43 分布式协调:etcd读写、MVCC原理与监听机制
你好,我是郑建勋。
这节课,我们重点来看看etcd的读写流程,以及它的两个重要特性:MVCC原理和监听机制。
写的完整流程
我们先来看看etcd怎么完整地写入请求。

- 客户端通过GRPC协议访问etcd-server服务端。
- 如果是一个写请求,会访问etcd-server注册的Put方法。要注意的是,在访问etcd-server时,会进行一些检查,例如DB配额(Quota)的检查。此外,如果客户端访问的节点不是Leader节点,这个节点会将请求转移到Leader中。
- etcd-server会调用raft-node模块的Propose方法进行限速、鉴权等判断,之后raft-node模块调用etcd-raft模块完成数据的封装。
- 接着,etcd-raft模块会将封装后的数据返回给raft-node模块。
- raft-node模块调用storage存储模块,将本次操作对应的Entry记录存储到WAL日志文件当中。
- raft-node模块将当前Entry广播给集群中的其他节点,snap模块还会在适当时候保存当前数据的快照。
- 当Leader最终收到了半数以上节点的确认时,该Entry的状态会变为committed ,这时etcd-raft模块会将Commit Index返回上游,供etcd-server模块执行。后面我们还会看到,etcd-server实现了MVCC机制,维护了某一个Key过去所有的版本记录。
etcd状态机中的数据存储包含了两个部分,第一部分是内存索引叫做treeIndex,用于存储Key与版本号之间的映射关系,另一部分是数据的持久化存储,默认情况下,etcd状态机的持久化存储选择的是BoltDB数据库(良好的接口设计让我们可以选择不同的存储引擎)。BoltDB作为KV存储引擎,底层使用了B+树,并且支持事务。etcd v3提供的事务能力就是基于BoltDB的事务实现的。在BoltDB中存储的数据Key值其实是版本号,而Value值包括了原始请求中的键值对和相应的版本号。
另外,还要格外注意的是,客户端调用写入方法Put成功后,并不意味着数据已经持久化到BoltDB了。因为这时 etcd 并未提交事务,数据只更新在了 BoltDB 管理的内存数据结构中。BoltDB事务提交的过程包含平衡B+树、调整元数据信息等操作,因此提交事务是比较昂贵的。如果我们每次更新都提交事务,etcd 的写性能就会较差。为了解决这一问题,etcd也有对策。etcd 会合并多个写事务请求,通常情况下定时机制会分批次(默认100毫秒/次)统一提交事务, 这就大大提高了吞吐量。
但是这种优化又导致了另一个问题。事务未提交时,读请求可能无法从 BoltDB 中获取到最新的数据。为了解决这个问题,etcd 引入了一个 Bucket Buffer 来保存暂未提交的事务数据。etcd 处理读请求的时候,会优先从 Bucket Buffer 里面读取,其次再从 BoltDB 中读取,通过 Bucket Buffer 提升读写性能,同时也保证了数据一致性。
读的完整流程
下面我们看看一个完整的线性一致性的读请求都要经过哪些过程。
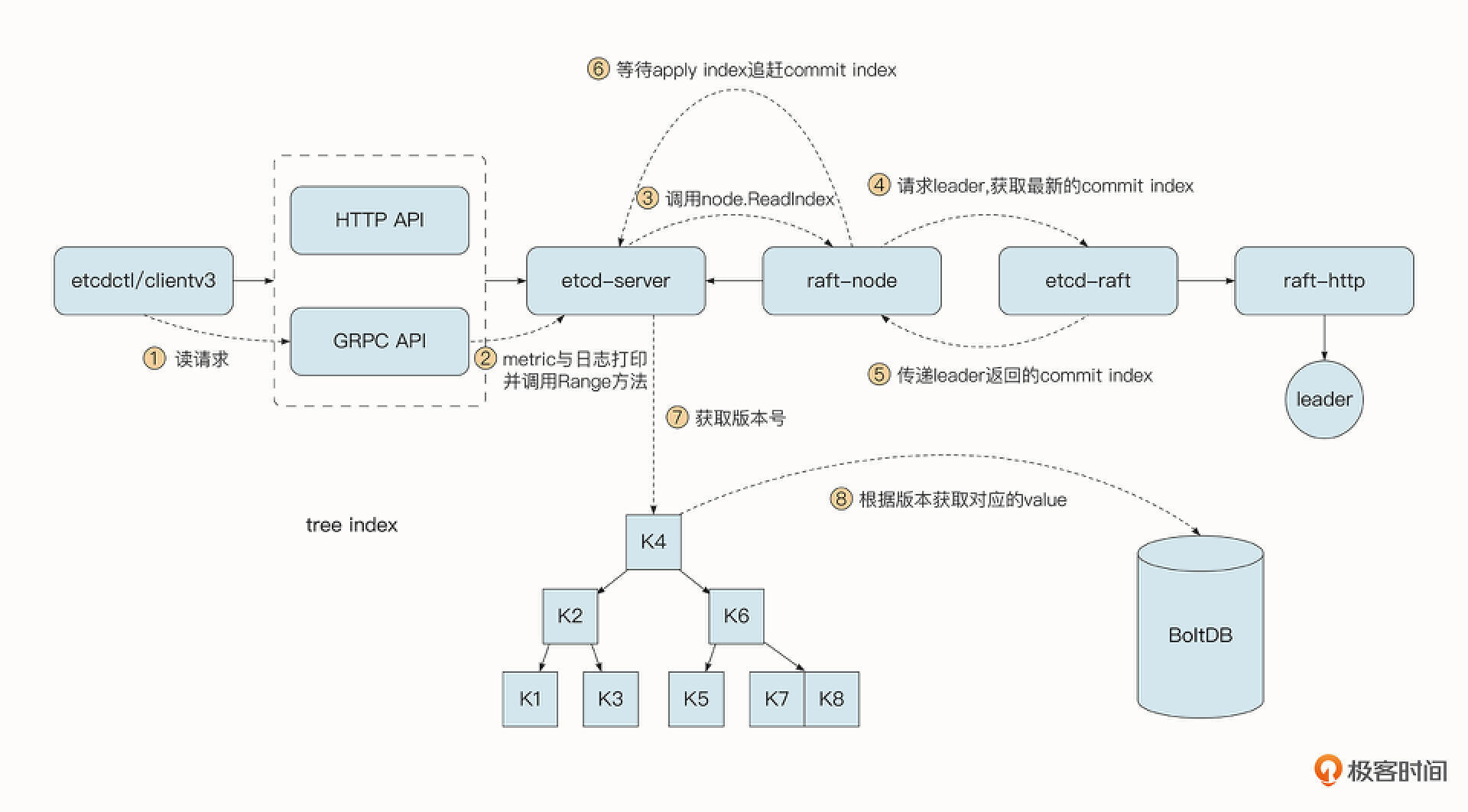
- 首先,客户端通过GRPC API访问etcd-server服务端,这一阶段会经过注册到GRPC服务器中的拦截器,实现日志打印、Metric统计等功能。
- 读操作调用的是etcd-server的Range方法,etcd-server会判断当前的请求是否需要线性一致性的读。
- 对于线性一致性读,etcd-server会调用raft-node模块的ReadIndex方法。
- raft-node模块在etcd-raft模块的帮助下请求Leader节点,获取Leader节点中当前最新的Commit Index。
- etcd-raft模块将Leader返回的Commit Index传递给上游模块etcd-server模块。
- 读取协程会陷入到等待的状态,一直到当前状态机已经执行的Apply Index追赶上当前最新的Commit Index为止。一旦Apply Index追赶上Leader的Commit Index, 就意味着当前我们读取到的数据一定是在最后一次写入操作之后,这就保证了读的强一致性。
- 接着etcd-server会在treeIndex这个B树中,得到当前请求中Key的最新的版本号(也可以在请求中指定读取的版本号和范围)。
- etcd-server最终在BoltDB中通过版本号查询到对应的Value值,并返回给客户端。
MVCC机制
etcd存储了当前Key过去所有操作的版本记录。这样做的好处是,我们可以很方便地获取所有的操作记录,而这些记录常常是实现更重要的特性的基础,例如要实现可靠的事件监听就需要Key的历史信息。
etcd v2会在内存中维护一个较短的全局事件滑动窗口,保留最近的 1000 条变更事件。但是当事件太多的时候,就需要删除老的事件,可能导致事件的丢失。而etcd v3解决了这一问题,etcd v3将历史版本存储在了BoltDB当中进行了持久化。可靠的Watch机制将避免客户端执行一些更繁重的查询操作,提高了系统的整体性能。
借助Key的历史版本信息,我们还能够实现乐观锁的机制。 乐观锁即乐观地认为并发操作同一份数据不会发生冲突,所以不会对数据全局加锁。但是当事务提交时,她又能够检测到是否会出现数据处理异常。乐观锁的机制让系统在高并发场景下仍然具备高性能。这种基于多版本技术实现的乐观锁机制也被称为MVCC。
下面就让我们来看看etcd是如何实现MVCC机制,对多版本数据的管理与存储的吧。在etcd中,每一个操作不会覆盖旧的操作,而是会指定一个新的版本,其结构为revision。
revision 主要由两部分组成,包括main与sub两个字段。其中每次出现一个新事务时main都会递增1,而对于同一个事务,执行事务中每次操作都会导致sub递增1,这保证了每一次操作的版本都是唯一的。假设事务1中的两条操作分别如下。
事务2中的两条操作是下面的样子。
那么每条操作对应的版本号就分别是下面这样。
etcd最终会默认将键值对数据存储到BoltDB当中,完成数据的落盘。不过为了管理多个版本,在BoltDB中的Key对应的是revision版本号,而Value对应的是该版本对应的实际键值对。BoltDB在底层使用B+树进行存储,而B+树的优势就是可以实现范围查找,这有助于我们在读取数据以及实现Watch机制的时候,查找某一个范围内的操作记录。
看到这里你可能会有疑问,在BoltDB中存储的key是版本号,但是在用户查找的时候,可能只知道具体数据里的Key,那如何完成查找呢?
为了解决这一问题,etcd在内存中实现了一个B树的索引treeIndex,封装了Google开源的B树的实现。B树的存储结构方便我们完成范围查找,也能够和BoltDB对应的B+树的能力对应起来。treeIndex实现的索引,实现了数据Key与keyIndex实例之间的映射关系,而在keyIndex中存储了当前Key对应的所有历史版本信息。 通过这样的二次查找,我们就可以通过Key查找到BoltDB中某一个版本甚至某一个范围的Value值了。
借助etcd的MVCC机制以及BoltDB数据库,我们可以在etcd中实现事务的 ACID 特性。etcd clientv3中提供的简易事务API正是基于此实现的。
Watch 机制
etdc支持监听某一个特定的Key,也支持监听一个范围。etcdv3的 MVCC 机制将历史版本都保存在了BoltDB中,避免了历史版本的丢失。 同时,etcdv3还使用GRPC协议实现了客户端与服务器之间数据的流式传输。
那etcd服务端是如何实现 Watch 机制的呢?
当客户端向etcd服务器发出监听的请求时,etcd服务器会生成一个watcher。etcd会维护这些watcher,并将其分为两种类型:synced 和 unsynced。
synced watcher意味着当前 watcher 监听的最新事件都已经同步给客户端,接下来synced watcher陷入休眠并等待新的事件。unsynced watcher 意味着当前watcher监听的事件并未完全同步到客户端。 etcd会启动一个单独的协程帮助unsynced watcher进行追赶。 当unsynced watcher 处理完最新的操作,将最新的事件同步到客户端之后,就会变为 synced watcher。
unsynced watcher的处理
etcd初始化时创建了单独的协程来处理unsynced watcher。由于unsynced watcher可能会很多,etcd采用了一种巧妙的方法来处理它,具体方式如下。
- 选择一批unsynced watcher,作为此次要处理的watcher。
- 查找这批watcher中最小的版本值。
- 在BoltDB中进行范围查询,查询最小版本号与当前版本号之间的所有键值对。
- 将这些键值对转换为Event事件,满足watcher条件的Event事件将会被发送回对应的客户端。
- 当unsynced watcher 处理完最新的操作之后,就会变为 synced watcher。
synced watcher的处理
当 etcd 收到一个写请求,Key-Value 发生变化的时候,对应的synced watcher需要能够感知到并完成最新事件的推送。这一步主要是在 Put 事务结束时来做的。
Put事务结束后,会调用watchableStore.notify,获取监听了当前Key的watcher,然后将Event送入这些watcher的 Channel 中,完成最终的处理和发送。
监听当前Key的watcher可能很多,你可能会想到用一个哈希表来存储Key与watcher的对应关系,但是这还不够,因为一个watcher可能会监听Key的范围和前缀。因此,为了能够高效地获取某一个Key对应的watcher,除了使用哈希表,etdc还使用了区间树结构来存储 watcher 集合。当产生一个事件时,etcd 首先需要从哈希表查找是否有 watcher 监听了该Key,然后它还需要从区间树重找出满足条件的所有区间,从区间的值获取监听的 watcher 集合。
总结
本节课程中我们介绍了etcd完整的读写流程。在整个复杂的流程中,核心模块无外乎是GRPC请求、权限和参数的检查、WAL日志的存储、Raft节点的网络协调以及执行操作更新状态机的状态等。把握这些核心处理流程和模块,也就能理解etcd是如何实现一致性、容错性以及高性能的了。
etcd存储实现了MVCC机制,保存了历史版本的所有数据。这种机制主要是依靠了内存索引treeIndex与后端存储BoltDB,它不仅提高了etcd系统的并发处理能力,也为构建可靠的Watch机制和事务提供了基础。
etcd将watch对象分为了unsynced watcher 与synced watcher,其中synced watcher表示最新事件已经同步给客户端,而 unsynced watcher 表示最新事件还未同步到客户端。etcd在初始化时就建立了一个单独的协程完成 unsynced watcher 的追赶,通过范围查找,即便存在大量的watcher,也能轻松应对。
这两节课我们更多还是在讲解理论,我希望你能够明白etcd的这些重要功能背后的实现机制,为我们后面要实战分布式协调做准备。如果你理解了原理却还觉得不过瘾,想要深入到源码中去学习etcd的话,我也推荐你去看看《etcd技术内幕》这本书,它对etcd源码的各个字段都介绍得比较详细。
课后题
学完这节课,给你留两道思考题。
- treeIndex的结构为什么是B树而不是哈希表或者是二叉树?
- 写操作会调用etcd Put方法,调用Put方法结束时并未真正地执行BoltDB的commit操作进行事务提交,如果这个时候节点崩溃了,如何保证数据不丢失呢?
欢迎你在留言区与我交流讨论,我们下节课见。
- Realm 👍(3) 💬(1)
思考题: 一 treeIndex 的结构为什么是 B 树而不是哈希表或者是二叉树? 不使用【hash表】的原因: 1. hash表不支持范围查询; 2. hash表可能有hash碰撞的问题(Hash_fn(k1) = Hash_fn(key2),还需要使用其他方法进行进一步处理(如:拉链法); 3. hash表不支持排序; 4. hash表不支持key的前缀索引,prefix=xxx,想必是用不了; 不使用【二叉树】的原因: 1. 二叉树造成树的层次太高,查找的时候,可能造成磁盘IO的次数较多,性能不好. 二 如果这个时候节点崩溃了,如何保证数据不丢失呢? 应该是通过WAL进行保障,先写日志在提交. 这样看,很多思路与MySQL相似.
2023-01-17 - Geek_c3c15b 👍(0) 💬(2)
怎么又是一整篇理论知识,实战课的重点不是实战吗?极客时间已经有etcd的专栏了
2023-02-22