24 拦截扩展:如何利用Filter进行扩展?
你好,我是何辉。今天我们继续学习Dubbo拓展的第二篇,拦截扩展。
再次见到“拦截”功能,有没有熟悉的感觉,我们前面学过的“参数验证”“缓存操作”,都利用了过滤器特性,对你来说,使用过滤器来编码解决实际问题,应该不是什么难事了。
但是会用,并不代表能用好,很多人在遇到问题或接到新增的业务需求时,面临的常见问题是:是否真的需要使用过滤器?如何适当地利用过滤器进行扩展?
我们进入今天的学习,尝试回答这些问题。
四个案例
想回答第一个问题是否该用过滤器,理解清楚“拦截”到底能达到什么效果就很重要。
我们先看四个可以使用拦截的实际场景,分析一下“拦截”在其中的作用。
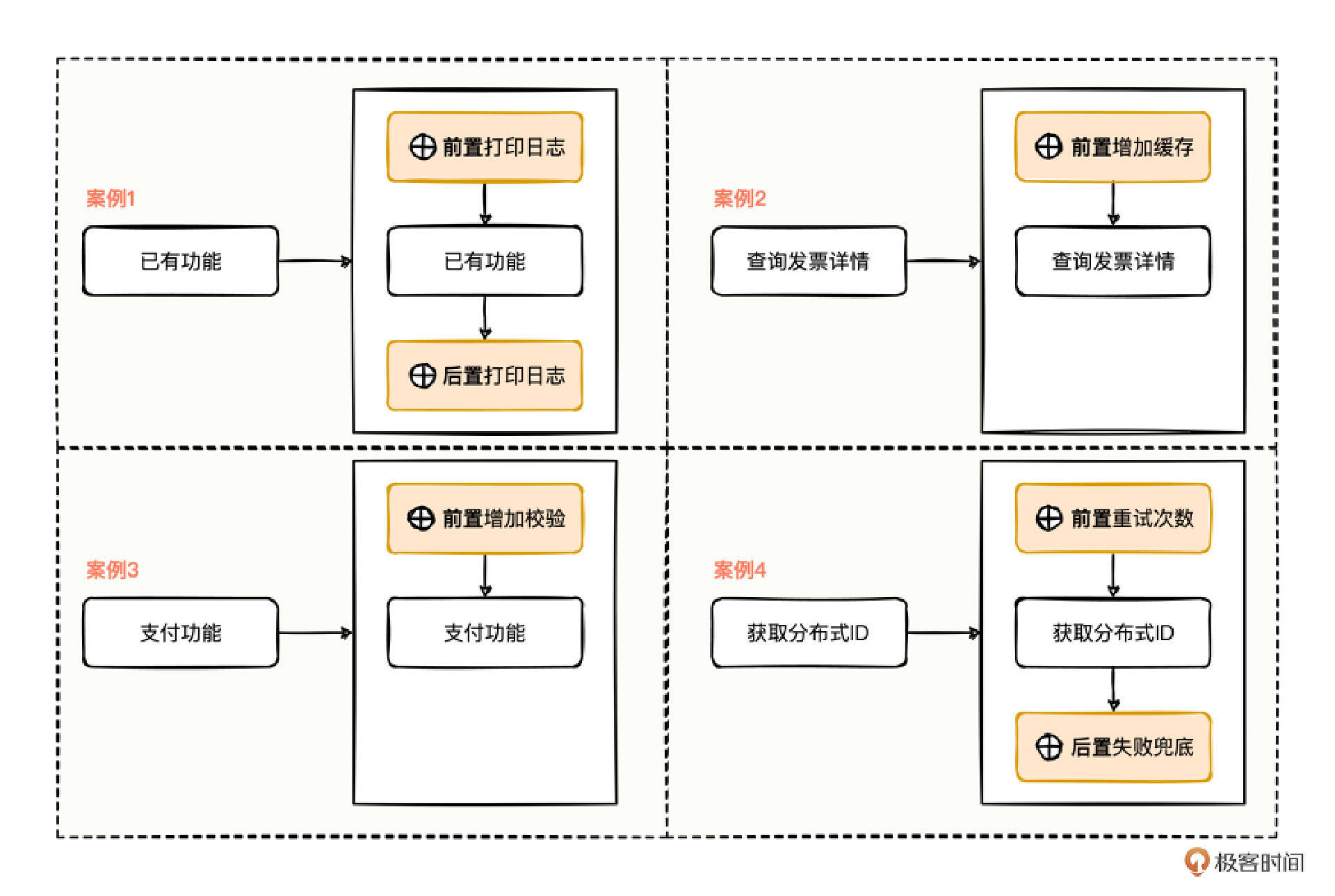
- 案例一,已有的功能在之前和完成时,都记录一下日志的打印。
- 案例二,查询发票详情功能,需要在查询之前先看看有没有缓存数据。
- 案例三,用户在进行支付功能操作时,需要增加一些对入参字段的合法性校验操作。
- 案例四,获取分布式ID时,需要增加重试次数,如果重试次数达到上限后,仍无法获取
结果,会在后置环节进行失败兜底逻辑处理,防止意外网络抖动影响正常的业务功能运转。
这四个案例,细心的你想必发现了一些共性,都在执行业务功能之前干一点事情,执行后又干一点事情。逻辑结构看起来是一段一段的,而且每段又各自承载着独立于整体的聚焦功能,功能的层次划分非常清晰。
有点类似我们学生时代的考试,考试之前需要做充足的准备,考试之后就享受高分的喜悦或做错题复盘,无形中形成了时空结构。但是,这种时空结构不是物理上的概念,更是一种强调流程、周期的思维方法。
那在这四个案例里,这些所谓的前置、后置处理的环节,与核心的业务功能又有着什么样的关系呢?
四种关系
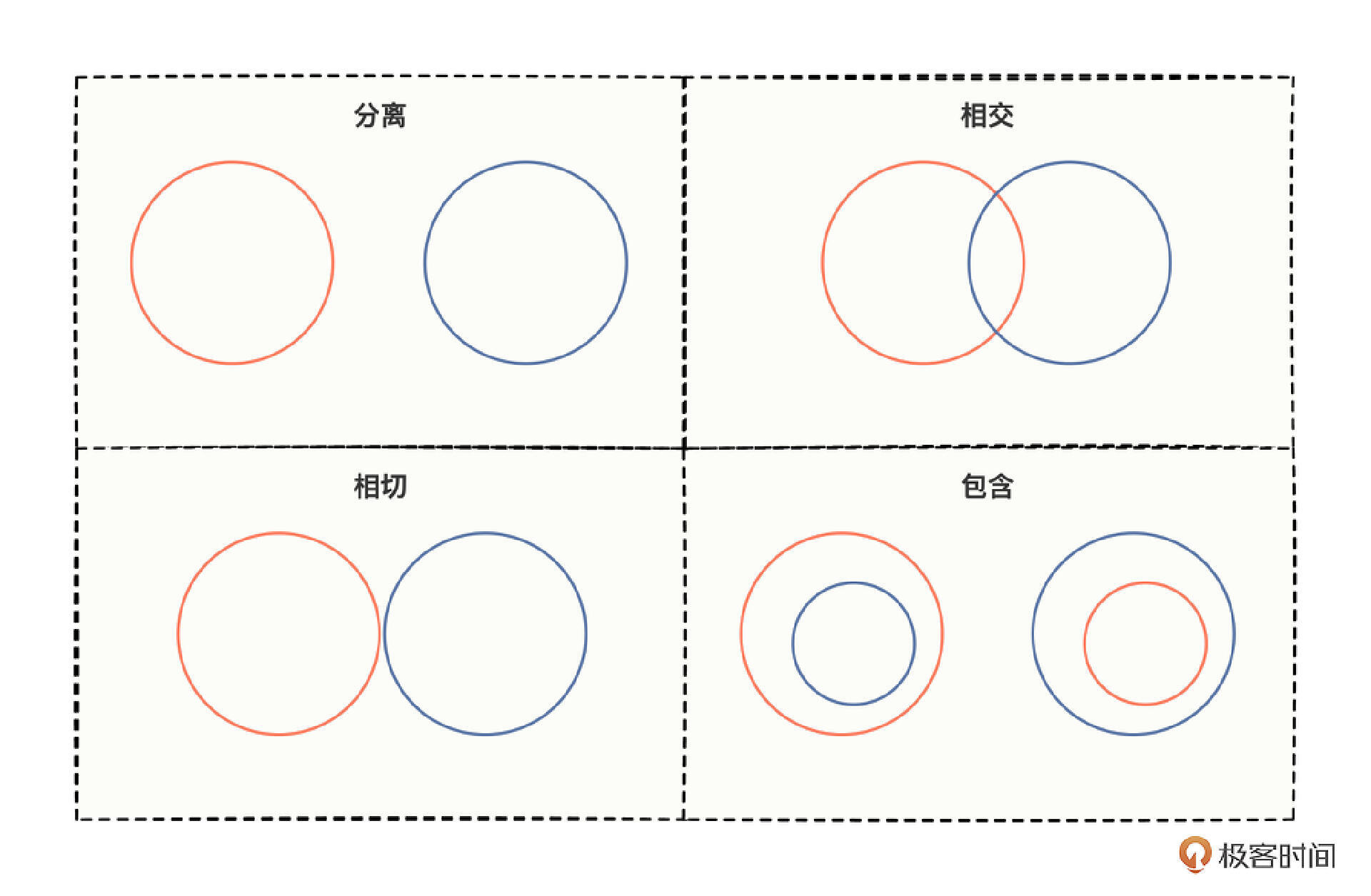
谈到关系,我们都知道,一般两个物体之间的关系共四种,分离、相交、相切、包含。
那前置、后置与核心的业务功能之间的关系,应该是什么样的呢?
首先,分离关系可以。前置、后置这些逻辑,本身就可以通过优秀的设计,隔离与实际业务功能的耦合度,比如,在框架已有的拦截器或过滤器中,嵌入具有通用拦截特性的代码。
那相交关系呢?当然就不可以了,这会导致一些本来可以横切拦截的代码,与业务功能的代码各种交叉耦合,我们后续维护起来特别痛苦,所以极度不提倡。
相切关系,有点临界点的味道,A代码块与B代码块,要找到既属于A又属于B,而且在从上到下执行时有脚踏两只船的小功能点,几乎是不可能,所以考虑相切也没有什么太大的意义。
最后一个,包含关系,当然也可以。如果前置、后置逻辑和业务代码写在一起,就是业务功能包含了前置后置逻辑;如果业务代码写在在过滤器里,就是前置后置包含了仅有的一句业务功能抽象代码的调用。
总的来说,前置、后置与核心的业务功能之间,可以是相离关系,也可以是包含关系。看到这样的结构关系,你有没有回想起,自己曾经编写的代码属于哪种风格呢?
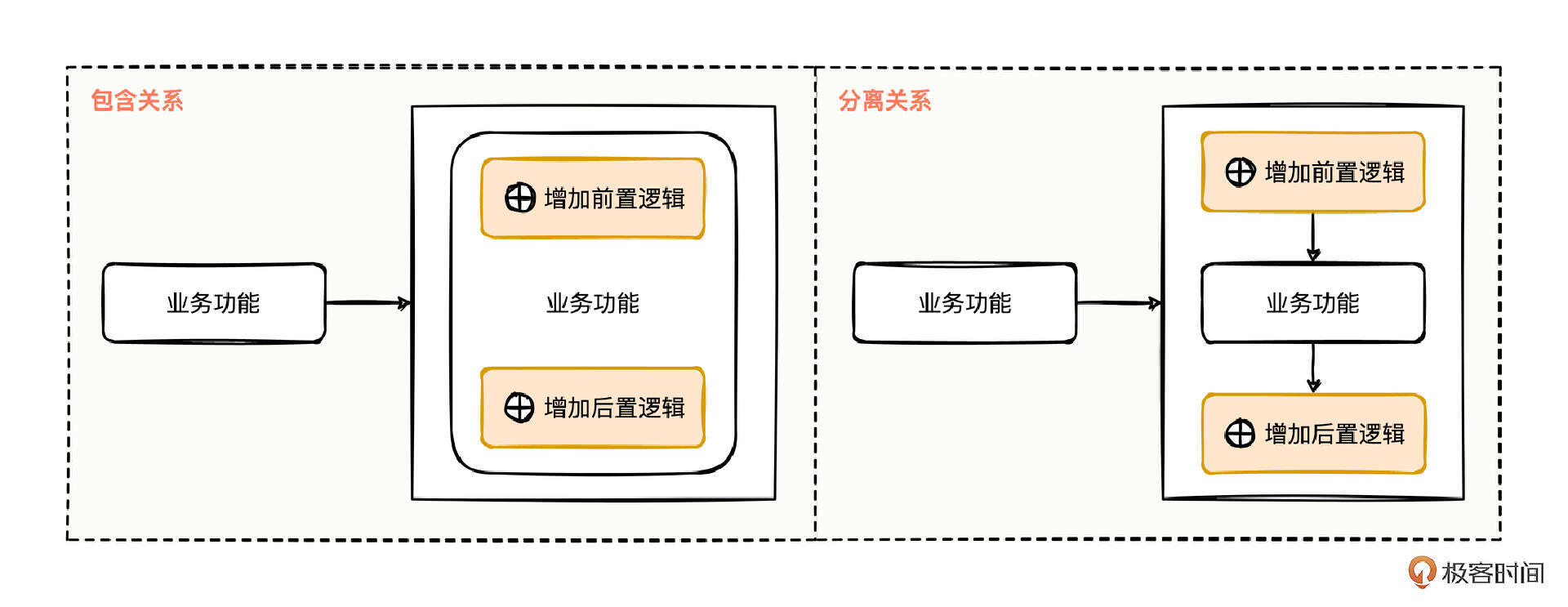
不过这两种结构关系,在实际工作使用时,维护性也有明显差异。
包含关系中,我们把前置后置逻辑与业务功能的代码写在一个地方,也许你会有意识地通过一些代码设计,做方法的封装,尽量隔离关联性,但难保未来的维护者也有同样高度的代码隔离意识。
分离关系中就会大大不一样,如果新增加的需求,能和现有的业务功拉开距离,要么会偏技术属性,要么会偏业务属性。
偏技术的属性,比如限流、熔断、缓存、日志、埋点等,都是比较通用的功能,不管是在 A 系统还是在 B 系统,只要某功能有类似的诉求,就可以和业务功能分开,让这类偏技术属性的功能,尽量少和业务功能发生关系。否则,技术属性和业务功能耦合不清,功能的维护成本只会与日俱增,蜘蛛网一样的代码,满天飞的连环 if…else 判断,简直不敢想象,最终就会沦为我们耳熟能详的大泥球系统。
偏业务的属性,比如支付功能添加了一些校验环节,虽然会和业务功能有一丝联系,但是我们巧妙运用自己的设计手段高度抽象一层,也可以做到把校验环节变成通用的技术属性。
解密需求
通过分析新增功能与原有功能的关系,相信你已经或多或少有了一些自己的看法。接下来我们就实践一下,看看面对新增的功能,该如何分析新老功能之间的相对关系,如何以低侵入的方式,调整代码逻辑结构,实现具体的业务诉求。
需求案例是这样的,原先系统 A 调用了系统 B 的一个方法,方法的入参主要是接收一些用户信息,做一些业务逻辑处理,而且入参值都是明文的。
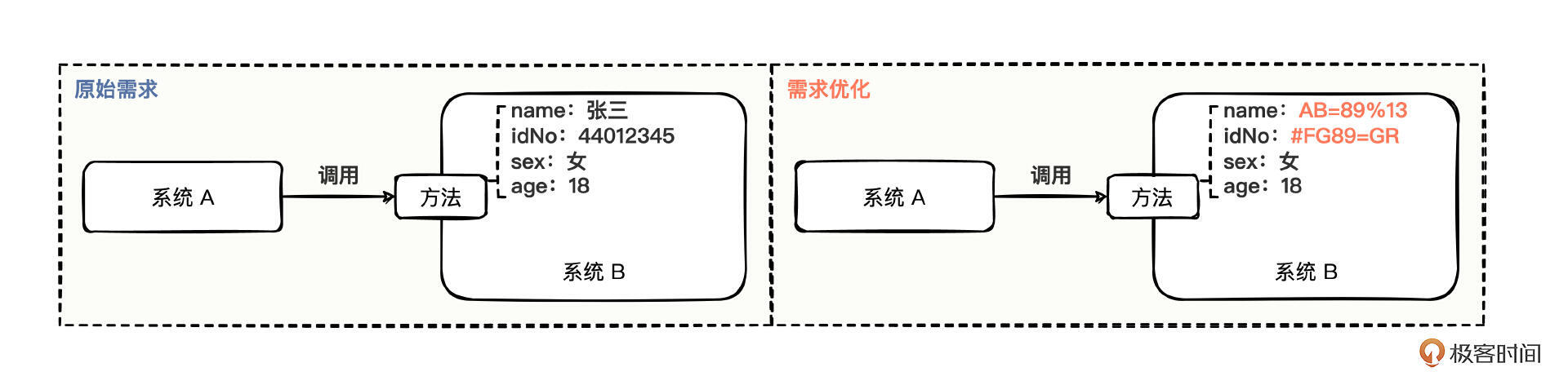
后来,出现了安全层面出现了一些整改需求,需要你把用户信息中的一些敏感字段,比如名称 name、身份证号 idNo 用密文传输。到时候系统 B 在接收用户信息name 和 idNo 的值时,就是密文了,对于这样一个简单的需求优化,你该怎么解决呢?
根据前面分析的,四种关系,我们只需要考虑分离关系和包含关系。
1.包含关系
先看更简单的包含关系。
在系统 B 方法的实现体中,我们会在尽量不影响原有逻辑的情况下,考虑在方法一进来的时候,针对入参字段进行解密,接着把解密之后的值再次替换原来的密文,然后走后续逻辑,你可能会写出这样的代码。
///////////////////////////////////////////////////
// 1、用户查询服务接口
// 2、在 saveUserInfo 保存用户信息的方法中,先解密入参数据,
// 再把明文塞到入参 req 中,然后继续走后续业务逻辑。
///////////////////////////////////////////////////
@DubboService
@Component
public class UserQueryFacadeImpl implements UserQueryFacade {
/** <h2>配置中心 AES 密钥的配置名称,通过该名称就能从配置中心拿到对应的密钥值</h2> **/
public static final String CONFIG_CENTER_KEY_AES_SECRET = "CONFIG_CENTER_KEY_AES_SECRET";
@Override
public SaveUserInfoResp saveUserInfo(SaveUserInfoReq req) {
///////////////////////////////////////////////////
// 为解密入参数据,新增处理逻辑 start
///////////////////////////////////////////////////
// 从 OPS 配置中心里面获取到 aesSecretOpsKey 对应的密钥值
String privateKey = OpsUtils.getAesSecret(CONFIG_CENTER_KEY_AES_SECRET);
// 将入参的 name、idNo 字段进行解密
String plainName = AesUtils.decrypt(req.getName(), privateKey);
String plainIdNo = AesUtils.decrypt(req.getIdNo(), privateKey);
// 然后将得到的明文 plainName、plainIdNo 再放回到入参 req 中去
req.setName(plainName);
req.setIdNo(plainIdNo);
///////////////////////////////////////////////////
// 为解密入参数据,新增处理逻辑 end
///////////////////////////////////////////////////
// 保存用户信息的核心逻辑
doSaveUserInfo(req);
// 返回成功响应
return buildSuccResp();
}
}
这段代码非常简单,只是在原来的核心保存用户逻辑之前,进行了一系列的解密操作,从配置中心读取 AES 密钥值,然后调用 AES 工具类进行解密,得到明文后再次放回到入参对象中。
整个过程,看起来行云流水,一气呵成,也确实做到了将入参数据进行解密处理,尽量不污染到原有的代码逻辑,但是可能带来的后遗症之前也说过,原本的核心逻辑是 doSaveUserInfo 方法,追加了解密功能之后,saveUserInfo 方法体也越发膨胀了,后续维护扩展的难度增加了一点。
2.分离关系
既然采用包含关系会有些不太友好,我们继续采用分离关系来设计看看。
首先,我们就得识别这种解密功能到底是偏技术属性,还是偏业务属性?
你肯定很有把握,偏技术属性,因为这种解密功能实在是太普通了,跟保存用户信息的关联程度并不大,只是保存用户信息路上的一条小插曲,不管有没有解密功能,用户信息都需要保存,只是现在因为安全整改,需要将字段进行加密传输,而原本的保存用户信息并没有发生业务变更。
一旦划分到偏技术属性范畴,我们就一定要想办法与业务功能隔离开,并且考虑到其他方法可能也有类似解密诉求,还可以复用。
所以,我们要想办法建立一种拦截所有方法的机制,在拦截环节,把密文直接改成明文,然后走后续逻辑,这样,所有的业务功能都不需要修改,既满足了通用性,又满足了对业务的零侵入性,一举两得。
那如何对方法进行拦截呢?寻找当前系统、当前框架具有的一些拦截机制,我们就找到了过滤器。所有的方法都会经过过滤器的 invoke 方法。
至于,方法体中需要对入参 invocation 中的哪个字段进行解密?回忆之前学的内容,可以通过一种标识来识别,在众多的入参字段中,哪些是需要进行解密的。和我们在“参数验证”中接触到的标准产物是一个概念,在字段上添加注解,标识哪些字段需要特殊处理。
3.小试牛刀
不过,注解方式有一点小问题。因为注解的编写是硬编码形式的,每次某个方法有解密诉求,我们就得给这个方法的敏感字段添加注解,然后打包、部署、测试、发版,整个流程下来,不仅毫无技术含量,效率还比较低。
我们的理想目标是,以后如果哪个方法的哪个字段需要解密,做到无需修改任何工程代码、无需发版,实现动态修改实时生效的效果。所以,采用动态的方式更合适。
不过动态实现也不难。在过滤器的 invoke 方法中,目的是需要寻找带有注解的字段,找的过程,我们可以理解为寻找认定的“标准”,只不过这个“标准”在硬编码的注解上。如果我们把这个“标准”放到其他存储媒介上,比如放到配置中心,就只需要从配置中心拿到“标准”,这样,注解就形同虚设了。
好,实现方法有了,新的调用流程图该怎么设计呢?
首先要在过滤器中,通过方法级别来进行细粒度控制,我们可以参考“流量控制”中关于计数逻辑的设计,通过服务名+方法名构成唯一,形成一种“约定大于配置”的理念。就像这样。
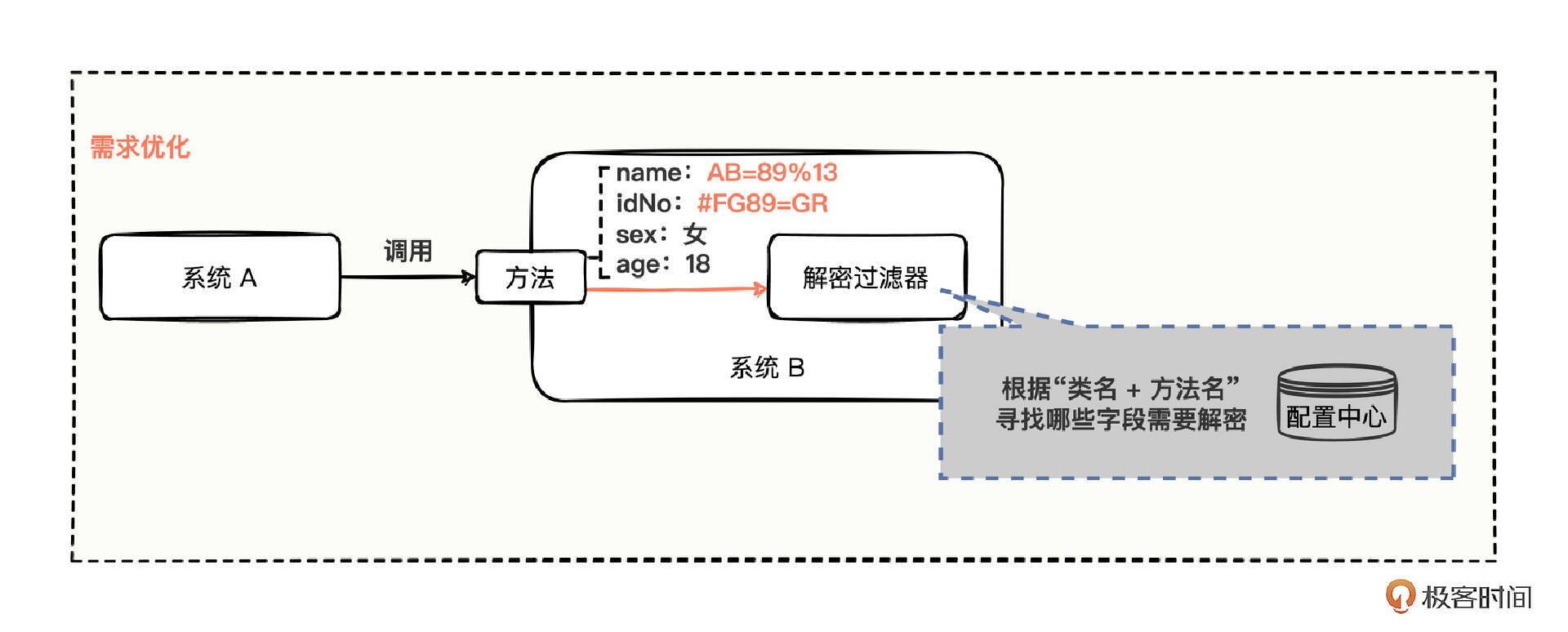
其中,系统 B 的内部有些变化,方法接收到请求后,会流进解密过滤器,而解密过滤器中会从 invocation 中拿到此次请求的类名和方法名,构建一个唯一的 KEY,通过 KEY 从配置中心查询是否有对应的一套需要解密的字段,如果有解密字段,就根据解密的字段,把 invocation 中的密文挨个替换为明文,否则就当作啥事也没发生过,继续走后续流程处理。
有了配置中心的介入,我们可以动态针对某个方法的部分字段进行解密处理了,看代码。
///////////////////////////////////////////////////
// 提供方:解密过滤器,仅在提供方有效,因为 @Activate 注解中设置的是 PROVIDER 侧
// 功能:通过 “类名 + 方法名” 从配置中心获取解密配置,有值就执行解密操作,没值就跳过
///////////////////////////////////////////////////
@Activate(group = PROVIDER)
public class DecryptProviderFilter implements Filter {
/** <h2>配置中心 AES 密钥的配置名称,通过该名称就能从配置中心拿到对应的密钥值</h2> **/
public static final String CONFIG_CENTER_KEY_AES_SECRET = "CONFIG_CENTER_KEY_AES_SECRET";
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
// 从 OPS 配置中心里面获取到 aesSecretOpsKey 对应的密钥值
String privateKey = OpsUtils.getAesSecret(CONFIG_CENTER_KEY_AES_SECRET);
// 获取此次请求的类名、方法名,并且构建出一个唯一的 KEY
String serviceName = invocation.getServiceModel().getServiceKey();
String methodName = RpcUtils.getMethodName(invocation);
String uniqueKey = String.join("_", serviceName, methodName);
// 通过唯一 KEY 从配置中心查询出来的值为空,则说明该方法不需要解密
// 那么就当作什么事也没发生,继续走后续调用逻辑
String configVal = OpsUtils.get(uniqueKey);
if (StringUtils.isBlank(configVal)) {
return invoker.invoke(invocation);
}
// 能来到这里说明通过唯一 KEY 从配置中心找到了配置,那么就直接将找到的配置值反序列化为对象
DecryptConfig decryptConfig = JSON.parseObject(configVal, DecryptConfig.class);
// 循环解析配置中的所有字段列表,然后挨个解密并回填明文值
for (String fieldPath : decryptConfig.getFieldPath()) {
// 通过查找节点工具类,通过 fieldPath 字段路径从 invocation 中找出对应的字段值
String encryptContent = PathNodeUtils.failSafeGetValue(invocation, fieldPath);
// 找出来的字段值为空的话,则不做任何处理,继续处理下一个字段
if (StringUtils.isBlank(encryptContent)) {
continue;
}
// 解密成为明文后,则继续将明文替换掉之前的密文
String plainContent = AesUtils.decrypt(encryptContent, privateKey);
PathNodeUtils.failSafeSetValue(invocation, fieldPath, plainContent);
}
// 能来到这里,说明解密完成,invocation 中已经是明文数据了,然后继续走后续调用逻辑
return invoker.invoke(invocation);
}
/**
* <h1>解密配置。</h1>
*/
@Setter
@Getter
public static class DecryptConfig {
List<String> fieldPath;
}
}
///////////////////////////////////////////////////
// 提供方资源目录文件
// 路径为:/META-INF/dubbo/org.apache.dubbo.rpc.Filter
///////////////////////////////////////////////////
decryptProviderFilter=com.hmilyylimh.cloud.filter.config.DecryptProviderFilter
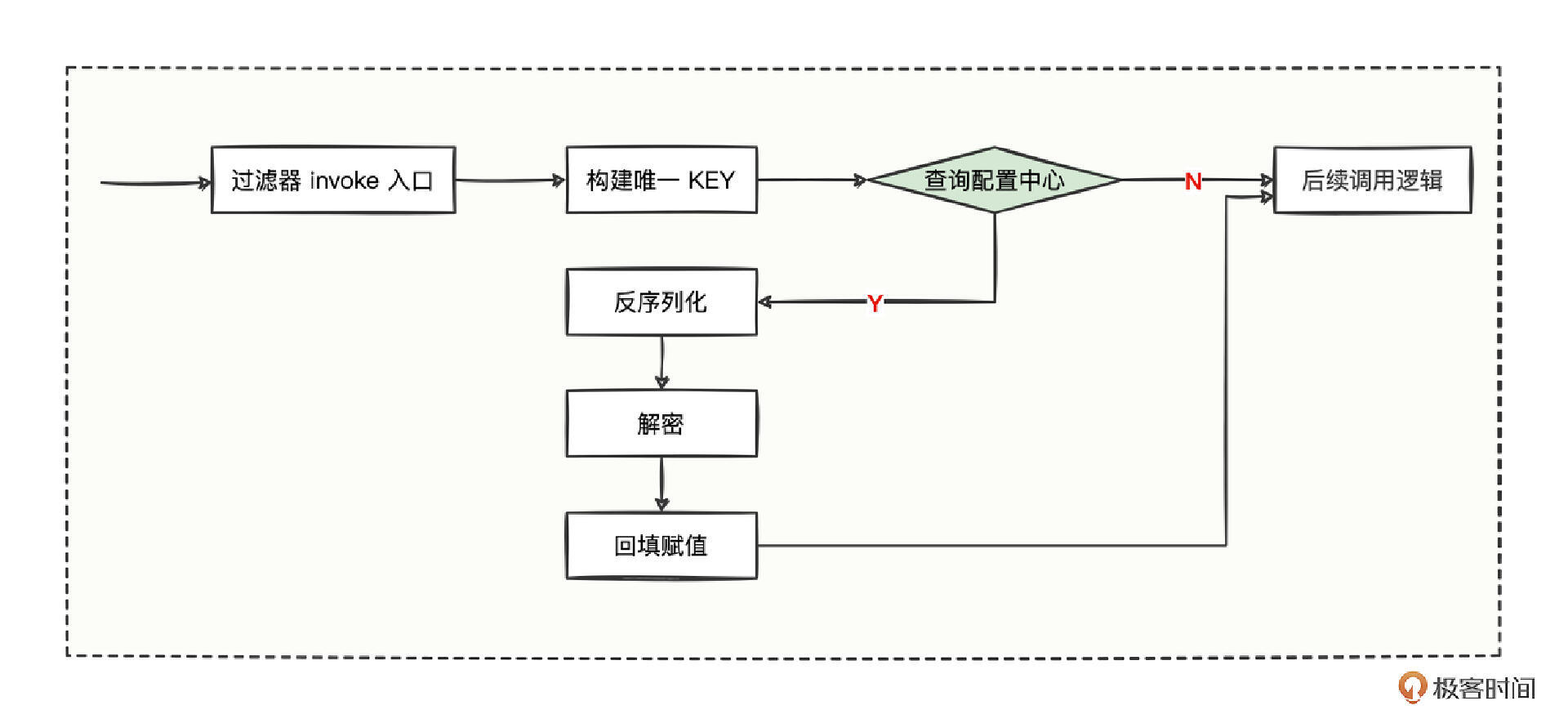
这段代码也非常简单,就是刚才梳理的。
- 首先,从 invocation 中找出类名和方法名,构建出一个唯一 KEY 值。
- 然后,通过唯一 KEY 值去从配置中心查找,如果没找到,就继续走后续调用逻辑。
- 最后,如果找到了对应配置内容,反序列化后,挨个循环配置好的字段路径,依次解密后将明文再次放回到 invocation 对应位置中,继续走后续调用逻辑。
拦截扩展的源码案例
通过这个简单的案例,相信你已经掌握如何针对解密过滤器扩展了,在我们日常开发的过程中,有一些框架的源码,其实也有着类似的拦截扩展的机制,这里我也举 4 个常见的拦截机制的源码关键类。
第一,SpringMvc 的拦截过滤器,通过扩展 org.springframework.web.servlet.HandlerInterceptor 接口,就可以在控制器的方法执行之前、成功之后、异常时,进行扩展处理。
第二,Mybatis 的拦截器,通过扩展 org.apache.ibatis.plugin.Interceptor 接口,可以拦截执行的 SQL 方法,在方法之前、之后进行扩展处理。
第三,Spring 的 BeanDefinition 后置处理器,通过扩展 org.springframework.beans.factory.config.BeanFactoryPostProcessor 接口,可以针对扫描出来的 BeanDefinition 对象进行修改操作,改变对象的行为因素。
第四,Spring 的 Bean 后置处理器,还可以通过扩展 org.springframework.beans.factory.config.BeanPostProcessor 接口,在对象初始化前、初始化后做一些额外的处理,比如为 bean 对象创建代理对象的经典操作,就是在 org.springframework.aop.framework.autoproxy.AbstractAutoProxyCreator#postProcessAfterInitialization 方法完成的。
总结
今天,我们从已经学过的过滤器知识点,抛出了一个在面对需求如何适当利用过滤器进行扩展的问题。
针对这个问题,我们通过四个拦截场景,分析了常见的分离、相交、相切、包含四种关系,在平常的业务逻辑编码中,包含关系和分离关系应用比较广泛。
分离关系,想要解耦,就必须得识别新增需求是偏技术属性,还是偏业务属性,另外都可以尽量往抽象层次上提炼,看看能否成为解决某一类问题的通用解决方案。最后我们也通过一个解密需求,结合包含关系和分离关系进行了相应编码,采用解密过滤器,实现了需求的通用性解决方案。
拦截扩展的常见源码案例有SpringMvc 的拦截过滤器、Mybatis 的拦截器、Spring 的 BeanDefinition 后置处理器、Spring 的 Bean 后置处理器。
思考题
今天的解密需求中,我们在提供方通过增加解密过滤器,解决了通用性解密诉求,那站在消费方的维度,在不修改业务功能的代码情况下,你能不能提供一套针对敏感字段进行加密的过滤器呢?
期待看到你的思考,我们下一讲见。
23 思考题参考
上一期的问题是利用已学的集群扩展知识,让内网环境中本机电脑的消费者应用,通过桥接服务来向测试环境中真实的提供者发起调用。
先来解答在消费方的集群扩展问题,我们仍然可以套用自定义集群扩展四部曲。
- 首先定义一个 HttpClusterInvoker 集群扩展处理器来处理核心的调用桥接服务。
- 其次定义一个 HttpClusterWrapper 集群扩展器来封装集群扩展处理器。
- 然后在 META-INF/dubbo/org.apache.dubbo.rpc.cluster.Cluster 定义 HttpClusterWrapper 的类路径。
- 最后在 dubbo.properties 配置文件通过一个别名来指定消费者需要使用的集群扩展器。
通过这四部曲最终实现的大致代码。
// Http集群扩展核心处理类
public class HttpClusterInvoke<T> extends MockClusterInvoker<T> {
// 按照父类的要求创建出来的构造方法
public HttpClusterInvoke(Directory<T> directory, Invoker<T> invoker) {
super(directory, invoker);
}
// 集群扩展器的调用,也可以理解为是比较接近代理类InvokerInvocationHandler触发调用的环节
@Override
public Result invoke(Invocation invocation) throws RpcException {
// 这里省略了很多参数有效无效的判断
check(invocation);
// 考虑泛化调用、正常调用两种方式,发起 HTTP 远程调用
return doHttpInvoke(invocation);
}
private Result httpInvoke(Invocation invocation) {
// 获取类名、方法名、方法入参类名、方法返参类名、请求参数,
// 来构建 CommonBodyRequest 请求对象
CommonBodyRequest request = buildRequest(invocation);
// 将参数按照约定的 URL 发送到桥接服务
CommonBodyResponse response = postJson(request);
// 判断 HTTP 响应码
checkHttpStatusCode(response.getCode());
// 将 HTTP 的结果转换为 Dubbo 的 Result 对象返回
return new RpcResult(JacksonUtils.fromJson(response.getBody()));
}
}
// Http集群扩展器的包装类
public class HttpClusterWrapper extends MockClusterWrapper {
// 定义抽象的 Cluster 接口,其实是通过 Dubbo 的依赖注入设置进来的一个自适应扩展点
private Cluster cluster;
// 按照 Dubbo 构造方法注入方式,将自适应扩展点注入进来
public HttpClusterWrapper(Cluster cluster) {
super(cluster);
this.cluster = cluster;
}
@Override
public <T> Invoker<T> join(Directory<T> directory, boolean buildFilterChain) throws RpcException {
// 创建集群扩展器的核心处理类
return new HttpClusterInvoke<T>(directory,
this.cluster.join(directory, buildFilterChain));
}
}
再来解决桥接服务中通用HTTP接口定义问题,我们需要关注2点。
- URL的入参要足够通用,尽可能囊括所有复杂的Dubbo接口定义形式。
- URL接口的实现逻辑可以采用泛化方式进行RPC调用,这样就可以调通测试环境中的所有提供者应用。
URL接口的大致定义形式就是这样。
@RestController
@Component
public class SimpleController {
// 在桥接服务中定义一个通用的 Web 控制器,然后泛化方式调用测试环境各种提供方系统
@PostMapping(value = "/simple/request", produces = "application/json;charset=UTF-8")
public String request(@RequestBody WebRequest webRequest) {
// 将收到的请求参数转换为 CommonGenericContext 对象
CommonGenericContext ctx = convertSimple2Req(webRequest);
// 泛化形式处理 Dubbo 的远程调用
WebResponse webResponse = doDubboInvoke(ctx);
// 组装成功的响应数据
return buildSuccResp(webResponse );
}
}
@Getter
@Setter
@ToString
public class WebRequest implements Serializable {
/** 接口归属的类路径 */
private String clzName;
/** 接口方法名 */
private String mtdName;
/** 接口方法请求参数类路径 */
private String mtdParamType;
/** 请求参数内容 */
private String content;
}