17 即时编译(下)
今天我们来继续讲解Java虚拟机中的即时编译。
Profiling
上篇提到,分层编译中的0层、2层和3层都会进行profiling,收集能够反映程序执行状态的数据。其中,最为基础的便是方法的调用次数以及循环回边的执行次数。它们被用于触发即时编译。
此外,0层和3层还会收集用于4层C2编译的数据,比如说分支跳转字节码的分支profile(branch profile),包括跳转次数和不跳转次数,以及非私有实例方法调用指令、强制类型转换checkcast指令、类型测试instanceof指令,和引用类型的数组存储aastore指令的类型profile(receiver type profile)。
分支profile和类型profile的收集将给应用程序带来不少的性能开销。据统计,正是因为这部分额外的profiling,使得3层C1代码的性能比2层C1代码的低30%。
在通常情况下,我们不会在解释执行过程中收集分支profile以及类型profile。只有在方法触发C1编译后,Java虚拟机认为该方法有可能被C2编译,方才在该方法的C1代码中收集这些profile。
只要在比较极端的情况下,例如等待C1编译的方法数目太多时,Java虚拟机才会开始在解释执行过程中收集这些profile。
那么这些耗费巨大代价收集而来的profile具体有什么作用呢?
答案是,C2可以根据收集得到的数据进行猜测,假设接下来的执行同样会按照所收集的profile进行,从而作出比较激进的优化。
基于分支profile的优化
举个例子,下面这段代码中包含两个条件判断。第一个条件判断将测试所输入的boolean值。
如果为true,则将局部变量v设置为所输入的int值。如果为false,则将所输入的int值经过一番运算之后,再存入局部变量v之中。
第二个条件判断则测试局部变量v是否和所输入的int值相等。如果相等,则返回0。如果不等,则将局部变量v经过一番运算之后,再将之返回。显然,当所输入的boolean值为true的情况下,这段代码将返回0。
public static int foo(boolean f, int in) {
int v;
if (f) {
v = in;
} else {
v = (int) Math.sin(in);
}
if (v == in) {
return 0;
} else {
return (int) Math.cos(v);
}
}
// 编译而成的字节码:
public static int foo(boolean, int);
Code:
0: iload_0
1: ifeq 9
4: iload_1
5: istore_2
6: goto 16
9: iload_1
10: i2d
11: invokestatic java/lang/Math.sin:(D)D
14: d2i
15: istore_2
16: iload_2
17: iload_1
18: if_icmpne 23
21: iconst_0
22: ireturn
23: iload_2
24: i2d
25: invokestatic java/lang/Math.cos:(D)D
28: d2i
29: ireturn
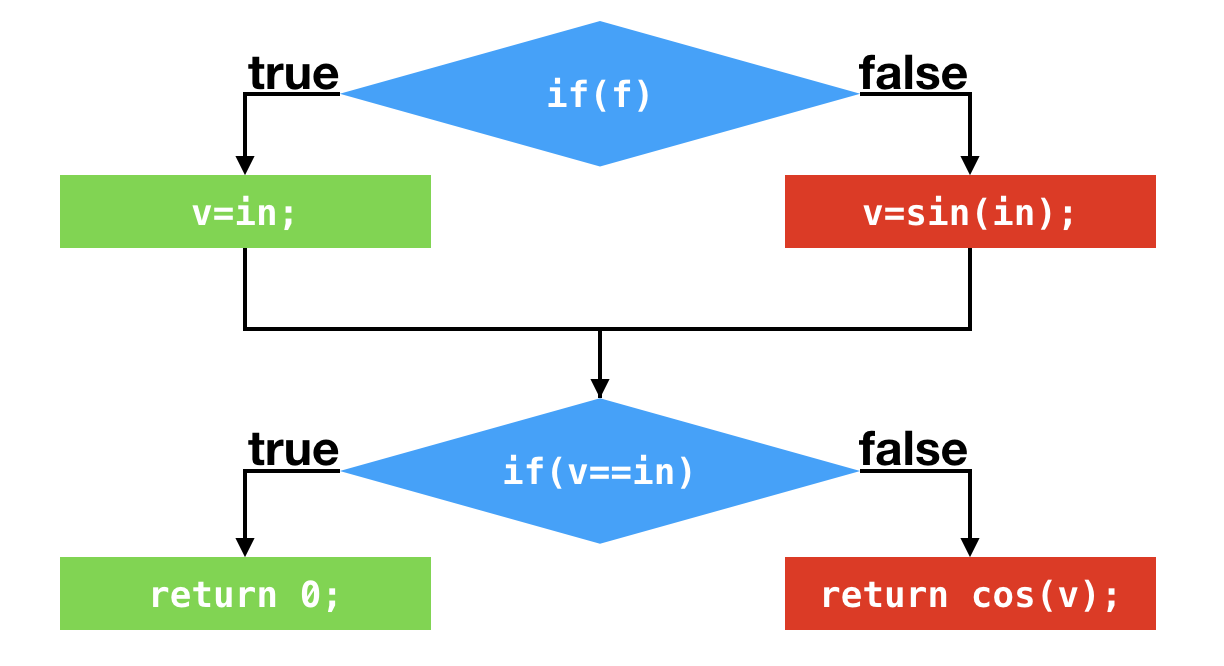
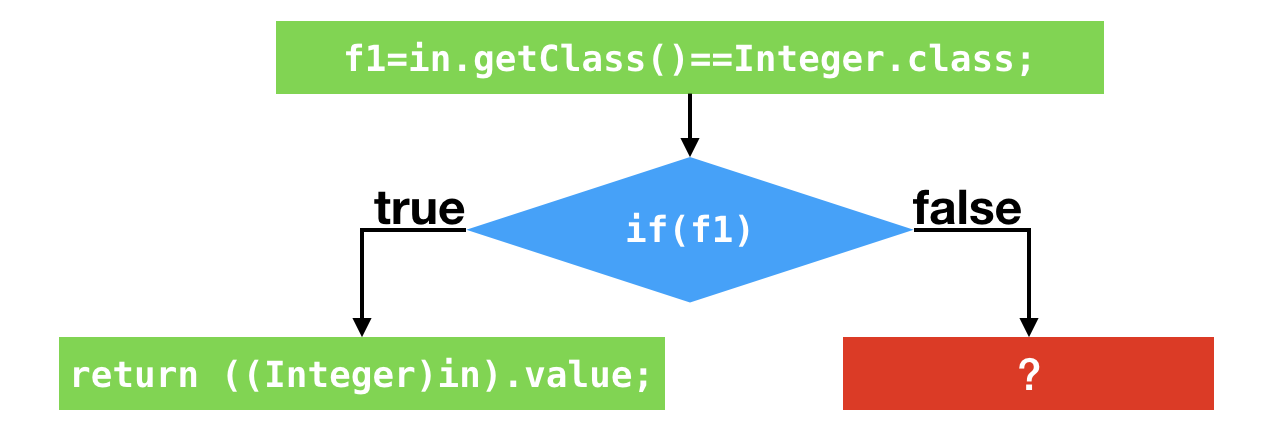
假设应用程序调用该方法时,所传入的boolean值皆为true。那么,偏移量为1以及偏移量为18的条件跳转指令所对应的分支profile中,跳转的次数都为0。
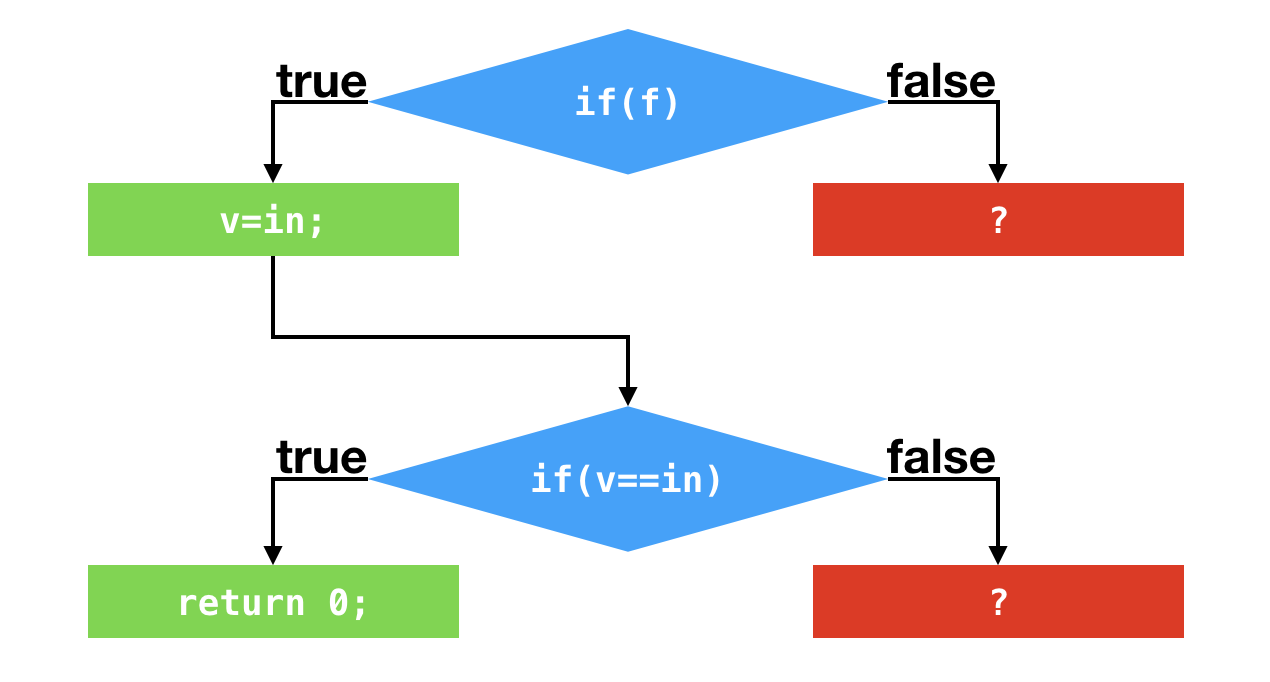
C2可以根据这两个分支profile作出假设,在接下来的执行过程中,这两个条件跳转指令仍旧不会发生跳转。基于这个假设,C2便不再编译这两个条件跳转语句所对应的false分支了。
我们暂且不管当假设错误的时候会发生什么,先来看一看剩下来的代码。经过“剪枝”之后,在第二个条件跳转处,v的值只有可能为所输入的int值。因此,该条件跳转可以进一步被优化掉。最终的结果是,在第一个条件跳转之后,C2代码将直接返回0。
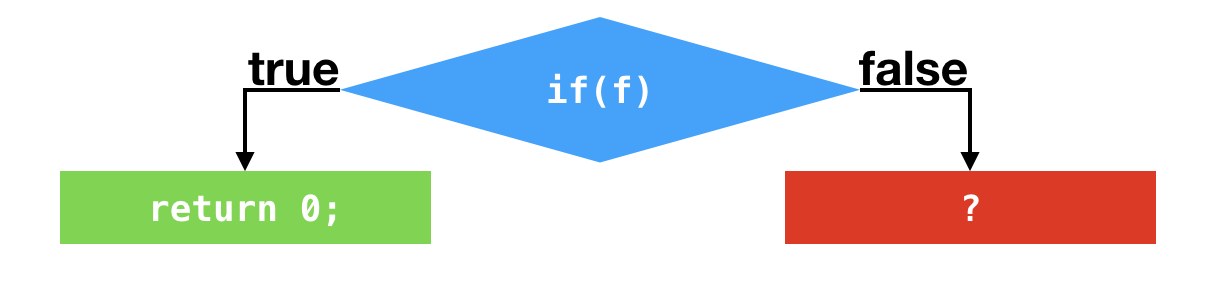
这里我打印了C2的编译结果。可以看到,在地址为2cee的指令处进行过一次比较之后,该机器码便直接返回0。
Compiled method (c2) 95 16 4 CompilationTest::foo (30 bytes)
...
CompilationTest.foo [0x0000000104fb2ce0, 0x0000000104fb2d38] 88 bytes
[Entry Point]
[Verified Entry Point]
[Constants]
# {method} {0x000000012629e380} 'foo' '(ZI)I' in 'CompilationTest'
# parm0: rsi = boolean
# parm1: rdx = int
# [sp+0x30] (sp of caller)
0x0000000104fb2ce0: mov DWORD PTR [rsp-0x14000],eax
0x0000000104fb2ce7: push rbp
0x0000000104fb2ce8: sub rsp,0x20
0x0000000104fb2cec: test esi,esi
0x0000000104fb2cee: je 0x0000000104fb2cfe // 跳转至?
0x0000000104fb2cf0: xor eax,eax // 将返回值设置为0
0x0000000104fb2cf2: add rsp,0x20
0x0000000104fb2cf6: pop rbp
0x0000000104fb2cf7: test DWORD PTR [rip+0xfffffffffca32303],eax // safepoint
0x0000000104fb2cfd: ret
...
总结一下,根据条件跳转指令的分支profile,即时编译器可以将从未执行过的分支剪掉,以避免编译这些很有可能不会用到的代码,从而节省编译时间以及部署代码所要消耗的内存空间。此外,“剪枝”将精简程序的数据流,从而触发更多的优化。
在现实中,分支profile出现仅跳转或者仅不跳转的情况并不多见。当然,即时编译器对分支profile的利用也不仅限于“剪枝”。它还会根据分支profile,计算每一条程序执行路径的概率,以便某些编译器优化优先处理概率较高的路径。
基于类型profile的优化
另外一个例子则是关于instanceof以及方法调用的类型profile。下面这段代码将测试所传入的对象是否为Exception的实例,如果是,则返回它的系统哈希值;如果不是,则返回它的哈希值。
public static int hash(Object in) {
if (in instanceof Exception) {
return System.identityHashCode(in);
} else {
return in.hashCode();
}
}
// 编译而成的字节码:
public static int hash(java.lang.Object);
Code:
0: aload_0
1: instanceof java/lang/Exception
4: ifeq 12
7: aload_0
8: invokestatic java/lang/System.identityHashCode:(Ljava/lang/Object;)I
11: ireturn
12: aload_0
13: invokevirtual java/lang/Object.hashCode:()I
16: ireturn
假设应用程序调用该方法时,所传入的Object皆为Integer实例。那么,偏移量为1的instanceof指令的类型profile仅包含Integer,偏移量为4的分支跳转语句的分支profile中不跳转的次数为0,偏移量为13的方法调用指令的类型profile仅包含Integer。
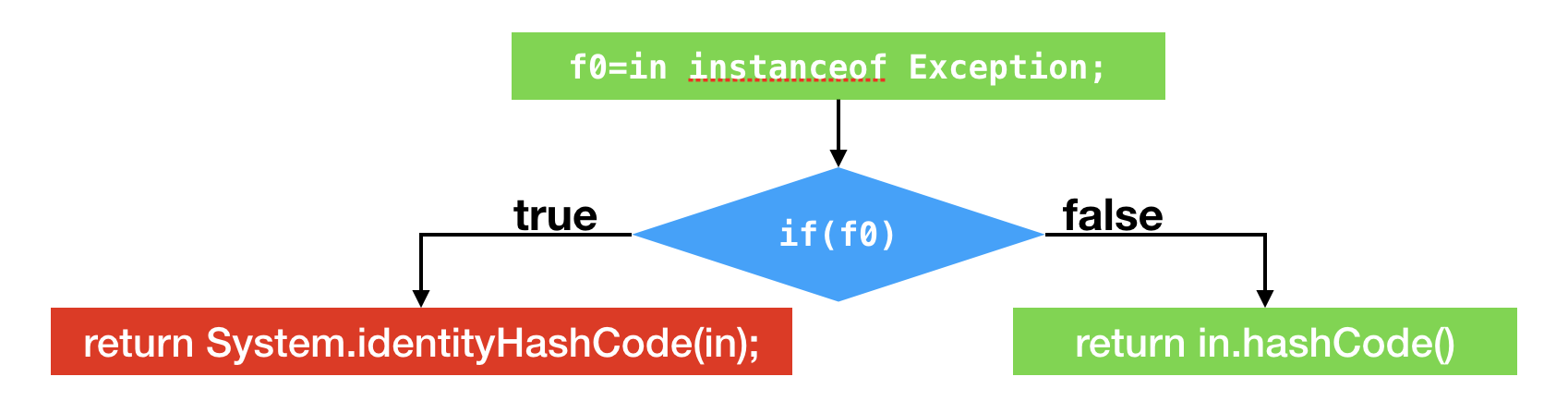
在Java虚拟机中,instanceof测试并不简单。如果instanceof的目标类型是final类型,那么Java虚拟机仅需比较测试对象的动态类型是否为该final类型。
在讲解对象的内存分布那一篇中,我曾经提到过,对象头存有该对象的动态类型。因此,获取对象的动态类型仅为单一的内存读指令。
如果目标类型不是final类型,比如说我们例子中的Exception,那么Java虚拟机需要从测试对象的动态类型开始,依次测试该类,该类的父类、祖先类,该类所直接实现或者间接实现的接口是否与目标类型一致。
不过,在我们的例子中,instanceof指令的类型profile仅包含Integer。根据这个信息,即时编译器可以假设,在接下来的执行过程中,所输入的Object对象仍为Integer实例。
因此,生成的代码将测试所输入的对象的动态类型是否为Integer。如果是的话,则继续执行接下来的代码。(该优化源自Graal,采用C2可能无法复现。)
然后,即时编译器会采用和第一个例子中一致的针对分支profile的优化,以及对方法调用的条件去虚化内联。
我会在接下来的篇章中详细介绍内联,这里先说结果:生成的代码将测试所输入的对象动态类型是否为Integer。如果是的话,则执行Integer.hashCode()方法的实质内容,也就是返回该Integer实例的value字段。
public final class Integer ... {
...
@Override
public int hashCode() {
return Integer.hashCode(value);
}
public static int hashCode(int value) {
return value;
}
...
}
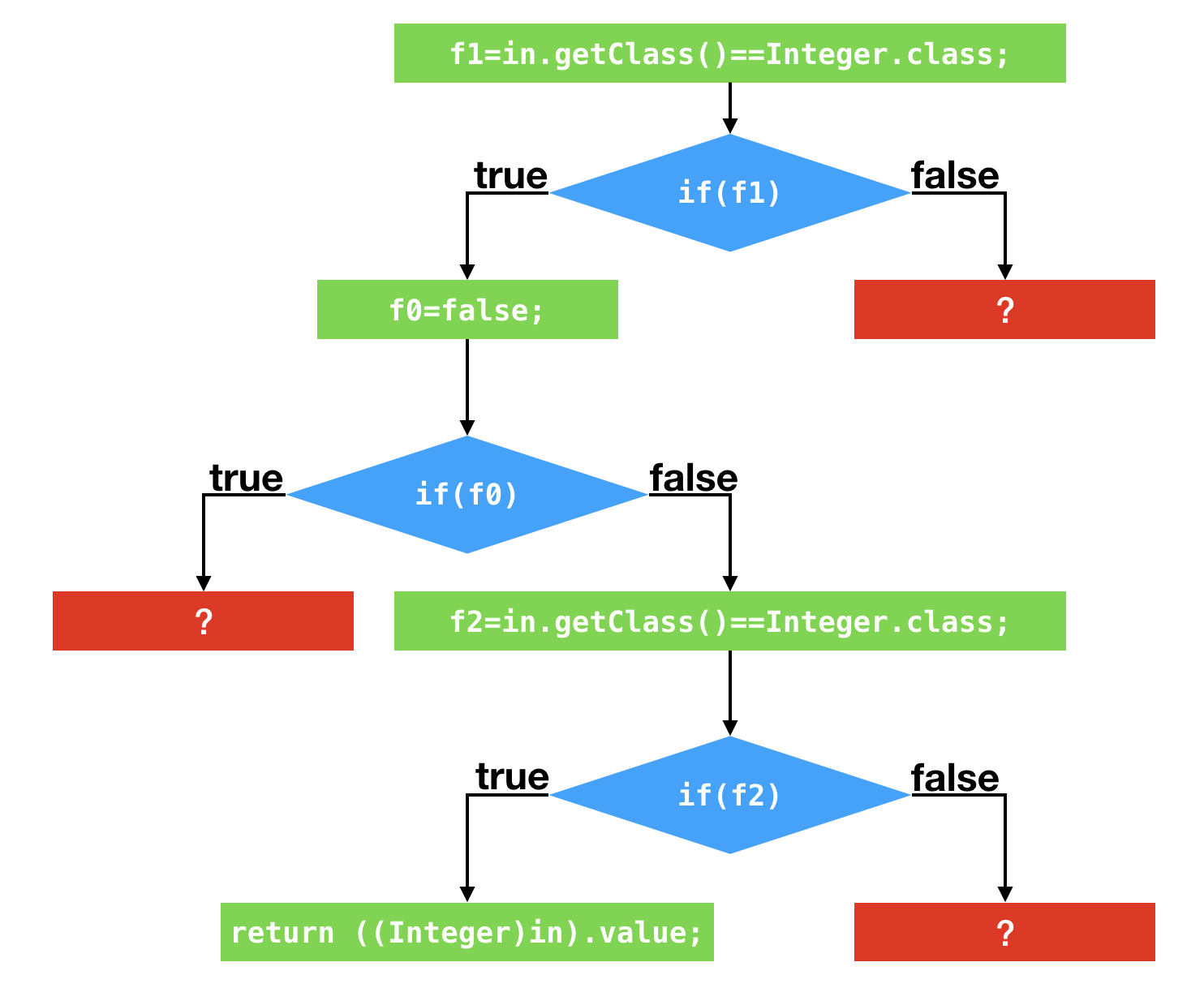
和第一个例子一样,根据数据流分析,上述代码可以最终优化为极其简单的形式。
这里我打印了Graal的编译结果。可以看到,在地址为1ab7的指令处进行过一次比较之后,该机器码便直接返回所传入的Integer对象的value字段。
Compiled method (JVMCI) 600 23 4
...
----------------------------------------------------------------------
CompilationTest.hash (CompilationTest.hash(Object)) [0x000000011d811aa0, 0x000000011d811b00] 96 bytes
[Entry Point]
[Verified Entry Point]
[Constants]
# {method} {0x00000001157053c8} 'hash' '(Ljava/lang/Object;)I' in 'CompilationTest'
# parm0: rsi:rsi = 'java/lang/Object'
# [sp+0x20] (sp of caller)
0x000000011d811aa0: mov DWORD PTR [rsp-0x14000],eax
0x000000011d811aa7: sub rsp,0x18
0x000000011d811aab: mov QWORD PTR [rsp+0x10],rbp
// 比较[rsi+0x8],也就是所传入的Object参数的动态类型,是否为Integer。这里0xf80022ad是Integer类的内存地址。
0x000000011d811ab0: cmp DWORD PTR [rsi+0x8],0xf80022ad
// 如果不是,跳转至?
0x000000011d811ab7: jne 0x000000011d811ad3
// 加载Integer.value。在启用压缩指针时,该字段的偏移量为12,也就是0xc
0x000000011d811abd: mov eax,DWORD PTR [rsi+0xc]
0x000000011d811ac0: mov rbp,QWORD PTR [rsp+0x10]
0x000000011d811ac5: add rsp,0x18
0x000000011d811ac9: test DWORD PTR [rip+0xfffffffff272f537],eax
0x000000011d811acf: vzeroupper
0x000000011d811ad2: ret
和基于分支profile的优化一样,基于类型profile的优化同样也是作出假设,从而精简控制流以及数据流。这两者的核心都是假设。
对于分支profile,即时编译器假设的是仅执行某一分支;对于类型profile,即时编译器假设的是对象的动态类型仅为类型profile中的那几个。
那么,当假设失败的情况下,程序将何去何从?我们继续往下看。
去优化
Java虚拟机给出的解决方案便是去优化,即从执行即时编译生成的机器码切换回解释执行。
在生成的机器码中,即时编译器将在假设失败的位置上插入一个陷阱(trap)。该陷阱实际上是一条call指令,调用至Java虚拟机里专门负责去优化的方法。与普通的call指令不一样的是,去优化方法将更改栈上的返回地址,并不再返回即时编译器生成的机器码中。
在上面的程序控制流图中,我画了很多红色方框的问号。这些问号便代表着一个个的陷阱。一旦踏入这些陷阱,便将发生去优化,并切换至解释执行。
去优化的过程相当复杂。由于即时编译器采用了许多优化方式,其生成的代码和原本的字节码的差异非常之大。
在去优化的过程中,需要将当前机器码的执行状态转换至某一字节码之前的执行状态,并从该字节码开始执行。这便要求即时编译器在编译过程中记录好这两种执行状态的映射。
举例来说,经过逃逸分析之后,机器码可能并没有实际分配对象,而是在各个寄存器中存储该对象的各个字段(标量替换,具体我会在之后的篇章中进行介绍)。在去优化过程中,Java虚拟机需要还原出这个对象,以便解释执行时能够使用该对象。
当根据映射关系创建好对应的解释执行栈桢后,Java虚拟机便会采用OSR技术,动态替换栈上的内容,并在目标字节码处开始解释执行。
此外,在调用Java虚拟机的去优化方法时,即时编译器生成的机器码可以根据产生去优化的原因来决定是否保留这一份机器码,以及何时重新编译对应的Java方法。
如果去优化的原因与优化无关,即使重新编译也不会改变生成的机器码,那么生成的机器码可以在调用去优化方法时传入Action_None,表示保留这一份机器码,在下一次调用该方法时重新进入这一份机器码。
如果去优化的原因与静态分析的结果有关,例如类层次分析,那么生成的机器码可以在调用去优化方法时传入Action_Recompile,表示不保留这一份机器码,但是可以不经过重新profile,直接重新编译。
如果去优化的原因与基于profile的激进优化有关,那么生成的机器码需要在调用去优化方法时传入Action_Reinterpret,表示不保留这一份机器码,而且需要重新收集程序的profile。
这是因为基于profile的优化失败的时候,往往代表这程序的执行状态发生改变,因此需要更正已收集的profile,以更好地反映新的程序执行状态。
总结与实践
今天我介绍了Java虚拟机的profiling以及基于所收集的数据的优化和去优化。
通常情况下,解释执行过程中仅收集方法的调用次数以及循环回边的执行次数。
当方法被3层C1所编译时,生成的C1代码将收集条件跳转指令的分支profile,以及类型相关指令的类型profile。在部分极端情况下,Java虚拟机也会在解释执行过程中收集这些profile。
基于分支profile的优化以及基于类型profile的优化都将对程序今后的执行作出假设。这些假设将精简所要编译的代码的控制流以及数据流。在假设失败的情况下,Java虚拟机将采取去优化,退回至解释执行并重新收集相关的profile。
今天的实践环节,你可以使用参数
来打印程序运行过程中即时编译器生成的机器码。官方的JDK可能不包含反汇编器动态链接库,如hsdis-amd64.dylib。你可能需要另外下载。
// java -XX:CompileCommand='print,CompilationTest.foo' CompilationTestjava -XX:CompileCommand='print,CompilationTest.foo' CompilationTest
public class CompilationTest {
public static int foo(boolean f, int in) {
int v;
if (f) {
v = in;
} else {
v = (int) Math.sin(in);
}
if (v == in) {
return 0;
} else {
return (int) Math.cos(v);
}
}
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 500000; i++) {
foo(true, 2);
}
Thread.sleep(2000);
}
}
// java -XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler -XX:CompileCommand='print,CompilationTest2.hash' CompilationTest2
public class CompilationTest2 {
public static int hash(Object input) {
if (input instanceof Exception) {
return System.identityHashCode(input);
} else {
return input.hashCode();
}
}
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 500000; i++) {
hash(i);
}
Thread.sleep(2000);
}
}
- 钱 👍(32) 💬(1)
这节是即时编译器的有关优化、去优化、以及何时优化和为什么去优化的内容。可能比较底层,看不见摸不着,一句两句也说不清楚,所以,有点晦涩。 不过经过反复看有点感觉了,小结如下: 1:profile-是收集运行时状态信息,用于编译器优化,当然,收集信息也是耗性能的,所以,也是有前提条件的,当存在优化的可能性时才去费劲吧啦的收集相关信息 2:本节介绍的两种优化的方式思路,都是采用取巧少做事情的方式实现,是建立在假设有些事情不需要做的前提下采用的优化措施 3:如果假设失败,那就去优化呗!还用原来的方式老老实实的解释执行就完了 上述思路是理解了,不过具体实现还是蒙蒙的,应该是水平有限理解不到位吧!整体还是有收获的,所以,非常感谢!
2018-09-02 - xiaobang 👍(8) 💬(2)
想问下生成的机器码如何和其它未编译的字节码交互?比如相互调用,访问对象内的字段,new对象和对应的gc
2018-10-10 - 徐志毅 👍(5) 💬(2)
雨迪老师,请问有什么方式可以跟踪JMM里主内存与工作内存的交互,如什么时候加载到工作内存、什么时候同步到主内存~ 盼回复,谢谢
2018-08-29 - 乔毅 👍(1) 💬(1)
请教下老师,JIT利用SIMD进行优化的实现程度?实践中看到大多是仅仅做了循环展开。换言之,有没有什么最佳实践,可以写出JIT SIMD优化友好的代码。
2018-09-03 - 李二木 👍(1) 💬(1)
感觉好难,我想问下在现实情况下通过编译器调优的情况多吗?
2018-08-30 - 茶底 👍(0) 💬(1)
大佬我已经把graal拿到手了。目前用了下gu下语言挺好使的。但是这个怎么编译啊。。。
2018-08-30 - 西门吹牛 👍(24) 💬(0)
这篇文章讲的分支优化,类型优化,其实就是对应了CPU指令执行时候的分支预测和冒险技术,JVM只是个虚拟机,都是在模拟整个计算机的运行过程,所以抽象出了内存模型等概率,因为java 在解释执行的时候,效率不高,但是解释执行的好处就是应用程序的启动不需要加载很多类,启动快。 为了平衡解释执行的效率问题,引入即时编译技术,即时编译是把一整块代码(可以是一个方法也可以是一个循环块)直接编译成一段机器码,以便后续热点代码重复使用。 CPU在执行指令的时候,从硬件方面考虑,CPU很快,CPU完全不会等某个条件判断结果出来以后在根据判断结果确定执行那条指令,而是根据预测的方法,不等判断结果就根据判断执行后续的指令,如果对了,就省去等待时间,虽然CPU等待一条指令执行完毕的时间很短,但是这个时间跟cpu的频率一比,还是很可观的,如果预测错了,那就把执行错误的指令移除,涉及到加载到寄存器的数据都删掉,然后在按正确的分支去执行。 java在即时编译的过程中,编译出来的是一整段机器码,程序还没运行呢,无法判断走哪个分支,所以是通过收集的profile 数据进行预测,预测对了当然好,错就错了,在回去走一遍就好,但是根据profile 的数据进行预测,错误的概率不高,试想一下,if条件判断,预测错误的概率是百分之五十,通过收集数据的分析,完全可以把这个错误的概率降到很低,所以jvm在即时编译的时候,完全有必要进行预测,虽然收集数据有开销,但是同样带来的性能效率也有提升。 之前只是对cpu的分支预测和数据冒险有了解,今天看了老师的文章,真是大赞。方法论都是通用的,只是在不同的地方用了不同的实现。
2020-07-15 - 任鑫 👍(2) 💬(0)
《老子》尝言:”将欲取之,必先予之“。我们想要使用编译优化来提高代码的执行效率,这就是你想要”取“,然而优化是要付出代价的,这就是”予“;全部都编译优化当然代价太大,我们希望让这个代价小一点,因此需要在前期代码执行过程中收集它的profile,根据这个统计消息来决定哪些优化,怎么优化,这就是要确定优化的策略,这又是一个”取“,收集profile会降低代码运行效率,这就是为了确定这个编译优化策略所要付出的代价,这就是第二个”予“。一切优化均需权衡代价,不管你是”时间换空间“、”空间换时间“什么的,就是一个”将欲取之必先与之“。
2020-05-27 - 随心而至 👍(1) 💬(0)
这两节都是讲JVM想做一些假设,来提高程序的运行效率(优化);如果假设错了就重新来过(去优化,退化为解释执行)。 这里JVM尝试做的事情,感觉和底层CPU想做的分支预测如出一辙。 具体可参考:https://time.geekbang.org/column/article/102166
2019-10-18 - 陈吉米 👍(1) 💬(1)
那么有什么规则,可以让代码尽可能被优化?
2018-08-29 - 农夫山泉 👍(0) 💬(0)
只有在方法触发 C1 编译后,Java 虚拟机认为该方法有可能被 C2 编译,方才在该方法的 C1 代码中收集这些 profile。 — 请问这个位置,Java 虚拟机是如何判断该方法是否有可能被 C2 编译的呢?
2021-11-02 - 水浴清风 👍(0) 💬(0)
即时编译采用分层编译来对执行效率与编译效率之间进行平衡. 分层分为五层: 0.解释执行 1.c1编译执行(其中分为三层,后两层收集profile,profile用于c2编译优化,层层递进) 2.c2编译执行 即使编译的profile收集; 1.方法调用次数 2.循环回边次数 3.分支profile 4.类型profile profile的收集对性能是🈶️消耗的,因此需要分层编译. 即时编译的优化是基于假设(运行态的状态转换以及分布),如果失败,在与假设原因相关时,需要做去优化.
2021-02-12 - 剑八 👍(0) 💬(0)
即时编绎器的优化: 1.将高频代码变成机器码,减少翻译的性能消耗 高频代码有:方法,及循环中的代码 2.基于条件假设 就是将相应的条件判断根据信息来进行剪枝,减少程序流。 如果优化的机器码在执行时发现没走到这个分支会触发一个陷阱代码,采用解释执行
2020-06-14 - 饭粒 👍(0) 💬(0)
给我的感觉是 JVM 基于代码执行数据的收集分析(有点像是用概率统计、机器学习来分析收集的代码执行数据 profiling),在不改变代码最终执行逻辑的正确性下,优化代码的执行。无法优化的情况下再回退优化。
2019-12-23 - 随心而至 👍(0) 💬(0)
Windows需要下载对应的dll文件,Google了对应的下载地址 https://github.com/LiuDui/JavaTools
2019-10-18