如何实现消息保序?
你好,我是李玥。
我看到有不少留言是关于“如何实现消息保序”的问题。关于这个问题,我在答疑中做了简单的回复,但限于篇幅并没有很深入。借助这次加餐的机会,我来深入地、一次性地把各种场景下如何实现消息保序的方法梳理清楚。
我们也会讨论在工程实践中,这些实现消息保序方法存在哪些限制、可能会遇到哪些问题,以及如何应对上面这些限制和问题,如何根据实际的业务场景,权衡一致性、可用性,做出取舍,实现相对的最优解。
哪些场景需要消息保序?
消息保序问题指的是,在通过消息中间件传递消息过程中,我们希望消费者收到消息的顺序,和发送者发送消息的顺序保持一致。或者说,消息中间件在传递消息时,不要改变消息之间的顺序。
不过在工程实践中,我们面临的保序问题不一定只是局限在消息保序这一个环节,更常见的场景是,事件经过包含消息队列等多个环节的处理和传递后,在某个服务内能够按照事件发生的顺序来逐个处理这些事件,不发生乱序。比如:
- 在证券、股票交易撮合场景中,对于出价相同的交易单,需要坚持按照先出价先交易的原则,下游处理订单的系统需要严格按照出价顺序来处理订单。
- 在数据库变更增量同步场景中,上游源端数据库按需执行增删改操作,将 BINLOG 作为消息,通过消息队列传输到下游系统,下游系统按顺序还原消息数据,实现状态数据有序更新。
- 在电商系统中,订单创建、支付、退款、物流等消息需要按照顺序处理,才能保证订单状态的正确更新。
- 在交易支付场景中,需要确保消息的顺序性和一致性,以满足金融领域对数据准确性的严苛要求。
如何实现消息保序?
有些消息队列其设计就是基于队列来实现的,比如 RabbitMQ。
我们知道队列的特性就是先进先出,天然就是有序的,使用这种“基于队列来实现的消息队列”传递消息,自然就可以实现消息保序。
但是为了实现高吞吐,更多的消息队列在设计上采用的是多分区或多队列的实现,比如 Kafka 或 RocketMQ 。这些消息队列在处理消息时,会将消息按照一定的策略分发到多个分区上并行处理,也就无法保证消息的有序性了。
如果我们希望在多分区的消息队列上实现消息保序,可以将分区数量配置为 1,这样就可以实现和单队列消息中间件一样的保序效果了。
此外,为了保证在消费者端消息的有序性,消费者也只能单实例单线程来消费消息,才能保证全流程消息是严格有序的。
以上就是全局消息保序的实现方法,这种方法的实现思路其实就是全局串行处理。我们知道,串行处理有一个很大的弊端,那就是消息吞吐量有限,也没法通过水平扩展来提升消息吞吐量。在规模比较大的场景下就显得力不从心了。
我们会发现,大多数需要消息保序的场景并不需要消息“全局有序”。多数场景下,我们只需要保证有业务关系的消息之间的顺序就可以了,没有业务关系的消息之间的先后顺序,其实是无所谓的。
可以看一下本节课中列出的几种场景,交易撮合场景下,只要保证同一支股票的交易单的下单顺序,不同股票的交易单没有任何关系,也就不需要保序。电商系统中的订单和支付单,只需要保证同一单号内的消息有序就可以了。
只有数据库 BINLOG 同步这个场景,因为数据库事务的存在,我们没有办法把 BINLOG 归并到数据库表上,也就无法判断 BINLOG 消息的关联性,这种情况下必须实现全局保序,才能保证数据同步的正确性。
将保序要求从全局放宽到局部,就可以充分利用多分区消息队列的并发能力来提升消息吞吐量了。
实现的思路是这样的,既然我们只需要保证有关联的消息之间的顺序,那么只要把关联的消息都发送给同一个分区处理,而分区内天然就可以保证消息的处理顺序,这样就实现了消息局部保序。下面举个例子来说明。
比如,我们用一个 4 分区的主题来处理订单消息。可以采用哈希算法将订单消息按照订单号的后两位均匀地分配到 4 个分区上。
也就是,将订单尾号 00-24 的订单发给 0 号分区,25-49 尾号的订单分给 1 号分区,50-74 尾号的订单发给 2 号分区,剩余的发给 3 号分区。这样就可以保证同一个订单的消息总是分配相同的分区,也就实现了订单内消息保序。
多数消息中间件都内置了相应的功能来帮助我们快速实现局部消息保序。
以 Kafka 为例,Kafka 的 API 支持在发送消息的时候指定一个消息的 Key,并且内置了默认的哈希算法将 Key 映射到主题的分区上,保证具有相同 Key 的消息总是会被发送到同一分区,从而实现了消息局部保序。在上面例子中,可以直接使用订单号作为消息的 Key,示例代码如下:
// 订单消息
OrderMessage orderMessage = createOrderMessage(...);
// 订单号,作为Key
String orderId = orderMessage.getOrderId();
// 创建ProducerRecord对象,指定Key和Value
ProducerRecord<String, String> record = new ProducerRecord<>("order-topic", orderId, orderMessage);
// 发送消息
producer.send(record, (metadata, exception) -> {
if (exception != null) {
System.out.println("Error while sending message: " + exception.getMessage());
} else {
System.out.println("Message sent to partition " + metadata.partition() + " with offset " + metadata.offset());
}
});
保序消息的常见问题和应对策略
以上就是实现消息保序的方法。工程实践中,这种需要保序的消息系统可能会遇到一些共性的问题,接下来我把这些常见的问题和应对这些问题的常规解法分享在这里。
1. 重复消息
首先我们先来讨论重复消息的问题。我们知道,市面上绝大多数消息队列产品都只能支持“至少一次”的可靠性,换句话说,不能保证消息不重复。需要消费者在处理消息逻辑支持幂等性,来兼容消息重复的问题。
而绝大多数需要消息保序的场景是无法实现幂等消费的,因为如果消费逻辑可以支持幂等性,那也就不需要消息保序了。为了避免重复消息导致的乱序,可以想办法在消费端跳过重复的消息。
一种方法是,在消息中携带一个单调递增的消息序号。这个序号可以利用消息数据本身的业务属性,比如订单表中每个订单的版本号,也可以让消息生产者在发消息的时候生成消息序号。消费者可以通过这个序号来判断收到的消息是否是重复消息。
具体的实现逻辑是,消费者每处理一条消息,就记录这条消息的序号,然后比对后续收到的消息的序号,根据消息序号单调递增这一特性,正常的消息序号一定比记录的消息序号大,否则就可以判断为重复消息。对于重复消息的处理方式,简单丢弃就可以了。
还是以处理订单消息为例,以下是消费者判断重复消息的实例代码:
private final int currentMaxSequenceNumber = 0; // 记录当前处理的最大消息序号
public void consume() {
consumer.subscribe(Collections.singletonList("order-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, OrderMessage> record : records) {
OrderMessage message = record.value();
long sequenceNumber = message.getSequenceNumber();
// 检查消息序号是否重复
if (sequenceNumber > currentMaxSequenceNumber) {
// 处理消息
processMessage(payload);
this.currentMaxSequenceNumber = sequenceNumber; // 更新最大消息序号
} else {
// 丢弃重复消息
logger.warn("Duplicate message detected. Sequence number: {}", sequenceNumber);
}
}
}
}
如果没有条件在消息中携带消息序号,也可以在消费端维护一个集合,记录最近一段时间已经消费的消息 ID,然后比对收到的新消息的 ID 是否在这个已消费消息 ID 的集合中,如果存在就说明是重复消息。
应用这个方法时,有些技术细节需要注意。
首先,这个“存放已消费消息 ID 的集合”的容量上限应该是固定的,并且需要根据实际情况设置一个合理的值。
容量过大不仅占用更多内存空间,还会导致每次在查找集合花费的时间过长,拖慢消费速度。容量过小,就不能过滤那种延迟时间较长的重复消息。合适经验值是缓存大约几分钟~几十分钟的消息对应容量。
其次,记录已消费消息 ID 的去重方法并不能百分之百地保证消息不重复,如果重复消息来得太晚,比如,在某些特殊情况下我们需要重置消费位点。这种情况下,已消费消息的集合中对应的消息 ID 已经被逐出,就没法识别并过滤重复消息了。
综合来看,这个方法虽然设计上不够优雅,极端情况下也不能保证消息不重复,但足以应对绝大部分重复消息情况,并且适用的业务场景广泛,当其他方法都不适用时,可以作为过滤重复消息的兜底选择。
2. 节点故障
接下来我们学习在节点故障情况下,如何尽量保证消息顺序。
如果消息生产者发生故障,这时消息都发不出来,这种情况可以不用考虑保序问题。消息队列的 Broker 节点故障时,可以依靠消息队列自身的高可用机制,消息队列会自动切换到备用的 Broker 节点。
Broker 在主备切换过程中,会出现短时间的不可用,可能会产生一些重复消息,除此之外对消息的顺序没有影响,也可以不用考虑。但如果消费者节点发生故障,就可能会导致消息乱序的情况发生。
正常情况下,消息队列会维护一个分区与消费者节点之间的绑定关系,这样同一个分区的消息总是由相同的消费者实例来消费。
如果一个消费者实例绑定了多个分区,消费者内部还会维护一个分区与消费线程的绑定关系,确保同一个分区总是由一个固定的消费线程来消费。
总体上来看,就是每个分区对应一个固定的消费线程,每个分区都是单线程串行消费的模式,这样就实现了消息的保序消费。当消费者节点发生故障时,消息队列会重新分配分区与消费者的绑定关系。
因为这个重新分配的不是一个原子操作,这个短暂切换过程中,会出现短时间一个分区对应新旧两个消费者实例的情况,这时消息由串行消费变成了并行消费,就有可能出现消息乱序。好在这种乱序只出现在重新分配过程中,一旦完成重新分配建立了新的绑定关系,之后的消息仍然可以保序。
对于这个问题,技术上没有特别完美的应对手段,实践中可以用一些方法来缓解。考虑到消费者节点故障发生的概率并不高,而且乱序只发生在切换过程的短时间内,通常影响的数据量有限。如果对数据时效性要求没那么高,可以考虑事后修复乱序导致的数据错误。修复数据的方法可以是回放这部分消息,或者依据业务逻辑来执行修复,这里就不具体展开了。
事后修复需要注意两个问题,第一是要建立监控告警手段,第一时间能够发现分区重新分配事件。第二就是要提前准备好数据比对和修复的工具,一旦出现乱序就可以快速修复。
如果业务场景不能接受事后修复乱序消息,可以考虑在消费者端自行维护分区与消费者实例关系。
设计思路是这样的,在数据库中建立一张表,维护分区与消费者实例之间的对应关系。消费者在消费消息时,采用指定分区消费的方式,消费自己负责的分区。
用健康检查或心跳机制监控每个消费者实例,如果发现消费者实例故障,先把故障实例销毁,再重新创建一个新实例替换掉故障实例,避免重新分配分区操作,达成了消费者故障时也能保序的目的。
需要注意的是,这种自行维护绑定关系的方式虽然优雅,但实现起来,需要考虑的各种情况很多,实现复杂度非常高,能完整正确地实现出来难度很大。除了那些对消息顺序和实时性都及其敏感的场景外,都不建议使用。
3. 分区扩容
随着消息量增长,我们会遇到分区数量不够用,或者消费者实例数不够的情况,这两种情况下都需要增加主题的分区数量,来提升主题的总体吞吐量。
对于部分有序的消息主题来说,扩容分区带来的一个副作用是,扩容后不得不重新分配消息 Key 与分区的映射关系,以及分区与消费者实例的绑定关系,这两个重新分配的过程,都可能导致消息乱序。
解决这个问题的思路是,想办法避免扩容期间的并行处理消息,最好是选择在消息低峰期进行扩容操作,扩容前先在生产者端暂停消息生产,然后等待消息队列中的消息都消费完。
这时候,整个消费流程处于暂停状态,就可以开始扩容分区的操作了。等分区扩容完成后,再恢复消息生产,这样就避免了扩容过程中并行处理,也就避免了消息乱序。
有些情况下,消息生产者没有地方暂存消息,不具备暂停生产的能力,可以考虑使用替换主题的方法实现保序扩容。
首先新建一个主题,这个主题的分区数量就是扩容后分区的数量。然后让生产者从旧主题切换到新主题。消费者这边,先把旧主题的消息都消费完成后,再切换到新主题继续消费。之后,旧主题就可以销毁下线了。这个新旧主题的切换过程如下图所示:
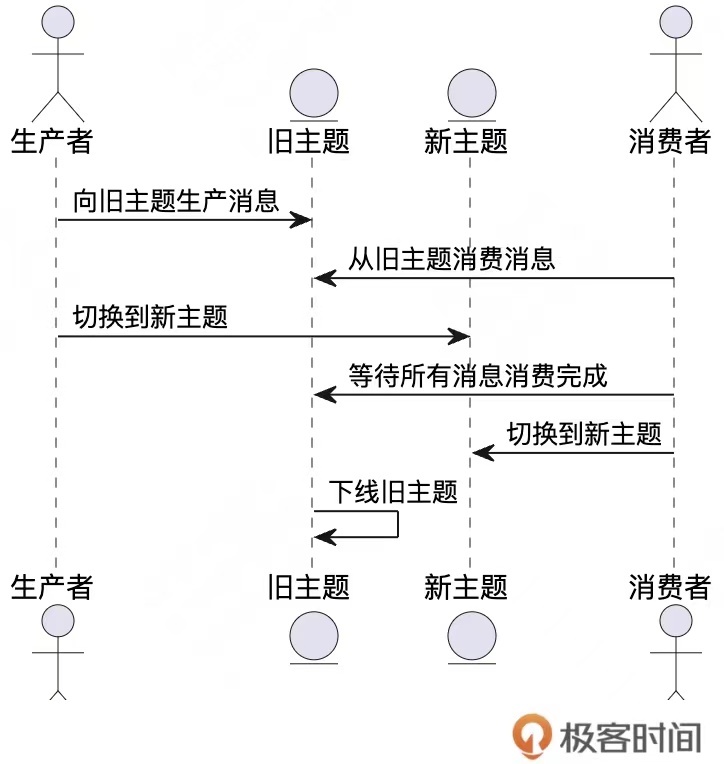 这种方法的关键在于消费者在切换到新主题之前,必须确保旧主题的消息已全部消费完毕。
这种方法的关键在于消费者在切换到新主题之前,必须确保旧主题的消息已全部消费完毕。
小结
以上就是这节课的全部内容了,照例我们来做个小结。这节课我们主要讨论了消息保序的实现方法和工程实践中可能遇到的问题以及对应的解法。
我们可以采用单分区串行处理方式,来实现全局保序,但这种方式系统吞吐量有限。更实用的做法是实现局部保序,即只保证有业务关联的消息之间的顺序。
局部保序可以通过将关联消息分配到同一分区来实现。比如 Kafka 提供了通过消息 Key 来实现消息路由到固定分区的机制。
实践中,对于重复消息问题,可以通过消息序号或维护已消费消息 ID 集合来过滤重复消息。对于因为消费者节点故障而出现的乱序问题,可以通过事后修复或自行维护分区与消费者的绑定关系来应对。
针对分区扩容出现的消息乱序问题,建议在低峰期暂停生产后进行扩容,或采用新旧主题替换的方式来实现。
实现消息保序时要根据具体业务场景,在保证必要的顺序性的同时,权衡可用性、性能和复杂度来选择合适的方案。
思考题
在课后思考题环节,这里再介绍一种比较通用的保序实现方法。这种方法实现稍微有些复杂,但适用性比较好,不仅可以用在消息保序场景,其他分布式系统中需要保序的场景都可以考虑使用这种方法。
这种方法的设计思路是这样的,在消息生产端为每条消息注入一个消息序号,要求这个序号是连续递增的。例如,某条消息的序号是 n,那下一条消息的序号就是 n+1,依此类推。
在消费端,维护一个消息缓存,所有收到的消息先进入缓存,在缓存中对乱序的消息进行重新排序,再消费排序后的消息,通过对消息重排序实现保序。
请你想一下,这种重排序的方法存在哪些限制,或者说在什么情况下这种方法就不适用了?在实现重排序时,有哪些异常情况需要考虑,如何处理这些异常情况?
欢迎在留言区写下你的想法,我们下节课公布答案。
- Geralt 👍(1) 💬(0)
思考题的一些想法: 1. 需要有一个发号器确保消息序号的连续递增 2. 存在单点限制,同一时间只能由一个进程进行排序 3. 排序操作的时间间隔如何确定?间隔太长会影响消息的时效性,太短会频繁执行排序操作 4. 进行排序时,缓存中的消息序号不一定是全部连续的,可能存在断层,会导致部分消息无法被及时消费 5. 消费消息前,需要检查之前的消息是否已经消费成功,确保消费消费的顺序是正确的,但是会增加性能消耗 6. 缓存可能出现故障,导致无法进行排序
2024-12-16 - 蝴蝶落于指尖 👍(1) 💬(0)
老师要不要补充一下,Kafka 的默认设置下其实不能百分百保证分区保序,在 Kafka 的文档中对 max.in.flight.requests.per.connection 的参数说明了默认配置在发生 retry 的时候可能乱序。
2024-12-12 - 木几丶 👍(0) 💬(1)
老师你好,如果在消费者升级过程中,造成消费者重平衡,是否会造成乱序?这种应该比较常见,如何解决呢?
2024-12-12