09 破解性能谜题:性能优化的五层境界
你好,我是郑建勋。
俗话说:“九层之台,起于累土”,在上节课,我们搭建起了Go程序性能优化的分层分析范式,并讲解了系统设计与程序设计层面需要考虑的性能问题。
在这节课,我将更进一步,分析一下影响高性能程序的底层基石:代码实施、操作系统与硬件。分析如何在这些层面进行设计和调优,最终实现高性能的目标。
让我们先从代码实施阶段讲起。
代码实施级别
代码实施,简单来说就是实际的代码开发。为了满足特定的目标,我们要在代码的设计、开发以及最终阶段对性能进行合理甚至是极致的优化。
编写代码时的性能优化有三层境界:
- 合理的代码;
- 刻意的优化;
- 危险的尝试。
合理的代码
合理的代码看起来非常自然,就像是从优秀开发者的指尖自然流淌出来的,但这样的代码对开发者的个人素质要求却极高。由于不同开发者在语言理解和程序设计上的差异,他们开发出来的代码常常风格迥异。这就需要一些制度和规范来帮助我们写出更优雅、高效、易懂的代码。
这些规范涉及程序开发的方方面面,包括目录结构规范、测试规范、版本规范、目录结构规范、代码评审规范、开发规范等等。这部分你可以参考一下UBER开源的Go语言开发规范。有时只需要遵守一些简单的规则,就能够大幅度减少未来在性能方面的困扰(我在后面将会给出一版更详细的Go语言开发规范)。
不合理的代码是什么样的呢?我们来看看下面这段程序,它的目的是往切片中循环添加元素。
func createSlice(n int) (slice []string) {
for i := 0; i < n; i++ {
slice = append(slice, "I", "love", "go")
}
return slice
}
从功能上来看,这段代码没有问题。但是,这种写法忽略了一个事实,如下图所示,往切片中添加数据时,切片会自动扩容,Go运行时会创建新的内存空间并执行拷贝(详细的扩容过程可以参考《Go语言底层原理剖析》)。
自动扩容显然不是没有成本的。在循环操作中执行这样的代码会放大性能损失,减慢程序的运行。性能损失的对比可参考这篇文章。

我们可以改写一下上面这段程序,在初始化时指定合适的切片容量:
func createSlice(n int) []string {
slice := make([]string, 0, n*3)
for i := 0; i < n; i++ {
slice = append(slice, "I", "love", "go")
}
return slice
}
这段代码在一开始就指定了需要的容量,最大程度上减少了内存的浪费。同时,运行时不需要再执行自动扩容的操作,加速了程序的运行。
除了切片,哈希表也比较容易犯类似的错误。一叶知秋,这个案例启发我们,即便是一开始不太理解底层的实现逻辑,也需要遵守一些基本的规则规避常见的性能陷阱,从小处开始优化代码编写习惯。
除了遵守常见的规范,要写出合理的代码,还需要对算法和数据结构进行设计改造。有人说“程序=算法+数据结构”,可见这两者的重要性。
对于算法来说,关键算法的调整常常能够给性能带来数倍的提升。例如,将冒泡排序(o(n^2))替换为快速排序(o(n*logn)),将线性查找(o(n)) 替换为二分查找(o(log n)),甚至到哈希表的方式(o(1)),都是常见的算法升级。
对数据结构的优化指的是添加或更改正在处理的数据的表示。数据结构在很大程度上决定了数据的处理方式,进而决定了时间与空间复杂度。举一个简单的例子,如下图所示,如果在链表的头部节点添加一个表明链表长度的字段,就不必遍历链表才能得到链表的总长度了。

有时候,我们需要做一些空间换时间的trade-off。缓存就是一种提高性能,减少数据库访问和防止全局结构锁的机制。缓存这种空间换时间的策略,在高并发程序中的应用非常广泛。不管是CPU多级缓存、Go的运行时调度器,还是Go内存分配管理,甚至标准库中sync.Pool的设计都包含了利用局部缓存提高整体并发速度的设计。
在设计算法与数据结构时要考虑的另一个重要因素是实现的复杂度。如下图所示,Go 1.13之前,内存分配使用了Treap平衡树,Treap 是一种引入了随机数的二叉树搜索树,它的实现简单,并且引入的随机数和必要的旋转保证了比较好的平衡特性。又如,Redis中选择跳表这样的数据结构是考虑到了红黑树等结构在实现上的复杂性。

当完成重要过程的优化之后,你应该对修改的功能进行Benckmark性能测试,并通过benchstat 工具对比两次Benckmark的差别,做到心中有数。
$ benchstat old.txt new.txt
name old time/op new time/op delta
GobEncode 13.6ms ± 1% 11.8ms ± 1% -13.31% (p=0.016 n=4+5)
JSONEncode 32.1ms ± 1% 31.8ms ± 1% ~ (p=0.286 n=4+5)
刻意的优化
写出合理的代码是一个优秀系统的第一步,但这还不够,为了达到性能目标,有时候我们需要对代码进行刻意的优化。例如,虽然Go语言适用于大多数通用场景,但是有时候我们业务面临的场景比较特殊,这时候就需要单独进行调优。刻意优化的点有很多,细化一点可以是:
- 放入接口中的数据会进行内存逃逸,需不需要优化?
- 字节数组与String互转导致的性能损失需不需要优化?
- 无用的内存需不需要复用?
当前,我们不用考虑这种细节问题, 因为这些优化点带来的性能损失很微小,很少成为程序真正的瓶颈,至少在项目开发的初期是这样。这里我想要讨论的刻意优化,是当前面临的最核心、最急需解决的问题。
优化的前提是定位瓶颈问题。能够发现程序哪里有问题并想办法解决,对开发者来说比写出合理的程序更难。因为排查问题时的不确定性更多,需要掌握的知识也更多。在后面的课程中,我会通过具体的案例为你演示如何通过pprof、trace、dlv、gdb等工具定位瓶颈问题。
瓶颈问题需对症下药,工具暴露出来的瓶颈通常就是我们要优化的目标。有时这种瓶颈是不明显的,需要开发者做一些假设并验证自己的猜想。有时数据结构和算法在之前是合理的,但是随着并发越来越大,就开始变得不合理了。
举一个例子,程序中常常使用JSON进行结构体的序列化,但是由于标准JSON库使用了大量反射,当并发量大幅度增加时,JSON标准库的耗时就可能变为瓶颈,这时需要考虑将标准库替换为更快的第三方库,甚至需要使用protobuf等更快的序列化方式。
还有一些优化涉及到Go语言的编译时和运行时。例如,之前介绍过的将环境变量GOMAXPROC调整为更合适的大小,本质上就是在修改运行时可并行的线程数量。
此外,当并发量上来之后,垃圾回收(GC)也可能成为系统的瓶颈所在。GC有一段STW的时长完全不能执行用户协程,并且在并行标记期间会占用25%的CPU时间。如果STW时间过长,或者并发标记阶段由于频繁的内存分配触发了辅助标记,都会导致程序无法有效处理用户协程,产生严重的响应超时问题。

一般这类GC问题可以通过修改代码逻辑减少内存分配频繁,或是借助sync.pool等内存池复用内存来解决。另外,运行时也暴露了一些有限的API能够干预垃圾回收的运行,在特殊情况下调整这些参数能够提高程序运行效率:
- 运行时环境变量GOGC可以调整GC的内存触发水位,当GOGC=off时,它甚至能够关闭GC的执行;
- Runtime.GC()可以手动强制执行GC。
另外,设置运行时环境变量GODEBUG=gctrace=1 可以让运行时打印GC的相关日志。
还有一些刻意的优化与Go的版本有关,需要具体版本具体分析。例如,Go1.14之前的版本,死循环没有办法被抢占,因此经常出现程序被卡死的现象。那在使用这些版本时,就不得不做一些特殊的判断和处理了。
危险的尝试
最后,代码实施阶段,由于迫不得已的原因,可能还需要进行一些特别的“危险的尝试”。
例如,由于很多机器学习库是用C或者C++完成的,因此需要使用CGO的技术。我曾经深度写过CGO相关的项目,可以说是苦不堪言。你可以看看下面这段代码,在这里,开发会面临各种问题:没有编辑器的提示,语法繁琐,难以调试,内存不受到Go运行时的管理。所以说不到万不得已,不要使用CGO。

另外,Go语言语法本身屏蔽了指针的操作,但有些场景为了提高性能,或为了使用某些高级能力会用到unsafe库操作指针。然而,想要正确地使用unsafe是很难的。
- 首先,Go语言中的unsafe库本身不是向后兼容的,这意味着在当前版本中有效的代码在之后的版本中的行为是未知的。
- 另外,对指针进行运算的uintptr类型本质上是一个整数,Go内置的垃圾回收无法对它进行管理。操作指针时,由于Go运行时栈的自动扩容,可能导致之前指针指向的内容无效。这些危险的操作,需要开发者摸透使用规则并进行正确的权衡(unsafe包的具体用法可以参考这篇文章)。
有些底层操作,为了获得更高的性能或者使用语言级别未暴露的功能(例如特殊的CPU指令),甚至需要书写汇编代码。举一个例子,TiDB数据库为了提高浮点数计算性能就使用了汇编代码。
刚才,我把代码实施分成了三层境界:合理的优化,刻意的优化,危险的优化。当我们能写出合理的代码时,才算是入了门,成为了一个合格的开发者。而当我们可以精细化地调优,驾驭整个程序时,我们的技术功夫才算是走向了成熟。代码实施就像盖房子,这座房子是由一块块砖砌成的,在码好每块砖的同时,还需要发挥创造力,这是更加考验开发者功力的时刻。
接下来我们继续看看程序的基座,也就是操作系统对性能的影响。
操作系统级别
程序是运行在操作系统基座之上的,程序所处的环境和操作系统的一些特性会深刻影响程序的性能。

如图所示,Linux操作系统位于硬件与用户应用程序之间。它一方面托管了与硬件的交互,另一方面提供了与应用程序交互的API。具体来说,Linux操作系统提供了下面几个重要的功能:
- 进程管理,例如进程启动与管理;
- 内存管理,例如为进程分配内存或将文件映射到内存;
- 网络管理,例如提供网络编程的API以及处理TCP协议栈;
- 文件管理,例如文件系统的组织、创建和删除;
- 设备管理。
一个程序通常会用到操作系统提供的多种服务,要在操作系统层面解决瓶颈问题,我们要做的第一步就是明确我们需要优化哪一个方向。例如,我们希望排查系统CPU利用率高的问题,主要关注的是操作系统对进程的管理与调度;如果要排查内存问题,则主要关注内存分配与缓存等问题;如果网络耗时过长,我们主要关注的则是操作系统的网络协议栈。当然,有一些问题可能是交叉的,例如,频繁的内存与磁盘的交换(swap)也会导致CPU利用率的飙升。
要在操作系统层面解决瓶颈问题,我们要做的第二步是熟悉我们希望优化的操作系统的核心功能流程与架构,从而才能有针对性地使用相关工具进行验证。例如,要排查CPU利用率过低的问题,需要明确操作系统如何将程序调度到CPU中执行、哪些问题可能导致CPU陷入等待或者发生切换、中断。
要解决这些问题,我们需要掌握相应的概念和知识,其中就包括了操作系统调度的原理。操作系统将程序分为了多个线程,并将线程调度到 CPU 上运行。为了公平地调度每一个线程,Linux2.6之后引入了CFS调度器,如下图所示。线程按照运行的优先级存储在红黑树结构中,红黑树中最左侧的线程会优先被调度执行。

下面几种情况都可能导致应用程序的CPU利用率低:
- 从线程可以运行到线程实际运行仍然有一定延时,当运行的程序越来越多,这种延迟会更加明显;
- 线程在执行过程中,可能会陷入到等待磁盘I/O的数据返回,I/O 等待时间越长,程序运行越慢;
- 线程在执行过程中,调度器会定时检查当前线程是否需要被抢占,执行线程的上下文,上下文切换越频繁,实际执行有用代码的时间就越短;
- 除此之外,影响CPU运行的原因可能来自硬/软中断信号,这时CPU会暂停当前的任务并执行中断处理程序。
在操作系统层面解决瓶颈问题的第三步,是要用对应的工具验证和排查瓶颈问题。
例如我们要排查系统CPU利用率异常的问题,其实就是要查看CPU在一段时间内更多的在做哪一部分的工作。我们期望CPU能够更多的执行应用程序交代的工作,而不是陷入到执行内核线程或者是大量时间堵塞在与硬件设备的I/O交互中。
我们有多种工具可以观察当前操作系统的资源利用情况。以CPU利用率为例,最常见的TOP命令可以查看用户CPU使用率、系统CPU使用率、IO WAIT率。而mpstat命令可以查看CPU软中断和硬中断使用率。不同指标的使用率上升对应的常见原因如图所示。从而我们可以更进一步明确CPU利用率异常的原因。
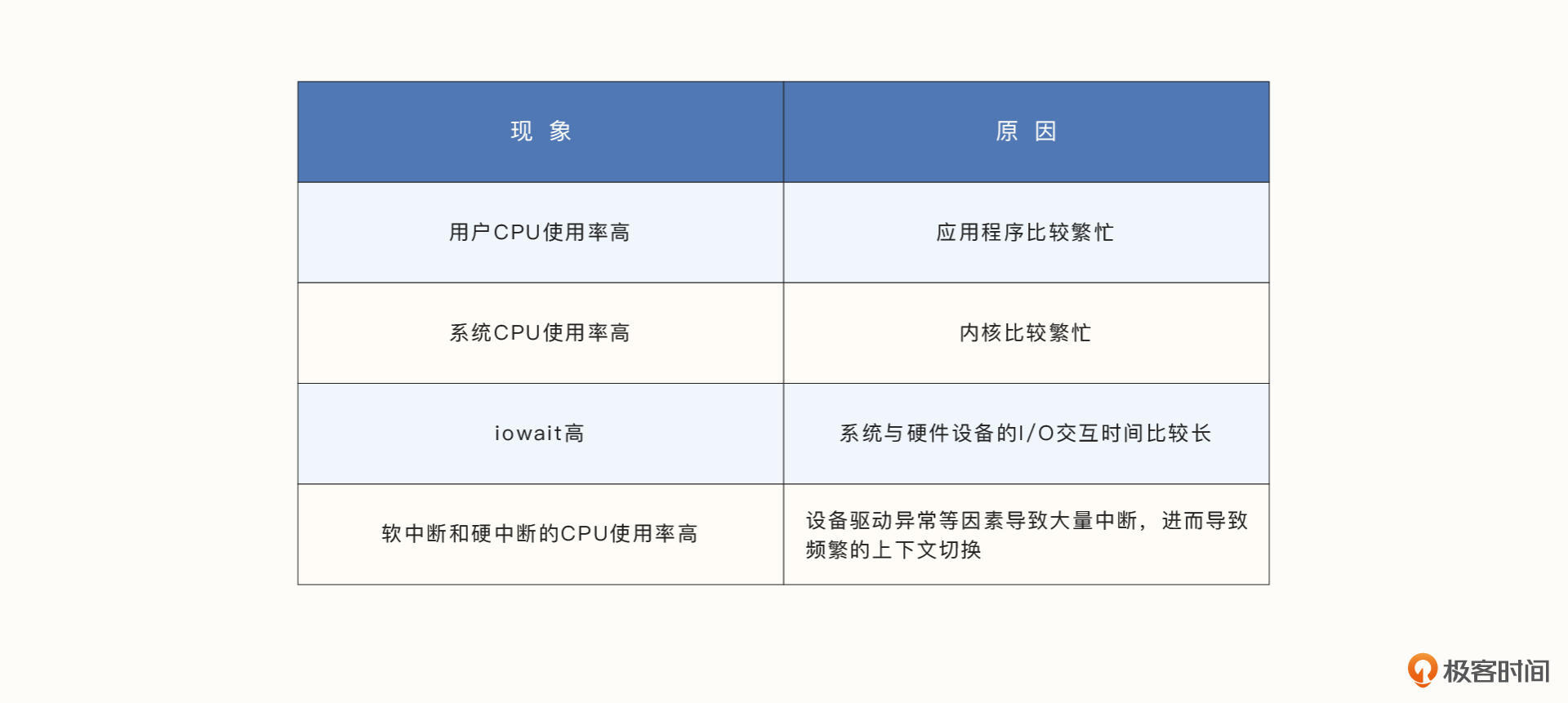
如果你想要了解更多在操作系统级别分析CPU、内存、文件、网络、磁盘等资源的现状、瓶颈、方法和工具,可以参考《Systems Performance, 2nd Edition》这本书。像perf这类工具甚至可以查看到操作系统的线程堆栈信息,输出CPU火焰图,快速寻找最可能的代码瓶颈。在某一个程序卡死导致无法响应的时候,或者在排查程序调用耗时过长问题时尤其有用。

容器化时代对分析和排查性能问题又提出了新的挑战。例如,Linux通过Cgroup和Namespace技术构建了轻量级的虚拟容器把资源隔离开,这样容器只能够使用限制好的资源,而不能使用宿主机的全部资源。
由于操作系统的很多观测手段还不成熟,一些初学者很容易被误导。例如在容器中top命令获得的cpu idle 和load average信息实际上是宿主机的信息,而进程的利用率等信息只是容器内部的信息。如果不清楚信息实际的含义,将导致我们得出错误的结论。这时候我们就可以使用像cadvisor这种第三方库获取容器的相应指标。
操作系统为我们屏蔽掉了不同硬件处理的细节,但操作系统也是一个特殊的软件,仍然是运行在硬件之上的,硬件的性能决定了处理速度的上限,硬件的设计值得我们在设计软件时参考,有效利用硬件的特性也能加速软件的运行,下面让我们看看性能优化的硬件级别。
硬件级别
操作系统的底座是硬件,上层开发者很少涉及硬件层面的内容,这是因为操作系统已经为我们屏蔽了硬件的细节。但是了解现代处理器的架构对于理解程序运行,书写高质量代码甚至解决一些棘手问题来说仍然意义重大。
大多数现代通用计算机的架构(个人电脑、笔记本电脑和服务器)都是基于冯·诺依曼的体系搭建的。它们的架构是由多个核心组成的中央处理器 (CPU)。每个内核都可以使用保存在随机存储器(RAM)或任何其他存储器(如寄存器或高速缓存)中的数据来执行所需要的指令。
下图是具有多核CPU和统一内存访问(UMA)的计算机体系结构,CPU通过总线与外部组件连接。当处理器数量增加时,由于对共享总线资源的争用,使用系统总线会出现可伸缩性问题,因此现代多核计算机通常采用了优化后的NUMA架构。
 的计算机体系结构")
和之前提到的操作系统的优化思路一样,硬件级别的优化也需要明确某一个优化的方向并熟悉其内部的架构。
CPU、内存、磁盘的架构都可谓别有洞天。以CPU为例,其内部包含了L1、L2和L3级缓存,了解这些缓存特性将有助于我们加快程序速度。
由于CPU高速缓存的特性,访问之前获取过的数据及其相邻数据的速度会更快。CPU高速缓存的特性影响了程序数据结构的设计。例如Go语言哈希表在解决哈希冲突时就考虑了CPU高速缓存的特性,使用了优化后的拉链法,每一个桶中存储了8 个元素,加快了哈希表的访问速度。
CPU缓存的特性还涉及到伪共享(False Sharing)。当多线程修改看似互相独⽴的变量时,如果这些变量共享同⼀个缓存⾏,就会在⽆意中影响彼此的性能,在Go源码中就常常看到这样的设计。
除此之外,现代CPU还有另一个特性:分支预测。

CPU 应用了各种算法和启发式方法来猜测程序在未来的分支,以便将执行的指令提前预取到CPU的缓存中,加快执行速度。
分支的预测是怎么实现的呢?下面我用两个函数来说明一下。请你思考一下,下面的两个程序有区别吗?从表面看,它们都执行了10000×1000×100次操作,但是它们实际运行的时间却相差很大。
func fast(){
for i:=0;i<100;i++{
for j:=0;j<1000;j++{
for k:=0;k<10000;k++{
}
}
}
}
func slow(){
for i:=0;i<10000;i++{
for j:=0;j<1000;j++{
for k:=0;k<100;k++{
}
}
}
}
对程序执行简单的性能测试,从输出的结果可以看出,fast函数比slow函数快了大约40%。这是什么原因呢?
原来,CPU会根据PC寄存器里的地址,从内存中把需要执行的指令读取到指令寄存器中执行,然后根据指令长度自增,开始从内存中顺序读取下一条指令。而循环或者if else语句会根据判断条件产生两个分支,其中一个分支成立时对应着特殊的跳转指令,它会修改PC寄存器中的地址。这样,下一条要执行的指令就不是从内存中顺序加载了。而另一个分支仍然会顺序读取内存中的指令。
最简单的一种分支预测策略是假定跳转不会发生。如果CPU执行了这种策略,那么对应到上面的循环代码就会始终循环下去。
我们仔细算一下。上面的fast 函数中,内层 k 每循环一万次才会发生一次预测上的错误。而同样的错误在外层i、j 循环上则每次都会发生。在这个运行周期内,j循环发生了1000 次预测错误,最外层的i循环发生了100次预测错误,所以一共会发生100 × 1000 = 10万次预测错误。而对于slow函数来说,内部k每循环100次,就会发生一次预测错误。而同样的错误,外层i、j每次循环都会发生。也就是说,第二层j循环发生了1000 次,最外层i循环发生了10000次,所以一共会发生1000×10000 = 1000万次预测错误。这是导致slow函数性能更差的原因。
硬件级别的优化的最后一步,涉及到用工具检测相关的指标并验证相关的结论,这些工具包括了mpstat、vmstat、perf、turboboost等诸多工具,具体你仍然可以参考《Systems Performance, 2nd Edition》这本书。
总结
好了,这节课就讲到这里。
性能分析的广度与深度都是超出想象的,它非常考验开发者的功力。如果没有方法论的支撑,找到性能问题并快速调优无异于大海捞针。
在这两节课里,我通过分层抽象的方法,带着你从最底层的硬件到最上层的系统设计,从设计、开发到发现问题和调优,拆解了性能问题的方方面面。希望能够帮助你查漏补缺,在遇到瓶颈问题时有的放矢。我也给你画了一张详细的思维导图,供你随时查看。
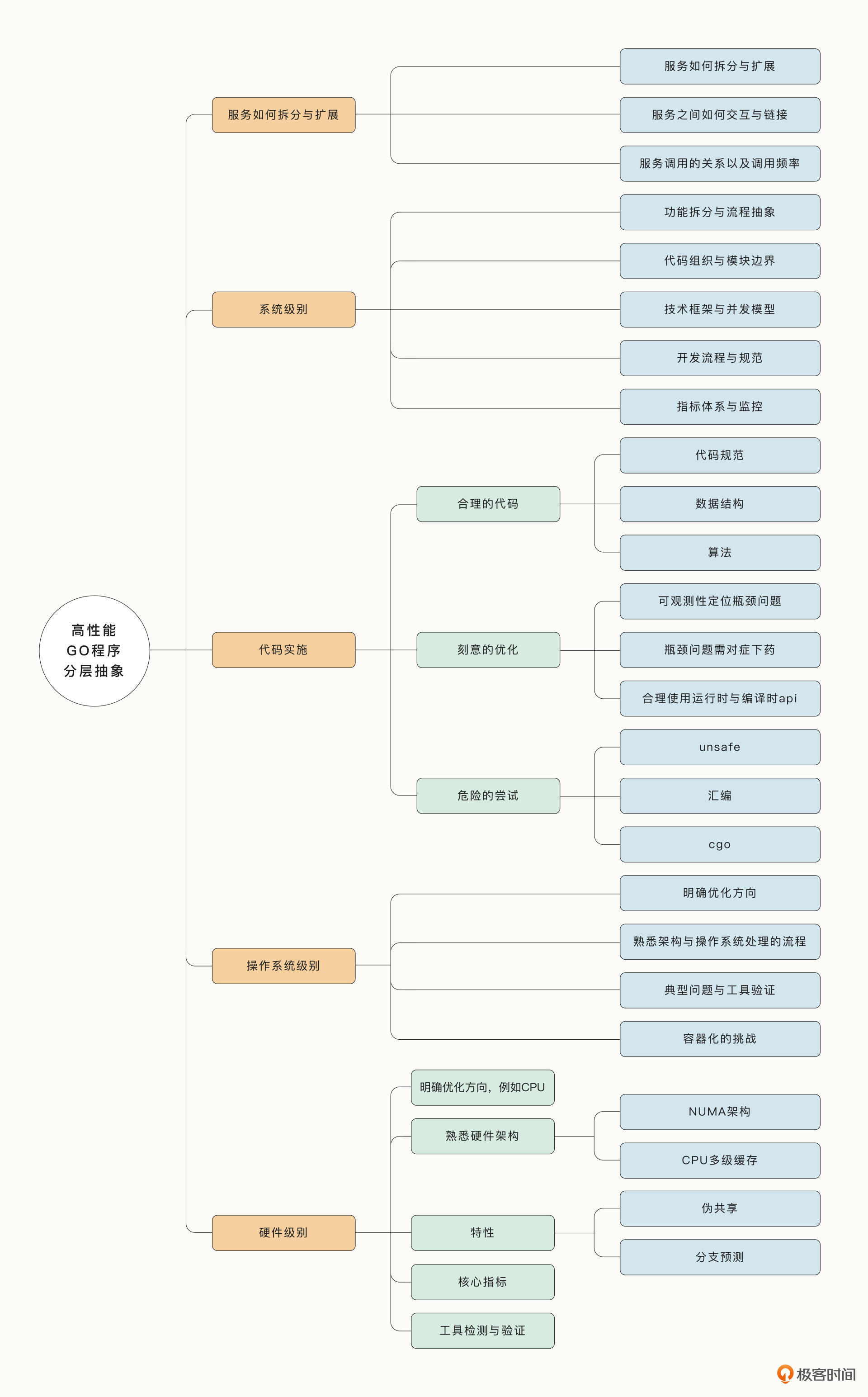
我们花了两节课程学习高性能程序前期的设计,但你可能有一个疑问,我们应该在哪一个阶段处理掉性能问题更好呢?
这个问题让我想起了扁鹊三兄弟的故事。扁鹊三兄弟的医术大哥最高,二哥其次,扁鹊最差。但是只有扁鹊名动天下。原因是大哥的医术最高,可以防患于未然。而扁鹊在病人病入膏肓、奄奄一息之时下虎狼之药,起死回生。这正是善战者无赫赫之名的道理。
我想,对于有追求的开发者,我们佩服的是扁鹊大哥这样的人物。如果我们能够在项目设计之初,就规避掉未来很长时间内可能遇到的性能瓶颈,又哪里会在出问题之后再手忙脚乱呢?
课后题
最后,我也给你留一道思考题。
写出合理的代码有时候需要工具的支持,你知道哪些工具可以用来规避代码书写中的错误?
欢迎你在留言区与我交流讨论,我们下节课再见!
- 范飞扬 👍(3) 💬(2)
课后思考题:现代IDE都支持语法检测,但不支持一些最佳实践。最近用了Copilot,发现它的代码提示非常强大,也可以作为“规避代码书写中的错误”的工具。老师怎么看Copilot? 它适合在学习中使用吗?它适合在工作中使用吗?
2022-10-31 - 8.13.3.27.30 👍(2) 💬(1)
太抽象了 后续有没有实战 手把手一样的 练习
2022-11-10 - 那时刻 👍(1) 💬(1)
文中提到:如何通过 pprof、trace、dlv、dgb 等工具。这里的dgb应该是gdb么?
2022-11-08 - Realm 👍(3) 💬(0)
1 编辑器很多提供lint,如goland安装一些插件,错误、警告⚠️都提示出来了; 2 可以配置golangci-lint ,确定哪些需要强制检查; 3 配合CI,在push代码的时候,强制检查; 确定原则、形成规范、逐步推广、优化.
2022-10-29 - 徐海浪 👍(2) 💬(1)
思考题: SonarQube等代码扫描工具
2022-10-30 - 奕 👍(1) 💬(0)
各种 linter
2022-10-29