22 协议编解码:接口调用的数据是如何发到网络中的?
你好,我是何辉。今天我们深入研究Dubbo源码的最后一篇,协议编解码。
你已经学过了 Dubbo 框架的十大模块(01讲),上一讲也掌握消费方调用的整体框架流程,基本把 Dubbo 框架纵向走了一遍,但依然在单进程中转悠。而 Dubbo 的本质就是网络通信,要想把数据发到网络送往提供方,默认用 Netty 网络通信框架完成的。
那发起接口调用时,你创建出来的一个普普通通的请求对象,到底是如何被编解码后发到网络中的呢?如果你平常不怎么接触底层,这个问题想回答好确实有点难。不过不用担心,我们也研究了不少源码,按套路,根据一些蛛丝马迹顺着研究,解答这个问题其实就是一层窗户纸的事。
什么是帧格式?
想回答清楚今天的问题,我们从一个概念开始,帧格式。
所谓的“帧格式”,就是指根据不同协议规定的数据传输的格式。举个常见的 TCP/IP 模型,分别有应用层、传输层、网络层、数据链路层,以及物理层,每一层都有着对应的数据帧格式。
我们以数据封装的过程为例。
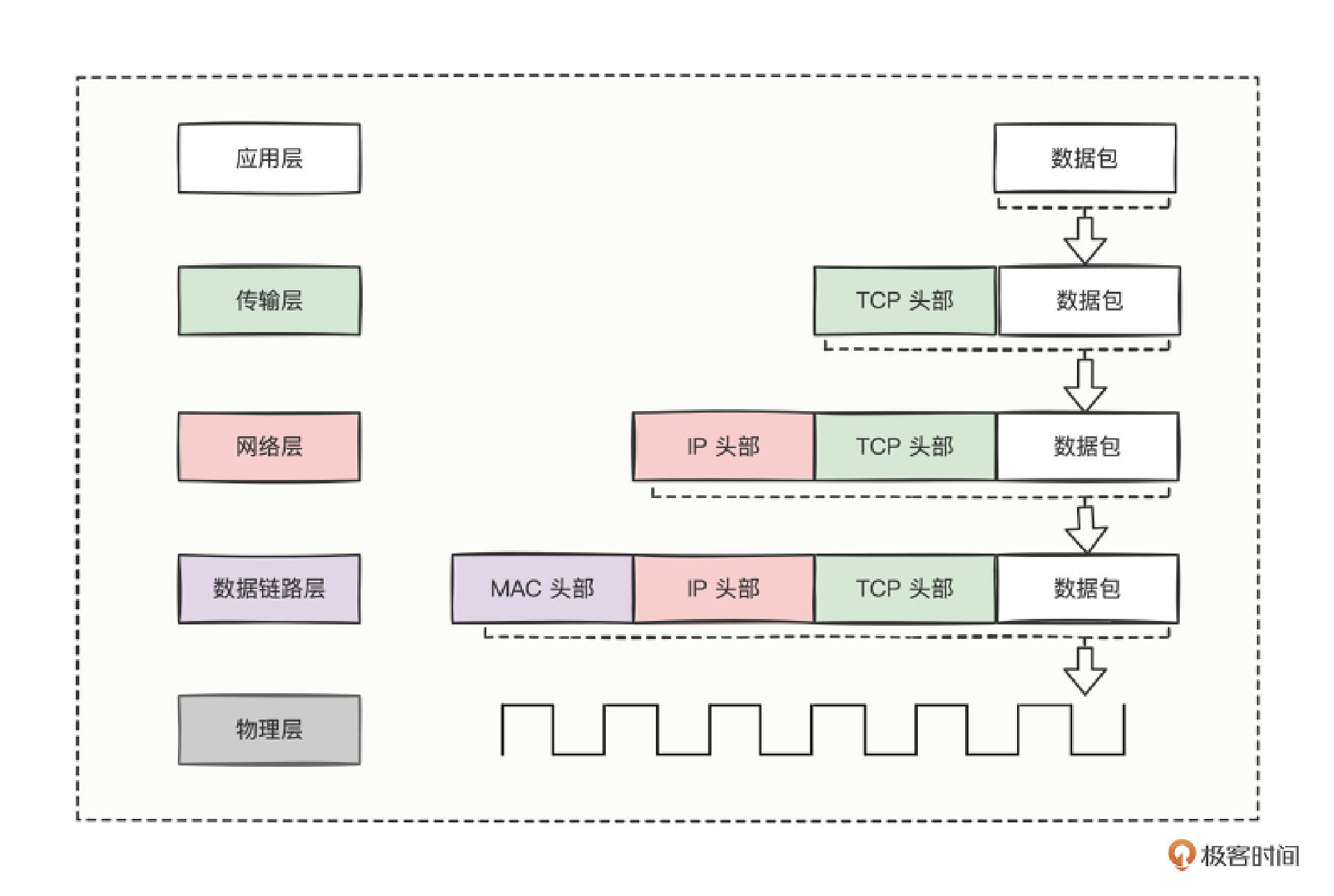
比如,应用层的数据包+TCP头部就是传输层的帧格式,传输层的数据包+IP头部就是网络层的帧格式,网络层的数据包+MAC头部就是数据链路层的帧格式,最后,会把数据链路层的整个数据包,变成比特流,通过工作在物理层的网卡、网线或光纤发送出去。
这是我们从 TCP/IP 模型层面认识帧格式,那对于这样的数据传输格式,在客户端向服务端发送数据的实际交互过程中,又是如何体现的呢?
我们看一个日常开发的交互案例。
client 把数据发往 server,这种交互形式估计你是再熟悉不过了。我们模拟一下数据的收发过程。
1. 固定长度
现在我们有 100 字节的数据,需要通过 client 发送出去,可是 client 的发送缓冲区太小了,缓冲区每次只能容纳 50 字节大小。所以,client 利用 socket 进行了 2 次 write 操作,才把 100 字节发送出去。
但是对于收数据的 server 来说,什么时候才认为数据接收齐全了呢?
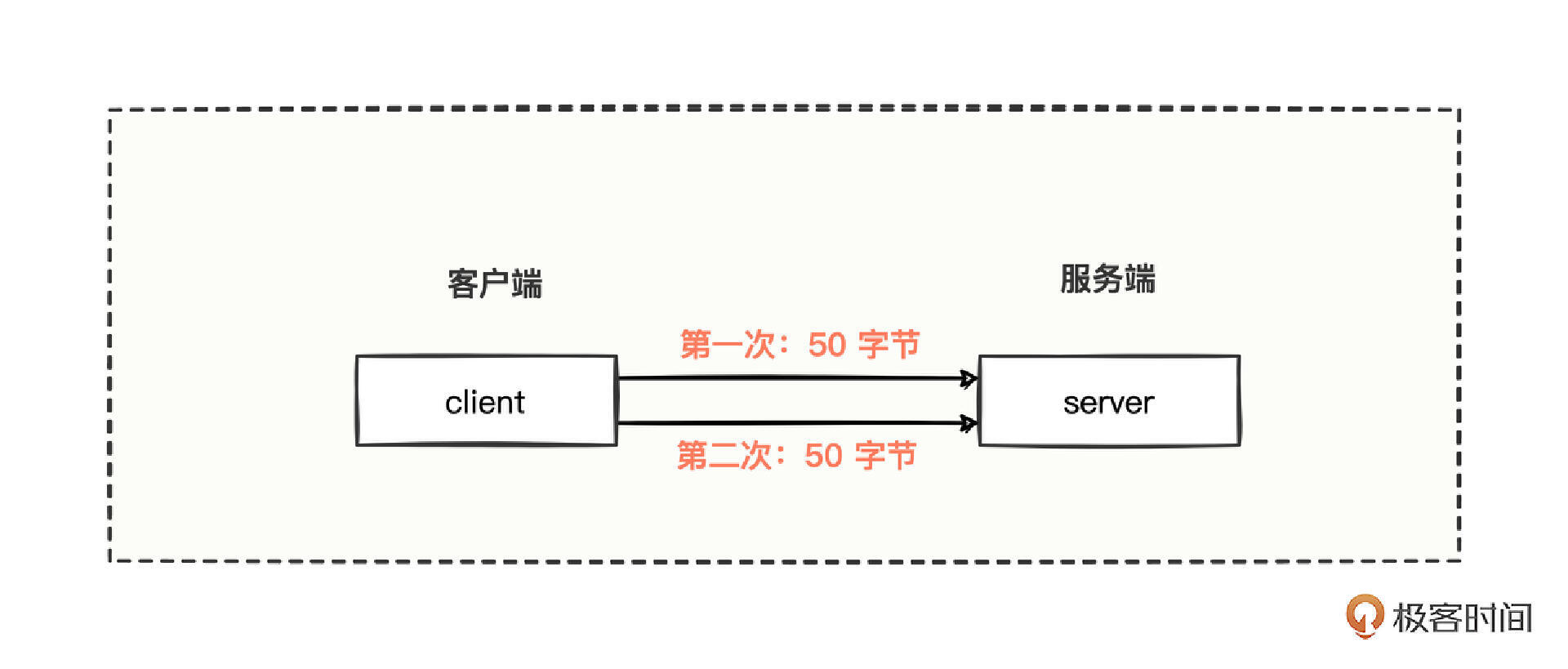
server 其实是很疑惑的,接收 client 第一次发来的数据后,到底该不该收 client 第二次发来的数据呢?若是不收的话,会不会造成少收数据?若是收,到底收多少数据才算完整呢?
为了解决种种疑惑,client 和 server 进行了双方的约定,按照固定长度直接进行收发。
在这个场景里约定 client 发起的一次短链接请求,server 收满 100 个字节就可以结束了。如果 client 发了 120 个字节,server 已经收下 100 个字节后,再继续收到 20 个字节时,发现 client 结束会话了,那么,server 会认为这20字节没有满 100 个字节,就干脆丢弃不要了。
2. 分隔符
看来长度的约定很重要,但是,这个长度到底该定义多少合适呢?
若短了,会增加通信的次数,增加双方的通信压力;若长了,比如定义为 1000 个字节,但是大多数情况下数据都是 1000 ~ 1100 个长度,岂不是 client 每次都要多发 900 ~ 1000 个没有意义的内容给到 server,不然 server 就会抛弃掉 client 第二次发送的数据。
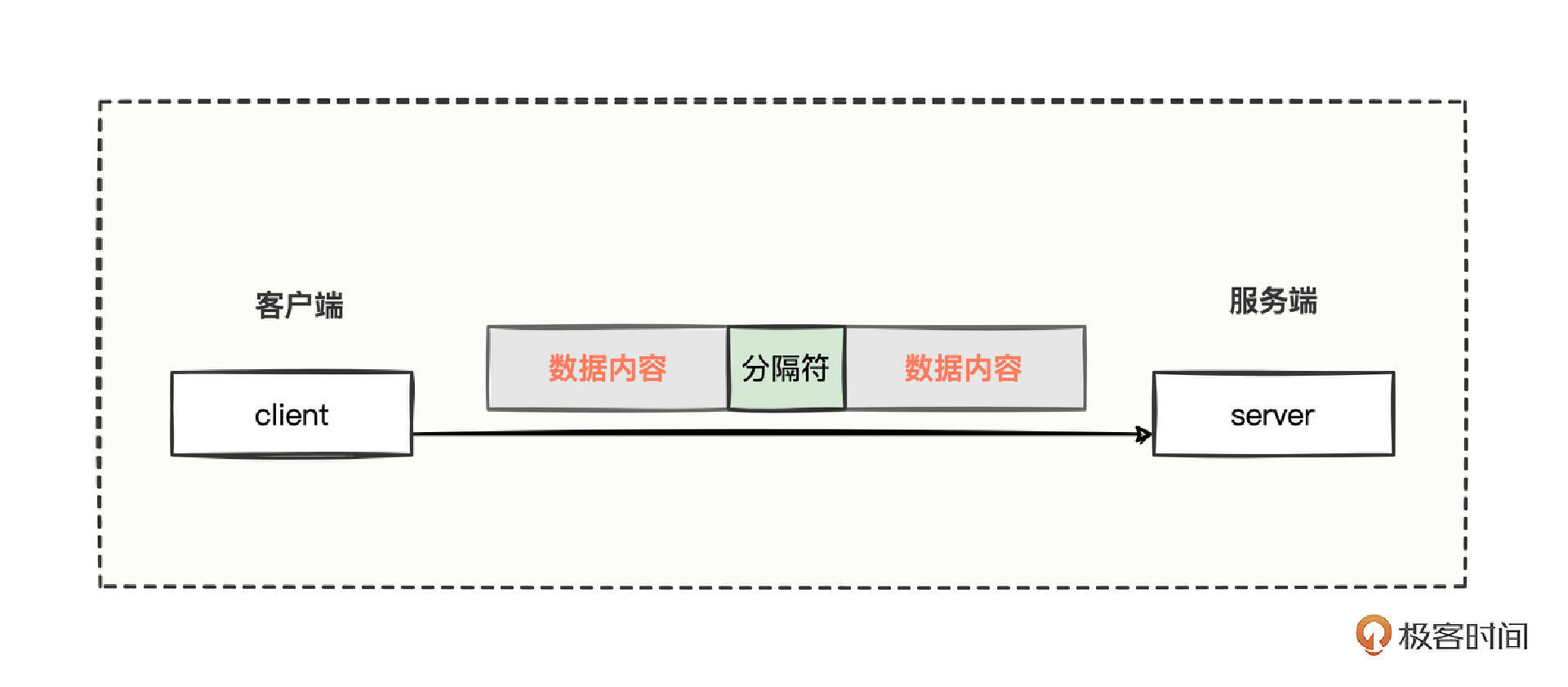
所以 client 又和 server 进行了约定,约定按照特殊字符切割。比如 client 给 server 发了一堆的数据,server 先一股脑全接收,当 server 碰到特殊字符时就切割开,然后继续接收新的一个数据包。
这也不失为一种办法,总比数据被丢弃好得多。
3. 定长+变长
可是试行了一段时间后,client 还是觉得有问题,因为有些数据内容如果含有分隔符,也被切割了。如果能有一种特殊的前缀标识就好了,识别到这种标识,就读多少数据,貌似更可行。
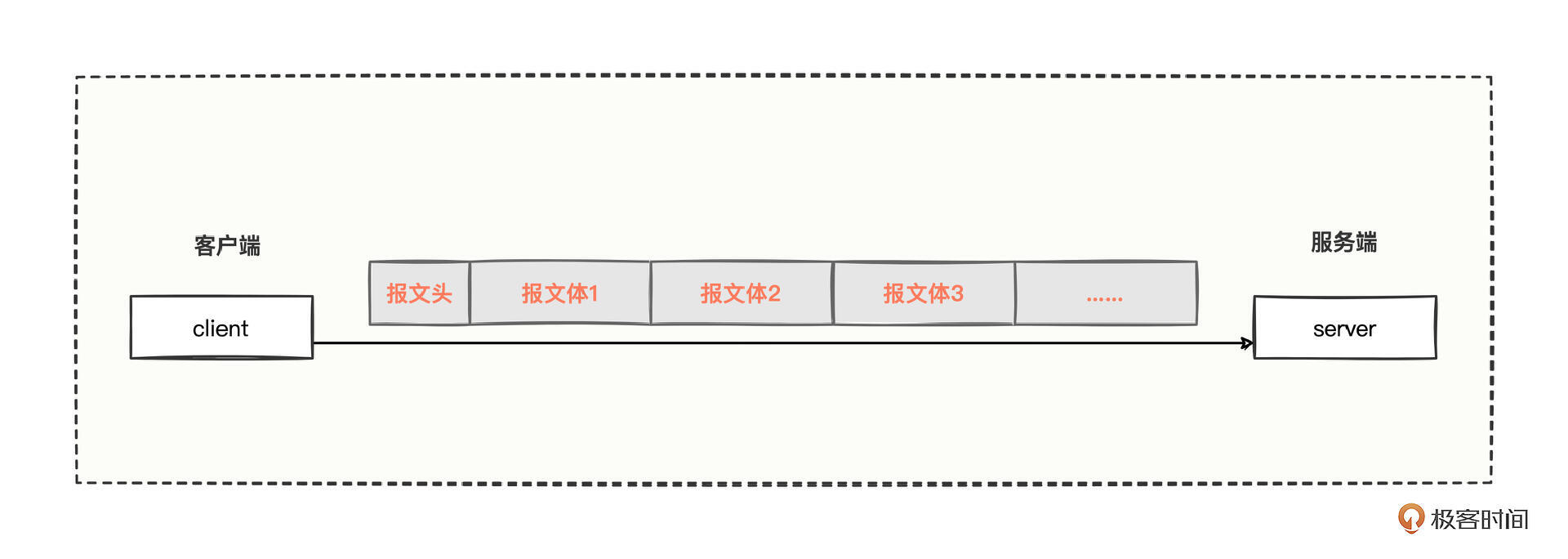
于是 client 又和 server 进行了约定,约定数据格式由两部分组成,报文头、报文体。报文头是固定长度,里面有特殊的前缀标识、报文体的总长度;而报文体,长度是可变的,有多少数据就有多少长度。
好,我们从固定长度,到分隔符,到定长+变长,梳理了三种 client 与 server 的约定传输数据方式,你也应该发现了,其实这就是约定数据如何传输的协议格式,约定是怎样的格式,那就按照怎样的格式进行收发处理。而这种约定数据包格式的方式,就是我们俗称的“数据帧格式”。
那 Dubbo 框架把对象编解码后变成了什么样的帧格式呢?
Dubbo 帧格式
问题来了,偌大的 Dubbo 源码工程,我们该怎么从源码层面找到底层是如何编解码的呢?
其实之前我们已经见过了,“源码框架”中的 Serialize 模块属于哪个层次?“调用流程”中将对象进行序列化的代码入口在哪里?
没错,想必你也想到了,我们可以顺着 NettyCodecAdapter 这个类的 encode 方法看源码,应该就可以找到了。
实践是检验真理的唯一标准,我们打个断点去 Debug 调试一下。启动 ZooKeeper 和提供方,然后 Debug 启动消费方,一会就来到了 encode 方法:
我们单步调试进去,先经过了 DubboCountCodec 类,然后经过了 ExchangeCodec 类,结果发现了一段惊喜的代码。
///////////////////////////////////////////////////
// org.apache.dubbo.remoting.exchange.codec.ExchangeCodec#encode
// 交换信息编解码操作,主要是将 Request、Response 对象按照 Dubbo 协议格式编码为字节流
///////////////////////////////////////////////////
@Override
public void encode(Channel channel, ChannelBuffer buffer, Object msg) throws IOException {
// 如果是需要发送给提供方的对象,那么就调用 encodeRequest 进行编码
if (msg instanceof Request) {
encodeRequest(channel, buffer, (Request) msg);
}
// 如果是响应给提供方的对象,那么就调用 encodeResponse 进行编码
else if (msg instanceof Response) {
encodeResponse(channel, buffer, (Response) msg);
}
// 如果是其他类型对象的话,那么就调用父类的通用 encode 方法进行编码操作
else {
super.encode(channel, buffer, msg);
}
}
从这段代码中,确实发现了一段非常有亮点的代码,逻辑也不多,就 3 条分支逻辑,一条是针对请求对象进行编码的分支,一条是针对响应对象进行编码的分支,最后一条是调用了父类的 encode 方法进行编码的分支。
虽然分支逻辑不多,但是我们从方法名上已经发现了端倪,这不就是即将要对 Request 和 Response 对象进行编码操作么?继续前进,我们进入 encodeRequest 方法看个究竟。
///////////////////////////////////////////////////
// 1、org.apache.dubbo.remoting.exchange.codec.ExchangeCodec#encodeRequest
// 2、将 Request 对象按照 Dubbo 协议格式编码为字节流
// 3、重点关注我在代码中描述的 ①②③④⑤⑥ 几个关键位置
///////////////////////////////////////////////////
// header length.
protected static final int HEADER_LENGTH = 16;
// magic header.
protected static final short MAGIC = (short) 0xdabb;
protected static final byte MAGIC_HIGH = Bytes.short2bytes(MAGIC)[0];
protected static final byte MAGIC_LOW = Bytes.short2bytes(MAGIC)[1];
// message flag.
protected static final byte FLAG_REQUEST = (byte) 0x80;
protected static final byte FLAG_TWOWAY = (byte) 0x40;
protected static final byte FLAG_EVENT = (byte) 0x20;
protected static final int SERIALIZATION_MASK = 0x1f;
// 将 Request 对象按照 Dubbo 协议格式编码为字节流
protected void encodeRequest(Channel channel, ChannelBuffer buffer, Request req) throws IOException {
Serialization serialization = getSerialization(channel, req);
// header.
// ① 针对 header 字节数组赋值一个 0xdabb 魔术值
byte[] header = new byte[HEADER_LENGTH];
// set magic number.
Bytes.short2bytes(MAGIC, header);
// set request and serialization flag.
// ② 设置序列化方式,序列化方式从 channel 的 url 取出 serialization 对应的参数值,
// 默认是 hessian2 方式,
// 而 org.apache.dubbo.common.serialize.hessian2.Hessian2Serialization#getContentTypeId 的值为 2
//
// serialization 属性值,在源码中有如下这些值:
// byte HESSIAN2_SERIALIZATION_ID = 2;
// byte JAVA_SERIALIZATION_ID = 3;
// byte COMPACTED_JAVA_SERIALIZATION_ID = 4;
// byte FASTJSON_SERIALIZATION_ID = 6;
// byte NATIVE_JAVA_SERIALIZATION_ID = 7;
// byte KRYO_SERIALIZATION_ID = 8;
// byte FST_SERIALIZATION_ID = 9;
// byte NATIVE_HESSIAN_SERIALIZATION_ID = 10;
// byte PROTOSTUFF_SERIALIZATION_ID = 12;
// byte AVRO_SERIALIZATION_ID = 11;
// byte GSON_SERIALIZATION_ID = 16;
// byte PROTOBUF_JSON_SERIALIZATION_ID = 21;
// byte PROTOBUF_SERIALIZATION_ID = 22;
// byte KRYO_SERIALIZATION2_ID = 25;
// byte MSGPACK_SERIALIZATION_ID = 27;
header[2] = (byte) (FLAG_REQUEST | serialization.getContentTypeId());
// ③ 设置请求类型,根据 mTwoWay、mEvent 来决定是怎样的请求类型
if (req.isTwoWay()) {
header[2] |= FLAG_TWOWAY;
}
if (req.isEvent()) {
header[2] |= FLAG_EVENT;
}
// ④ 设置请求唯一ID;
// set request id.
Bytes.long2bytes(req.getId(), header, 4);
// encode request data.
int savedWriteIndex = buffer.writerIndex();
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH);
ChannelBufferOutputStream bos = new ChannelBufferOutputStream(buffer);
// ⑤ 构建一个输出流,根据 mEvent 的值来将 mData 进行序列化转为字节数组
if (req.isHeartbeat()) {
// heartbeat request data is always null
bos.write(CodecSupport.getNullBytesOf(serialization));
} else {
ObjectOutput out = serialization.serialize(channel.getUrl(), bos);
if (req.isEvent()) {
encodeEventData(channel, out, req.getData());
} else {
encodeRequestData(channel, out, req.getData(), req.getVersion());
}
out.flushBuffer();
if (out instanceof Cleanable) {
((Cleanable) out).cleanup();
}
}
bos.flush();
bos.close();
int len = bos.writtenBytes();
checkPayload(channel, len);
Bytes.int2bytes(len, header, 12);
// write
buffer.writerIndex(savedWriteIndex);
buffer.writeBytes(header); // write header.
// ⑥ 最终将序列化出来的字节数组的长度填充至报文体长度位置
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH + len);
}
对这个 encodeRequest 方法仔细研读后,恍然大悟,原来 Dubbo 协议帧格式如此简单,正好就是我们协议约定中“定长 + 变长”的实现版本。
光从代码上不好看出“定长 + 变长”的可视化效果,这里我也根据源码的编写逻辑,总结了下代码所表达的数据帧格式。
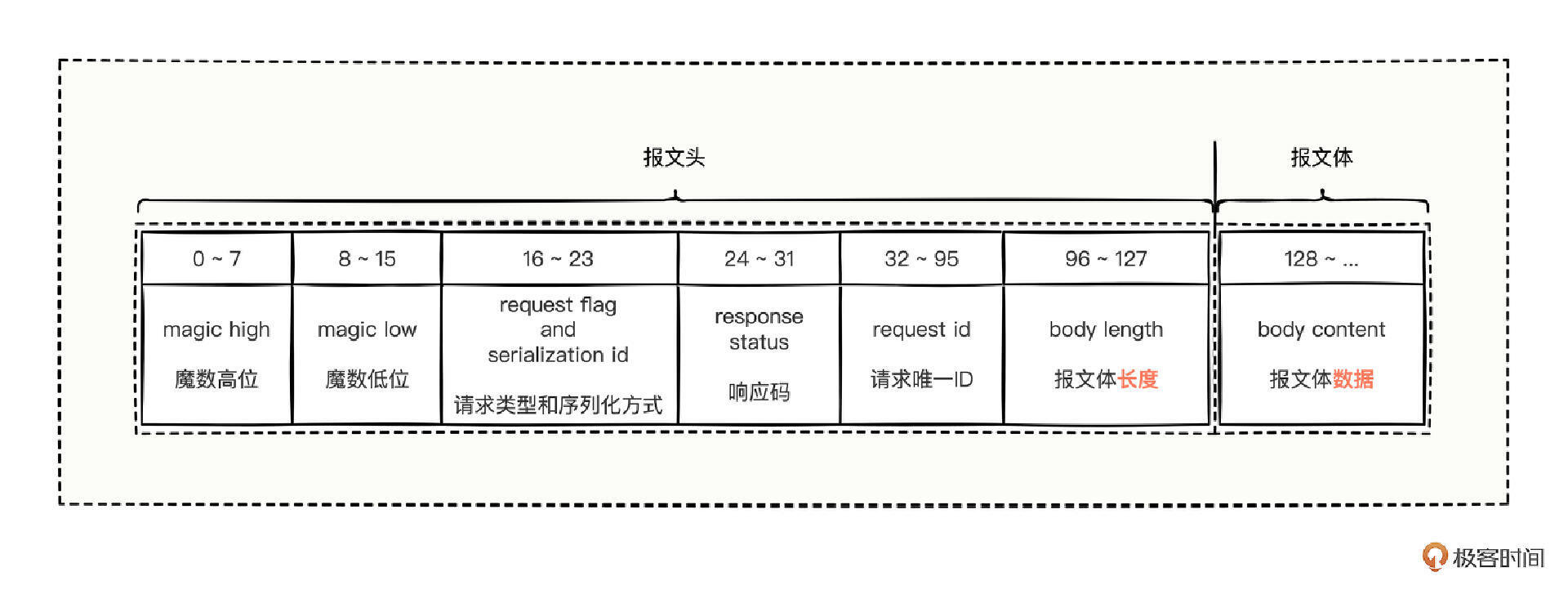
图中写的 0 ~ 7、8 ~ 15 这些数字表示的是一些 bit 位对应位置,也就是,各个方块占据了多少 bit,除以 8 得到的结果,就是占据了多少 byte(字节)。接下来,我们挨个认识一下每个小方块是什么含义:
- magic high:魔术高位,占用 8 bit,也就是 1 byte。该值固定为 0xda,是一种标识符。
- magic low:魔术低位,占用 8 bit,也就是 1 byte。该值固定为 0xbb,也是一种标识符。
魔术低位和魔术高位合并起来就是 0xdabb,代表着 dubbo 数据协议报文的开始。如果从通信 socket 收到的报文不是以 0xdabb 开始的,可以认为是非法报文。
- request flag and serialization id:请求类型和序列化方式,占用 8 bit,也就是 1 byte。前面 4 bit 是请求类型,后面 4 bit 是序列化方式,合起来用 1 个 byte 来表示。
- response status:响应码,占用 8 bit,也是 1 byte。因为已经明确是响应码了,所以一个请求发送出去的时候,不用填充这个值,响应回来的时候,这里就有值了。
但是这个响应码,并不是那些真实业务数据功能的响应码,而是 Dubbo 通信层面的错误码,比如通信响应成功码、消费方超时码、服务方超时码、请求格式错误码等等,都是一些 Dubbo 框架自己易于通信识别错误的码,并非那些真正上层业务功能的错误码。
- request id:请求唯一ID,占用 64 bit,也就是 8 byte。标识请求的唯一性,用来证明你收到的响应,就是你曾经发出去的请求返回来的数据。
- body length:报文体长度,占用 32 bit,也就是 4 byte。体现真正的业务报文数据到底有多长。
因为真实的业务数据有大有小,如果报文里不告知业务数据的长度,服务方就不知道要读取多长的字节,所以,就需要知道业务报文数据到底有多长。当客户端发送数据时,把要发送的业务数据报文计算一下长度后,放到这个位置,服务方看到该长度后,就会读取指定长度的字节,读完就结束,也就收到了一个完整的报文数据。
- body content:报文体数据,占用的 bit 未知,占用的 byte 字节个数也未知。这里是我们真正业务数据的内容,至于真正的业务数据的长度有多长,完全由报文体长度决定。
了解了 Dubbo 的协议帧格式,是不是并没有那么难,我们只需要按照上面的帧格式一步步构建出这样的字节数组,然后利用 socket,write 出去就可以了。服务方在接收数据的时候,也是一样,严格按照报文格式进行解析,不是 oxdabb 开头的就直接丢弃,是的话就继续往后读取,按照数据帧格式,直到读完整个报文为止。
好,到这里,我们详读了 encodeRequest 源码,反推出了 Dubbo 的协议帧格式,另外一个 encodeResponse 方法想必对你来说是小菜一碟了,课后你可以自己研究一下。
协议编解码的应用
Dubbo 协议的数据帧格式,是一个非常典型的协议格式案例,你以后在实际开发中,如果需要自定义数据传输报文格式,也可以参照 Dubbo 的协议数据格式,稍加改造一番,然后自行通过代码编码和解码就可以了。
除了 Dubbo 协议有这样的协议编解码的操作,其实市面上还有许许多多的应用案例,我们看 3 个常见的。
第一,HTTP 协议,是由请求行 + 请求头 + 请求体构成的,比如我们熟知的 Tomcat 容器就有这样一个 Http11Processor 的类,按照 HTTP 协议规范,来解析 HTTP 请求报文。
第二,RESP 协议,Redis 通信使用的协议,通过首字节的字符,来区分不同数据类型的序列化协议,甚至你都可以直接手写 Socket,把一段事先准备好的 RESP 报文调用 write 方法,就可以对 Redis 进行操作了。
第三,WebSocket 协议,是 HTML5 的一种新型协议,实现了浏览器与服务器的全双工通信,本质还是基于 HTTP 协议的基础之上,借助 HTTP 协议来完成握手工作的。
总结
今天,我们从已经学过的知识点中挑出一个从未深究的细节,一个接口调用时“所创建的请求对象”是如何编码发到网络中的?
针对这个问题,我们梳理了帧格式的概念,借助 client 向 server 发送数据的简单模型案例,引出了 client 与 server 约定了三种类型的协议格式,分别是固定长度、分隔符、定长+变长。
然后回忆所学的知识点,找到了 Dubbo 框架进行编码的入口,通过 Debug 模式步步深入,阅读 encodeRequest 方法后,挖掘出了把对象按照 Dubbo 协议进行编码的核心代码。

类似协议编解码的常见应用案例比如HTTP 协议、RESP 协议、WebSocket 协议等。
思考题
留个作业给你,我们已经分析了 encodeRequest 方法,你尝试自己研究一下 encodeResponse 方法的逻辑,总结一下与 encodeRequest 的异同。
期待看到你的思考,如果觉得今天的内容对你有帮助,也欢迎分享给身边的朋友一起讨论。我们下一讲见。
21 思考题参考
上一期留了个作业,研究下消费方进行泛化调用时会经历哪些流程,泛化调用的底层是如何实现的。
1.泛化调用流程
想要解答第一个问题,我们得首先有拥有一套消费方泛化调用的代码,这里我已经给你准备好了。
///////////////////////////////////////////////////
// org.apache.dubbo.remoting.transport.netty4.NettyCodecAdapter.InternalEncoder#encode
// 将对象按照一定的序列化方式发送出去
///////////////////////////////////////////////////
@Component
public class GenericDemoService {
public String invokeDemo() {
return stringStyleRpcInvoke();
}
public static String stringStyleRpcInvoke() {
ReferenceConfig<GenericService> referenceConfig =
buildReferenceConfig("com.hmilyylimh.cloud.facade.demo.DemoFacade");
referenceConfig.setGeneric("true");
// 获取泛化引用对象
GenericService genericService = referenceConfig.get();
// 返回调用
Object rpcResult = genericService.$invoke(
"sayHello",
new String[]{"java.lang.String"},
new Object[]{"Generic Demo"});
// 返回结果
return (String) rpcResult;
}
private static ReferenceConfig<GenericService> buildReferenceConfig(String interfaceName) {
DubboBootstrap dubboBootstrap = DubboBootstrap.getInstance();
// 设置应用服务名称
ApplicationConfig applicationConfig = new ApplicationConfig();
applicationConfig.setName(dubboBootstrap.getApplicationModel().getApplicationName());
// 设置注册中心的地址
String address = dubboBootstrap.getConfigManager().getRegistries().iterator().next().getAddress();
RegistryConfig registryConfig = new RegistryConfig(address);
ReferenceConfig<GenericService> referenceConfig = new ReferenceConfig<>();
referenceConfig.setApplication(applicationConfig);
referenceConfig.setRegistry(registryConfig);
referenceConfig.setInterface(interfaceName);
return referenceConfig;
}
}
代码其实非常简单,通过创建 ReferenceConfig 得到泛化引用对象,也就是泛化服务对象,然后调用泛化服务对象的 $invoke 方法,实现远程调用,并最终泛化调用的结果。
有了消费方的泛化调用代码后,学过了“调用流程”巧妙打断点的方式,想必你已经想到了,可以直接在 NettyClient 的 send 方法打个断点,然后启动提供方,Debug 启动消费方,静候断点的到来。

我们观察左侧的调用堆栈,很明显就找到了泛化实现类的过滤器,再细看其他环节的调用,可以发现,泛化调用和普通调用的区别就在于,泛化调用会经过一个泛化实现类过滤器(GenericImplFilter),其他环节的流程基本上没啥异样。
2.泛化调用内幕
既然要弄懂泛化调用的核心内幕逻辑,那就自然少不了去拜读一下源码的细节。
///////////////////////////////////////////////////
// org.apache.dubbo.rpc.filter.GenericImplFilter#invoke
// 泛化调用的核心 invoke 处理逻辑
///////////////////////////////////////////////////
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
// 获取 url 上的 generic 属性值,目前得到的值是 true
String generic = invoker.getUrl().getParameter(GENERIC_KEY);
// calling a generic impl service
// 1、如果是泛化调用所认可的标识(ProtocolUtils.isGeneric(generic))
// 2、且调用下游接口的方法名不是 "$invoke"
// 3、且调用下游接口的方法名不是 "$invokeAsync"
// 4、且 invocation 对象的类型还必须属于 RpcInvocation 类型
// 如果刚刚的 4 点都符合的话,那么就会进入 isCallingGenericImpl 方法逻辑
if (isCallingGenericImpl(generic, invocation)) {
// 将入参的 invocation 重新拷贝一份新的对象为 invocation2
RpcInvocation invocation2 = new RpcInvocation(invocation);
invocation2.put("GENERIC_IMPL", true);
String methodName = invocation2.getMethodName();
Class<?>[] parameterTypes = invocation2.getParameterTypes();
Object[] arguments = invocation2.getArguments();
String[] types = new String[parameterTypes.length];
for (int i = 0; i < parameterTypes.length; i++) {
types[i] = ReflectUtils.getName(parameterTypes[i]);
}
Object[] args;
// 如果 generic = bean,则调用 JavaBeanSerializeUtil 工具类进行序列化操作
if (ProtocolUtils.isBeanGenericSerialization(generic)) {
args = new Object[arguments.length];
for (int i = 0; i < arguments.length; i++) {
args[i] = JavaBeanSerializeUtil.serialize(arguments[i], JavaBeanAccessor.METHOD);
}
}
// 如果 generic != bean 的话,则调用默认的序列化操作
else {
args = PojoUtils.generalize(arguments);
}
// 然后把一些调用所需的一些参数都全部放到这个新的 invocation2 对象中
if (RpcUtils.isReturnTypeFuture(invocation)) {
invocation2.setMethodName("$invokeAsync");
} else {
invocation2.setMethodName("$invoke");
}
invocation2.setParameterTypes(new Class<?>[]{String.class, String[].class, Object[].class});
invocation2.setParameterTypesDesc("Ljava/lang/String;[Ljava/lang/String;[Ljava/lang/Object;");
invocation2.setArguments(new Object[]{methodName, types, args});
// 最终传递给下一步进行后续调用操作
return invoker.invoke(invocation2);
}
// making a generic call to a normal service
// 1、如果调用下游接口的方法名是 "$invoke" 或 "$invokeAsync"
// 2、如果 invocation 的入参数据不为空,且入参的个数恰好是 3 个
// 3、如果是泛化调用所认可的标识(ProtocolUtils.isGeneric(generic))
// 如果刚刚的 3 点都符合的话,那么就会进入 isMakingGenericCall 方法逻辑
else if (isMakingGenericCall(generic, invocation)) {
Object[] args = (Object[]) invocation.getArguments()[2];
// 如果 generic = nativejava
if (ProtocolUtils.isJavaGenericSerialization(generic)) {
for (Object arg : args) {
if (byte[].class != arg.getClass()) {
error(generic, byte[].class.getName(), arg.getClass().getName());
}
}
}
// 如果 generic = bean
else if (ProtocolUtils.isBeanGenericSerialization(generic)) {
for (Object arg : args) {
if (!(arg instanceof JavaBeanDescriptor)) {
error(generic, JavaBeanDescriptor.class.getName(), arg.getClass().getName());
}
}
}
invocation.setAttachment(
"generic", invoker.getUrl().getParameter("generic"));
}
return invoker.invoke(invocation);
}
↓
///////////////////////////////////////////////////
// org.apache.dubbo.rpc.filter.GenericImplFilter#isCallingGenericImpl
// 1、如果是泛化调用所认可的标识(ProtocolUtils.isGeneric(generic))
// 2、且调用下游接口的方法名不是 "$invoke"
// 3、且调用下游接口的方法名不是 "$invokeAsync"
// 4、且 invocation 对象的类型还必须属于 RpcInvocation 类型
///////////////////////////////////////////////////
private boolean isCallingGenericImpl(String generic, Invocation invocation) {
return ProtocolUtils.isGeneric(generic)
&& (!"$invoke".equals(invocation.getMethodName()) && !"$invokeAsync".equals(invocation.getMethodName()))
&& invocation instanceof RpcInvocation;
}
↓
///////////////////////////////////////////////////
// org.apache.dubbo.rpc.filter.GenericImplFilter#isMakingGenericCall
// 1、如果调用下游接口的方法名是 "$invoke" 或 "$invokeAsync"
// 2、如果 invocation 的入参数据不为空,且入参的个数恰好是 3 个
// 3、如果是泛化调用所认可的标识(ProtocolUtils.isGeneric(generic))
///////////////////////////////////////////////////
private boolean isMakingGenericCall(String generic, Invocation invocation) {
return (invocation.getMethodName().equals("$invoke") || invocation.getMethodName().equals("$invokeAsync"))
&& invocation.getArguments() != null
&& invocation.getArguments().length == 3
&& ProtocolUtils.isGeneric(generic);
}
↓
///////////////////////////////////////////////////
// org.apache.dubbo.rpc.support.ProtocolUtils#isGeneric
// generic 的属性值可以有以下 6 种值:
// 1、true
// 2、nativejava
// 3、bean
// 4、protobuf-json
// 5、gson
// 6、raw.return
///////////////////////////////////////////////////
public static boolean isGeneric(String generic) {
return StringUtils.isNotEmpty(generic)
&& ("true".equalsIgnoreCase(generic) /* Normal generalization cal */
|| "nativejava".equalsIgnoreCase(generic) /* Streaming generalization call supporting jdk serialization */
|| "bean".equalsIgnoreCase(generic)
|| "protobuf-json".equalsIgnoreCase(generic)
|| "gson".equalsIgnoreCase(generic)
|| "raw.return".equalsIgnoreCase(generic));
}
翻看消费方泛化调用的源码,由于我们调用的是下游 sayHello 方法,但是通过泛化形式调用的话,从 invocation 中获取的 methodName 却是 $invoke,自然跳过了 isCallingGenericImpl 逻辑的判断,然后进入到 isMakingGenericCall 的分支逻辑中,只是赋值了一个属性就完事了,所以,我们可以得知设置 generic = true 进行泛化调用是最简单的泛化调用形式。
当然,我们从源码中了解了以前不知道的一些细节逻辑。
- 设置 generic 属性的值时,有六种设置方法,分别为 true、nativejava、bean、protobuf-json、gson、raw.return。
- 从 isCallingGenericImpl 分支逻辑中,我们发现进行普通的远程调用时,也可以在 @DubboReference 注解中加上 generic 属性值。
总的来说,消费方的泛化服务过滤器,也确实没有干什么非常特别的事情,关键就是将 generic 属性值传到了提供方那边,至于提供方拿到 generic 的不同属性值,会按照怎样的处理逻辑,有兴趣的话你可以自行研究 GenericFilter,这个类是专门处理提供方接收泛化请求的泛化过滤器。
- 张三丰 👍(0) 💬(3)
老师,这里我有个疑问,在定长+变长这个协议格式传输的时候,如果服务端第一次接收的不完整,比如120字节的消息,第一次接收100字节,第二次接收20字节,对于服务端来说,如果第二次接收20字节的时候,这个20字节的消息会像100字节的消息那样包括请求头吗? 比如请求头+100字节请求体、请求头+20字节请求体,如果包括请求头,那么第一次处理消息和第二次处理消息在逻辑上有什么不同?第一次处理消息时肯定是先解析请求头再解析请求体,第二次也是这样解析吗?服务端怎么确认第二次收到的消息是第一次消息的接续?
2023-03-20 - Lum 👍(0) 💬(2)
希望老师出一章消费端发送请求后,服务端是如何接收消息并返回的章节~
2023-03-06 - BraveSky 👍(0) 💬(1)
老师你好,请教个dubbo序列化问题,目前线上服务用的kryo 序列化,kryo序列化对象dto 加字段,调用方反序列化就会报错,重新部署服务才行,这个有什么好的解决方案吗?如果换序列化方式的话,如何不影响现有服务情况下,平滑切换?
2023-02-14 - Six Days 👍(0) 💬(0)
本章能稍微讲下服务端如何接收处理数据包就更好了
2024-04-07