32 隔离级别对应用程序有什么影响?
你好,我是俊达。
事务的ACID属性中,I(Isolation)表示隔离性,指的是多个事务并发执行时,各个事务之间相互独立,仿佛在独立的环境中执行一样。数据库用来实现隔离性的两个重要的方法分别是MVCC(Multi-Version Concurrency Control,多版本并发控制)和锁。
这一讲我们会介绍MVCC,锁的内容在下一讲中再展开。
事务的隔离级别是什么意思?
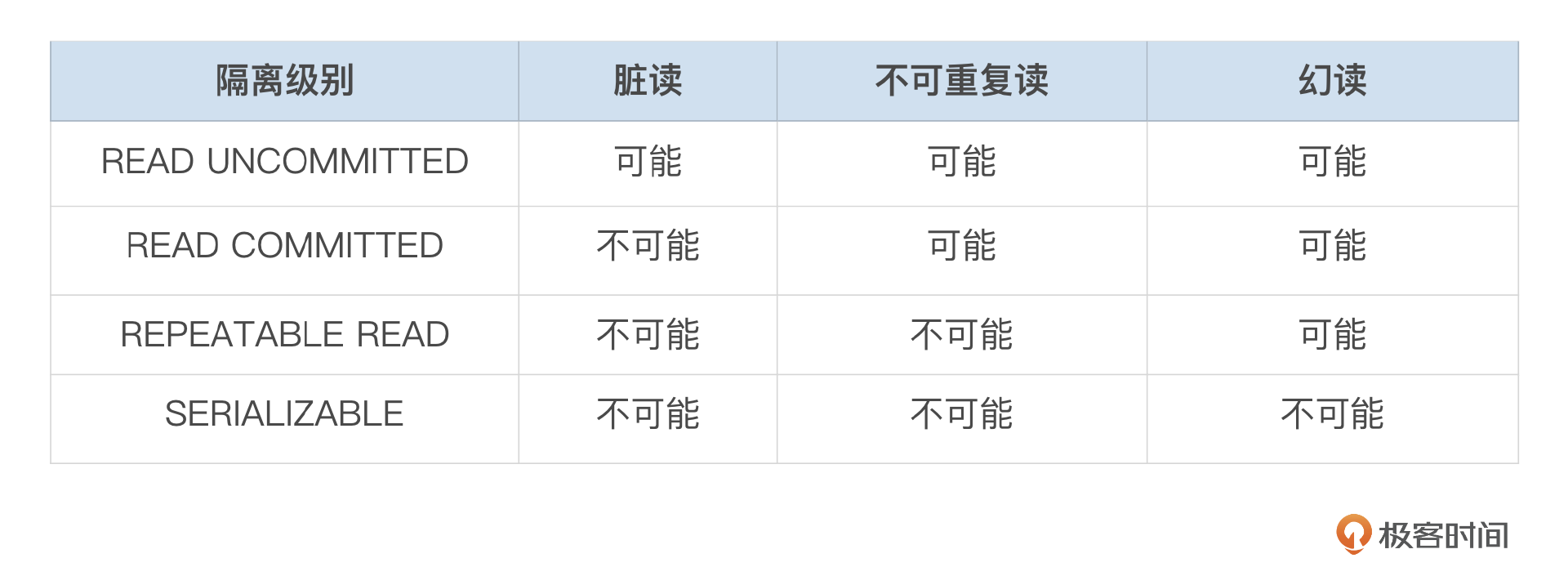
事务之间互相隔离的程度使用隔离级别来描述。ISO SQL标准定义了4个隔离级别,分别为READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ、SERIALIZABLE。事务的隔离级别决定了并发的事务在执行过程中,读取和写入数据受其他事务的影响程度。
根据隔离级别的不同设置,事务在执行过程中可能会存在下面这几种现象:
- 脏读(Dirty read):读取到其他事务还没有提交的修改。
- 不可重复读(Nonrepeatable read):事务在T1时刻读取到的记录,在T2时刻再次读取时,可能会发生变化,要么字段被更新了,要么记录被删除了。
- 幻读(Phantom read):事务中的一个SQL,在T1时刻执行获取到的记录,在T2时刻执行同一个SQL时,依然能获取到,但是在T2时刻还能获取到额外的记录。
根据事务是否会遇到上面的几种现象,ISO SQL标准定义了4种隔离级别,参考下面这个表格。
如何设置隔离级别?
MySQL支持SQL标准定义的4种隔离级别,默认的隔离级别是REPEATABLE READ。你可以使用参数transaction_isolation或命令set transaction isolation level在全局、会话或事务设置隔离级别。
设置全局隔离级别
使用set global transaction_isolation设置全局隔离级别。
set global transaction_isolation = 'READ-UNCOMMITTED' |
'READ-COMMITTED' |
'REPEATABLE-READ' |
'SERIALIZABLE';
使用set global transaction isolation level设置全局隔离级别。
set global transaction isolation level READ UNCOMMITTED |
READ COMMITTED |
REPEATABLE READ |
SERIALIZABLE;
使用两种方式设置隔离级别的效果是一样的。设置全局隔离级别并不会改变当前会话的隔离级别,只有建立新的会话时配置才会生效。
全局隔离级别可以通过命令show global variables查看。
mysql> show global variables like 'transaction_isolation';
+-----------------------+-----------------+
| Variable_name | Value |
+-----------------------+-----------------+
| transaction_isolation | REPEATABLE-READ |
+-----------------------+-----------------+
1 row in set (0.00 sec)
设置会话隔离级别
使用set transaction_isolation设置会话隔离级别。
set [session] transaction_isolation = 'READ-UNCOMMITTED' |
'READ-COMMITTED' |
'REPEATABLE-READ' |
'SERIALIZABLE';
上述命令中的session关键字可以加上,也可以不加。
使用set session transaction isolation level设置会话隔离级别。
set session transaction isolation level READ UNCOMMITTED |
READ COMMITTED |
REPEATABLE READ |
SERIALIZABLE;
新开启一个事务时,会根据会话级别的隔离设置来决定事务的隔离级别。需要注意,如果在设置会话隔离级别时,事务已经开启,那么当前事务的隔离级别并不会发生变化。
使用命令show variables查看会话的隔离级别。
设置下一个事务的隔离级别
使用set @@transaction_isolation设置下一个事务的隔离级别。
set @@transaction_isolation = 'READ-UNCOMMITTED' |
'READ-COMMITTED' |
'REPEATABLE-READ' |
'SERIALIZABLE';
使用set transaction isolation level 设置下一个事务的隔离级别。
使用上面两种方法,都可以修改下一个事务的隔离级别,修改只对下一个事务生效。(下一个事务)之后事务,隔离级别会依据会话的隔离级别来确定。
如果当前已经开启了事务,执行这两个命令都会报错。
mysql> set @@transaction_isolation = 'READ-UNCOMMITTED';
ERROR 1568 (25001): Transaction characteristics can't be changed while a transaction is in progress
mysql> set transaction isolation level read committed;
ERROR 1568 (25001): Transaction characteristics can't be changed while a transaction is in progress
不同隔离级别下,事务的数据可见性
接下来我们使用几个具体的例子,来看看不同隔离级别下事务的数据可见性。
READ UNCOMMITTED
在READ UNCOMMITTED隔离级别下, 事务可以读取其他事务还没有提交的修改。
下面我以一个简单的例子来演示。先准备测试表和数据。
mysql> create table test_dirty(a int, b int);
Query OK, 0 rows affected (0.76 sec)
mysql> insert into test_dirty values(1,1);
Query OK, 1 row affected (0.53 sec)
按顺序执行下面这些SQL。

可以看到,使用READ UNCOMMITTED隔离级别可以读取其他会话还没有提交的修改。有些数据库中,使用READ UNCOMMITTED隔离级别的一个原因是避免读取过程中的锁等待,代价是牺牲了数据的一致性。在MySQL数据库中,普通的SELECT语句不需要获取记录锁,查询也不会对记录加锁,因此一般不会使用MySQL的READ UNCOMMITTED隔离级别。
READ COMMITTED
在READ COMMITTED隔离级别下,事务能读取到其他事务提交后的数据。
准备测试数据。
create table test_account(account_no int, balance int);
insert into test_account values(1001, 1000);
insert into test_account values(1002, 2000);
insert into test_account values(9009, 10000);
按以下顺序执行SQL:

例子中,会话2在T6时刻提交了修改,会话1在T2和T7两个时间点读取到的记录发生了变化。
我们设想这样一种场景。

上述假想的例子中,会话1开始执行统计SQL,由于表比较大,该SQL需要执行一段时间,在这个SQL执行期间,会话2发起一个转账事务,将部分金额从account_no为1001的记录转到account_no为9009的记录并提交。会话1中的SQL,在T1时刻读取到account_no为1001的记录的余额,其中有500转到了T3时刻读取到的account_no为9009的记录中,那么在READ COMMITTED隔离级别下,该SQL是否存在数据不一致的情况(金额被重复计算)?
如果会话1的Select执行过程中对数据加锁,那么会话2的update语句需要等待select执行完成后才能执行。MySQL中普通select语句不会对数据加锁,而是通过语句级别的一致性读取来避免上述假想例子中存在的数据不一致现象。
总结一下,MySQL中,READ COMMITTED不会出现脏读,但是会有不可重复读和幻读。
REPEATABLE READ
按照SQL标准的定义,REPEATABLE READ隔离级别下,不会出现不可重复读现象,但是可能会出现幻读现象。接下来我们测试一下MySQL的REPEATABLE READ隔离级别。
create table test_account(account_no int, balance int);
insert into test_account values(1001, 1000);
insert into test_account values(1002, 2000);
insert into test_account values(9009, 10000);

下面是另外一个例子,REPEATABLE READ隔离级别下,如果select语句后加上for share、for update,或者执行的是update、delete、insert into t2 select from t1这类语句时,需要读取记录最新版本,称为当前读。MySQL会根据where条件和SQL的执行计划,加上相应的锁,阻止其他会话写入满足查询条件的记录。

上述例子中,会话1查询了balance <= 2000的记录,会话2插入的记录满足会话1中SQL的where条件(balance <= 2000),因此被阻塞。
上面的两个例子,MySQL看上去实现了可重复读,没有幻读,是不是能说MySQL的隔离级别完全实现了SQL标准呢?
create table test_account2(account_no int, balance int, remark varchar(30)) engine=innodb;
insert into test_account2 values(1001, 1000, '');
insert into test_account2 values(1002, 2000, '');
insert into test_account2 values(9009, 10000, '');

T5时刻,会话1更新了两行记录后,再查询数据,可以看到,被更新过的记录,读取到了最新的版本。因此,这个例子中,出现了幻读(多了account_no 1003的数据),还出现了不可重复读(account_no 1002的数据发生了变化)。
小结一下,MySQL的REPEATABLE READ隔离级别,如果事务是只读的,或者事务中没有修改数据,或者事务中修改的数据和其他事务没有重叠,可以保证可重复读,而且没有幻读。
SERIALIZABLE
SERIALIZABLE是等级最高的隔离级别。MySQL里,SERIALIZABLE事务中的普通SQL读取数据时也会加锁。在MySQL中使用SERIALIZABLE隔离级别可以避免出现经典的“更新丢失(lost update)”问题。
更新丢失问题:

会话1和会话2分别开启事务,读取account_no为1002的账户余额,然后会话1给账号增加200的余额,会话2给账号增加300的余额。会话1的事务先提交,当会话2的事务提交时,会话1的更新被覆盖,最终账号余额变成2300,会话1的更新相当于丢失了。
解决更新丢失问题,有几种不同的方法。
方法1:使用select for update,在查询时就直接锁定记录。
begin;
select * from test_account where account_no = 1002 for update;
update test_account set balance = 2200 where account_no = 1002;
commit;
使用这种方法,在查询时就需要锁定记录,会影响系统的并发性。select和update执行的间隔时间越长,事务持有锁的时间就越长。
方法2:将update语句改成下面这种形式。
方法3:给记录加上版本号,每次修改记录时需要同时修改版本号。
begin;
select account_no, balance, version
from test_accout
where account_no = 1002;
update test_accout
set balance = 2200, version = version + 1
where account_no = 1002
and version = :version
commit;
使用这种方法,只会在执行update时持有锁。如果其他会话修改了当前的记录,版本号也会发生变化,事务在更新记录时就匹配不到这行记录。
如果事务的隔离级别为SERIALIZABLE,那么在查询数据时就会给记录加上锁。在上面的例子中, T5时刻的update操作需等待会话2释放锁,T7时刻,会话2的update操作需要等待会话1释放锁,形成了死锁。MySQL检测到死锁后,会回滚其中一个事务。
mysql> update test_account set balance = 2300 where account_no = 1002;
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
这样也避免了更新丢失的问题。 当然在实际应用中,如果用了SERIALIZABLE隔离级别,读操作会阻塞写操作,写操作也会阻塞读操作,会严重影响系统的并发性,所以一般很少使用SERIALIZABLE隔离级别。
前面讲了,SERIALIZABLE隔离级别下SELECT也会获取锁,其实也有例外的情况,在autocommit=ON的设置下,如果没有显式开启事务,那么SELECT是不需要锁的。
InnoDB的MVCC是怎么实现的?
InnoDB的MVCC机制,使用了Undo日志,来实现READ COMMITTED和REPEATABLE READ隔离级别下的一致性读取。一致性读取在执行时不需要对记录加锁,这样就不会被其他事务的写操作阻塞,也不会阻塞其他事务修改数据。
当然下面的这些情况下,使用了当前读,需要获取记录锁。
- 使用select for share或select for update的语句,总是查询数据的当前版本,需要对记录加锁。
- update和delete语句,在查找满足条件的记录时,需要获取记录的当前版本,查找时需要给记录加锁。这里有一种特殊情况:在READ COMMITTED隔离级别下,UPDATE会使用半一致性读取(semi-consistent read)。关于锁的问题,我们到下一讲再具体介绍。
- REPEATABLE READ隔离级别下,insert into t select * from tab、create table t as select * from tab这类SQL中的select操作需要对读取到的记录加锁。
一致性读取的一个例子
我们以一个简单的例子来说明MySQL中MVCC的大致工作原理。
先创建一个测试表:
create table tab(
pk varchar(10),
c1 int,
data varchar(100),
primary key(pk),
key idx_c1(c1)
) engine=innodb;
开启2个会话,按以下表格中的时间顺序依次执行SQL。

- T1时刻,事务trx1 INSERT一条记录并提交。

- T3时刻,事务trx2查询数据,从索引idx_c1中定位到记录的主键,然后根据主键到Primary索引中获取记录,对比记录的trx字段,trx1在trx2开始之前已经提交,所以这条记录对于trx2可见。
- T4时刻,会话1开启事务trx3,执行UPDATE操作更新了记录。
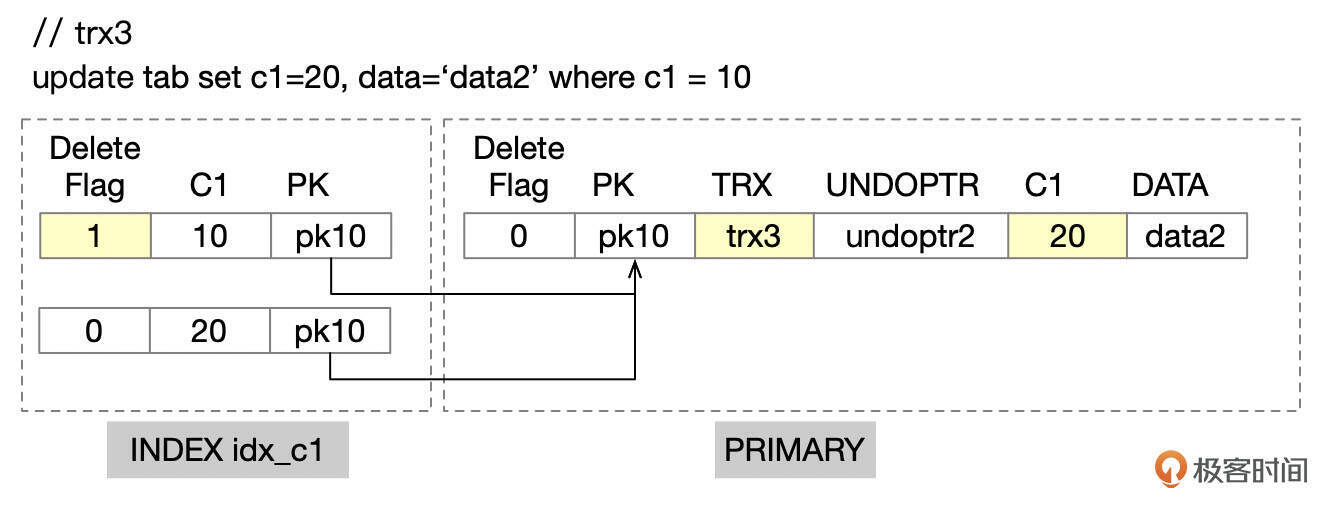
更新之后,索引idx_c1中的记录(10, pk10)被标记为已删除,同时插入新的索引记录(20, pk10)。主键记录中,db_trx_id字段更新为trx3,db_roll_ptr指向UPDATE操作产生的undo记录,C1字段更新为20。
- T5时刻,会话2再次执行SELECT时,根据索引中被标记为删除的记录获取到记录的主键,然后从Primary中获取到记录,对比trx字段,trx3是在trx2之后才开启的,所以当前的记录对事务trx2不可见,MySQL根据undoptr2找到undo记录,计算得到记录的上一个版本,并判定版本是否可见。
- T6时刻,会话1开启事务trx4,执行INSERT操作。
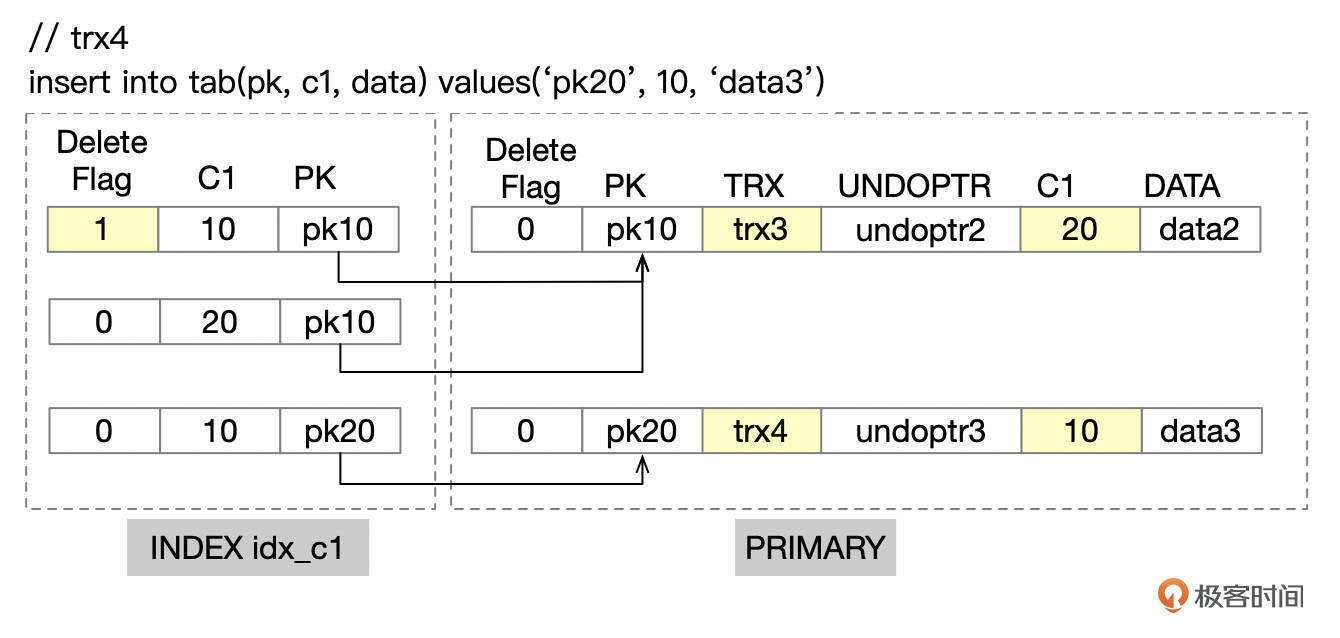
- T7时刻,事务trx2再次执行SELECT操作,这次根据条件(c1=10)从索引idx_c1中得到2条记录,PK分别为pk10、pk20,对于主键为pk10的记录,通过多版本机制获取到上一个版本的记录满足trx2。对于主键为pk20的记录,最近一次操作是INSERT,事务ID trx4对当前事务不可见。因此只返回一行记录。
- T8时刻,事务trx2执行的SQL使用了覆盖索引。但是索引页面的max_transaction_id是trx4,虽然使用了覆盖索引,但需要回表构建记录的历史版本,因为只有聚簇索引中记录了db_roll_ptr。
- T9时刻,事务trx2提交。
- T10时刻,新的事务trx5执行同样的SELECT查询,从索引idx_c1中获取到2条满足条件的记录:(10,pk10)和(10,pk20),对于主键为pk20的记录,对比发现trx4在trx5开始前已经提交,所以该记录对trx5可见。对于主键为pk10的记录,对比发现trx3在trx5开始之前已经提交,所以该记录对trx5可见,但是该记录的C1字段已经被修改为20,不满足C1=10的条件,所以查询最终只返回主键为pk20的记录。
Read View
怎么判断读某一行数据对当前的事务或语句是否可见呢?MySQL使用了Read View来实现这个功能。这里的Read View和平时我们说的视图不是同一个概念,千万不要搞混淆了。
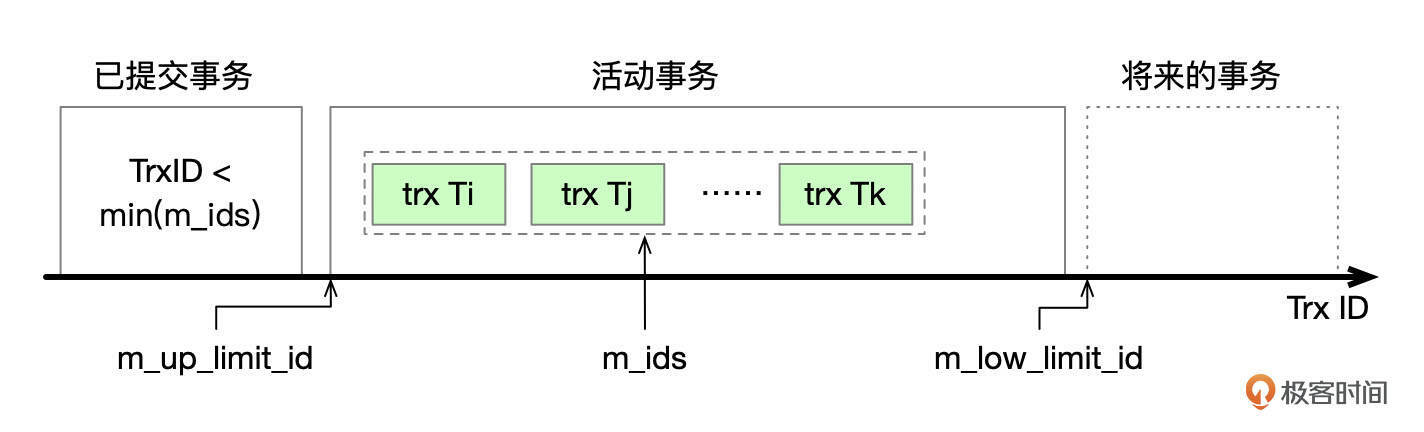
Read View中记录了当前系统中活动事务信息。
对于一个Read View而言,哪些数据是可见的呢?规则其实很简单。
- 创建Read View时就已经提交的事务,它们的修改可见。
- 和Read View绑定的那个事务,自己修改的数据可见。
Read View中记录了当前系统中活动事务的ID列表(m_ids),这些事务的修改不可见。这些事务ID中,一定存在一个最小值,最小值保持在成员m_up_limit_id中,小于这个ID的事务,在创建Read View时肯定都已经提交了,他们的修改可见。
创建Read View时,系统将分配给下一个事务的ID记录在成员m_low_limit_id中,大于这个ID的事务,在创建Read View时,还不存在,因此这些事务的修改不可见。Read View还记录了创建者的事务ID m_creator_trx_id,本事务修改的数据,对自己当然是可见的。
READ COMMITTED和REPETABLE READ隔离级别在实现上最根本的区别就是创建READ VIEW的时间不一样。对于READ COMMITTED隔离级别的事务,每次执行一致性查询时,都会创建一个新的Read View,这样SELECT就能获取系统中当前已经提交的最新数据。对于REPETABLE READ隔离级别的事务,在第一次执行一致性读取时创建READ VIEW。事务中后续再次执行SELECT时,会重用已经创建好的Read View。
前面有一个例子,一致性读取查不到的数据,却可以被更新到。而更新之后,就可以读取到其他事务的修改了。
mysql> select * from test_account2 where balance <= 3000;
+------------+---------+
| account_no | balance |
+------------+---------+
| 1001 | 1000 |
| 1002 | 2000 |
+------------+---------+
2 rows in set (0.01 sec)
mysql> update test_account2 set remark = 'vip' where account_no in (1002, 1003);
mysql> select * from test_account2 where balance <= 3000;
+------------+---------+--------+
| account_no | balance | remark |
+------------+---------+--------+
| 1001 | 1000 | |
| 1002 | 2001 | vip |
| 1003 | 1501 | vip |
+------------+---------+--------+
这是因为更新时,使用了当前读。而更新记录时,也修改了记录的db_trx_id字段,和Read View的m_creator_trx_id一样了,因此后续的一致性读取也能查询到这些记录了。
记录版本链
最后介绍一下记录的版本链。
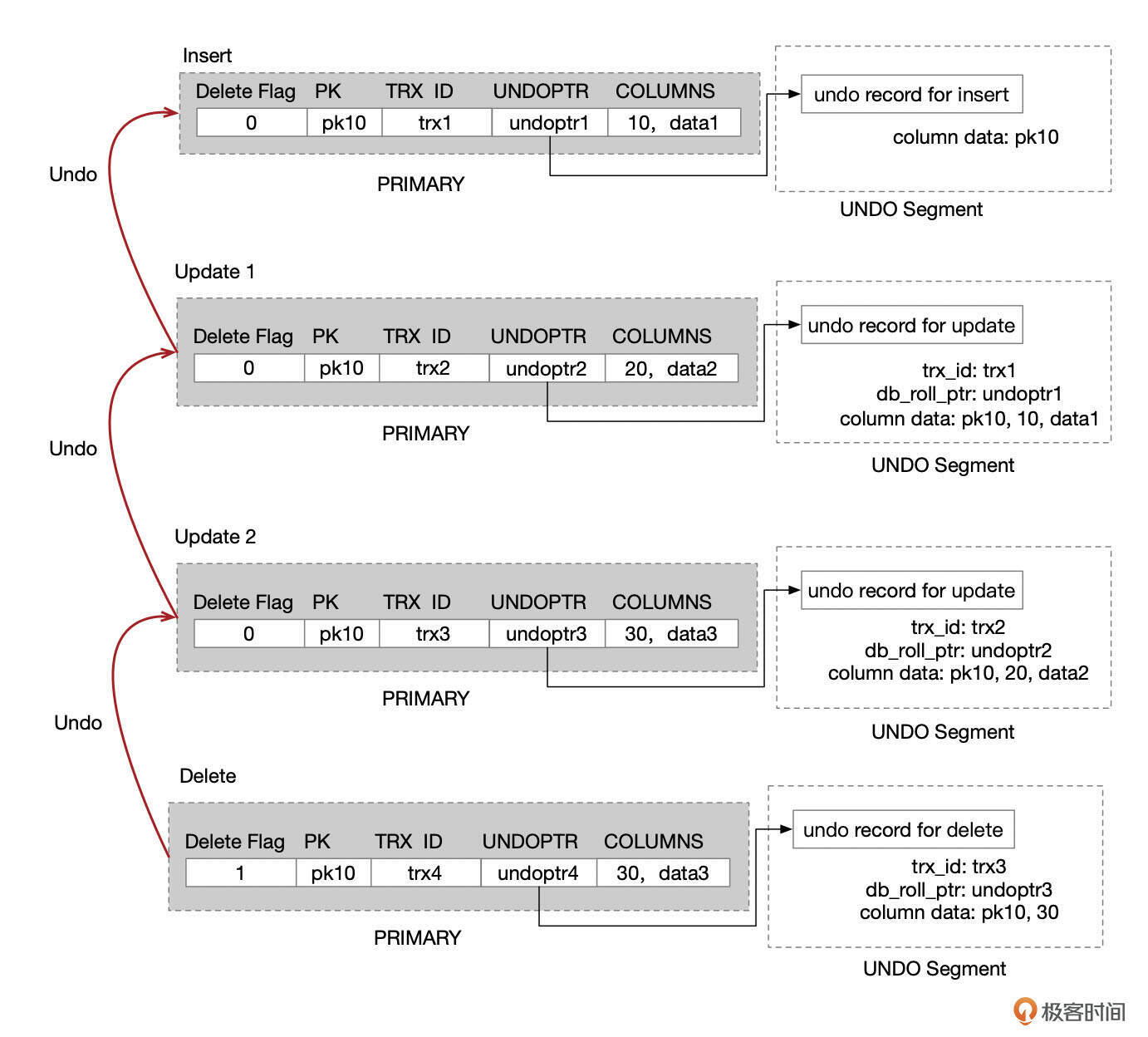
- InnoDB给每一行记录增加了两个隐藏字段:事务ID(db_trx_id)和回滚段指针(db_roll_ptr)。
- 每次修改记录时,InnoDB会将撤销该修改所需的数据写入到回滚段。
- 每次修改记录时,InnoDB还会修改db_trx_id和db_roll_ptr字段。
- 修改二级索引页面时,会更新页面中的max_transaction_id。
- 执行一致性读取时,如果记录当前的版本不可见,就通过db_roll_ptr找到Undo记录,将记录回退到上一个版本(具体的操作是先将记录复制到临时内存中,然后在临时内存上执行版本回退,不会修改聚簇索引中的数据)。
- 判断回退后的版本是否可见,如果不可见,就继续进行回退操作,直到记录版本可见。或者回退到记录INSERT之前,也就是记录不存在。
通过这种版本链条的机制,InnoDB实现了一致性读取。
回退INSERT操作
对于INSERT操作,UNDO PTR有一个特殊的标识为,标记当前的操作为INSERT。
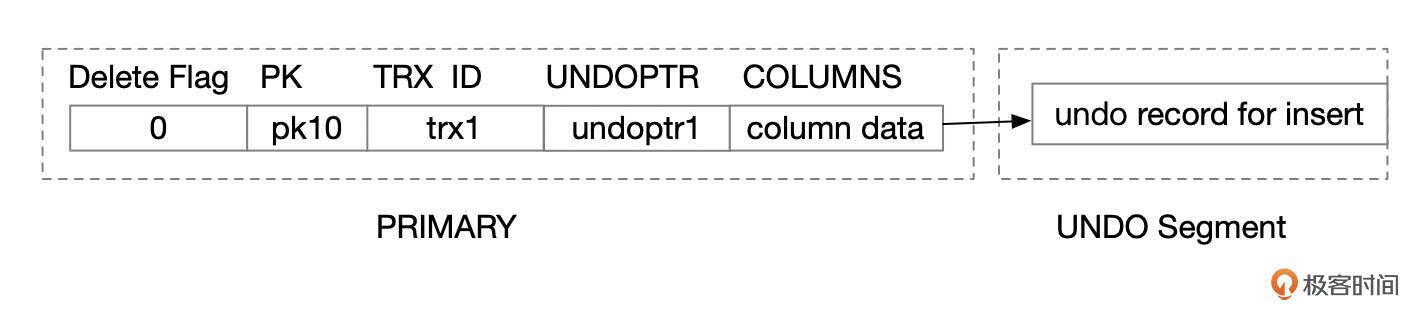
回退INSERT操作其实不需要UNDO记录中的信息。
回退UPDATE操作
对于UPDATE操作,情况就比较复杂了,可大致分为以下情况。
- update之后所有字段长度都没有变长,update可以直接在本地完成。
- update之后记录长度发生了变化,需要在页面内寻找新的空间。也有可能当前页面空间不足,需要分裂当前页面。
- update更新了主键字段。对于B+树,更新key字段相当于进行了delete+insert,先delete原来的记录,再insert新的记录。
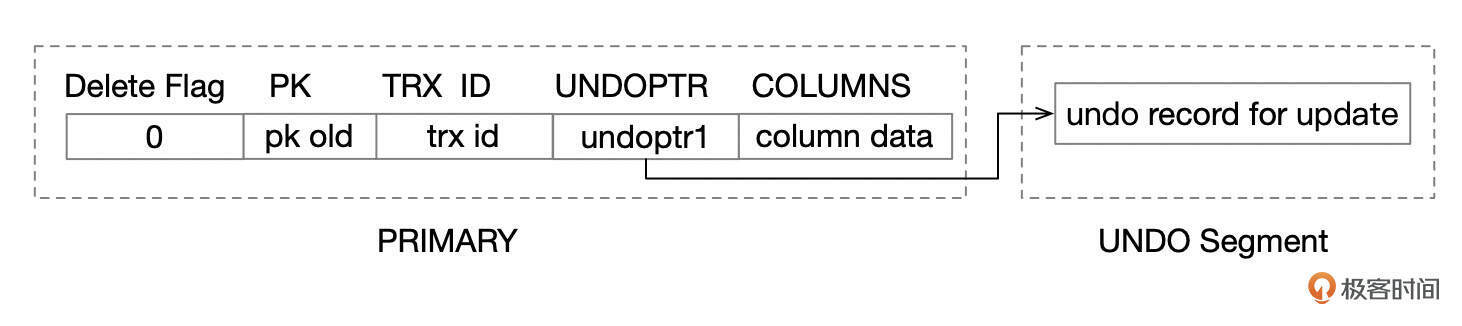
UPDATE没有修改主键字段。
UPDATE修改了主键字段。
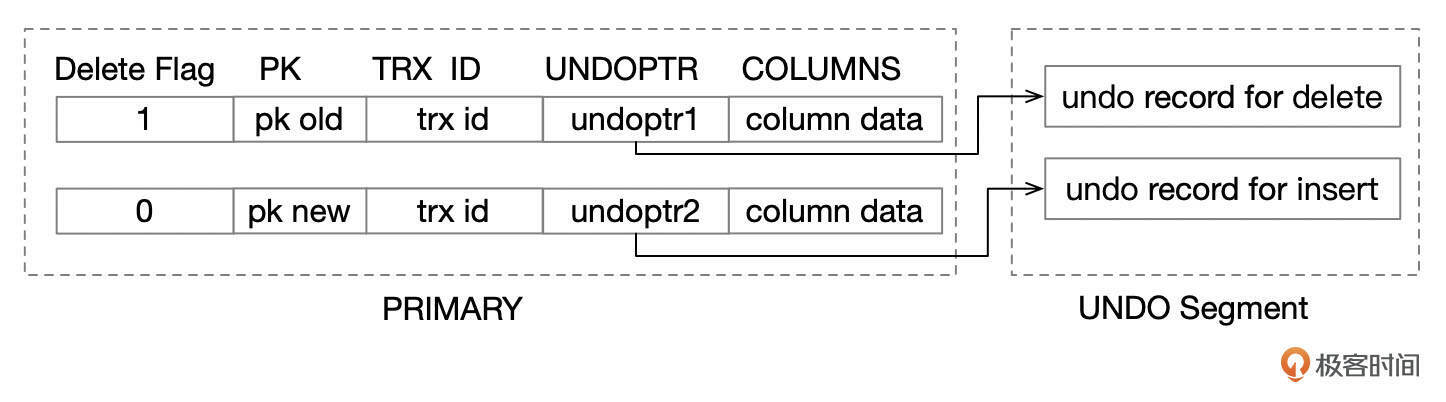
对于不同的情况,UNDO记录的格式有所不同,但是都可以将记录回退到上一个版本。
回退DELETE操作
对于DELETE操作,InnoDB分为两个阶段执行。
- 给记录加上删除标志(delete mark)。
- 事务提交后,如果系统中其他事务都不需要该记录delete之前的版本,就由单独的线程进行purge操作。purge操作将回收标记为已删除的记录占有的空间,也会回收相应的undo段。
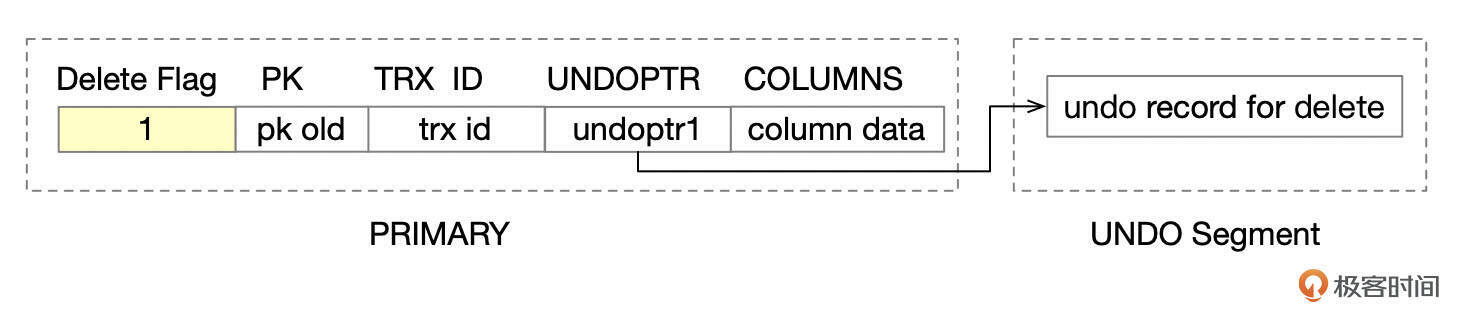
下面这张图中,记录pk10 insert后,更新了两次,最后被delete了,通过Undo,可以构建出记录的任何一个版本。
总结
MVCC是InnoDB的一个重要机制,通过MVCC,MySQL实现了读不阻塞写,写不阻塞读。当然,由于MySQL的实现机制,如果事务一直没提交,Read View一直开着,会导致Undo一直不能清理,Undo表空间就会一直增长,影响数据库的性能,所以需要做好监控。
思考题
InnoDB Purge线程会定期清理Undo日志,但是有些情况下,清理可能会有比较大的延迟,导致Undo表空间持续增长。如何查看系统中有多少Undo日志没有被清理?有哪些原因会导致Undo日志没有及时清理,如何分析?
期待你的思考,欢迎在留言区中与我交流。如果今天的课程让你有所收获,也欢迎转发给有需要的朋友。我们下节课再见!
- binzhang 👍(1) 💬(1)
Some questions: 1) when do delete or insert, why mysql need to save a copy of PK data in undo segment. is it duplicated or just used as undo entry cksum? 2) in your past experience, how many percent of mysql database still use repeatable-read as default consistency level?
2024-11-07 - 笙 鸢 👍(0) 💬(1)
老师,RC级别的read view也是一直开着?等到再次一致性读的时候,更新read view??
2024-12-17