41 线上综合案例:节约线上千台容器的性能分析实战
你好,我是郑建勋。
当我们对Go程序进行性能分析时,一般想到的方式是使用pprof提供的一系列工具分析CPU火焰图、内存占用情况等。
诚然,通过分析CPU耗时最多的流程,设法对CPU耗时最多的函数进行优化,毫无疑问能够改善程序整体的状况。然而,优化了这些步骤就一定能够大幅度提高容器的QPS,降低机器数量,一定能够大幅度提高性能吗?
不一定。因为一个函数在pprof中耗时多,可能是因为它本身耗时就多,它是现象却不一定是问题。同时,在高负载情况下,可能会导致某一些请求、函数的耗时突然升高,而这些异常却又不一定能够体现在pprof上。因为pprof能看到整体的耗时情况,却难以分析个例。因此,有时候我们需要跳出pprof cpu profiling,仔细审视程序遇到的最严重的性能瓶颈。
这节课,我们一起来回顾分析线上的Go Web程序的性能瓶颈的整个过程,看看最终如何节约上千台容器。这节课用到的工具和方法也可以给我们排查其他瓶颈问题一些启发。
程序问题描述与排查过程
我们团队维护的一个核心程序为Go Web服务,当前程序能够承载的QPS非常低。当QPS上涨到一个阈值时,就会出现p99抖动,导致接口耗时超过了上游给定的超时时间。在过去,解决这类问题的方法就是加容器来分摊请求量,随着业务发展,时间久了,这个核心服务线上就有了几千台容器。最近几年,很多开发者都尝试分析这个问题的原因,但都无功而返,现在由于有了降本的需求,需要再次直视这个问题。
为了更精准地分析现状,我们采用了线上压测的方式,通过提高某一台容器权重的方式提高该容器的请求量。经过压测分析,我们得到了下面这些信息。
- 正常情况下服务约为 3QPS,p99耗时在300毫秒左右(意味着如果有100个请求,99个请求的耗时在300毫秒以下),p95耗时120毫秒左右。当压测上涨到 16QPS 以上时,会看到耗时p99抖动,而p95仍保持稳定。压测时容器 p99 在700毫秒以上。
- cpu idle(CPU处于空闲状态时间比例)在80%以上。
- 内存容量充足,内存利用率55%左右。
- 获取耗时异常的请求,并再次调用该请求时,耗时能够恢复正常。每次请求走的是相同的代码路径,但是请求耗时差距可达300毫秒以上。
- 程序也会有许多下游的网络调用,而这些下游调用的p99耗时稳定,可以大致排除问题出在下游服务的可能。
- 程序占用的内存约为4G,而且较为稳定。容器Cgroup可使用的容量大小为16G。分析程序暴露的运行时内存分配Metric,没有发现明显的异常。
- 程序本身协程数量在120左右,但是大部分都在休眠状态。在负载情况下,协程数量与请求数量大致相同。协程数量增长到了130左右。运行的协程数量是不多的。
- 用如下指令获取线程数量,结果约为14个,在压测时并没有增加线程数量。
- 当容器飘逸到性能更强的宿主机后,耗时能够得到显著缓解。
综上,我们主要面对的其实是耗时p99抖动的问题,下面我们分别对问题进行拆解。
请求排队问题
首先,耗时上涨可能是HTTP请求排队导致的吗?HTTP Keep-Alive为 true 时会复用连接,第二个请求会等待第一个请求完成,但是这种假设不成立。通过下面的指令,我们发现连接总是在不断变化,没有复用长连接。
并且,我们在程序中打印的请求耗时时间,是从接收到请求之后开始计时的,所以耗时还是发生在程序中的。
程序随着时间状态恶化问题
但是我们新部署的容器,还是会出现这个问题,所以排除掉这个假设。
网络请求处理不过来的问题
要验证这一假设,我们需要看看Go语言中的网络处理模型。对于网络IO来说,Go语言拥有足够优秀的网络模型来处理大量的网络请求。它使用的是封装epoll的方式,过程轻量、异步且快速。不会因为某一个协程的网络堵塞导致其他协程排队。同时,观察我们打印的p99异常请求的耗时,会发现这些请求的下游网络耗时很正常,并没有堵塞。
磁盘IO和系统调用堵塞问题
磁盘 IO 和系统调用确实有可能因为堵塞产生排队的问题。但是Go语言的 sysmon 监控程序每隔10毫秒会监控这种情况并适时地创建新的线程。再加上Go调度器的均衡工作,从理论上来讲,程序的理想运行状态应该是,随着负载的增加,耗时稳定上升,不会突然出现的毛刺。
Go调度器的调度延迟问题
实际上,即便在压测时,当前的QPS也很低,只有16QPS左右。如果任务数增加,Go运行时调度器进行调度时,某一个协程长期得不到执行的可能性很低。8个逻辑处理器 P 足够承载当前的QPS了。
我们再进一步分析一下调度器的细节。如下面的启动指令,在程序启动时加入环境变量GODEBUG=schedtrace=1000,scheddetail=1,这时程序每隔一秒就会打印出调度器的细节。
GOMAXPROCS=8 GODEBUG=schedtrace=1000,scheddetail=1 nohup ./main -config conf/conf.test.toml > runoob.log 2>&1 &

通过打印出的日志我们发现,协程等待队列中基本没有等待运行的协程,这从侧面证明,当前程序有极大的QPS提升空间。这个现象也解释了为什么在压测情况下 cpu idle仍然很高,因为程序没有满负载运行。
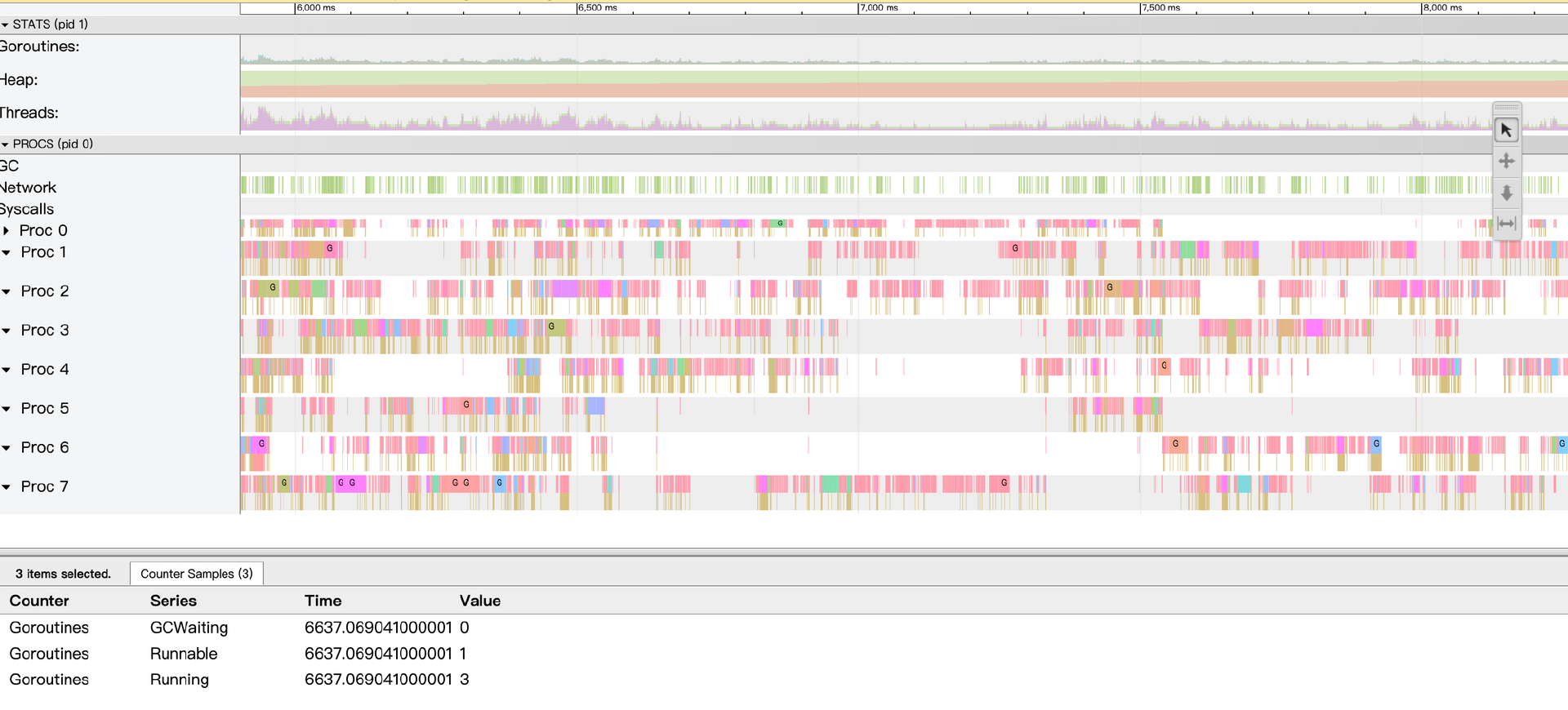
我们使用trace工具进行分析,能够更直观地分析出程序负载不足的情况。瞬时可运行协程数量小于逻辑处理器P的数量,并且P运行协程有大量的间隙。
请求消耗过多CPU的问题
在压测时,我们收集了pprof火焰图,并把它和正常负载下的火焰图进行了对比,没有发现明显变化。
并发导致的锁问题
在高并发场景下,如果程序都在争抢同一把锁,那么有可能会产生协程等待,导致耗时变长的问题。
但是从代码上来看,我们当前分析的程序几乎未使用锁等同步机制。另一方面,即便是使用锁,在如此低的负载情况下,也几乎不可能出现几百毫秒的延迟,更不要提标准库中的锁耗时,都要上万QPS才可能导致瓶颈问题。
查看 pprof block,也没有发现瓶颈问题。
go tool pprof http://localhost:9981/debug/pprof/block
go tool pprof http://localhost:9981/debug/pprof/mutex
同步写日志的磁盘问题
在Go程序中,磁盘IO并没有像网络一样,可以使用多路复用的机制。这意味着协程可能会陷入到操作系统调用中。这也是我们之前想要去查看线程数量的原因。因为长时间陷入到操作系统调用时,sysmon监控程序会创建新的线程。但是线程数量是比较正常的,同时查看下面磁盘的一些核心指标没有发现异常:
- 磁盘容量正常
- 磁盘利用率正常
- inode利用率正常
- iops正常
- 磁盘输入/输出操作时间占比正常
垃圾回收问题
接着往下想,会不会是垃圾回收的问题?
当前程序GC频率相对较高,在压测时能够达到几秒一次,但是初步分析不足以导致瓶颈。从程序暴露的运行时指标来看,GC程序生命周期内,平均花费的CPU时间在千分之二左右,STW时间(即不可用时间)小于1毫秒,这些信息都表明GC不是瓶颈。
宿主机问题
我们再来看看宿主机,由于我们现在的程序运行在容器中,虽然理论上资源是完全隔离的,但是现在宿主机的问题仍然可能影响到容器。我们需要依次查看下面这些指标。
- 宿主机cpu idle正常。
- CPU外部争抢cpu.exter_wait_rate正常,这个指标主要用来衡量任务在线程等待队列中等待时,等待其他容器的时间是否过长,这是我们公司内部自己的指标。
- Cgroup CPU与内存设置正常。
- 查看容器 cpu.throttled 和throttled_time,发现它们在正常情况下和压测时都会存在。这个指标可以判断是否存在资源抢占导致的耗时增加。如果容器的资源被利用得太狠,到达了分配的资源限制,就可能出现这样的情况。但是压测时数据没有明显的飙升,不足以导致耗时增加300毫秒。
- 查看一段时间内操作系统线程堆栈,发现程序大部分时间并没有耗在操作系统调用上,而是在用户态上。
总之,从现象上看,这个问题和宿主机有关系,但直接对宿主机进行分析无法得出清晰的结论。
“以退为进分析法”
分析到这里,问题似乎陷入了僵局。不得已,我们需要以退为进,回归到最原始的问题,来分析耗时是陷入到了哪里。
我们直接在代码的关键位置打印出耗时,分析耗时高的程序到底把时间消耗在了哪里。
通过对日志的分析,我们发现,大部分时间都消耗在了clone函数上,其功能是对一个结构体进行深拷贝。程序中调用clone非常频繁,一次复杂的请求可能会调用1000次clone函数。但是我们打印每一次clone函数的时间,发现都不足1毫秒,只是累积起来就比较吓人了。也就是说,内存分配没有明显的突然的恶化导致的卡点,而是有一种情况让整体的内存分配耗时恶化了。
在深入分析运行时内存分配可能的Bug之前,我选择了使用更强大的工具trace分析程序在生命周期内的运行状态,这也让我最终找到了答案。trace借助于Go运行时在关键时刻的埋点,帮助我们一窥程序的运行过程。
具体做法是,首先抓取压测情况下的trace,然后分析Goroutine analysis。Goroutine analysis是一个非常有用的工具,它可以分析单个协程的情况。
curl -o trace.out http://127.0.0.1:9981/debug/pprof/trace?seconds=30
go tool trace -http=localhost:8000 trace.out
我们要做的是,找到我们想要分析的那个函数对应的协程。如下所示,A.func6是A函数的第6个协程,样本数有五百多个。

接下来,分析一下这些样本协程的耗时情况。
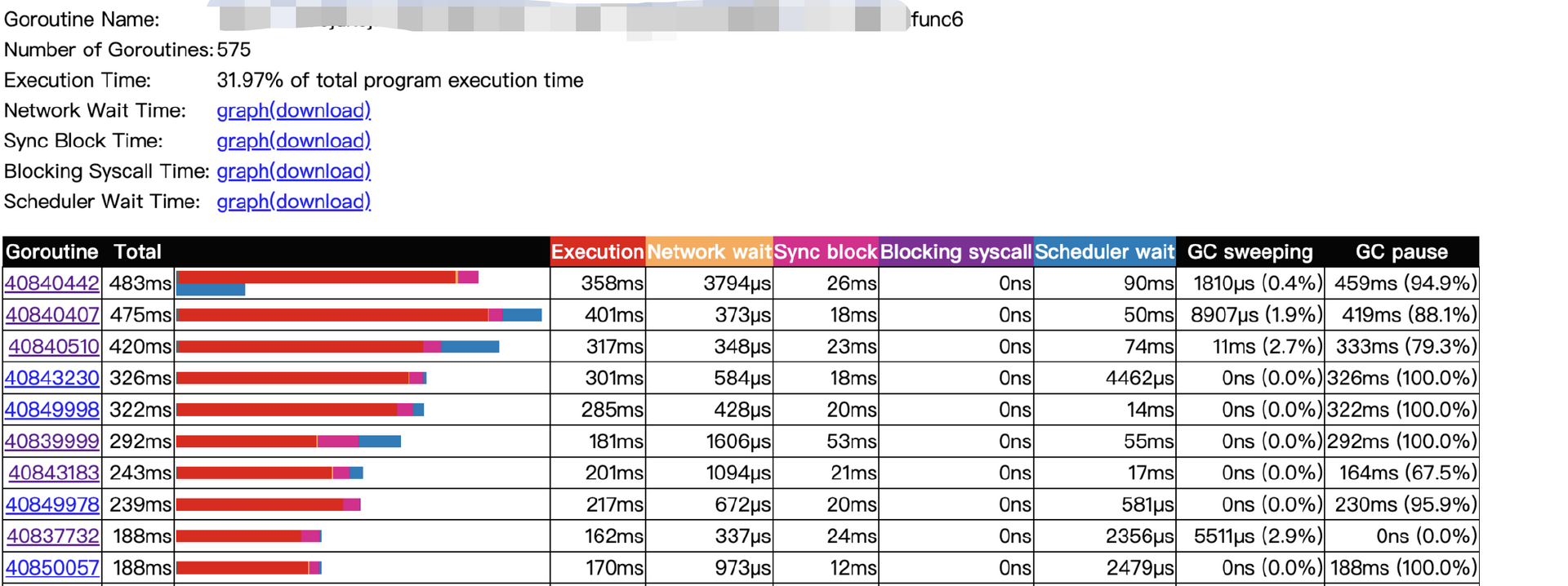
从图中可以看出,一些协程的最大函数耗时超过了300毫秒,这些协程会导致p99的飙升,和现象是对应的。同时,点击耗时比较大的协程,可以看到协程的耗时花在了哪些地方。可以看到,协程的耗时主要花费在了Execution执行阶段,比较奇怪的是,这一阶段的大部分时间都处于GC阶段。
点击某一个协程的详细信息,可以看到协程在当前一段时间内的运行状态。等等,这密密麻麻的绿色线条是怎么回事,放大以后特别吓人,大部分时间都在Mark Assisst。

也就是说,程序在已经GC的情况下,由于疯狂的内存分配导致的Mark Assisst问题非常严重,这也就解释了为什么只有负载上来了才会导致P99问题。
进一步分析与修复问题
再总结一下问题的根源就是:GC阶段下,大量的内存分配导致了大量的辅助标记,加上25%的专有GC处理占用了2个线程,程序运行状态会迅速恶化。

上一节课程我们就已经介绍过辅助标记。在并发标记阶段,扫描内存的同时,用户协程也会不断被分配内存,当用户协程的内存分配速度快到后台标记协程来不及扫描时,GC 标记阶段将永远不会结束。这样一来,GC 周期就无法完整,还会进一步造成内存泄漏。
为了解决这样的问题,Go1.5引入了辅助标记算法。用户协程被分配了超过限度的内存,运行时不得不将协程暂停,并切换去执行辅助标记工作。而由于我们当前程序的特性会频繁地分配内存,超过了内存扫描的速度,导致协程执行一段时间后就不得不切换到辅助标记工作,这增加了协程运行的时间,并最终导致了p99耗时非常严重。
这个问题的根源是内存的频繁释放和分配。在实践中我们发现,频繁的内存分配导致的程序问题经常会出现。举一个例子,我遇到过一个由于内存分配不合理导致程序直接OOM的问题。容器的内存容量本身为16G,但是当程序内存达到8G之后,下一次GC的目标内存到达了16G。在这段时间里,内存频繁分配,不到两分钟就上涨到了16G,直接导致了程序的崩溃。Go运行时本身有一个定时监控服务,每2分钟会强制触发一次GC,但是程序的特性却导致不到2分钟就把内存打满了。
遇到这样的问题应该如何解决呢?
有两种思路。一种是减少内存的分配,在这个线上问题中,由于程序设计不合理,导致每一次请求都会对一个大对象进行深拷贝,因此我们需要思考如何结合程序的场景,减少不合理的内存拷贝。
另一种思路是构建内存池来复用内存。谈到内存池,很多人会想到sync.Pool。确实,sync.Pool的源码是比较值得学习的,Go在其中进行了很多底层优化,包括为了防止内存泄露而采取的回收策略;对结构的设计可以防止CPU缓存伪共享;设计Ring-Buffer结构可以复用内存并提高CPU缓存效率,每一个P中会存储本地缓存方便并发时的无锁访问。如果有兴趣你可以再深入学习sync.Pool的源码,这里我就不详细解读了。
但是我们不能忽视的是,sync.Pool还有一些陷阱。sync.Pool是一个底层的缓存池接口,它没有内置清空对象中的数据,这就需要我们在get或put对象时,额外去做这件事,否则会出现脏数据。
我们举一个sync.Pool的最佳实践,这是一个fmt包中使用sync.Pool的例子。fmt利用sync.Pool缓存了pp结构体,在pp结构体中,有一个buf字节数据。fmt调用结束时,会使用free方法将buf清空。p.buf = p.buf[:0] 利用切片的截取将buf清空,并且保留了切片的容量。这在清空数据的同时,复用了之前分配的内存。
func (p *pp) free() {
// See https://golang.org/issue/23199
if cap(p.buf) > 64<<10 {
return
}
p.buf = p.buf[:0]
p.arg = nil
p.value = reflect.Value{}
p.wrappedErr = nil
ppFree.Put(p)
}
不过sync.Pool不是万能的,它并不是在所有场景下都适用,甚至可能适得其反。例如,如果我们的数据大量存储在Map中,想用sync.Pool缓存Map就不太好。因为我们无法在对Map进行清空操作的同时保持Map的容量。这时,我们常常要根据实际的场景,修改设计结构或者构造自己的缓存池。此外,如果在我们的场景中,操作对象时get多put少,那么也会大量地分配内存,起不到缓存的作用。而在get少put多的场景下,sync.Pool还会加重GC的负担。所以我建议你在使用sync.Pool前,先认真分析一下自己的场景是否适合使用sync.Pool。
总结
这节课,我们讲了一个真实的线上性能分析的实战案例。
这一线上瓶颈的本质是内存使用的不合理。当GC被触发之后,在高负载的情况下,内存分配的速度超过了GC扫描的速度,导致一直在执行辅助标记,大大减慢了程序运行的速度。这一现象进一步导致调度延迟等各方面的问题。通过优化代码逻辑和复用内存分配,我们可以消除瓶颈,节约上千台容器。
程序的运行状态就像是一个黑盒,不同的指标可以在侧面反映程序的运行状态,不同的工具也可以反映相同的问题。所以在合适的时间使用合适的工具,将起到事半功倍的效果。
一个运行中的程序似乎总是缺乏“内省”的能力,而为了观察到程序的运行过程,trace工具通过在关键事件处进行埋点来实现事件追踪的能力。这节课的案例证明,trace工具在分析程序整体运行状态甚至是P99瓶颈问题时确实非常强大,它是性能分析甚至是启发式探索问题的利器。
不得不说,在容器化的趋势下,排查复杂问题变得更加困难了。很多时候我们面临的问题不只是语言层面的,而是所有程序都需要面对的。所以一定要有体系化的思考和强大的学习能力。
课后题
学完这节课,请你思考下面这个问题。
对于一个复杂的性能问题,需要有综合的能力并具备一些分析的工具。以CPU和内存为例,你知道哪些排查工具?
欢迎你在留言区与我交流讨论,我们下节课见。
- Realm 👍(3) 💬(0)
1.CPU - top - vmstat - mpstat - pidstat - /proc/softirqs - /proc/interrupts, - sar - strace - perf 2.内存: - free - top - vmstat -pidstat -sar
2023-01-12 - 牙小木 👍(0) 💬(0)
一种是减少(此处为“合理“比较合适)内存的分配,比如代码层面的优化 另一种思路是构建内存池来复用内存, 最后一个暴力的思路是加大gc执行的阈值,
2023-08-19 - 牙小木 👍(0) 💬(0)
这篇不错,团队的力量
2023-08-19