08 数据库设计:怎样按领域模型设计数据库?
你好,我是钟敬。
这节课,我们来学习数据库设计。
前面我们说过,模型驱动设计可以分成两大部分:模型的建立和模型的实现。模型的建立要求模型和业务需求一致,模型的实现要求实现和模型一致。现在,咱们已经建立了领域模型,并且从理论层面对模型驱动设计的概念进行了总结,这些都属于模型的建立。而我们这节课要做的数据库设计,则属于模型的实现。
那么,怎样由领域模型,一步一步地推导出数据库的设计呢?这种方法和以前的方法有什么不同呢?这节课我们就来讨论这两个问题。在这个过程中,我们要着重体会数据库设计是如何与领域模型保持一致的。
今天讲的内容,在软件工程中叫做建立物理数据模型(physical data model, PDM),主要目的就是对数据表进行设计。具体来说,包括以下几点:
- 建立哪些表;
- 表中有哪些字段;
- 表的主键和外键是什么;
- 字段的数据类型以及约束。
还有一点要说明,虽然我们的例子是用MySQL完成的,但我们讲的是通用原理,所以采用其他数据库引擎的话,道理也是一样的。
我们在领域建模的时候把模型分成了四个模块,下面,我们就一个模块一个模块地进行数据库设计。
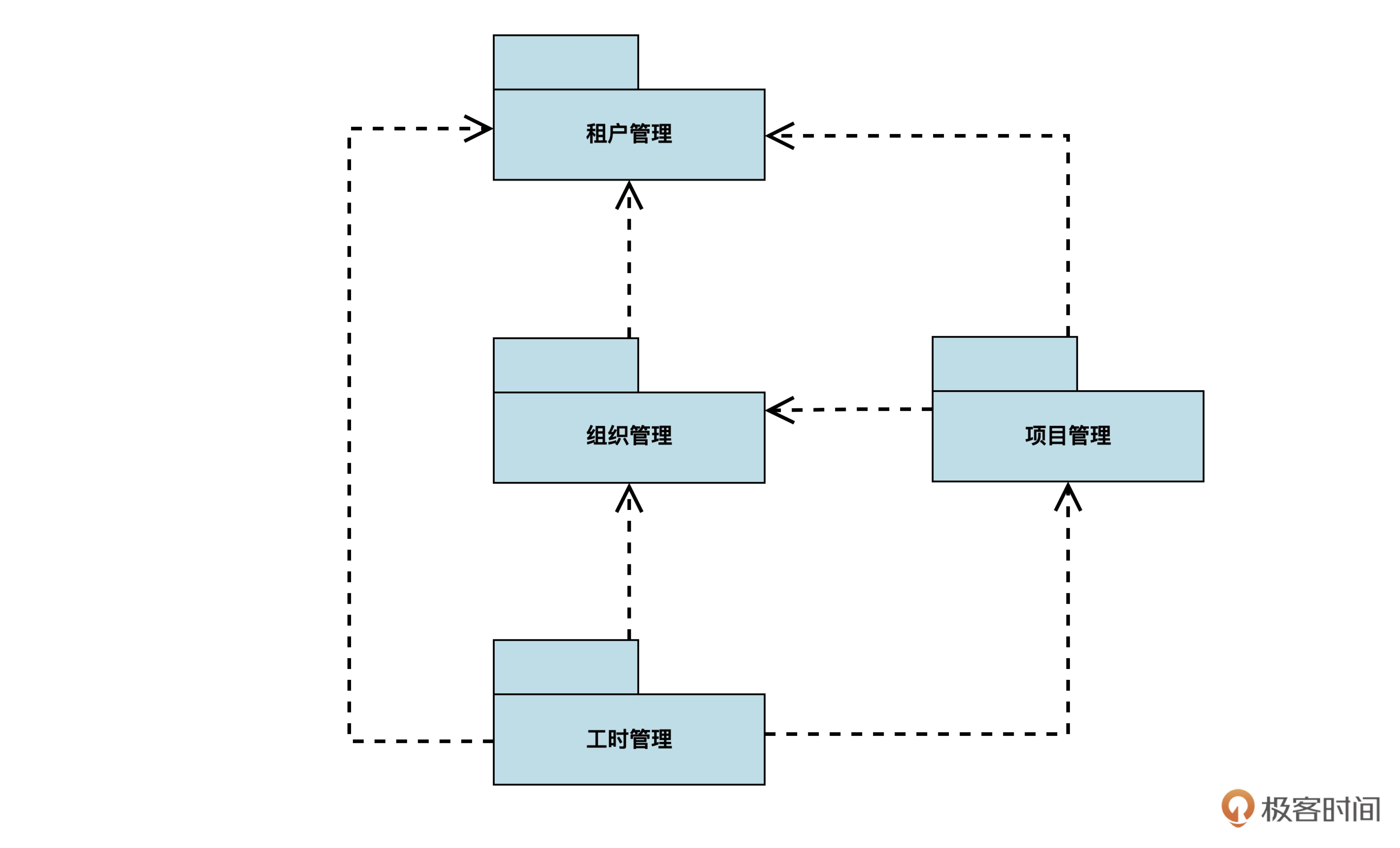
“租户管理”的数据库设计
咱们就从最简单的租户管理模块开始吧,下面是这个模块的模型图:
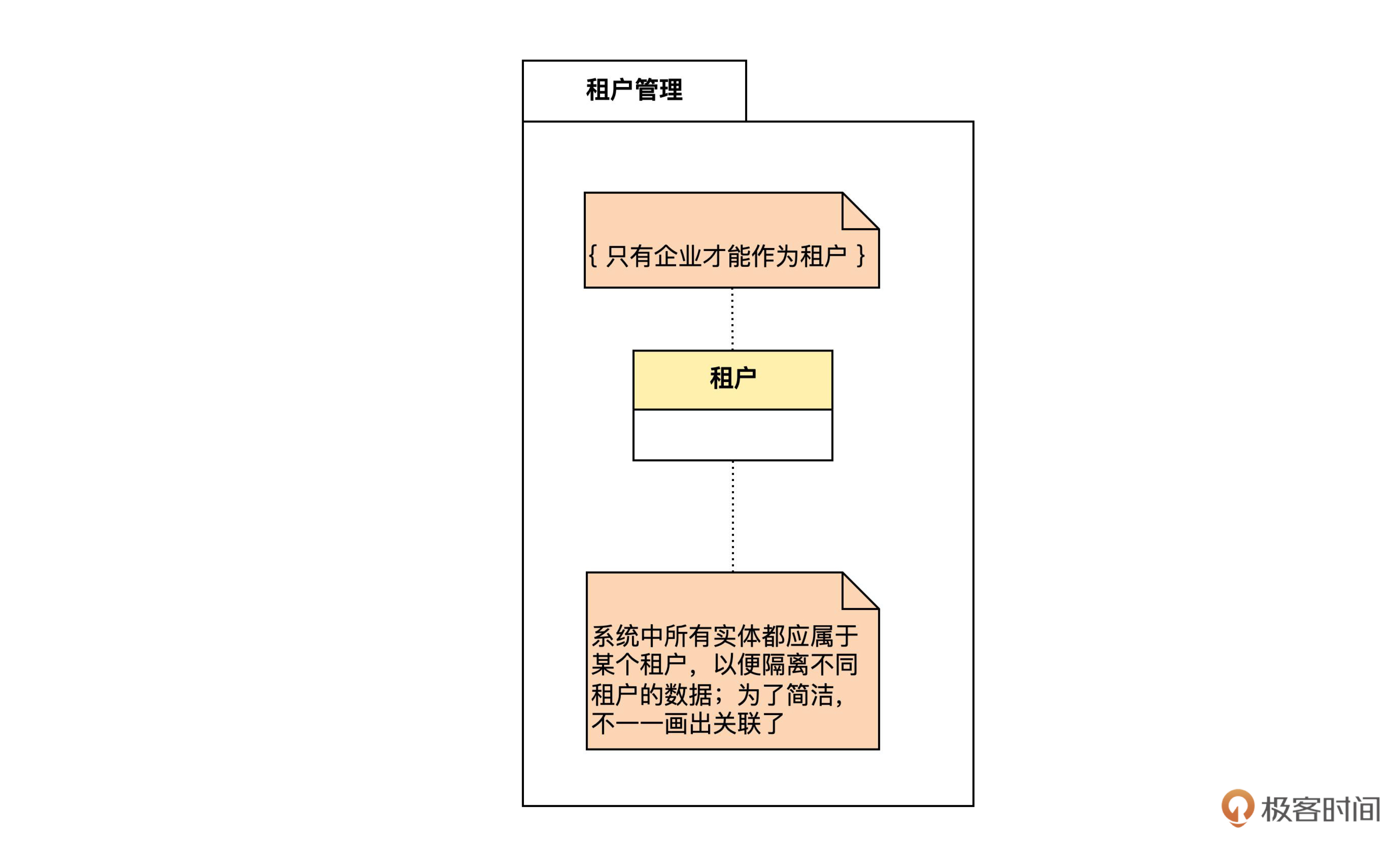
一般来说,一个实体可以映射为一个数据库表。所以,咱们可以先根据租户实体设计出租户表。可以用下面的符号表示:
前面说过,今天的内容,是建立物理数据模型。和UML不同,物理数据模型的图示法并没有统一的国际标准。所以不同的专家、不同的工具,画出来的都不太一样。这里我用了绘图工具(draw.io)中提供的符号。
另外,还可以用建表语句(create table) 表示表的结构。建表语句和图形符号是同一个意思的两种等价的表示方法,比如上图可以直接翻译成下面的建表语句:
所以,原则上直接用建表语句进行数据库设计也是可以的。不过为了直观,我们的课程中还是用图示的方法。
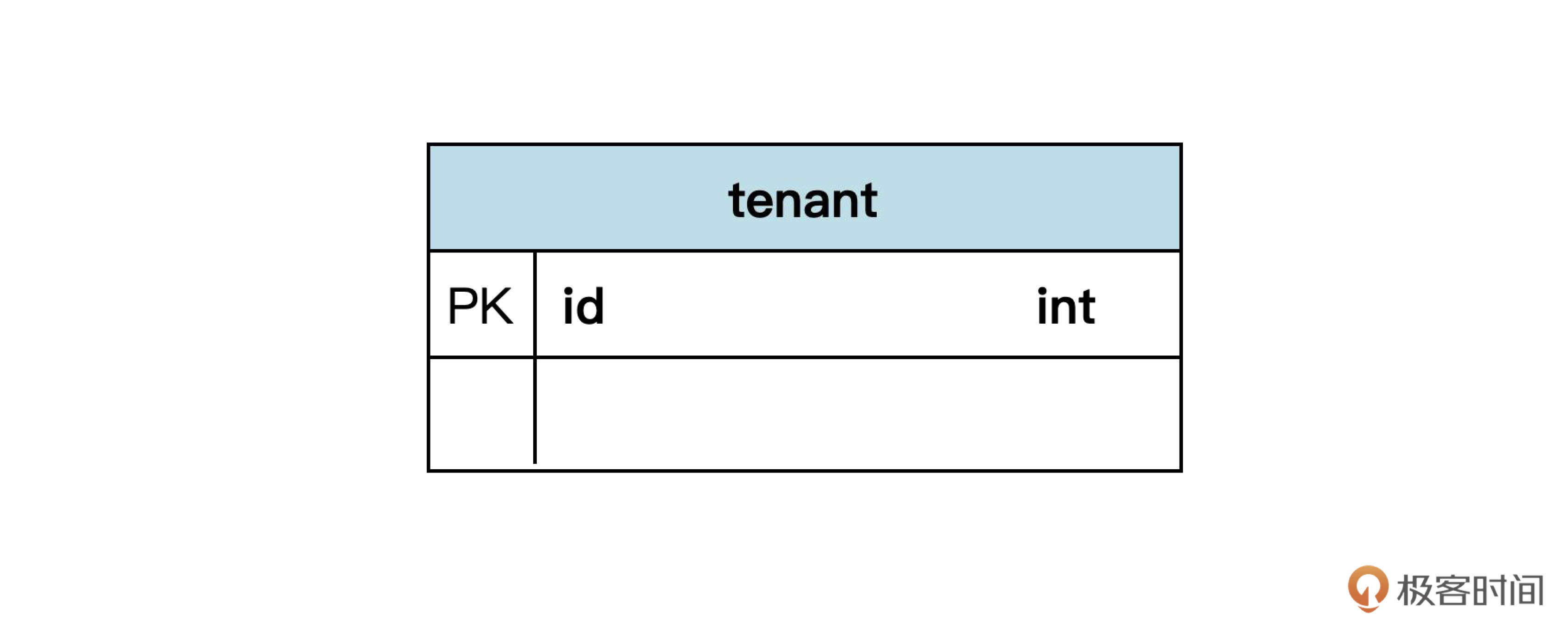
下面我们仔细看看表示数据表的符号。
首先看这个符号的第一行,这里的 tenant 是表的名称。在领域建模阶段,为了和领域专家进行沟通,模型中使用的都是中文。但建表时,一般要用英文来命名。那问题就来了,怎么保证中英文的一致,从而在实现层面贯彻统一语言呢?
答案就是使用我们前面建的词汇表。在词汇表里,我们规定了每个中文词汇对应的英文全称和简称。在为数据库表以及字段等命名时,如果词汇表中有简称就用简称,否则就用全称。我们把词汇表在这里再列一遍作为参考。
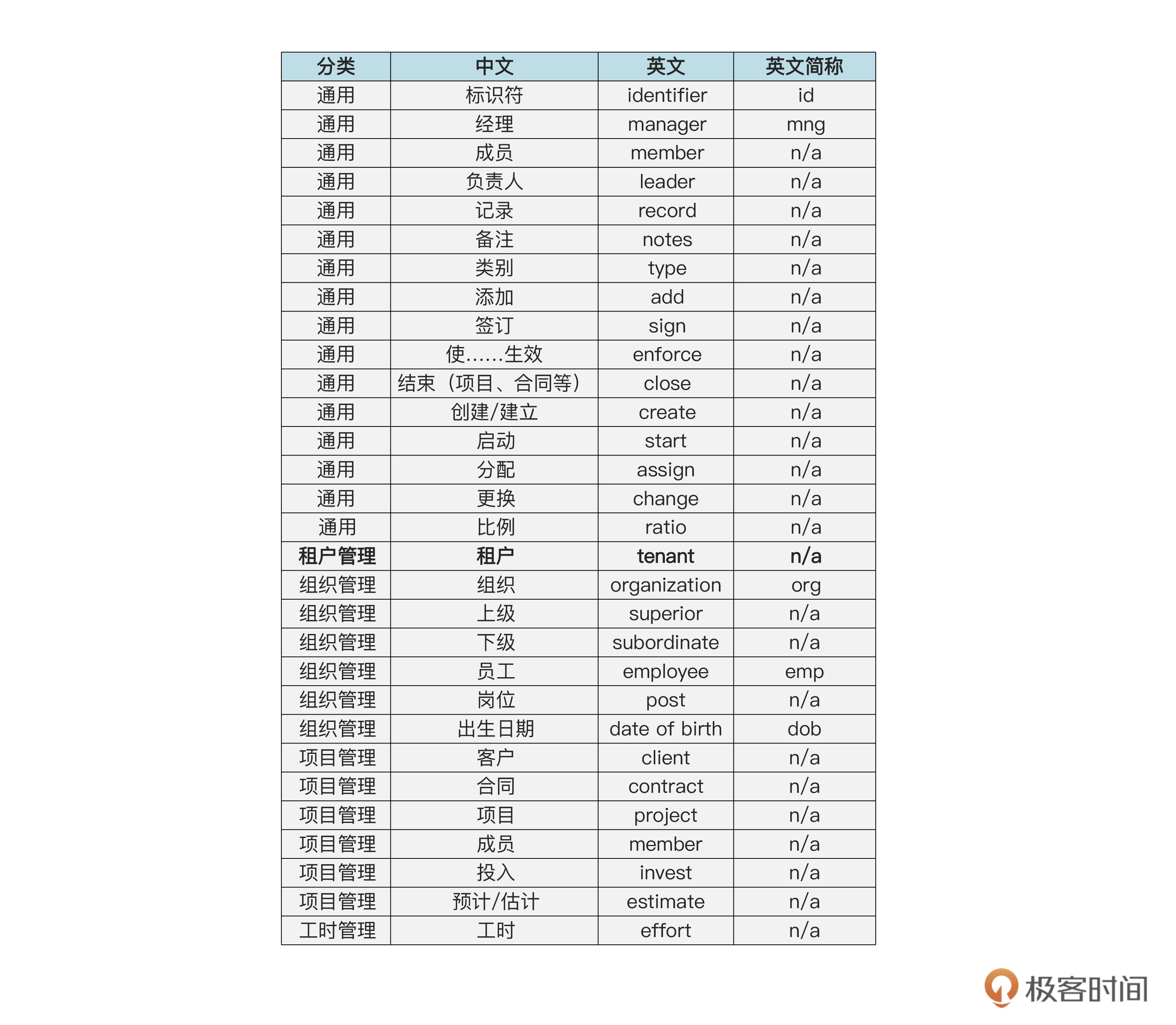
在词汇表里,查到租户的英文是 tenant,所以用它作为表的名称。
然后我们再看这个表符号的第二行,这是表的主键,包括主键的名称 “id” 和数据类型 “int” 。“PK”(primary key)表示这个字段是一个主键。
除了这种命名法以外,主键命名的另一种常见做法是包含表名,也就是命名为 tenant_id。不过我比较习惯极简主义,所以只用了 id。两种方法都可以,根据你具体项目的规定来选择就行了。
最后,我们再为这个表添加其他字段。领域模型中的属性,一般会映射成表中的字段。
在领域建模的时候,为了模型的简洁和稳定,我们主张只写出有助于表达实体含义的主要属性,一些不言自明的属性就不用写了。但在数据库设计阶段,就要根据需求列出所有字段了。这里,我们要补充下面几个字段:
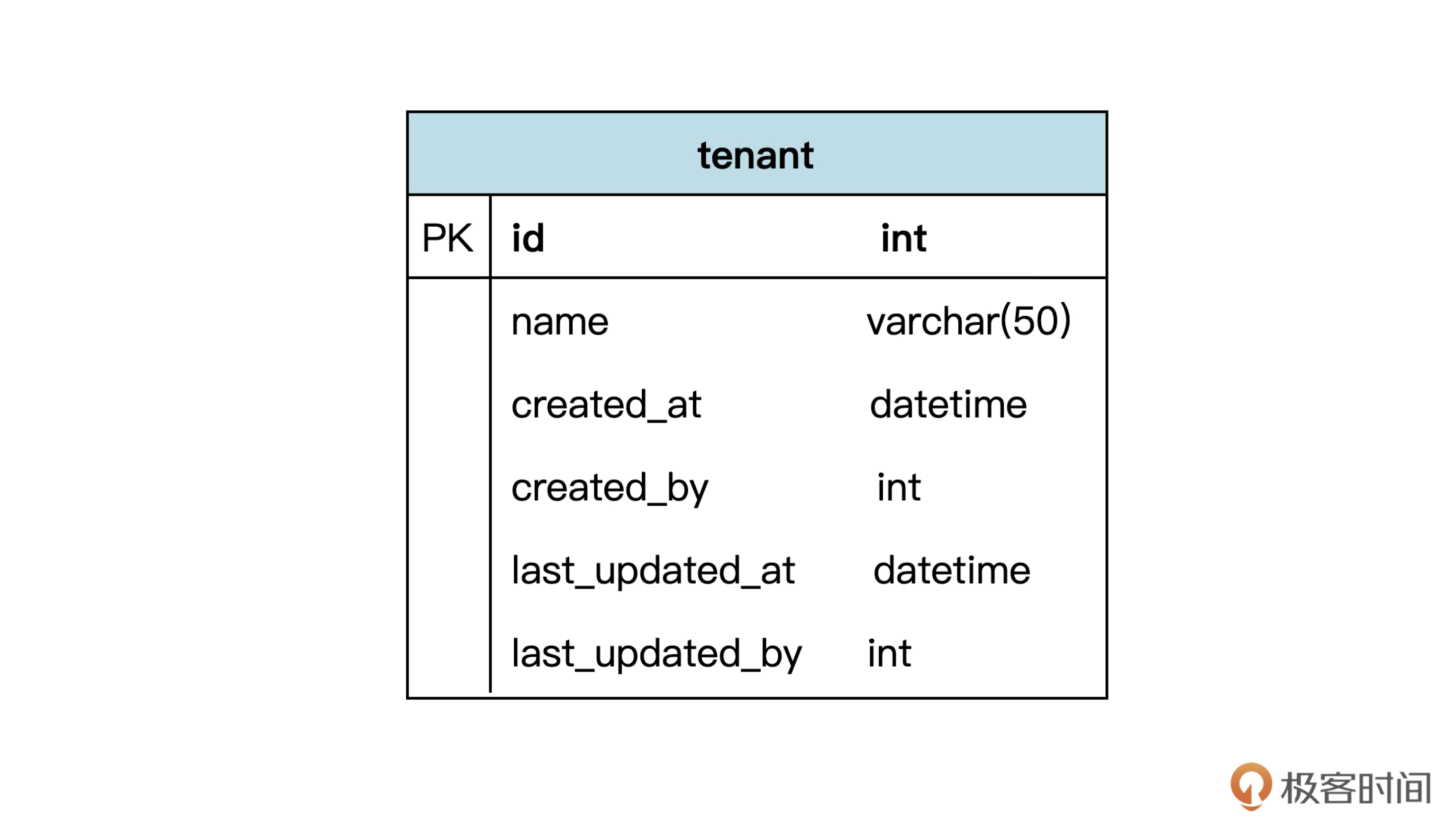 name表示租户的名称。created_at,created_by,last_updated_at 和 last_updated_by 分别表示一条记录的创建时间、创建人、最后一次修改时间和最后一次修改人。创建人和最后修改人保存的是用户的 id。
name表示租户的名称。created_at,created_by,last_updated_at 和 last_updated_by 分别表示一条记录的创建时间、创建人、最后一次修改时间和最后一次修改人。创建人和最后修改人保存的是用户的 id。
这四个字段常常被称为审计字段,可以用来进行安全审计和错误排查。作为一种最佳实践,我们在每一个表中都会包含这四个字段。
“组织管理”的数据库设计
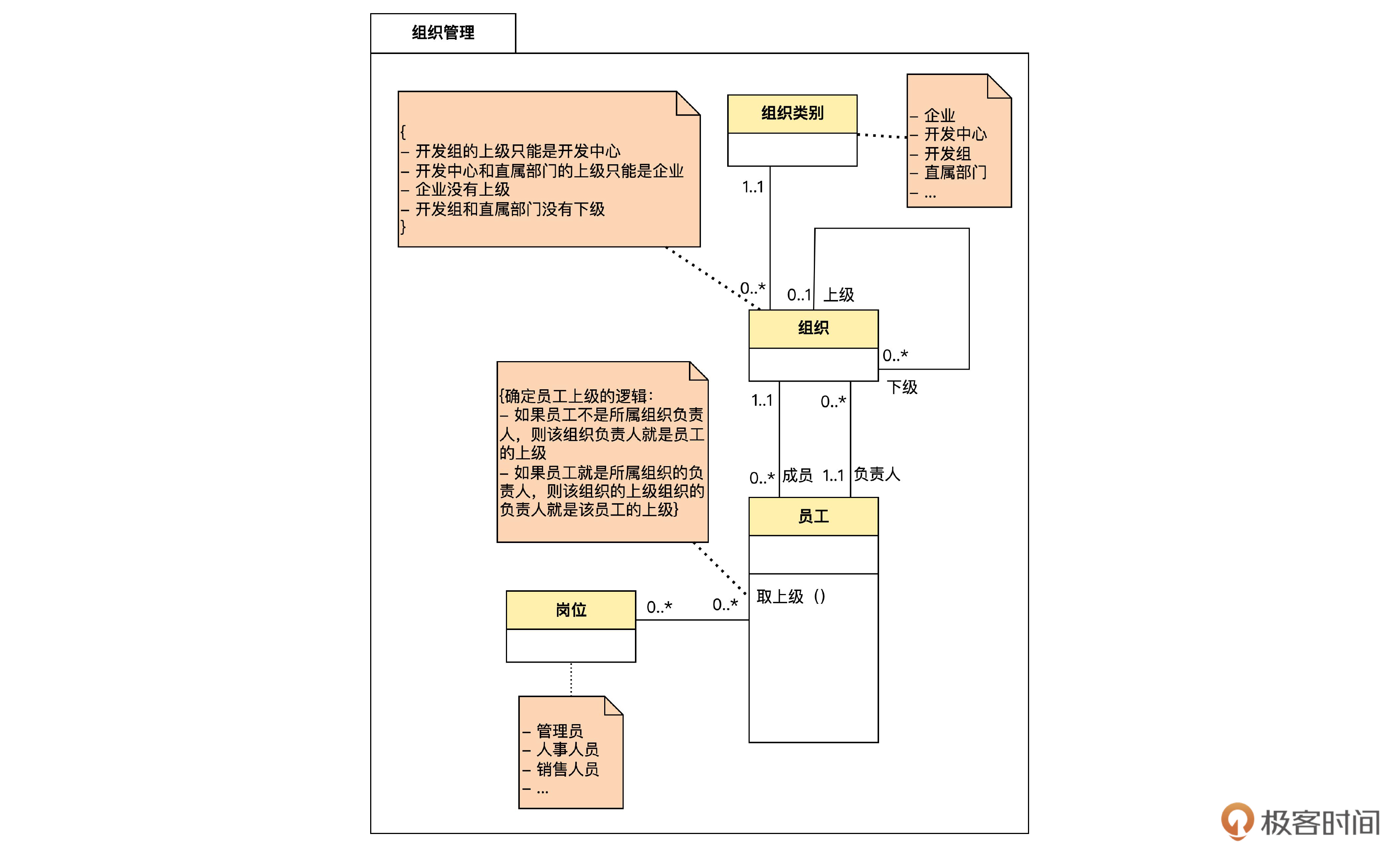
做好了租户管理,我们继续为组织管理进行数据库设计。领域模型如下:
首先,我们用类似的方法为组织实体建表,如下图:

先看图中的实线箭头,这个箭头代表外键参照关系。按照领域模型,租户和组织是一对多关联。一个一对多关联,在数据库设计时可以映射成一个外键。
图中的FK(foreign key) 代表外键。FK = tenant_id 说明 org 表中指向 tenant 表的外键是 tenant_id 字段。
此外,我们还添加了非空(NOT NULL)约束。这和领域模型中的多重性有关。租户和组织间的关联,在租户端实际是“1..1”,也就是说一个组织至少会关联一个租户,最多也只能关联一个租户。“1..1”前面的“1”就映射成了组织表里 tenant_id 字段后面的非空约束。假如不是“1..1”而是“0..1”,那么就不会有 NOT NULL 了。所以,关联上的多重性决定了外键字段的非空约束。
不过,在基于云的应用里,为了减少数据库处理的瓶颈,一般不主张建立真正的外键,而是用程序来保证外键约束。但是在物理数据模型里,我们又希望表达外键参照,方便理解数据表间的关系。这时候,我们可以把实线箭头换成虚线箭头,表示虚拟外键,如下图:
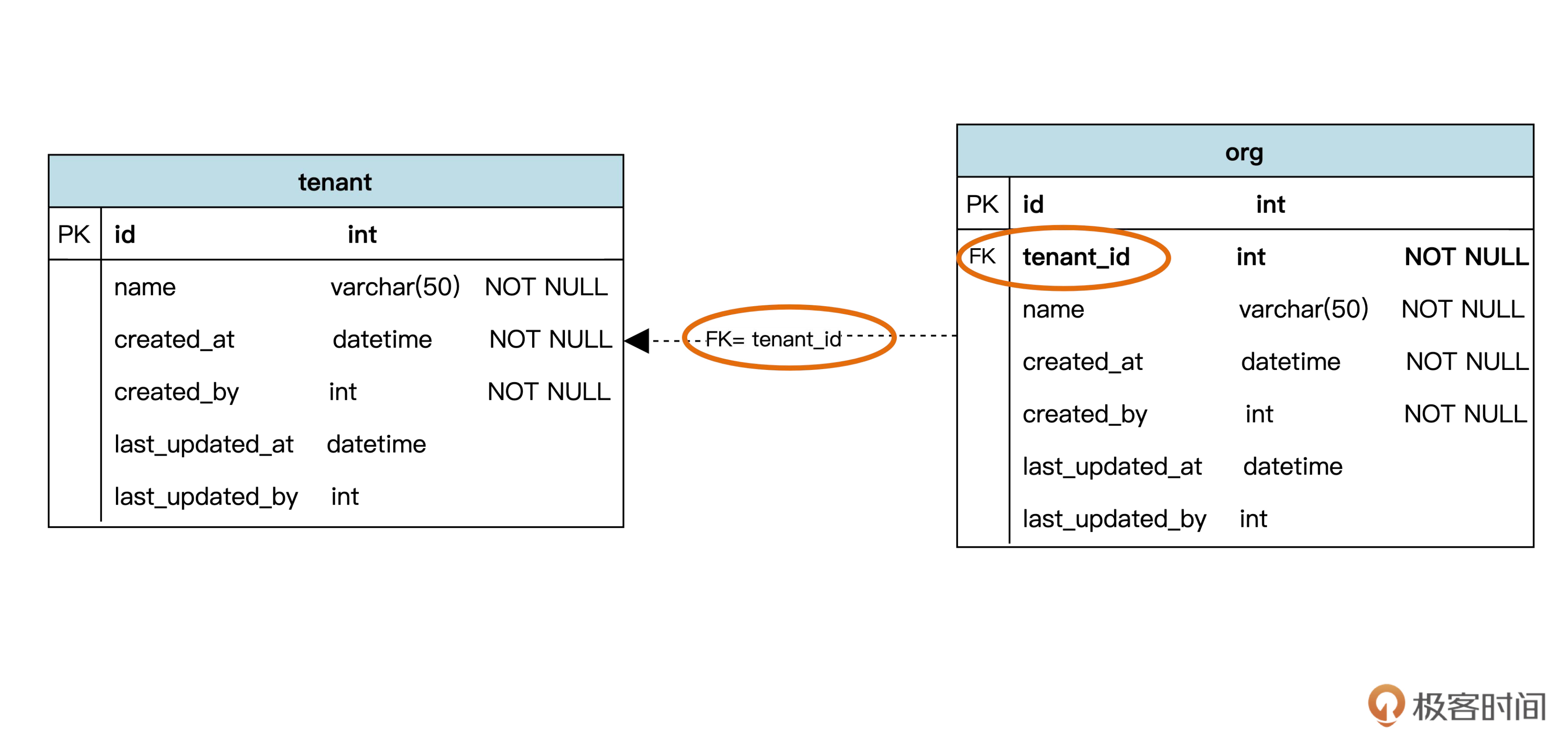
后面我们所有的数据表设计都采用虚拟外键。
事实上,数据库中其他所有表都有一个指向 tenant 表的虚拟外键,以便区分是哪个租户的数据。如果每个虚拟外键都画出来,我们的图会变得很乱,所以后面就只在表中写出 tenant_id,不画箭头了,我们可以用一个注释说明这件事。

接下来,咱们用类似的方法完成组织、组织类别和员工实体。如下图:
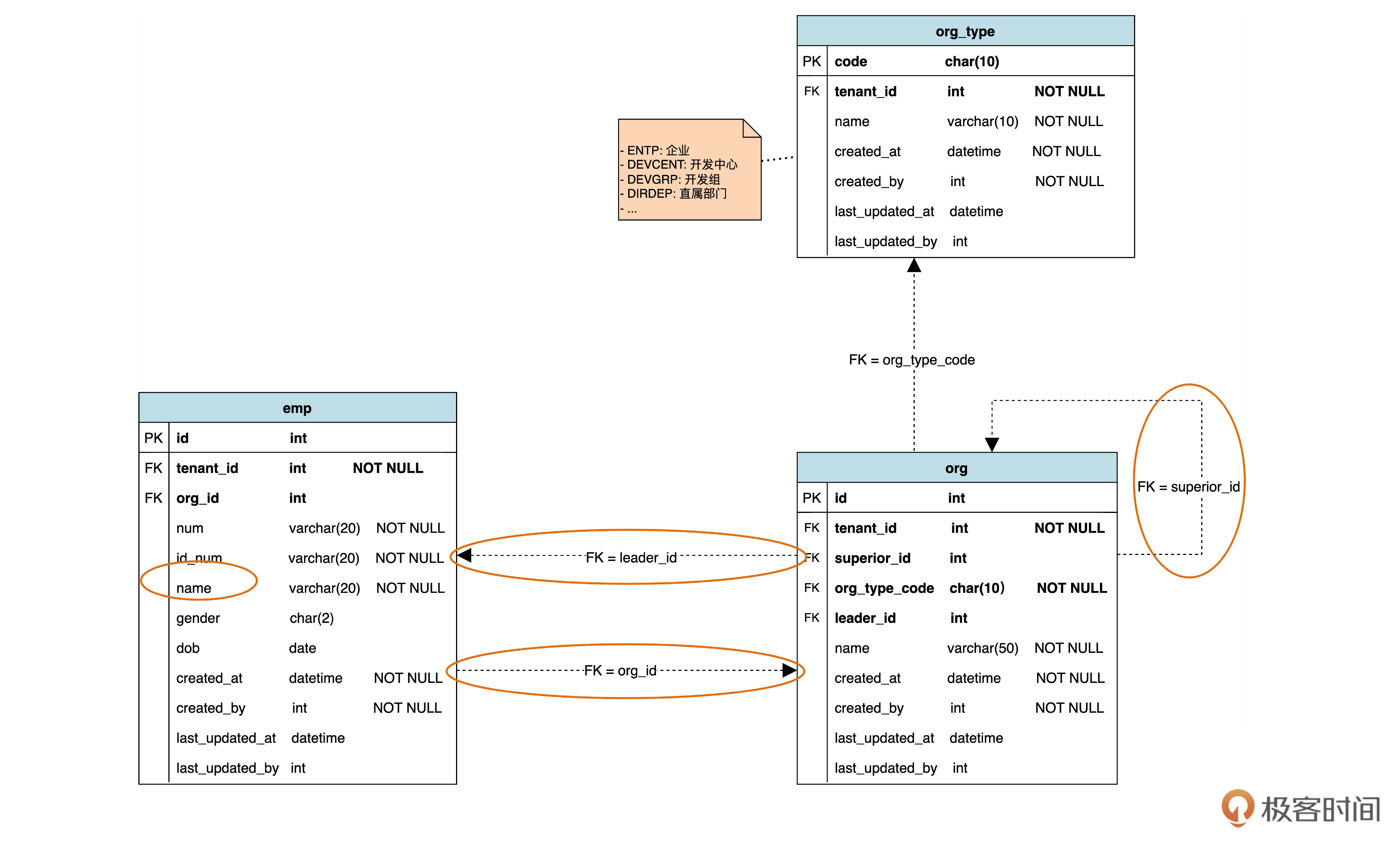
我们为这张图补充几点说明。
首先看 org(组织)表,这里有一个指向自身的虚拟外键 superior_id ,表示组织之间的上级关系,对应于领域模型中的自关联。
然后还可以看到 emp(员工)表和 org 表之间有两个方向相反的虚拟外键,一个表示组织的负责人关系,另一个表示员工归属于哪个组织。
另外,emp 表中的 num、id_num、name、gender、dob 分别表示员工号、身份证号、姓名、性别和出生日期(date of birth)。
最后,我们来处理岗位。
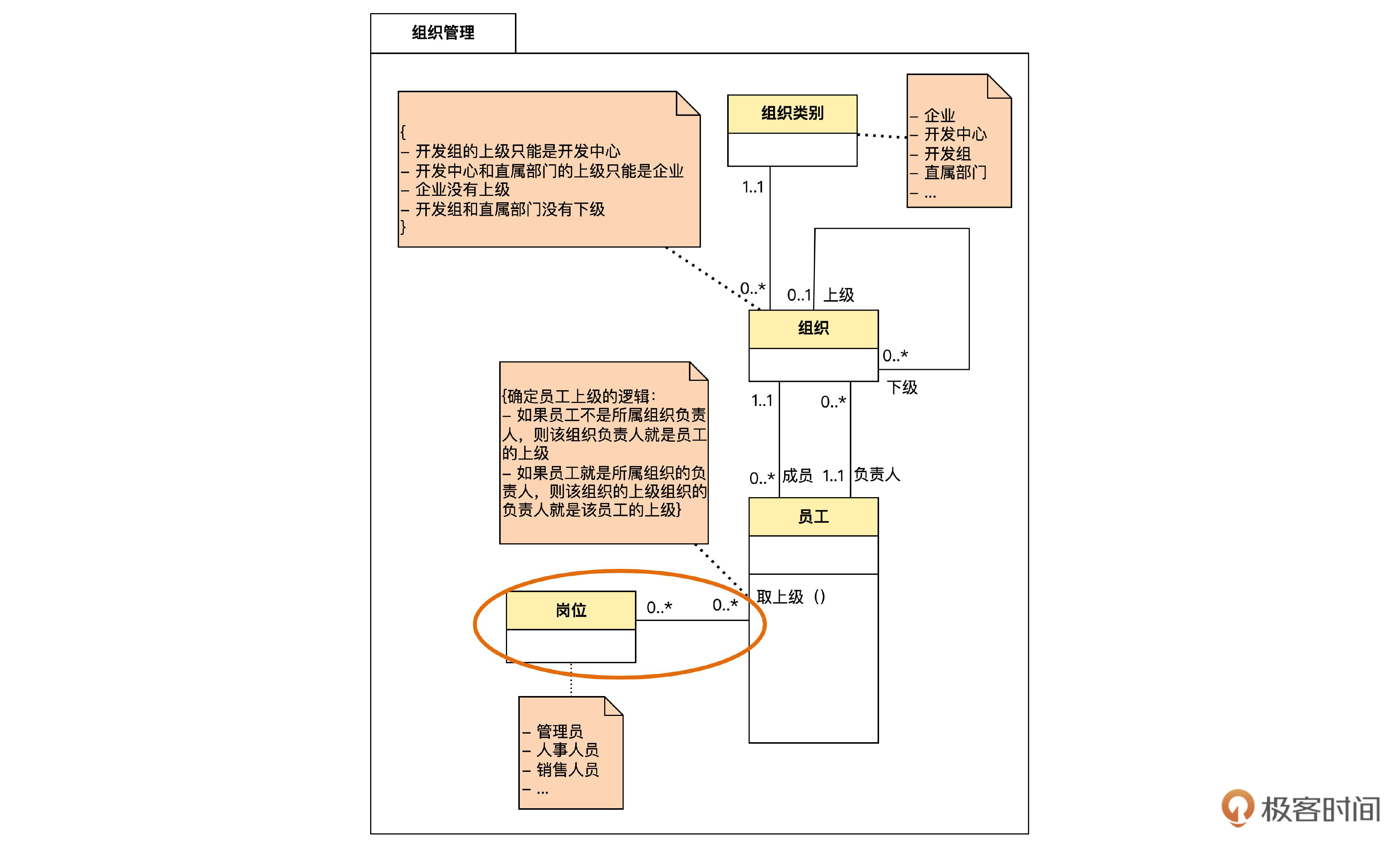
你可能注意到了,岗位和员工之间是多对多关联。这时,我们必须增加一个关联表,来表达两者之间的关系,如下图:
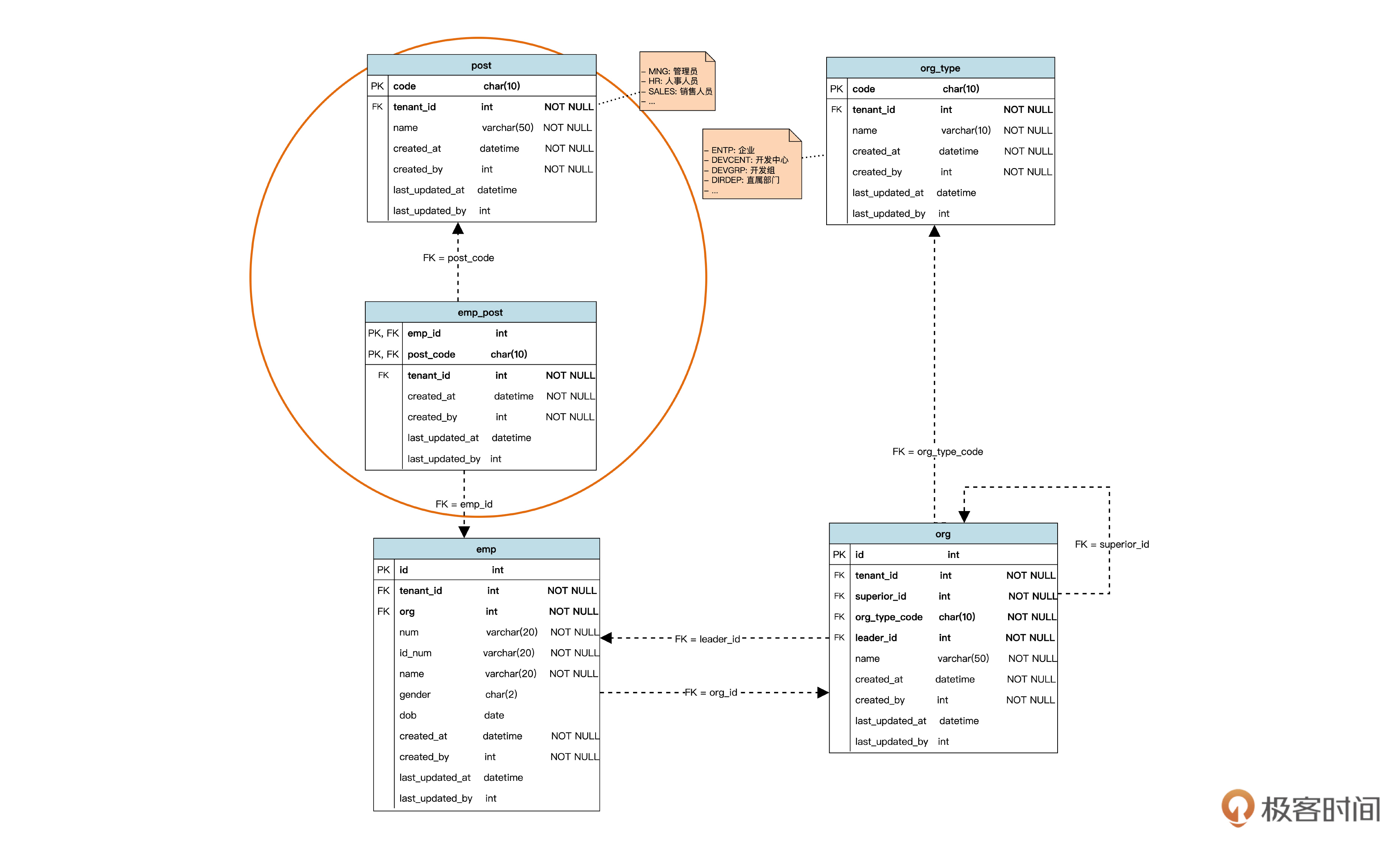 这里,我们增加了 emp_post 表来表达多对多的关联。表中包含了 post (岗位) 和 emp 两个表的主键作为自己的虚拟外键。我们采用了由 emp_id 和 post_id 两个字段组成的复合主键,因为这时添加一个单独的 id 主键并没有什么意义。
这里,我们增加了 emp_post 表来表达多对多的关联。表中包含了 post (岗位) 和 emp 两个表的主键作为自己的虚拟外键。我们采用了由 emp_id 和 post_id 两个字段组成的复合主键,因为这时添加一个单独的 id 主键并没有什么意义。
一般来说,我们都主张用单独的 id 主键,只有符合以下两个条件时,才应该使用上面这种联合主键:
第一,两个外键字段,例如 emp_id 和 post_id ,唯一决定了一条记录;
第二,这个表的主键没有被其他表作为外键引用。
“项目管理”数据库设计
好,现在我们完成了组织管理模块的数据库设计,接着做项目管理模块。在下面这张领域模型图中,我省略了和项目管理无关的部分。
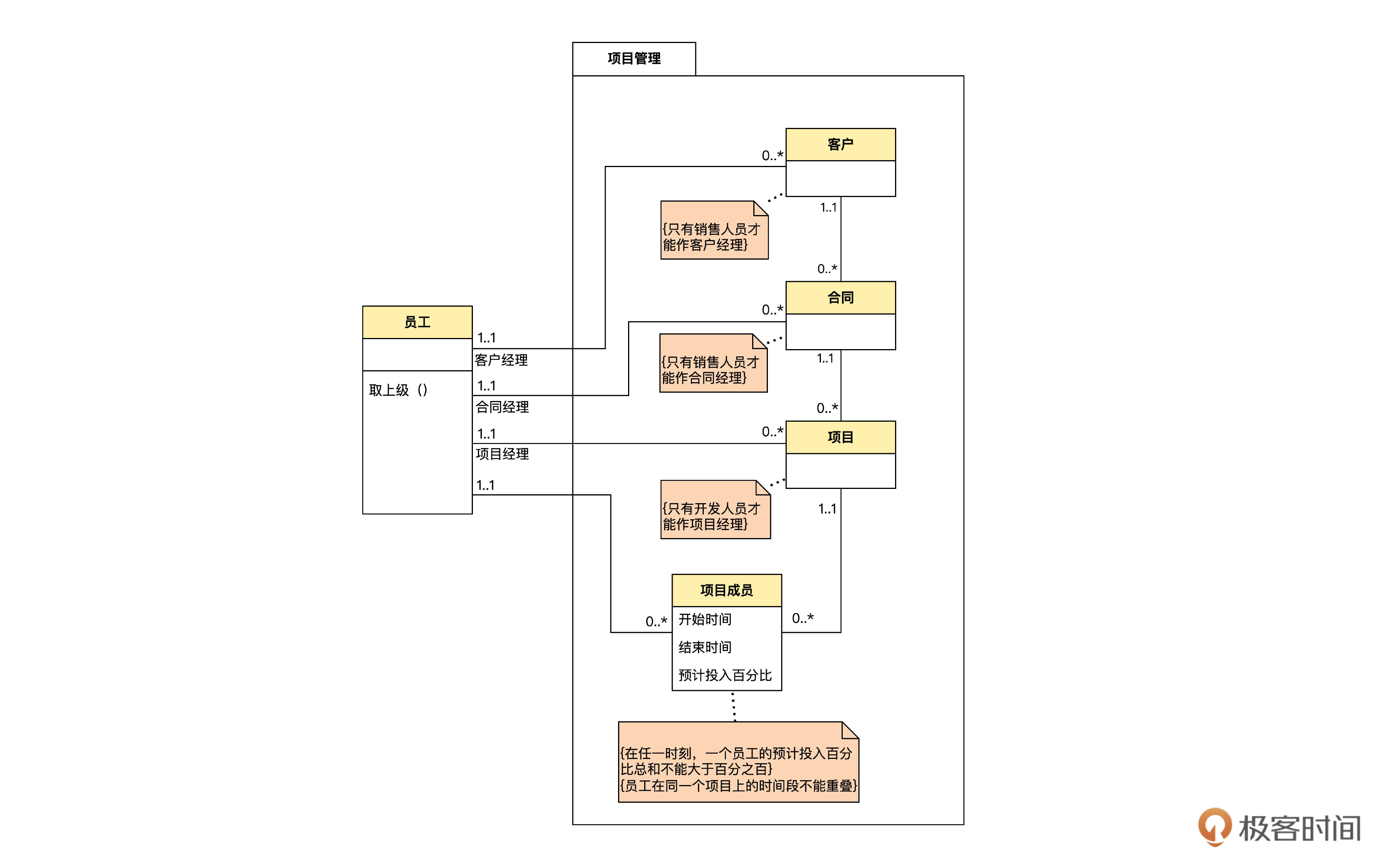
用前面的方法,我们可以画出项目管理模块的物理数据模型图:
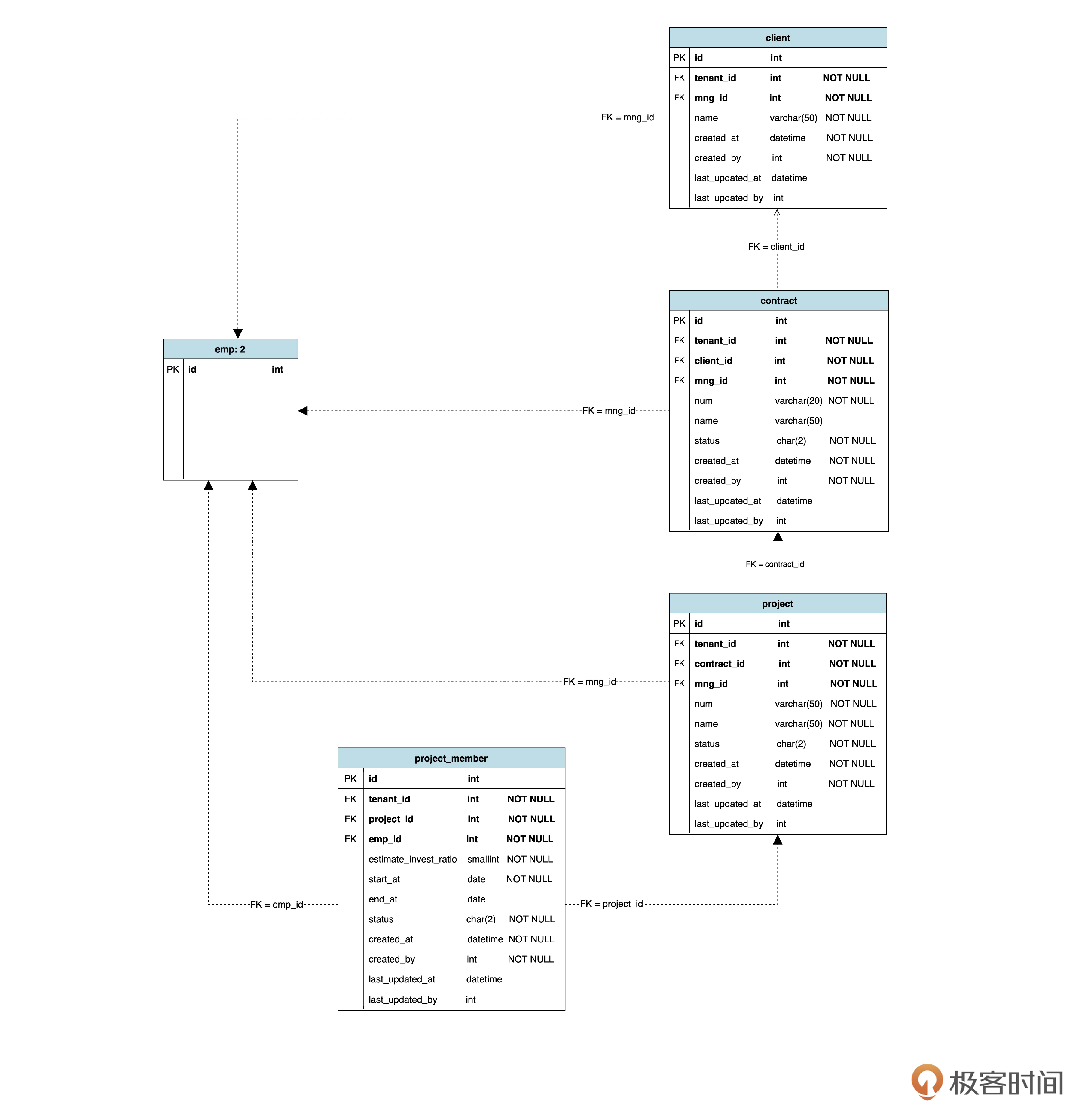
在这张图里,有没有注意到员工表的名称写成了 emp: 2 ,而且除了主键以外没有其他属性?
这其实是一种绘图技巧。为了避免整张图像蜘蛛网一样凌乱,我们不打算把所有表都画在同一张图上,而是每个模块画一张。而 emp 表在组织管理中出现过一次,在项目管理中又出现了,所以我们用了 emp: 2 说明这是 emp 表的第 “2” 次出现。
至于属性,我们只在 emp 表第一次出现的时候详细写出来就可以了,其他地方不写属性,这样,当需要更改属性的时候,只改一个地方就可以了。
“工时管理”的数据库设计
完成了项目管理模块,我们来设计最后的工时管理模块。领域模型图如下:
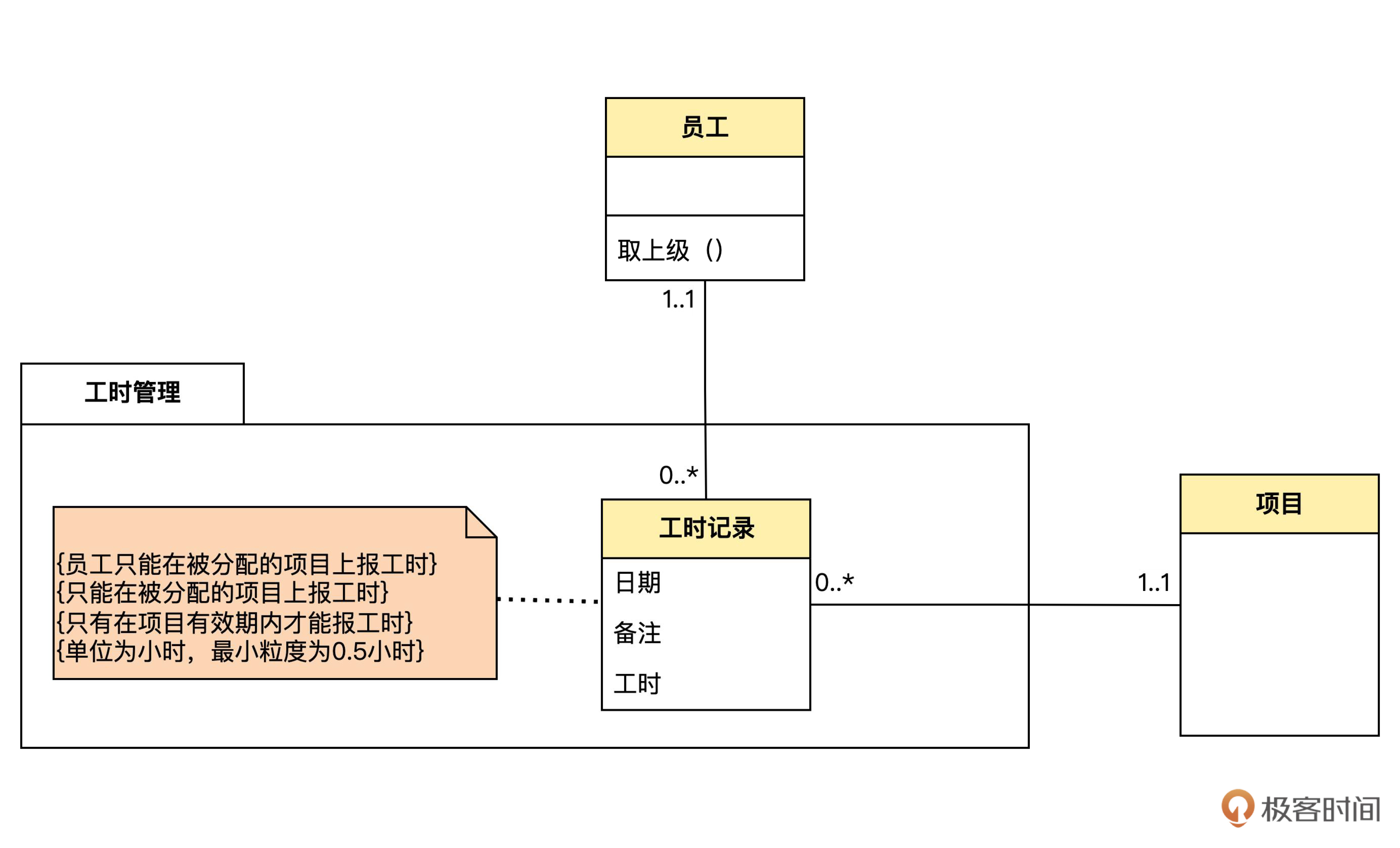
用我们前面的知识,很容易就能做出下面的设计:
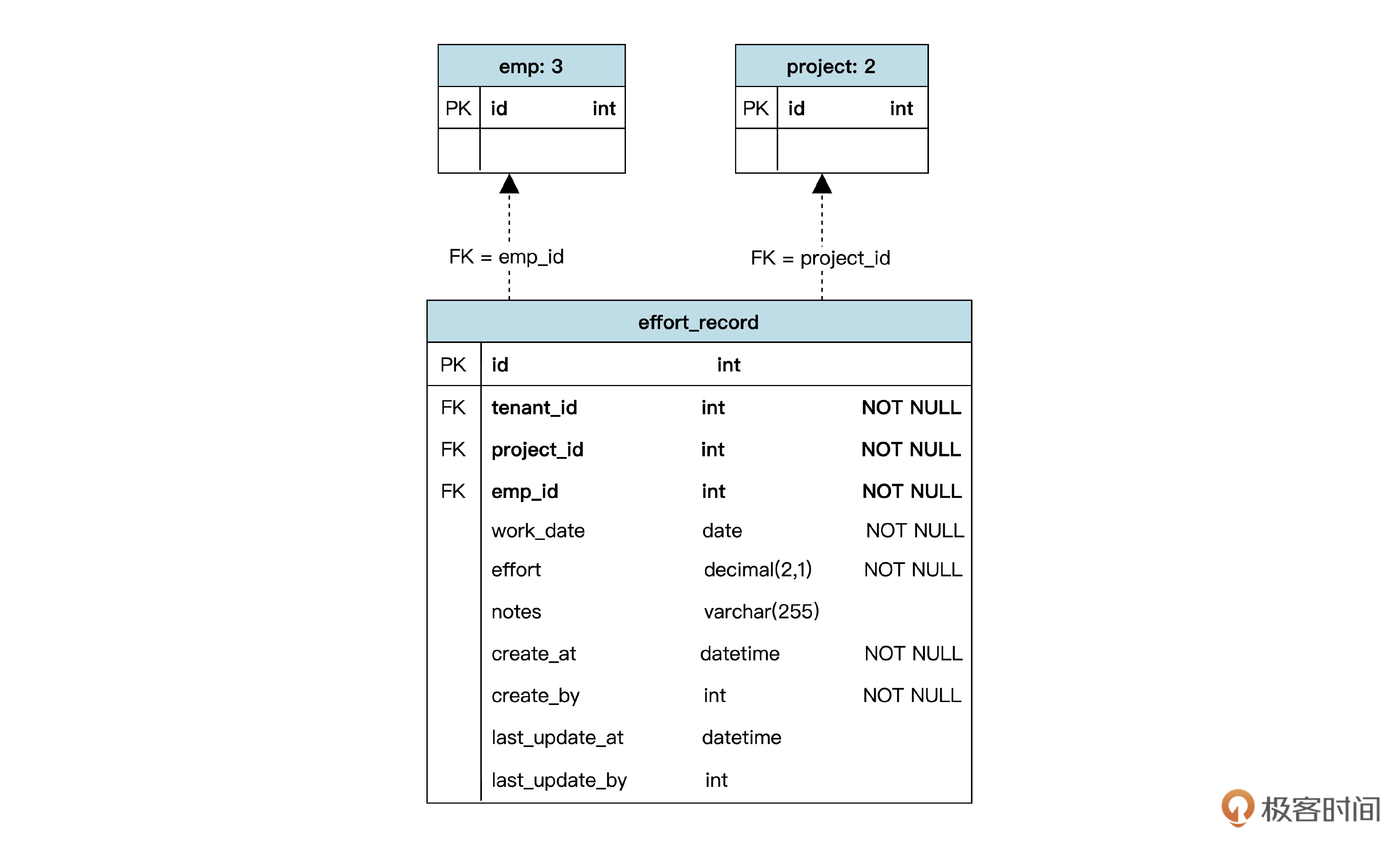
到这里,数据库设计就完成了。那么让我们再思考一下,这种基于领域模型的方法和我们以前常用的做法有什么区别呢?
按照DDD进行数据库设计和“以前方法”的对比
要回答这个问题,我们先来明确一下这里所谓以前的方法指什么。传统的软件工程中本来就有一套以ER图为工具、规范的数据库设计方法。不过我们多数小伙伴并没有严格按照这种方法去做,而是直接拍脑袋设计数据表。我们可以把这两种方法称为“ER图法”和“拍脑袋法”,看看它们和我们这节课的方法有什么区别。
与“拍脑袋法”的区别
先看看和“拍脑袋法”的区别。如果我们只是靠直觉设计数据库,不去深入分析领域知识,虽然刚开始时可能可以满足业务需求,但随着需求越来越复杂,问题就会逐渐浮现出来。
首先我们要知道,无论是数据模型图还是建表语句,都是面向技术人员的,业务专家很难理解。所以我们无法使用这些方式和业务专家沟通,也就很难保证数据库设计能准确地反映领域知识。而按照DDD的方法,我们可以先基于领域模型和业务专家对齐需求,再把领域模型转换为数据库设计,从而解决领域知识的沟通问题。
第二个问题在于,这样随意的数据库设计,很可能会违反数据库设计的范式,造成数据冗余和潜在错误。范式(NF)是规范形式(Normal Form)的简称,核心思想在于避免数据的冗余。也就是说,数据表的范式越高,数据冗余就越少。
不过在实践中,一般做到第三范式就够了。范式并不是用于直接进行数据库设计的,而是正确的数据库设计的反向验证。正确地运用领域模型进行数据库设计,一般而言,就不会违反第三范式了。
与“ER图法”的区别
接着再看看我们的方法与“ER图法”的区别。
传统的软件工程,是按照“概念设计”“逻辑设计”和“物理设计”的步骤进行数据库设计的。其中概念设计和逻辑设计,通常会采用ER图,也就是实体联系图。ER图同样没有业界统一的标准,有多种画法。下面这张图用了一种常用的画法,表示组织和员工的一对多关系。
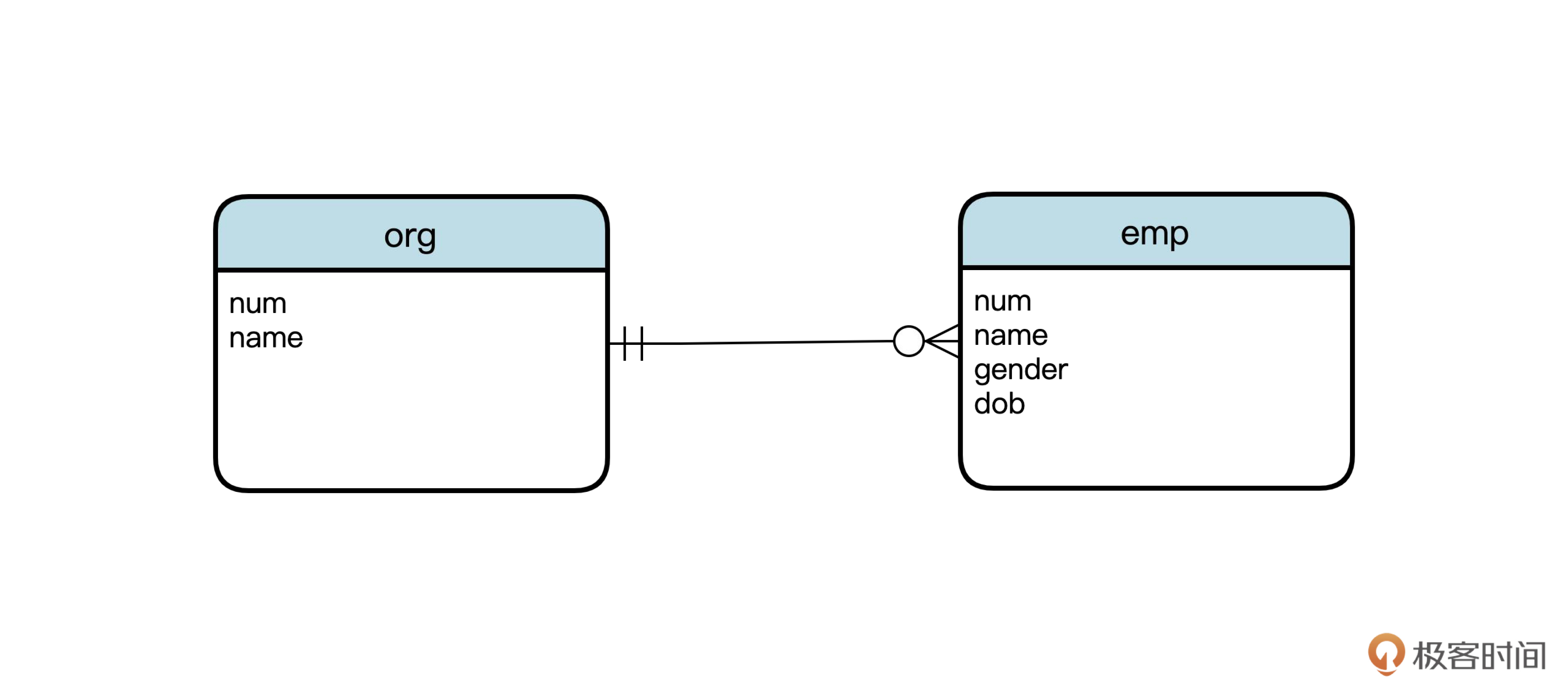
这里要注意一点,有些人以为前面的物理数据模型图就是ER图,其实是不对的。ER图的关注点和领域模型图类似,是实体以及实体之间的关联关系,而物理数据模型图关注的是表、字段、主键和外键等等。
那ER图法和我们这节课讲的方法有什么区别呢?
首先,采用UML类图描述的领域模型图是ER图的超集。也就是说,ER图能表达的,领域模型图都能表达;而领域模型图能表达的,ER图未必能表达。因此,使用领域模型图以后,我们就不必再使用ER图了。
其实我们前几节课进行的领域建模,大体上相当于传统意义上的“概念设计”。如果把领域模型中的属性都补全,就相当于传统意义的“逻辑设计”了。而我们今天做的,其实就是传统上的“物理设计”,所以产物叫做“物理数据模型”。
第二个区别是,ER图只能表达静态的数据关系,只用于数据库设计,而领域模型图则可以将静态数据和动态行为绑定,不仅可以用于数据库设计,还可以用于程序设计,这一点我们在后面的课程会看到。也就是说,基于DDD的方法能够保证程序设计和数据库设计的高度统一。
第三个区别是,领域模型对应的主要是传统软件工程的分析模型,而ER图在传统软件工程里则处于设计阶段,所以两者的层次和使用场合也是不一样的。
总结
好,这节课的主要内容就讲完了,我们来总结一下。
DDD主张要根据领域模型来进行数据库设计,保证数据库和领域模型的一致,从而保证数据库和业务需求以及代码的一致性。在进行数据库设计时,我们可以用物理数据模型图,也可以直接用建表语句,两者基本是等价的。为了直观,我们采用了图示的方法。
对数据表、字段等等的命名,应该依据词汇表,以便保证统一语言。一般来说,领域模型中的实体映射为数据库中的表;领域模型中的属性,映射成表中的字段。同时还要根据需求补充更多的字段。
模型中的一个一对多关联,可以映射成一个外键字段,以及一个外键约束。但基于云的应用一般不会真的建立外键约束,而外键的逻辑关系还是存在的。我们用虚线箭头表示这种逻辑上的外键关系,称为虚拟外键。对于多对多关联,我们必须增加一个关联表,其中包括了两个实体表各自的主键。另外,关联上的多重性决定了外键字段的非空约束。
最后,我们还总结了基于DDD的数据库设计和以前方法的区别。比起“拍脑袋”的方法,DDD的方法更容易和业务专家对齐领域知识,而且不容易违反数据库设计范式。另一方面,DDD方法是ER图法的“超集”,并且能够将静态数据和动态逻辑整合在一起,达到业务、数据库和代码三者的统一。
思考题
最后有两个思考题:
1.我们在多数数据表设计中都用了没有业务含义的 id 作为主键,这种做法比起使用有业务含义的字段做主键有什么优点?
2.我们今天讲的数据表设计都是符合第三范式的,但有时为了性能的原因,常常会有意引入冗余字段,进行“反规范化”设计。在反规范化设计中,你觉得应该注意什么呢?
好,今天的课程结束了,有什么问题欢迎在评论区留言,下节课,我们讲解DDD代码的分层架构,开始进入编程阶段。
- Jxin 👍(6) 💬(5)
以下内容,仅个人补充,不一定正确。与大家探讨。 1.POJO(Plain Old Java Object) 和 POCO(Plain Old CLR Object)以及 PI(Persistence Ignorance)。在ddd里,持久化对象与具体的持久化实现机制之间应该是隔离的,虽然这可能是过度设计,但思路并没有毛病。所以,可能不需要特别关心。 2. not null 这个事,部分公司dba很可能会强制限制默认都是not null, 用def处理 null场景。 道理大家应该也懂。 数据库存储承载模型关系?第一次见,有新意,就是感觉载体不大稳定(存储随意,与领域模型本就没有1:1的必然性)。 3.表命名,有些公司规范可能要 xxx团队_xxx项目_xxx模块_xxx表名。图省事,因为CDC的时候表可能是打散的(比如,ODPS),这时候需要做去重+定位。(当然,你也可以CDC映射时转名字,就是可能要做多次,毕竟CDC不一定就到一个平台,手工多次重复操作?很容易出问题《墨菲定律》) 课后题: 1.没有业务含义的 id 作为主键?不确定是指主键名叫id,还是指主键值没有业务含义。两个都回答下,前者部分low的orm框架的插件限制(不叫id没法自动生成代码);后者是从数据库的性能(B+树要维护有序性)和内存空间占用(其他索引叶子节点空间大小)考虑,但事无绝对,例如 单索引 kv场景。(减少一次回表,抵消写时索引树排序, 无其他索引,无叶子节点空间浪费)。 2.避免了数据冗余并不意味着代码能支持重用,遵守与否都不解决核心问题,所以不用太纠结。更何况存储不见得一直都是关系性数据库。把它当成持久化的一种实现手段,大胆干有问题就改就是。过度在意反而可能影响模型设计,毕竟关系性数据库的范式包含性能等一系列考虑并不是很适应代码模型的设计。
2023-01-03 - ╭(╯ε╰)╮ 👍(16) 💬(4)
自从入行,有四件事阻止了我在技术上的发展 一是数据库范式 二是单元测试 三是领域驱动设计 四是docker 这些东西我甚至比极客时间上的老师接触到的还要早,但是奇妙的事情是我的同事没有一个支持这四个概念,大部分都是持反对态度。同事的“阻挠”让我起了个大早,赶了个晚集。现在看着老师们布道,回想当年同事们看我的眼神,好像我是异教徒,伤感自己生不逢时,好人所恶。自己越是执念越会被社会教育。 随波逐流crud到现在,终于觉得自己熬出头,见到自己曾经执着并放弃的东西又回到了自己的身边。自己没有能力做到的事情看着别人做到,事实挺开心的。 希望老师的课程能让更多的人有所收获。
2022-12-22 - 老狗 👍(7) 💬(3)
问题1: 有以下几个因素: 首先由业务含义的字段虽然业务上不允许重复,但有些时候会出现意料之外的场景,比如拿学生的名字作为主键就会遇到重名的问题,我父亲就是因为重名问题考虑把我名字里的一个字改了,避免了很多困扰。 其次业务主键一般都为字符型,考虑到数据库优化,有的时候递增主键会带来一些效率 再次业务上的唯一主键有些时候为联合主键,维护起来难度更加提升 再再次,解耦业务需求和技术实现。 问题2: 一致性问题是冗余字段必须要考虑的首要问题,就是冗余字段和冗余来源之间的一致性,另外就是性能问题了
2022-12-31 - leesper 👍(5) 💬(2)
前面阳了几天休息了一下,今天可以继续学习了,思考题: 1. 用没有业务含义的id作为主键我觉得是一种分离关注点的设计方式;业务是在变化的,今天适合用来做主键的业务字段,未来未必,索性约定俗成用id算了 2. 符合范式的数据库设计是为了写操作的高效(没有冗余就没有重复的写,同时避免疏忽大意造成漏写),适当的冗余是为了读操作的高效(不必join很多张表才能拿到自己想要的数据)。所以做冗余设计的数据主要用来读,而不是写,比如一些历史的交易流水数据什么的,经常变的数据就不适合做这种冗余设计了 钟老师我有个问题请教下:我记得前面几节课说过,员工和项目之间的“项目成员”关系、“工时记录”关系,不都是多对多吗?为啥不用联合主键的方式设计,而仍然采用id呢?
2022-12-29 - Geek_8ac303 👍(4) 💬(1)
表的主键不使用xx_id而是id,往往是被代码框架约束了,在很多orm模型里,save方法中是按照id不存在就插入,存在就更新 关于违反第三范式,主要还是看表关系和业务需要,如果一个表在搜索的时候可能用到外键表的数据,如果俩个表关联还好,多于俩表,性能会严重下降。在项目初期一般都是冗余字段,来提升搜索和查询数据的性能。业务发展起来有钱有人了,就要考虑搜索引擎了。 但是冗余了字段就要考虑,冗余字段是否会被更新,如果更新了是否要更新冗余字段,在大部分情况下都是些不经常更新的字段才冗余,为了效率,对这种不经常更新的字段就不考虑更新冗余字段
2022-12-22 - Geek_c33f40 👍(2) 💬(1)
老师您好, 审计字段是否应该显示在领域模型上面? 因为有时候审计字段也是有业务含义的, 例如发起人, 群主. 我觉得分开会更好一些. 一方面领域模型和数据模型映射更加清晰一些. 一方面避免业务改动导致审议字段逻辑有变, 例如最后更新时间, 对于某些业务来说, 某些关联的变更不会影响到最后更新时间, 但对于审计来说可能对这条记录的任何修改都需要变更更新时间. 缺点是有部分会有重复
2023-02-11 - aoe 👍(2) 💬(2)
两个思考题: 1. 规则通俗易懂,一下就能掌握规律;降低认知复杂度; 2. 当冗余字段更新时,要更新所有相关数据,不然可能产生不可思议的 Bug。
2022-12-26 - escray 👍(2) 💬(2)
有了前面的领域模型的分析和设计,再加上词汇表的加持,数据库设计看上去似乎水到渠成。 create_at、created_by、last_updated_at、last_updated_by 这四个审计字段确实好用。 文中对于外键约束的说法我比较赞同,就是清楚外键的逻辑关系,但是在实施的时候不使用数据库中的外键约束,而采用程序代码来保证。另外就是,可以考虑一定的数据冗余,这样保证查询的效率。 对于思考题: 1. 采用没有业务含义的 id 做主键应该已经是业界标准了吧,有业务含义的字段很难保证始终不会发生变化。另外,就是倾向于使用整型数字做主键,而不是那种很长的 UUID 字符串 2. 在反规范化设计的时候,同样需要清楚哪些部分是冗余;这些数据冗余甚至可以采用一定的步骤进行统一的清洗和更新。
2022-12-22 - ╭(╯ε╰)╮ 👍(2) 💬(1)
课后思考题 id这个名字算是一种约定大于配置,看到这个名字大家一眼就能识别出来它是表中的主键,背后的逻辑也会被本能的浮现在脑海里。沟通时,丢给对方一个id无需多言,如果使用有业务含义的字段名,那就不好意思了,大家坐下来互相battle一下,从设计到实现,各种细节扯皮一遍,别嫌麻烦 冗余的数据我个人观点是跟回表息息相关,两方面:一是如果数据库足够高级,我们能轻易得到自己需要的数据自然就不需要冗余;二是软件建模不同,结果数据是否冗余也不同,面向对象设计的好,映射到数据库上自然而然的是符合范式的。不需要花额外的功夫。
2022-12-22 - Geek4329 👍(1) 💬(1)
老师有个疑问点,数据模型不一定和领域模型完全一致吧,领域模型和数据模型可能是一对多,多对一都有可能
2023-10-19 - Geek_a2b9d0 👍(1) 💬(1)
如果数据库模型和领域模型一样,那我们还是在面向数据库模型编程
2023-06-26 - py 👍(1) 💬(2)
1. id无感业务,不会被频繁变更;主键一般设为自增长,业务一般不符合;业务字段可能是string等非int字段,性能不高 2. 充分评估必要性;控制度,非必要不违反
2023-02-03 - Michael 👍(1) 💬(1)
组织类别这种表示类型的我的实践一般是在代码里创建枚举类型,然后用 varchar 或者自建的枚举类型作为字段类型,但是这里老师用了一张类似字典表的设计,想请教这样的设计的意图是啥?
2023-01-23 - 6点无痛早起学习的和尚 👍(1) 💬(1)
一些思考和问题: 1. 如果组织类别是死的,那就可以直接作为一个表的字段去枚举,课中是灵活动态添加的,所以是一个单独的表,员工岗位同理。 2. 工时记录表里的租户 id,是否只是一个扩展字段设计,方便可以直接看到这个工时记录是哪个租户的,因为如果为了最终能查询到租户 id,在工时记录表里不设计租户 id,可以通过项目 id 一步一步去反查到租户 id,因为之前在领域建模设计阶段,工时记录和组织其实没有直接的比例关系。 3. 还需要再继续读一读:与“ER 图法”的区别
2023-01-03 - 刘学习来学习 👍(0) 💬(1)
按照领域模型直接建表的话会不会有这样的问题,领域模型重在业务语义的表达,数据表要考虑性能和扩展,我理解一个模型可能会拆分成n张表来存储,只需要过程中有一个对象可以映射领域模型就行了吧
2024-08-27