第33讲 后台服务出现明显“变慢”,谈谈你的诊断思路?
在日常工作中,应用或者系统出现性能问题往往是不可避免的,除了在有一定规模的IT企业或者专注于特定性能领域的企业,可能大多数工程师并不会成为专职的性能工程师,但是掌握基本的性能知识和技能,往往是日常工作的需要,并且也是工程师进阶的必要条件之一,能否定位和解决性能问题也是对你知识、技能和能力的检验。
今天我要问你的问题是,后台服务出现明显“变慢”,谈谈你的诊断思路?
典型回答
首先,需要对这个问题进行更加清晰的定义:
- 服务是突然变慢还是长时间运行后观察到变慢?类似问题是否重复出现?
- “慢”的定义是什么,我能够理解是系统对其他方面的请求的反应延时变长吗?
第二,理清问题的症状,这更便于定位具体的原因,有以下一些思路:
- 问题可能来自于Java服务自身,也可能仅仅是受系统里其他服务的影响。初始判断可以先确认是否出现了意外的程序错误,例如检查应用本身的错误日志。 对于分布式系统,很多公司都会实现更加系统的日志、性能等监控系统。一些Java诊断工具也可以用于这个诊断,例如通过JFR(Java Flight Recordera>),监控应用是否大量出现了某种类型的异常。 如果有,那么异常可能就是个突破点。 如果没有,可以先检查系统级别的资源等情况,监控CPU、内存等资源是否被其他进程大量占用,并且这种占用是否不符合系统正常运行状况。
自下而上。从类似CPU这种硬件底层,判断类似Cache-Miss之类的问题和调优机会,出发点是指令级别优化。这往往是专业的性能工程师才能掌握的技能,并且需要专业工具配合,大多数是移植到新的平台上,或需要提供极致性能时才会进行。
例如,将大数据应用移植到SPARC体系结构的硬件上,需要对比和尽量释放性能潜力,但又希望尽量不改源代码。
我所给出的回答,首先是试图排除功能性错误,然后就是典型的自上而下分析思路。
第二,我们一起来看看自上而下分析中,各个阶段的常见工具和思路。需要注意的是,具体的工具在不同的操作系统上可能区别非常大。
系统性能分析中,CPU、内存和IO是主要关注项。
对于CPU,如果是常见的Linux,可以先用top命令查看负载状况,下图是我截取的一个状态。
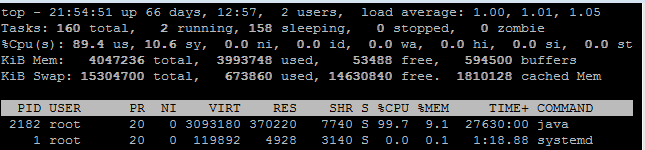
可以看到,其平均负载(load average)的三个值(分别是1分钟、5分钟、15分钟)非常低,并且暂时看并没有升高迹象。如果这些数值非常高(例如,超过50%、60%),并且短期平均值高于长期平均值,则表明负载很重;如果还有升高的趋势,那么就要非常警惕了。
进一步的排查有很多思路,例如,我在专栏第18讲曾经问过,怎么找到最耗费CPU的Java线程,简要介绍步骤:
- 利用top命令获取相应pid,“-H”代表thread模式,你可以配合grep命令更精准定位。
- 然后转换成为16进制。
- 最后利用jstack获取的线程栈,对比相应的ID即可。
当然,还有更加通用的诊断方向,利用vmstat之类,查看上下文切换的数量,比如下面就是指定时间间隔为1,收集10次。
输出如下:
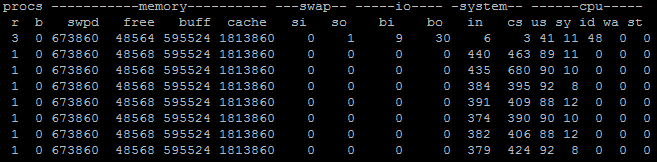
如果每秒上下文(cs,context switch)切换很高,并且比系统中断高很多(in,system interrupt),就表明很有可能是因为不合理的多线程调度所导致。当然还需要利用pidstat等手段,进行更加具体的定位,我就不再进一步展开了。
除了CPU,内存和IO是重要的注意事项,比如:
- 利用free之类查看内存使用。
- 或者,进一步判断swap使用情况,top命令输出中Virt作为虚拟内存使用量,就是物理内存(Res)和swap求和,所以可以反推swap使用。显然,JVM是不希望发生大量的swap使用的。
- 对于IO问题,既可能发生在磁盘IO,也可能是网络IO。例如,利用iostat等命令有助于判断磁盘的健康状况。我曾经帮助诊断过Java服务部署在国内的某云厂商机器上,其原因就是IO表现较差,拖累了整体性能,解决办法就是申请替换了机器。
讲到这里,如果你对系统性能非常感兴趣,我建议参考Brendan Gregg提供的完整图谱,我所介绍的只能算是九牛一毛。但我还是建议尽量结合实际需求,免得迷失在其中。
对于JVM层面的性能分析,我们已经介绍过非常多了:
- 利用JMC、JConsole等工具进行运行时监控。
- 利用各种工具,在运行时进行堆转储分析,或者获取各种角度的统计数据(如jstat -gcutil分析GC、内存分带等)。
- GC日志等手段,诊断Full GC、Minor GC,或者引用堆积等。
这里并不存在放之四海而皆准的办法,具体问题可能非常不同,还要看你是否能否充分利用这些工具,从种种迹象之中,逐步判断出问题所在。
对于应用Profiling,简单来说就是利用一些侵入性的手段,收集程序运行时的细节,以定位性能问题瓶颈。所谓的细节,就是例如内存的使用情况、最频繁调用的方法是什么,或者上下文切换的情况等。
我在前面给出的典型回答里提到,一般不建议生产系统进行Profiling,大多数是在性能测试阶段进行。但是,当生产系统确实存在这种需求时,也不是没有选择。我建议使用JFR配合JMC来做Profiling,因为它是从Hotspot JVM内部收集底层信息,并经过了大量优化,性能开销非常低,通常是低于 2% 的;并且如此强大的工具,也已经被Oracle开源出来!
所以,JFR/JMC完全具备了生产系统Profiling的能力,目前也确实在真正大规模部署的云产品上使用过相关技术,快速地定位了问题。
它的使用也非常方便,你不需要重新启动系统或者提前增加配置。例如,你可以在运行时启动JFR记录,并将这段时间的信息写入文件:
然后,使用JMC打开“.jfr文件”就可以进行分析了,方法、异常、线程、IO等应有尽有,其功能非常强大。如果你想了解更多细节,可以参考相关指南。
今天我从一个典型性能问题出发,从症状表现到具体的系统分析、JVM分析,系统性地整理了常见性能分析的思路;并且在知识扩展部分,从方法论和实际操作的角度,让你将理论和实际结合,相信一定可以对你有所帮助。
一课一练
关于今天我们讨论的题目你做到心中有数了吗? 今天的思考题是,Profiling工具获取数据的主要方式有哪些?各有什么优缺点。
请你在留言区写写你对这个问题的思考,我会选出经过认真思考的留言,送给你一份学习奖励礼券,欢迎你与我一起讨论。
你的朋友是不是也在准备面试呢?你可以“请朋友读”,把今天的题目分享给好友,或许你能帮到他。
- 江南白衣Calvin 👍(197) 💬(5)
找繁忙线程时,top -h , 再jstack, 再换算tid比较累,而且jstack会造成停顿。推荐用vjtools里的vjtop, 不断显示繁忙的javaj线程,不造成停顿。
2018-08-10 - 杨东yy 👍(40) 💬(1)
确实不错,还有个命令,sar,主要看iowait的值,如果它比较高,也说明磁盘io写入慢,当时我们的系统是虚拟机,和别的业务共用物理机,所以当别人并发大,也影响了我们,我们有切面写日志,系统日志写的比较多,就出现整个服务慢了,后来减少不必要的日志,找运维换机器
2018-07-24 - 盼盼 👍(31) 💬(1)
profiling收集程序运行时信息的方式主要有以下三种: 事件方法:对于 Java,可以采用 JVMTI(JVM Tools Interface)API 来捕捉诸如方法调用、类载入、类卸载、进入 / 离开线程等事件,然后基于这些事件进行程序行为的分析。 统计抽样方法(sampling): 该方法每隔一段时间调用系统中断,然后收集当前的调用栈(call stack)信息,记录调用栈中出现的函数及这些函数的调用结构,基于这些信息得到函数的调用关系图及每个函数的 CPU 使用信息。由于调用栈的信息是每隔一段时间来获取的,因此不是非常精确的,但由于该方法对目标程序的干涉比较少,目标程序的运行速度几乎不受影响。 植入附加指令方法(BCI): 该方法在目标程序中插入指令代码,这些指令代码将记录 profiling 所需的信息,包括运行时间、计数器的值等,从而给出一个较为精确的内存使用情况、函数调用关系及函数的 CPU 使用信息。该方法对程序执行速度会有一定的影响,因此给出的程序执行时间有可能不准确。但是该方法在统计程序的运行轨迹方面有一定的优势。
2018-07-24 - Yano 👍(24) 💬(4)
一直以来看老师的专栏没有留言过,今天特意来留言。我看了13讲(当时只出到13讲)面试就轻松通过了~老师每一篇文章,都让我非常收益,赞一个~!
2018-07-21 - clz1341521 👍(23) 💬(1)
dstat这个命令也很有用
2018-08-11 - 有福 👍(13) 💬(2)
喜欢用火焰图来辅助定位
2018-08-17 - One day 👍(1) 💬(1)
之前看到目录上还有讲spring和数据库等等,后面还会讲吧!
2018-07-21 - 张永峰 👍(10) 💬(3)
我都是一边看服务层,一边找DBA,80%都是DB慢SQL导致服务慢,经验之谈。
2020-02-28 - 硅谷居士 👍(7) 💬(1)
阿里的 arthas 不错。淘宝也有一个 profiler。
2019-04-20 - 磊吐槽 👍(7) 💬(0)
百度搜索 profiling是什么
2018-07-21 - 颇忒妥 👍(6) 💬(0)
我们应用跑在K8S上,我一般是看thread dump和gc log 。thread dump可以通过jstack或者spring boot actuator可以得到(推荐这个办法),然后交给fastthread.io分析。gc log 则在jvm启动时增加参数,然后交给gceasy.io 分析。内存泄露则是jvm 启动时增加参数,如果oom则heap dump到某个目录,而这个目录用emptyDir 卷挂载。
2020-06-26 - ub8 👍(4) 💬(1)
Full GC ,Minor GC 频率是多少算是频繁呢?
2020-01-04 - 大神仙 👍(3) 💬(0)
老师,minor gc变长的通常情况有哪些,除了young配置小以外,和系统io有关系么
2018-08-27 - james.h.fu 👍(2) 💬(0)
老师,我感觉很需要高质量的面向对象分析和设计。看代码的时候,总感觉有些地方OO写不好。
2018-12-13 - Gen幸福旅程iuS 👍(1) 💬(0)
vmstat -1 -10 这个命令写错了,应该为:vmstat 1 10
2023-05-30