Kafka如何保证配置下发的一致性?
你好,我是李玥。
我们这个课程讲解消息队列实现原理的内容,大多集中在数据面上,控制面的相关知识涉及较少。在这次加餐中,我会把这部分内容补充完整。
这节课中,我会带你一起分析 Kafka 的源代码,看一下 Kafka 是如何实现主题创建的。更重要的是,通过学习 Kafka 的实现方法,提炼并总结出在分布式系统中,保证配置下发一致性的方法。
分布式系统的控制面与数据面
任何一个分布式系统都可以按照功能划分为控制面与数据面。
数据面,可以理解为“业务数据流经的部分”,负责数据流入流出、执行业务逻辑处理数据和存储数据。控制面,顾名思义,管理控制集群的功能都被划分到控制平面,业务数据不会流经到控制面。控制面的主要功能包括:存储集群元数据、指导数据面路由、下发配置和策略以及实现集群高可用等。
以消息中间件为例说明。数据面包括生产者、Broker 和消费者。这些都是消息数据流经的组件,都属于数据面。
- 生产者:负责发消息。
- Broker:负责接收、存储和分发消息。
- 消费者:负责接收消息。
控制面的功能包括:元数据存储、消息路由、集群管理、高可用、选举、认证等功能。
- 元数据存储:负责保存集群主题、分区和副本以及集群配置等元数据。
- 消息路由:指导生产者将消息发送给特定的 Broker 节点,指导消费者从特定的 Broker 节点获取消息。
- 集群管理:负责主题创建、修改和删除,管理集群中的生产者、消费者和 Broker 节点。
- 高可用:监控集群节点的健康情况,必要时执行主从切换。
- 选举:负责集群内各种主节点选举,比如主副本选举等。
- 认证:负责管理用户的认证和权限控制,确保只有授权的用户才能访问特定的资源。
总体来说,集群的数据面负责实现系统的核心业务功能,控制面作为辅助角色,负责管理和控制数据面。
创建主题的过程和实现难点
在学习创建主题的实现过程之前,我们先回顾一下 Kafka 中主题的数据结构。
在 Kafka 中,主题是收发消息的单元,一个主题下面包含多个分区,我们可以把分区理解为一个中转消息的串行队列,多个分区就可以提升主题的并行度,通过水平扩展来提升消息的吞吐能力。
每个分区物理上由多个副本构成,这些副本被分散到不同的 Broker 节点上。同一个分区的多个副本拥有相同的消息数据,它们通过选举产生一个主副本,负责消息收发。
从副本从主副本实时同步消息数据,但不提供任何服务,它的作用是保证高可用和一致性。当主副本所在的 Broker 宕机时,Kafka 会从可用的从副本中选举出新的主副本继续提供服务。
在 Kafka 集群中创建主题是一个比较复杂的流程,简单来说创建一个新的主题,需要完成如下主要步骤:
- 创建并保存主题、分区和副本这些元数据。
- 将分区的副本分配给集群中的多个 Broker。
- 每个 Broker 在本地创建分区副本的消息和索引文件。
- 为每个分区选举主副本节点。
在分析 Kafka 源码之前,你可以想一下,如果是我们来实现这个功能,我们会如何设计这个主题创建流程?大多数人都会按照常规的思路来这样设计。
我们会有一个中心化的管理节点来负责按顺序执行每个步骤,检查执行结果,并负责错误处理。
比如,如果从命令行发起,这个命令行程序就可以作为这个管理节点;如果从 Web 管理平台发起,这个 Web 管理平台的服务端也可以作为这个管理节点。或者也可以有一个集群管控服务,负责接收各种终端的命令,统一执行。
管控节点收到创建主题命令后,首先要获取集群中各 Broker 的状态信息,再根据一定的策略计算出主题的分区副本应该如何分配,然后给各 Broker 发送创建分区副本的请求,等待各 Broker 将分区副本创建好。
再然后为所有新建的分区发起选举,等待全部分区选举完成。最后,将主题、分区和副本这些元数据保存到 ZooKeeper 中,再通知集群各种节点更新元数据和状态。这时新主题创建完成,给发送创建主题请求的调用方返回创建成功。
以下是上述流程的时序图:
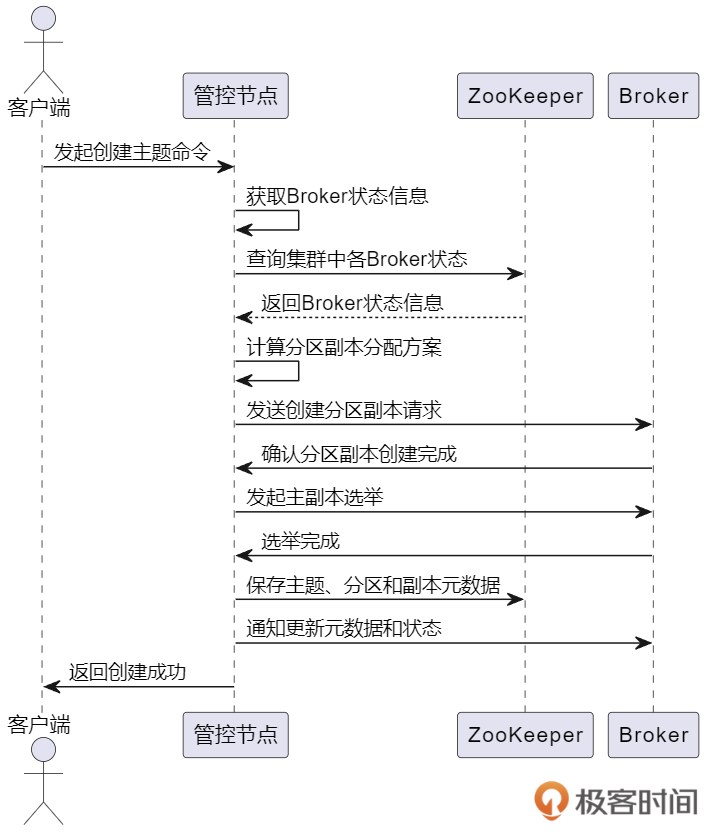
为了简化流程便于理解,上图中只绘制了一个 Broker,通常创建主题需要和多个 Broker 通信。
以上就是创建主题的实现流程,这个流程虽然可以实现功能,但是有一些异常情况会比较难处理。
比如说,执行上面这些步骤中如果某个步骤执行失败了,应该如何处理?
我们可以通过重试来缓解这个问题。
然而,这个创建主题过程的大部分步骤都是变更操作,如果增加重试逻辑,就需要相应地修改每一个变更操作步骤的实现逻辑,让每个可能重试的变更步骤都具备幂等性。
因为需要同步给用户返回主题创建的结果,为了避免总体流程超时,重试次数不能太多,重试间隔时间不能过长。所以,重试只能解决网络丢包导致的请求失败这类问题。
对于像Broker 节点故障这种情况,短时间内几次重试也不会成功。这种情况下,只能给用户返回创建主题失败的响应。如果主题创建失败,还需要将创建流程中已经执行的步骤逐一进行回滚。也就是说,我们需要为每个步骤都编写相应的回滚的逻辑。如果回滚失败了如何处理,也是另外一个比较难解的问题。
再比如,如果在执行过程中,执行流程所在的管控节点宕机了,应该如何处理?
虽然我们可以让本次创建主题的命令执行失败,但是仍然需要清理执行到一半的流程,回滚所有已执行的操作,将系统各节点都恢复到之前的状态。
为了实现这些清理,我们需要管控节点在一个外部存储中记录并实时更新流程的执行状态,以便事后去回滚已执行的步骤,恢复系统状态。
还有一个比较难处理的情况是,如果执行的步骤比较多或者某些步骤比较耗时,所需的总体执行时长就会很长。对于发起命令并等待执行结果的前端来说很可能会超时,这会出现前后端对命令执行结果的认知不一致。无论是前端下发命令的程序,还是后端执行命令的管控节点,对这种超时的情况都不太好处理。
Kafka 如何实现创建主题的过程?
接下来我们看一下,Kafka 是如何实现创建主题过程的,以及 Kafka 是如何解决上述难题的。
在 Kafka 中,参与创建主题的模块包括:AdminClient、Controller、ZooKeeper 和 Broker。其中 AdminClient 负责通过命令行与用户直接交互,并将创建主题的命令发送给 Controller。
Controller 职责类似于上面我们提到的中心化管理节点,负责协调整个创建流程并管理元数据变更。ZooKeeper 负责存储元数据。Broker 负责执行实际的分区副本创建操作。
总体的主题创建流程如下图所示:
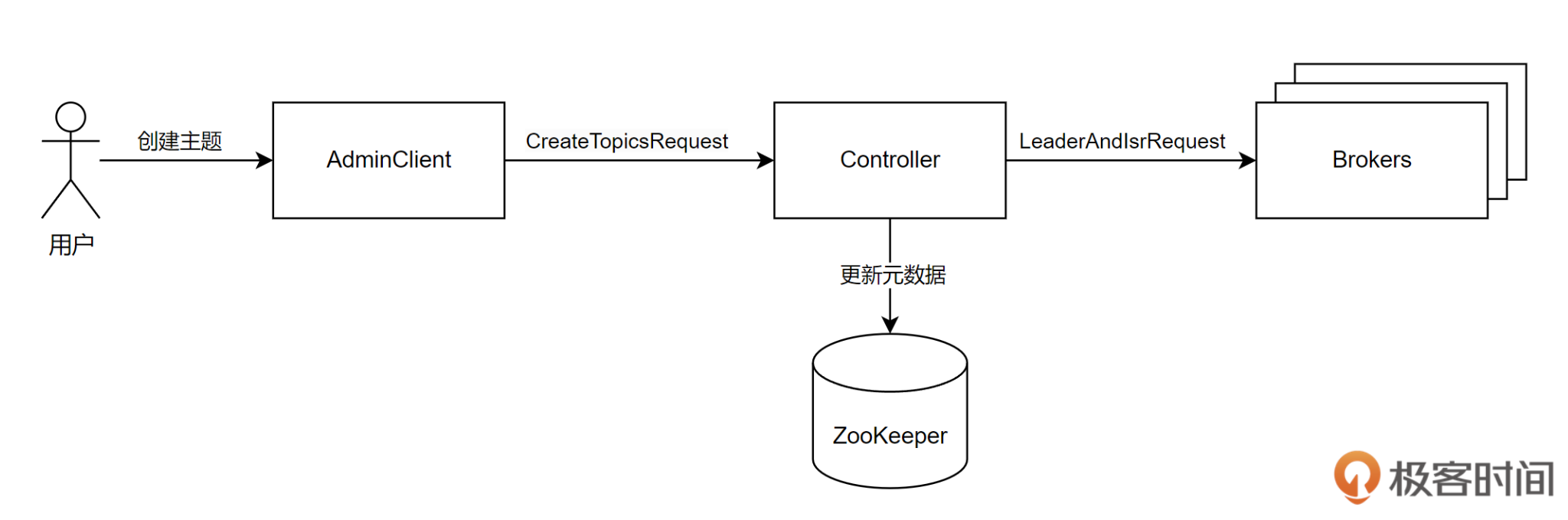
接下来分步骤看一下具体的实现过程。
当用户调用 kafka-topics.sh 创建命令后,kafka-topics.sh 调用了 AdminClient 来执行客户端创建逻辑。
AdminClient 的逻辑很简单,先检查用户输入是否合法,然后根据用户输入构建一个创建主题的请求 CreateTopicsRequest,这个请求中的主要信息包括:主题名称、分区数量、副本数量和其他一些配置信息。AdminClient 将构建好的 CreateTopicsRequest 发送给 Controller。
Controller 是 Kafka 中的一个非常重要的控制面模块,是 Kafka 集群的“大脑”,负责协调和管理整个集群的运行状态。Controller 的职责包括:管理主题、分区等元数据、管理集群中的 Broker 以及故障处理和故障恢复等。
需要注意的是 Controller 是一个逻辑模块,也就是说,在 Kafka 集群中并不存在一个 Controller 物理进程。实际上,Controller 是 Broker 中的一个功能模块,每个集群中的所有 Broker 通过选举,选出一个 Broker,这个 Broker 上的 Controller 功能被激活,行使管理集群的职责。
Controller 收到 CreateTopicsRequest 后,会根据请求中的主题和副本数量,创建出一个主题的分区分配方案,分配方案中定义新主题的每个分区副本应该被分配到集群中的哪个 Broker 上。
分配方案创建之后,Controller 会将主题信息和这个分配方案写入到 ZooKeeper 中,然后就给 AdminClient 返回成功响应。需要注意的是,这时主题并未被真正创建出来,这个响应仅代表 Controller 接受了请求,做了各种创建主题前的检查,确认集群具备创建主题的条件。
客户端收到这个响应时,新主题可能并未完全就绪,这就是为什么 Kafka 文档建议在收到创建响应后要等待一段时间再使用新主题的原因。
以上这部分逻辑的实现在 Kafka 源码中 AdminManager 类的 createTopics 方法中。
Controller 会监听 ZooKeeper 中主题元数据变化,触发 TopicChange 事件,在响应事件的逻辑中继续完成主题创建的剩余步骤。
接下来,Controller 会更新主题每个分区的状态,然后为每个分区选举出 Leader,然后分别给相关的 Broker 发送 UpdateMetadataRequest 请求通知 Broker 元数据已变更,并发送 LeaderAndIsrRequest 请求通知 Broker 更新分区状态。
以上这部分逻辑的实现在 kafka 源码中 KafkaController 类的 processTopicChange 方法中。
Broker 收到 UpdateMetadataRequest 请求后,会更新缓存在 Broker 本地的元数据,然后返回响应。在收到 LeaderAndIsrRequest 后,按需创建本地的分区副本,并更新分区副本状态,完成分区创建。
以上这部分逻辑的实现入口在 kafka 源码中 KafkaApi 类的 handleUpdateMetadataRequest 和 handleLeaderAndIsrRequest 方法中。
当所有 Broker 都完成分区创建后,主题创建流程就结束了。
以下是详细的时序图:

通过异步配置下发达成最终一致
从上面的实现流程可以看出来,Kafka 对于创建主题这类配置下发的设计和传统的设计思路是有区别的。
Kafka 在设计思路上有两个重要的特点:异步和最终一致。在配置下发流程中,凡是涉及到通过远程调用下发配置的步骤,都遵循这样一种模式:
- 客户端发送配置变更请求。
- 服务端收到请求后,对请求做基本的检查验证,通过后更新本地元数据,只要本地元数据更新成功后,就立刻返回响应。然后通过元数据更新事件,再异步触发服务端后续的变更流程。
- 客户端收到响应后,更新客户端本地元数据的状态。
这种模式将难处理的分布式事务问题,转化为最终一致的模型,极大地简化了系统应对故障的处理难度。每个远程请求的处理逻辑只涉及元数据更新,很容易实现幂等,可以安全地重试。
通过元数据变更事件异步触发后续流程的实现方式,使得故障恢复的逻辑变得更加简单。故障恢复时,只需检查系统的实际状态与元数据的状态之间的差别,触发相应的变更事件即可,不需要实现专门的回滚或故障恢复逻辑。
如果事件丢失或者事件触发的后续变更流程失败,也可以通过定时器来检查实际状态与元数据的状态之间的差别,再次触发变更实现来重试,直到实际状态与元数据状态达成最终一致。
Kubernetes 中,使用 kubectl 来管理集群的所有命令,也都是采用一样的设计思路来实现的。
在 Kubernetes 称为“声明式 API”,用户通过 kubectl 提交的变更,并非是变更命令(例如,为主题增加一个分区),而是期望的变更后的目标状态(例如,将主题的分区数变为 3)。
Kubernetes 在收到这个变更时,将状态保存到 etcd 中就返回了。后续依靠元数据变更事件,再异步触发执行实际的变更,直到集群实际状态与元数据中存储的目标状态达成最终一致。
可以看出,这种通过异步配置下发实现最终一致的模式并非 Kafka 独创,已经广泛应用在分布式系统中的各种配置变更场景。如果在我们开发的系统中遇到类似场景,也应该遵循这种模式来设计实现。
当然,这种设计也有其自身的问题。
异步变更的方式对用户不够友好,用户执行命令后,并没有一个明确的响应告知用户何时以及是否执行成功,用户只能通过不断地轮询系统状态来判断命令是否执行成功。
因为这种模式通过不断地重试达成最终一致,就需要确保你的场景可以通过重试达成最终一致,比如像 Kafka 和 Kubernetes 的配置下发场景,无论是网络故障还是服务器故障,在故障恢复后都可以重试执行成功,达成最终一致。
有些无法重试成功的场景就不适用,比如扣减库存场景,如果库存不足已经超卖了,那无论如何重试也无法达成最终一致。
小结
通过分析 Kafka 的主题创建过程,我们可以看到 Kafka 在处理配置下发时采用了异步和最终一致性的设计模式。
这种模式将复杂的分布式事务问题简化为元数据的更新和事件驱动的异步处理,极大地提高了系统的可靠性和可维护性。
Kafka 通过这种方式确保了在面对各种故障时,系统能够自动恢复并最终达到一致状态。这种设计思路不仅适用于 Kafka,也被广泛应用于其他分布式系统,如 Kubernetes。
尽管这种模式对用户体验有一定影响,但在确保系统一致性和简化故障处理方面具有显著优势。
思考题
在理解了声明式 API 的含义后,请列举一下你还在哪些常见开源的系统中见过或使用声明式 API 的例子?
欢迎你在评论区留言,我们下节课再见。
上节课思考题答案
关于上节课我提到的问题,参考答案如下:
可以尝试用两种方法实现,一种方法是修改方法签名,返回一个包含结果引用的 Future,使用者调用 Future.join() 方法就可以拿到结果;另一种方法是发消息后阻塞当前线程,等待收到处理结果的消息后再返回。以下是两种方法的示例代码:
// 方法一:返回Future
public CompletableFuture<Boolean> placeOrder(Map<String, Integer> foods) {
// 给食材管理员发消息下单
return actor.<Boolean>sendThen("inventory-manager", "placeOrder", foods);
}
// 方法二:等待结果消息后返回结果
public boolean placeOrderAndWait(String tableId, Map<String, Integer> foods) {
return placeOrder(tableId, foods).join();
}