01 Java代码是怎么运行的?
我们学院的一位教授之前去美国开会,入境的时候海关官员就问他:既然你会计算机,那你说说你用的都是什么语言吧?
教授随口就答了个Java。海关一看是懂行的,也就放行了,边敲章还边说他们上学那会学的是C+。我还特意去查了下,真有叫C+的语言,但是这里海关官员应该指的是C++。
事后教授告诉我们,他当时差点就问海关,是否知道Java和C++在运行方式上的区别。但是又担心海关官员拿他的问题来考别人,也就没问出口。那么,下次你去美国,不幸地被海关官员问这个问题,你懂得如何回答吗?
作为一名Java程序员,你应该知道,Java代码有很多种不同的运行方式。比如说可以在开发工具中运行,可以双击执行jar文件运行,也可以在命令行中运行,甚至可以在网页中运行。当然,这些执行方式都离不开JRE,也就是Java运行时环境。
实际上,JRE仅包含运行Java程序的必需组件,包括Java虚拟机以及Java核心类库等。我们Java程序员经常接触到的JDK(Java开发工具包)同样包含了JRE,并且还附带了一系列开发、诊断工具。
然而,运行C++代码则无需额外的运行时。我们往往把这些代码直接编译成CPU所能理解的代码格式,也就是机器码。
比如下图的中间列,就是用C语言写的Helloworld程序的编译结果。可以看到,C程序编译而成的机器码就是一个个的字节,它们是给机器读的。那么为了让开发人员也能够理解,我们可以用反汇编器将其转换成汇编代码(如下图的最右列所示)。
; 最左列是偏移;中间列是给机器读的机器码;最右列是给人读的汇编代码
0x00: 55 push rbp
0x01: 48 89 e5 mov rbp,rsp
0x04: 48 83 ec 10 sub rsp,0x10
0x08: 48 8d 3d 3b 00 00 00 lea rdi,[rip+0x3b]
; 加载"Hello, World!\n"
0x0f: c7 45 fc 00 00 00 00 mov DWORD PTR [rbp-0x4],0x0
0x16: b0 00 mov al,0x0
0x18: e8 0d 00 00 00 call 0x12
; 调用printf方法
0x1d: 31 c9 xor ecx,ecx
0x1f: 89 45 f8 mov DWORD PTR [rbp-0x8],eax
0x22: 89 c8 mov eax,ecx
0x24: 48 83 c4 10 add rsp,0x10
0x28: 5d pop rbp
0x29: c3 ret
既然C++的运行方式如此成熟,那么你有没有想过,为什么Java要在虚拟机中运行呢,Java虚拟机具体又是怎样运行Java代码的呢,它的运行效率又如何呢?
今天我便从这几个问题入手,和你探讨一下,Java执行系统的主流实现以及设计决策。
为什么Java要在虚拟机里运行?
Java作为一门高级程序语言,它的语法非常复杂,抽象程度也很高。因此,直接在硬件上运行这种复杂的程序并不现实。所以呢,在运行Java程序之前,我们需要对其进行一番转换。
这个转换具体是怎么操作的呢?当前的主流思路是这样子的,设计一个面向Java语言特性的虚拟机,并通过编译器将Java程序转换成该虚拟机所能识别的指令序列,也称Java字节码。这里顺便说一句,之所以这么取名,是因为Java字节码指令的操作码(opcode)被固定为一个字节。
举例来说,下图的中间列,正是用Java写的Helloworld程序编译而成的字节码。可以看到,它与C版本的编译结果一样,都是由一个个字节组成的。
并且,我们同样可以将其反汇编为人类可读的代码格式(如下图的最右列所示)。不同的是,Java版本的编译结果相对精简一些。这是因为Java虚拟机相对于物理机而言,抽象程度更高。
# 最左列是偏移;中间列是给虚拟机读的机器码;最右列是给人读的代码
0x00: b2 00 02 getstatic java.lang.System.out
0x03: 12 03 ldc "Hello, World!"
0x05: b6 00 04 invokevirtual java.io.PrintStream.println
0x08: b1 return
Java虚拟机可以由硬件实现[1],但更为常见的是在各个现有平台(如Windows_x64、Linux_aarch64)上提供软件实现。这么做的意义在于,一旦一个程序被转换成Java字节码,那么它便可以在不同平台上的虚拟机实现里运行。这也就是我们经常说的“一次编写,到处运行”。
虚拟机的另外一个好处是它带来了一个托管环境(Managed Runtime)。这个托管环境能够代替我们处理一些代码中冗长而且容易出错的部分。其中最广为人知的当属自动内存管理与垃圾回收,这部分内容甚至催生了一波垃圾回收调优的业务。
除此之外,托管环境还提供了诸如数组越界、动态类型、安全权限等等的动态检测,使我们免于书写这些无关业务逻辑的代码。
Java虚拟机具体是怎样运行Java字节码的?
下面我将以标准JDK中的HotSpot虚拟机为例,从虚拟机以及底层硬件两个角度,给你讲一讲Java虚拟机具体是怎么运行Java字节码的。
从虚拟机视角来看,执行Java代码首先需要将它编译而成的class文件加载到Java虚拟机中。加载后的Java类会被存放于方法区(Method Area)中。实际运行时,虚拟机会执行方法区内的代码。
如果你熟悉X86的话,你会发现这和段式内存管理中的代码段类似。而且,Java虚拟机同样也在内存中划分出堆和栈来存储运行时数据。
不同的是,Java虚拟机会将栈细分为面向Java方法的Java方法栈,面向本地方法(用C++写的native方法)的本地方法栈,以及存放各个线程执行位置的PC寄存器。
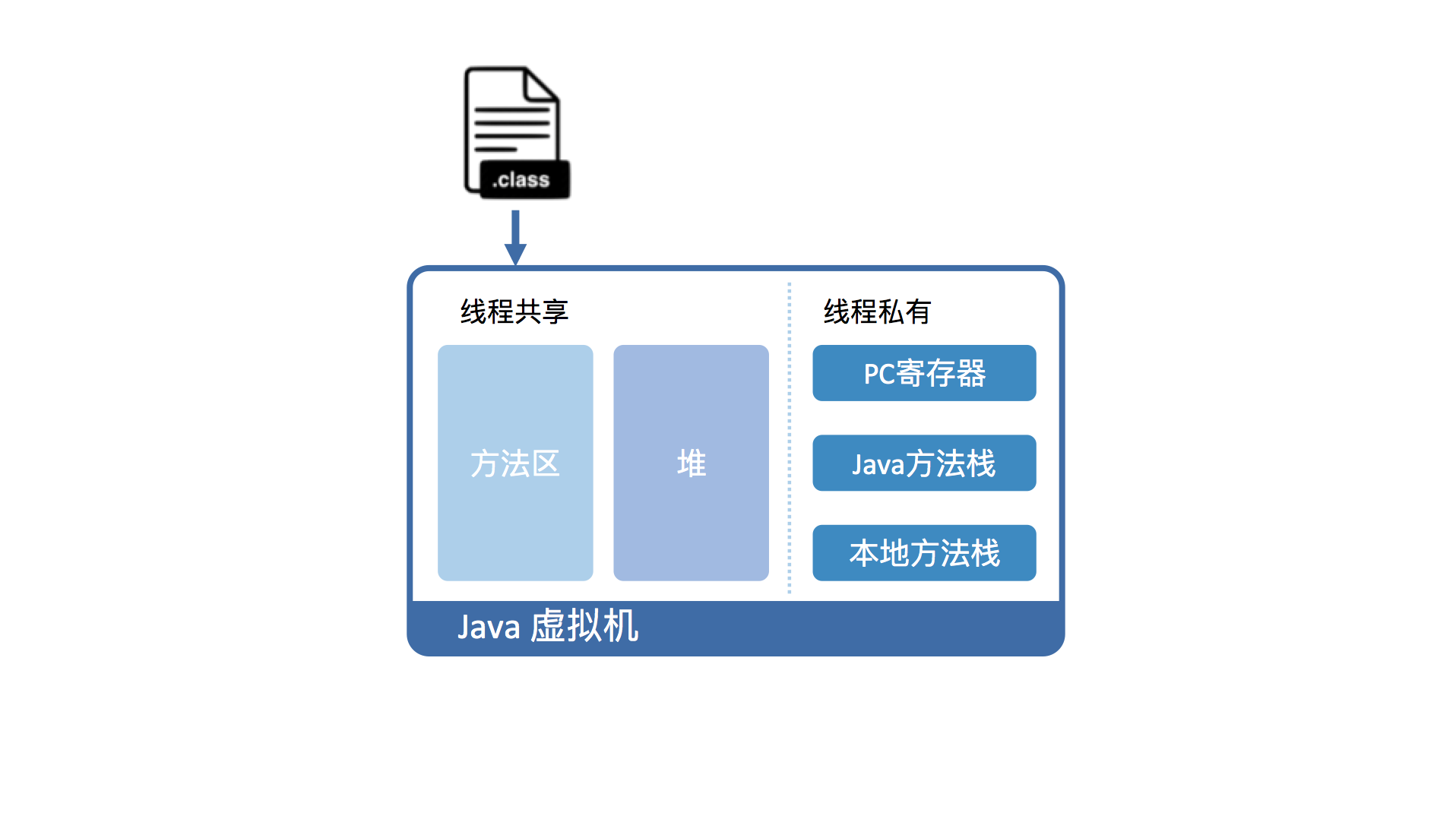
在运行过程中,每当调用进入一个Java方法,Java虚拟机会在当前线程的Java方法栈中生成一个栈帧,用以存放局部变量以及字节码的操作数。这个栈帧的大小是提前计算好的,而且Java虚拟机不要求栈帧在内存空间里连续分布。
当退出当前执行的方法时,不管是正常返回还是异常返回,Java虚拟机均会弹出当前线程的当前栈帧,并将之舍弃。
从硬件视角来看,Java字节码无法直接执行。因此,Java虚拟机需要将字节码翻译成机器码。
在HotSpot里面,上述翻译过程有两种形式:第一种是解释执行,即逐条将字节码翻译成机器码并执行;第二种是即时编译(Just-In-Time compilation,JIT),即将一个方法中包含的所有字节码编译成机器码后再执行。
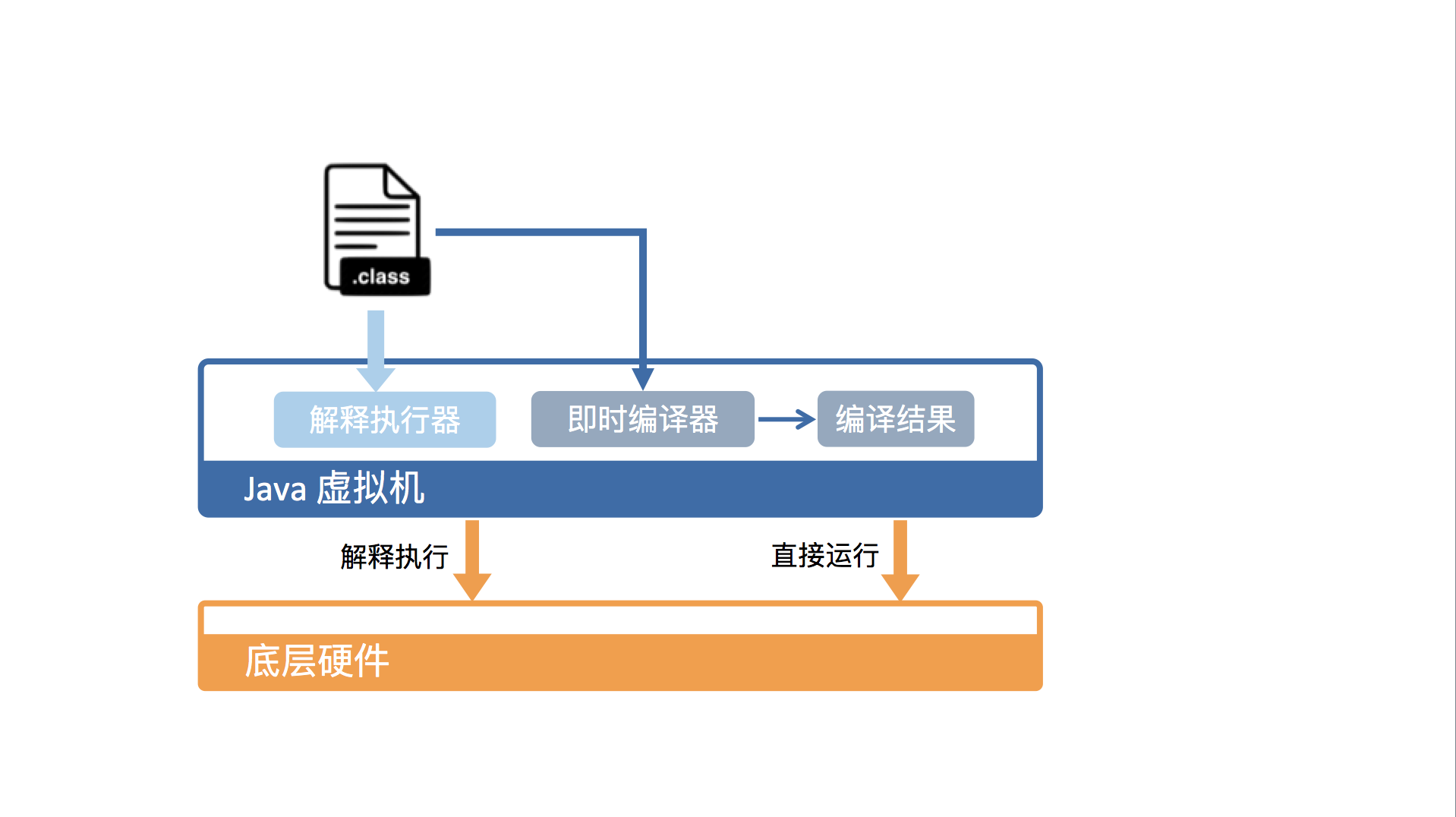
前者的优势在于无需等待编译,而后者的优势在于实际运行速度更快。HotSpot默认采用混合模式,综合了解释执行和即时编译两者的优点。它会先解释执行字节码,而后将其中反复执行的热点代码,以方法为单位进行即时编译。
Java虚拟机的运行效率究竟是怎么样的?
HotSpot采用了多种技术来提升启动性能以及峰值性能,刚刚提到的即时编译便是其中最重要的技术之一。
即时编译建立在程序符合二八定律的假设上,也就是百分之二十的代码占据了百分之八十的计算资源。
对于占据大部分的不常用的代码,我们无需耗费时间将其编译成机器码,而是采取解释执行的方式运行;另一方面,对于仅占据小部分的热点代码,我们则可以将其编译成机器码,以达到理想的运行速度。
理论上讲,即时编译后的Java程序的执行效率,是可能超过C++程序的。这是因为与静态编译相比,即时编译拥有程序的运行时信息,并且能够根据这个信息做出相应的优化。
举个例子,我们知道虚方法是用来实现面向对象语言多态性的。对于一个虚方法调用,尽管它有很多个目标方法,但在实际运行过程中它可能只调用其中的一个。
这个信息便可以被即时编译器所利用,来规避虚方法调用的开销,从而达到比静态编译的C++程序更高的性能。
为了满足不同用户场景的需要,HotSpot内置了多个即时编译器:C1、C2和Graal。Graal是Java 10正式引入的实验性即时编译器,在专栏的第四部分我会详细介绍,这里暂不做讨论。
之所以引入多个即时编译器,是为了在编译时间和生成代码的执行效率之间进行取舍。C1又叫做Client编译器,面向的是对启动性能有要求的客户端GUI程序,采用的优化手段相对简单,因此编译时间较短。
C2又叫做Server编译器,面向的是对峰值性能有要求的服务器端程序,采用的优化手段相对复杂,因此编译时间较长,但同时生成代码的执行效率较高。
从Java 7开始,HotSpot默认采用分层编译的方式:热点方法首先会被C1编译,而后热点方法中的热点会进一步被C2编译。
为了不干扰应用的正常运行,HotSpot的即时编译是放在额外的编译线程中进行的。HotSpot会根据CPU的数量设置编译线程的数目,并且按1:2的比例配置给C1及C2编译器。
在计算资源充足的情况下,字节码的解释执行和即时编译可同时进行。编译完成后的机器码会在下次调用该方法时启用,以替换原本的解释执行。
总结与实践
今天我简单介绍了Java代码为何在虚拟机中运行,以及如何在虚拟机中运行。
之所以要在虚拟机中运行,是因为它提供了可移植性。一旦Java代码被编译为Java字节码,便可以在不同平台上的Java虚拟机实现上运行。此外,虚拟机还提供了一个代码托管的环境,代替我们处理部分冗长而且容易出错的事务,例如内存管理。
Java虚拟机将运行时内存区域划分为五个部分,分别为方法区、堆、PC寄存器、Java方法栈和本地方法栈。Java程序编译而成的class文件,需要先加载至方法区中,方能在Java虚拟机中运行。
为了提高运行效率,标准JDK中的HotSpot虚拟机采用的是一种混合执行的策略。
它会解释执行Java字节码,然后会将其中反复执行的热点代码,以方法为单位进行即时编译,翻译成机器码后直接运行在底层硬件之上。
HotSpot装载了多个不同的即时编译器,以便在编译时间和生成代码的执行效率之间做取舍。
下面我给你留一个小作业,通过观察两个条件判断语句的运行结果,来思考Java语言和Java虚拟机看待boolean类型的方式是否不同。
下载asmtools.jar [2] ,并在命令行中运行下述指令(不包含提示符$):
$ echo '
public class Foo {
public static void main(String[] args) {
boolean flag = true;
if (flag) System.out.println("Hello, Java!");
if (flag == true) System.out.println("Hello, JVM!");
}
}' > Foo.java
$ javac Foo.java
$ java Foo
$ java -cp /path/to/asmtools.jar org.openjdk.asmtools.jdis.Main Foo.class > Foo.jasm.1
$ awk 'NR==1,/iconst_1/{sub(/iconst_1/, "iconst_2")} 1' Foo.jasm.1 > Foo.jasm
$ java -cp /path/to/asmtools.jar org.openjdk.asmtools.jasm.Main Foo.jasm
$ java Foo
[1] : https://en.wikipedia.org/wiki/Java_processor [2]: https://wiki.openjdk.java.net/display/CodeTools/asmtools
- jiaobuchongจุ๊บ 👍(97) 💬(1)
对老师写的那段 awk 不懂得可参考: https://blog.csdn.net/jiaobuchong/article/details/83037467
2018-10-14 - 小名叫大明 👍(49) 💬(5)
受益匪浅,多谢老师。 请教老师一个问题,网上我没有搜到。 服务器线程数爆满,使用jstack打印线程堆栈信息,想知道是哪类线程数太多,但是堆栈里全是一样的信息且没有任何关键信息,是哪个方法创建的,以及哪个线程池的都看不到。 如何更改打印线程堆栈信息的代码(动态)让其打印线程池信息呢?
2018-07-26 - 曲东方 👍(430) 💬(10)
jvm把boolean当做int来处理 flag = iconst_1 = true awk把stackframe中的flag改为iconst_2 if(flag)比较时ifeq指令做是否为零判断,常数2仍为true,打印输出 if(true == flag)比较时if_cmpne做整数比较,iconst_1是否等于flag,比较失败,不再打印输出
2018-07-20 - novembersky 👍(150) 💬(7)
文中提到虚拟机会把部分热点代码编译成机器码,我有个疑问,为什么不把java代码全部编译成机器码?很多服务端应用发布频率不会太频繁,但是对运行时的性能和吞吐量要求较高。如果发布或启动时多花点时间编译,能够带来运行时的持久性能收益,不是很合适么?
2018-07-20 - 钱 👍(53) 💬(1)
1:为什么使用JVM? 1-1:可以轻松实现Java代码的跨平台执行 1-2:JVM提供了一个托管平台,提供内存管理、垃圾回收、编译时动态校验等功能 1-3:使用JVM能够让我们的编程工作更轻松、高效节省公司成本,提示社会化的整体快发效率,我们只关注和业务相关的程序逻辑的编写,其他业务无关但对于编程同样重要的事情交给JVM来处理 2:听完此节的课程的疑惑(之前就没太明白,原期待听完后不再疑惑的) 2-1:Java源代码怎么就经过编译变成了Java字节码? 2-2:JVM怎么就把Java字节码加载进JVM内了?先加载那个类的字节码?它怎么定位的?拿到后怎么解析的?不会整个文件放到一个地方吧?使用的时候又是怎么找到的呢?这些感觉还是黑盒 2-3:JVM将内存区域分成堆和栈,然后又将栈分成pc寄存器、本地方法栈、Java方法栈,有些内存空间是线程可共享的,有些是线程私有的。现在也了解不同的内存区块有不同的用处,不过他们是怎么被划分的哪?为什么是他们,不能再多几种或少几种了吗?共享的内存区和私有的又是怎么控制的哪?
2018-07-24 - Ryan-Hou 👍(43) 💬(3)
在为什么Java要在虚拟机里执行这一节您提到,java语法复杂,抽象度高,直接通过硬件来执行不现实,但是同样作为高级语言为什么C++就可以呢?这个理由作为引入虚拟机这个中间层的原因不是很充分吧
2018-07-20 - 周仕林 👍(38) 💬(2)
看到有人说热点代码的区别,在git里面涉及到的热点代码有两种算法,基于采样的热点探测和基于计数器的热点探测。一般采用的都是基于计数器的热点探测,两者的优缺点百度一下就知道了。基于计数器的热点探测又有两个计数器,方法调用计数器,回边计数器,他们在C1和C2又有不同的阈值。😂😂
2018-07-23 - 笨笨蛋 👍(23) 💬(5)
什么时候使用C1,什么时候使用C2,他是怎么区分热点方法的呢?
2018-07-24 - 那我懂你意思了 👍(18) 💬(3)
老师,那个pc寄存器,本地方法栈,以及方法栈,java方法栈这三个组成的就是我们常统称的栈吧,然后也叫栈帧?
2018-07-20 - 踏雪无痕 👍(16) 💬(1)
您好,我现在所在的项目经常堆外内存占用非常多,超过总内存的70%,请问一下有没有什么方法能观察一下堆外内存有什么内容?
2018-07-20 - Phoenix 👍(14) 💬(1)
解释执行是将字节码翻译为机器码,JIT也是将字节码翻译为机器码,为什么JIT就比解释执行要快这么多? 如果说JIT检测到是热点代码并且进行优化,那么为什么解释执行不直接就用这种优化去解释字节码? 一些比较浅的问题,希望老师能指点一二
2018-09-16 - 金龟 👍(12) 💬(2)
感觉看完后,解释执行和jit的区别还是有点没搞懂。解释执行的意思是:直接将整个字节码码文件转化成机器码,jit的意思是:用到哪段编译哪段?
2018-11-24 - suzuiyue 👍(11) 💬(3)
JIT程序重启之后还需要再来一遍吗?
2018-09-18 - 临风 👍(10) 💬(2)
我跟楼上的novembersky同学一样疑惑,对于性能要求高的web应用,为什么不直接使用即时编译器在启动时全部编译成机器码呢?虽然启动耗时,但是也是可以接受的
2018-07-20 - Kouichi 👍(8) 💬(1)
为啥是"理论"上比cpp快...这样看起来 如果都编译成机器码了 应该就是挺快的呀... 那干啥不像Go一样 直接编译成目标平台的机器码... 咋感觉绕了一圈..
2018-07-20