02 工具使用:三大利器帮你迅速优化性能瓶颈
你好,我是徐逸。
在上节课中,我提到了刚开始做性能优化工作常见的3个痛点。
现在我们对于性能优化的流程已经心中有数了。今天我就来带你消除另一个痛点,掌握常见的Golang性能优化工具。它也是服务性能优化流程第三步——分析瓶颈原因的基础。只要能够灵活运用这些工具,我们就能更快地定位到代码优化点进行优化。
在介绍工具之前,我们先想一想,当发现CPU和内存占用过高时,你会怎么排查资源占用高的问题呢?
pprof工具:是什么导致了高CPU和内存占用?
为了分析CPU和内存资源占用高的原因,我们的首要任务便是精准找出那些消耗大量 CPU 资源以及频繁进行内存分配的热点代码。在锁定这些热点代码之后,我们才能紧密结合代码的上下文,找到消耗资源的原因。值得庆幸的是,Golang 的生态体系为我们提供了快速定位热点代码的工具——pprof。
pprof 具有强大的功能,它能够定时针对正在运行的 Go 程序展开采样操作。在这个过程中,它会全面搜集程序运行时的各类堆栈信息,像是那些消耗大量 CPU 资源的代码片段所在位置,以及内存分配的具体情况等。随后,pprof 会依据所搜集到的这些丰富信息,经过一系列细致的统计分析,生成可视化的性能报告供我们查看。
如此强大的 pprof,我们又该如何去使用它呢?
首先你需要触发pprof采集性能数据并生成性能报告。pprof支持多种采集触发方式。在实践中的大多数场景,我们会引入net/http/pprof包,并在main函数中开放http端口。你可以参考后面的代码。
import (
"net/http"
_ "net/http/pprof"
)
func main() {
err := http.ListenAndServe(":8888", nil)
if err != nil {
panic(err)
}
}
程序跑起来后,访问下面的url,我们就能得到一个触发采集的页面。然后在采集页面点击具体的采样类型,就能触发采样并生成性能报告。

当然,我们也可以不通过上面的页面触发性能数据采集,而是直接访问url并添加参数来控制采集的时长,就像下面这样。
在这些采样类型里,常用的有下面两类:
- profile采样,也就是cpu采样,用于确定程序中哪些函数或代码片段在运行时消耗了大量的 CPU 时间,帮助定位 CPU 性能瓶颈。
- 内存分配采样,具体包括allocs采样和heap采样。其中,allocs 采样侧重于定位那些频繁进行内存分配的函数,而 heap 采样用于查看存活对象的内存分配情况,侧重于定位内存泄漏问题。
对于不能采用开放http端口触发性能数据采集的场景,比如在程序启动初始化时,http端口还未开放,无法通过url触发采集性能数据。Golang提供了runtime/pprof包,像下面的代码一样,我们可以显式地触发和结束性能数据采集。
import (
"runtime/pprof"
)
func main() {
// cpu采样
f, err := os.Create("profile.pprof")
if err != nil {
panic(err)
}
defer f.Close()
if err := pprof.StartCPUProfile(f); err != nil {
panic(err)
}
defer pprof.StopCPUProfile()
// 运行业务逻辑
expensiveCPU()
}
func main() {
// 堆内存分配采样
f, err := os.Create("heap.pprof")
if err != nil {
panic(err)
}
defer f.Close()
runtime.GC()
// 业务逻辑
expensiveMem()
if err := pprof.WriteHeapProfile(f); err != nil {
panic(err)
}
}
接下来就是将性能报告可视化的环节。Golang提供了可视化展示工具pprof,我们可以通过下面的命令,启动一个Web界面查看(可视化界面需要提前安装graphviz)。
我们进入到可视化页面后,会发现存在多个展示形式各异的视图。在实际应用当中,火焰图(Flame Graph)因为比较直观,所以用得最广泛。火焰图是按照自顶向下的方式来呈现的,这种排列方式能够清晰地展示出函数之间的调用关系。此外,在火焰图中,每一个横条的长度也有意义,横条越长,就意味着其所对应的资源消耗或者占用的情况越严重。

不过这里需要特别注意,尽管你可能会看到某个函数对应的横条很长,但实际上这有可能是由其下层的 “子调用” 所耗费的资源累加导致的。所以,在分析的时候,务必要着重关注 “下一层子调用” 各自的资源消耗分布情况。
比如下面的CPU火焰图,虽然我们直接看到的是expensiveCPU函数消耗比较高,但这主要是下层函数rand.Float32导致的。

又比如下面的内存火焰图,虽然表面是main.main函数的内存分配比较高,但主要也是下层函数expensiveMem导致的。

利用火焰图定位到消耗CPU和内存资源的热点函数,我们可以通过右键点击,定位到具体的代码。
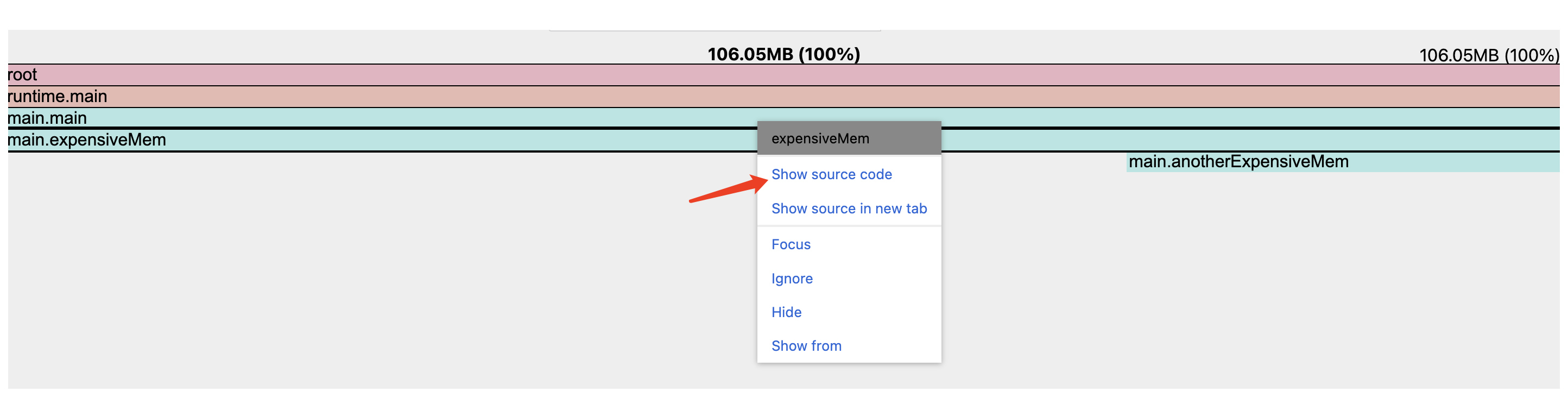

运用 pprof 工具,我们能够精准定位到那些消耗 CPU 以及内存资源的热点代码区域。在此基础上,还可以结合相关代码的上下文环境来深入分析出现这种情况的具体原因。
benchmark功能:如何判断你的方案是可行的?
然而,当我们已经成功找出问题产生的原因,并且着手去调研各种优化方案的时候,又该如何判断我们所制定的优化方案是否可行,尤其是它比起原来的方案究竟能够带来多大程度的性能提升呢?
在进行方案调研的过程中,我们需要针对各个优化点开展优化前后的性能对比测试工作。而 Golang 的测试框架为我们提供了一项十分有用的基准测试功能,它就是 benchmark。
benchmark 能够协助我们对代码的性能状况进行评估,它主要的操作方式是在规定的一段时间内,不断地重复运行待测试的代码,随后输出代码的执行次数、单次运行的时间和内存分配的相关结果。
接下来,我们利用一个简单的示例来对此进行验证,看看将字节切片转换为字符串的两种不同实现方式,究竟哪一种速度会更快一些。首先,我们需要编写一段用于基准测试的代码,具体内容如下:
func BenchmarkBytes2StrRaw(b *testing.B) {
aa := []byte("abcdefg")
for n := 0; n < b.N; n++ {
Bytes2StrRaw(aa)
}
}
func BenchmarkBytes2StrUnsafe(b *testing.B) {
aa := []byte("abcdefg")
for n := 0; n < b.N; n++ {
Bytes2StrUnsafe(aa)
}
}
func Bytes2StrRaw(b []byte) string {
return string(b)
}
func Bytes2StrUnsafe(b []byte) string {
return *(*string)(unsafe.Pointer(&b))
}
运行下面的go test命令,即可触发benchmark运行。
# -bench 表示需要benchmark运行的方法,.表示运行本目录所有Benchmark开头的方法
# -benchmem 显示与内存分配相关的详细信息
# -benchtime 设定每个基准测试用例的运行时间
# -cpuprofile 生成 CPU 性能分析文件
# -memprofile 生成内存性能分析文件
go test -bench='.' -benchmem -benchtime=10s -cpuprofile='cpu.prof' -memprofile='mem.prof'
下面是benchmark输出的结果,通过单次运行消耗的时间,我们发现,下面这种字节切片转字符串的方式比上面那种更快。
#从左到右分别表示benchmark函数、运行次数、单次运行消耗的时间、单次运行内存分配的字节数和次数
BenchmarkBytes2StrRaw-4 442384430 26.62 ns/op 8 B/op 1 allocs/op
BenchmarkBytes2StrUnsafe-4 1000000000 1.524 ns/op 0 B/op 0 allocs/op
trace工具:是什么导致了接口响应延时高?
尽管我们拥有 pprof 这样堪称神器的工具,然而它所呈现的仅仅是基于采样后得到的聚合信息,并不包含协程运行的详细情况。因此面对后面这类需求时,它就爱莫能助了,比如说,当我们遇到接口延时明显偏高的情况,此时若想要深入了解协程具体是如何运行的详细信息,像是究竟哪个协程的运行时长比较长,又或者是什么原因导致了协程的运行受到阻塞等等。
不过好在 Golang 还为我们提供了另外一款十分有用的工具——trace。
当我们开启 trace 功能之后,程序便会对下面的一系列事件进行详细记录,并且会依据所搜集到的这些信息,生成能够以可视化方式查看的 trace 视图。具体记录的事件如下:
- 协程的创建过程、开始运行的时刻以及结束运行的时间点。
- 协程由于系统调用、通道操作、锁的使用等情况而出现被阻塞的现象。
- 网络 IO 相关的操作情况。
- 垃圾收集的相关活动情况。
那么trace该如何使用呢?
首先,和pprof一样,我们需要触发采集trace数据并生成trace报告。trace也支持多种采集触发方式。
通常对于线上应用,我们会引入net/http/pprof包,并在main函数中开放http端口。后面是示例代码。
import (
"net/http"
_ "net/http/pprof"
)
func main() {
err := http.ListenAndServe(":8888", nil)
if err != nil {
panic(err)
}
}
程序跑起来后,我们可以通过直接访问url并加参数控制触发采集,就像下面这样。
对于不能采用开放http端口采集trace数据的场景,Golang提供了runtime/trace包,像下面的代码一样,我们可以通过在代码中显式的触发和结束trace,来生成trace报告。
import (
"runtime/trace"
)
// 埋点触发的方式
func main() {
// 创建trace性能分析文件
f, err := os.Create("trace.out")
if err != nil {
panic(err)
}
defer f.Close()
if err := trace.Start(f); err != nil {
log.Fatalf("failed to start trace: %v", err)
}
defer trace.Stop()
// your program here
RunMyProgram()
}
生成了报告以后,我们用trace工具打开文件,首页包含了多个链接。我们一般重点关注下面两个内容,它们会分别从处理器视角和协程视角分析程序的运行情况。

有了trace报告,我们就可以分析协程阻塞情况和处理器是否得到充分使用。
比如我们想排查协程阻塞情况,就可以看协程分析(Goroutine analysis)视图。就像下面的图展示的一样,协程分析视图会将trace期间的所有协程,按运行时间降序排序。

点击单个协程,会进入下图单个协程的统计页面。在这个页面里,我们可以看到协程运行时间、同步阻塞时间、系统调用阻塞时间、调度延迟时间等。

当我们发现协程阻塞时间比较长时,可以通过点击Summary区的链接,就可以定位到具体的阻塞代码了。比如上图中的同步阻塞,我们点击Sync block profile可以定位到造成阻塞的代码,会发现存在通道读等待。

再比如,当我们想要查看处理器的使用状况时,便可以使用处理器分析视图(View trace by Proc)。后面就是这个视图的样子。

借助处理器视图,我们既能了解到多核是否处于被充分使用的状态,也能够知晓在某一特定时刻,处于不同状态的协程数量分别是多少。假如处于可调度(Runnable)状态的协程数量较多,这可能意味着创建的协程数量过多,导致无法得到 CPU 的有效调度。
此外,我们还能够查看在那些占用处理器时间的各类事件当中,究竟哪些是由垃圾回收(GC)所占用的。倘若垃圾回收占用 CPU 的时间过多,这同样也意味着程序处于一种不健康的运行状态。

小结
这节课的内容就到这里了,今天我们一共学习了三款 Golang 性能优化工具,并且了解了每个工具在分析各类问题时的具体用法。现在,我们再来一起回顾一下这几款工具的应用场景。
- 首先是 pprof 工具。当我们发现CPU 或者内存资源的占用率过高时,借助 pprof 工具能够精准快速定位到消耗资源的热点代码。
- 接着是 benchmark 工具。当我们有对不同方案进行性能对比的需求时,通过使用 benchmark 工具,可以获取到不同方案在耗时和内存消耗方面的对比详细情况。
- 最后是 trace 工具。当我们发现接口的延时比较高,想要深入了解程序内部具体的运行状况的时候,比如说想知道协程是否存在阻塞、处理器有没有被充分地利用起来等等,这时候就可以运用 trace 工具来精准定位到那些导致协程运行受阻的相关代码。
希望你能够好好体会在面对不同的性能场景时,应该如何去应用这几款性能工具。这样下次再碰到类似这些场景的时候,你就能很快找到趁手工具,更快找到出现瓶颈的原因,进而制定出有效的优化方案。
思考题
为什么有些公司会选择在 QPS 高峰期对线上进行 pprof 定时采样,而较少在此时进行 trace 操作呢?
欢迎你把你的答案分享在评论区,也欢迎你把这节课的内容分享给需要的朋友,我们下节课再见!
- 快叫我小白 👍(1) 💬(1)
在公司的报警系统中我也常看到类似图9这样的调用图,但是图中每个方块的函数名都非常陌生,甚至从未见过,请教一下老师这些函数名有什么解读规则吗?
2024-12-15 - onemao 👍(1) 💬(1)
高峰期pprof采样容易获得"极限值",较少时trace是因为样本少容易获取,分析trace也更方便
2024-12-11 - okkkkk 👍(0) 💬(1)
runtime/pprof 部分的代码有两个main函数,粘贴错了吧
2025-01-23 - MClink 👍(0) 💬(1)
Trace Viewer is running with WebComponentsV0 polyfill, and some features may be broken. As a workaround, you may try running chrome with "--enable-blink-features=ShadowDOMV0,CustomElementsV0,HTMLImports" flag. See crbug.com/1036492. how to do?
2024-12-22 - MClink 👍(0) 💬(1)
是版本问题吗,trace 我搞出来的。和老师的图不一样。长这个样子: Goroutines: runtime.main N=1 runtime/trace.Start.func1 N=1 N=4
2024-12-22 - 巅 👍(0) 💬(2)
程序里多个定时任务以及携程,最终pprof的结果打头都是runtime包的函数 看不到调用链,堆栈第一个都是runtime.mcall之类,这种则怎么分析呢
2024-12-14 - ly 👍(0) 💬(1)
go tool trace trace.out 2024/12/13 16:03:34 Preparing trace for viewer... failed to create trace reader: bad file format: not a Go execution trace?是版本的问题吗,我的版本go version go1.23.2 windows/amd64
2024-12-13