32 存储引擎:数据清洗与存储
你好,我是郑建勋。
爬虫项目的一个重要的环节就是把最终的数据持久化存储起来,数据可能会被存储到MySQL、MongoDB、Kafka、Excel等多种数据库、中间件或者是文件中。
要达到这个目的,我们很容易想到使用接口来实现模块间的解耦。我们还要解决数据的缓冲区问题。最后,由于爬虫的数据可能是多种多样的,如何对最终数据进行合理的抽象也是我们需要面临的问题。
这节课,我们将书写一个存储引擎,用它来处理数据的存储问题。
爬取结构化数据
之前我们爬取的案例比较简单,像是租房网站的信息等。但是实际情况下,我们的爬虫任务通常需要获取结构化的数据。例如一本书的信息就包含书名、价格、出版社、简介、评分等。为了生成结构化的数据,我以豆瓣图书为例书写我们的任务规则。
第一步,从首页中右侧获取热门标签的信息。
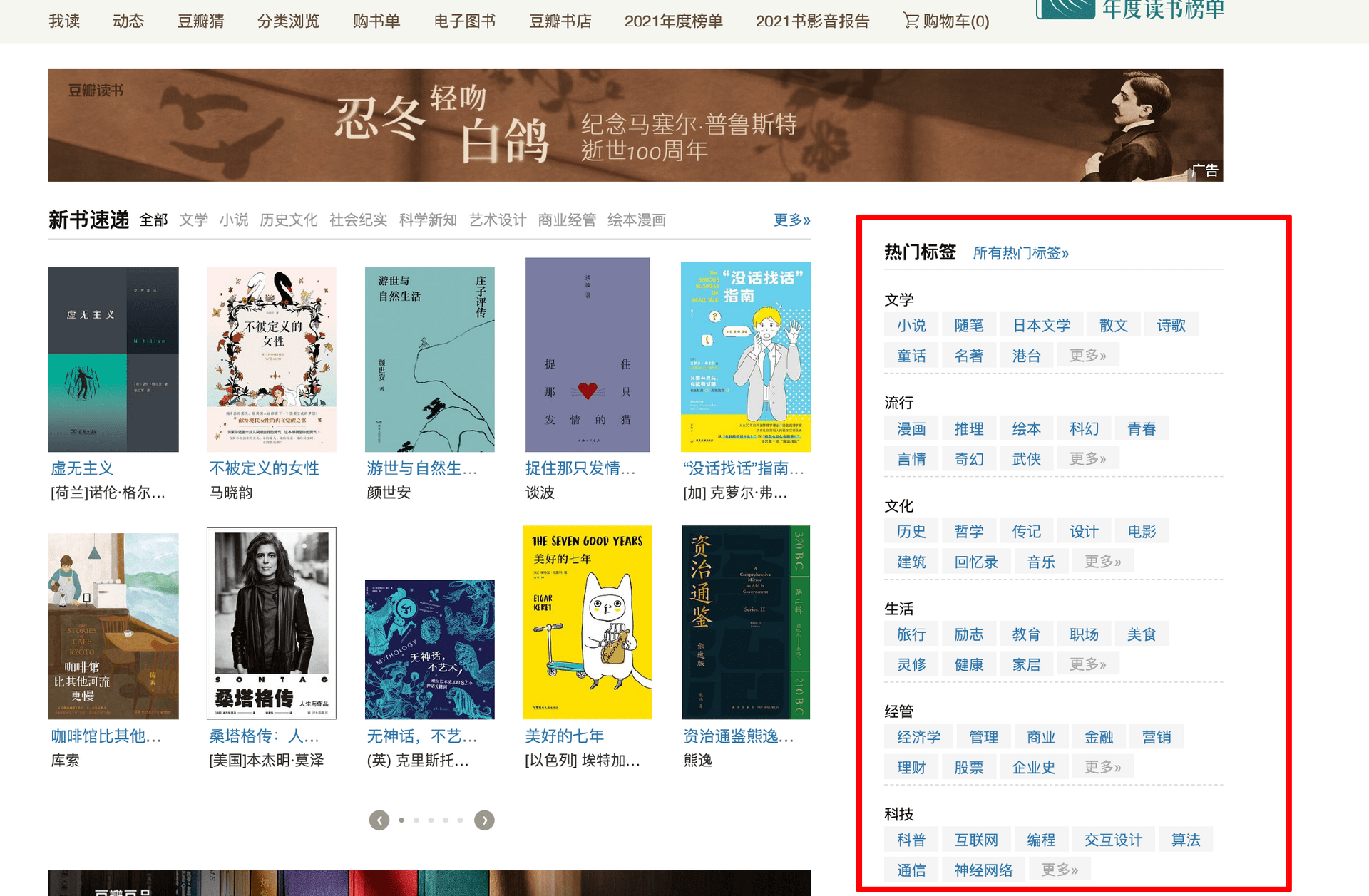
const regexpStr = `<a href="([^"]+)" class="tag">([^<]+)</a>`
func ParseTag(ctx *collect.Context) (collect.ParseResult, error) {
re := regexp.MustCompile(regexpStr)
matches := re.FindAllSubmatch(ctx.Body, -1)
result := collect.ParseResult{}
for _, m := range matches {
result.Requesrts = append(
result.Requesrts, &collect.Request{
Method: "GET",
Task: ctx.Req.Task,
Url: "<https://book.douban.com>" + string(m[1]),
Depth: ctx.Req.Depth + 1,
RuleName: "书籍列表",
})
}
return result, nil
}
进入标签页面后,我们可以进一步获取到图书的列表。
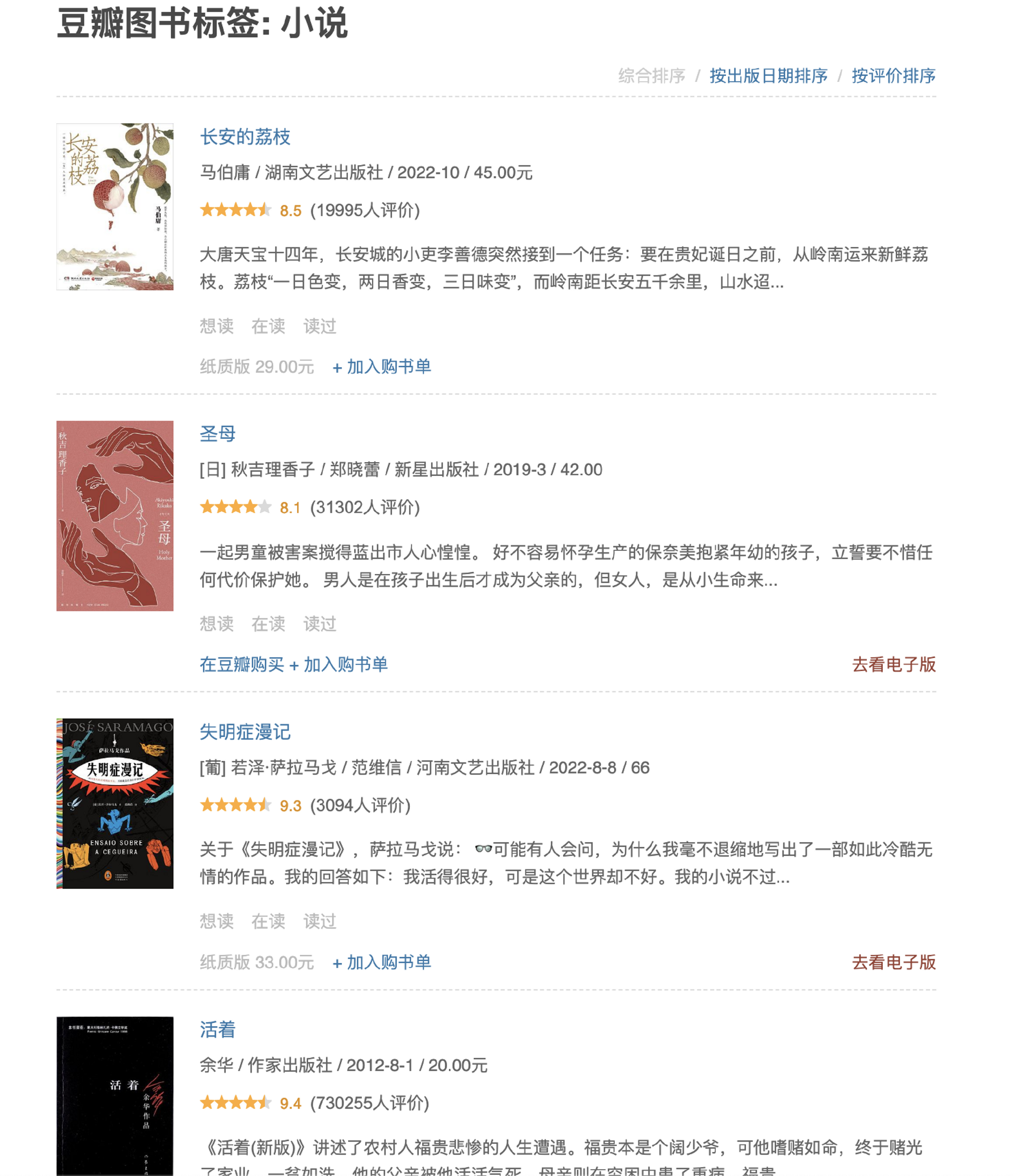
解析图片列表的代码如下:
const BooklistRe = `<a.*?href="([^"]+)" title="([^"]+)"`
func ParseBookList(ctx *collect.Context) (collect.ParseResult, error) {
re := regexp.MustCompile(BooklistRe)
matches := re.FindAllSubmatch(ctx.Body, -1)
result := collect.ParseResult{}
for _, m := range matches {
req := &collect.Request{
Method: "GET",
Task: ctx.Req.Task,
Url: string(m[1]),
Depth: ctx.Req.Depth + 1,
RuleName: "书籍简介",
}
req.TmpData = &collect.Temp{}
req.TmpData.Set("book_name", string(m[2]))
result.Requesrts = append(result.Requesrts, req)
}
return result, nil
}
注意,这里我获取到书名之后,将书名缓存到了临时的tmp结构中供下一个阶段读取。这是因为我们希望得到的某些信息是在之前的阶段获得的。在这里我将缓存结构定义为了一个哈希表,并封装了Get与Set两个函数来获取和设置请求中的缓存。
type Temp struct {
data map[string]interface{}
}
// 返回临时缓存数据
func (t *Temp) Get(key string) interface{} {
return t.data[key]
}
func (t *Temp) Set(key string, value interface{}) error {
if t.data == nil {
t.data = make(map[string]interface{}, 8)
}
t.data[key] = value
return nil
}
最后,点击图书的详情页,可以看到图书的作者、出版社、页数、定价、得分、价格、简介等信息。

解析图书详细信息的代码如下:
var autoRe = regexp.MustCompile(`<span class="pl"> 作者</span>:[\d\D]*?<a.*?>([^<]+)</a>`)
var public = regexp.MustCompile(`<span class="pl">出版社:</span>([^<]+)<br/>`)
var pageRe = regexp.MustCompile(`<span class="pl">页数:</span> ([^<]+)<br/>`)
var priceRe = regexp.MustCompile(`<span class="pl">定价:</span>([^<]+)<br/>`)
var scoreRe = regexp.MustCompile(`<strong class="ll rating_num " property="v:average">([^<]+)</strong>`)
var intoRe = regexp.MustCompile(`<div class="intro">[\d\D]*?<p>([^<]+)</p></div>`)
func ParseBookDetail(ctx *collect.Context) (collect.ParseResult, error) {
bookName := ctx.Req.TmpData.Get("book_name")
page, _ := strconv.Atoi(ExtraString(ctx.Body, pageRe))
book := map[string]interface{}{
"书名": bookName,
"作者": ExtraString(ctx.Body, autoRe),
"页数": page,
"出版社": ExtraString(ctx.Body, public),
"得分": ExtraString(ctx.Body, scoreRe),
"价格": ExtraString(ctx.Body, priceRe),
"简介": ExtraString(ctx.Body, intoRe),
}
data := ctx.Output(book)
result := collect.ParseResult{
Items: []interface{}{data},
}
return result, nil
}
func ExtraString(contents []byte, re *regexp.Regexp) string {
match := re.FindSubmatch(contents)
if len(match) >= 2 {
return string(match[1])
} else {
return ""
}
}
其中,书名是从缓存中得到的。这里仍然使用了正则表达式作为演示,你也可以改为使用更合适的CSS选择器。
完整的任务规则如下所示:
var DoubanBookTask = &collect.Task{
Property: collect.Property{
Name: "douban_book_list",
WaitTime: 1 * time.Second,
MaxDepth: 5,
Cookie: "xxx"
},
Rule: collect.RuleTree{
Root: func() ([]*collect.Request, error) {
roots := []*collect.Request{
&collect.Request{
Priority: 1,
Url: "<https://book.douban.com>",
Method: "GET",
RuleName: "数据tag",
},
}
return roots, nil
},
Trunk: map[string]*collect.Rule{
"数据tag": &collect.Rule{ParseFunc: ParseTag},
"书籍列表": &collect.Rule{ParseFunc: ParseBookList},
"书籍简介": &collect.Rule{
ItemFields: []string{
"书名",
"作者",
"页数",
"出版社",
"得分",
"价格",
"简介",
},
ParseFunc: ParseBookDetail,
},
},
},
}
在采集规则节点中,我们加入了一个新的字段 ItemFields 来表明当前输出数据的字段名,后面我们还会看到它的用途。
上述代码位于v0.2.6中,执行程序后,输出结果如下:
{"level":"INFO","ts":"2022-11-19T11:19:23.720+0800","caller":"crawler/main.go:16","msg":"log init end"}
{"level":"INFO","ts":"2022-11-19T11:19:28.119+0800","caller":"engine/schedule.go:301","msg":"get result: &{map[Data:map[书名:长安的荔枝 价格: 45.00元 作者:马伯庸 出版社: 得分: 8.5 简介:——陕西师范大学历史文化学院教授 于赓哲 页数:224] Rus://book.douban.com/subject/36104107/]}"}
现在我们就能够爬取结构化的图书信息了。
数据存储
数据抽象
爬取到足够的信息之后,为了将数据存储起来,首先我们需要完成对数据的抽象。在这里我将每一条要存储的数据都抽象为了DataCell结构。我们可以把DataCell想象为MySQL中的一行数据。
我们规定,DataCell中的Key为“Task”的数据存储了当前的任务名,Key为“Rule”的数据存储了当前的规则名,Key为“Url”的数据存储了当前的网址,Key为“Time”的数据存储了当前的时间。而最重要的Key为“Data”的数据存储了当前核心的数据,即当前书籍的详细信息。
在解析图书详细信息的规则中,我们定义“Data”对应的数据结构又是一个哈希表map[string]interface{}。在这个哈希表中,Key为“书名”“评分”等字段名,Value为字段对应的值。要注意的是,这里Data对应的Value不一定需要是map[string]interface{},只要我们在后面能够灵活地处理不同的类型就可以了。
func (c *Context) Output(data interface{}) *collector.DataCell {
res := &collector.DataCell{}
res.Data = make(map[string]interface{})
res.Data["Task"] = c.Req.Task.Name
res.Data["Rule"] = c.Req.RuleName
res.Data["Data"] = data
res.Data["Url"] = c.Req.Url
res.Data["Time"] = time.Now().Format("2006-01-02 15:04:05")
return res
}
完成了数据的抽象之后,就可以将最终的数据存储到Items中,供我们专门的协程去处理了。
数据底层存储
在之前我们一直有一个未完成项,就是在HandleResult方法中对解析后的数据进行存储,现在我们就可以将它处理完整了。现在我们要循环遍历Items,判断其中的数据类型,如果数据类型为DataCell,我们就要用专门的存储引擎将这些数据存储起来。(存储引擎是和每一个爬虫任务绑定在一起的,不同的爬虫任务可能会有不同的存储引擎。)
func (s *Crawler) HandleResult() {
for {
select {
case result := <-s.out:
for _, item := range result.Items {
switch d := item.(type) {
case *collector.DataCell:
name := d.GetTaskName()
task := Store.Hash[name]
task.Storage.Save(d)
}
s.Logger.Sugar().Info("get result: ", item)
}
}
}
}
我选择使用比较常见的MySQL数据库作为这个示例的存储引擎。在这里,我创建了一个接口Storage作为数据存储的接口,Storage中包含了Save方法,任何实现了Save方法的后端引擎都可以存储数据。
不过我们还需要完成一轮抽象,因为后端引擎会处理的事务比较繁琐,它不仅仅包含了存储,还包含了缓存、对表头的拼接、数据的处理等。所以,我们要创建一个更加底层的模块,只进行数据的存储。
这个底层抽象的好处在于,我们可以比较灵活地替换底层的存储模块,我在这个例子中使用了原生的MySQL语句来与数据库交互。你也可以使用Xorm与Gorm这样的库来操作数据库。
新建一个文件夹mysqldb,设置操作数据库的接口DBer,里面的两个核心函数分别是CreateTable(创建表)以及Insert(插入数据)。
type DBer interface {
CreateTable(t TableData) error
Insert(t TableData) error
}
type Field struct {
Title string
Type string
}
type TableData struct {
TableName string
ColumnNames []Field // 标题字段
Args []interface{} // 数据
DataCount int // 插入数据的数量
AutoKey bool
}
参数TableData包含了表的元数据,TableName为表名,ColumnNames包含了字段名和字段的属性 ,Args为要插入的数据,DataCount为插入数据的个数,AutoKey标识是否为表创建自增主键。 下面这段代码,我们使用option模式生成了SqlDB结构体,实现了DBer接口。Sqldb.OpenDB方法用于与数据库建立连接,需要从外部传入远程MySQL数据库的连接地址。
type Sqldb struct {
options
db *sql.DB
}
func New(opts ...Option) (*Sqldb, error) {
options := defaultOptions
for _, opt := range opts {
opt(&options)
}
d := &Sqldb{}
d.options = options
if err := d.OpenDB(); err != nil {
return nil, err
}
return d, nil
}
func (d *Sqldb) OpenDB() error {
db, err := sql.Open("mysql", d.sqlUrl)
if err != nil {
return err
}
db.SetMaxOpenConns(2048)
db.SetMaxIdleConns(2048)
if err = db.Ping(); err != nil {
return err
}
d.db = db
return nil
}
两个核心的方法CreateTable 与 Insert 会拼接 MySQL语句,并分别执行创建表与插入数据的从操作。
func (d *Sqldb) CreateTable(t TableData) error {
if len(t.ColumnNames) == 0 {
return errors.New("Column can not be empty")
}
sql := `CREATE TABLE IF NOT EXISTS ` + t.TableName + " ("
if t.AutoKey {
sql += `id INT(12) NOT NULL PRIMARY KEY AUTO_INCREMENT,`
}
for _, t := range t.ColumnNames {
sql += t.Title + ` ` + t.Type + `,`
}
sql = sql[:len(sql)-1] + `) ENGINE=MyISAM DEFAULT CHARSET=utf8;`
d.logger.Debug("crate table", zap.String("sql", sql))
_, err := d.db.Exec(sql)
return err
}
func (d *Sqldb) Insert(t TableData) error {
if len(t.ColumnNames) == 0 {
return errors.New("empty column")
}
sql := `INSERT INTO ` + t.TableName + `(`
for _, v := range t.ColumnNames {
sql += v.Title + ","
}
sql = sql[:len(sql)-1] + `) VALUES `
blank := ",(" + strings.Repeat(",?", len(t.ColumnNames))[1:] + ")"
sql += strings.Repeat(blank, t.DataCount)[1:] + `;`
d.logger.Debug("insert table", zap.String("sql", sql))
_, err := d.db.Exec(sql, t.Args...)
return err
}
存储引擎实现
接下来,我们再看看如何实现存储引擎Storage。
type SqlStore struct {
dataDocker []*collector.DataCell //分批输出结果缓存
columnNames []sqldb.Field // 标题字段
db sqldb.DBer
Table map[string]struct{}
options
}
func New(opts ...Option) (*SqlStore, error) {
options := defaultOptions
for _, opt := range opts {
opt(&options)
}
s := &SqlStore{}
s.options = options
s.Table = make(map[string]struct{})
var err error
s.db, err = sqldb.New(
sqldb.WithConnUrl(s.sqlUrl),
sqldb.WithLogger(s.logger),
)
if err != nil {
return nil, err
}
return s, nil
}
SqlStore是对Storage接口的实现,SqlStore实现了option模式,同时它的内部包含了操作数据库的DBer接口。让我们来看看SqlStore如何实现DBer接口中的Save方法,它主要实现了三个功能:
- 循环遍历要存储的DataCell,并判断当前DataCell对应的数据库表是否已经被创建。如果表格没有被创建,则调用CreateTable创建表格。在存储数据时,getFields用于获取当前数据的表字段与字段类型,这是从采集规则节点的
ItemFields数组中获得的。你可能想问,那我们为什么不直接用DataCell中Data对应的哈希表中的Key生成字段名呢?这一方面是因为它的速度太慢,另外一方面是因为Go中的哈希表在遍历时的顺序是随机的,而生成的字段列表需要顺序固定。
func getFields(cell *collector.DataCell) []sqldb.Field {
taskName := cell.Data["Task"].(string)
ruleName := cell.Data["Rule"].(string)
fields := engine.GetFields(taskName, ruleName)
var columnNames []sqldb.Field
for _, field := range fields {
columnNames = append(columnNames, sqldb.Field{
Title: field,
Type: "MEDIUMTEXT",
})
}
columnNames = append(columnNames,
sqldb.Field{Title: "Url", Type: "VARCHAR(255)"},
sqldb.Field{Title: "Time", Type: "VARCHAR(255)"},
)
return columnNames
}
- 如果当前的数据小于s.BatchCount,则将数据放入到缓存中直接返回(使用缓冲区批量插入数据库可以提高程序的性能)。
- 如果缓冲区已经满了,则调用SqlStore.Flush()方法批量插入数据。
func (s *SqlStore) Save(dataCells ...*collector.DataCell) error {
for _, cell := range dataCells {
name := cell.GetTableName()
if _, ok := s.Table[name]; !ok {
// 创建表
columnNames := getFields(cell)
err := s.db.CreateTable(sqldb.TableData{
TableName: name,
ColumnNames: columnNames,
AutoKey: true,
})
if err != nil {
s.logger.Error("create table falied", zap.Error(err))
}
s.Table[name] = struct{}{}
}
if len(s.dataDocker) >= s.BatchCount {
s.Flush()
}
s.dataDocker = append(s.dataDocker, cell)
}
return nil
}
SqlStore.Flush()方法的实现如下:
func (s *SqlStore) Flush() error {
if len(s.dataDocker) == 0 {
return nil
}
args := make([]interface{}, 0)
for _, datacell := range s.dataDocker {
ruleName := datacell.Data["Rule"].(string)
taskName := datacell.Data["Task"].(string)
fields := engine.GetFields(taskName, ruleName)
data := datacell.Data["Data"].(map[string]interface{})
value := []string{}
for _, field := range fields {
v := data[field]
switch v.(type) {
case nil:
value = append(value, "")
case string:
value = append(value, v.(string))
default:
j, err := json.Marshal(v)
if err != nil {
value = append(value, "")
} else {
value = append(value, string(j))
}
}
}
value = append(value, datacell.Data["Url"].(string), datacell.Data["Time"].(string))
for _, v := range value {
args = append(args, v)
}
}
return s.db.Insert(sqldb.TableData{
TableName: s.dataDocker[0].GetTableName(),
ColumnNames: getFields(s.dataDocker[0]),
Args: args,
DataCount: len(s.dataDocker),
})
}
这段代码的核心是遍历缓冲区,解析每一个DataCell中的数据,将扩展后的字段值批量放入args参数中,并调用底层DBer.Insert方法批量插入数据(上述代码位于v0.2.7分支。)
存储引擎验证
接下来我们简单地验证下我们书写的存储引擎的正确性。首先为了方便起见,我们用Docker在后台启动一个MySQL数据库,将当前的数据库映射到本机的3326端口,设置root密码为123456。创建名为crawler的数据库。
docker run -d --name mysql-test -p 3326:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql
docker exec -it mysql-test sh
CREATE DATABASE crawler;
use crawler;
在main.go的启动参数中,创建sqlstorage并注入到Task当中。注意,这里WithSqlUrl的作用是传递MySQL的连接地址。
func main(){
...
var storage collector.Storage
storage, err = sqlstorage.New(
sqlstorage.WithSqlUrl("root:123456@tcp(127.0.0.1:3326)/crawler?charset=utf8"),
sqlstorage.WithLogger(logger.Named("sqlDB")),
sqlstorage.WithBatchCount(2),
)
if err != nil {
logger.Error("create sqlstorage failed")
return
}
seeds := make([]*collect.Task, 0, 1000)
seeds = append(seeds, &collect.Task{
Property: collect.Property{
Name: "douban_book_list",
},
Fetcher: f,
Storage: storage,
})
s := engine.NewEngine(
engine.WithFetcher(f),
engine.WithLogger(logger),
engine.WithWorkCount(5),
engine.WithSeeds(seeds),
engine.WithScheduler(engine.NewSchedule()),
)
s.Run()
}
运行代码后,数据将存储到MySQL表的douban_book_list中。我们可以用多种与数据库交互的工具查看表中的数据。例如,我们这里使用的是DataGrip,使用地址、密码、和对应的Crawler Database,就可以连接到对应的数据库。

运行SHOW FULL COLUMNS FROM douban_book_list; 可以查看生成的表的字段和类型。
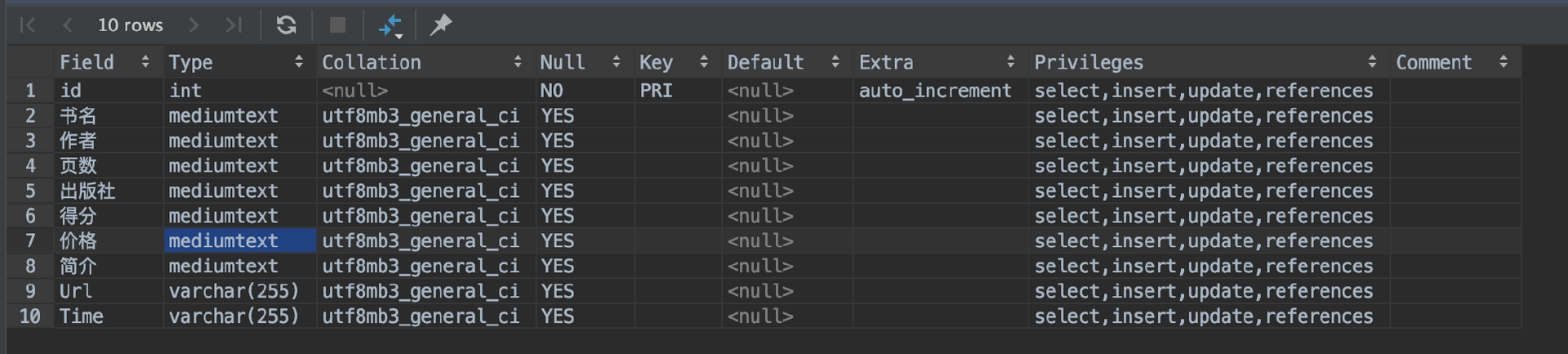
运行select * from douban_book_list; 可以查看表中已经插入的数据。

总结
好了,这节课,我们以存储数据为目标,实现了存储引擎。我们还以豆瓣图书的结构化数据为例,学习了如何对不同的数据进行抽象。我以MySQL为例,并使用了原生的SQL语句来从操作数据库,在这个过程中我们再次看到了接口的强大能力。当前的架构能够帮助我们比较容易地写一个新的存储引擎,例如把数据存储到Kafka,MongoDB、Excel中的存储引擎。如果我们希望在底层使用ORM库来操作数据库也会比较容易。
课后题
这节课的课后题是这样的:
在对不同的结构化信息进行抽象时,我们使用了map[string]interface{}来存储书籍的属性。那么我们有没有可能在数据输出时直接使用像Book这样的结构体,把数据直接传递给存储引擎来处理呢?
欢迎你在留言区与我交流讨论,我们下节课见。
- 出云 👍(0) 💬(1)
按文中的写法,SqlStore.Flush() 方法不能处理同一个Batch中存在不同Task的DataCell的情况。
2023-03-12