个独立的ID作为参数。
- 过滤简单的函数。过滤一些类似直接return、i++这样的简单函数,并且支持黑名单配置。对一些调用非常频繁的函数,需要添加到黑名单中来降低整个方案对性能的损耗。
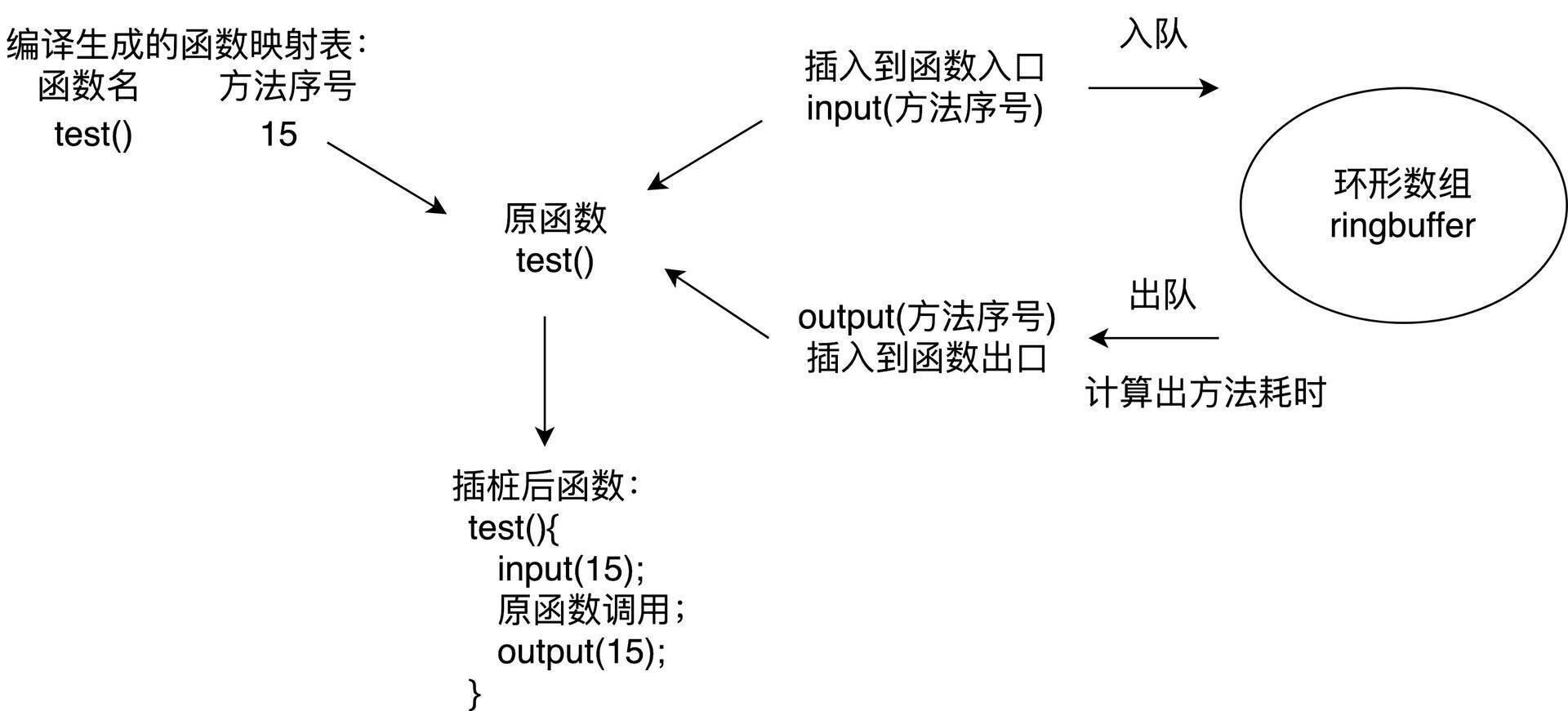
基于性能的考虑,线上只会监控主线程的耗时。微信的Matrix使用的就是这个方案,因为做了大量的优化,所以最终安装包体积只增大1~2%,平均帧率下降也在2帧以内。虽然插桩方案对性能的影响总体还可以接受,但只会在灰度包使用。
插桩方案看起来美好,它也有自己的短板,那就是只能监控应用内自身的函数耗时,无法监控系统的函数调用,整个堆栈看起来好像“缺失了”一部分。
3. Profilo
2018年3月,Facebook开源了一个叫Profilo的库,它收集了各大方案的优点,令我眼前一亮。具体来说有以下几点:
第一,集成atrace功能。ftrace所有性能埋点数据都会通过trace_marker文件写入内核缓冲区,Profilo通过PLT Hook拦截了写入操作,选择部分关心的事件做分析。这样所有systrace的探针我们都可以拿到,例如四大组件生命周期、锁等待时间、类校验、GC时间等。
不过大部分的atrace事件都比较笼统,从事件“B|pid|activityStart”,我们并不知道具体是哪个Activity的创建。同样我们可以统计GC相关事件的耗时,但是也不知道为什么发生了这次GC。

第二,快速获取Java堆栈。很多同学有一个误区,觉得在某个线程不断地获取主线程堆栈是不耗时的。但是事实上获取堆栈的代价是巨大的,它要暂停主线程的运行。
Profilo的实现非常精妙,它实现类似Native崩溃捕捉的方式快速获取Java堆栈,通过间隔发送SIGPROF信号,整个过程如下图所示。
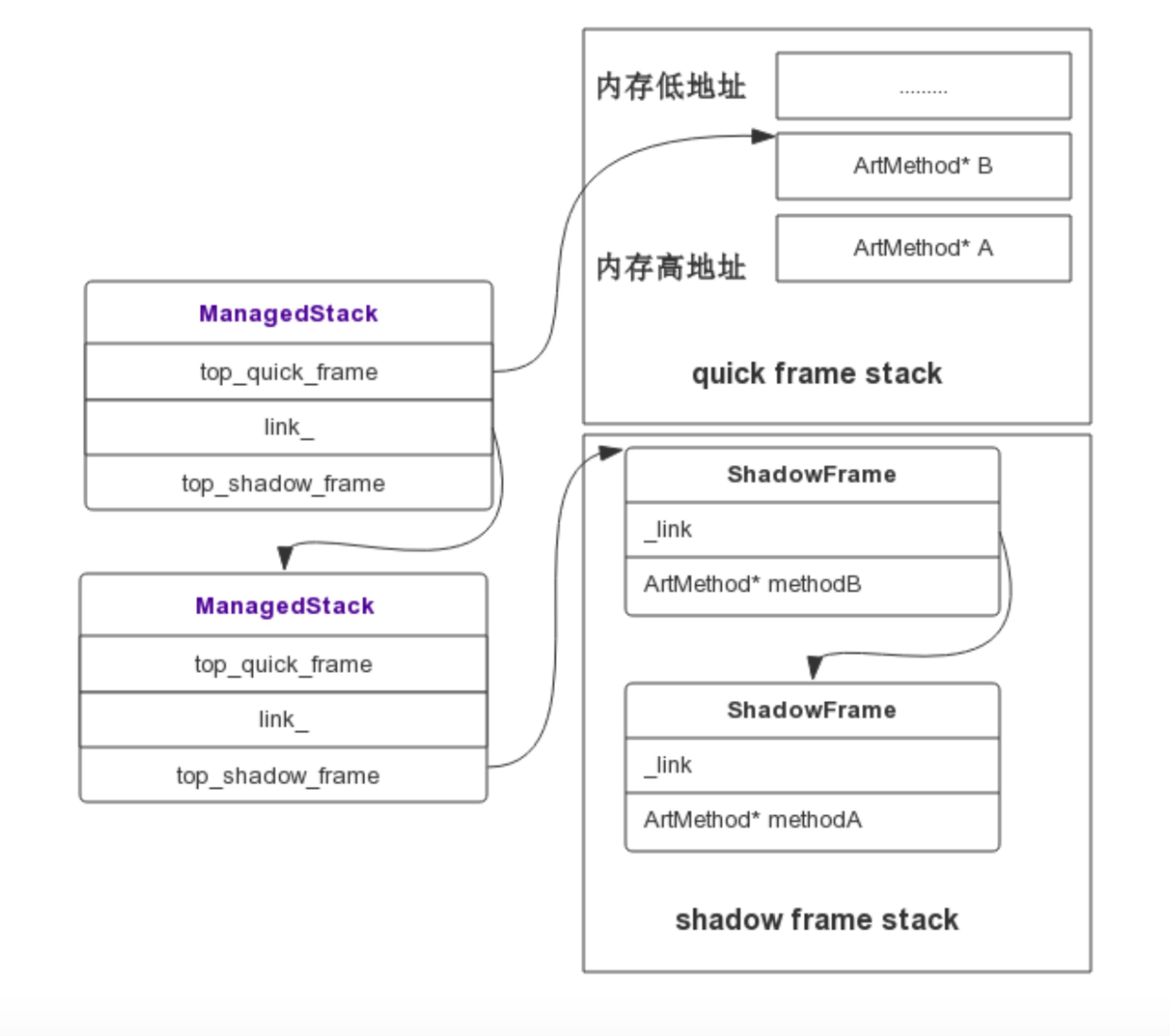
Signal Handler捕获到信号后,拿取到当前正在执行的Thread,通过Thread对象可以获取当前线程的ManagedStack,ManagedStack是一个单链表,它保存了当前的ShadowFrame或者QuickFrame栈指针,先依次遍历ManagedStack链表,然后遍历其内部的ShadowFrame或者QuickFrame还原一个可读的调用栈,从而unwind出当前的Java堆栈。通过这种方式,可以实现线程一边继续跑步,我们还可以帮它做检查,而且耗时基本忽略不计。代码可以参照:Profilo::unwind和StackVisitor::WalkStack。
不用插桩、性能基本没有影响、捕捉信息还全,那Profilo不就是完美的化身吗?当然由于它利用了大量的黑科技,兼容性是需要注意的问题。它内部实现有大量函数的Hook,unwind也需要强依赖Android Runtime实现。Facebook已经将Profilo投入到线上使用,但由于目前Profilo快速获取堆栈功能依然不支持Android 8.0和Android 9.0,鉴于稳定性问题,建议采取抽样部分用户的方式来开启该功能。
先小结一下,不管我们使用哪种卡顿监控方法,最后我们都可以得到卡顿时的堆栈和当时CPU运行的一些信息。大部分的卡顿问题都比较好定位,例如主线程执行一个耗时任务、读一个非常大的文件或者是执行网络请求等。
其他监控
除了主线程的耗时过长之外,我们还有哪些卡顿问题需要关注呢?
Android Vitals是Google Play官方的性能监控服务,涉及卡顿相关的监控有ANR、启动、帧率三个。尤其是ANR监控,我们应该经常的来看看,主要是Google自己是有权限可以准确监控和上报ANR。
对于启动和帧率,Android Vitals只是上报了应用的区间分布,但是不能归纳出问题。这也是我们做性能优化时比较迷惑的一点,即使发现整体的帧率比过去降低了5帧,也并不知道是哪里造成的,还是要花很大的力气去做二次排查。
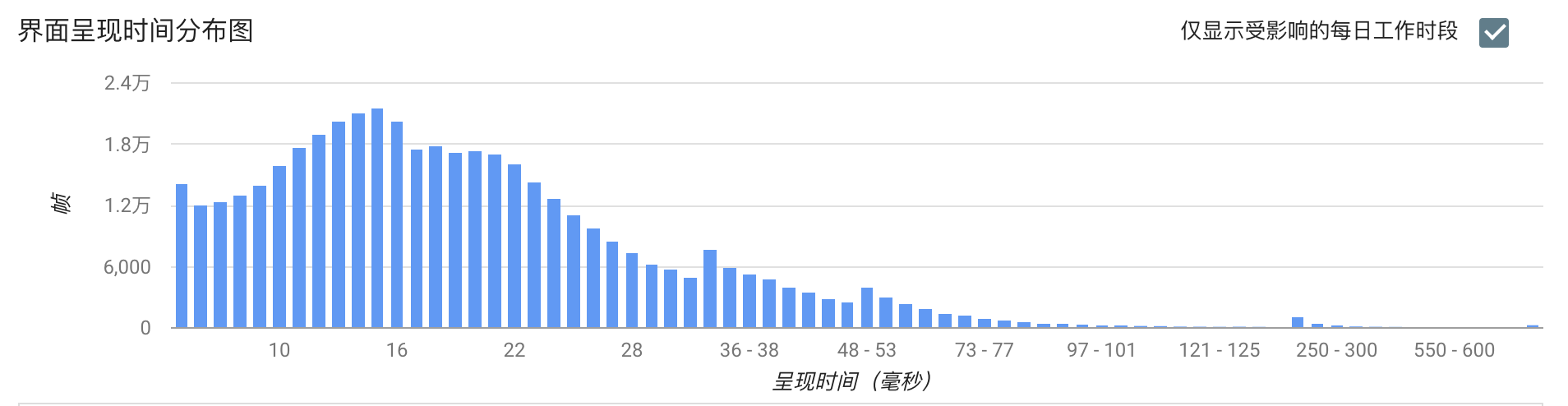
能不能做到跟崩溃、卡顿一样,直接给我一个堆栈,告诉我就是因为这里写的不好导致帧率下降了5帧。退一步说,如果做不到直接告诉我堆栈,能不能告诉我是因为聊天这个页面导致的帧率下降,让我缩小二次排查的范围。
1. 帧率
业界都使用Choreographer来监控应用的帧率。跟卡顿不同的是,需要排除掉页面没有操作的情况,我们应该只在界面存在绘制的时候才做统计。
那么如何监听界面是否存在绘制行为呢?可以通过addOnDrawListener实现。
我们经常用平均帧率来衡量界面流畅度,但事实上电影的帧率才24帧,用户对于应用的平均帧率是40帧还是50帧并不一定可以感受出来。对于用户来说,感觉最明显的是连续丢帧情况,Android Vitals将连续丢帧超过700毫秒定义为冻帧,也就是连续丢帧42帧以上。
因此,我们可以统计更有价值的冻帧率。冻帧率就是计算发生冻帧时间在所有时间的占比。出现丢帧的时候,我们可以获取当前的页面信息、View信息和操作路径上报后台,降低二次排查的难度。
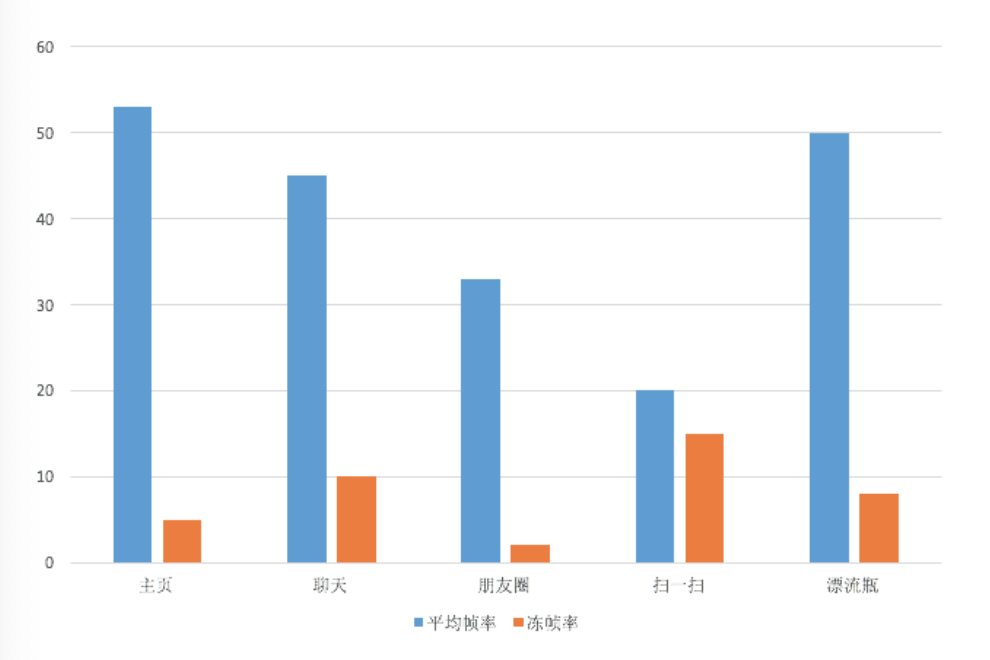
正如下图一样,我们还可以按照Activity、Fragment或者某个操作定义场景,通过细化不同场景的平均帧率和冻帧率,进一步细化问题排查的范围。
2. 生命周期监控
Activity、Service、Receiver组件生命周期的耗时和调用次数也是我们重点关注的性能问题。例如Activity的onCreate()不应该超过1秒,不然会影响用户看到页面的时间。Service和Receiver虽然是后台组件,不过它们生命周期也是占用主线程的,也是我们需要关注的问题。
对于组件生命周期我们应该采用更严格地监控,可以全量上报。在后台我们可以看到各个组件各个生命周期的启动时间和启动次数。
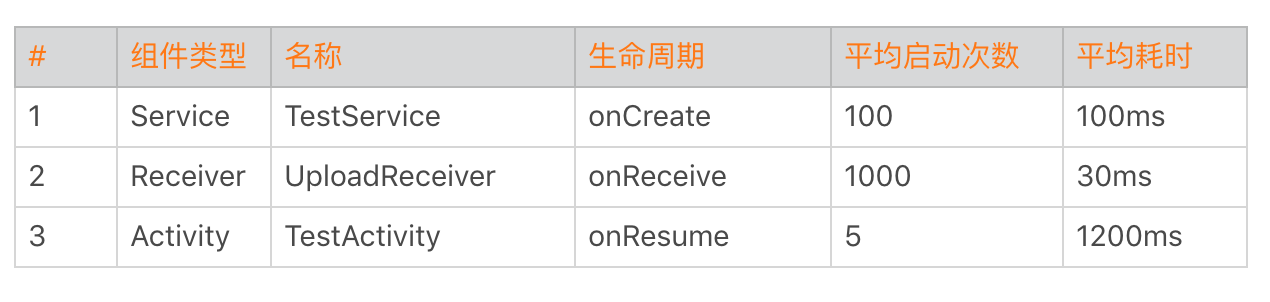
有一次我们发现有两个Service的启动次数是其他的10倍,经过排查发现是因为频繁的互相拉起导致。Receiver也是这样,而且它们都需要经过System Server。曾经有一个日志上报模块通过Broadcast来做跨进程通信,每秒发送几千次请求,导致系统System Server卡死。所以说每个组件各个生命周期的调用次数也是非常有参考价值的指标。
除了四大组件的生命周期,我们还需要监控各个进程生命周期的启动次数和耗时。通过下面的数据,我们可以看出某些进程是否频繁地拉起。

对于生命周期的监控实现,我们可以利用插件化技术Hook的方式。但是Android P之后,我还是不太推荐你使用这种方式。我更推荐使用编译时插桩的方式,后面我会讲到Aspect、ASM和ReDex三种插桩技术的实现,敬请期待。
3. 线程监控
Java线程管理是很多应用非常头痛的事情,应用启动过程就已经创建了几十上百个线程。而且大部分的线程都没有经过线程池管理,都在自由自在地狂奔着。
另外一方面某些线程优先级或者活跃度比较高,占用了过多的CPU。这会降低主线程UI响应能力,我们需要特别针对这些线程做重点的优化。
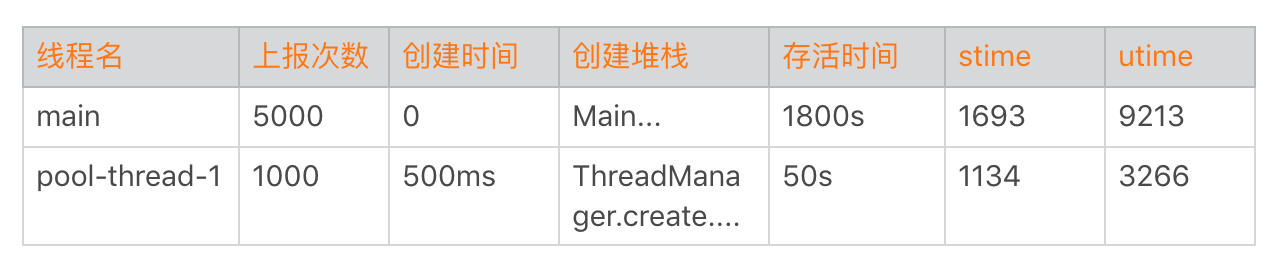
对于Java线程,总的来说我会监控以下两点。
- 线程数量。需要监控线程数量的多少,以及创建线程的方式。例如有没有使用我们特有的线程池,这块可以通过got hook线程的nativeCreate()函数。主要用于进行线程收敛,也就是减少线程数量。
- 线程时间。监控线程的用户时间utime、系统时间stime和优先级。主要是看哪些线程utime+stime时间比较多,占用了过多的CPU。正如上一期“每课一练”所提到的,可能有一些线程因为生命周期很短导致很难发现,这里我们需要结合线程创建监控。
看到这里可能有同学会比较困惑,卡顿优化的主题就是监控吗?导致卡顿的原因会有很多,比如函数非常耗时、I/O非常慢、线程间的竞争或者锁等。其实很多时候卡顿问题并不难解决,相较解决来说,更困难的是如何快速发现这些卡顿点,以及通过更多的辅助信息找到真正的卡顿原因。
就跟在本地使用各种卡顿分析工具一样,卡顿优化的难点在于如何把它们移植到线上,以最少的性能代价获得更加丰富的卡顿信息。当然某些卡顿问题可能是I/O、存储或者网络引发的,后面会还有专门的内容来讲这些问题的优化方法。
总结
今天我们学习了卡顿监控的几种方法。随着技术的深入,我们发现了旧方案的一些缺点,通过不断地迭代和演进,寻找更好的方案。
Facebook的Profilo实现了快速获取Java堆栈,其实它参考的是JVM的AsyncGetCallTrace思路,然后适配Android Runtime的实现。systrace使用的是Linux的ftrace,Simpleperf参考了Linux的perf工具。还是熟悉的配方,还是熟悉的味道,我们很多创新性的东西,其实还是基于Java和Linux十年前的产物。
还是回到我在专栏开篇词说过的,切记不要浮躁,多了解和学习一些底层的技术,对我们的成长会有很大帮助。日常开发中我们也不能只满足于完成需求就可以了,在实现上应该学会多去思考内存、卡顿这些影响性能的点,我们比别人多想一些、多做一些,自己的进步自然也会更快一些。
课后作业
看完我分享的卡顿优化的方法后,相信你也肯定还有很多好的思路和方法,今天的课后作业是分享一下你的卡顿优化的“必杀技”,在留言区分享一下今天学习、练习的收获与心得。
课后练习
我在上一期中提到过Linux的ftrace机制,而systrace正是利用这个系统机制实现的。而Profilo更是通过一些黑科技,实现了一个可以用于线上的“systrace”。那它究竟是怎么实现的呢?
通过今天这个Sample,你可以学习到它的实现思路。当你对这些底层机制足够熟悉的时候,可能就不局限在本地使用,而是可以将它们搬到线上了。
当然,为了能更好地理解这个Sample,可能你还需要补充一些ftrace和atrace相关的背景知识。你会发现这些的确都是Linux十年前的一些知识,但时至今日它们依然非常有用。
1.ftrace 简介、ftrace使用(上)、frace使用(下)。
欢迎你点击“请朋友读”,把今天的内容分享给好友,邀请他一起学习。最后别忘了在评论区提交今天的作业,我也为认真完成作业的同学准备了丰厚的“学习加油礼包”,期待与你一起切磋进步哦。
- 希夷 👍(9) 💬(2)
如果给完全没有卡顿的APP打分100的话,对于大厂的APP本来就有90分,追求的是如何将分数提到95,98,99,甚至100,邵文老师所讲主要也是针对这块;但对于很多想我这样的小公司开发者来说,受人力物力时间所限,想做到的其实是先达到90分,而这块专栏涉及的有限,对于跟我类似的受众不够友好。
2018-12-15 - 雪人 👍(8) 💬(1)
老师,看了您这些内容,对我的第一感觉是要对源码很熟悉,那您对学习源码有什么建议吗,(看的晚了,不知道现在评论还会不会回)
2019-03-05 - 小洁 👍(3) 💬(1)
请问下,目前有个需求是对卡顿和启动耗时做性能指标线上预警,对于 activity、fragment的生命周期启动耗时的监控数据,还有主线程卡顿堆栈的数据,应该按什么的维度去统计比较合理呢
2019-04-18 - 斑马线 👍(3) 💬(1)
老师你好,最学习了你的专栏,准备优化一下项目,用一个第三方开源工具检测了一下,发现项目有大量的“主线程阻塞超过70ms”,请问主线程执行耗时操作,多久才算耗时,该如何定义?
2019-02-25 - eyeandroid 👍(2) 💬(1)
请教下老师,hook抓到的systrace里面有其它进程的信息吗,跟python systrace.py抓到的内容有什么差别
2019-04-24 - 蚂蚁内推+v 👍(2) 💬(1)
Nanoscope 是什么 方便老师说下吗
2018-12-13 - VK 👍(1) 💬(1)
绍文老师,想问下卡顿信息监控上报,有什么策略判断吗,哪些方法函数需要监控,哪些不需要监控?
2019-05-18 - 冬 👍(1) 💬(1)
有个问题请教 用empty message 去检查卡顿 ,比如1s 没消费 ,就能说message 卡顿1s 吗 ? 如果空消息前边有几个消息 比如3个 ,现在正在执行第三个 我觉得也正常啊 不能说明卡顿啊
2019-01-11 - Kenny 👍(1) 💬(1)
张老师,刚试了你给的Sample,plthook实现的自定义ftrace,B与E事件日志不成对?这个怎么看每一个事件的耗时?每个B找最近的E作为截止算时间吗?还是按照一个B对应一个E去算?还有一个问题就是课程提到通过hook thread_create去监控线程,这个是指监控应用的线程吗?如果是的话,那系统的线程比如binder,jit等如何去监控?话说这个张老师能把hook 线程创建的实现也放Sample?
2018-12-13 - EchoSomeTH 👍(0) 💬(1)
adb shell objdump /system/lib/libutils.so 提示objdump not found,咋导出来?
2019-07-22 - YI🎐 👍(0) 💬(1)
profilo是怎么用起来的?创建profilo时候都要报错
2019-05-02 - 金大圣 👍(0) 💬(1)
张老师,文章里面提到的inline hook技术可以多介绍一点吗?跟前面文章提到的PLT hook是一样的吗?
2019-01-27 - CHY 👍(0) 💬(1)
通过 proc/cpuinfo 好像拿不到 cpu 核数,只能获取到打开了的 cpu 核心信息。。
2018-12-24 - Sgx 👍(0) 💬(1)
绍文哥你好,请问每次课程中所说的黑科技是啥意思?
2018-12-21 - 蚂蚁内推+v 👍(0) 💬(1)
有什么方案可以统计系统线程数呢
2018-12-13