31 加餐1:带你吃透课程中Java 8的那些重要知识点(一)
你好,我是朱晔。
Java 8是目前最常用的JDK版本,在增强代码可读性、简化代码方面,相比Java 7增加了很多功能,比如Lambda、Stream流操作、并行流(ParallelStream)、Optional可空类型、新日期时间类型等。
这个课程中的所有案例,都充分使用了Java 8的各种特性来简化代码。这也就意味着,如果你不了解这些特性的话,理解课程内的Demo可能会有些困难。因此,我将这些特性,单独拎了出来组成了两篇加餐。由于后面有单独一节课去讲Java 8的日期时间类型,所以这里就不赘述了。
如何在项目中用上Lambda表达式和Stream操作?
Java 8的特性有很多,除了这两篇加餐外,我再给你推荐一本全面介绍Java 8的书,叫《Java实战(第二版)》。此外,有同学在留言区问,怎么把Lambda表达式和Stream操作运用到项目中。其实,业务代码中可以使用这些特性的地方有很多。
这里,为了帮助你学习,并把这些特性用到业务开发中,我有三个小建议。
第一,从List的操作开始,先尝试把遍历List来筛选数据和转换数据的操作,使用Stream的filter和map实现,这是Stream最常用、最基本的两个API。你可以重点看看接下来两节的内容来入门。
第二,使用高级的IDE来写代码,以此找到可以利用Java 8语言特性简化代码的地方。比如,对于IDEA,我们可以把匿名类型使用Lambda替换的检测规则,设置为Error级别严重程度:
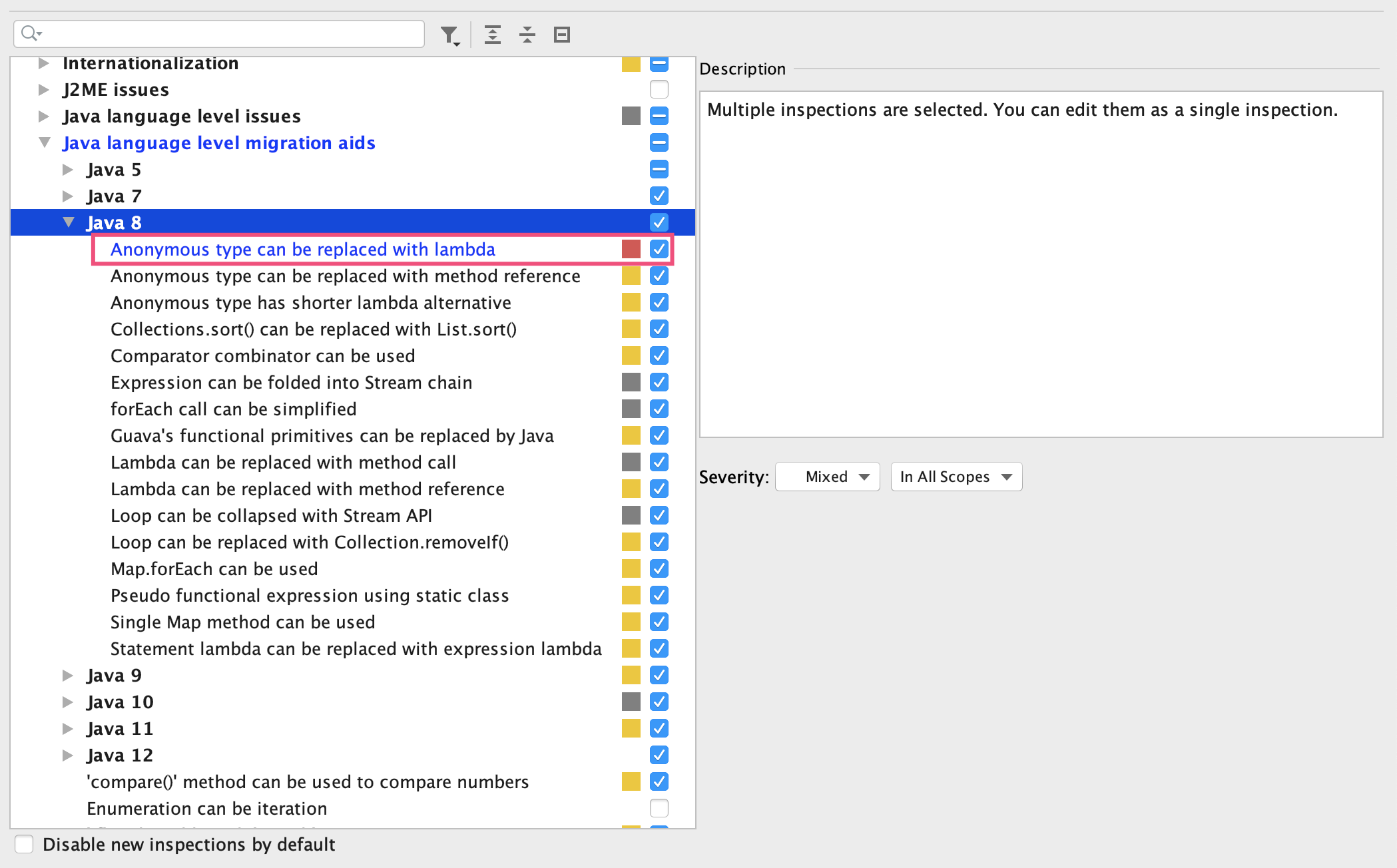
这样运行IDEA的Inspect Code的功能,可以在Error级别的错误中看到这个问题,引起更多关注,帮助我们建立使用Lambda表达式的习惯:

第三,如果你不知道如何把匿名类转换为Lambda表达式,可以借助IDE来重构:
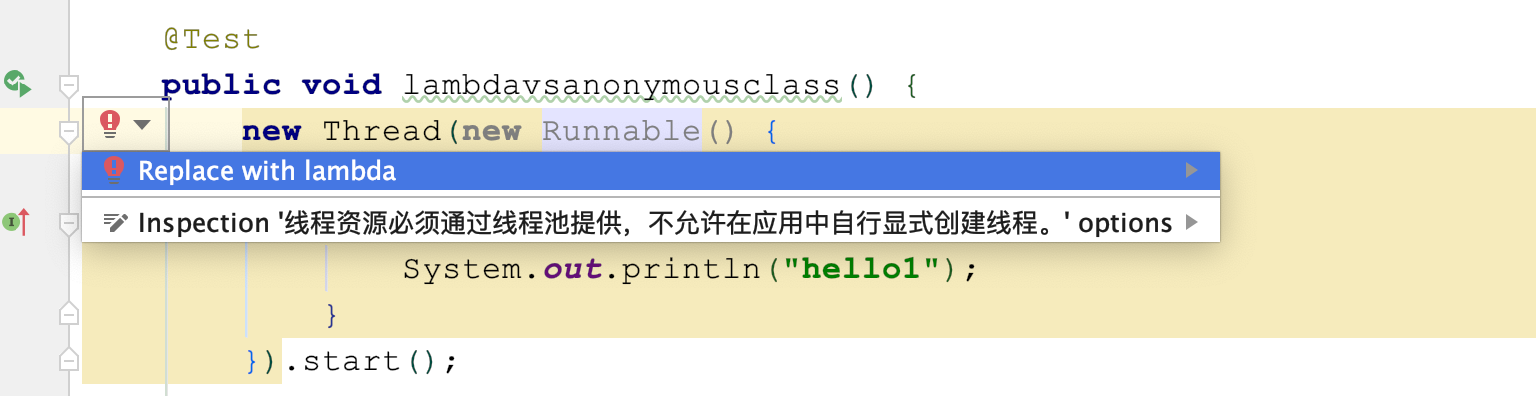
反过来,如果你在学习课程内案例时,如果感觉阅读Lambda表达式和Stream API比较吃力,同样可以借助IDE把Java 8的写法转换为使用循环的写法:

或者是把Lambda表达式替换为匿名类:

Lambda表达式
Lambda表达式的初衷是,进一步简化匿名类的语法(不过实现上,Lambda表达式并不是匿名类的语法糖),使Java走向函数式编程。对于匿名类,虽然没有类名,但还是要给出方法定义。这里有个例子,分别使用匿名类和Lambda表达式创建一个线程打印字符串:
//匿名类
new Thread(new Runnable(){
@Override
public void run(){
System.out.println("hello1");
}
}).start();
//Lambda表达式
new Thread(() -> System.out.println("hello2")).start();
那么,Lambda表达式如何匹配Java的类型系统呢?
答案就是,函数式接口。
函数式接口是一种只有单一抽象方法的接口,使用@FunctionalInterface来描述,可以隐式地转换成 Lambda 表达式。使用Lambda表达式来实现函数式接口,不需要提供类名和方法定义,通过一行代码提供函数式接口的实例,就可以让函数成为程序中的头等公民,可以像普通数据一样作为参数传递,而不是作为一个固定的类中的固定方法。
那,函数式接口到底是什么样的呢?java.util.function包中定义了各种函数式接口。比如,用于提供数据的Supplier接口,就只有一个get抽象方法,没有任何入参、有一个返回值:
@FunctionalInterface
public interface Supplier<T> {
/**
* Gets a result.
*
* @return a result
*/
T get();
}
我们可以使用Lambda表达式或方法引用,来得到Supplier接口的实例:
//使用Lambda表达式提供Supplier接口实现,返回OK字符串
Supplier<String> stringSupplier = ()->"OK";
//使用方法引用提供Supplier接口实现,返回空字符串
Supplier<String> supplier = String::new;
这样,是不是很方便?为了帮你掌握函数式接口及其用法,我再举几个使用Lambda表达式或方法引用来构建函数的例子:
//Predicate接口是输入一个参数,返回布尔值。我们通过and方法组合两个Predicate条件,判断是否值大于0并且是偶数
Predicate<Integer> positiveNumber = i -> i > 0;
Predicate<Integer> evenNumber = i -> i % 2 == 0;
assertTrue(positiveNumber.and(evenNumber).test(2));
//Consumer接口是消费一个数据。我们通过andThen方法组合调用两个Consumer,输出两行abcdefg
Consumer<String> println = System.out::println;
println.andThen(println).accept("abcdefg");
//Function接口是输入一个数据,计算后输出一个数据。我们先把字符串转换为大写,然后通过andThen组合另一个Function实现字符串拼接
Function<String, String> upperCase = String::toUpperCase;
Function<String, String> duplicate = s -> s.concat(s);
assertThat(upperCase.andThen(duplicate).apply("test"), is("TESTTEST"));
//Supplier是提供一个数据的接口。这里我们实现获取一个随机数
Supplier<Integer> random = ()->ThreadLocalRandom.current().nextInt();
System.out.println(random.get());
//BinaryOperator是输入两个同类型参数,输出一个同类型参数的接口。这里我们通过方法引用获得一个整数加法操作,通过Lambda表达式定义一个减法操作,然后依次调用
BinaryOperator<Integer> add = Integer::sum;
BinaryOperator<Integer> subtraction = (a, b) -> a - b;
assertThat(subtraction.apply(add.apply(1, 2), 3), is(0));
Predicate、Function等函数式接口,还使用default关键字实现了几个默认方法。这样一来,它们既可以满足函数式接口只有一个抽象方法,又能为接口提供额外的功能:
@FunctionalInterface
public interface Function<T, R> {
R apply(T t);
default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
}
很明显,Lambda表达式给了我们复用代码的更多可能性:我们可以把一大段逻辑中变化的部分抽象出函数式接口,由外部方法提供函数实现,重用方法内的整体逻辑处理。
不过需要注意的是,在自定义函数式接口之前,可以先确认下java.util.function包中的43个标准函数式接口是否能满足需求,我们要尽可能重用这些接口,因为使用大家熟悉的标准接口可以提高代码的可读性。
使用Java 8简化代码
这一部分,我会通过几个具体的例子,带你感受一下使用Java 8简化代码的三个重要方面:
- 使用Stream简化集合操作;
- 使用Optional简化判空逻辑;
- JDK8结合Lambda和Stream对各种类的增强。
使用Stream简化集合操作
Lambda表达式可以帮我们用简短的代码实现方法的定义,给了我们复用代码的更多可能性。利用这个特性,我们可以把集合的投影、转换、过滤等操作抽象成通用的接口,然后通过Lambda表达式传入其具体实现,这也就是Stream操作。
我们看一个具体的例子。这里有一段20行左右的代码,实现了如下的逻辑:
- 把整数列表转换为Point2D列表;
- 遍历Point2D列表过滤出Y轴>1的对象;
- 计算Point2D点到原点的距离;
- 累加所有计算出的距离,并计算距离的平均值。
private static double calc(List<Integer> ints) {
//临时中间集合
List<Point2D> point2DList = new ArrayList<>();
for (Integer i : ints) {
point2DList.add(new Point2D.Double((double) i % 3, (double) i / 3));
}
//临时变量,纯粹是为了获得最后结果需要的中间变量
double total = 0;
int count = 0;
for (Point2D point2D : point2DList) {
//过滤
if (point2D.getY() > 1) {
//算距离
double distance = point2D.distance(0, 0);
total += distance;
count++;
}
}
//注意count可能为0的可能
return count >0 ? total / count : 0;
}
现在,我们可以使用Stream配合Lambda表达式来简化这段代码。简化后一行代码就可以实现这样的逻辑,更重要的是代码可读性更强了,通过方法名就可以知晓大概是在做什么事情。比如:
- map方法传入的是一个Function,可以实现对象转换;
- filter方法传入一个Predicate,实现对象的布尔判断,只保留返回true的数据;
- mapToDouble用于把对象转换为double;
- 通过average方法返回一个OptionalDouble,代表可能包含值也可能不包含值的可空double。
下面的第三行代码,就实现了上面方法的所有工作:
List<Integer> ints = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8);
double average = calc(ints);
double streamResult = ints.stream()
.map(i -> new Point2D.Double((double) i % 3, (double) i / 3))
.filter(point -> point.getY() > 1)
.mapToDouble(point -> point.distance(0, 0))
.average()
.orElse(0);
//如何用一行代码来实现,比较一下可读性
assertThat(average, is(streamResult));
到这里,你可能会问了,OptionalDouble又是怎么回事儿?
有关Optional可空类型
其实,类似OptionalDouble、OptionalInt、OptionalLong等,是服务于基本类型的可空对象。此外,Java8还定义了用于引用类型的Optional类。使用Optional,不仅可以避免使用Stream进行级联调用的空指针问题;更重要的是,它提供了一些实用的方法帮我们避免判空逻辑。
如下是一些例子,演示了如何使用Optional来避免空指针,以及如何使用它的fluent API简化冗长的if-else判空逻辑:
@Test(expected = IllegalArgumentException.class)
public void optional() {
//通过get方法获取Optional中的实际值
assertThat(Optional.of(1).get(), is(1));
//通过ofNullable来初始化一个null,通过orElse方法实现Optional中无数据的时候返回一个默认值
assertThat(Optional.ofNullable(null).orElse("A"), is("A"));
//OptionalDouble是基本类型double的Optional对象,isPresent判断有无数据
assertFalse(OptionalDouble.empty().isPresent());
//通过map方法可以对Optional对象进行级联转换,不会出现空指针,转换后还是一个Optional
assertThat(Optional.of(1).map(Math::incrementExact).get(), is(2));
//通过filter实现Optional中数据的过滤,得到一个Optional,然后级联使用orElse提供默认值
assertThat(Optional.of(1).filter(integer -> integer % 2 == 0).orElse(null), is(nullValue()));
//通过orElseThrow实现无数据时抛出异常
Optional.empty().orElseThrow(IllegalArgumentException::new);
}
我把Optional类的常用方法整理成了一张图,你可以对照案例再复习一下:

Java 8类对于函数式API的增强
除了Stream之外,Java 8中有很多类也都实现了函数式的功能。
比如,要通过HashMap实现一个缓存的操作,在Java 8之前我们可能会写出这样的getProductAndCache方法:先判断缓存中是否有值;如果没有值,就从数据库搜索取值;最后,把数据加入缓存。
private Map<Long, Product> cache = new ConcurrentHashMap<>();
private Product getProductAndCache(Long id) {
Product product = null;
//Key存在,返回Value
if (cache.containsKey(id)) {
product = cache.get(id);
} else {
//不存在,则获取Value
//需要遍历数据源查询获得Product
for (Product p : Product.getData()) {
if (p.getId().equals(id)) {
product = p;
break;
}
}
//加入ConcurrentHashMap
if (product != null)
cache.put(id, product);
}
return product;
}
@Test
public void notcoolCache() {
getProductAndCache(1L);
getProductAndCache(100L);
System.out.println(cache);
assertThat(cache.size(), is(1));
assertTrue(cache.containsKey(1L));
}
而在Java 8中,我们利用ConcurrentHashMap的computeIfAbsent方法,用一行代码就可以实现这样的繁琐操作:
private Product getProductAndCacheCool(Long id) {
return cache.computeIfAbsent(id, i -> //当Key不存在的时候提供一个Function来代表根据Key获取Value的过程
Product.getData().stream()
.filter(p -> p.getId().equals(i)) //过滤
.findFirst() //找第一个,得到Optional<Product>
.orElse(null)); //如果找不到Product,则使用null
}
@Test
public void coolCache()
{
getProductAndCacheCool(1L);
getProductAndCacheCool(100L);
System.out.println(cache);
assertThat(cache.size(), is(1));
assertTrue(cache.containsKey(1L));
}
computeIfAbsent方法在逻辑上相当于:
if (map.get(key) == null) {
V newValue = mappingFunction.apply(key);
if (newValue != null)
map.put(key, newValue);
}
又比如,利用Files.walk返回一个Path的流,通过两行代码就能实现递归搜索+grep的操作。整个逻辑是:递归搜索文件夹,查找所有的.java文件;然后读取文件每一行内容,用正则表达式匹配public class关键字;最后输出文件名和这行内容。
@Test
public void filesExample() throws IOException {
//无限深度,递归遍历文件夹
try (Stream<Path> pathStream = Files.walk(Paths.get("."))) {
pathStream.filter(Files::isRegularFile) //只查普通文件
.filter(FileSystems.getDefault().getPathMatcher("glob:**/*.java")::matches) //搜索java源码文件
.flatMap(ThrowingFunction.unchecked(path ->
Files.readAllLines(path).stream() //读取文件内容,转换为Stream<List>
.filter(line -> Pattern.compile("public class").matcher(line).find()) //使用正则过滤带有public class的行
.map(line -> path.getFileName() + " >> " + line))) //把这行文件内容转换为文件名+行
.forEach(System.out::println); //打印所有的行
}
}
输出结果如下:

我再和你分享一个小技巧吧。因为Files.readAllLines方法会抛出一个受检异常(IOException),所以我使用了一个自定义的函数式接口,用ThrowingFunction包装这个方法,把受检异常转换为运行时异常,让代码更清晰:
@FunctionalInterface
public interface ThrowingFunction<T, R, E extends Throwable> {
static <T, R, E extends Throwable> Function<T, R> unchecked(ThrowingFunction<T, R, E> f) {
return t -> {
try {
return f.apply(t);
} catch (Throwable e) {
throw new RuntimeException(e);
}
};
}
R apply(T t) throws E;
}
如果用Java 7实现类似逻辑的话,大概需要几十行代码,你可以尝试下。
并行流
前面我们看到的Stream操作都是串行Stream,操作只是在一个线程中执行,此外Java 8还提供了并行流的功能:通过parallel方法,一键把Stream转换为并行操作提交到线程池处理。
比如,如下代码通过线程池来并行消费处理1到100:
IntStream.rangeClosed(1,100).parallel().forEach(i->{
System.out.println(LocalDateTime.now() + " : " + i);
try {
Thread.sleep(1000);
} catch (InterruptedException e) { }
});
并行流不确保执行顺序,并且因为每次处理耗时1秒,所以可以看到在8核机器上,数组是按照8个一组1秒输出一次:

在这个课程中,有很多类似使用threadCount个线程对某个方法总计执行taskCount次操作的案例,用于演示并发情况下的多线程问题或多线程处理性能。除了会用到并行流,我们有时也会使用线程池或直接使用线程进行类似操作。为了方便你对比各种实现,这里我一次性给出实现此类操作的五种方式。
为了测试这五种实现方式,我们设计一个场景:使用20个线程(threadCount)以并行方式总计执行10000次(taskCount)操作。因为单个任务单线程执行需要10毫秒(任务代码如下),也就是每秒吞吐量是100个操作,那20个线程QPS是2000,执行完10000次操作最少耗时5秒。
private void increment(AtomicInteger atomicInteger) {
atomicInteger.incrementAndGet();
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
现在我们测试一下这五种方式,是否都可以利用更多的线程并行执行操作。
第一种方式是使用线程。直接把任务按照线程数均匀分割,分配到不同的线程执行,使用CountDownLatch来阻塞主线程,直到所有线程都完成操作。这种方式,需要我们自己分割任务:
private int thread(int taskCount, int threadCount) throws InterruptedException {
//总操作次数计数器
AtomicInteger atomicInteger = new AtomicInteger();
//使用CountDownLatch来等待所有线程执行完成
CountDownLatch countDownLatch = new CountDownLatch(threadCount);
//使用IntStream把数字直接转为Thread
IntStream.rangeClosed(1, threadCount).mapToObj(i -> new Thread(() -> {
//手动把taskCount分成taskCount份,每一份有一个线程执行
IntStream.rangeClosed(1, taskCount / threadCount).forEach(j -> increment(atomicInteger));
//每一个线程处理完成自己那部分数据之后,countDown一次
countDownLatch.countDown();
})).forEach(Thread::start);
//等到所有线程执行完成
countDownLatch.await();
//查询计数器当前值
return atomicInteger.get();
}
第二种方式是,使用Executors.newFixedThreadPool来获得固定线程数的线程池,使用execute提交所有任务到线程池执行,最后关闭线程池等待所有任务执行完成:
private int threadpool(int taskCount, int threadCount) throws InterruptedException {
//总操作次数计数器
AtomicInteger atomicInteger = new AtomicInteger();
//初始化一个线程数量=threadCount的线程池
ExecutorService executorService = Executors.newFixedThreadPool(threadCount);
//所有任务直接提交到线程池处理
IntStream.rangeClosed(1, taskCount).forEach(i -> executorService.execute(() -> increment(atomicInteger)));
//提交关闭线程池申请,等待之前所有任务执行完成
executorService.shutdown();
executorService.awaitTermination(1, TimeUnit.HOURS);
//查询计数器当前值
return atomicInteger.get();
}
第三种方式是,使用ForkJoinPool而不是普通线程池执行任务。
ForkJoinPool和传统的ThreadPoolExecutor区别在于,前者对于n并行度有n个独立队列,后者是共享队列。如果有大量执行耗时比较短的任务,ThreadPoolExecutor的单队列就可能会成为瓶颈。这时,使用ForkJoinPool性能会更好。
因此,ForkJoinPool更适合大任务分割成许多小任务并行执行的场景,而ThreadPoolExecutor适合许多独立任务并发执行的场景。
在这里,我们先自定义一个具有指定并行数的ForkJoinPool,再通过这个ForkJoinPool并行执行操作:
private int forkjoin(int taskCount, int threadCount) throws InterruptedException {
//总操作次数计数器
AtomicInteger atomicInteger = new AtomicInteger();
//自定义一个并行度=threadCount的ForkJoinPool
ForkJoinPool forkJoinPool = new ForkJoinPool(threadCount);
//所有任务直接提交到线程池处理
forkJoinPool.execute(() -> IntStream.rangeClosed(1, taskCount).parallel().forEach(i -> increment(atomicInteger)));
//提交关闭线程池申请,等待之前所有任务执行完成
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
//查询计数器当前值
return atomicInteger.get();
}
第四种方式是,直接使用并行流,并行流使用公共的ForkJoinPool,也就是ForkJoinPool.commonPool()。
公共的ForkJoinPool默认的并行度是CPU核心数-1,原因是对于CPU绑定的任务分配超过CPU个数的线程没有意义。由于并行流还会使用主线程执行任务,也会占用一个CPU核心,所以公共ForkJoinPool的并行度即使-1也能用满所有CPU核心。
这里,我们通过配置强制指定(增大)了并行数,但因为使用的是公共ForkJoinPool,所以可能会存在干扰,你可以回顾下第3讲有关线程池混用产生的问题:
private int stream(int taskCount, int threadCount) {
//设置公共ForkJoinPool的并行度
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", String.valueOf(threadCount));
//总操作次数计数器
AtomicInteger atomicInteger = new AtomicInteger();
//由于我们设置了公共ForkJoinPool的并行度,直接使用parallel提交任务即可
IntStream.rangeClosed(1, taskCount).parallel().forEach(i -> increment(atomicInteger));
//查询计数器当前值
return atomicInteger.get();
}
第五种方式是,使用CompletableFuture来实现。CompletableFuture.runAsync方法可以指定一个线程池,一般会在使用CompletableFuture的时候用到:
private int completableFuture(int taskCount, int threadCount) throws InterruptedException, ExecutionException {
//总操作次数计数器
AtomicInteger atomicInteger = new AtomicInteger();
//自定义一个并行度=threadCount的ForkJoinPool
ForkJoinPool forkJoinPool = new ForkJoinPool(threadCount);
//使用CompletableFuture.runAsync通过指定线程池异步执行任务
CompletableFuture.runAsync(() -> IntStream.rangeClosed(1, taskCount).parallel().forEach(i -> increment(atomicInteger)), forkJoinPool).get();
//查询计数器当前值
return atomicInteger.get();
}
上面这五种方法都可以实现类似的效果:

可以看到,这5种方式执行完10000个任务的耗时都在5.4秒到6秒之间。这里的结果只是证明并行度的设置是有效的,并不是性能比较。
如果你的程序对性能要求特别敏感,建议通过性能测试根据场景决定适合的模式。一般而言,使用线程池(第二种)和直接使用并行流(第四种)的方式在业务代码中比较常用。但需要注意的是,我们通常会重用线程池,而不会像Demo中那样在业务逻辑中直接声明新的线程池,等操作完成后再关闭。
另外需要注意的是,在上面的例子中我们一定是先运行stream方法再运行forkjoin方法,对公共ForkJoinPool默认并行度的修改才能生效。
这是因为ForkJoinPool类初始化公共线程池是在静态代码块里,加载类时就会进行的,如果forkjoin方法中先使用了ForkJoinPool,即便stream方法中设置了系统属性也不会起作用。因此我的建议是,设置ForkJoinPool公共线程池默认并行度的操作,应该放在应用启动时设置。
重点回顾
今天,我和你简单介绍了Java 8中最重要的几个功能,包括Lambda表达式、Stream流式操作、Optional可空对象、并行流操作。这些特性,可以帮助我们写出简单易懂、可读性更强的代码。特别是使用Stream的链式方法,可以用一行代码完成之前几十行代码的工作。
因为Stream的API非常多,使用方法也是千变万化,因此我会在下一讲和你详细介绍Stream API的一些使用细节。
今天用到的代码,我都放在了GitHub上,你可以点击这个链接查看。
思考与讨论
- 检查下代码中是否有使用匿名类,以及通过遍历List进行数据过滤、转换和聚合的代码,看看能否使用Lambda表达式和Stream来重新实现呢?
- 对于并行流部分的并行消费处理1到100的例子,如果把forEach替换为forEachOrdered,你觉得会发生什么呢?
关于Java 8,你还有什么使用心得吗?我是朱晔,欢迎在评论区与我留言分享你的想法,也欢迎你把这篇文章分享给你的朋友或同事,一起交流。
- 小阳 👍(10) 💬(1)
疑问: 代码3 的执行代码 ,forkJoinPool.execute(() -> IntStream.rangeClosed(1, taskCount).parallel().forEach(i -> increment(atomicInteger))); 我的理解是 通过自定义的forkJoinPool来将并行任务提交到公共的forkJoinPool去执行,因为 paraller().forEach()执行过程中并没提供像代码5那样设置用户的forkJoinPool,您说是在自定义的forkJoinPool执行increment(atomicInteger)的,这是为什么呢?
2020-03-18 - Darren 👍(19) 💬(3)
疑问:匿名内部类和Lambda到底有什么区别?为什么匿名内部类会生成$1这样的class文件而Lambda并没有??? 回答下问题: 1.项目中现在基本都是在使用Lambda表达式,主要是因为使用的vert.x和RxJava2,响应式变成基本都是Lambda; 2.并行效果消失,和去掉parallel()的效果是一样的,因为forEachOrdered将按照其源指定的顺序处理流的元素,而不管流是连续的还是并行的。 JavaDoc: forEach:The behavior of this operation is explicitly nondeterministic. For parallel stream pipelines, this operation does not guarantee to respect the encounter order of the stream, as doing so would sacrifice the benefit of parallelism. -------谷歌翻译------ 此操作的行为明确地是不确定的。 对于并行流管道,此操作不能保证尊重流的遇到顺序,因为这样做会牺牲并行性的好处。 对于任何给定的元素,可以在库选择的任何时间和线程中执行操作。 如果操作访问共享状态,则它负责提供所需的同步。 forEachOrdered :Performs an action for each element of this stream, in the encounter order of the stream if the stream has a defined encounter order. -------谷歌翻译----- 如果流具有定义的遇到顺序,则按流的遇到顺序对此流的每个元素执行操作。
2020-03-17 - 👽 👍(2) 💬(1)
检查下代码中是否有使用匿名类,以及通过遍历 List 进行数据过滤、转换和聚合的代码,看看能否使用 Lambda 表达式和 Stream 来重新实现呢? 已经使用lambda,stream快一年了,匿名类,基本就通过idea的自动处理,自己使用的基本上就:forEach,filter,map,这些。 对于并行流部分的并行消费处理 1 到 100 的例子,如果把 forEach 替换为 forEachOrdered,你觉得会发生什么呢? 个人猜测是会被有序化地多线程执行,四核CPU,1234 等一秒5678 这样。 但是,实际上,并发能力被直接移除。1等一秒,2等一秒,3......这样。不严谨的猜测,forEachOrdered 将本来的打印加上了类似于synchronized的效果。
2020-03-17 - 退而结网 👍(16) 💬(1)
这个课程未免也太划算了,这个加餐囊括了好多其他的内容,物超所值,为老师点赞!打call
2020-03-18 - 刘大明 👍(12) 💬(6)
想问下老师,既然Lambda 表达式这么简洁,方便,但是我们项目经理要我们在项目中不要使用他,说是不好调试.......这个是理由吗?
2020-03-17 - 杰哥长得帅 👍(3) 💬(1)
想问一下大佬,把受检异常转换为运行时异常,有什么作用呢
2020-03-28 - 大头 👍(3) 💬(1)
从传递对象,到传递匿名内部类,再到lambda表达式的演化,去掉了重复的代码,仅保留有意义的代码,越来越简洁明了了
2020-03-18 - mgs2002 👍(3) 💬(1)
forEachOrdered 保证元素按顺序执行,我测试了代码的例子,发现去掉parallel后执行时间跟forEach差不多,加上后执行时间快了一倍多,结论是forEachOrdered并没有使parallel并行化效果完全消失,是这样的吗,也尝试看了一下源码,有点蒙。。 以下是我的测试结果 246810421086246810StopWatch '': running time = 23068739988 ns --------------------------------------------- ns % Task name --------------------------------------------- 15051360863 065% stream 2010090132 009% parallelStream 6007288993 026% parallelStreamForEachOrdered
2020-03-17 - 陈天柱 👍(3) 💬(1)
我实际开发的时候,最喜欢用的lambda表达式就是将一个集合对象转换成由该对象的指定字段值组成的集合,以前只会用,看了老师的文章以后才意识到学东西还是需要系统! 关于第二个思考题,尝试去阅读了一下源码,发现完全懵逼了,所以直接用idea跑了一下代码发现并行流forEachOrderd的效果直接是串行化了,虽然使用了并行流,但需要让任务有序化,让我想起了RocketMq里的顺序消息。
2020-03-17 - 👽 👍(3) 💬(1)
java8的Lambda,给程序员提供了极大的便利性,和大幅度简化代码的可能性。单纯使用的话,学习成本并不高。常用的主流的操作也就那么几个。 但是要自行定义,并灵活变通使用,还是需要花些功夫去学习练习的。
2020-03-17 - jjn0703 👍(2) 💬(1)
Java8实战是出第二版了吗?
2020-03-17 - 大京 👍(1) 💬(1)
小白问题,往flatMap(ThrowingFunction.unchecked里传的参数function怎么就当做ThrowingFunction了呢
2020-04-11 - sky 👍(1) 💬(1)
老师,idea设置没按lambda语法报错的地方在哪,没找到
2020-04-06 - Geek_3b1096 👍(1) 💬(1)
满满干货
2020-03-19 - 汝林外史 👍(1) 💬(1)
大佬厉害! IntStream.rangeClosed(1, taskCount).parallel().forEach(i -> increment(atomicInteger)); 上面的代码3、4、5三种方法中完全相同,只不过是自己调用和放进线程池调用的区别,既然4都能自己用了,还要3、5干啥呢?
2020-03-17