特别放送 Go泛型:用法、原理与最佳实践
你好,我是郑建勋。
泛型一直是自Go语言诞生以来讨论最热烈的话题之一,之前,Go语言因为没有泛型而被很多人吐槽过。经过了多年的设计,我们正式迎来了 Go1.18 泛型。这节课就让我们来看一看泛型的几个重要问题,你也可以先问一问自己下面几个问题。
- 什么是泛型?
- Go为什么需要泛型?
- Go之前为什么没有泛型?
- Go泛型的特性与使用方法是什么?
什么是泛型?
我们先来看看维基百科对泛型的定义。
Generic programming centers around the idea of abstracting from concrete, efficient algorithms to obtain generic algorithms that can be combined with different data representations to produce a wide variety of useful software.
泛型编程的核心思想是从具体的、高效的运算中抽象出通用的运算,这些运算可以适用于不同形式的数据,从而能够适用于各种各样的场景。
显然,泛型是高级语言为了让一段代码拥有更强的抽象能力和表现力而设计出来的。
许多语言都有对泛型的支持,我们可以看看其他语言是怎么实现泛型的。在Java中对函数进行泛型抽象的代码如下所示。
public static <E> boolean containsElement(E [] elements, E element){
for (E e : elements){
if(e.equals(element)){
return true;
}
}
return false;
}
其中,E代表类型参数,可以指代任何类型。这个函数的功能是查看任意类型的元素是否在对应的数组中。
Java是通过类型擦除(Type Erasure)来实现泛型的。类型擦除指的是在编译阶段,编译器会将上面的泛型函数实例化为如下的形式。
public static boolean containsElement(Object [] elements, Object element){
for (Object e : elements){
if(e.equals(element)){
return true;
}
}
return false;
}
在Java中,java.lang.Object是所有类型的父类。Java编译时的这个特性使得泛型函数并不会实例化为一个具体类型的函数,这导致了程序在运行时需要花费额外的成本处理实际类型与Object之间的转换。
同时,Java中无处不在的自动装箱和拆箱机制也不可避免地在运行时消耗时间与空间。
而 C++ 中实现泛型的方式称为模版。我们举一个例子,用C++求两个数的最大值。这里,C++中的模版只存在于编译时,编译时会将模版函数实例化为具体的类型。
#include <iostream>
using namespace std;
template <typename T> T myMax(T x, T y)
{
return (x > y) ? x : y;
}
int main()
{
cout << myMax<int>(3, 7) << endl;
cout << myMax<double>(3.0, 7.0) << endl;
cout << myMax<char>('g', 'e') << endl;
return 0;
}
例如,myMax 会将myMax函数实例化如下。
而 myMax 会实例化另一个myMax。
C++模版的这一特性使得它在编译时存在代码膨胀的问题,减慢了编译的速度。而由于C++允许循环依赖、模版会被实例化多次等问题,编译速度会进一步减慢。
我们可以看到,泛型在使代码变得抽象的同时,也不可避免地需要花费额外的成本。好在这通常是值得的,因为我们的最终目标就是能够写出更加抽象、更有表现力的高级语言。
Go为什么需要泛型?
Go作为强类型语言,在没有泛型之前,在许多场景下书写代码都很繁琐。例如,还是刚才要判断两个数的大小这个例子,在Go中一般需要调用math.Min与math.Max两个函数。 然而,由于函数参数定义了float64类型,所以并不适合其他的类型。
同样的例子还存在于加法操作中,我们无法写出一个能够适用所有类型的加法函数。在过去,每一个类型都需要写一个单独的函数,如下所示。
func SumInt64(x,y int64) int64{
return x + y
}
func SumInt32(x,y int32) int32{
return x + y
}
func SumUint64(x,y uint64) uint64{
return x + y
}
func SumUint32(x,y uint32) uint32{
return x + y
}
过去要解决这种问题,一般会采用go generate等工具自动生成代码,或者使用如下接口的方式。但都相对比较繁琐。
func Sum(a, b interface{}) interface{} {
switch a.(type) {
case int:
a1 := a.(int)
b1 := b.(int)
return a1 + b1
case float64:
a1 := a.(float64)
b1 := b.(float64)
return a1 + b1
default:
return nil
}
}
而泛型解决了这一问题。我们以数组的加法为例,通用的泛型加法函数如下所示,这是Go中的新语法。Go1.18后扩展了接口的能力,在这个例子中,Number是类型的集合,用于对类型进行约束,后面我们还会详细介绍。
type Number interface {
int | int64 | float64
}
func Sum[T Number](numbers []T) T {
var total T
for _, x := range numbers {
total += x
}
return total
}
上面的语法可以修改成更简洁的样子,如下。这一个函数适用于int、int64、float64 这三个类型数组的加法,而在过去却需要分别书写3个函数。
func Sum[T int | int64 | float64](numbers []T) T {
var total T
for _, x := range numbers {
total += x
}
return total
}
你可能会问,既然泛型有这么多好处,那为什么之前Go一直都没有实现泛型呢?我们可以从官方文档FAQ中找到问题的答案。总结一下,主要有下面几个方面的原因。
- Go语言专注于软件工程本身,其目的是设计出简单、可读、可扩展的语言。因此一开始为了确保其简单性,就没有将泛型作为语言的设计目标。
- 泛型通常会带来额外的成本,这个成本可能来自编译时或者运行时的耗时,还有复杂度的上升。因此设计泛型时,需要做好成本与收益的平衡。Go团队一开始并没有想清楚泛型的最终形态,并且Go的空接口也给了和泛型类似的灵活性,这就降低了泛型的紧迫性。
泛型的特性与使用方法
Go1.18引入了泛型之后,一些之前重复的代码就可以用更简单的泛型代码来表示了。Go的泛型有下面这些特点。
- 只存在于编译时,并不会在运行时有任何的性能损耗。
- 由于存在泛型,在编译时的编译速度会下降。但是由于Go对泛型的限制加上Go依赖管理禁止了循环依赖,Go没有代码膨胀问题,编译速度仍然一骑绝尘。
- 与C++不同,Go中的泛型是有类型约束的,它可以限制参数的类型范围。Go中的这种约束是通过扩展接口的能力实现的。
- 当前Go的泛型语法还有诸多限制,后续可能会放开。
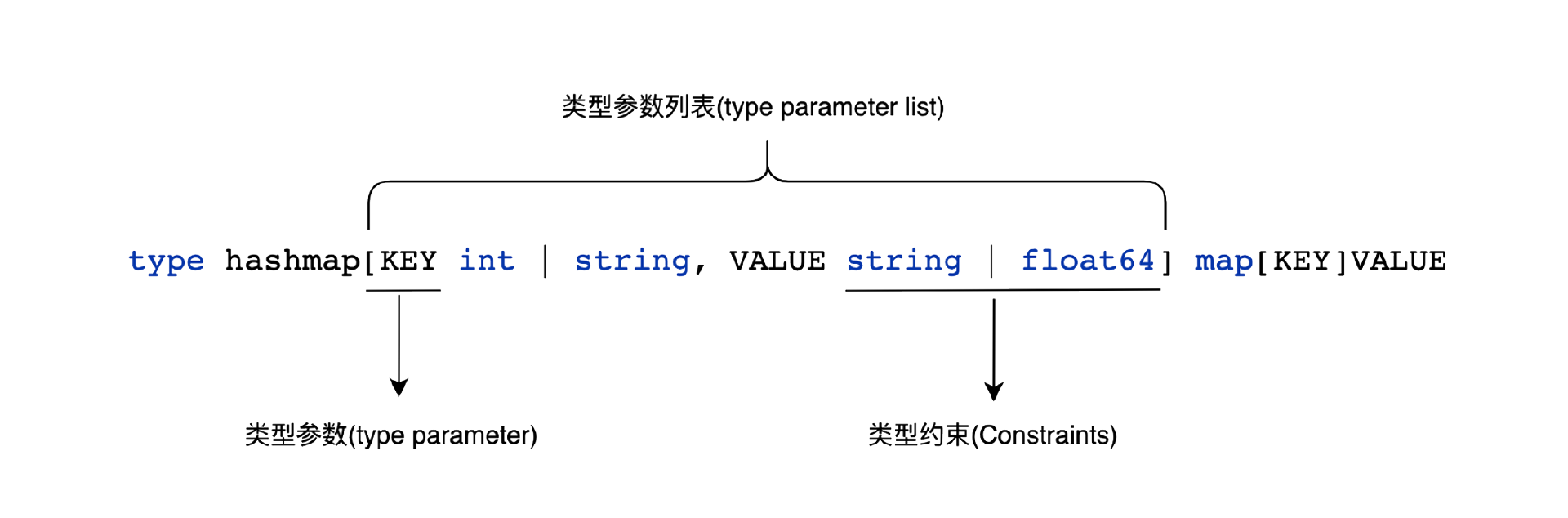
要准确地理解泛型这个新概念,我们需要明确一些概念在中英文中的差异,这样才有进一步讨论的基础。我们以下面这个简单的泛型变量HashMap为例,HashMap声明了一个带泛型的哈希表。其中Key可以是int或者string,而Value必须是string或者float。
在这个例子中,[]括号中的这一串叫做类型参数列表(Type Parameter List),类型参数列表是由多个类型参数组成的,中间用逗号隔开。这个例子中的Key与Value被叫做类型参数(Type Parameter),可以取任意的名字。它们后方的 int|string 与 string|float64 叫做类型约束(Constraints)。
此外,学习泛型时,还有几个重要知识点,分别是:
- 泛型的声明
- 泛型的类型约束
- 泛型的实例化
- 泛型的自动类型推断
- 泛型类型参数的操作与限制
- 泛型类型的转换
下面我们挨个来介绍一下这些知识点。
泛型的声明
我们先来看泛型的声明。泛型可以用在切片、哈希表、结构体、方法、函数、接口等类型中,我们先来看看泛型在各个类型中的表现,就能对泛型的声明方式有大体的了解。
- 泛型切片的声明。
该泛型切片可以指代下面的3种切片类型。
- 泛型哈希表的声明。
该泛型哈希表可以指代下面的4种切片类型。
type Map2 map[int]string
type Map3 map[int]float64
type Map4 map[string]string
type Map5 map[string]float64
- 泛型结构体的声明。
该泛型结构体可以指代下面的3种类型。
// 结构体
type Struct3 struct {
Title string
Content string
}
type Struct4 struct {
Title string
Content int
}
type Struct5 struct {
Title string
Content float64
}
- 泛型方法的声明。 下面的泛型方法可以灵活地对任意类型的Data进行加锁,并执行f函数。
type Lockable[T any] struct {
mu sync.Mutex
data T
}
func (l *Lockable[T]) Do(f func(*T)) {
l.mu.Lock()
defer l.mu.Unlock()
f(&l.data)
}
- 泛型函数的声明。 下面的函数NoDiff可以判断可变长度数组中的每一个元素是不是都是相同的。
// 函数
func NoDiff[V comparable](vs ...V) bool {
if len(vs) == 0 {
return true
}
v := vs[0]
for _, x := range vs[1:] {
if v != x {
return false
}
}
return true
}
- 泛型接口的声明。 下面的泛型接口可以指代不同类型的方法。
从上面的例子可以看出,不同的泛型声明都有相似的表示形式。无外乎在[]中添加类型参数,然后为类型参数加上类型约束,从而利用类型参数指代多种不同的类型。下面我们来看一看类型约束。
泛型的类型约束
正如之前看到的,Go可以为类型参数加上约束。其实我们可以将约束视为类型的类型,这种约束使类型参数成为了一种类型的集合,这个集合可能很大也可能很小。
Go引入了一些新的符号来表示类型的约束,我们具体来看一看。
~T表示一个类型集,它包括所有基础类型为 T 的类型。
举一个例子,type flag int 中的 flag 是一个新的类型,但是它的基础类型仍然是int。golang.org/x/exp/constraints 库也为我们预置了几个类型:Complex、Float、Integer、Ordered、Signed、Unsigned。以Ordered为例,它本身的定义如下,它约束了类型必须可以进行<、<=、>=、>等比较操作。
- Comparable为Go中的预定义类型,约束了类型可以进行等于和不等于的判断(、!)。
- Any也是Go中的预定义类型,它其实就是空接口的别名,在Go源码中,已经将所有的空接口都替换为了Any。
- T1 | T2 | … | Tn 表示集合类型,它指的是所有这些类型的并集,Tn可以是上方的
~T类型、基础类型或者是类型名。
uint8 | uint16 | uint32 | uint64
~[]byte | ~string
map[int]int | []int | [16]int | any
chan struct{} | ~struct{x int}
类型约束是通过接口来实现的,Go1.18放宽了接口的定义,可以在接口中包含类型的集合,如下所示。
type L interface {
Run() error
Stop()
}
type M interface {
L
Step() error
}
type N interface {
M
interface{ Resume() }
~map[int]bool
~[]byte | string
}
type O interface {
Pause()
N
string
int64 | ~chan int | any
}
接口中用空行分割的类型则标识了类型的交集。在下面这个例子中,约束 generic 是类型 int | ~float64 与 float64 的交集,所以 generic 只能够代表 float64 类型。 所以下例中尝试使用int类型实例化时,编译会报错。
type generic interface {
int | ~float64
float64
}
func Sum[T generic](numbers []T) T {
var total T
for _, x := range numbers {
total += x
}
return total
}
// int does not implement generic (int missing in float64)
func main() {
xs := []int{3, 5, 10}
total := Sum(xs)
fmt.Println(total)
}
另外,约束虽然靠的是扩展后的接口,但书写却可以简化,像下面两个类型参数列表就是等价的。
泛型的实例化
泛型类型必须被实例化才能够使用。和声明一样,让我们看看各个泛型类型是如何被实例化的。
- 泛型切片实例化
type Slice1 [T int|float64|string] []T
var MySlice1 Slice1[int] = []int{1,2,3}
var MySlice3 Slice1[string] = []string{"hello", "small", "yang"}
var MySlice5 Slice1[float64] = []float64{1.222, 3.444, 5.666}
- 泛型Map实例化
type Map1[KEY int | string, VALUE string | float64] map[KEY]VALUE
var MyMap1 Map1[int, string] = map[int]string{
1: "hello",
2: "small",
}
var MyMap3 Map1[string, string] = map[string]string{
"one": "hello",
"two": "small",
}
- 泛型结构体实例化
type Aticle [T string|int|float64] struct {
Title string
Content T
}
var s = Aticle[string]{
Title: "hello",
Content: "small",
}
// 复杂结构体的实例化
type MyStruct[S int | string, P map[S]string] struct {
Name string
Content S
Job P
}
var MyStruct1 = MyStruct[int, map[int]string]{
Name: "small",
Content: 1,
Job: map[int]string{1: "ss"},
}
- 泛型函数实例化
// 函数实例化
package main
func NoDiff[V comparable](vs ...V) bool {
if len(vs) == 0 {
return true
}
v := vs[0]
for _, x := range vs[1:] {
if v != x {
return false
}
}
return true
}
func main() {
var NoDiffString = NoDiff[string]
println(NoDiffString("Go", "go")) // false
println(NoDiff[int](123, 123, 789)) // false
}
// 函数实例化,例子2
type Ordered interface {
~int | ~uint | ~int8 | ~uint8 | ~int16 | ~uint16 |
~int32 | ~uint32 | ~int64 | ~uint64 | ~uintptr |
~float32 | ~float64 | ~string
}
func Max[S ~[]E, E Ordered](vs S) E {
if len(vs) == 0 {
panic("no elements")
}
var r = vs[0]
for i := range vs[1:] {
if vs[i] > r {
r = vs[i]
}
}
return r
}
type Age int
var ages = []Age{99, 12, 55, 67, 32, 3}
var langs = []string {"C", "Go", "C++"}
func main() {
var maxAge = Max[[]Age, Age]
println(maxAge(ages)) // 99
var maxStr = Max[[]string, string]
println(maxStr(langs)) // Go
}
- 泛型方法实例化
package main
import "sync"
type Lockable[T any] struct {
mu sync.Mutex
data T
}
func (l *Lockable[T]) Do(f func(*T)) {
l.mu.Lock()
defer l.mu.Unlock()
f(&l.data)
}
func main() {
var n Lockable[uint32]
n.Do(func(v *uint32) {
*v++
})
var f Lockable[float64]
f.Do(func(v *float64) {
*v += 1.23
})
var b Lockable[bool]
b.Do(func(v *bool) {
*v = !*v
})
var bs Lockable[[]byte]
bs.Do(func(v *[]byte) {
*v = append(*v, "Go"...)
})
}
// 方法实例化,例子2
type Number interface{
int | int32 | int64 | float64 | float32
}
//定义一个泛型结构体,表示堆栈
type Stack[V Number] struct {
size int
value []V
}
//加上Push方法
func (s *Stack[V]) Push(v V) {
s.value = append(s.value, v)
s.size++
}
//加上Pop方法
func (s *Stack[V]) Pop() V {
e := s.value[s.size-1]
if s.size != 0 {
s.value = s.value[:s.size-1]
s.size--
}
return e
}
//实例化成一个int型的结构体堆栈
s1 := &Stack[int]{}
//入栈
s1.Push(1)
s1.Push(2)
s1.Push(3)
fmt.Println(s1.size, s1.value) // 3 [1 2 3]
//出栈
fmt.Println(s1.Pop()) //3
fmt.Println(s1.Pop()) //2
fmt.Println(s1.Pop()) //1
- 泛型接口实例化
type MyInterface[T int | string] interface {
WriteOne(data T) T
ReadOne() T
}
type Note struct {
}
func (n Note) WriteOne(one string) string {
return "hello"
}
func (n Note) ReadOne() string {
return "small"
}
var one MyInterface[string] = Note{}
fmt.Println(one.WriteOne("hello"))
fmt.Println(one.ReadOne())
从上面泛型实例化的例子中我们可以看出,在实际使用泛型时,我们需要在[]中明确泛型的具体类型,这样编译器就能够为我们生成具体类型的函数或者类型了。不过,每一次都需要在[]中指定类型还是比较繁琐的,好在借助编译器的自动推断能力,我们就可以简化泛型实例化的书写方式。
泛型的自动类型推断
以泛型函数实例化为例,借助编译时的自动类型推断,泛型函数的调用可以像调用正常的函数一样自然。
// 函数实例化
package main
func NoDiff[V comparable](vs ...V) bool {
if len(vs) == 0 {
return true
}
v := vs[0]
for _, x := range vs[1:] {
if v != x {
return false
}
}
return true
}
func main() {
println(NoDiff("Go", "Go", "Go")) // true,自动推断
println(NoDiff[string]("Go", "go")) // false
println(NoDiff(123, 123, 123, 123)) // true, 自动推断
println(NoDiff[int](123, 123, 789)) // false
type A = [2]int
println(NoDiff(A{}, A{}, A{})) // true, 自动推断
println(NoDiff(A{}, A{}, A{1, 2})) // false,自动推断
println(NoDiff(new(int))) // true,自动推断
println(NoDiff(new(int), new(int))) // false,自动推断
}
泛型类型参数的操作与限制
在使用泛型的过程中,我们还不可避免地会遇到一个问题,那就是在对类型参数进行操作时,哪些操作是有效的,哪些是无效的?下面我们来看一些类型参数允许的重要操作。
- 类型断言
类型参数本质是扩展了接口的能力实现的,因此它仍然可以进行类型的断言,判断实际的类型以给出不同的操作。
import "fmt"
func nel[T int | string](x any) {
if v, ok := x.(T); ok {
fmt.Printf("x is a %T\\n", v)
} else {
fmt.Printf("x is not a %T\\n", v)
}
}
func wua[T int | string](x any) {
switch v := x.(type) {
case T:
fmt.Println(v)
case int:
fmt.Println("int")
case string:
fmt.Println("string")
}
}
- 核心类型限制
由于类型参数是类型的集合,原则上只有当类型参数中的所有类型都可以执行这个操作时,才被认为是有效的。下面这类操作在编译时就会直接报错,因为Any是所有类型的集合,但是并不是所有类型都可以进行加法操作。
// invalid operation: operator + not defined on total (variable of type T constrained by any)
func Sum[T any](numbers []T) T {
var total T
for _, x := range numbers {
total += x
}
return total
}
此外,即便是类型参数中的所有类型都可以执行的操作,在Go中也有一些限制。例如,对于下面的函数类型,调用时必须具有相同的核心类型,否则会在编译时报错。一般来说,如果一个类型参数的所有类型都共享一个相同的底层类型,这个相同的底层类型就被称为类型参数的核心类型。
func foo[F func(int) | func(any)] (f F, x int) {
f(x) // error: invalid operation: cannot call non-function f
}
func bar[F func(int) | func(int)int] (f F, x int) {
f(x) // error: invalid operation: cannot call non-function f
}
type Fun func(int)
func tag[F func(int) | Fun] (f F, x int) {
f(x) // okay
}
执行切片的截取操作时,类型参数也必须具有相同的核心类型。
func foo[T []int | [2]int](c T) {
_ = c[:] // invalid operation: cannot slice c: T has no core type
}
func bar[T [8]int | [2]int](c T) {
_ = c[:] // invalid operation: cannot slice c: T has no core type
}
同样的道理也存在于 for-range 循环中。
func values[T []E | map[int]E, E any](kvs T) []E {
r := make([]E, 0, len(kvs))
// error: cannot range over kvs (T has no core type)
for _, v := range kvs {
r = append(r, v)
}
return r
}
泛型类型的转换
类型参数还可以完成类型的转换操作。例如,要想让 From 类型顺利转换为 To 类型,必须确保 From 中的所有类型都能够强制转换为 To 中的所有类型,只有这样操作才是有效的。
func pet[A ~int32 | ~int64, B ~float32 | ~float64](x A, y B){
x = A(y)
y = B(x)
}
func dig[From ~byte | ~rune, To ~string | ~int](x From) To {
return To(x)
}
func cov[V ~[]byte | ~[]rune](x V) string {
return string(x)
}
func voc[V ~[]byte | ~[]rune](x string) V {
return V(x)
}
func eve[X, Y int | string](x X) Y {
return Y(x) // error
}
相似的情况还出现在内置的len函数、make函数、close函数中,这里就不一一赘述了。
除了转换,当前Go泛型中还有一个重要的限制,就是方法的接受者可以有类型参数,但是方法中不能够有类型参数。例如下面的代码在编译时会直接报错。
type MyThing[T any] struct {
value T
}
// syntax error: method must have no type parameters
func (m MyThing[T]) Perform[R any](f func(T) R) R {
return f(m.value)
}
func main() {
fmt.Println("Hello, playground")
}
总结
Go1.18之后,我们期待已经的泛型终于问世了。泛型使Go能够书写更加简单、抽象的代码。但泛型通常也是成本与收益之间的权衡。
Go的泛型只存在于编译时,它以增加少量编译时间为代价,换来了更方便的代码书写。泛型的使用方法需要重点考虑几个问题,即泛型的声明、泛型的约束、泛型的实例化和泛型的操作。
Go泛型通过扩展接口的能力实现了类型的集合与约束,但是当前Go中的泛型仍然有不少的限制。在实际使用时,我建议你像往常一样书写代码,当真正需要代码抽象时替换为泛型也不迟。
- 牙小木 👍(1) 💬(1)
Key 可以是 int 或者 string,而 Value 必须是 string 或者 float。没get到这句话啥意思
2023-08-19