13 多线程之锁优化(中):深入了解Lock同步锁的优化方法
你好,我是刘超。
今天这讲我们继续来聊聊锁优化。上一讲我重点介绍了在JVM层实现的Synchronized同步锁的优化方法,除此之外,在JDK1.5之后,Java还提供了Lock同步锁。那么它有什么优势呢?
相对于需要JVM隐式获取和释放锁的Synchronized同步锁,Lock同步锁(以下简称Lock锁)需要的是显示获取和释放锁,这就为获取和释放锁提供了更多的灵活性。Lock锁的基本操作是通过乐观锁来实现的,但由于Lock锁也会在阻塞时被挂起,因此它依然属于悲观锁。我们可以通过一张图来简单对比下两个同步锁,了解下各自的特点:

从性能方面上来说,在并发量不高、竞争不激烈的情况下,Synchronized同步锁由于具有分级锁的优势,性能上与Lock锁差不多;但在高负载、高并发的情况下,Synchronized同步锁由于竞争激烈会升级到重量级锁,性能则没有Lock锁稳定。
我们可以通过一组简单的性能测试,直观地对比下两种锁的性能,结果见下方,代码可以在Github上下载查看。

通过以上数据,我们可以发现:Lock锁的性能相对来说更加稳定。那它与上一讲的Synchronized同步锁相比,实现原理又是怎样的呢?
Lock锁的实现原理
Lock锁是基于Java实现的锁,Lock是一个接口类,常用的实现类有ReentrantLock、ReentrantReadWriteLock(RRW),它们都是依赖AbstractQueuedSynchronizer(AQS)类实现的。
AQS类结构中包含一个基于链表实现的等待队列(CLH队列),用于存储所有阻塞的线程,AQS中还有一个state变量,该变量对ReentrantLock来说表示加锁状态。
该队列的操作均通过CAS操作实现,我们可以通过一张图来看下整个获取锁的流程。
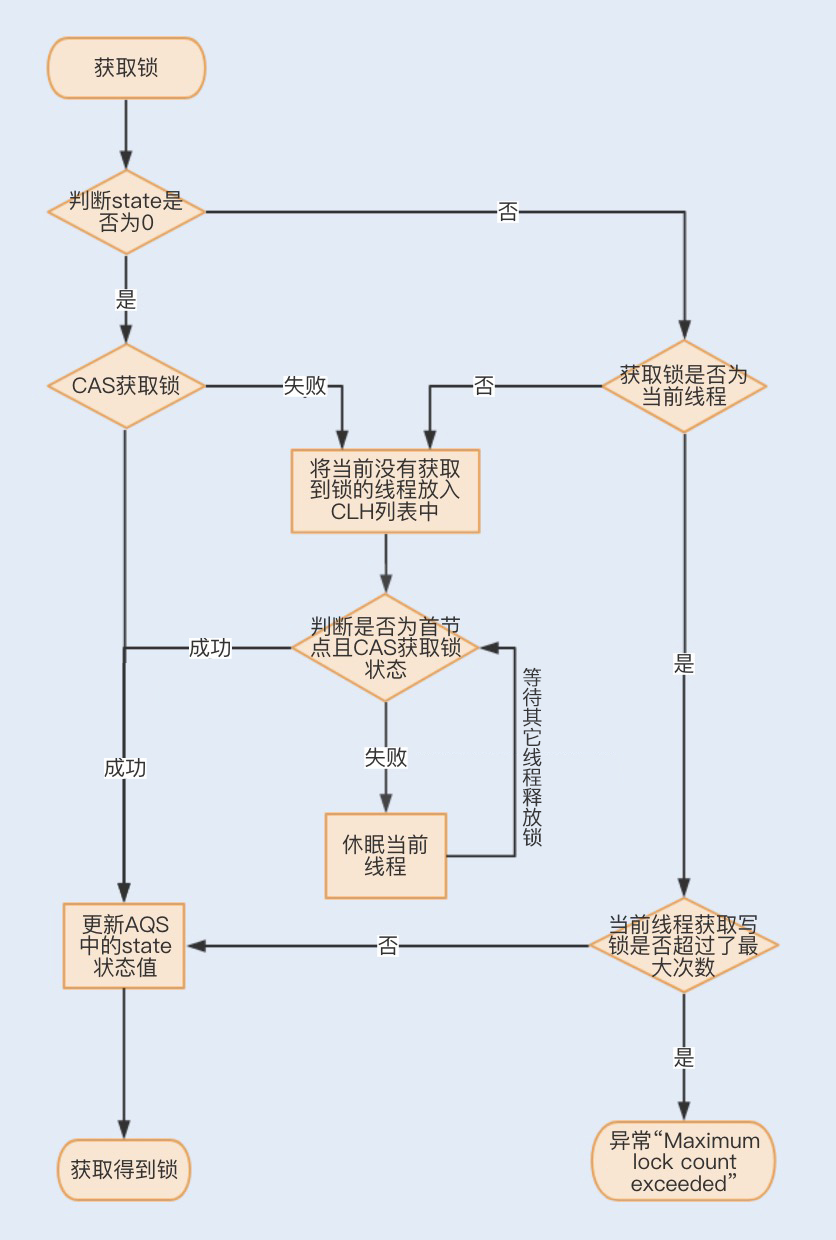
锁分离优化Lock同步锁
虽然Lock锁的性能稳定,但也并不是所有的场景下都默认使用ReentrantLock独占锁来实现线程同步。
我们知道,对于同一份数据进行读写,如果一个线程在读数据,而另一个线程在写数据,那么读到的数据和最终的数据就会不一致;如果一个线程在写数据,而另一个线程也在写数据,那么线程前后看到的数据也会不一致。这个时候我们可以在读写方法中加入互斥锁,来保证任何时候只能有一个线程进行读或写操作。
在大部分业务场景中,读业务操作要远远大于写业务操作。而在多线程编程中,读操作并不会修改共享资源的数据,如果多个线程仅仅是读取共享资源,那么这种情况下其实没有必要对资源进行加锁。如果使用互斥锁,反倒会影响业务的并发性能,那么在这种场景下,有没有什么办法可以优化下锁的实现方式呢?
1.读写锁ReentrantReadWriteLock
针对这种读多写少的场景,Java提供了另外一个实现Lock接口的读写锁RRW。我们已知ReentrantLock是一个独占锁,同一时间只允许一个线程访问,而RRW允许多个读线程同时访问,但不允许写线程和读线程、写线程和写线程同时访问。读写锁内部维护了两个锁,一个是用于读操作的ReadLock,一个是用于写操作的WriteLock。
那读写锁又是如何实现锁分离来保证共享资源的原子性呢?
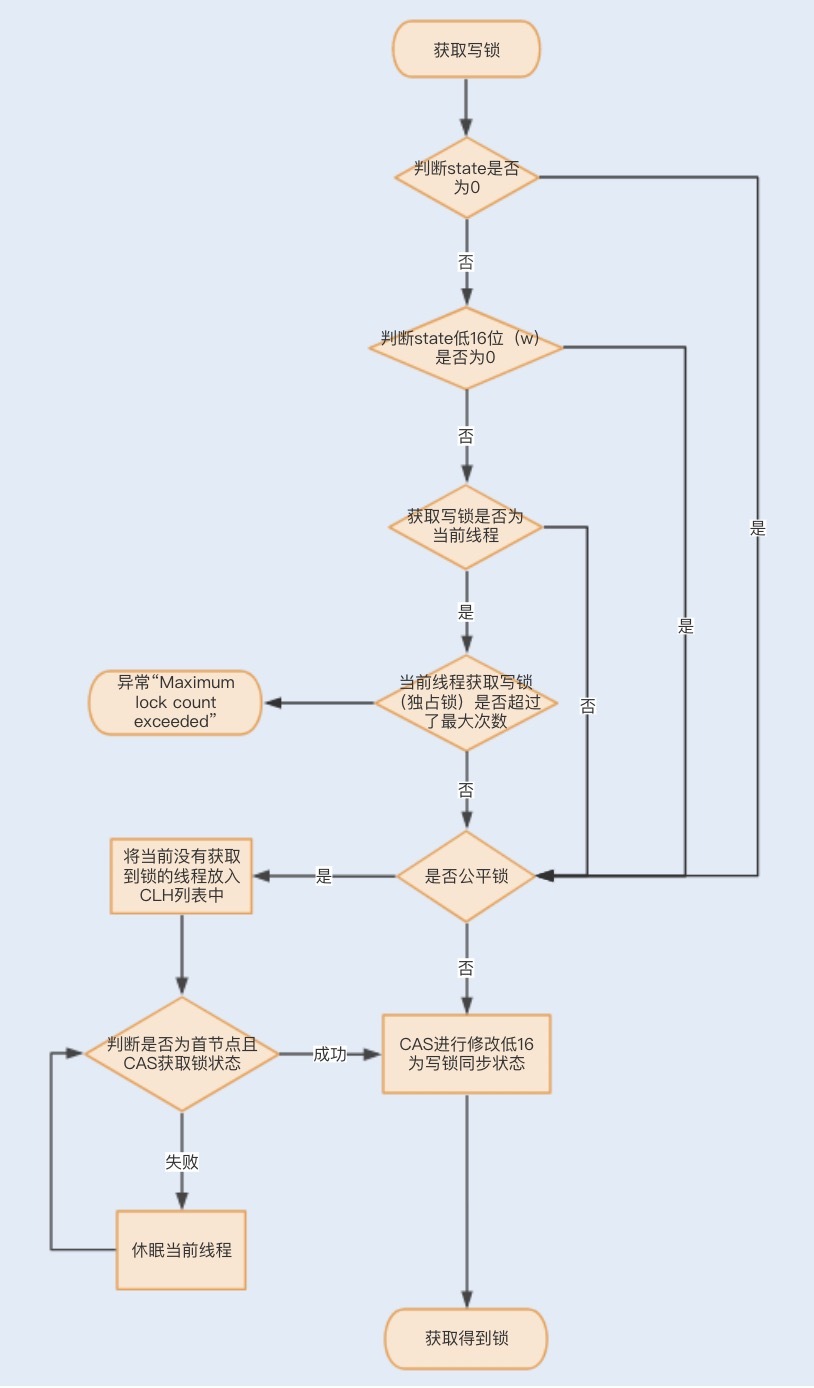
RRW也是基于AQS实现的,它的自定义同步器(继承AQS)需要在同步状态state上维护多个读线程和一个写线程的状态,该状态的设计成为实现读写锁的关键。RRW很好地使用了高低位,来实现一个整型控制两种状态的功能,读写锁将变量切分成了两个部分,高16位表示读,低16位表示写。
一个线程尝试获取写锁时,会先判断同步状态state是否为0。如果state等于0,说明暂时没有其它线程获取锁;如果state不等于0,则说明有其它线程获取了锁。
此时再判断同步状态state的低16位(w)是否为0,如果w为0,则说明其它线程获取了读锁,此时进入CLH队列进行阻塞等待;如果w不为0,则说明其它线程获取了写锁,此时要判断获取了写锁的是不是当前线程,若不是就进入CLH队列进行阻塞等待;若是,就应该判断当前线程获取写锁是否超过了最大次数,若超过,抛异常,反之更新同步状态。
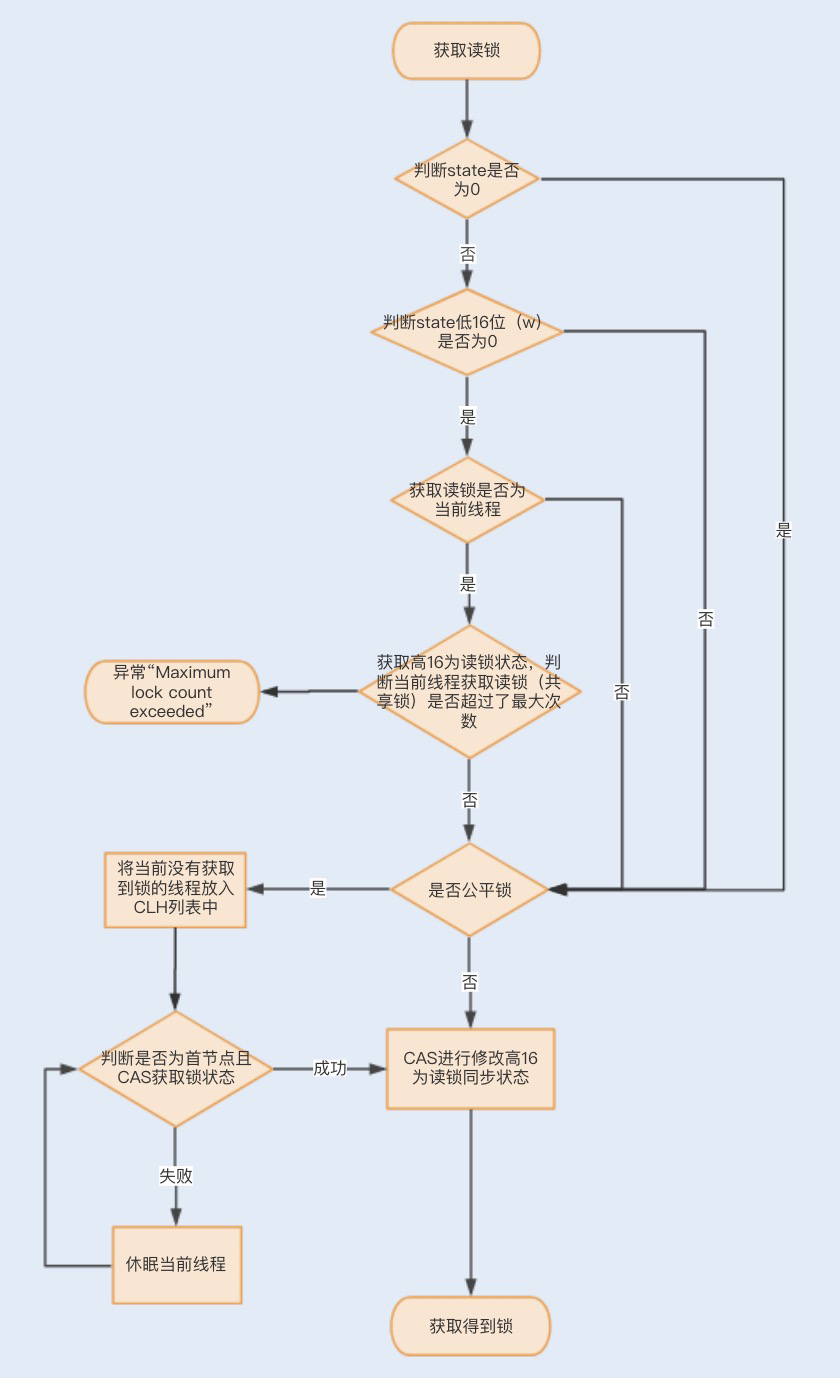
一个线程尝试获取读锁时,同样会先判断同步状态state是否为0。如果state等于0,说明暂时没有其它线程获取锁,此时判断是否需要阻塞,如果需要阻塞,则进入CLH队列进行阻塞等待;如果不需要阻塞,则CAS更新同步状态为读状态。
如果state不等于0,会判断同步状态低16位,如果存在写锁,则获取读锁失败,进入CLH阻塞队列;反之,判断当前线程是否应该被阻塞,如果不应该阻塞则尝试CAS同步状态,获取成功更新同步锁为读状态。
下面我们通过一个求平方的例子,来感受下RRW的实现,代码如下:
public class TestRTTLock {
private double x, y;
private ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
// 读锁
private Lock readLock = lock.readLock();
// 写锁
private Lock writeLock = lock.writeLock();
public double read() {
//获取读锁
readLock.lock();
try {
return Math.sqrt(x * x + y * y);
} finally {
//释放读锁
readLock.unlock();
}
}
public void move(double deltaX, double deltaY) {
//获取写锁
writeLock.lock();
try {
x += deltaX;
y += deltaY;
} finally {
//释放写锁
writeLock.unlock();
}
}
}
2.读写锁再优化之StampedLock
RRW被很好地应用在了读大于写的并发场景中,然而RRW在性能上还有可提升的空间。在读取很多、写入很少的情况下,RRW会使写入线程遭遇饥饿(Starvation)问题,也就是说写入线程会因迟迟无法竞争到锁而一直处于等待状态。
在JDK1.8中,Java提供了StampedLock类解决了这个问题。StampedLock不是基于AQS实现的,但实现的原理和AQS是一样的,都是基于队列和锁状态实现的。与RRW不一样的是,StampedLock控制锁有三种模式: 写、悲观读以及乐观读,并且StampedLock在获取锁时会返回一个票据stamp,获取的stamp除了在释放锁时需要校验,在乐观读模式下,stamp还会作为读取共享资源后的二次校验,后面我会讲解stamp的工作原理。
我们先通过一个官方的例子来了解下StampedLock是如何使用的,代码如下:
public class Point {
private double x, y;
private final StampedLock s1 = new StampedLock();
void move(double deltaX, double deltaY) {
//获取写锁
long stamp = s1.writeLock();
try {
x += deltaX;
y += deltaY;
} finally {
//释放写锁
s1.unlockWrite(stamp);
}
}
double distanceFormOrigin() {
//乐观读操作
long stamp = s1.tryOptimisticRead();
//拷贝变量
double currentX = x, currentY = y;
//判断读期间是否有写操作
if (!s1.validate(stamp)) {
//升级为悲观读
stamp = s1.readLock();
try {
currentX = x;
currentY = y;
} finally {
s1.unlockRead(stamp);
}
}
return Math.sqrt(currentX * currentX + currentY * currentY);
}
}
我们可以发现:一个写线程获取写锁的过程中,首先是通过WriteLock获取一个票据stamp,WriteLock是一个独占锁,同时只有一个线程可以获取该锁,当一个线程获取该锁后,其它请求的线程必须等待,当没有线程持有读锁或者写锁的时候才可以获取到该锁。请求该锁成功后会返回一个stamp票据变量,用来表示该锁的版本,当释放该锁的时候,需要unlockWrite并传递参数stamp。
接下来就是一个读线程获取锁的过程。首先线程会通过乐观锁tryOptimisticRead操作获取票据stamp ,如果当前没有线程持有写锁,则返回一个非0的stamp版本信息。线程获取该stamp后,将会拷贝一份共享资源到方法栈,在这之前具体的操作都是基于方法栈的拷贝数据。
之后方法还需要调用validate,验证之前调用tryOptimisticRead返回的stamp在当前是否有其它线程持有了写锁,如果是,那么validate会返回0,升级为悲观锁;否则就可以使用该stamp版本的锁对数据进行操作。
相比于RRW,StampedLock获取读锁只是使用与或操作进行检验,不涉及CAS操作,即使第一次乐观锁获取失败,也会马上升级至悲观锁,这样就可以避免一直进行CAS操作带来的CPU占用性能的问题,因此StampedLock的效率更高。
总结
不管使用Synchronized同步锁还是Lock同步锁,只要存在锁竞争就会产生线程阻塞,从而导致线程之间的频繁切换,最终增加性能消耗。因此,如何降低锁竞争,就成为了优化锁的关键。
在Synchronized同步锁中,我们了解了可以通过减小锁粒度、减少锁占用时间来降低锁的竞争。在这一讲中,我们知道可以利用Lock锁的灵活性,通过锁分离的方式来降低锁竞争。
Lock锁实现了读写锁分离来优化读大于写的场景,从普通的RRW实现到读锁和写锁,到StampedLock实现了乐观读锁、悲观读锁和写锁,都是为了降低锁的竞争,促使系统的并发性能达到最佳。
思考题
StampedLock同RRW一样,都适用于读大于写操作的场景,StampedLock青出于蓝结果却不好说,毕竟RRW还在被广泛应用,就说明它还有StampedLock无法替代的优势。你知道StampedLock没有被广泛应用的原因吗?或者说它还存在哪些缺陷导致没有被广泛应用。
期待在留言区看到你的见解。也欢迎你点击“请朋友读”,把今天的内容分享给身边的朋友,邀请他一起学习。

- Liam 👍(69) 💬(3)
StampLock不支持重入,不支持条件变量,线程被中断时可能导致CPU暴涨
2019-06-18 - 我知道了嗯 👍(24) 💬(2)
可重入锁是什么?另外什么场景下会使用到?
2019-06-20 - -W.LI- 👍(18) 💬(1)
老师好!读写锁那个流程图看不太明白,没有写线程的时候,判断不是当前线程在读就会进入CLF阻塞等待。 问题1:不是可以并发读的嘛?按这图读线程也要阻塞等待的意思么? 问题二:CLF阻塞队列里是读写线程公用的么?队列里,读写交替出现。那不就没法并发读了么?
2019-06-18 - 密码123456 👍(13) 💬(1)
为什么?因为锁不可重入?
2019-06-18 - 王圣军 👍(10) 💬(1)
老师这里说的公平锁和非公平锁让我想起两者是获取方式不同,非公平锁是首先就CAS来获取一次,成功就拿到锁,失败就放入队列;公平锁不会有这步操作,直接放入队列
2019-12-27 - 码农Kevin亮 👍(7) 💬(4)
请问老师,在读写锁的场景中,我在读操作时为什么还要加锁?直接读不就可以了?如果担心数据不刷新,那在变量加volatile是不是就可以满足?请解惑
2020-03-18 - 张三丰 👍(6) 💬(1)
获取读锁的流程图有问题吧,应该是判断写锁是否为当前线程,而不是判断读锁。
2020-04-10 - -W.LI- 👍(5) 💬(1)
StampedLock在写多读少的时候性能会很差吧
2019-06-18 - 你好旅行者 👍(4) 💬(1)
老师我有几个问题: 1.在ReentrantLock中,state这个变量,为0的时候表示当前的锁是没有被占用的。这个时候线程应该用CAS尝试修改state变量的值对锁进行抢占才对呀,为什么在您的图里当state=0的时候还需要判断是否为当前线程呢? 2.老师提到读写锁在读多写少的情况下会使得写线程遭遇饥饿问题,那我是不是只需要将锁设置为公平锁,这样先申请写锁的线程就可以先获得锁,从而避免饥饿问题呢? 3.StampedLock中引入了一个stamp版本对版本进行控制,那么对这个stamp变量进行写入的时候是否需要使用CAS操作?如果不是,那如何保证对stamp变量的读写是线程安全的呢? 谢谢老师!
2019-06-18 - 奋斗的小白鼠 👍(3) 💬(1)
老师,lock锁中的线程阻塞进行的上下文切换会设计系统内核态和用户态的转换吗?啥时候会引起系统内核态和用户态转换成啊?.io流编程中会出现吗
2019-11-28 - 欧星星 👍(3) 💬(1)
sync使用的是操作系统的Mutex Lock来实现的锁,Lock是使用线程等待来实现锁的,线程也会存在用户态内核态的切换,这样理解对吗?
2019-06-21 - 又双叒叕是一年啊 👍(2) 💬(1)
RRW 加写锁 和 读锁 都需要判断低16位? 这块写锁是不是应该判读的是高16位有没有读锁,从而判断有没有冲突?
2019-11-10 - 考休 👍(1) 💬(1)
老师,公平锁因为要维持一个线程执行的顺序,是不是性能相对非公平锁弱一些?
2019-11-08 - 钱 👍(1) 💬(1)
课后思考及问题 1:公平锁和非公平锁具体指什么?怎么体现? 2:锁的状态可中断和不可中断具体是指什么意思? 晚上加班状态可能不太好,感觉老师主要讲解了几种同步锁的实现原理,以及特点,如果能列个二维表就更好啦!
2019-09-09 - Jxin 👍(1) 💬(1)
我觉的票据本来就是读写锁升级版,性能绝逼是优于读写锁的。硬要说不如,不允许锁重入和阻塞时调用interrupt()有CPU彪高的bug算是存在的问题吧。前者,毕竟票据和读写都是用于读多写少的场景,所以互斥锁重入这块感觉量不大,没了倒也无伤大雅。而后者bug就是bug没得说。其实如果是写多读少的场景,隐式锁会比这些读写锁性能更好。重点还是根据具体的业务场景去选择。
2019-06-18