33 固若金汤:限速器与错误处理
你好,我是郑建勋。
我们前面的课程,由于一直都是不加限制地并发爬取目标网站,很容易导致被服务器封禁。为了能够正常稳定地访问服务器,我们这节课要给项目增加一个重要的功能:限速器。同时,我们还会介绍在Go中进行错误处理的最佳实践。
限速器
先来看限速器。很多情况下,不管你是想防止黑客的攻击,防止对资源的访问超过服务器的承载能力,亦或是防止在爬虫项目中被服务器封杀,我们都需要对服务进行限速。
在爬虫项目中,保持合适的速率也有利于我们稳定地爬取数据。大多数限速的机制是令牌桶算法(Token Bucket)来完成的。
令牌桶算法的原理很简单,我们可以想象这样一个场景,你去海底捞吃饭,里面只有10个座位,我们可以将这10个座位看作是桶的容量。现在,由于座位已经满了,服务员就帮我们叫了个号,我们随即进入到了等待的状态。
一桌客人吃完之后,下一位并不能马上就座,因为服务员还需要收拾饭桌。由于服务员的数量有限,因此即便很多桌客人同时吃完,也不能立即释放出所有的座位。如果每5分钟收拾好一桌,那么“1桌/5分钟”就叫做令牌放入桶中的速率。轮到我们就餐时,我们占据了一个座位,也就是占据了一个令牌,这时我们就可以开吃了。
通过上面简化的案例能够看到,令牌桶算法通过控制桶的容量和令牌放入桶中的速率,保证了系统能在最大的处理容量下正常工作。在Go中,我们可以使用官方的限速器实现:golang.org/x/time/rate,它提供了一些简单好用的API。
在 golang.org/x/time/rate 库中,类型Limit表示速率,代表每秒钟放入到桶中的令牌个数。NewLimiter函数中,第一个参数传递的是Limit速率,第二个参数b表示桶的数量。除此之外,库中还有Every函数,它的参数是两个令牌之间的时间间隔,它会转化为对应的Limit速率。
// Limit defines the maximum frequency of some events. Limit is
// represented as number of events per second. A zero Limit allows no
// events.
type Limit float64
// NewLimiter returns a new Limiter that allows events up to rate r
// and permits bursts of at most b tokens.
func NewLimiter(r Limit, b int) *Limiter
// Every converts a minimum time interval between events to a Limit.
func Every(interval time.Duration) Limit
生成了Limiter之后,我们一般会调用Limiter的Wait方法等待可用的令牌。其中,参数ctx可以设置超时退出的时间,它可以避免协程一直陷在堵塞状态中。
如果没有可用的令牌,当前协程会陷入到堵塞状态。我们用一个例子来说明一下Limiter的使用方法。 在下面的例子中,rate.NewLimiter生成了一个限速器,其中桶的最大容量为2,rate.Limit(1)表示每隔1秒钟向桶中放入1个令牌。
package main
import (
"context"
"fmt"
"golang.org/x/time/rate"
"time"
)
func main() {
limit := rate.NewLimiter(rate.Limit(1), 2)
for {
if err := limit.Wait(context.Background()); err == nil {
fmt.Println(time.Now().Format("2006-01-02 15:04:05"))
}
}
}
我们用一个for循环打印当前时间会发现,前两次打印是在同一秒,这是因为桶中一开始有两个令牌可以用。之后,每一次打印都需要间隔一秒,因为每隔一秒钟才会往桶中填充一个令牌。
我们再尝试使用rate.Every来生成Limit速率:
func main() {
limit := rate.NewLimiter(rate.Every(500*time.Millisecond), 2)
for {
if err := limit.Wait(context.Background()); err == nil {
fmt.Println(time.Now().Format("2006-01-02 15:04:05"))
}
}
}
其中,rate.Every(500*time.Millisecond)表示每500毫秒放入一个令牌,换算过来就是每秒钟放入2个令牌。
所以我们可以看到,现在每秒钟都会输出两条记录:
2022-11-22 22:39:28
2022-11-22 22:39:28
2022-11-22 22:39:29
2022-11-22 22:39:29
2022-11-22 22:39:30
2022-11-22 22:39:30
刚才我们已经看到了限速器Limiter的基本用法。但有时候我们还会有一些更复杂的需求,例如有多层限速器的需求(细粒度限速器限制每秒的请求,粗粒度限速器限制每分钟、每小时或每天的请求)。
假设我们的爬虫项目希望每分钟只能够访问10次目标网站,但是只有每分钟的限制是不够的。因为这样我们可能会一秒钟直接访问10次,这样服务器就能直接检测出我们是爬虫机器人了。所以,我们还需要控制一下瞬时的请求量,例如每秒钟访问的频率不超过0.5次。这里我也借鉴了《Concurrency in Go》中多层限速器的设计,在新的Limiter包中将限速器抽象为了RateLimiter接口,golang.org/x/time/rate实现的Limiter自动就实现了该接口:
多层限速器对应的multiLimiter如下:
type multiLimiter struct {
limiters []RateLimiter
}
func MultiLimiter(limiters ...RateLimiter) *multiLimiter {
byLimit := func(i, j int) bool {
return limiters[i].Limit() < limiters[j].Limit()
}
sort.Slice(limiters, byLimit)
return &multiLimiter{limiters: limiters}
}
func (l *multiLimiter) Wait(ctx context.Context) error {
for _, l := range l.limiters {
if err := l.Wait(ctx); err != nil {
return err
}
}
return nil
}
func (l *multiLimiter) Limit() rate.Limit {
return l.limiters[0].Limit()
}
其中,MultiLimiter函数用于聚合多个RateLimiter,并将速率由小到大排序。Wait方法会循环遍历多层限速器multiLimiter中所有的限速器并索要令牌,只有当所有的限速器规则都满足后,才会正常执行后续的操作。
最后,我们生成多层限速器并把它放入爬虫任务Task中,每一个爬虫任务可能有不同的限速。这里生成速率的函数用Per进行了封装,例如limiter.Per(20, 1*time.Minute)代表速率是每1分钟补充20个令牌。
func main(){
//2秒钟1个
secondLimit := rate.NewLimiter(limiter.Per(1, 2*time.Second), 1)
//60秒20个
minuteLimit := rate.NewLimiter(limiter.Per(20, 1*time.Minute), 20)
multiLimiter := limiter.MultiLimiter(secondLimit, minuteLimit)
seeds := make([]*collect.Task, 0, 1000)
seeds = append(seeds, &collect.Task{
Property: collect.Property{
Name: "douban_book_list",
},
Fetcher: f,
Storage: storage,
Limit: multiLimiter,
})
}
func Per(eventCount int, duration time.Duration) rate.Limit {
return rate.Every(duration / time.Duration(eventCount))
}
到这里,我们就不再需要在爬取数据时固定休眠了,只要使用限速器来控制速度的就可以了。
随机休眠
不过,如果使用多层限速器,我们访问服务器的频率会过于稳定。为了模拟人类的行为,我们还可以在限速器的基础上,增加随机休眠。
如下所示,假设设置的r.Task.WaitTime为2秒,我们这里使用了随机数,获取0-2000毫秒之间的任何一个整数作为休眠时间。
func (r *Request) Fetch() ([]byte, error) {
if err := r.Task.Limit.Wait(context.Background()); err != nil {
return nil, err
}
// 随机休眠,模拟人类行为
sleeptime := rand.Int63n(r.Task.WaitTime * 1000)
time.Sleep(time.Duration(sleeptime) * time.Millisecond)
return r.Task.Fetcher.Get(r)
}
下面是我通过多层限速器和随机休眠机制成功爬取到的图书数据:
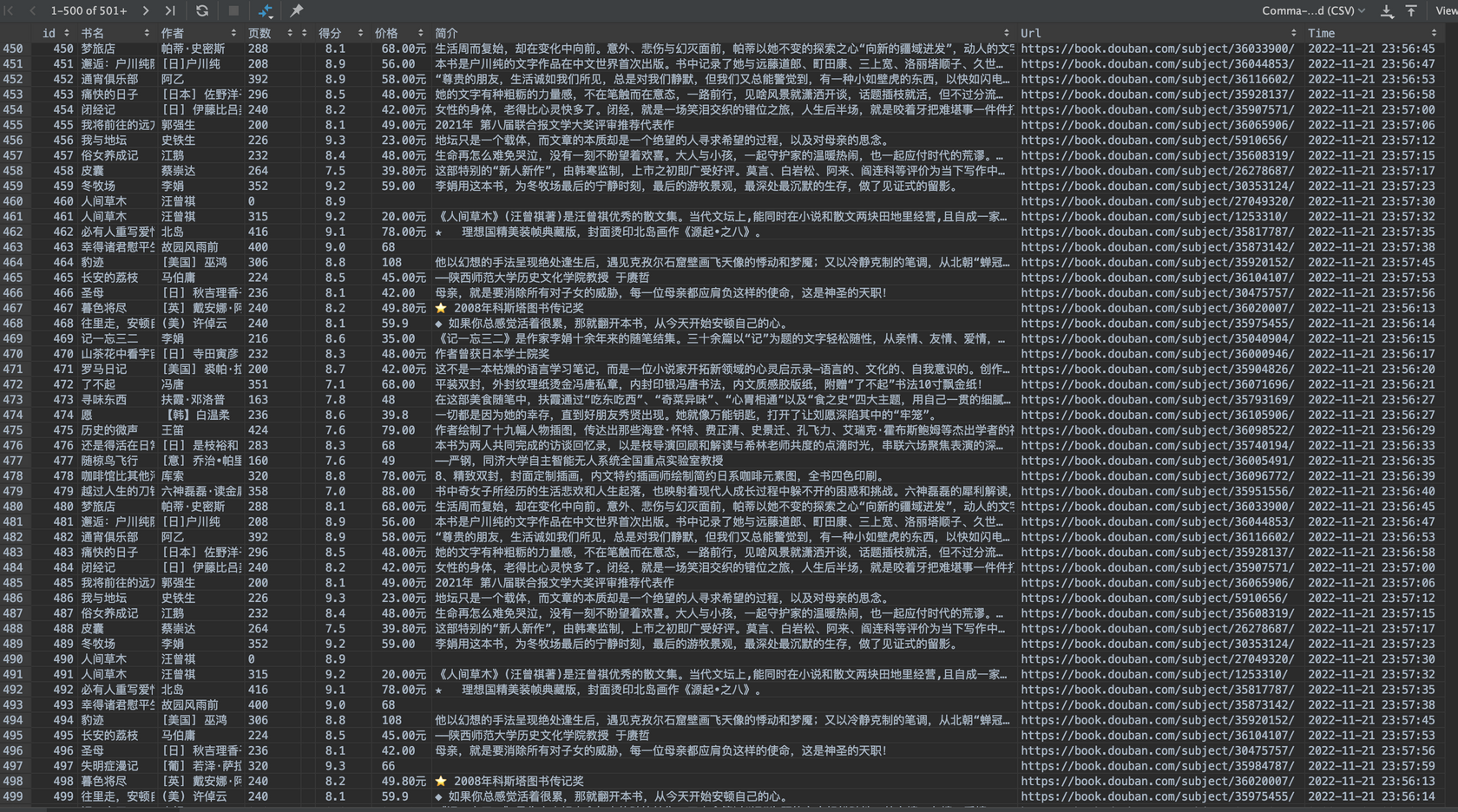
上述代码位于v0.2.8。
错误处理
介绍了限速器,我们再来看一看Go项目中另一个重要的话题:错误处理。在Go中,错误处理也是被人吐槽得比较多的地方。很多批评者根据自己过去的编程语言的经验,觉得在Go中有很多下面这样的错误处理语法。
确实,在日常实践中,代码常常会变得像下面这样,让人感觉不太优雅。
func doSomething() error {
if err := foo(); err != nil {
return err
}
if err := bar(); err != nil {
return err
}
if err := baz(); err != nil {
return err
}
return nil
}
然而,Go这种错误处理方式实际上是深思熟虑的结果,它也是有软件工程的经验作为指导的。像Java或C++中错误处理的try…catch语句被实践证明面临可读性差、难以精准地处理错误等问题。而在Go语言中,错误处理的哲学是强制调用者检查错误,这就保证了代码的可读性和健壮性。
虽然在某些情况下,这确实使 Go 代码变得冗长,但幸运的是,我们可以使用一些技术来最大程度地降低错误处理的重复性。
基本的错误处理方式
由于Go中允许多返回值,因此最常见的错误处理方式是将函数的最后一个返回值作为error接口,接口中的Error方法返回错误的信息。
这种方式会用errors.New函数来生成一个新的错误,其中参数为本次的错误信息。
func (r *Request) Check() error {
if r.Depth > r.Task.MaxDepth {
return errors.New("max depth limit reached")
}
return nil
}
错误的信息需要清晰表明错误,方便定位问题,例如通过 open not_here.txt: no such file or directory ,我们可以清楚地知道打开的文件不存在。
errors.New的实现非常简单,它生成了一个内置的errorString结构体,而 errorString 则实现了Error()方法。
func New(text string) error {
return &errorString{text}
}
type errorString struct {
s string
}
func (e *errorString) Error() string {
return e.s
}
我们也可以采用fmt.Errorf来做一些格式化的输出:
func (b BrowserFetch) Get(request *Request) ([]byte, error) {
client := &http.Client{
Timeout: b.Timeout,
}
if b.Proxy != nil {
transport := http.DefaultTransport.(*http.Transport)
transport.Proxy = b.Proxy
client.Transport = transport
}
req, err := http.NewRequest("GET", request.Url, nil)
if err != nil {
return nil, fmt.Errorf("get url failed:%v", err)
}
...
}
fmt.Errorf的好处是,我们可以在之前错误的基础上,附加一些额外的错误信息。 由于接口的零值为nil,因此在处理函数返回的错误时,我们要通过error != nil来判断是否有错误产生:
func (s *Crawler) CreateWork() {
for {
...
body, err := req.Fetch()
if err != nil {
s.Logger.Error("can't fetch ",
zap.Error(err),
zap.String("url", req.Url),
)
s.SetFailure(req)
continue
}
}
此外,在进行错误处理时,我们还要谨慎地处理自定义的错误。我们之前在介绍接口时提到过,当接口为nil时,意味着接口内部的动态类型和动态数据都为nil。所以下面foo函数返回的err不为nil:
func foo() error {
var err *os.PathError
return err
}
func main() {
err := foo()
fmt.Println(err != nil) // true
}
另一个类似的例子也是如此:
func GenerateError(flag bool) error {
var genErr StatusErr
if flag {
genErr = StatusErr{
Status: NotFound,
}
}
return genErr
}
func main() {
err := GenerateError(true) // **true**
fmt.Println(err != nil)
err = GenerateError(false) // **true**
fmt.Println(err != nil)
}
那我们应该怎么处理返回的错误呢?应该直接return err 让上层区处理?还是应该先对错误进行一些特殊的处理?
在实践中我们经常看到一些对错误反复、无意义的处理,最典型的就是日志处理。我们当前的项目也存在这个问题,当爬取网站超时时,会在多个地方打印错误信息,这时常是多余的。
{"level":"ERROR","ts":"2022-11-22T00:22:57.549+0800","caller":"collect/collect.go:74","msg":"fetch failed","error":"Get \\"<https://book.douban.com/subject/1008145/\\>": context deadline exceeded (Client.Timeout exceeded while awaiting headers)"}
{"level":"ERROR","ts":"2022-11-22T00:22:57.549+0800","caller":"engine/schedule.go:263","msg":"can't fetch ","error":"Get \\"<https://book.douban.com/subject/1008145/\\>": context deadline exceeded (Client.Timeout exceeded while awaiting headers)","url":"<https://book.douban.com/subject/1008145/>"}
但如果我们只是return err,又容易失去一些函数堆栈的关键信息,变得只知道最终的错误信息,不知道函数的调用链是如何触发这一问题的。其实,我们可以使用fmt.Errorf包装额外的错误信息来解决这一问题。
错误链处理方式
在实践中,我们可能还会遇到下面这样的特殊情况。例如tasks是任务的列表,我们希望所有任务都执行,即便前面任务执行失败也不退出。但是下面这样的写法就只能得到最后一个错误的信息:
func doSomething() error {
var reserr error
for _, task := range tasks {
if err = f(task);err != nil{
reserr = err
}
}
return reserr
}
还有一种情况是希望能够检测到错误链中的某一类特定错误。举一个例子,foo函数通过读取Read来读取文件中的信息,当读取到最后,Read函数会返回特定的错误类型:io.EOF。而在一些场景需要检测特殊的错误类型来进行额外的逻辑处理。
func foo() error {
f, _ := os.Open(file)
if _, err = f.Read(b); err != nil {
fmt.Println(err == io.EOF) // true
}
}
要解决这个问题,我们首先可能会想到在 foo 函数中使用 fmt.Errorf 包裹信息,但是很快会发现,现在已经失去了io.EOF这个原始的错误类型。
其实,为了解决这类问题,Go标准库为我们实现了类似错误包装的机制,它可以将多个错误组成一个错误链。要使用错误包装机制有一个非常简单的方法,那就是在使用fmt.Errorf的时候加入一个特殊的格式化符号%w,在下面这段代码中, fmt.Errorf("read failed,%w", err) 将错误err进行了包装。
这时,我们可以通过errors.Is来判断当前错误中是否包含了原始的io.EOF错误,errors.Is会遍历整个错误链并查找是否有相同的错误。
func foo() error {
f, _ := os.Open(file)
if _, err = f.Read(b); err != nil {
warpErr := fmt.Errorf("read failed,%w", err)
fmt.Println(errors.Is(warpErr, io.EOF)) // true
}
}
另外,errors.Unwrap还可以对错误进行解包,如下所示:
func foo() error {
f, _ := os.Open(file)
if _, err = f.Read(b); err != nil {
warpErr := fmt.Errorf("read failed,%w", err)
err = errors.Unwrap(warpErr)
fmt.Println(err == io.EOF) // true
}
}
一般我们会使用errors.Is来判断错误链中是否包含了指定的错误,而不是直接使用下面的== 来判断。
要注意,尽量不要在自己的API中返回 syscall.ENOENT 以及 io.EOF 这样的特殊类型。因为这通常意味着调用者需要依赖我们代码库当中定义的特定类型。这在标准库中没有问题,但是如果是第三方库返回了一个新的错误类型,或者使用fmt.Errorf等方式进行了包裹,这种相等关系在后续就不再成立了。同时,这种方式还可能带来不必要的包之间的依赖。
减少错误处理的实践
为了避免冗长的错误处理,我们可以使用一些最佳实践。
例如下面的HTTP服务器中,每一个路由函数都需要处理错误,这看起来很繁琐。
func main() {
http.HandleFunc("/users", viewUsers)
http.HandleFunc("/companies", viewCompanies)
}
func viewUsers(w http.ResponseWriter, r *http.Request) {
...
if err := userTemplate.Execute(w, user); err != nil {
http.Error(w, err.Error(), 500)
}
}
func viewCompanies(w http.ResponseWriter, r *http.Request) {
...
if err := companiesTemplate.Execute(w, companies); err != nil {
http.Error(w, err.Error(), 500)
}
}
这时候,我们可以用一个类似中间件的函数appHandler来统一处理错误,改造如下:
func main() {
http.HandleFunc("/users", appHandler(viewUsers))
http.HandleFunc("/companies", appHandler(viewCompanies))
}
func viewUsers(w http.ResponseWriter, r *http.Request) {
return userTemplate.Execute(w, user)
}
func viewCompanies(w http.ResponseWriter, r *http.Request) {
return companiesTemplate.Execute(w, companies)
}
type appHandler func(http.ResponseWriter, *http.Request) error
func (fn appHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
if err := fn(w, r); err != nil {
http.Error(w, err.Error(), 500)
}
}
第二个最佳实践是使用defer来减少错误处理。
例如,下面的函数在错误返回时,包装函数的逻辑是相同的。
func DoSomeThings(val1 int, val2 string) (string, error) {
val3, err := doThing1(val1)
if err != nil {
return "", fmt.Errorf("in DoSomeThings: %w", err)
}
val4, err := doThing2(val2)
if err != nil {
return "", fmt.Errorf("in DoSomeThings: %w", err)
}
result, err := doThing3(val3, val4)
if err != nil {
return "", fmt.Errorf("in DoSomeThings: %w", err)
}
return result, nil
}
如果我们把这里的函数改造为使用defer,会更为简洁:
func DoSomeThings(val1 int, val2 string) (_ string, err error) {
defer func() {
if err != nil {
err = fmt.Errorf("in DoSomeThings: %w", err)
}
}()
val3, err := doThing1(val1)
if err != nil {
return "", err
}
val4, err := doThing2(val2)
if err != nil {
return "", err
}
return doThing3(val3, val4)
}
panic
最后,我们再来讲讲一类特殊的错误:panic。当发生算术除0错误、内存无效访问、数组越界等问题时,会触发程序panic,导致程序异常退出并打印出函数的堆栈信息。
在Go 语言中,有以下两个内置函数可以处理程序的异常情况:
panic 函数传递的参数为空接口interface{},它可以存储任何形式的错误信息并进行传递,然后在异常退出时打印出来。
Go 程序在 panic 时并不会直接导致程序异常退出,它会终止当前正在正常执行的函数,执行defer 函数并逐级返回。 例如,对于函数调用链a()→b()→c(),当函数 c 发生 panic 后,会返回函数b。此时,函数 b 也像发生了 panic 一样返回函数a。函数c、b、a 中的 defer 函数都将正常执行。
func a() {
defer fmt.Println("defer a")
b()
fmt.Println("after a")
}
func b() {
defer fmt.Println("defer b")
c()
fmt.Println("after b")
}
func c() {
defer fmt.Println("defer c")
panic("this is panic")
fmt.Println("after c")
}
func main() {
a()
}
如下所示,当函数 c 触发了 panic 后,所有函数中的 defer 语句都会被正常调用,并且在panic时打印出堆栈信息。
defer c
defer b
defer a
panic: this is panic
goroutine 1 [running]:
main.c()
bookcode/panic/panic_chain.go:19 +0x95
main.b()
bookcode/panic/panic_chain.go:13 +0x96
main.a()
bookcode/panic/panic_chain.go:7 +0x96
main.main()
bookcode/panic/panic_chain.go:24 +0x20
通常,我们希望能够捕获这样的错误,然后让程序继续正常执行。要捕获这种异常,我们需要将 defer 与内置 recover 函数结合起来使用。
func executePanic() {
defer func() {
if errMsg := recover(); errMsg != nil {
fmt.Println(errMsg)
}
fmt.Println("This is recovery function...")
}()
panic("This is Panic Situation")
fmt.Println("The function executes Completely")
}
func main() {
executePanic()
fmt.Println("Main block is executed completely...")
}
从下面这段输出可以看出,尽管有panic,main 函数仍然在正常执行后才退出。
在实践中,我们常常看到一些开发者为了避免异常退出在各个函数调用的地方都加上了recover捕获,但其实这是没有必要的。借助上面的这个特性,我们只需要在最上层函数捕获异常就可以了。
有些同学可能会想,那我直接在main函数里加一个recover函数,这样捕获异常不就可以了吗?但这是不对的,因为我们讲的这个特性只适用于某一个单独的协程。所以我们应该对每一个重要的协程的最上层函数进行捕获,这样就可以避免程序的异常退出了。
下面这段代码中,我们在CreateWork方法中捕获到panic并打印到了日志中。一般这种日志会被额外的监控系统发现并报警。
func (s *Crawler) CreateWork() {
defer func() {
if err := recover(); err != nil {
s.Logger.Error("worker panic",
zap.Any("err", err),
zap.String("stack", string(debug.Stack())))
}
}()
...
}
总结
好了, 总结一下。
这节课,我们介绍了两个重要的特性限速器与错误处理。限速器通过令牌桶机制,帮助我们减少了爬虫对目标服务器的压力,并且使用了多层限速器对爬虫进行精细化的管理。
而对于错误处理,Go语言吸收了当前软件开发中遇到的经验与教训,其哲学是函数的调用者理应对错误进行处理,但这个思路确实有时候会带来错误处理冗长的问题。错误处理目前有许多最佳的实践,其中包括了错误的包装,错误中间件以及通过defer来减少错误的处理等。
最后我们还介绍了panic,在关键的功能最上层使用defer+recover可以防止程序异常退出。不过要注意,对异常进行捕获时,只能对单个协程生效。
课后题
学完这节课,给你留一道课后题。
错误处理是Go语言中被吐槽很多的话题,但是这其实是深思熟虑的设计结果。你可以查阅相关资料,谈一谈在Go中如何更好地进行错误处理。
欢迎你在留言区与我交流讨论,我们下节课见。
- viclilei 👍(0) 💬(2)
老师,为什么我按照代码写完后,请求数据还是有1s20条左右。可以帮忙判断我大概是什么地方写错了吗?
2023-01-09 - Realm 👍(1) 💬(0)
在程序中应该避免使用野生的goroutine带来的panic,可以放在一个有个异常捕获的Go函数中来执行goroutine。姿势如下: ``` func Go(f func()) { go func() { // defer recover 捕获panic defer func() { if err := recover(); err != nil { log.Printf("panic: %+v", err) } }() f() }() } func main() { f := func() { panic("xxx") } Go(f) time.Sleep(1 * time.Second) } ```
2022-12-24 - 大毛 👍(0) 💬(0)
1 - 官方的 golang.org/x/time/rate 实现限流是通过记录最后操作的时间+计算完成的,感觉这种处理方式让人耳目一新。以前我一直觉得这种令牌限流的算法就是使用 ticker 定时向一个 chan 中放入令牌,然后让获取令牌的人阻塞然后自行争抢,计算的方式毫无疑问比 ticker 的方式更优。另外这种计算的实现让这个limiter 有了一个有趣的特点,就是当调用 Wait(ctx context.Context) 的时候,如果 ctx 设置了过期时间,limiter 可以立即计算出这个调用者是否有机会获取到令牌(如果下一个令牌生成时间是 3 秒后,而 ctx 的过期时间是 1 秒,limiter 会立即返回一个错误,表示这个调用者不可能在过期时间内获取令牌),这不会让调用者一直在 Wait 方法上阻塞,也算是提升性能的一个小技巧 2 - 课程中自行实现的多个级别的 limiter 感觉是有一个 bug?即如果设置了 5 个级别的 limiter,用户已经获得了前 3 个 limiter 的令牌,但是在尝试获取第 4 个令牌的时候出错,那是否应该将前三个令牌放回去? 3 - error 推荐使用 github.com/pkg/errors 4 - 一个 goroutine 如果没有使用 defer + recover 的方式来捕获 panic,这个 goroutine 将导致整个程序直接崩溃,如果你不想这样,要记得添加 defer + recover
2024-01-29 - 卢承灏 👍(0) 💬(0)
老师,appHandler 讲解那里,viewUsers还有下面那个方法是不是漏了error 返回
2022-12-26