30 限界上下文(下):限界上下文之间如何集成?
你好,我是钟敬。
上节课我们进一步深入学习了上下文映射,并且开始根据限界上下文进行架构设计,主要谈的是单体架构。
在某些场合里,采用单体架构比较适合。不过,我们现在开发的是一个基于云原生的 SaaS 应用。在云原生的情况下,一般不会采用单体架构,微服务才是最佳实践。那么微服务应该怎么设计呢?
这节课,我们会继续学习微服务的设计。之后,会讨论限界上下文之间的集成。所谓限界上下文的集成,就是通过在代码中实现限界上下文的映射,完成跨限界上下文的业务功能。
微服务的设计
我们先了解一下微服务的设计方法,再进一步讨论为什么要根据限界上下文设计微服务。
微服务的设计方法
设计微服务,我们可以先假定每个限界上下文对应一个微服务。然后,再综合考虑多方面的因素,决定是否需要进一步细分。下面是几种常见的情况。
第一,不同的可伸缩性要求。如果一个上下文里有些部分,需要随着使用情况,动态部署到更多的容器,比如说“双十一”促销的时候。而另外的部分性能要求比较稳定,不需要动态伸缩。那么,如果不同部分都混在一个微服务中,那么当扩展到更多容器的时候,成本就会比较高了。这时候,我们可以考虑根据可伸缩性的不同,划分成两个微服务。
第二,不同的安全性要求。比如说,有些功能要接入互联网,有些部分在内网用,需要部署在防火墙的不同位置。这时候,也需要划分成不同的微服务。
第三,技术异构性。比如说,有些部分需要用 Java 开发,有些部分需要用 node.js 开发,这时候,也要分成不同的微服务了。
就我们目前的例子而言,假设没有上述因素的影响,那么直接按限界上下文来划分就可以了。我画了一张架构图,供你参考。
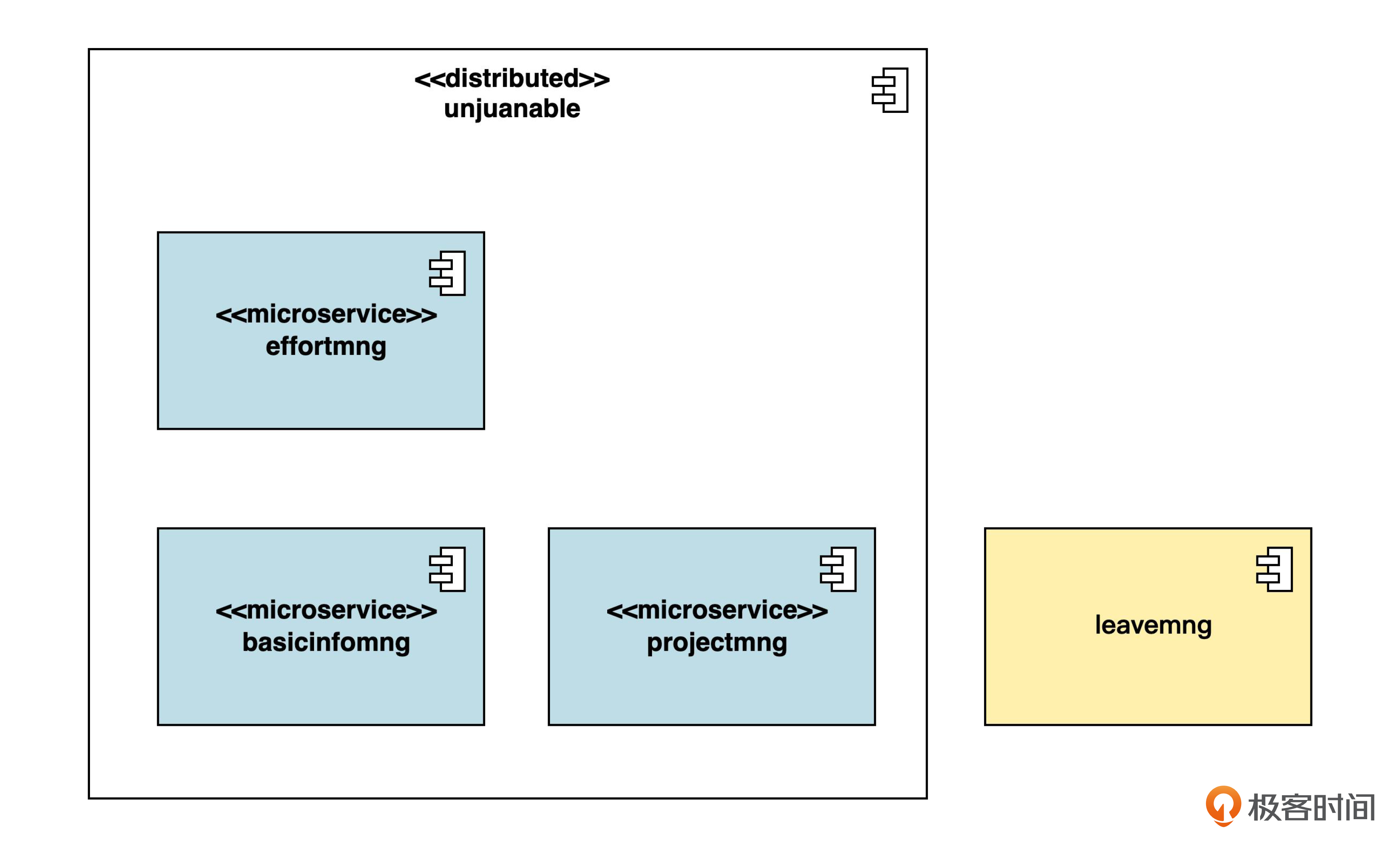
这个图在形式上看起来和单体架构很像,不同之处在于衍型。父组件用 <<distributed>> 衍型来说明这是一个分布式应用。各个子组件用 <<microservice>> 来说明这些是微服务。这两个衍型也是自定义的。事实上,你也可以自己定义衍型,满足团队或项目的需求。
为什么要根据限界上下文设计微服务
说到这,我们回过头来思考一下为什么要根据限界上下文来设计微服务。
微服务的划分,可以从功能性需求和非功能性需求两方面考虑。
从功能性方面考虑,微服务的划分应该有利于保证系统概念的一致性,更容易灵活扩展功能,而这些又要求开发团队顺畅的沟通协作。
根据限界上下文来划分模型,既考虑到了传统模块化思维中对业务概念的松耦合、高内聚的要求,又考虑到团队的认知负载和认知边界。这样,一方面解决了团队协作和概念一致性问题。另一方面,每个限界上下文又是一个业务概念内聚的边界。在这个边界内部,就更容易建立可维护、易扩展的模型。
从另一个角度来说,合理的微服务划分,应该是对于多数需求变更,只需改动一个或少量的微服务。而划分不合理的话,对于多数业务需求,都要修改多个微服务。有人把这种现象叫做“分布式单体”,这其实也是因为模型划分不合理,没有找到内聚的业务边界。而限界上下文可以解决这个问题。
限界上下文为微服务的划分奠定了基础。然后,就可以再考虑性能、安全、可用性等非功能性需求,看是不是需要进一步划分。有时候,其实也可以考虑把几个限界上下文合并到一个微服务里。极端情况下,所有上下文合并到一个服务,就又变成了单体。
这样做的话,至少保证微服务和限界上下文的划分不会产生“交错”的情况。也就是一个微服务包含了一个上下文的一部分,但是又包含了另一个上下文的另一部分,这就很容易出现“分布式单体”了。
限界上下文间的集成
现在我们已经讨论完了微服务设计,下面继续进行限界上下文集成的设计。
不同的集成策略
在概念上的同一种映射关系,在实现上可以有不同的策略。我们可以先想一想,从“基础信息管理”上下文把员工信息映射到“工时管理”上下文的逻辑。
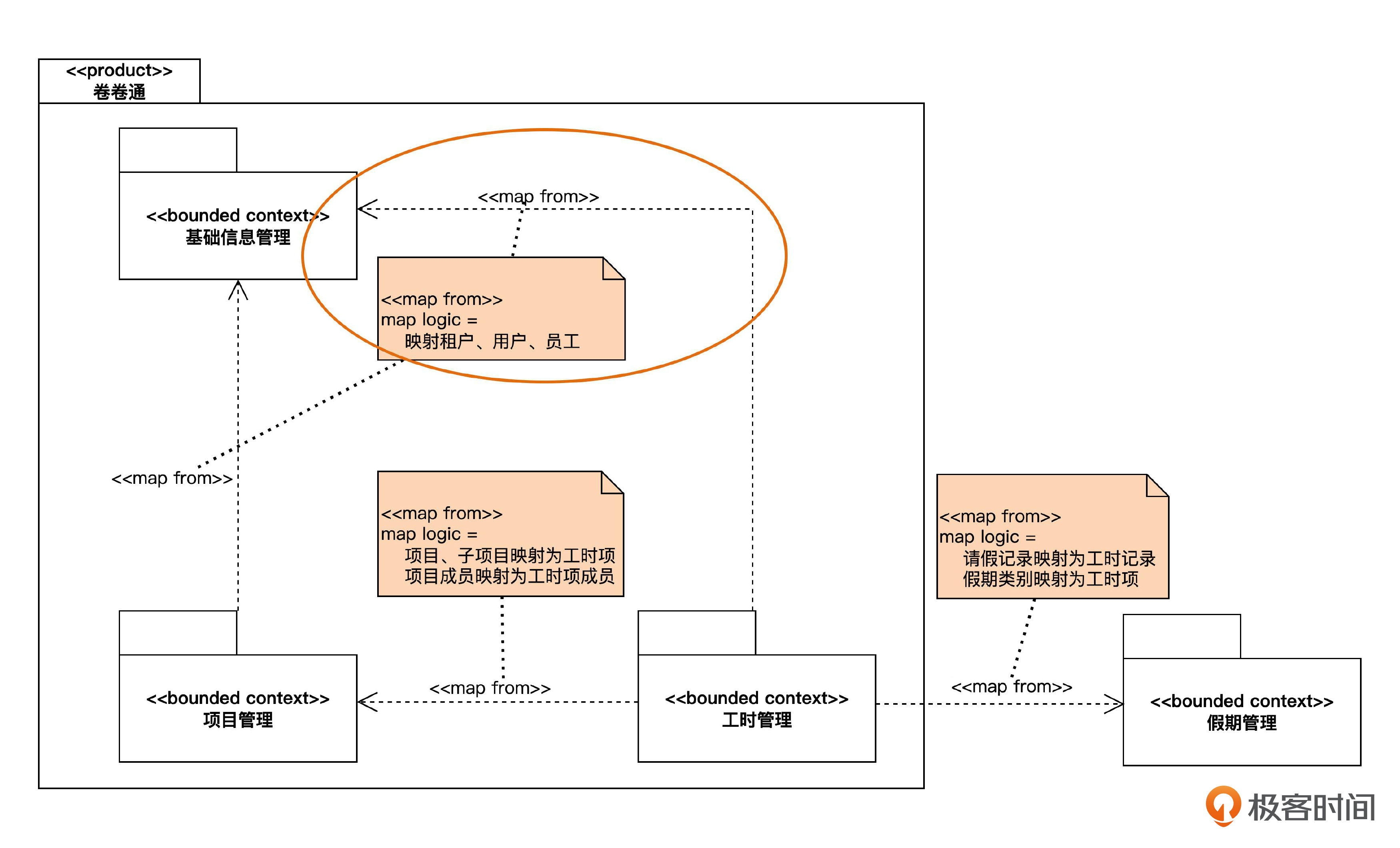
假设已经按上下文划分了微服务,这时候“工时管理”中的某个功能,需要获得“基础信息管理”中的员工数据,那么,至少可以有两种策略供我们选择。
一种是数据同步策略。也就是说,在“工时管理”服务对应的数据库里,建立员工表,但只包含工时管理需要的字段。然后,当“基础信息管理”中的员工信息发生了新增、修改或删除的时候,以某种方式把数据同步到“工时管理”数据库。这样,工时管理就可以通过访问本地数据库获得员工信息了。
另一种是 API调用策略。在“工时管理”的数据库里不需要建立员工表,而是每次需要员工信息的时候,都调用“基础信息管理”提供的 API 来获取数据。
再来考虑一下“项目管理上下文”的项目信息映射到“工时管理”中的工时项的情况。
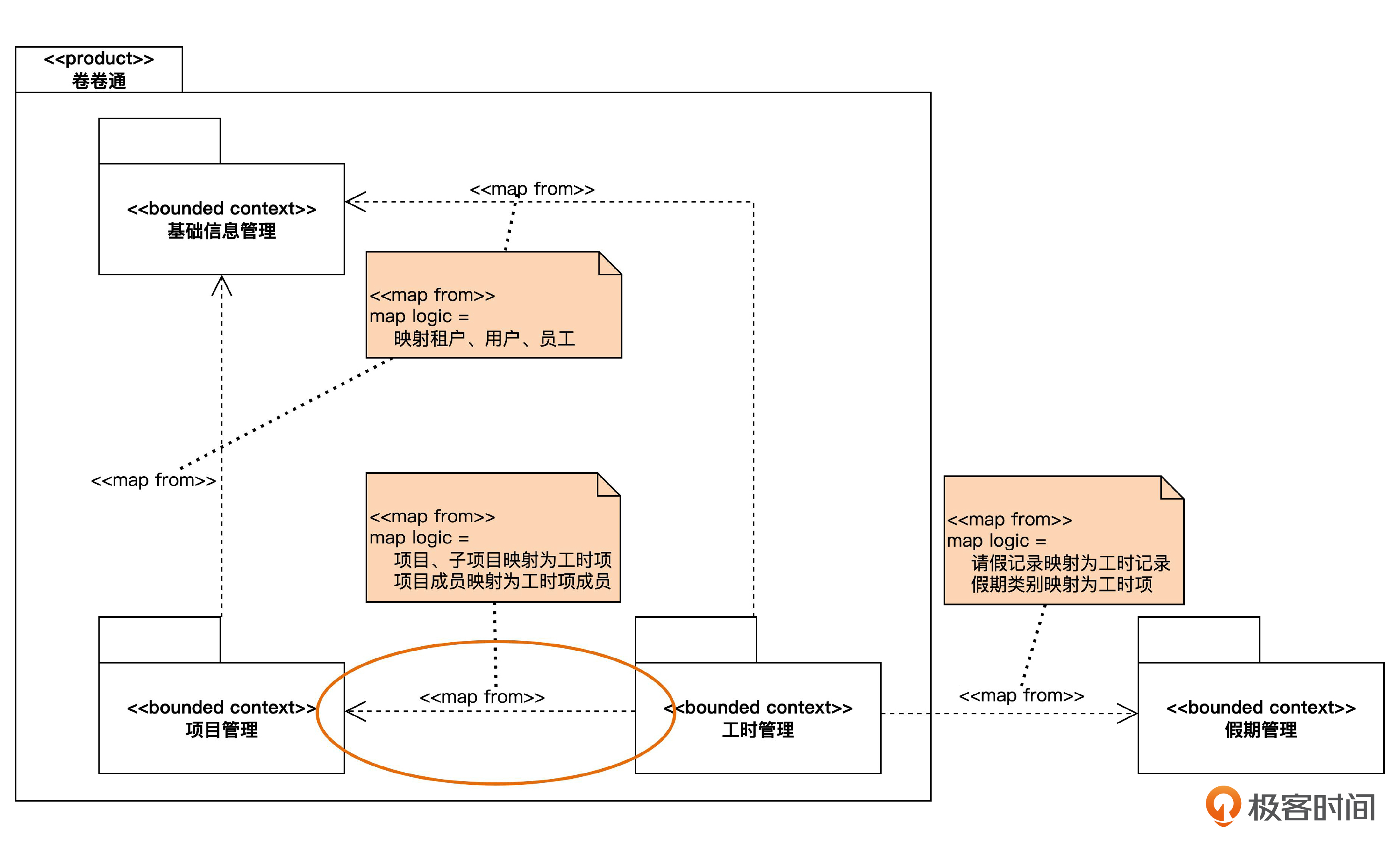
这时候,工时管理数据库中有一个工时项表。“项目管理”在新增、修改和删除项目时,“工时管理”中的工时项表可能会发生相应的变化。我们以在“项目管理”中新增项目为例,来看看实现策略有哪些。
一种是同步调用。“项目管理”新增一个项目,“项目管理”服务就会调用“工时管理”服务中的一个“新增工时项”接口,“工时管理”服务就会在自己的工时项表里增加一条记录,然后把成功信息返回给调用方。“项目管理”服务会等待这个成功信息,收到以后,才会继续处理其他逻辑。
另一种是异步调用。“项目管理”新增项目以后,会向消息中间件发送一个“项目已增加”的事件,然后不用等待,继续进行其他处理。而“工时管理”服务中会订阅“项目已增加”事件。当监听到这个事件发生的时候,就会在自己的工时项表里增加一条记录。这种方式也叫做“事件驱动”架构。
前面说的“工时管理”服务调用“基础信息管理”服务的 API, 来获取员工信息的策略,通常也是同步调用。
注意,不论采用哪种策略,概念层面的映射关系都是一样的,只是实现层面不同。不同的实现策略,可以根据性能、时效性、技术复杂度、数据可靠性等多个维度进行权衡。
防腐层
下面我们聊一个比较重要的问题,就是当两个上下文发生概念映射的时候,进行数据转换的逻辑应该写在哪里。
就以“工时管理”服务调用“基础信息管理”服务的 API, 获取员工信息为例吧。我们先谈单体的情况,然后再过渡到微服务。
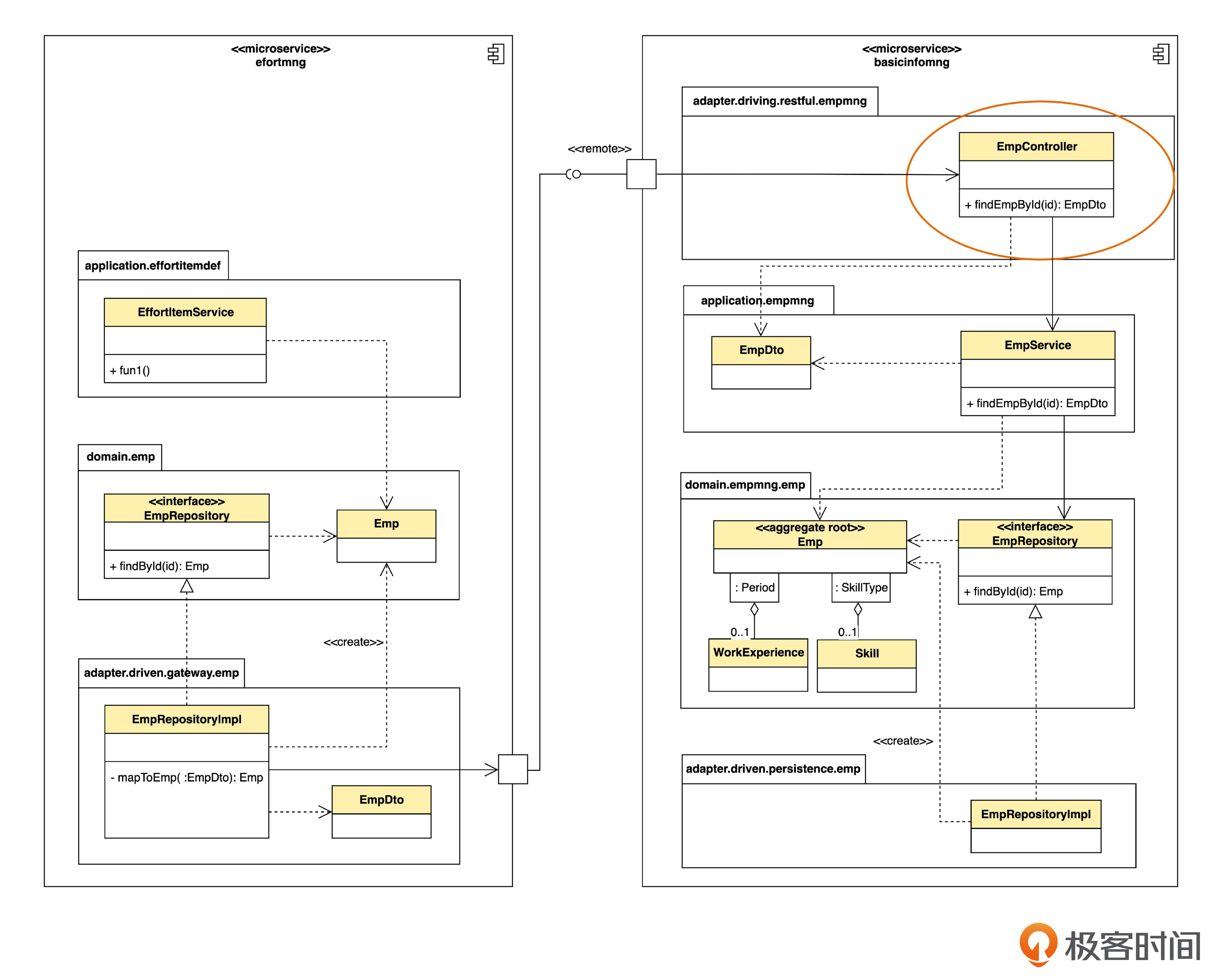
先看看单体架构下,上下文调用的设计类图。
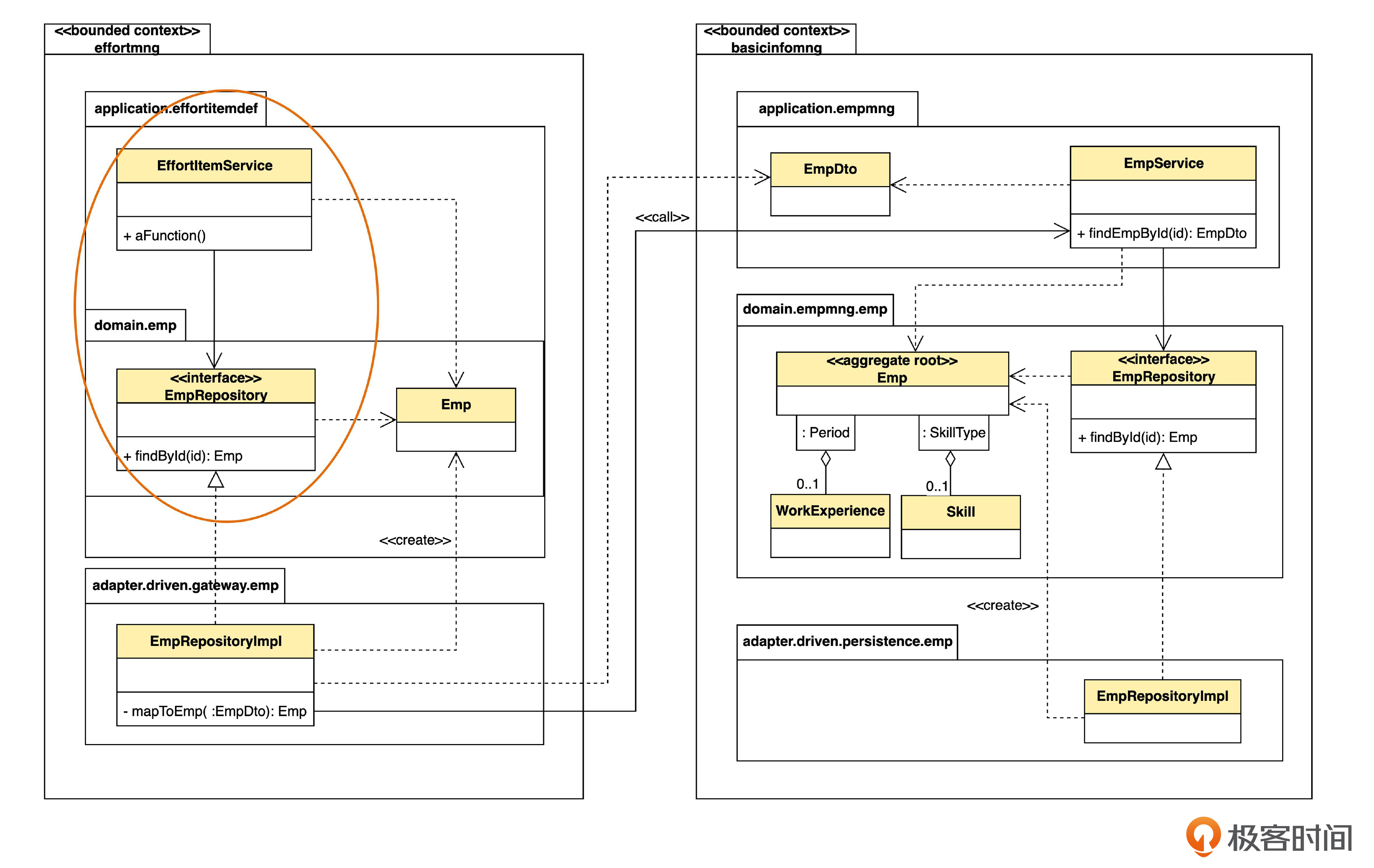
从图里可以看到,工时管理(effortmng)和基础信息管理(basicinfomng)是这个单体系统根目录下的两个包,分别代表两个限界上下文。假设 EffortItemService 里有一个 aFunction() 方法,在执行过程中,需要获得员工信息。这时,aFunction() 可以调用 EmpRepository 中的 findById() 方法。我们一步一步来说明。
上图的 EffortItemService 和 EmpRepository 之间是实线箭头,表示单向关联关系,也可以叫单向导航关系。之所以是实线,是因为 EmpRepository 的实例是 EffortItemService 的一个属性,一般通过依赖注入机制来注入。而 EffortItemService 和 Emp 之间则是虚线箭头,表示依赖关系,这是因为 Emp 并不是 EffortItemService 的属性,只是被使用了。其他的虚线箭头同理。
下面再强调一下两个上下文间的概念区别。
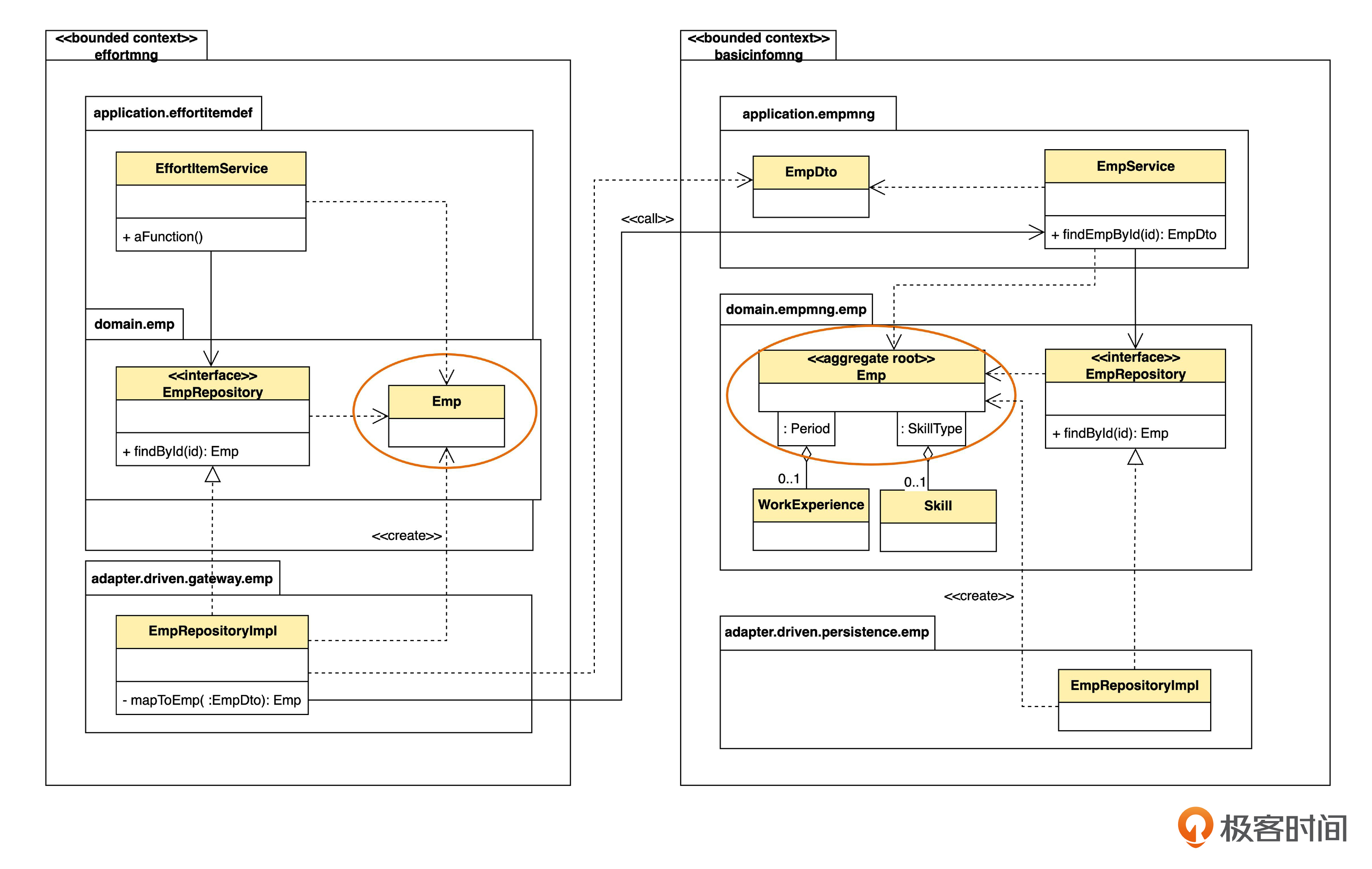
同一个系统里,有两个 Emp 类,但是属于不同的上下文。“基础信息管理”里面的 Emp 带有工作经验和技能,并且属性会更多;而“工时管理”里面的 Emp 没有工作经验和技能信息,而且只有少数几个要用到的属性。那么这两个Emp 转换发生在哪里呢?
转换就发生在员工仓库,也就是 EmpRepository 的实现里。
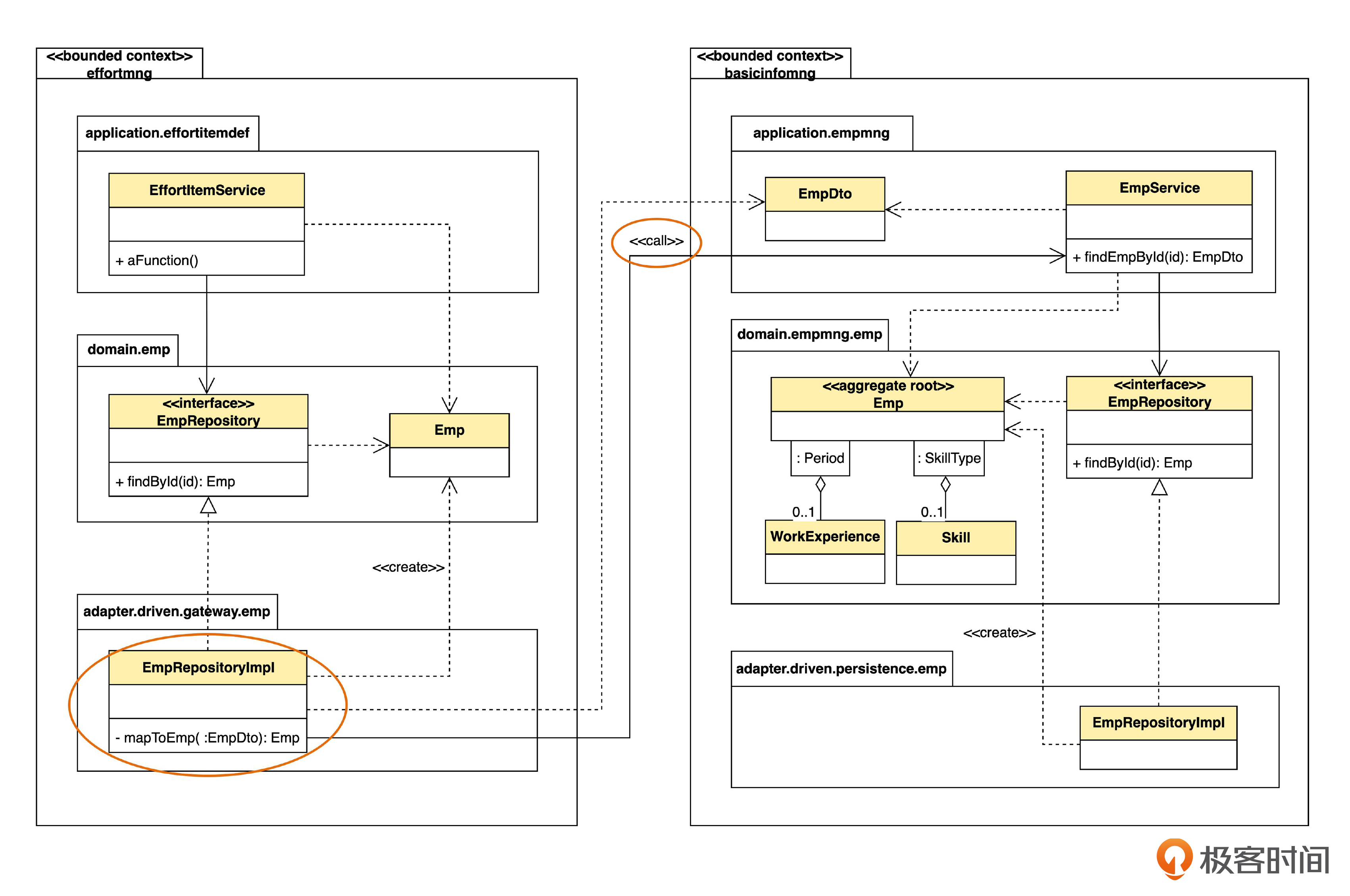
首先,EmpRepository 并不直接访问数据库,而是访问另一个上下文的 Service。不过,对于 EffortItemService 来说,它并不需要知道仓库是怎么实现的。它只知道,要调用仓库取一个实体,所以,仍然命名为 Repository。但是,如果在语义上不是简单的增删改查的话,就不应该用 Repository 的名字了,可以起别的名字,比如说 XxxService 之类。
再留意一下,仓库的实现类 EmpRepositoryImpl 在 gateway 包里面,而不是像之前那样在 persistence(持久化)包里面。这是因为,在实现层面,就要考虑不同技术了。如果访问数据库,就算是持久化;如果访问别的 Service,通常叫 gateway,也有人喜欢叫做 proxy。
EmpRositoryImpl 对 findById() 的实现过程分两步。
第一步,调用 “基础信息管理”里的EmpService 中的 findEmpById(),得到 EmpDto。
第二步,调用自身的 mapToEmp() 方法,把来自于“基础信息管理”上下文的 EmpDto 转化成“工时管理”上下文中的 Emp,然后返回给 EffortItemService。
我们看到,在“工时管理”上下文,只有 EmpRositoryImpl 能够看到其他上下文的Service 和 DTO。也就是说,仓库的实现封装了对其他上下文的调用。如果将来,“基础信息管理”的 API 和DTO 改变了,那么只需要改EmpRositoryImpl 内部的逻辑就可以了,“工时管理”的其他部分都不需要修改。EmpRositoryImpl 就充当了防腐层的作用。
DDD 中,防腐层也是一种用于上下文映射的模式。指的是两个上下文之间的转换逻辑,这个逻辑可以屏蔽两个上下文的差异,从而使两个上下文可以相对独立地演进。我们目前采用的方法是让适配器充当防腐层。
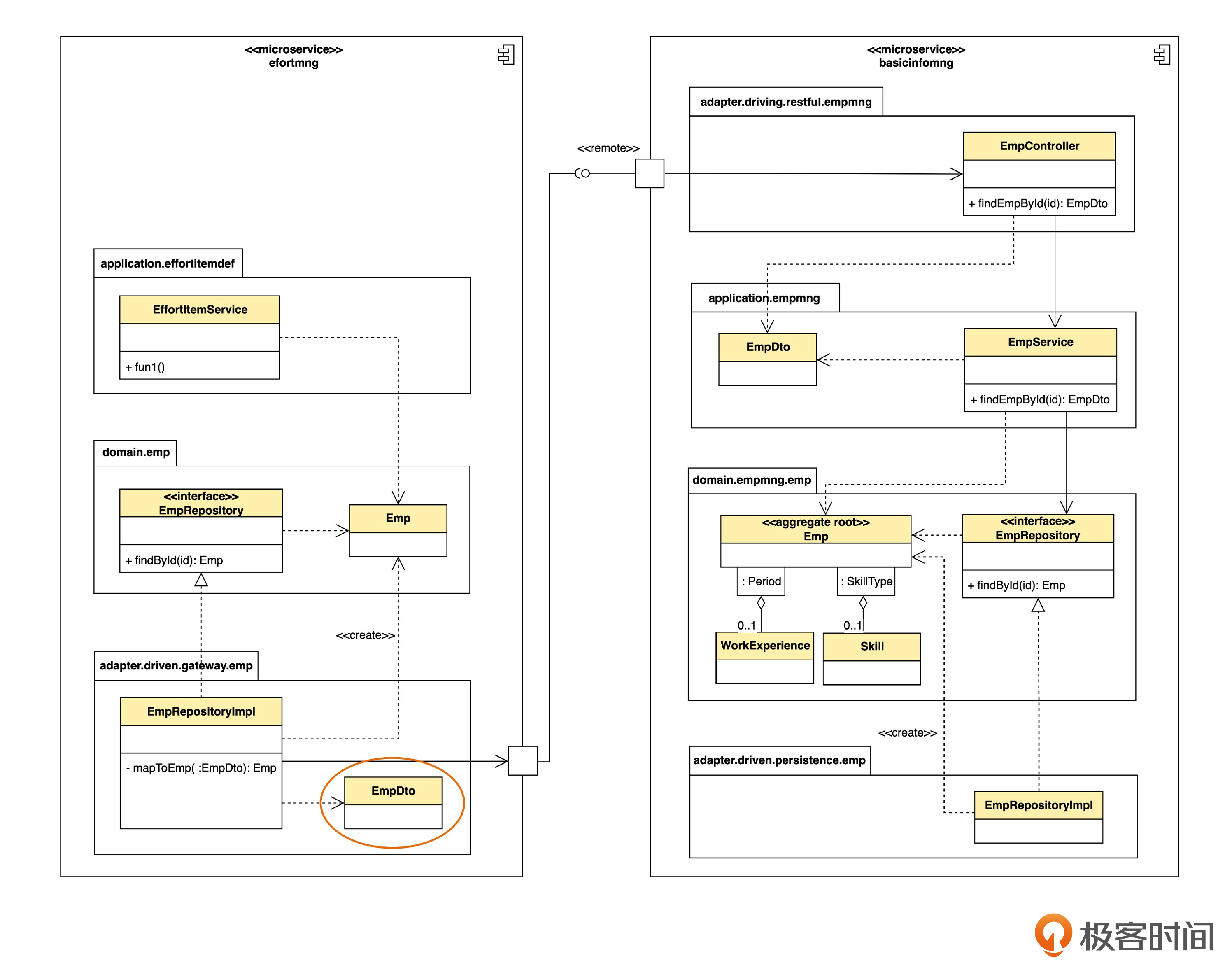
下面,假设我们要把单体拆成微服务,那么同样的功能,就变成下面的样子。

这个图和之前的单体架构相比发生了几个变化。
第一,原来在一个组件里的两个包,变成了两个表示微服务的组件。
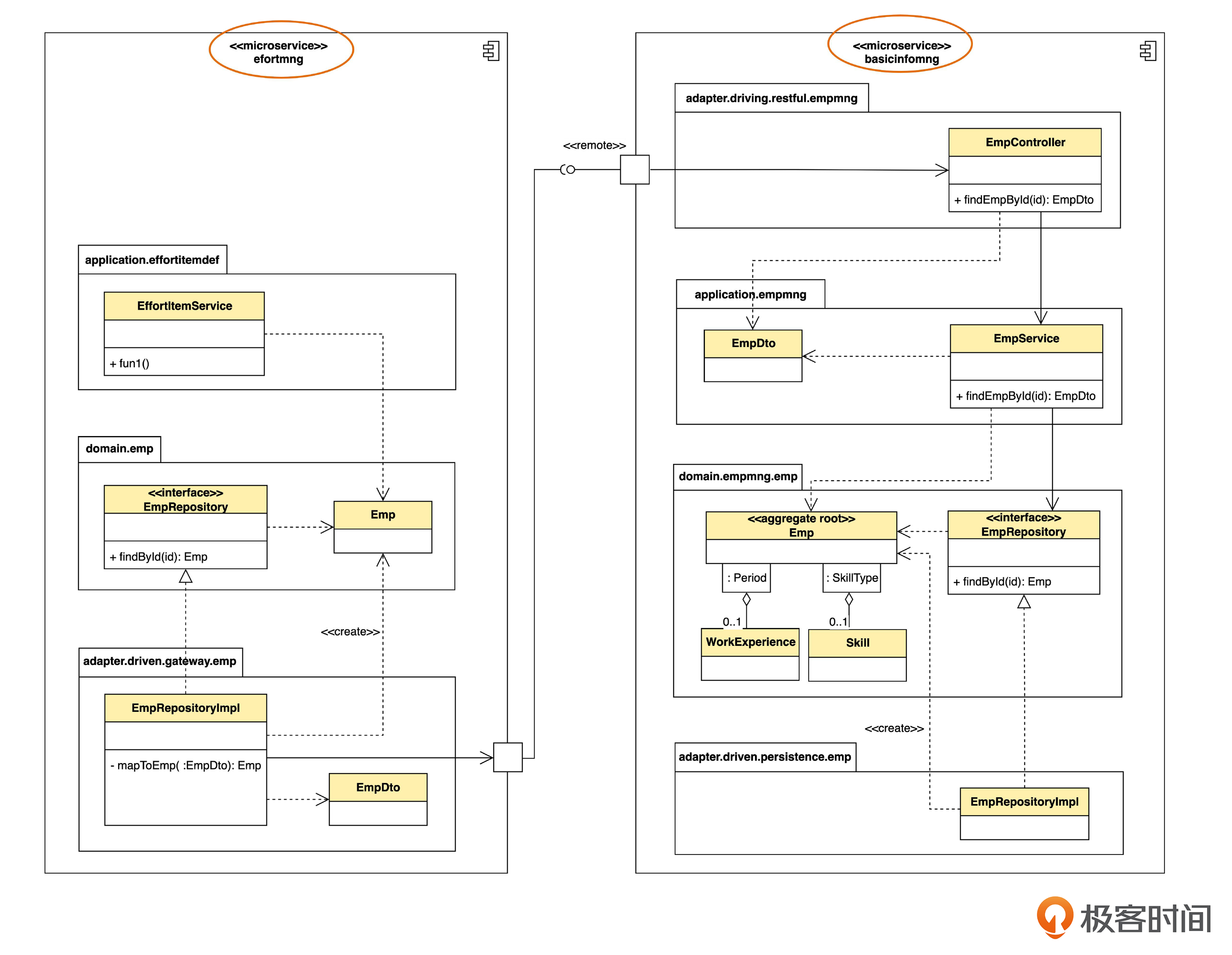
第二,原来的本地调用变成了远程调用。
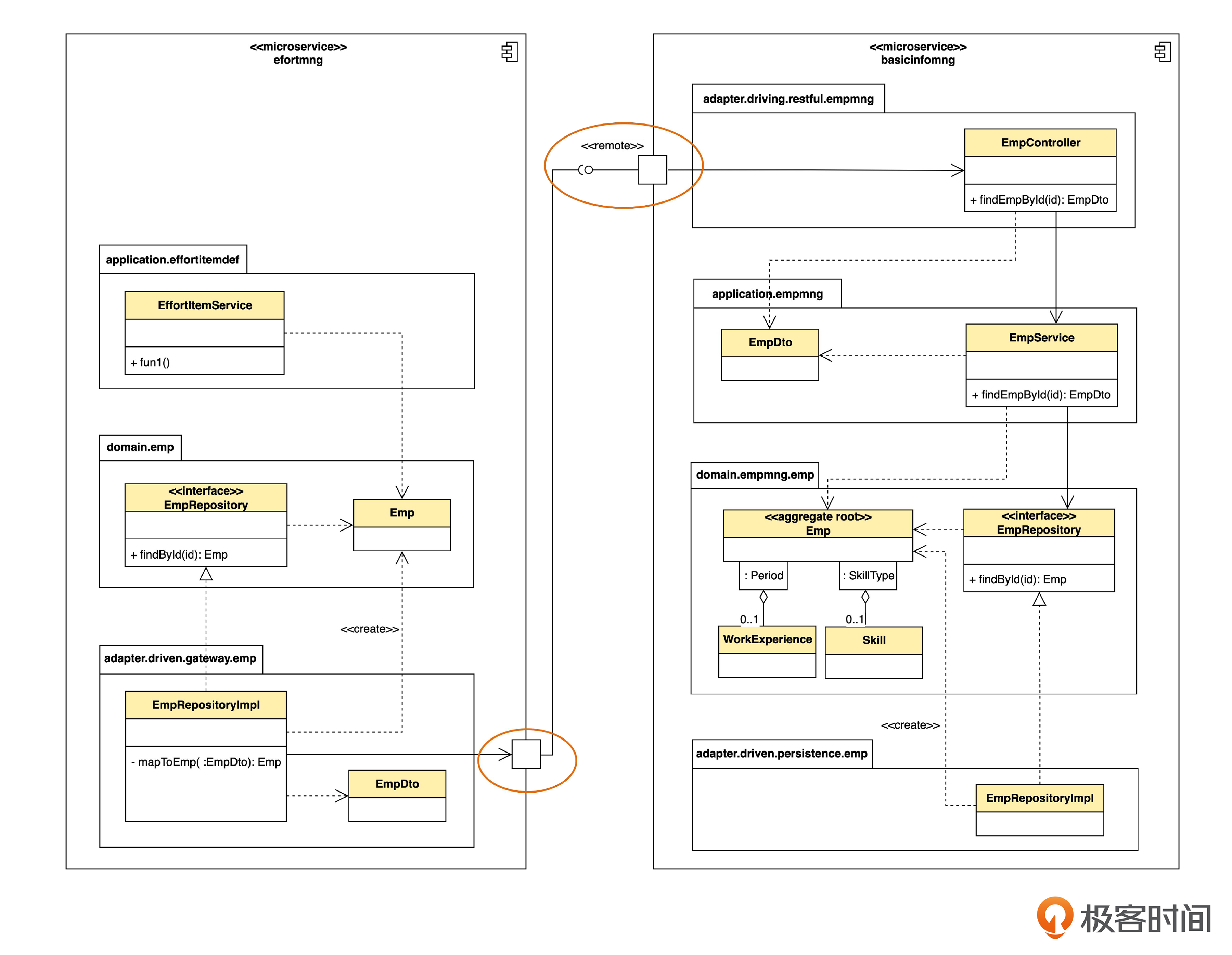
注意一下新增的两个符号。
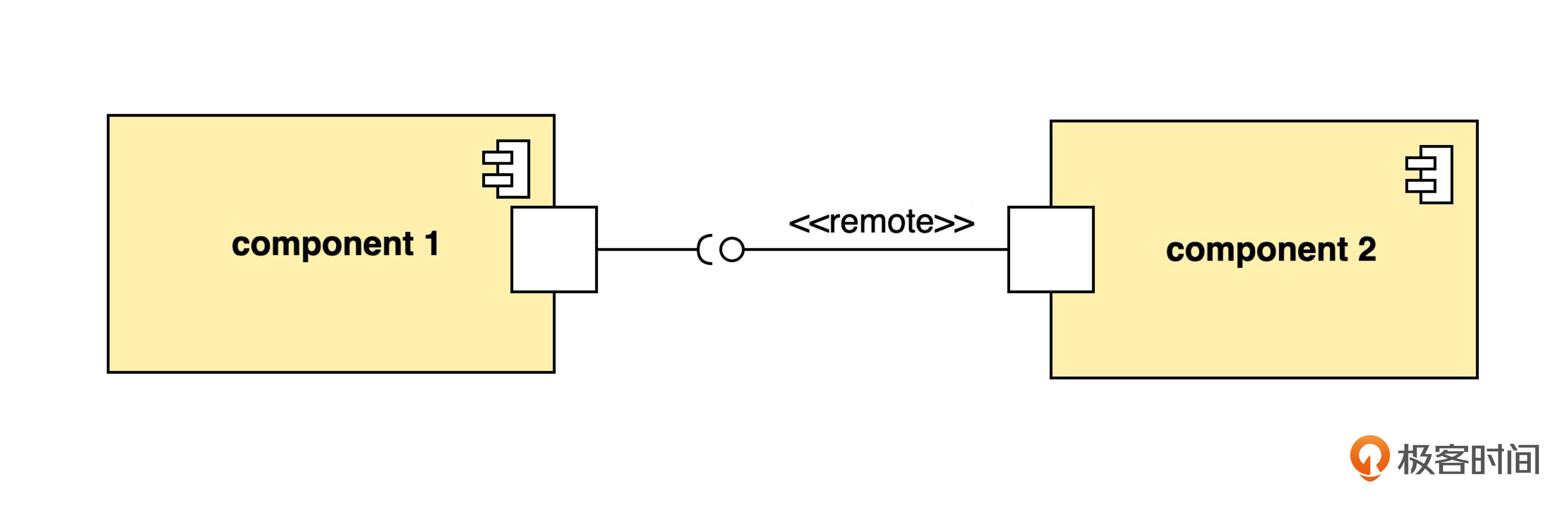
组件上的小正方形,在 UML 里叫做端口(port)。端口上的小圆圈代表组件对外提供的接口,也叫“供给接口”。端口上的小半圆代表对其它接口的调用,也叫“需求接口”。两者连在一起,表示一个完整的调用关系。一个端口上可以提供若干个接口,也可以调用若干个接口。
接口可以是本地的或者远程的(例如 Resful API)。我这里用一个 <<remote>> 衍型表示远程 API。
第三,原来EmpRepositoryIml 直接调用 EmpService,现在则要经过 EmpController ,也就是适配器层。这是因为,在远程调用的情况下需要适配器来进行技术适配,而本地调用时则不需要。
第四,原来EmpRepositoryImpl 直接使用“基础信息管理”中的 EmpDto,现在要自己定义一个了。假如远程通信使用的数据格式是JSON,那么 EmpRepositoryImpl 在接收数据时,就会通过某种机制把 JSON 转成 EmpDto。
尽管有这四点改变,但是有一样没有变,就是从“基础信息管理”上下文获取员工数据的逻辑,仍然是封装在仓库(EmpRepository),或者说防腐层里。也就是说,如果按照这里说的防腐层的机制来做,在把单体拆成微服务的时候,理论上只需要改防腐层的逻辑就可以了。
这样,你是不是更深刻地体会到了防腐层的作用?防腐层隔离了上下文之间的变化,可以使两个上下文各自独立演化,逻辑更加内聚,也更容易测试。
什么是战略设计和战术设计
最后,我们再说一下什么是战略设计和战术设计。我发现这个问题也是众说纷纭。其实在 《领域驱动设计》原书里只提了战略设计,包括限界上下文、精炼、大型结构三部分。但没有提战术设计这个词,或许这就是后来概念混乱的原因吧。
不过按一般人的思维,有了战略,自然要有“战术”。所以后来有的书就提出了“战术设计”这个词。大体上,不是战略的部分就属于战术了。
首先,战略设计和战术设计中的“设计”应该指广义的设计,而不是和“分析”相对的软件设计。
所谓战术设计,就是细粒度的建模,包括实体、值对象、关联、模块、聚合等等。
而战略设计,解决的是当系统变得很大很复杂的时候,怎样从宏观上把握系统的总体结构,应对系统的规模和复杂性的问题。我们的课程中讲的限界上下文,就是一种在宏观上分而治之的手段。
总结
好,这节课的内容讲完了,我们来总结一下。
设计微服务,可以先假定一个限界上下文就对应一个微服务。然后,再综合考虑可伸缩性、安全性、技术异构性等因素,看是否要把限界上下文进一步拆分或合并。
根据限界上下文设计微服务有两个优点,一个是便于开发团队的协作,另一个是避免开发出“分布式单体”。
我们还讨论了上下文间的集成问题。限界上下文之间可以有多种集成策略。在一个维度上,可以分成数据同步和 API调用两种;在另一个维度上,可以分成同步调用和异步调用。异步调用,常常采用“事件驱动”的架构。
我们也介绍了在集成中常用的防腐层模式。防腐层能够隔离两个限界上下文的变化,使两个上下文各自独立地演进。理论上,当单体架构拆分成微服务的时候,只需要修改防腐层就可以了。我们例子中的防腐层是在适配器中实现的。
我们还顺便复习了设计图的画法,学习了 UML 中组件的端口和接口如何表示。
思考题
最后给你留两道思考题。
1.软件开发中,一般都比较注重可重用性。那么,如果两个限界上下文中有类似或相同的部分,你觉得是否应该抽取成可重用的模块呢?
2.除了在仓库里以外,你觉得防腐层还有没有其他的实现方式以及其他的实现位置?
好,今天的课程结束了,有什么问题欢迎在评论区留言。下节课,我们讲解 CQRS 模式,用于处理查询需求,敬请期待。
- 李威 👍(16) 💬(1)
问题一:假设两个限界上下文是由两个团队负责的微服务,当两个限界上下文只有少量相同的逻辑,最好就各自维护自己的,用少量的重复来换取两个团队之间的沟通成本,当两个限界上下文出现了很多的重复逻辑那就可以考虑把相同的逻辑抽取成一个单独的微服务,并提供给之前的那两个微服务去调用。 问题二:仓库作为防腐层屏蔽了实体的获取细节,其实Controller也是防腐层,它屏蔽了不同的请求协议。
2023-02-22 - 荣耀39 👍(1) 💬(1)
几个限界上下文在同一个微服务中,互相间的调用都通过反腐层调用的方式,会多出不少的转化的代码,特别是dto转domain对象,这个代价相对于收益是否划算?我们是否也可以两个领域对象Emp间进行转化呢?要拆分微服务的时候再去做防腐层调用及dto转domain对象
2023-03-14 - humor 👍(0) 💬(1)
而另外的部分性能要求比较稳定,不需要动态伸缩。那么,如果不同部分都混在一个微服务中,那么当扩展到更多容器的时候,成本就会比较高了。 为什么不用伸缩性要求的部分放在一起会导致成本高呢?不就是把代码部署一份吗?cpu和内存应该跟分开部署差别不大吧
2024-04-11 - 努力的C-C 👍(0) 💬(1)
对于从单体应用--->微服务应用的设计图有一点疑问, 在单体应用中EffrotItemService会直接调用EmpRepository来获取Emp. 但是在微服务应用的设计里EffrotItemService只依赖了EMP .没有看到如何通过EmpRepository来获取Emp . 请问在微服务应用的设计中EffrotItemService是如何通过EmpRepository获取EMP的
2024-02-19 - Geek_2ba566 👍(0) 💬(1)
防腐层我一直没搞明白,一般放在哪个调用模块中还是被调用模块中呢?有没有示例代码,可供参考学习学习?
2023-09-09 - aoe 👍(0) 💬(2)
来自新必应对思考题的回答: 问题一 这是一个很好的问题。限界上下文是用来细分领域,从而定义通用语言所在的边界1。限界上下文之间可能存在依赖或重叠,这时候就需要考虑是否抽取成可重用的模块。 根据我的搜索结果,有以下几种可能的做法: 如果两个限界上下文之间有类似或相同的部分,但是它们的含义和行为不一样,那么就不应该抽取成可重用的模块,而是应该保持各自独立。 如果两个限界上下文之间有类似或相同的部分,并且它们的含义和行为一致,那么可以抽取成可重用的模块,并且在物理层面上进行无缝集成3。这种情况下,需要注意避免开发人员绕过防腐层直接调用另一个限界上下文的代码。 如果两个限界上下文之间有类似或相同的部分,并且它们的含义和行为基本一致,但是有些细节不同,那么可以抽取成可重用的模块,并且在逻辑层面上进行隔离3。这种情况下,需要使用防腐层进行模型或协议的转换。 问题二 防腐层是一种用于隔离两个系统的模式,可以在不知道对方领域知识的情况下进行集成¹。防腐层主要进行的是两个系统之间的模型或协议的转换。 除了在仓库里以外,防腐层还可以作为应用程序内的组件或作为独立服务实现。但是,防腐层也有一些问题和注意事项,比如可能增加调用延迟、管理和维护成本、缩放方式等。 我的读后感 1. 好强大的设计:不论采用哪种策略,概念层面的映射关系都是一样的,只是实现层面不同 2. 又学到了一个根据不同实现技术分层的原则:访问数据库用 persistence、访问别的 service 用 gateway 或 proxy
2023-02-28 - 铿然 👍(0) 💬(0)
是否重用跟技术难度和组织也有很大关系,难度不大谁都能写直接就写了;组织中如果专门有人负责公共组件并且有制度约束那重用概率就大。 限界上下文划分微服务要看粒度,很多时候作为一个小模块,子功能就可以,不需要拆分微服务,不能为了拆而拆,不同上下文的概念映射,数据同步带来了复杂性,要权衡是否必要。
2023-06-20 - buoge 👍(0) 💬(0)
作为AI语言模型,我认为抽取成可重用的模块是有必要的。这样可以避免重复的代码,提高代码的可维护性和可重用性。而且如果有多个限界上下文中需要使用相同的部分,抽取成模块可以方便地在各个上下文中进行使用和维护,同时还能降低代码的耦合性,提高系统的灵活性和可扩展性。
2023-03-22 - 6点无痛早起学习的和尚 👍(0) 💬(2)
思考题: 1. 在实际开发过程中,遇到上下文的实体重复,我们会把 xxRequest、xxResponse 放在一个 common 包里,多个服务用一个 common jar 包 2. 有时候能否也在应用层去实现,应用层一边调用领域层,然后再调用其他上下文,转换逻辑放在调用层里的上下文映射实体里
2023-02-27