53 容器化实战:怎样搭建K8s爬虫集群?
你好,我是郑建勋。
上节课,我们介绍了 Kubernetes 架构和相关的原理。这节课让我们更进一步,将爬虫项目相关的微服务部署到 Kubernetes 中。
安装 Kubernetes 集群
首先,我们需要准备好Kubernetes的集群。部署 Kubernetes 集群的方式有很多种,典型的方式有下面几种:
- Play with Kubernetes (PWK)
- Docker Desktop
- 云厂商的k8s服务,例如Google Kubernetes Engine (GKE)
- kops
- kubeadm
- k3s
- k3d
其中,PWK 是试验性质的免费的Kubernetes集群,只要有Docker或者Github账号就可以在浏览器上一键生成Kubernetes集群。但是它有诸多限制,例如一次只能使用4个小时,并且有扩展性和性能等问题。所以PWK一般只用于教学或者试验。
之前,我们在Windows和Mac中用Docker Desktop安装包来安装了Docker,其实利用最新的Docker Desktop,我们还可以在本地生成Kubernetes集群。使用Docker Desktop生成Kubernetes集群非常简单,我们只需要点击Docker的鲸鱼图标,并且在Preferences中勾选Enable Kubernetes,然后点击下方的Apply & restart 就可以创建我们的 Kubernetes 集群了。
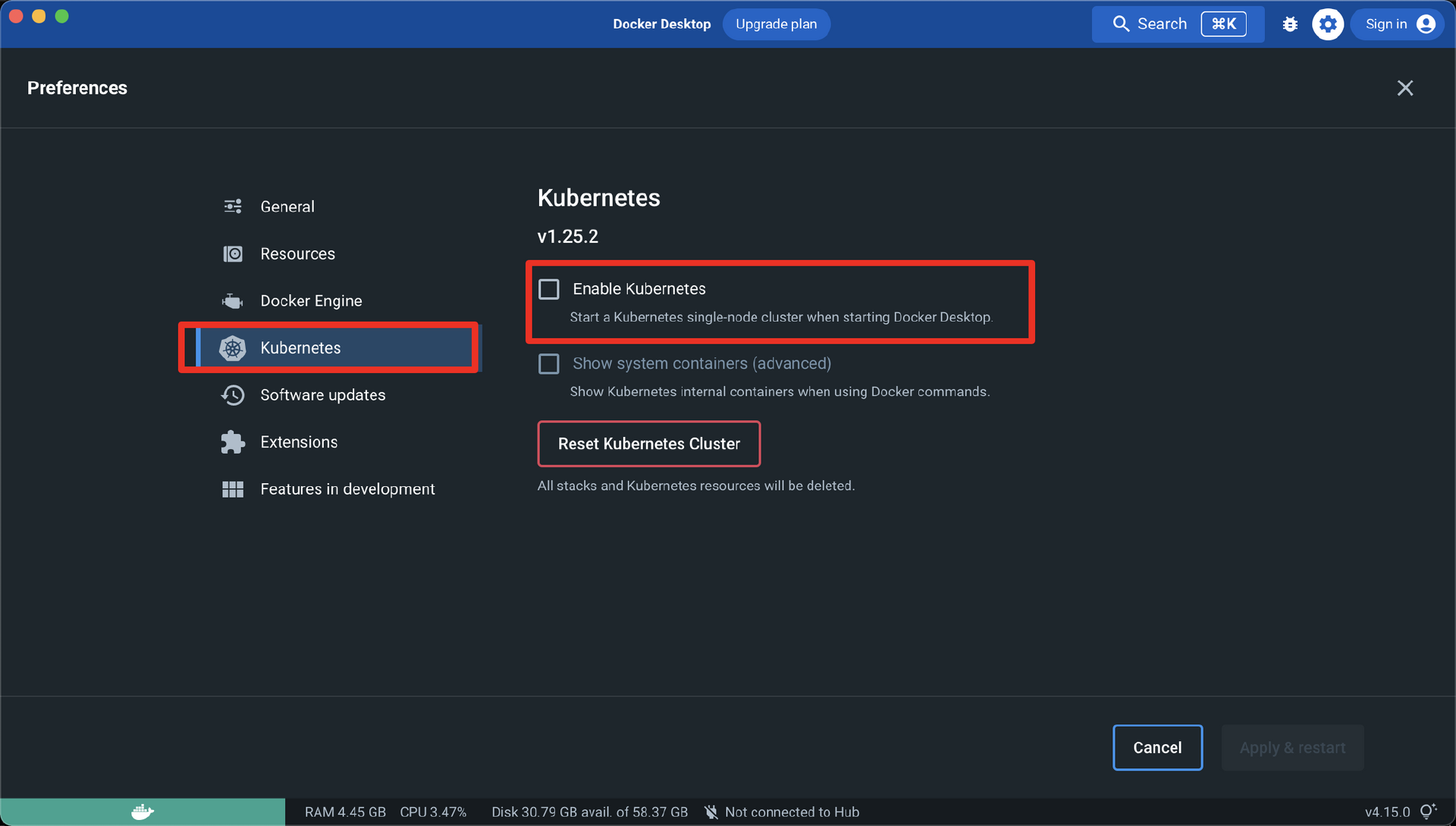
最后,Docker Desktop还提供了切换Kubernetes Context的能力,我们点击docker-desktop,这样我们通过kubectl发送的命令就会传到Docker Desktop构建的Kubernetes集群中。
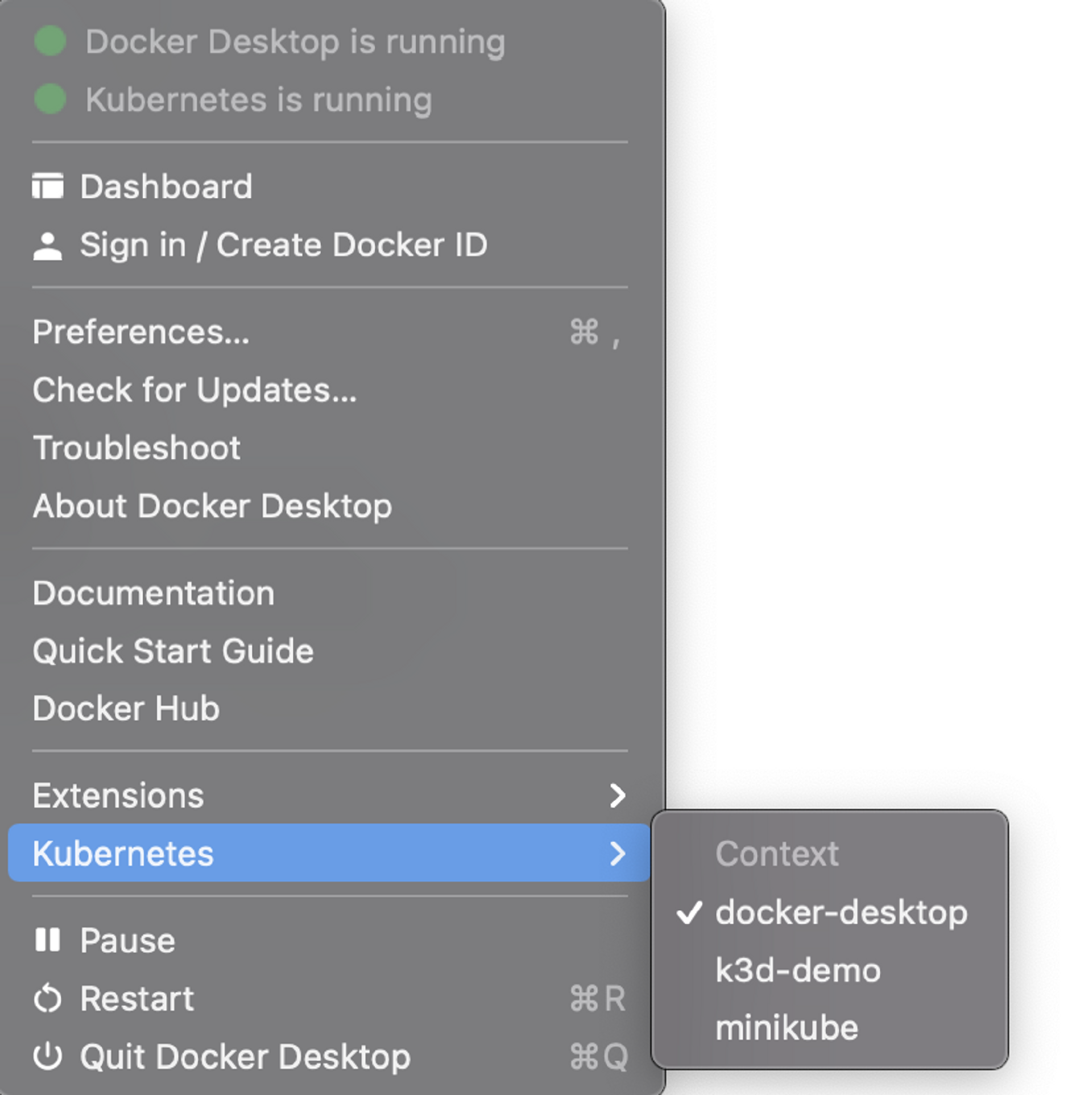
上面的这个界面操作和下面的命令行操作在功能上是相同的。
» kubectl config use-context docker-desktop jackson@jacksondeMacBook-Pro
Switched to context "docker-desktop".
接着,我们执行kubectl get nodes可以看到当前集群为单节点的集群,版本为v1.25.2。
» kubectl get nodes jackson@jacksondeMacBook-Pro
NAME STATUS ROLES AGE VERSION
docker-desktop Ready control-plane 25d v1.25.2
Docker Desktop生成的Kubernetes集群可以用于开发测试,但是它不能模拟多节点的Kubernetes集群。
在一些生产环境中,我们可能需要手动部署多节点的Kubernetes集群。例如我们要以Kubernetes为基座为某企业部署一套人脸识别系统,这时我们可以使用 kubeadm 工具来安装Kubernetes集群。
kubeadm是 Kubernetes 1.4版本引入的命令行工具,它致力于简化集群的安装过程。如果要更精细地调整Kubernetes各组件服务的参数和安全设置,还可以用Kubernetes二进制文件的方式进行部署。kubeadm和二进制文件的安装方式你可以查看官方文档和《kubernetes权威指南》。
在另一些生产环境中,例如在私有云的场景下,如果为了应对高峰期而购入机器,容易导致机器闲置,带来资源浪费,这时我们可以借助云厂商的Kubernetes服务(Google GKE,Microsoft AKS,Amazon EKS,腾讯云,阿里云)搭建 Kubernetes 集群。以 GKE 为例,GKE是运行在谷歌云平台上的Kubernetes托管服务,它可以为我们快速部署和管理生产级的Kubernetes 集群。要注意的是,部署在云厂商的Kubernetes集群一般都是需要付费的。
k3s是轻量级的Kubernetes集群,它通过删除Kubernetes中不必要的第三方存储驱动,删除与云厂商交互的代码,将Kubernetes组件合并到了不到100 MB的二进制文件中去运行,这就减少了二进制文件与内存占用的大小。这个方案适用于物联网等对资源吃紧的环境,也可以用于CI及开发环境。
而k3d是一个社区驱动的项目,它对k3s进行了封装,从而可以在Docker中创建单节点或多节点的 Kubernetes 集群。使用k3d,我们用一行指令就可以创建Kubernetes 集群。这节课,我们就用k3d搭建多节点、轻量级的Kubernetes集群,实现开发与测试的目的。
安装 k3d
k3d的安装方式比较简单,可以执行如下的脚本完成。
如果想安装k3d的指定版本,可以使用下面的指令。
在Mac中,还可以使用brew进行安装,如下所示。其他的安装方式你可以查看官方文档。
安装完成后,执行 k3d version 可以查看k3d的版本信息和k3d依赖的k3s的版本。
k3d的使用方法我推荐你阅读它的官方文档和k3d维护的一个交互式的demo项目。这个demo项目可以完成从集群的创建到销毁,从Pod的创建到销毁的完整链路。你可以下载k3d-demo项目的代码,然后make demo,跟着它的提示一步步去学习。
下面让我们来看看如何借助k3d搭建Kubernetes集群。
首先执行k3d cluster create命令,创建Kubernetes集群。
» k3d cluster create demo --api-port 6550 --servers 1 --c 3 --port 8080:80@loadbalancer --wait
INFO[0000] portmapping '8080:80' targets the loadbalancer: defaulting to [servers:*:proxy agents:*:proxy]
INFO[0000] Prep: Network
INFO[0000] Created network 'k3d-demo'
INFO[0000] Created image volume k3d-demo-images
INFO[0000] Starting new tools node...
INFO[0000] Starting Node 'k3d-demo-tools'
INFO[0007] Creating node 'k3d-demo-server-0'
INFO[0007] Creating node 'k3d-demo-agent-0'
INFO[0007] Creating node 'k3d-demo-agent-1'
INFO[0007] Creating node 'k3d-demo-agent-2'
INFO[0007] Creating LoadBalancer 'k3d-demo-serverlb'
INFO[0007] Using the k3d-tools node to gather environment information
INFO[0007] Starting new tools node...
INFO[0007] Starting Node 'k3d-demo-tools'
INFO[0009] Starting cluster 'demo'
INFO[0009] Starting servers...
INFO[0009] Starting Node 'k3d-demo-server-0'
INFO[0013] Starting agents...
INFO[0014] Starting Node 'k3d-demo-agent-2'
INFO[0014] Starting Node 'k3d-demo-agent-1'
INFO[0014] Starting Node 'k3d-demo-agent-0'
INFO[0019] Starting helpers...
INFO[0019] Starting Node 'k3d-demo-serverlb'
INFO[0026] Injecting records for hostAliases (incl. host.k3d.internal) and for 6 network members into CoreDNS configmap...
INFO[0028] Cluster 'demo' created successfully!
其中,运行参数api-port用于指定Kubernetes API server对外暴露的端口。servers用于指定master node的数量。agents用于指定worker node的数量。port用于指定宿主机端口到Kubernetes集群的映射。后面我们会看到,当我们访问宿主机8080端口时,实际上会被转发到集群的80端口。wait参数表示等待k3s集群准备就绪后指令才会返回。
创建好 Kubernetes 集群后,执行 k3d cluster list 可以看到当前创建好的demo集群信息。
要让kubectl客户端能够访问到我们刚创建好的Kubernetes集群,需要使用下面的指令,把当前集群的配置信息合并到kubeconfig文件中,然后切换Kubernetes Context,使kubectl能够访问到新建的集群。
接下来,输入kubectl get nodes,可以看到当前集群的Master Node与Worker Node。
» kubectl get nodes jackson@localhost
NAME STATUS ROLES AGE VERSION
k3d-demo-server-0 Ready control-plane,master 2m36s v1.24.4+k3s1
k3d-demo-agent-1 Ready <none> 2m31s v1.24.4+k3s1
k3d-demo-agent-0 Ready <none> 2m31s v1.24.4+k3s1
k3d-demo-agent-2 Ready <none> 2m31s v1.24.4+k3s1
部署Worker Deployment
创建好集群之后,我们要想办法将当前的爬虫项目部署到 Kubernetes 集群中。首先让我们书写一个crawl-worker.yaml文件,用它来创建Deployment资源,管理我们的容器crawl-worker。描述文件如下。
apiVersion: apps/v1
kind: Deployment
metadata:
name: crawler-deployment
labels:
app: crawl-worker
spec:
replicas: 3
selector:
matchLabels:
app: crawl-worker
template:
metadata:
labels:
app: crawl-worker
spec:
containers:
- name: crawl-worker
image: crawler:local
command:
- sh
- -c
- "./crawler worker --podip=${MY_POD_IP}"
ports:
- containerPort: 8080
env:
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
下面我们来挨个解释一下文件中的信息。
- apiVersion:定义创建对象时使用的 Kubernetes API的版本。apiVersion的一般形式为
<GROUP_NAME>/<VERSION>。在这里,Deployment的API group为app,版本为v1。而Pod对象由于位于特殊的核心组,可以省略掉<GROUP_NAME>。apiVersion的设计有助于Kubernetes对不同的资源进行单独的管理,也有助于开发者创建Kubernetes中实验性质的资源进行测试。 - kind 表示当前资源的类型,在这里我们定义的是Deployment对象。之前我们提到过,Deployment在Pod之上增加了自动扩容、自动修复和滚动更新等功能。
- metadata.name:定义deployment的名字。
- metadata.labels:给 Deployment 的标签。
- spec:代表对象的期望状态。
- spec.replicas:代表创建和管理的 Pod 的数量。
- spec.selector:定义了 Deployment Controller 要管理哪些Pod。这里定义的通常是标签匹配的Pod,满足该标签的Pod会被纳入到Deployment Controller 中去管理。
- spec.template.metadata:定义了Pod的属性,在上例中,定义了标签属性crawl-worker。
- spec.template.spec.containers:定义了Pod中的容器属性。
- spec.template.spec.containers.name:定义了容器的名字。
- spec.template.spec.containers.image:定义了容器的镜像。
- spec.template.spec.containers.command:定义了容器的启动命令。注意,启动参数中的
${MY_POD_IP}是从环境变量中获取的MY_POD_IP对应的值。 - spec.template.spec.container.ports:描述服务暴露的端口信息,方便开发者更好地理解服务,没有实际的作用。
- spec.template.spec.container.env:定义容器的环境变量。在这里,我们定义了一个环境变量MY_POD_IP,并且传递了一个特殊的值,即Pod的IP。并将该环境变量的值传递到了运行参数当中。
这里我将Pod的IP传入到程序中有一个妙处。我们之前在程序运行时手动传入了Worker的ID,这在开发环境中是没有问题的。但是在生产环境中,我们希望Worker能够动态扩容,这时就不能手动地指定ID了。我们需要让程序在启动后自动生成一个ID,并且这个ID在分布式节点中是唯一的。
一些同学可能会想到把时间当作唯一的ID,例如使用 time.Now().UnixNano() 来获取Unix时间戳。但是,程序获取到的时间仍然可能是重复的,虽然概率很小。另一些同学可能会想到利用MySQL的自增主键或者借助etcd等分布式组件来得到分布式ID。这当然是一种解决办法,不过却依赖了额外的外部服务。在这里,我选择了一种更为巧妙的方法,即借助Kubernetes中Pod的IP不重复的特性,将Pod的IP传递到程序中,借助唯一的Pod IP生成唯一的ID。代码如下所示。
WorkerCmd.Flags().StringVar(
&podIP, "podip", "", "set worker id")
WorkerCmd.Flags().StringVar(
&workerID, "id", "", "set worker id")
var podIP string
if workerID == "" {
if podIP != "" {
ip := generator.GetIDbyIP(podIP)
workerID = strconv.Itoa(int(ip))
} else {
workerID = fmt.Sprintf("%d", time.Now().UnixNano())
}
}
// generator/generator.go
func GetIDbyIP(ip string) uint32 {
var id uint32
binary.Read(bytes.NewBuffer(net.ParseIP(ip).To4()), binary.BigEndian, &id)
return id
}
现在workerID的默认值为空,如果没有传递id flag,也没有传递podip flag,这一般是线下开发场景,我们直接使用Unix时间戳来生成ID。如果没有传递id flag,但传递了podip flag,我们则要利用Pod IP的唯一性生成ID。
准备好程序代码之后,让我们生成Worker的镜像,并打上镜像tag:crawler:local。 要注意的是,这里我们并没有和之前一样将镜像变为crawler:latest。 这是因为对于crawler:latest的镜像,Kubernetes会在DockerHub中默认拉取最新的镜像,这会导致镜像拉取失败,这里我们希望 Kubernetes 使用本地缓存的镜像。
接着,将镜像导入到k3d集群中。
准备好镜像之后,我们就可以创建 Kubernetes 中的 Deployment 资源,用它管理我们的Worker节点了。具体步骤是,执行kubectl apply,告诉 Kubernetes 我们希望创建的Deployment资源的信息。
接下来,输入kubectl get po,查看default namespace中Pod的信息。可以看到,Kubernetes已经为我们创建了3个Pod。
» kubectl get po
NAME READY STATUS RESTARTS AGE
crawler-deployment-6744cc644b-2mm9r 1/1 Running 0 88s
crawler-deployment-6744cc644b-bgjqc 1/1 Running 0 88s
crawler-deployment-6744cc644b-84t9g 1/1 Running 0 88s
使用kubectl logs 打印出某一个Pod的日志,可以看到Worker节点已经正常地运行了。
还要注意的是,当前Worker节点的启动依赖于MySQL和etcd这两个组件。和之前一样,我们是先将这两个组件在宿主机中Docker启动的,后续这两个组件可以部署到Kubernetes集群中。
» kubectl logs -f crawler-deployment-6744cc644b-2mm9r
{"level":"INFO","ts":"2022-12-24T07:50:09.301Z","caller":"worker/worker.go:101","msg":"log init end"}
{"level":"INFO","ts":"2022-12-24T07:50:09.301Z","caller":"worker/worker.go:109","msg":"proxy list: [<http://192.168.0.105:8888> <http://192.168.0.105:8888>] timeout: 3000"}
{"level":"DEBUG","ts":"2022-12-24T07:50:09.311Z","caller":"worker/worker.go:152","msg":"grpc server config,{RegistryAddress::2379 RegisterTTL:60 RegisterInterval:15 Name:go.micro.server.worker ClientTimeOut:10}"}
{"level":"DEBUG","ts":"2022-12-24T07:50:09.313Z","caller":"worker/worker.go:223","msg":"start http server listening on :8080 proxy to grpc server;:9090"}
2022-12-24 07:50:09 file=worker/worker.go:196 level=info Starting [service] go.micro.server.worker
2022-12-24 07:50:09 file=v4@v4.9.0/service.go:96 level=info Server [grpc] Listening on [::]:9090
2022-12-24 07:50:09 file=grpc@v1.2.0/grpc.go:913 level=info Registry [etcd] Registering node: go.micro.server.worker-1
现在让我们来尝试从外部访问一下Worker节点。 由于网络存在隔离性,当前要想从外部访问Worker节点还没有那么容易。但是我们之前讲过,Pod之间是可以通过IP相互连接的,所以我们打算通过一个 Pod 容器访问Worker节点。由于当前我们生成的crawler容器内没有内置网络请求工具,所以在这里我们用kubectl run启动一个带有curl工具的镜像curlimages/curl,并命名为mycurlpod。
如下,我们仍然使用kubectl get pod 查看当前Worker Pod 的IP地址,-o wide 可以帮助我们得到更详细的Pod信息。
» kubectl get pod -o wide jackson@bogon
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
crawler-deployment-6744cc644b-2mm9r 1/1 Running 0 40m 10.42.4.9 k3d-new-agent-1 <none> <none>
crawler-deployment-6744cc644b-bgjqc 1/1 Running 0 40m 10.42.5.10 k3d-new-agent-0 <none> <none>
crawler-deployment-6744cc644b-84t9g 1/1 Running 0 40m 10.42.3.6 k3d-demo-agent-2 <none> <none>
mycurlpod 1/1 Running 0 26m 10.42.4.10 k3d-new-agent-1 <none> <none>
接着进入到mycurlpod中,利用Worker节点的Pod IP地址进行访问,成功返回预期数据。
» curl -H "content-type: application/json" -d '{"name": "john"}' http://10.42.4.9:8080/greeter/hello
{"greeting":"Hello "}
部署Worker Service
不过到这里还不能放松警惕。我们上节课说过,Pod的IP会随时发生变化,为了有稳定的IP来访问我们的Worker与Master,我们要创建一个文件crawl-worker-service.yaml,用它来描述Service资源。Service默认的类型为ClusterIP,该类型的Service IP只能够在集群内部访问。
kind: Service
apiVersion: v1
metadata:
name: crawl-worker
labels:
app: crawl-worker
spec:
selector:
app: crawl-worker
ports:
- port: 8080
name: http
- port: 9090
name: grpc
描述Service资源与之前描述Deployment资源非常类似。
- kind: Service:指的是当前的Kubernetes资源类型为Service。
- apiVersion: v1:代表apiVersion的版本是v1,由于Service是核心类型,因此省略掉了API GROUP的命名前缀。
- metadata.name:当前Service的名字。
- metadata.labels:当前Service的标签。
- spec.selector:选择器,表示当前Service管理哪些后台服务,只有标签为 app: crawl-worker的Pod才会受到该Service的管理,这些Pod就是我们的Worker节点。
- spec.ports.port:当前Service监听的端口号。例如。port: 8080指的是当前Service会监听8080端口。默认情况下,当外部访问该Service的8080端口时,会将请求转发给后端服务相同的端口。
- spec.ports.port.name:描述了当前Service端口规则的名字。
接下来使用 kubectl apply 创建Service资源,并使用kubectl get service得到Service的Cluster-IP地址。
» kubectl apply -f crawl-worker-service.yaml
» kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
crawl-worker ClusterIP 10.43.245.115 <none> 8080/TCP,9090/TCP 13m
同样,在包含curl工具的mycurlpod中,访问Service暴露的ClusterIP,这时请求会负载均衡到后端任意一个Worker节点中。
$ curl -H "content-type: application/json" -d '{"name": "john"}' http://10.43.245.115:8080/greeter/hello
部署 Master Deployment
Master节点的部署和Worker节点的部署非常类似。如下所示,创建crawler-master.yaml文件,描述Deployment资源的信息。这里和Worker Deployment不同的主要是相关的名字和程序启动的命令。
apiVersion: apps/v1
kind: Deployment
metadata:
name: crawler-master-deployment
labels:
app: crawl-master
spec:
replicas: 1
selector:
matchLabels:
app: crawl-master
template:
metadata:
labels:
app: crawl-master
spec:
containers:
- name: crawl-master
image: crawler:local
command:
- sh
- -c
- "./crawler master --podip=${MY_POD_IP}"
ports:
- containerPort: 8081
env:
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
部署 Master Service
同样地,为了能够用固定地IP访问Master,我们需要创建Master Service。新建crawl-master-service.yaml文件,如下所示,port指的是Service监听的端口80,这是默认的HTTP端口,而targetPort指的是转发到后端服务器的端口,也就是Master服务的HTTP端口8081。
kind: Service
apiVersion: v1
metadata:
name: crawl-master
labels:
app: crawl-master
spec:
selector:
app: crawl-master
type: NodePort
ports:
- port: 80
targetPort: 8081
name: http
- port: 9091
name: grpc
接下来,我们还是利用kubectl apply创建Master Service。
现在我们就可以和Worker一样,利用Service访问Masrer暴露的接口了。
创建 Ingress
下面让我们更进一步,尝试在宿主机中访问集群的Master服务。由于资源具有隔离性,之前我们一直都是在集群内从一个Pod中去访问另一个Pod。现在我们希望在集群外部使用HTTP访问Master服务。要实现这个目标,可以使用Ingress资源。
具体做法是,创建ingress.yaml,在ingress.yaml文件中书写相关的HTTP路由规则,根据不同的域名和URL将请求路由到后端不同的Service中。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: crawler-ingress
spec:
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: crawl-master
port:
number: 80
spec.http.paths中描述了Ingress的路由规则,我们对应上面这个例子解读一下。
- spec.http.paths.path 表示URL匹配的路径。
- spec.http.paths.pathType 表示URL匹配的类型为前缀匹配。
- spec.http.paths.backend.service.name 表示路由到后端的Service的名字。
- spec.http.paths.backend.service.port 表示路由到后端的Service的端口。
其实要使用Ingress的功能,光是定义ingress.yaml中的路由规则是不行的,我们还需要Ingress Controller控制器来实现这些路由规则的逻辑。但是和Kubernetes中内置的Controller不同,Ingress Controller 是可以灵活选择的,比较有名的Ingress Controller包括Nginx、Kong等。如果你想使用这些Ingress Controller ,需要单独安装。
好在,k3d默认为我们内置了traefik Ingress Controller,这样我们就不需要再额外安装了。只要创建Ingress资源,就可以直接访问它了。
下一步,我们在宿主机中访问集群。在这里我们访问的是8080端口,因为我在创建集群时指定了端口的映射,所以当前8080端口的请求会转发到集群的80端口中。然后根据Ingress指定的规则,请求会被转发到后端的Master Service当中。
» curl -H "content-type: application/json" -d '{"id":"zjx","name": "douban_book_list"}' http://127.0.0.1:8080/crawler/resource
此外,Ingress还可以设置规则,让不同的域名走不同的域名规则,这里就不再赘述了。
» curl -H "content-type: application/json" -d '{"id":"zjx","name": "douban_book_list"}' http://zjx.vx1131052403.com:8080/crawler/resource
创建 ConfigMap
到这一步,我们的配置文件都是打包在镜像中的,如果想要修改程序的启动参数会非常麻烦。因此,我们可以借助Kubernetes中的ConfigMap资源,将配置挂载到容器当中,这样我们就可以更灵活地修改配置文件,而不必每一次都打包新的镜像了。
具体做法如下。我们创建一个ConfigMap资源,把它放到默认的namespace中。在Data下,对应地输入文件名config.toml和文件内容。
apiVersion: v1
kind: ConfigMap
metadata:
name: crawler-config
namespace: default
data:
config.toml: |-
logLevel = "debug"
[fetcher]
timeout = 3000
proxy = ["http://192.168.0.105:8888", "http://192.168.0.105:8888"]
[storage]
sqlURL = "root:123456@tcp(192.168.0.105:3326)/crawler?charset=utf8"
[GRPCServer]
HTTPListenAddress = ":8080"
GRPCListenAddress = ":9090"
ID = "1"
RegistryAddress = "192.168.0.105:2379"
RegisterTTL = 60
RegisterInterval = 15
ClientTimeOut = 10
Name = "go.micro.server.worker"
[MasterServer]
RegistryAddress = "192.168.0.105:2379"
RegisterTTL = 60
RegisterInterval = 15
ClientTimeOut = 10
Name = "go.micro.server.master"
然后,修改crawler-master.yaml文件,将ConfigMap挂载到容器中。
apiVersion: apps/v1
kind: Deployment
metadata:
name: crawler-master-deployment
labels:
app: crawl-master
spec:
replicas: 1
selector:
matchLabels:
app: crawl-master
template:
metadata:
labels:
app: crawl-master
spec:
containers:
- name: crawl-master
image: crawler:local
command:
- sh
- -c
- "./crawler master --podip=${MY_POD_IP} --config=/app/config/config.toml"
ports:
- containerPort: 8081
env:
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
volumeMounts:
- name: crawler-config
mountPath: /app/config/
volumes:
- name: crawler-config
configMap:
name: crawler-config
在这个例子中,spec.template.spec.volumes创建了一个存储卷crawler-config,它的内容来自于名为crawler-config的ConfigMap。接着,spec.template.spec.containers.volumeMounts表示将该存储卷挂载到容器的/app/config目录下,这样程序就能够顺利使用ConfigMap中的配置文件了。
总结
这节课,我们学习了如何安装Kubernetes集群,然后使用k3d工具搭建起了轻量级的Kubernetes集群,从而在开发环境中模拟了多节点的Kubernetes集群。
我们还书写了核心的YAML描述文件,创建了Kubernetes中的资源,包括Deployment、Pod、Service、Ingress、ConfigMap等,将我们的爬虫项目部署到了Kubernetes中。
如果你是第一次接触这些 Kubernetes 描述文件,可能会觉得非常繁琐,但是熟悉之后就会变得简单了。创建了这些资源之后,剩下服务的扩容、维护就可以交给强大的Kubernetes来管理了。
(这节课中的 YAML 文件在最新代码分支的Kubernetes文件夹中。 )
课后题
学完这节课,请你思考下面这个问题。
我们这节课书写的YAML文件中的资源对象,都是Kubernetes中定义好的资源类型。那么我们可不可以创建一个自定义的类型,自己去控制它的生命周期呢?
欢迎你在留言区留下自己思考的结果,也可以把这节课分享给对这个话题感兴趣的同事和朋友,我们下节课再见!
- Geek_2c2c44 👍(0) 💬(0)
这个集群高度依赖etcd, 但是这里部署的etcd本身似乎好像没有很强的可用性保障?
2024-01-31 - 北庭 👍(0) 💬(1)
老师,在使用kubectl get node命令后出现了这样的错误:couldn't get current server API group list: Get "https://host.docker.internal:6550/api?timeout=32s": dial tcp 10.0.0.35:6550: connectex: A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond. 这是什么原因呢
2023-03-14 - Geek_7873ee 👍(0) 💬(0)
master 只部署了一个节点,那代码中对master做的高可用,就不是看不出来效果了嘛
2023-02-15