32 CQRS(下):CQRS还有哪些变化?
你好,我是钟敬。
上节课,我们从业务需求出发,一步步推演,学习了CQRS的基本原理。另外,我们还学习了“代码结构分离”和“数据库结构分离”两种策略。
在这两种策略中,程序仍然在同一个微服务,数据库也只有一个实例。但是,当我们遇到更高的并发性能需求时,就要考虑分布式程序和数据库了。这就是今天的两种策略要解决的问题。之后,我们还会讨论如何权衡这些策略,做出恰当的技术决策。
应用服务分离
我们先回顾一下上节课里,“数据库结构分离”部分的架构图。
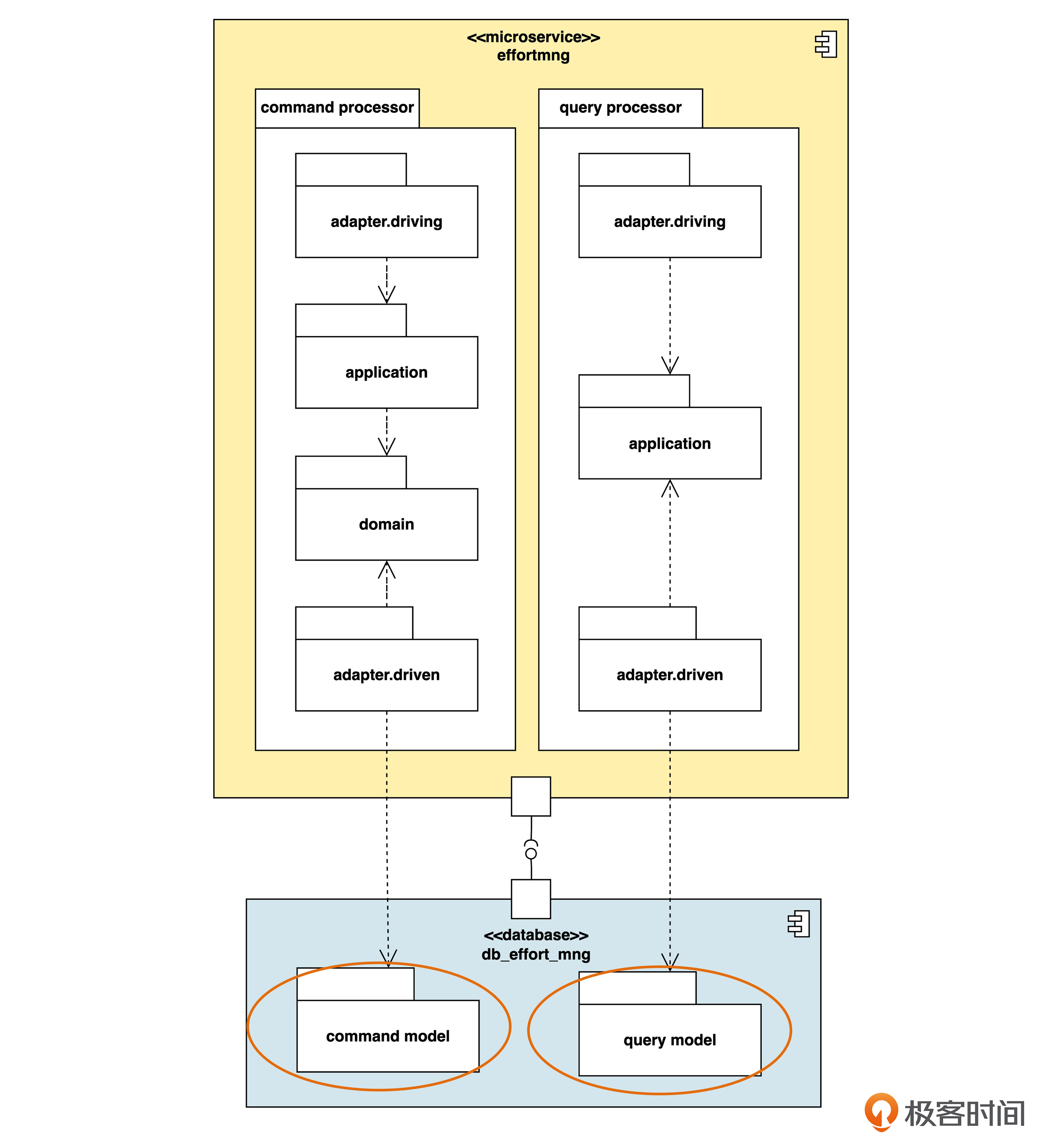
如果我们发现,使用命令的并发请求相对比较少,而使用查询的并发请求却很多,需要横向扩展才能满足性能和可用性要求,那么就可以考虑拆成两个微服务了。我们把这种策略称为“应用服务分离”。
拆分后的架构图是后面这样。
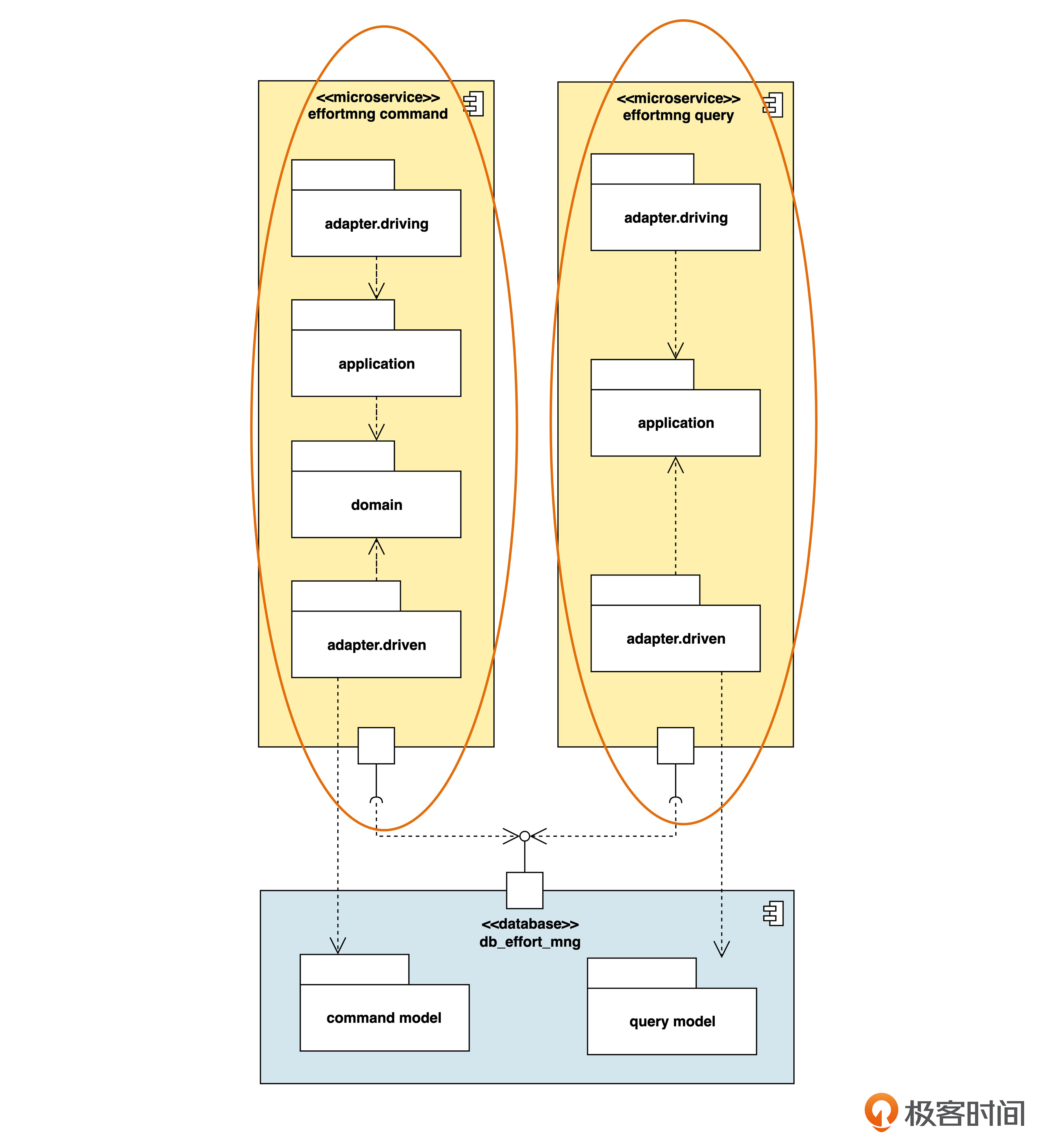
对照这张图我们可以看到,命令处理器和查询处理器原来是在同一个微服务中的,现在拆成了两个。这样,两个服务的可伸缩性就可以不一样了。例如负责处理命令的微服务可以部署在 5 个容器里,而负责处理查询的微服务部署在 10 个容器里。
另外还有一个小细节,你可以结合后面这张图看一下。
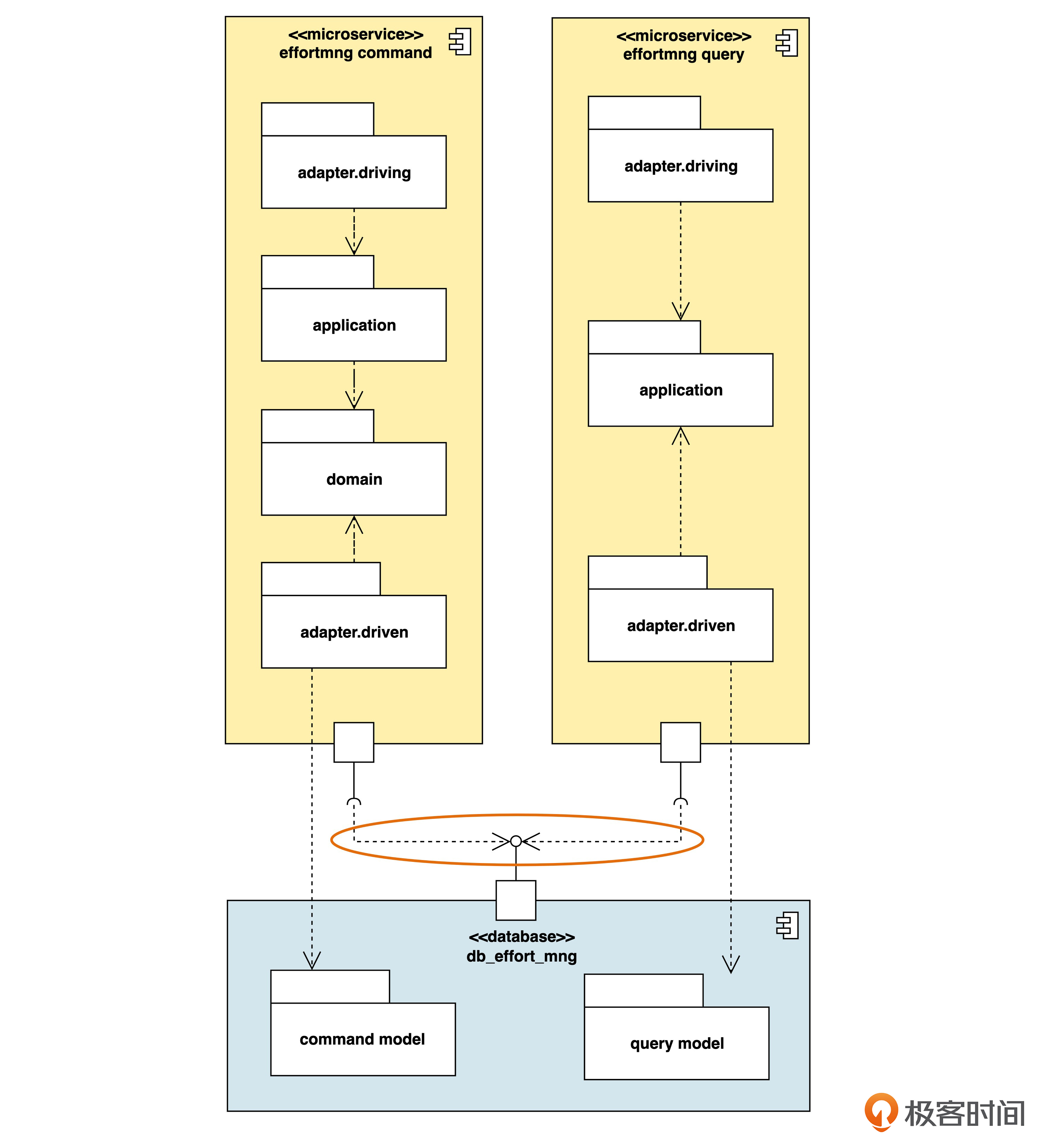
在之前的组件图里,供给接口和需求接口是直接相连的。而这里使用了表示依赖的线。这两种方法都可以。如果供给和需求接口离得比较远,或者像这张图一样,两个需求接口共用一个供给接口,就可以采用依赖的形式来描述。
应用服务分离策略的好处是容易横向扩展,代价则是微服务的数量增加了,相应的运维和治理成本也就随之增加了。
数据库实例分离
在上面的例子里,微服务分开了,但是数据库实例并没有分开。虽然通过微服务的横向扩展,可以解决由于应用程序造成的性能瓶颈,但是如果性能瓶颈是由数据库引发的,那么拆分微服务的策略就无法解决问题了。这时候,就可以考虑“数据库实例分离”的策略了。
数据库实例分离的架构图是后面这样。
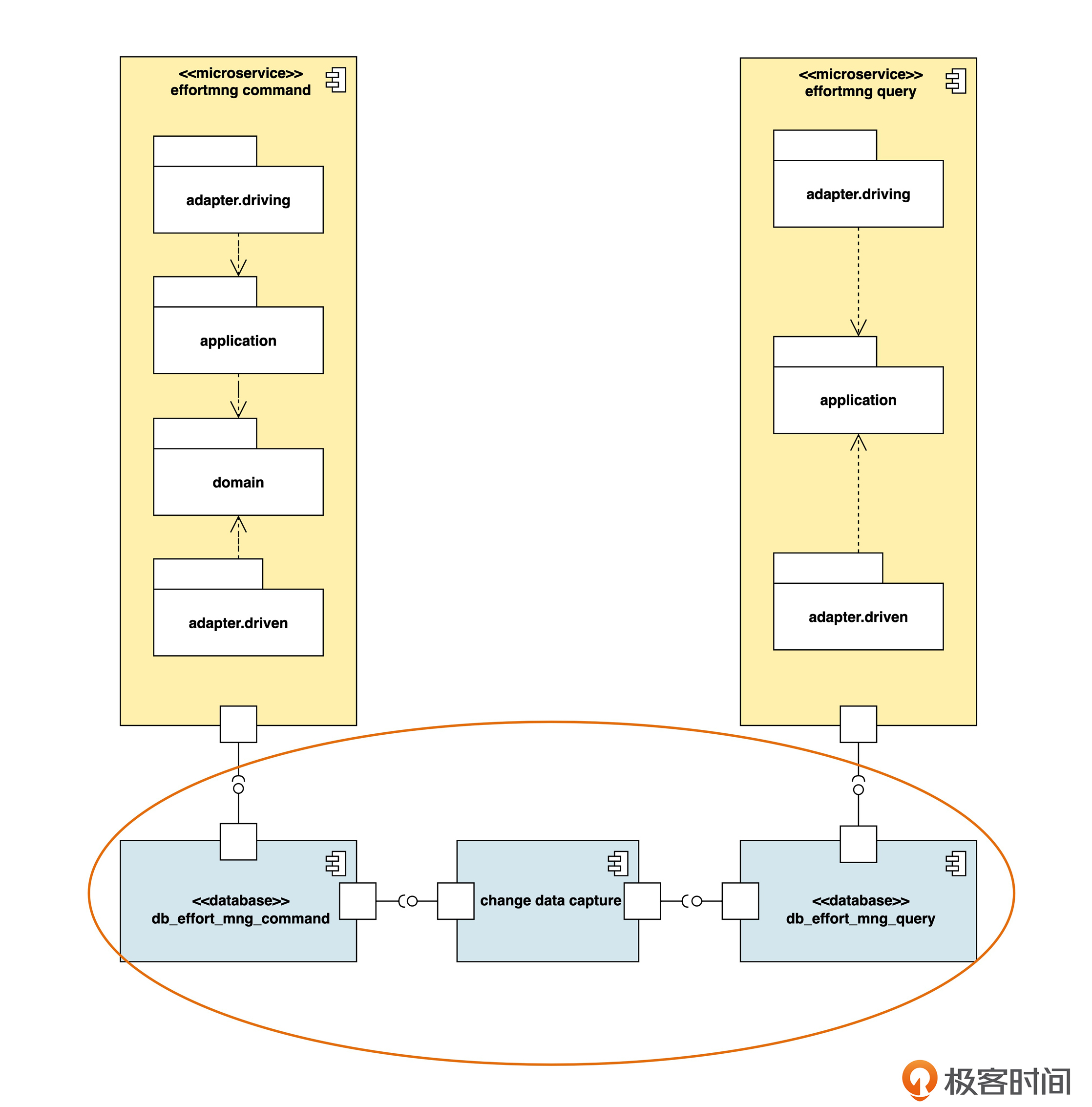
采用这种策略时,我们把数据库实例也分成了两个,分别用于命令和查询两种数据模型。
数据库之间用“变更数据捕获”(change data capture, 简称 CDC)机制来同步。目前有多种开源或商业的方案可以选择。多数方案的原理都是由命令模型的数据库日志的变化来触发,然后同步到查询模型的数据库。
除了通过数据库底层机制来同步数据以外,我们还可以在应用程序层面同步数据。

上面的架构图中,我们又使用了一个自定义的衍型 <<event>> ,表示当工时记录已创建、工时记录已更改和工时记录已删除三个领域事件发生时,这三个事件会被发送到消息队列(message queue)。之后,订阅了这些事件的服务就会被触发,然后进行相应的处理。在这个例子中,相应的处理就是指对数据的同步。
数据库实例分离以后,查询模型库就未必是关系型数据库了,我们可以选择 NoSql 数据库、内存数据库或其他数据存储技术。
数据库实例分离策略的好处是查询数据库可以横向扩展,可以灵活地选择数据存储机制,比较容易解决数据库造成的性能瓶颈。代价是增加了数据同步的复杂性,数据同步的延迟也可能会更高。
各种策略的组合
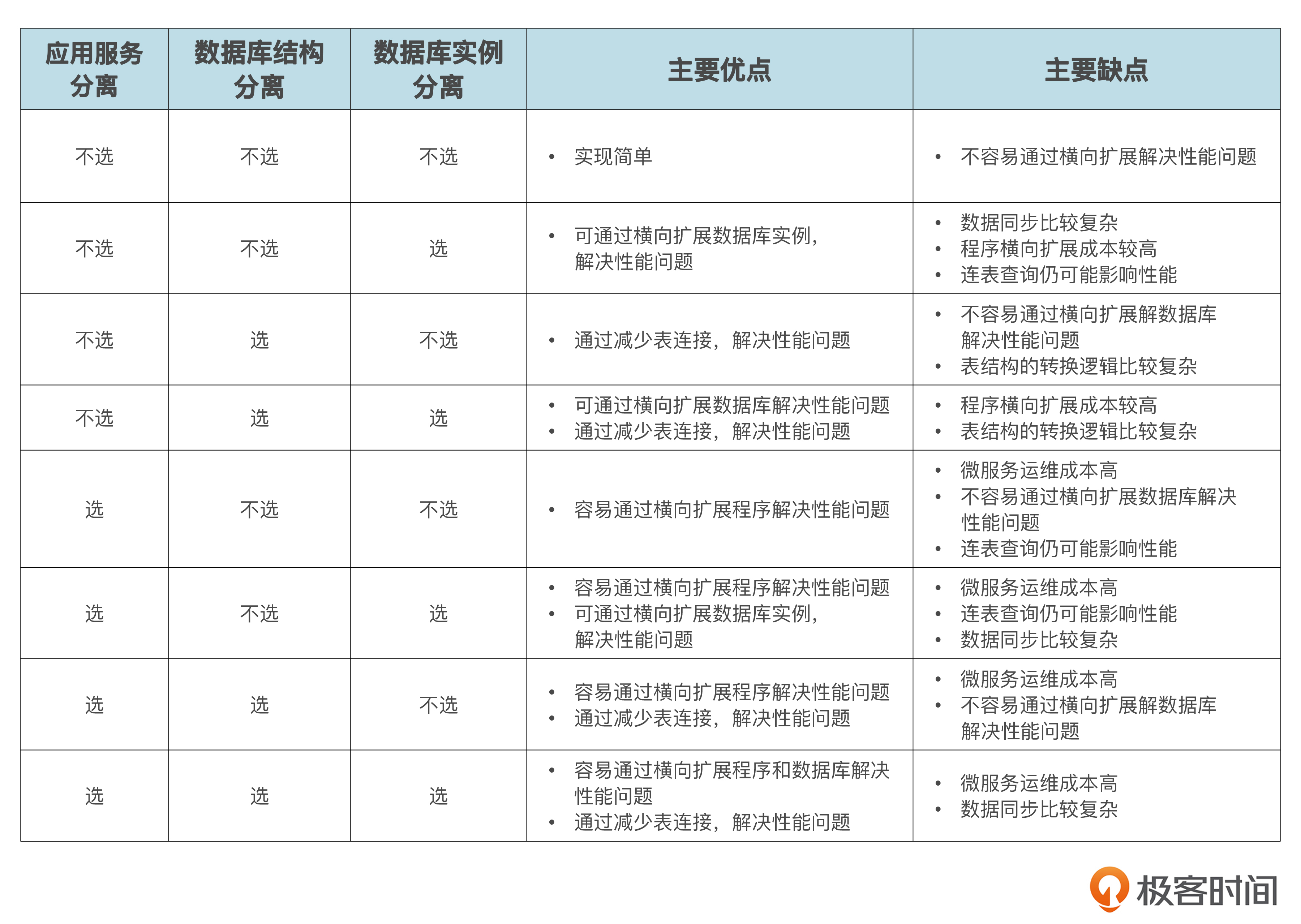
到现在,我们学习了 CQRS 四个层面的策略,分别是“代码结构分离”“数据库结构分离”“应用服务分离”和“数据库实例分离”。其中,“代码结构分离”是其他几种策略的基础,一般来说对于 CQRS 是必选的。
而其他三种策略都是可选的。而且,虽然咱们讲课的时候是按照层层递进的方式讲的,但其实这三种策略之间并没有依赖关系,你可以根据情况灵活组合使用。你可以先想想,一共有多少种组合,各自的优缺点是什么。
由于一共三种可选策略,每种都有使用和不使用两种选择,所以一共就可以有 8 种组合。我帮你梳理了一张策略选择表,列出了 8 种组合的主要优缺点。
为了实现命令进行的查询
最后,我再说一个微妙的问题。前面说命令和查询分离,给你的感觉可能是所有的数据库查询,都要绕过领域模型吧?
其实,有一种查询一般来说不会绕过领域模型,这种查询就是“为了实现命令而进行的查询”。比如说,修改员工信息,相应的应用服务可以经过后面这四个步骤。
第一步,把这个员工聚合从数据库里查询出来。
第二步,进行校验,看看是否符合修改的条件。
第三步,在内存中对员工聚合进行修改。
第四步,把修改的员工聚合存回数据库。
这里面的第一步,就是为了实现命令而进行的查询。这种查询,一般仍然要在命令处理器内部做,而不是在查询处理器中完成。
这是因为,这种查询的目的就是查出领域对象,然后进一步执行领域逻辑。而查询模型中的表结构可能已经按照查询的要求进行了反规范化,返回结果也是DTO而不是领域对象,这时候,转换回领域模型反而会更麻烦了。
这个问题,我们也可以从另一个角度来理解。CQRS 中的 Q(查询),指的其实是来自客户端的意图。也就是说,客户端的目的就是查询,才算是 CQRS 里的 Q,如果客户端的目的是增、删、改,在这个过程中发生的查询,一般不算是 CQRS 里的 Q。
总结
好,这节课的主要内容就讲完了,下面来总结一下。
今天我们学习了 CQRS 的另外两种策略,“应用服务分离”和“数据库实例分离”。我们还需要了解每种策略的优点和代价,这样才能结合项目实际情况,选择适合的策略。
对于 CQRS 来说,“代码结构分离”是必选的,其他几种则是可选的,并且相对独立,可以根据情况组合使用。 我们用表格总结了 8 种组合的主要优缺点。
另外,我们还讨论了“为了实现命令而进行的查询”其实不算 CQRS 里的 Q,而是应该在命令处理器中处理。不要小看了这个问题,虽然只是个细节,但也给不少小伙伴的实践带来过困扰。
学习了CQRS这两节课以后,不知道你的收获如何?之后,如果再有人对 CQRS 有不同意见,你就不要和他笼统地谈,而是问他,他所理解的是哪个层面的 CQRS。然后,根据他实际所指的含义来进行讨论,这样就比较容易达成一致了。
下节课,我们来聊聊怎样用分析模式解决更加复杂的建模问题,敬请期待。
思考题
最后给你留两道思考题。
1.其实我们之前还提出了另外两个需求。一个需求是给定一个时间段,可以看到某员工在这个时期内各个工时项的累计工时信息;另一个需求是,给定一个项目,可以看到这个项目下各成员的累计工时信息。你觉得可以有哪些方法实现这两个需求呢?
2.你以前是否用过 CDC 工具,可否分享一下你的使用经验,比较一下不同 CDC 工具的特点?
好,今天的课程结束了,有什么问题欢迎你在评论区留言,下节课再见。
- aoe 👍(8) 💬(5)
“为了实现命令而进行的查询”其实不算 CQRS 里的 Q,而是应该在命令处理器中处理,这点提醒的太及时了,不然不知道什么时候才能从迷惑中走出来
2023-03-03 - Fredo 👍(4) 💬(2)
1. 如果查询比较简单,是不是可以直接走领域模型,而不用 Q 2. 搜索场景,canal 增量同步 ES;flink CDC 同步到数仓
2023-03-02 - 黑夜看星星 👍(1) 💬(2)
老师,请教数据库结构分离和数据库实例分离的区别
2023-08-28 - 你来吧 👍(1) 💬(3)
手把手教你落地DDD的源代码在哪里呢
2023-03-22 - NoSuchMethodError 👍(0) 💬(2)
比如领域服务中需要查询list,list中的item是聚合根,且只需要item中的部分属性,那么还需要挨个重新生成聚合根嘛
2023-04-24 - 胡昌龙 👍(0) 💬(1)
钟老师,如果一个聚合如营销补贴计算。需要用到同一限界上下文里的另一个聚合 如营销补贴规则。考虑到性能,此时希望从数据库只查询出补贴规则的局部属性,是建一个新的值对象类来接收并参与运算,还是使用原来的补贴规则聚合对象类,只是对局部属性赋值呢(感觉模型重建就不完整啦)?假设新建值对象类,那如果有多种计算场景,需要用到不同的补贴规则局部属性,这样会导致建出很多的类来,这些个类放在哪里又比较合适?
2023-04-15 - 胡昌龙 👍(0) 💬(1)
钟老师,如果一个聚合如营销补贴计算。需要用到同一限界上下文里的另一个聚合 如营销补贴规则。考虑到性能,此时希望从数据库只查询出补贴规则的局部属性,是建一个新的值对象类来接收并参与运算,还是使用原来的补贴规则聚合对象类,只是对局部属性赋值呢(感觉模型重建就不完整啦)?假设新建值对象类,那如果有多种计算场景,需要用到不同的补贴规则局部属性,这样会导致建出很多的类来,这些个类放在哪里又比较合适?
2023-04-14 - 胡昌龙 👍(0) 💬(1)
钟老师,如果一个聚合如营销补贴计算。需要用到同一限界上下文里的另一个聚合 如营销补贴规则。考虑到性能,此时希望从数据库只查询出补贴规则的局部属性,是建一个新的值对象类来接收并参与运算,还是使用原来的补贴规则聚合对象类,只是对局部属性赋值呢(感觉模型重建就不完整啦)?假设新建值对象类,那如果有多种计算场景,需要用到不同的补贴规则局部属性,这样会导致建出很多的类来,这些个类放在哪里又比较合适?
2023-04-14 - 杰 👍(0) 💬(2)
老师,如果是应用和数据库都不分离的情况,用cqrs是不是可以理解为我直接跟以前一样,使用表关联查询就行?
2023-04-12 - 6点无痛早起学习的和尚 👍(0) 💬(2)
思考题: 1. 需求一:没有说清楚累计工时信息是不是 累计工时时间? 直接 select effort_item_id,xxx effort_record where emp_id = xxx and 时间区间 group by effort_item_id 需求二:把项目表、工时项、工时记录表 join 越到后面,留言越少
2023-02-28 - 胡昌龙 👍(0) 💬(0)
钟老师,如果是一个聚合(如营销补贴计算)的命令,用到同一个限界上下文另一个聚合(营销补贴规则)的查询,此时考虑到性能,希望只从数据库查询出部分补贴规则的属性,此时是创建新的补贴规则值对象,还是直接重建出带有部分属性的补贴规则聚合呢(感觉模型重建不完整)?假设创建新的值对象,那如果有多种补贴计算场景需要用到不同的补贴规则局部属性,就可能建出很多新entity出来,这些个类又放在哪里合适?感谢 备注:
2023-04-14 - 胡昌龙 👍(0) 💬(0)
钟老师,如果一个聚合(如营销补贴计算)的命令逻辑,需要用到另一个聚合(如营销补贴规则)里面的少部分字段,因为并发量较高,考虑到性能希望只从数据库查询出部分字段,而不是重建整个补贴规则聚合出来,这时怎么处理合适?如果有多种补贴计算场景分别需要不同的补贴规则局部属性,是分别创建多个补贴规则的值对象,还是都用补贴规则这个领域模型实体(也就是同一个实体类),只是每次只赋需要的那几个字段的属性(感觉只重建了部分,会带来模型不完整的问题)? 备注:是命令计算里的q哈,只是q了另一个关联紧密的聚合而已
2023-04-14