31 事务怎么回滚?(下)
你好,我是俊达。
我们接着上一讲,继续介绍Undo。
Undo里的链表结构
Undo里面,存在着好几个链表结构,包括Undo页面链表、Undo日志头链表、Undo记录链表。
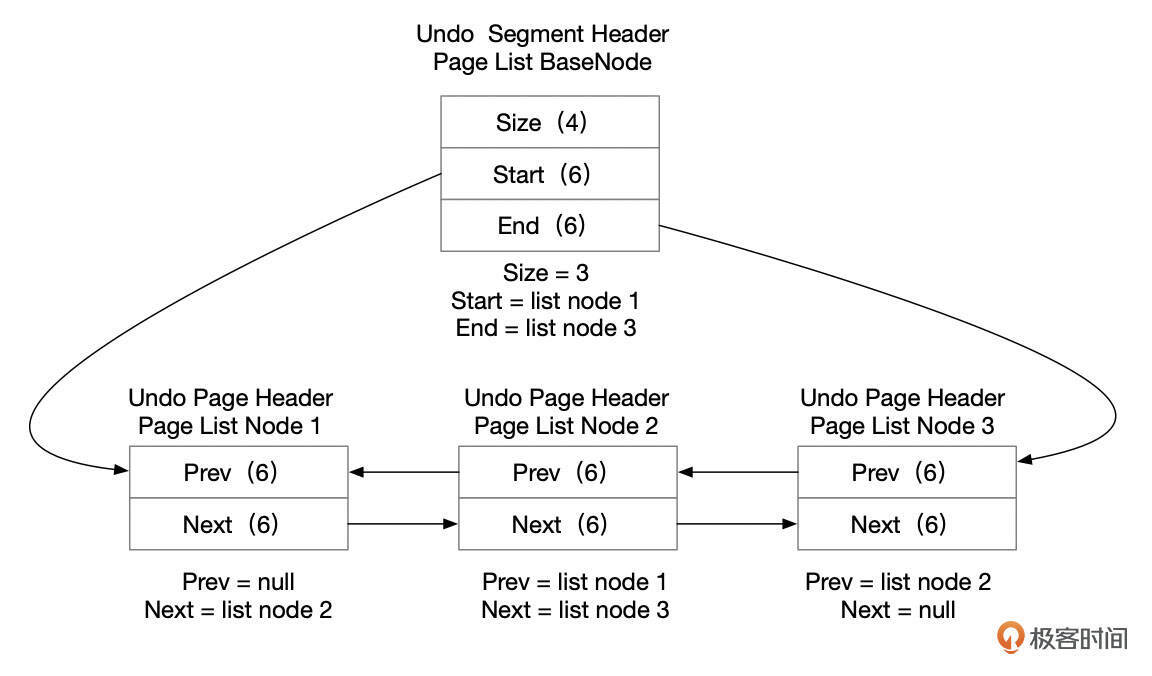
Undo段页面链表
Undo段中的页面组成一个双向链表。开始时,Undo段只有1个页面。如果事务中修改的记录数很多,1个页面无法容纳所有的Undo记录,就需要往Undo段中添加新的Undo页面。Undo段头部信息中记录了Undo页面链表的起点和终点。每一个Undo页面的头部信息中,记录了链表中前后相邻的Undo页面的地址。通过Undo页面链表,可以按正向或逆向的顺序遍历所有Undo页面。
下面是一个Undo页面链表的示意图。
Undo日志头链表
Update类型的Undo段,如果一个事务产生的Undo记录不多,那么当前事务结束后,这个Undo段还可以被后续的事务重用。重用时,会在Undo段中生成一个新的Undo日志头。一个Undo段中的所有日志头结构,组成了一个双向链表。
下面就是一个Undo页面中的多个Undo日志,通过双向链表连在一起。
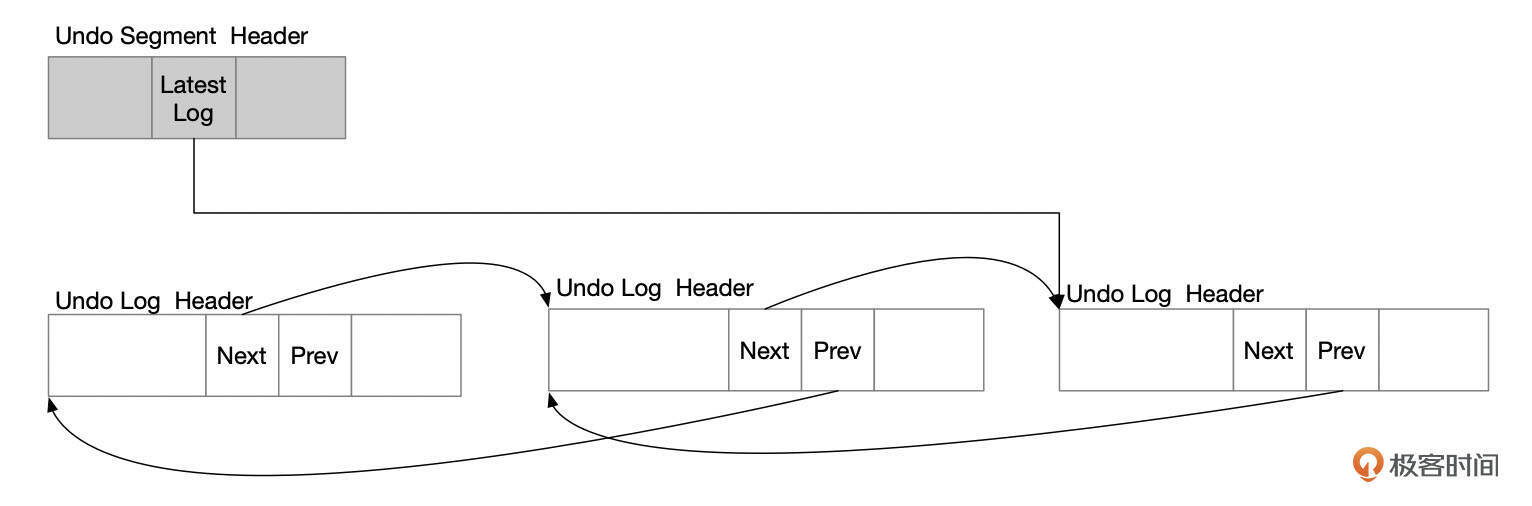
当然,一个Undo段被重用,需要满足几个条件。
- Undo段只使用了一个Undo页。如果一个Undo段中的Undo页数超过了1,就不重用这个Undo段。
- Undo页面里剩余空间超过页面大小的1/4。如果Undo页面的剩余空间不到页面大小的1/4,也不重用这个Undo段。
Undo页面内的记录链表
一个事务,在同一个Undo页面内的记录,通过Undo记录中的Next和Prev指针,组成一个双向的链表。
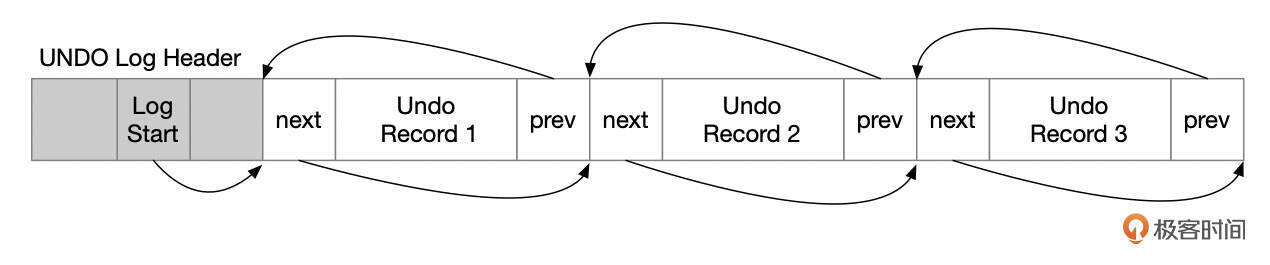
结合Undo页面链表和页面内记录链表,就可以按顺序或逆序的方式遍历整个事务的Undo记录。回滚事务时,需要以逆序的方式读取和应用Undo日志。Purge历史数据时,以顺序的方式读取和处理Undo记录。
Undo日志格式
接下来我们看一下Insert、Update、Delete语句产生的Undo记录的格式。
INSERT类型的Undo记录格式
INSERT语句一般情况下产生类型为TRX_UNDO_INSERT_REC的UNDO记录。日志格式参考下面这张图。
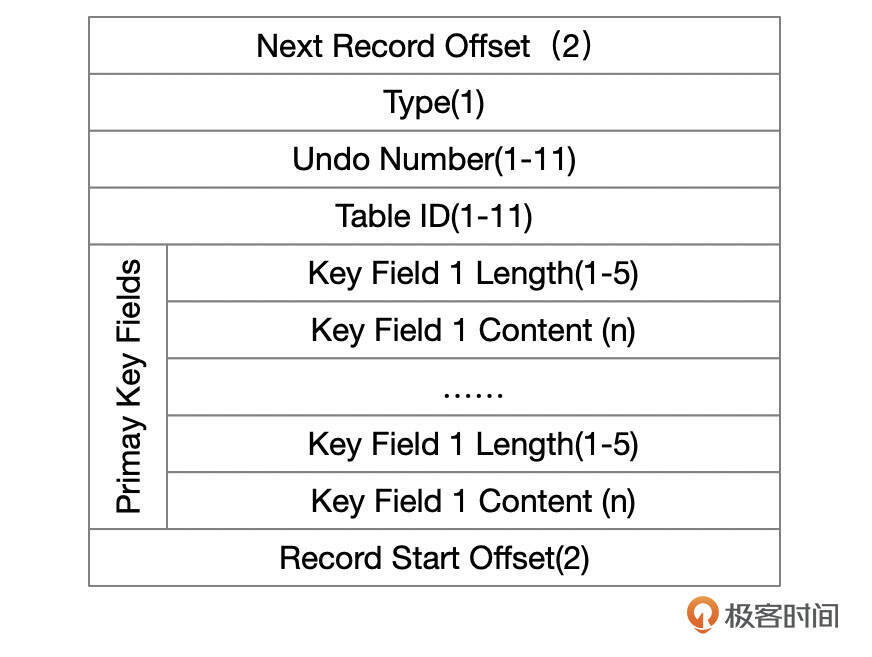
Undo记录的通用格式已经在上一讲中介绍过了。Insert类型的Undo中,记录了主键字段的数据长度和具体的数据。
我们来看下测试案例中,Insert记录ROW_01的Undo记录。从数据页中可以看到db_trx_id为01 E0 AF, db_roll_ptr为83/000001C9/0110,所以Undo段的页面编号为01C9。下图是Undo段(页面01C9)的内容,图上标注了Insert Undo记录中的信息。
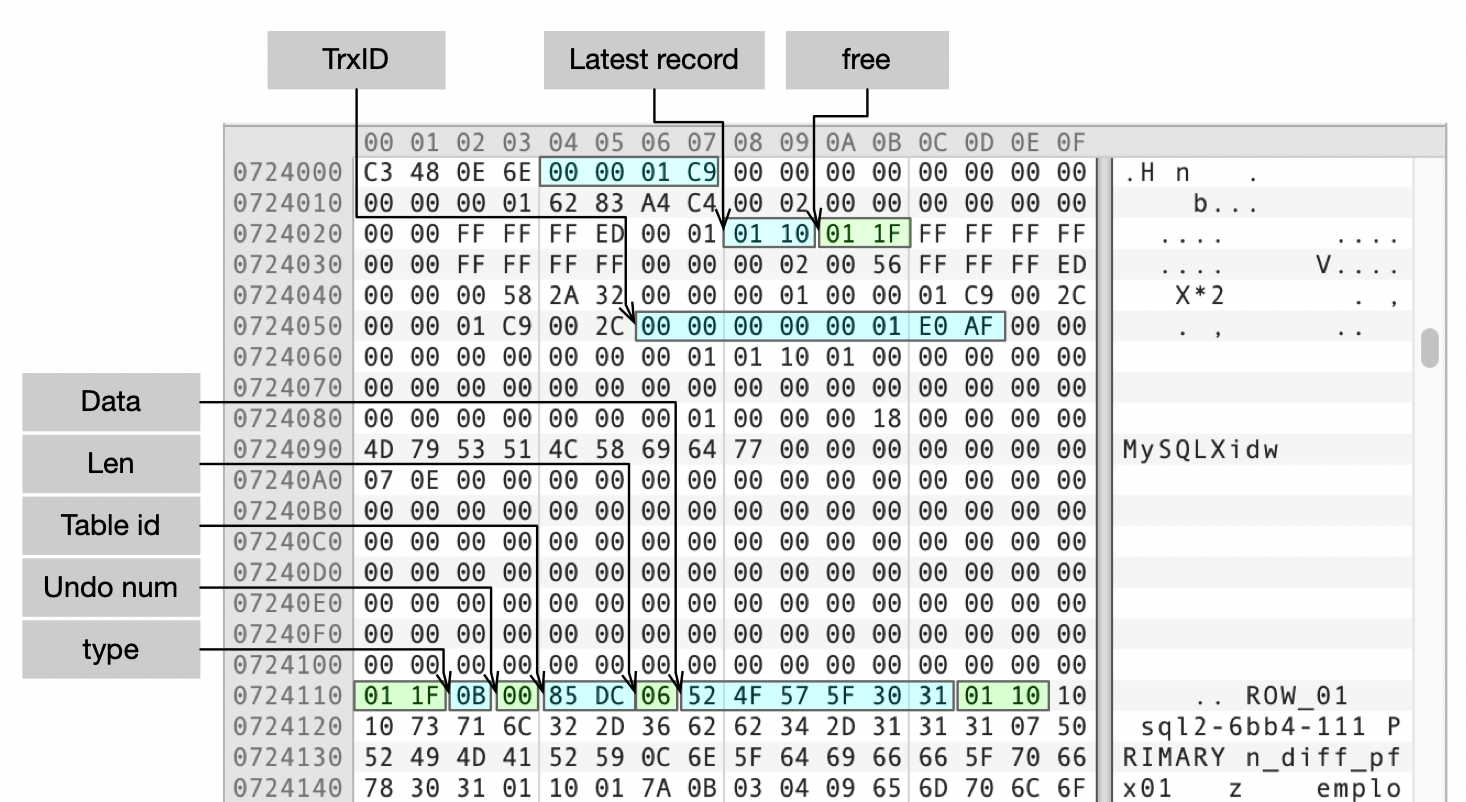
- type为0B,是TRX_UNDO_INSERT_REC。
- Undo num为0。
- Table ID为85 DC,转换为十进制是1500(0x5DC)。
从数据字典中确认Table ID就是1500。
mysql> select table_id, name, space, space_type from information_schema.innodb_tables where name = 'rep/t_undo';
+----------+------------+-------+------------+
| table_id | name | space | space_type |
+----------+------------+-------+------------+
| 1500 | rep/t_undo | 434 | Single |
+----------+------------+-------+------------+
- 数据长度为6。
- 数据内容为ROW_01,也就是我们插入记录的主键值。
UPDATE类型的Undo记录格式
Update和Delete语句产生都会产生Update格式的Undo记录。UPDATE语句产生的Undo类型为TRX_UNDO_UPD_EXIST_REC。DELETE语句产生的UNDO类型为TRX_UNDO_DEL_MARK_REC。Undo记录中的信息参考下面这张图。
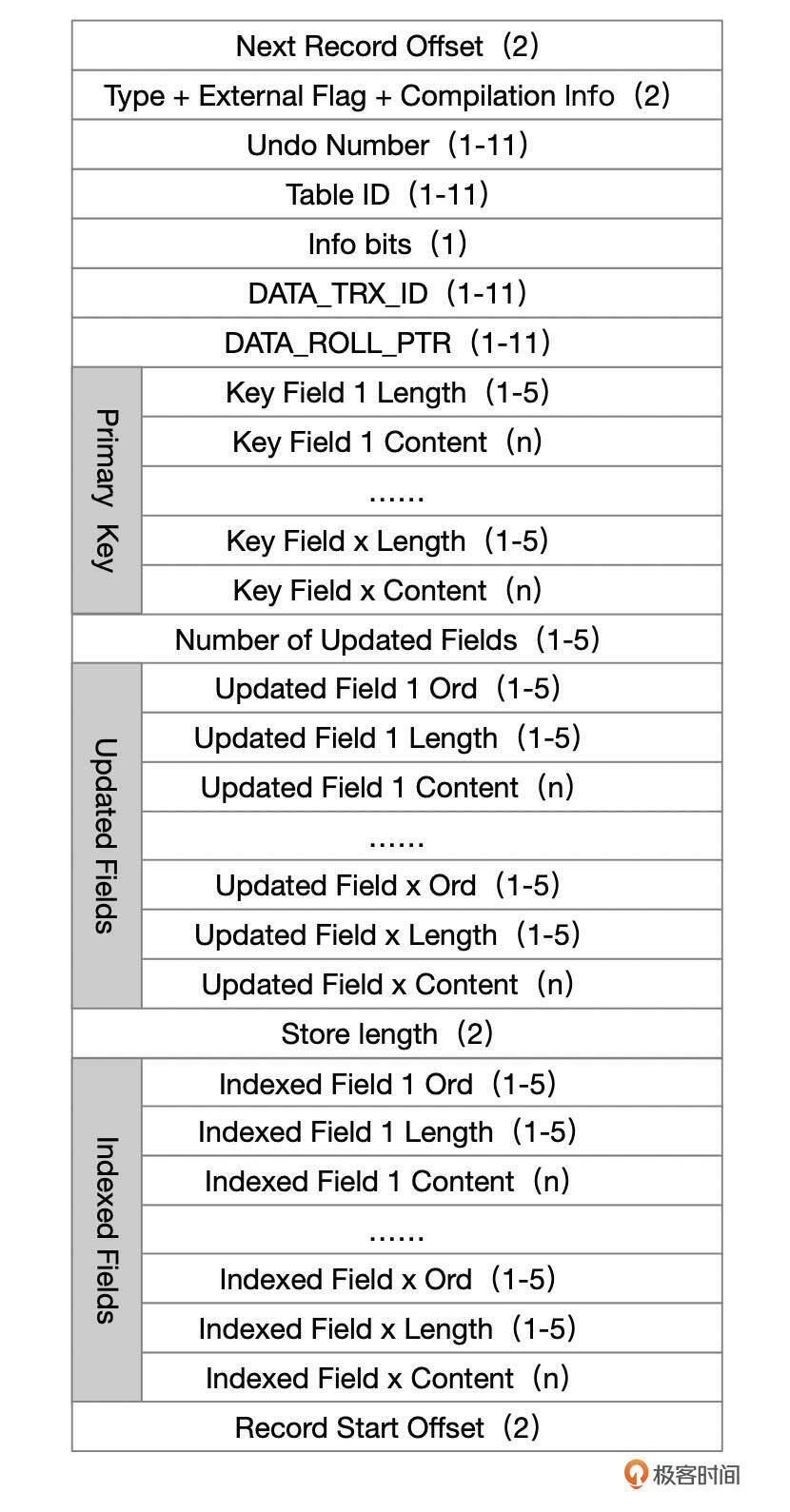
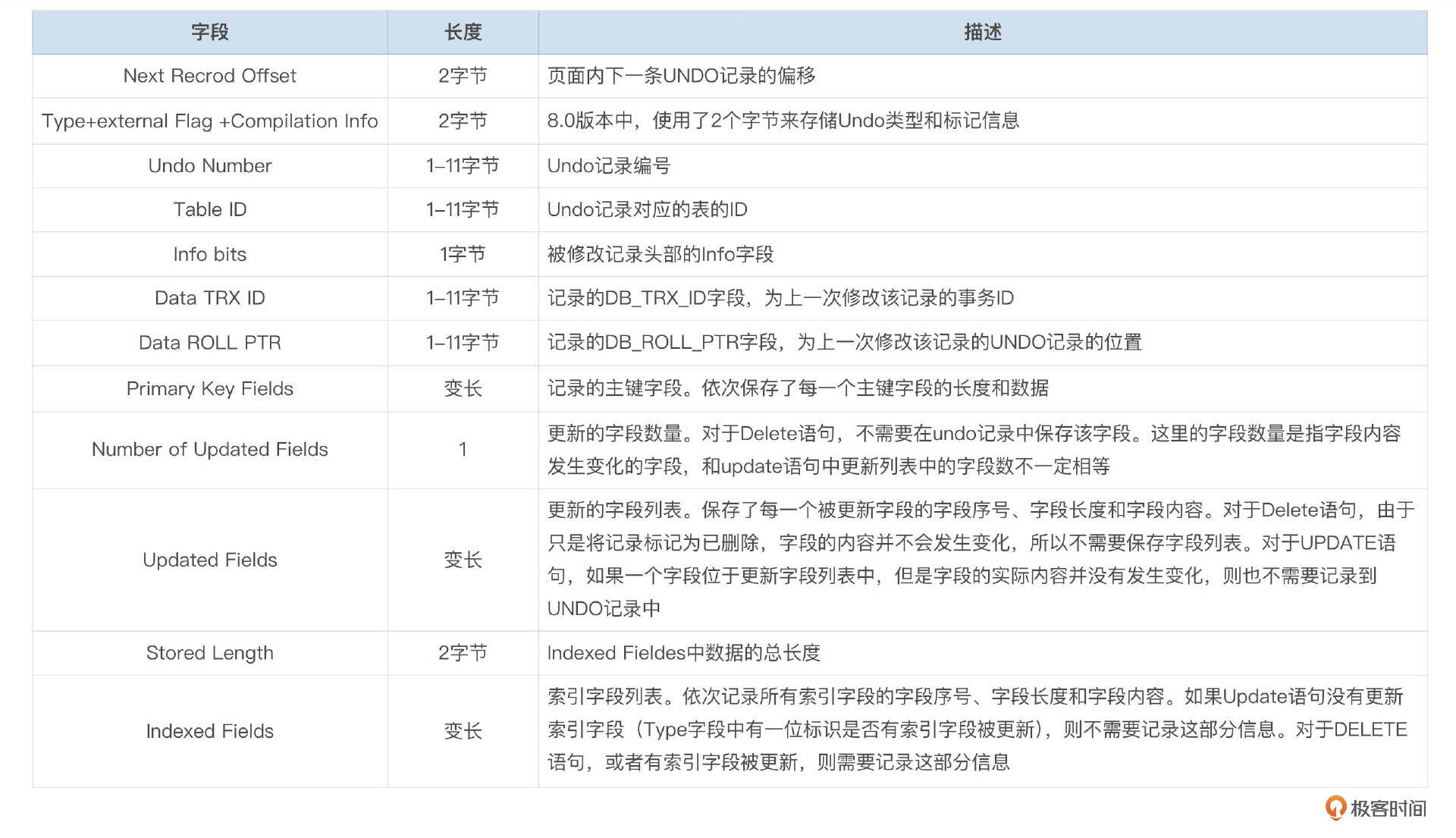
Update类型的Undo记录中,保存了记录上次更新时的db_trx_id和db_roll_ptr,还保存了主键值、更新过的字段更新前的值,以及索引字段的值。这里保存的索引字段的值,在Purge Undo日志时会用到。字段的具体含义可以参考下面这个表格。
可以看一下对记录ROW_03执行Delete、Insert和update语句所生成的Undo日志。图里面标注了Undo记录的一些信息。

Delete、Insert、Update这三个语句的Undo类型分别是4E,4D,4C,可以参考下面这个表格中的说明。
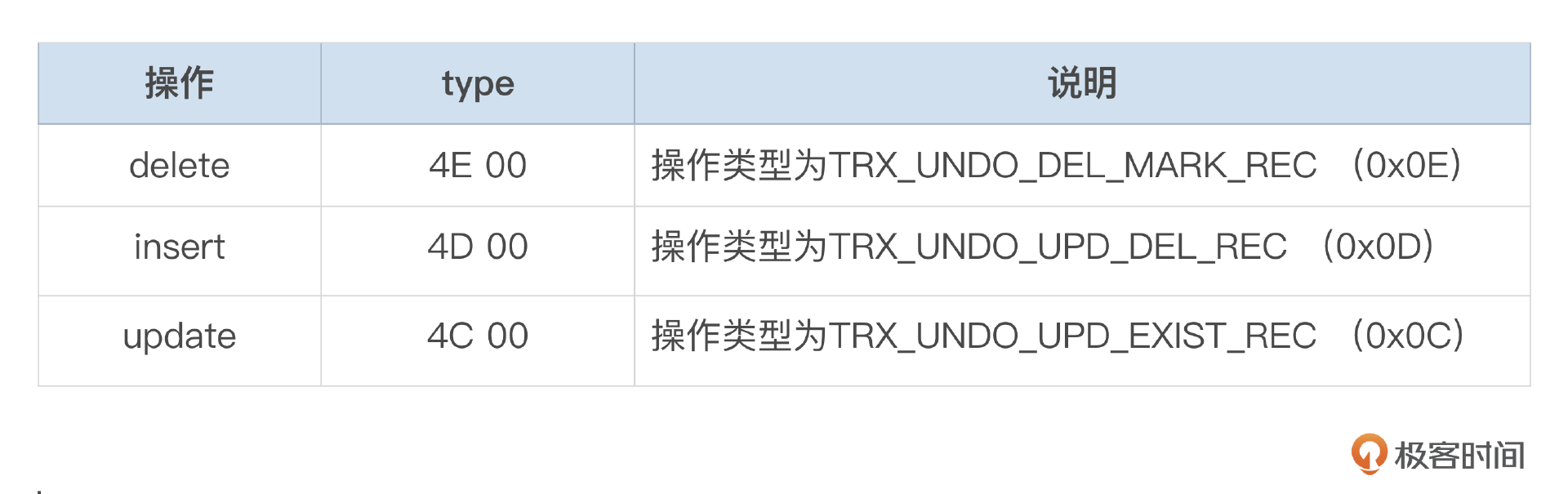
执行Insert时,如果新插入的记录和表中标记为删除的记录主键值相同,就会生成TRX_UNDO_UPD_DEL_REC类型的Undo,把加了删除标记的整行记录保存下来。我们的测试中,第二次Insert记录ROW_03就是这种情况。
UPDATE主键
如果更新时修改了主键字段,则InnoDB需要先删除原来的记录,然后再插入新记录,因此需要记录2条Undo。
- 对原有的记录设置删除标记,Undo类型为TRX_UNDO_DEL_MARK_REC。
- 插入新记录,Undo类型为TRX_UNDO_INSERT_REC。
事务(和Undo段)的生命周期
InnoDB开启事务时,并不会立刻为事务分配Undo段,只有当事务修改了数据,需要保存Undo信息时,才会分配Undo段。通常Insert操作会产生insert类型的Undo,insert Undo保存到insert Undo段中。Update和Delete操作产生update类型的Undo,update Undo保存到update Undo段中。
同一个事务中insert和update undo会保存到两个不同的undo段中,主要的原因是事务提交后,update类型的undo记录不能立刻删掉,MVCC机制可能还需要使用这些undo来构建记录的历史版本。而insert类型的undo记录在事务提交后可以立刻删掉,因为如果记录是新insert的,那么对应的DB_ROLL_PTR字段中会设置insert标记位,并且对于新insert的记录,不存在更早的版本。
修改临时表所产生的Undo记录,会保存到临时undo段中。临时Undo段从临时表空间中分配。往临时undo段中写入undo记录时,不需要记录REDO日志。系统重启时,临时表空间内的所有数据都会被清空,由于不需要恢复临时表空间内的数据,所以修改临时表空间时,不用记录Redo日志。
分配回滚段
事务中首次修改数据时,会先分配回滚段,MySQL以轮询的方式依次在所有Undo表空间的所有回滚段中选取。
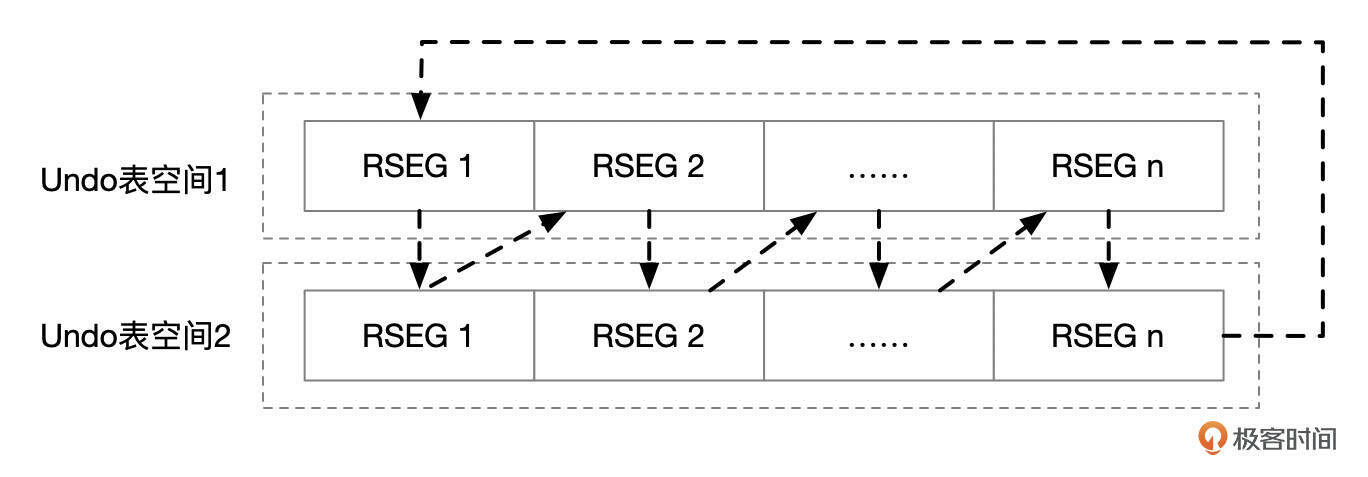
分配Undo段
对每个回滚段,InnoDB在内存中维护了2个Undo段的链表。事务结束时,如果对应的Undo段只有1个Undo页,并且Undo页剩余空间多于页面大小的1/4,就会将Undo段加入到缓存的Undo段列表中,给后面的事务重复使用。
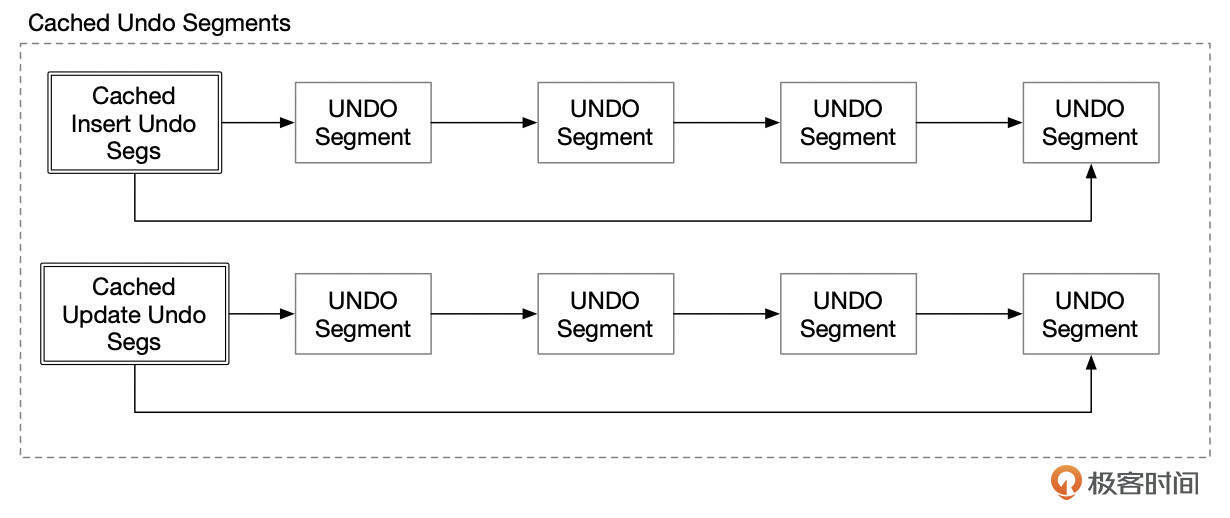
分配Undo段时,先根据Undo类型,到对应的链表中查找是否有可重用的Undo段。如果找到了可重用Undo段,先将Undo段从链表中取下,然后在Undo页面中加入Undo记录头部信息。对于Insert类型的Undo段,之前事务写入的Undo信息可以直接覆盖掉。对于Update类型的Undo段,之前事务写入的Undo信息不能直接覆盖,需要将新的Undo记录头部信息添加到Undo页面的空闲区域内。
如果当前没有可重用的Undo段,就需要创建新的Undo段。每一个回滚段最多可容纳1024个Undo段。在回滚段的页面中,以数组的形式记录了每一个Undo段的第一个页面的编号。
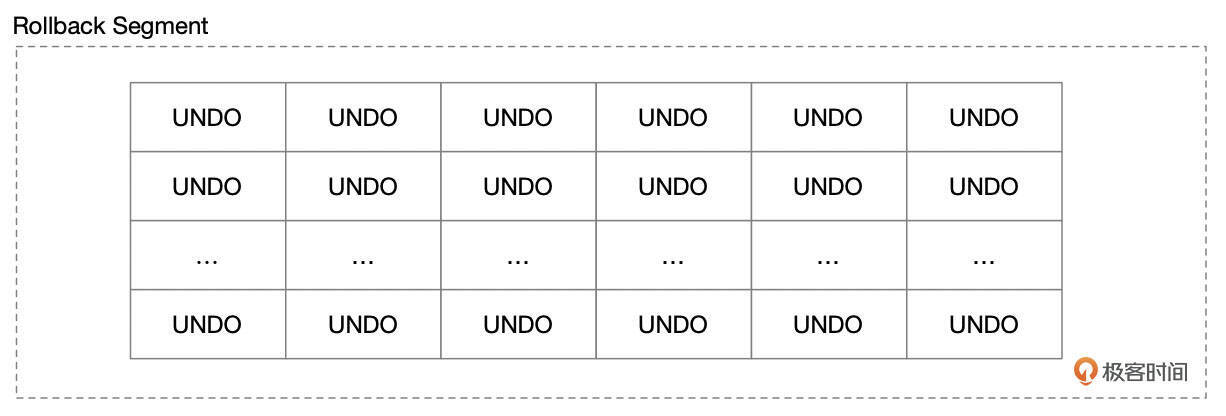
创建新的Undo段时,要先从数组中找到一个空闲的Undo槽位,空闲槽位由特殊值FIL_NULL(0xFFFF)标识。如果回滚段中的Undo槽位都已经被占用,就无法分配新的Undo段,事务无法进行。如果有空闲的Undo槽位,就创建一个新的Undo段,并在Undo槽位中记录Undo段的页面编号。
释放Undo段
事务结束时,需要释放已经分配的Undo段。释放Undo段大致上分为下面这几个步骤。
- 设置Undo段头部的状态信息(TRX_UNDO_STATE)。
如果Undo段内只有1个页面,并且页面的空闲空间大于页面大小的1/4,则说明该Undo段可以被后续事务重用,状态设置为TRX_UNDO_CACHED。如果Undo段无法重用,则对于Insert Undo段,状态设置为TRX_UNDO_TO_FREE,对于Update Undo段,状态设置为TRX_UNDO_TO_PURGE。
- 将Update Undo段加入到History链表中。
- 计算事务的trx no。trx no从变量next_trx_id_or_no中获取。
- 如果Undo段可重用(状态为TRX_UNDO_CACHED),将Undo段加入到update_undo_cached链表中。否则将回滚段中Undo数组中对应的槽位设置为空闲状态。
- 将Update Undo日志头加入到History链表中。
- 设置undo段头部的相关字段,包括trx no、删除标记、GTID等信息。
- 释放insert undo段,基于Undo段的状态执行下面的步骤。
- 如果状态为TRX_UNDO_CACHED,就把undo段加入到insert_undo_cached链表中。
- 如果状态为TRX_UNDO_TO_FREE,就释放undo段,并将Rollback段中Undo数组中对应的槽位设置为空闲状态。
History列表和Purge
Update Undo段在事务完成时加入到History列表中。每个回滚段都维护了一个历史Undo的双向链表(可以参考上一讲中的回滚段格式,RSEG History Base Node就是链表的基节点)。后台Purge线程会定期回收History链表中的Undo段。
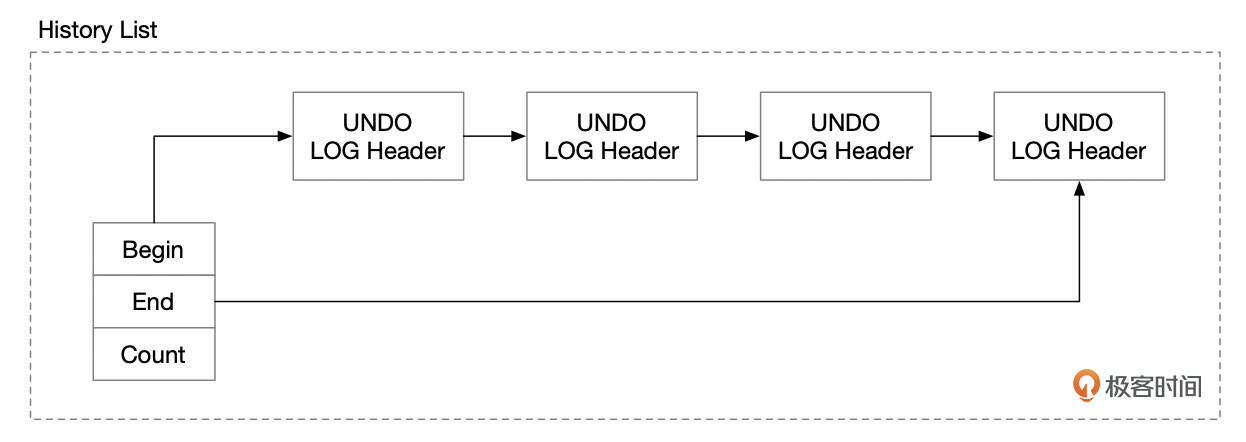 Undo Purge需要完成几件事情:
Undo Purge需要完成几件事情:
- InnoDB在删除记录时,或者更新主键字段或二级索引字段时,会给记录添加删除标记。记录只是逻辑上被删除了,记录占用的空间还没有被释放出来。Purge时,需要将标记为删除的记录从物理上真正删除,释放记录占用的空间。
- Update Undo段加入到History链表中后,占用的空间并没有释放。Purge时,需要将Undo段也释放掉。
Undo段按事务提交的顺序加入到History链表。Purge时,需要先确定哪些Undo段可以Purge。这和当前系统中打开的Read View有关。每个Read View开启时,会记录当前处于活跃状态的事务的最小的事务ID(m_up_limit_id)。Purge时,先计算所有Read View中m_up_limit_id的最小值。History链表中,如果Undo记录的trx no小于m_up_limit_id,就说明所有事务都不需要这个Undo记录了,可以清理掉。至于Read View具体是什么意思,我们在下一讲中会详细介绍。
show engine innodb status命令的输出中,Transactions部分记录了History链表相关信息。如果History链表的长度持续增加,可能是有长事务一直没有提交,或者Purge的速度跟不上数据写入的速度。
------------
TRANSACTIONS
------------
Trx id counter 29778
Purge done for trx's n:o < 29726 undo n:o < 0 state: running but idle
History list length 0
Total number of lock structs in row lock hash table 0
LIST OF TRANSACTIONS FOR EACH SESSION:
系统崩溃恢复
MySQL数据库运行时,每开启一个新的事务,都会将事务加入到活动事务的链表中,事务提交或回滚后,会将事务从链表中移除。通过事务链表,可以获取到每一个进行中的事务。但是如果数据库崩溃了,内存中的信息全部都丢失了,下一次数据库启动时,怎么知道之前数据库中有哪些进行中的事务呢?
InnoDB给每一个修改了数据的事务都分配了Undo段,Undo段中保存了事务相关信息,包括事务的状态、事务的ID等。数据库启动时,会扫描所有的回滚段,根据回滚段中记录的Undo段数组,读取事务状态,对于未提交的事务进行回滚操作,将数据库恢复到一致的状态下。
系统启动时,会进行崩溃恢复,大致上要执行下面这些步骤。
- 重做lsn号在checkpoint之后的redo日志。Redo在上一讲已经做了介绍。
- 扫描回滚段,根据回滚段Undo段数组里的信息,解析Undo段。
- 基于解析到的Undo段,构建事务列表。
- 回滚还没有提交的事务。
- 对于状态为prepared的事务,还需要根据Binlog中是否有对应的XID事件,来判断是提交还是回滚事务。
总结
通过上一讲和这一讲,你应该已经知道MySQL中Undo的原理和作用了。在写入特别繁忙的数据库中,清理(Purge)Undo日志可能会成为制约数据库性能的一个重要因素。建议把History链表长度监控起来。有一些Purge相关的参数可以配置,具体信息可以参考官方文档。Undo还在事务的一致性读取(MVCC)中起到重要的作用,我们在下一讲中再介绍。
思考题
MySQL中,提交一个事务通常是非常快的,因为提交事务时,不需要等待脏页刷新,只需要将事务生成的Redo日志刷新到磁盘就可以了。但是回滚一个事务,成本就比较大了,特别是当你在事务中修改了大量数据后再回滚。
考虑这么一个场景,你对一个大表执行了不带where条件的delete语句,执行了很长一段时间后,你发现delete还没有完成,而且数据库卡死了,为了尽快恢复业务,你选择了重新启动数据库。在数据库启动时,MySQL会怎么处理这个被中断的delete操作?
期待你的思考,欢迎在留言区中与我交流。如果今天的课程让你有所收获,也欢迎转发给有需要的朋友。我们下节课再见!
- TheOne 👍(1) 💬(1)
会把执行过程中标记为删除的记录都回滚,也就是回滚掉还没提交的事务
2024-11-04 - binzhang 👍(1) 💬(1)
在数据库启动时,MySQL 会怎么处理这个被中断的 delete 操作? assume it's INNODB. Mysql will start crash recovery processes, apply redo, do un-commit transaction rollback. Since this huge delete is not commit, mysql has to rollback it. Until all rollback finished, mysql can accept application traffic. so this guy might need to wait for long time while mysql is un-available. But i think in concept, once mysql finish redo apply in crash-recovery phase, it should be able to accept traffic while rollback un-commit transaction is still in-progress; application query can still wait for lock or do MVCC read. not sure if there're some internal parameter control it.
2024-11-02