14 代码模型(下):如何保证领域模型与代码模型的一致性?
你好,我是欧创新。
在 [第 12 讲] 中,我们了解了如何用事件风暴来构建领域模型,在构建领域模型的过程中,我们会提取出很多的领域对象,比如聚合、实体、命令和领域事件等。到了 [第 13 讲],我们又根据DDD分层架构模型,建立了标准的微服务代码模型,为代码对象定义好了分层和目录结构。
那要想完成微服务的设计和落地,这之后其实还有一步,也就是我们今天的重点——将领域对象映射到微服务代码模型中。那为什么这一步如此重要呢?
DDD强调先构建领域模型然后设计微服务,以保证领域模型和微服务的一体性,因此我们不能脱离领域模型来谈微服务的设计和落地。但在构建领域模型时,我们往往是站在业务视角的,并且有些领域对象还带着业务语言。我们还需要将领域模型作为微服务设计的输入,对领域对象进行设计和转换,让领域对象与代码对象建立映射关系。
接下来我们围绕今天的重点,详细来讲一讲。
领域对象的整理
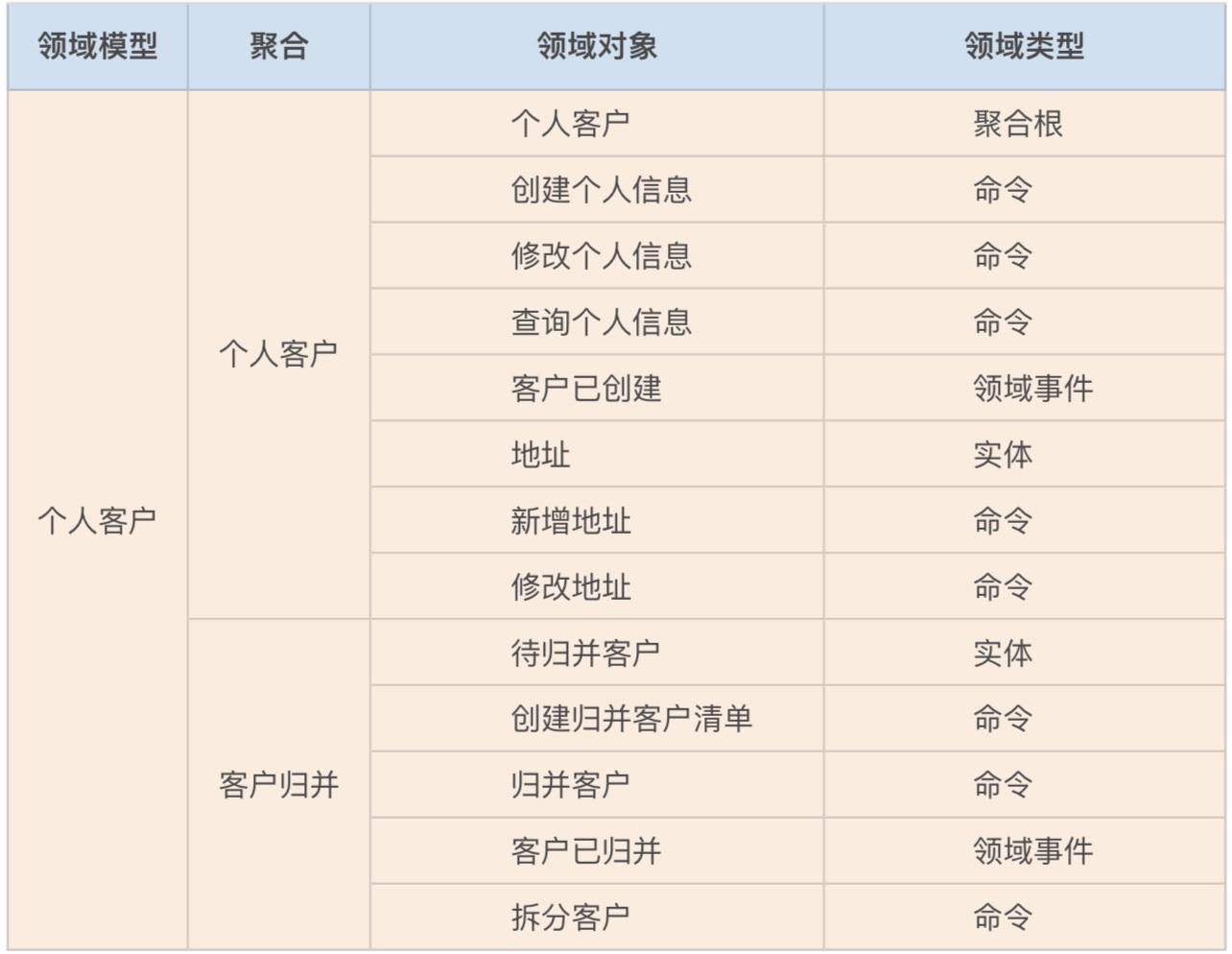
完成微服务拆分后,领域模型的边界和领域对象就基本确定了。
我们第一个重要的工作就是,整理事件风暴过程中产生的各个领域对象,比如:聚合、实体、命令和领域事件等内容,将这些领域对象和业务行为记录到下面的表格中。
你可以看到,这张表格里包含了:领域模型、聚合、领域对象和领域类型四个维度。一个领域模型会包含多个聚合,一个聚合包含多个领域对象,每个领域对象都有自己的领域类型。领域类型主要标识领域对象的属性,比如:聚合根、实体、命令和领域事件等类型。
从领域模型到微服务的设计
从领域模型到微服务落地,我们还需要做进一步的设计和分析。事件风暴中提取的领域对象,还需要经过用户故事或领域故事分析,以及微服务设计,才能用于微服务系统开发。
这个过程会比事件风暴来的更深入和细致。主要关注内容如下:
- 分析微服务内有哪些服务?
- 服务所在的分层?
- 应用服务由哪些服务组合和编排完成?
- 领域服务包括哪些实体的业务逻辑?
- 采用充血模型的实体有哪些属性和方法?
- 有哪些值对象?
- 哪个实体是聚合根等?
- 最后梳理出所有的领域对象和它们之间的依赖关系,我们会给每个领域对象设计对应的代码对象,定义它们所在的软件包和代码目录。
这个设计过程建议参与的角色有:DDD专家、架构师、设计人员和开发经理。
领域层的领域对象
事件风暴结束时,领域模型聚合内一般会有:聚合、实体、命令和领域事件等领域对象。在完成故事分析和微服务设计后,微服务的聚合内一般会有:聚合、聚合根、实体、值对象、领域事件、领域服务和仓储等领域对象。
下面我们就来看一下这些领域对象是怎么得来的?
1. 设计实体
大多数情况下,领域模型的业务实体与微服务的数据库实体是一一对应的。但某些领域模型的实体在微服务设计时,可能会被设计为多个数据实体,或者实体的某些属性被设计为值对象。
我们分析个人客户时,还需要有地址、电话和银行账号等实体,它们被聚合根引用,不容易在领域建模时发现,我们需要在微服务设计过程中识别和设计出来。
在分层架构里,实体采用充血模型,在实体类内实现实体的全部业务逻辑。这些不同的实体都有自己的方法和业务行为,比如地址实体有新增和修改地址的方法,银行账号实体有新增和修改银行账号的方法。
实体类放在领域层的Entity目录结构下。
2. 找出聚合根
聚合根来源于领域模型,在个人客户聚合里,个人客户这个实体是聚合根,它负责管理地址、电话以及银行账号的生命周期。个人客户聚合根通过工厂和仓储模式,实现聚合内地址、银行账号等实体和值对象数据的初始化和持久化。
聚合根是一种特殊的实体,它有自己的属性和方法。聚合根可以实现聚合之间的对象引用,还可以引用聚合内的所有实体。聚合根类放在代码模型的Entity目录结构下。聚合根有自己的实现方法,比如生成客户编码,新增和修改客户信息等方法。
3. 设计值对象
根据需要将某些实体的某些属性或属性集设计为值对象。值对象类放在代码模型的Entity目录结构下。在个人客户聚合中,客户拥有客户证件类型,它是以枚举值的形式存在,所以将它设计为值对象。
有些领域对象可以设计为值对象,也可以设计为实体,我们需要根据具体情况来分析。如果这个领域对象在其它聚合内维护生命周期,且在它依附的实体对象中只允许整体替换,我们就可以将它设计为值对象。如果这个对象是多条且需要基于它做查询统计,我建议将它设计为实体。
4. 设计领域事件
如果领域模型中领域事件会触发下一步的业务操作,我们就需要设计领域事件。首先确定领域事件发生在微服务内还是微服务之间。然后设计事件实体对象,事件的发布和订阅机制,以及事件的处理机制。判断是否需要引入事件总线或消息中间件。
在个人客户聚合中有客户已创建的领域事件,因此它有客户创建事件这个实体。
领域事件实体和处理类放在领域层的Event目录结构下。领域事件的发布和订阅类我建议放在应用层的Event目录结构下。
5. 设计领域服务
如果一个业务动作或行为跨多个实体,我们就需要设计领域服务。领域服务通过对多个实体和实体方法进行组合,完成核心业务逻辑。你可以认为领域服务是位于实体方法之上和应用服务之下的一层业务逻辑。
按照严格分层架构层的依赖关系,如果实体的方法需要暴露给应用层,它需要封装成领域服务后才可以被应用服务调用。所以如果有的实体方法需要被前端应用调用,我们会将它封装成领域服务,然后再封装为应用服务。
个人客户聚合根这个实体创建个人客户信息的方法,被封装为创建个人客户信息领域服务。然后再被封装为创建个人客户信息应用服务,向前端应用暴露。
领域服务类放在领域层的Service目录结构下。
6. 设计仓储
每一个聚合都有一个仓储,仓储主要用来完成数据查询和持久化操作。仓储包括仓储的接口和仓储实现,通过依赖倒置实现应用业务逻辑与数据库资源逻辑的解耦。
仓储代码放在领域层的Repository目录结构下。
应用层的领域对象
应用层的主要领域对象是应用服务和事件的发布以及订阅。
在事件风暴或领域故事分析时,我们往往会根据用户或系统发起的命令,来设计服务或实体方法。为了响应这个命令,我们需要分析和记录:
- 在应用层和领域层分别会发生哪些业务行为;
- 各层分别需要设计哪些服务或者方法;
- 这些方法和服务的分层以及领域类型(比如实体方法、领域服务和应用服务等),它们之间的调用和组合的依赖关系。
在严格分层架构模式下,不允许服务的跨层调用,每个服务只能调用它的下一层服务。服务从下到上依次为:实体方法、领域服务和应用服务。
如果需要实现服务的跨层调用,我们应该怎么办?我建议你采用服务逐层封装的方式。
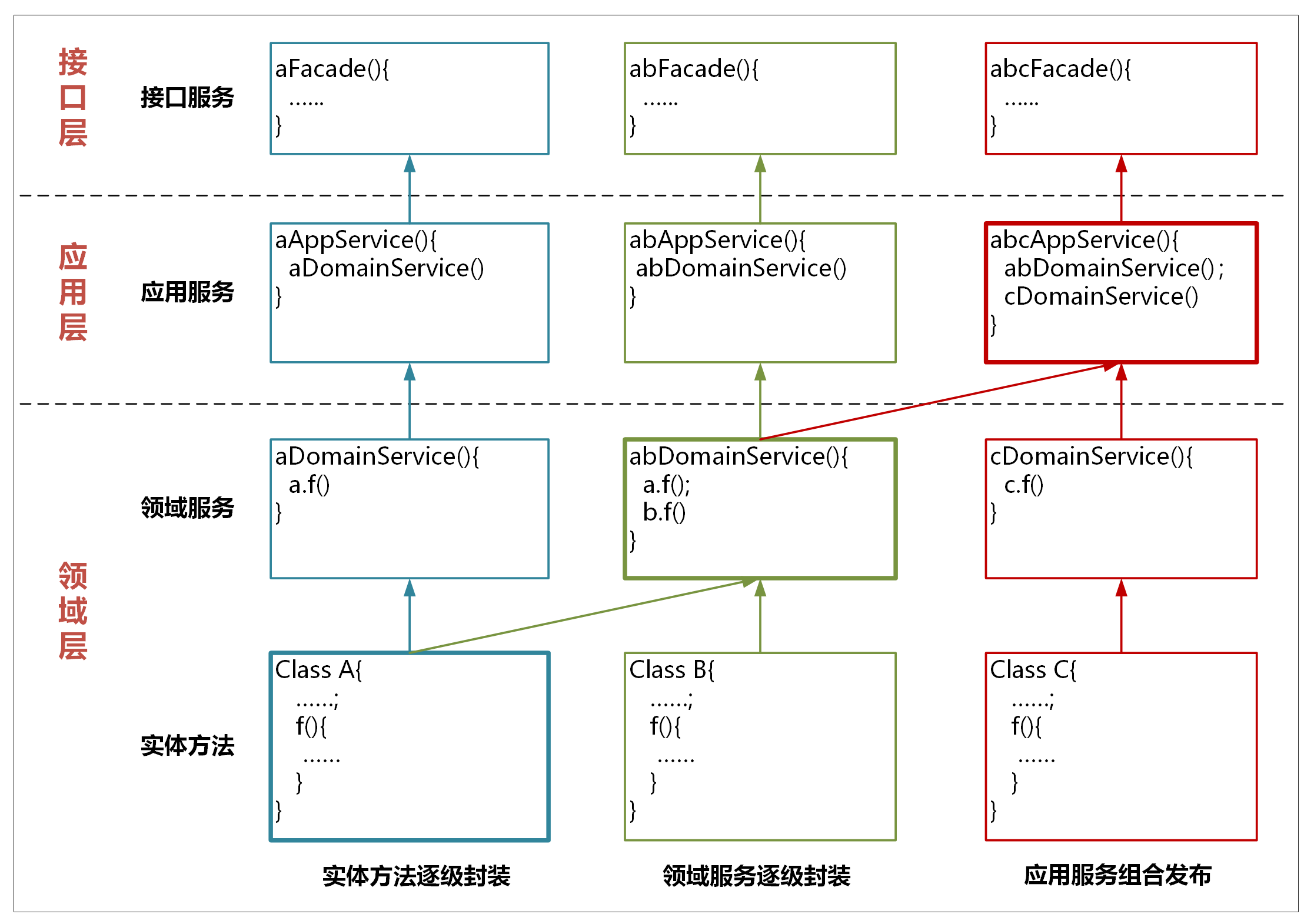
我们看一下上面这张图,服务的封装和调用主要有以下几种方式。
1. 实体方法的封装
实体方法是最底层的原子业务逻辑。如果单一实体的方法需要被跨层调用,你可以将它封装成领域服务,这样封装的领域服务就可以被应用服务调用和编排了。如果它还需要被用户接口层调用,你还需要将这个领域服务封装成应用服务。经过逐层服务封装,实体方法就可以暴露给上面不同的层,实现跨层调用。
封装时服务前面的名字可以保持一致,你可以用*DomainService或*AppService后缀来区分领域服务或应用服务。
2. 领域服务的组合和封装
领域服务会对多个实体和实体方法进行组合和编排,供应用服务调用。如果它需要暴露给用户接口层,领域服务就需要封装成应用服务。
3.应用服务的组合和编排
应用服务会对多个领域服务进行组合和编排,暴露给用户接口层,供前端应用调用。
在应用服务组合和编排时,你需要关注一个现象:多个应用服务可能会对多个同样的领域服务重复进行同样业务逻辑的组合和编排。当出现这种情况时,你就需要分析是不是领域服务可以整合了。你可以将这几个不断重复组合的领域服务,合并到一个领域服务中实现。这样既省去了应用服务的反复编排,也实现了服务的演进。这样领域模型将会越来越精炼,更能适应业务的要求。
应用服务类放在应用层Service目录结构下。领域事件的发布和订阅类放在应用层Event目录结构下。
领域对象与微服务代码对象的映射
在完成上面的分析和设计后,我们就可以建立像下图一样的,领域对象与微服务代码对象的映射关系了。
典型的领域模型
个人客户领域模型中的个人客户聚合,就是典型的领域模型,从聚合内可以提取出多个实体和值对象以及它的聚合根。
我们看一下下面这个图,我们对个人客户聚合做了进一步的分析。提取了个人客户表单这个聚合根,形成了客户类型值对象,以及电话、地址、银行账号等实体,为实体方法和服务做了封装和分层,建立了领域对象的关联和依赖关系,还有仓储等设计。关键是这个过程,我们建立了领域对象与微服务代码对象的映射关系。
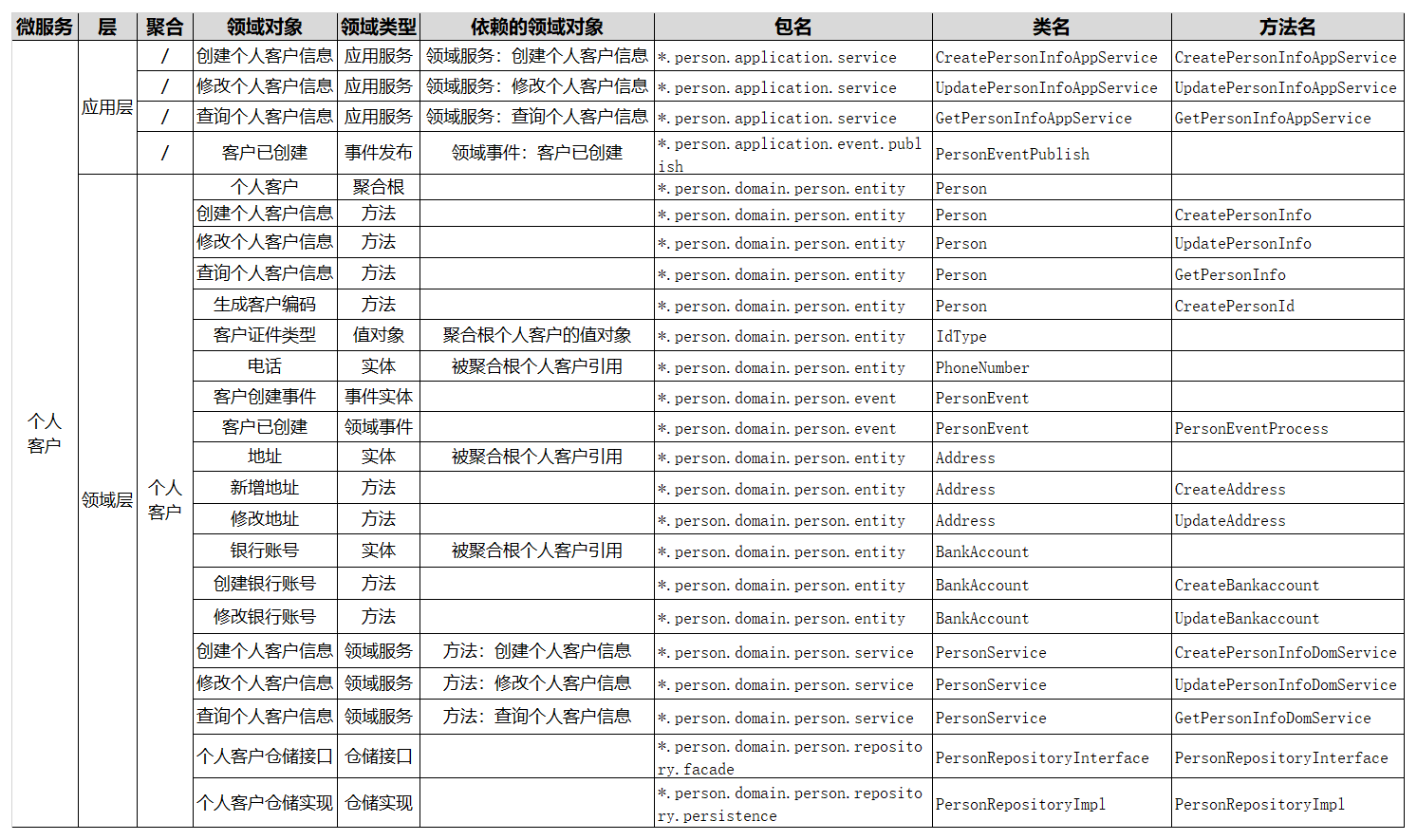
下面我对表格的各栏做一个简要的说明。
- 层:定义领域对象位于分层架构中的哪一层,比如:接口层、应用层、领域层以及基础层等。
- 领域对象:领域模型中领域对象的具体名称。
- 领域类型:根据DDD知识体系定义的领域对象的类型,包括:限界上下文、聚合、聚合根、实体、值对象、领域事件、应用服务、领域服务和仓储服务等领域类型。
- 依赖的领域对象:根据业务对象依赖或分层调用的依赖关系,建立的领域对象的依赖关系,比如:服务调用依赖、关联对象聚合等。
- 包名:代码模型中的包名,对应领域对象所在的软件包。
- 类名:代码模型中的类名,对应领域对象的类名。
- 方法名:代码模型中的方法名,对应领域对象实现或操作的方法名。
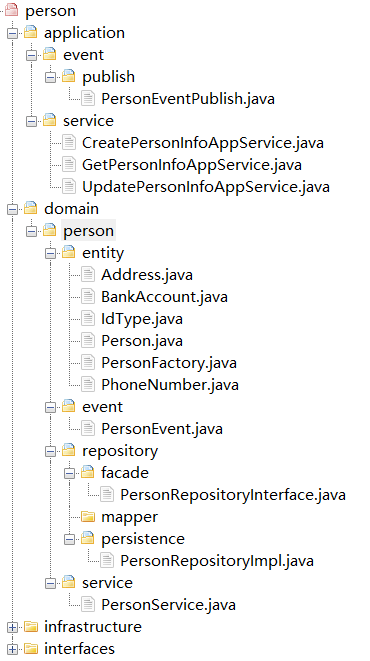
在建立这种映射关系后,我们就可以得到如下图的微服务代码结构了。
非典型领域模型
有些业务场景可能并不能如你所愿,你可能无法设计出典型的领域模型。这类业务中有多个实体,实体之间相互独立,是松耦合的关系,这些实体主要参与分析或者计算,你找不出聚合根,但就业务本身来说它们是高内聚的。而它们所组合的业务与其它聚合是在一个限界上下文内,你也不大可能将它单独设计为一个微服务。
这种业务场景其实很常见。比如,在个人客户领域模型内有客户归并的聚合,它扫描所有客户,按照身份证号码、电话号码等是否重复的业务规则,判断是否是重复的客户,然后对重复的客户进行归并。这种业务场景你就找不到聚合根。
那对于这类非典型模型,我们怎么办?
我们还是可以借鉴聚合的思想,仍然用聚合来定义这部分功能,并采用与典型领域模型同样的分析方法,建立实体的属性和方法,对方法和服务进行封装和分层设计,设计仓储,建立领域对象之间的依赖关系。唯一可惜的就是我们依然找不到聚合根,不过也没关系,除了聚合根管理功能外,我们还可以用DDD的其它设计方法。
总结
今天我们学习了从领域模型到微服务的设计过程,这个过程在微服务设计过程中非常的关键。你需要从微服务系统的角度,对领域模型做深入、细致的分析,为领域对象分层,找出各个领域对象的依赖关系,建立领域对象与微服务代码对象的映射关系,从而保证领域模型与代码模型的一致性,最终完成微服务的设计。
在建立这种业务模型与微服务系统架构的关系后,整个项目团队就可以在统一的通用语言下工作,即使不熟悉业务的开发人员,或者不熟悉代码的业务人员,也可以很快就定位到代码位置。
思考题
分析一下基于DDD领域模型的微服务设计方式,和你公司现在所进行的微服务设计,或者和你了解到的微服务设计,有什么不同?
期待你的分享,我们一同交流!
- 伊来温 👍(25) 💬(13)
我的回复怎么不见了,再发一下。请教下老师,关于领域代码的分层和编排上一直以来我有个一个疑问。假设我有两个领域聚合跟,用户(User)和企业(Corp),对应的领域服务是UserDomianService和CorpDomainService,那我假如需要这个一个接口listCoprUser来获取企业下面的用户列表, 这个接口该放在哪一层做编排呢。1. 如果放在CorpDomainService里面,则会造成对User实体的引用,造成耦合。2.难道上升到app层做编排么?但listCoprUser又像是一个领域服务。3.又或者做成一个新的领域服务CorpUserDomainService吗?那是不是CorpUserDomainService在代码结构上只有一个领域服务,而没有repository, domain层级了呢?
2020-07-02 - Jack.Chen 👍(16) 💬(6)
希望把完整样例代码放出来
2019-12-30 - 冯磊 👍(13) 💬(4)
感觉application这一层完全可以去掉,intrerface直接调domain service就可以的。作者能解释一下application这一层为什么必须存在吗?
2020-06-29 - suke 👍(12) 💬(4)
老师 请问依赖倒置是如何体现的?还有所谓的充血模式,最好能有具体的代码说明,不然还是觉得很空洞
2020-06-27 - ANYI 👍(5) 💬(7)
1,对于实体采用充血模型,包含自己的属性及行为,例如保持、更新、删除等行为方法,需要持久化,依赖基础层数据库操作,是在实体直接引入,例如mybatis的mapper? 2,对于相对简单的实体操作增删改查这种,需要暴露到接口层;那要一层一层向上封装,实体》领域服务》应用服务》接口服务;这样是不是又显得代码很多余;一个简单的增加修改方法接口,需要很多冗余代码,上层也没有其他逻辑,封装一下调用下层,写一个接口,要写很多层次调用,是否会很臃肿啰嗦,是不是就可以直接接口层封装就省去一些层呢? 3,在服务编排上有没有一些框架什么的?还是都是通过if else的手写?
2019-11-15 - Jxin 👍(5) 💬(1)
1.同求代码案例。(基于一个非ddd微服务的demo,分支形式实现微服务内部代码规范,跨服务间代码重组) 2.代码案例这个成本很大,但还是厚颜无耻的提了。毕竟缺少代码这个实体,这个专栏感觉就少点东西。毕竟讲得再抽象精准,可能也没有展示code来得直接明了。 3.我们需要从实悟虚,从虚就实。如果理论能结合code案例,这个专栏的学习成本和实用性将会有质得飞跃。
2019-11-15 - 日月星辰 👍(4) 💬(1)
同一个微服务里不同领域之间的调用可以在应用层直接调用吗?
2020-06-02 - Peter Yu 👍(3) 💬(1)
老师,aDomainService何以调用bDomainService的方法吗。比如之前有个同学提问:Corp和User属于两个领域,但是Corp中有个查询user的服务,你建议他将此方法放在domainService层,那同步user的数据时,corpDomainService岂不是得调用userDomainService了?
2020-11-26 - Geek_deb968 👍(3) 💬(3)
大部分业务场景其实都是查询的比较多,关于领域模型我现在看到的和理解到的都是实体简单业务操作,我十分希望能看到关于查询在DDD上代码是怎么实现的,比如门店是一个聚合根,门店菜系设计为值对象,那么我根据菜系查询门店是不是在领域模型上很难操作了,感觉领域模型都是在实体也就是满足确定了唯一标识的情况下,才能发挥作用,动态的查询在DDD上是需要怎样实现呢
2020-03-28 - 峰 👍(3) 💬(1)
如何识别出聚合根?
2020-03-21 - 有爱有波哥 👍(2) 💬(1)
老师说的在DDD领域模型中主要是基于聚合根的id的查询,这个不理解,那复杂查询怎么设计,能给点建议和思路吗
2020-11-11 - Jesen 👍(2) 💬(1)
老师,如果把仓储Respository的实现放到基础设施层,其仓储接口定义在领域层里面,那么在领域层里面该怎么持久化呢,可以通过在应用层中将仓储注入到领域服务里面来实现吗?
2019-11-29 - Even He 👍(1) 💬(1)
老师您好。想请教一个问题。 例子中,遵循了严格的分层方式,即不允许跨层调用。如appService需要调用entity的方法需要通过domainService。(虽然我觉得appService调entity也不算跨层,理由是application层和domain层中间没有其他的层。) 那interface中的assembler,它的职责是将dto转化成domain object。这个处理如果实在interface种执行,是不是变成了跨层调用? 期待您的回复。谢谢。
2020-11-03 - 一两 👍(1) 💬(1)
老师,聚合或实体可以直接调用仓储接口吗?为什么网上有的说法是仓储接口应该在应用层调用,感觉应用层调用仓储接口的话,难免会把业务逻辑拆的四分五裂把
2020-10-26 - 赵宇浩 👍(1) 💬(4)
问题一: 假如用户是个复杂聚合根,同时存在List的操作一般怎么处理。 比如支持单用户信息创建以及批量用户信息创建。 单用户的实体创建包含基本信息校验和仓储写入两个步骤。 但批量创建不太可能循环调用每个用户的创建方法吧。 所以这样就要给用户这个类再加个基本信息校验的方法? 然后领域服务层,循环校验之后,再批量写入? 但这样用户这个类,就要有两个构造方法? 一个需要持有仓储(单用户操作), 一个不需要持有仓储(用于多用户操作)? 问题二: 比如用户里包含了地址和账户。 那么仓储的事务怎么考虑,事务也由用户这个类去保证么?还是事务在领域服务里实现? 实现一:在用户实体里持有用户仓储,账户实体里持有账户仓储,然后用户创建的方法里,先调用账户的写入方法,再调用自己的仓储保存,如果自己存储失败,回滚?听上去好像可以实现,也符合逻辑。但是感觉这个类的每次实例初始化是不是有点麻烦。 实现二:实体不持有仓储,领域服务是单例的,就可以直接注入用户,账户,地址的仓储,然后只是组装内存数据,在领域服务层依次调用仓储,保证事务。也可以实现,但这样实体的责任是不是太弱了,这个领域服务层和三层架构的service层是不是有点像。 不知道实际中怎么做更推荐,望指导
2020-02-10