22 数据库应用(二):数据库ORM对象关系映射
你好,我是Barry。
上节课,我们全面认识了数据库,对数据库的基本概念和操作都有了大致了解。不过虽然我们完成了数据库应用的准备阶段,但是还没有把数据库应用在我们的项目里。
这节课,我们继续深入学习数据库应用,熟悉SQL语言应用,并实现数据库与项目的联动。即使你之前没接触过SQL也没关系,只要你跟住我的节奏,就能更高效地掌握数据库的应用技巧。
数据库表的建立
我们都知道,在项目中需要通过编程语言来操作数据库,实现项目中的增、删、改、查等一系列功能。而操作数据库时最常用的就是SQL语言,所以熟练应用SQL是我们操作数据库时必备的一项技能。
在Flask中使用MySQL时,其实你不需要直接编写SQL语句来操作数据库。我们还可以通过ORM框架实现,它的作用是将面向对象编程语言(如Java、Python等)与关系型数据库(如MySQL、Oracle等)进行交互。
认识ORM
ORM本身就是一种编程技术,全称是“对象关系映射”。通俗地说,你可以把ORM看成一种“翻译”技术,它能把数据库中的数据转换成程序中的对象,这样我们就可以像操作对象一样来操作数据库,而不用写一堆复杂的SQL语句了。
实现的过程一般借助Flask中的SQLAlchemy扩展,SQLAlchemy是一个Python编程语言下的SQL工具包和ORM库,提供了SQL表达式操作和ORM映射操作的工具。借助这个工具,我们无需掌握SQL语句,即可实现数据库操作。
下面我给你整理了一张表,来说明SQL中的表和ORM的对应关系。

对照表格可以发现,ORM是将SQL的表格,转换成了我们编程语言当中的类。它的对应关系是整个表格,也就是类;表的行,我们也称为记录,就是类的实例对象;表的列,就是类的属性。
在了解了对应关系之后,我们再来对比一下ORM语句和SQL语句,看看二者在实现数据库操作方面谁更有优势。
我们一起来设想一个场景,比方说我们想建立一个用户信息表user_info,其中包含字段id、nickname、mobile、sex,主键为id,sex可为1,2,0(1为男性,2为女性,0为暂不填写),字段默认值为0。
如果我们通过SQL语言来建立这个表,代码是后面这样。
CREATE TABLE user_info (
id INT PRIMARY KEY,
nickname VARCHAR(255) DEFAULT '0',
mobile VARCHAR(20) DEFAULT '0',
sex INT DEFAULT 0 CHECK(sex IN (1,2,0))
);
这段代码里,我们创建一个名字为 “user_info” 的数据库表,定义了四个字段。
语句PRIMARY KEY 表示设置id为主键。定义nickname和mobile字段时,定义类型VARCHAR,并且还要设置字段长度。DEFAULT “0” 代表设置默认值,由于类型是VARCHAR,也就是字符串型,所以数字 0 需要打上引号,表示成字符。
接下来,我们来看看如何用ORM实现同样的效果。
使用ORM语句,我们就把要建立的表当成一个类来看待,字段就相当于属性。我们对于建立类以及设置其中的属性相对就熟悉很多了。
使用ORM来建立数据库表,主要分成下面两步。
前面我们说过了表和类的关系,所以,使用ORM建表的第一步就是创建一个UserInfo类,这里的类名一般就是我们的表名。如果想指定表名,我们可以使用__tablename__ 这个属性来进行赋值。代码是后面这样。
这里我们用到了__tablename__这个属性,给数据库表的表名赋值为 “user_info”,意思就是用户信息表。
你应该也注意到了,我们在创建类时传入了一个参数db.Model。db是我们后面使用的工具SQLAIchemy的一个实例化对象。我们这里用到的db.Model 就是它的一个基类,用来定义数据库中的模型,并与数据库进行交互。
当一个类继承db.Model后,就可以使用ORM(对象关系映射)的方式来操作数据库。同时,通过继承db.Model,类也会自动获得数据库表的一些基本属性,例如表名、主键等信息。
接下来,我们就来了解一下db.Model模型基类中包含哪些内容,你可以看看后面我做的整理。
__tablename__:表示该模型对应的数据库表名;
主键字段:一般使用id字段作为主键;
列字段:该模型对应的数据库表中的各个列及其数据类型;
属性:通过定义类变量来实现;
关系属性:db.relationship(),用于定义不同表之间的关系;
查询类:包含了常见的查询方法,如all()、filter()、order_by()等。
db.Column类:用来定义列和它们的属性;
db.session对象:用于在数据库中进行查询、插入、修改和删除等操作。
第二步,我们需要创建表的列,也就是字段,这一点可以借助db.Column()类来实现。其中的第一个参数为该字段的数据类型。所有字段的创建必须要有第一个参数,至于其余参数,我们可以根据需求灵活添加。
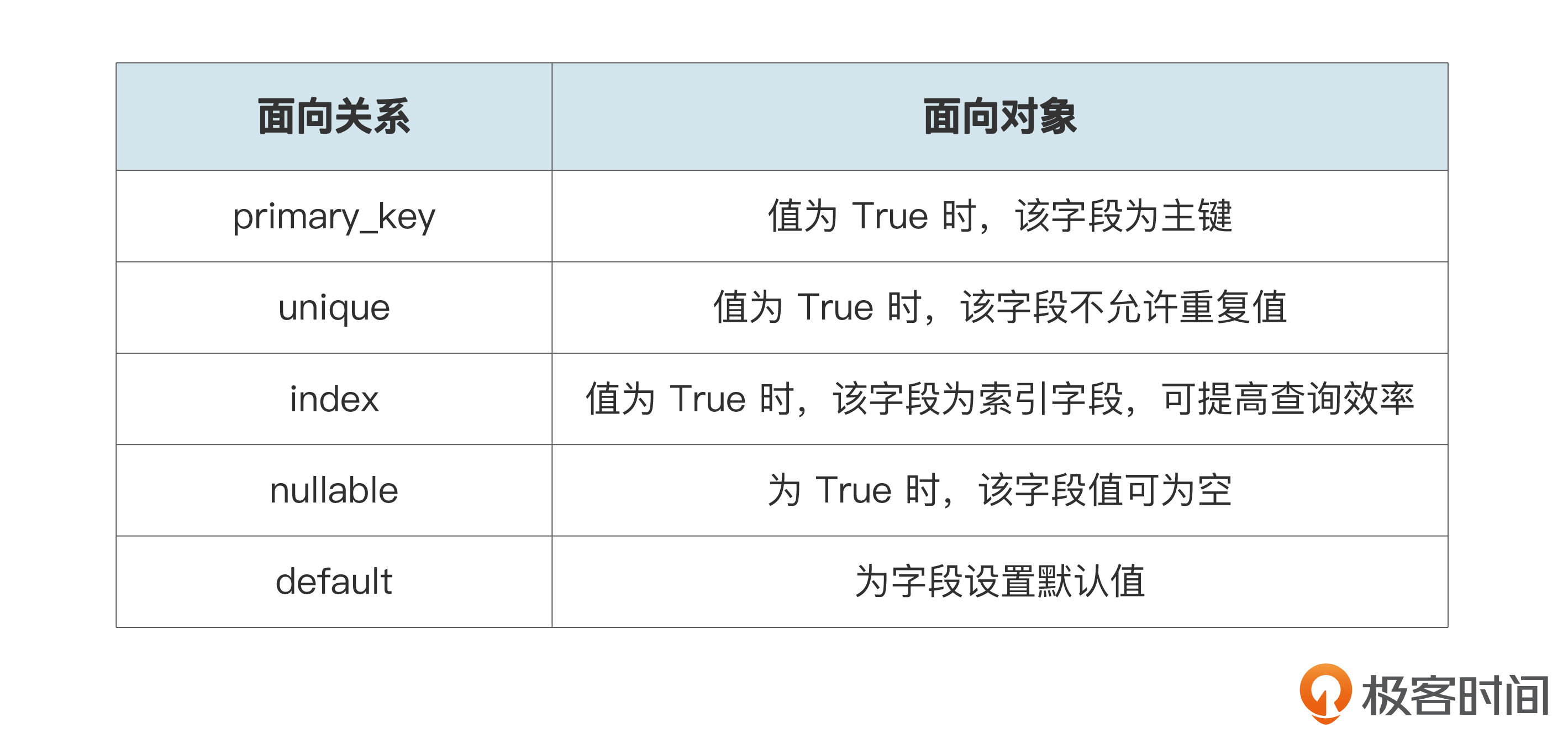
其中SQLAIchemy中的字段参数,对应的含义和作用我给你写在了下面,你可以参考一下。
后面就是创建过程的代码。
class UserInfo(db.Model):
"""用户信息表"""
__tablename__ = "user_info" # 表名
# id
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
nickname = db.Column(db.String(64), nullable=False) # 用户昵称
mobile = db.Column(db.String(16)) # 手机号
sex = db.Column(db.Enum('0', '1', '2'), default='0')
# 1=男,2=女,0=暂不填写,默认值为
创建表的过程中,我们重点要关注如何定义表的字段,也就是数据库表中的列,它是由db.Column类的实例来表示的。我们通过Column类构造方法的第一个参数传入来设定字段的类型。
例如我们在定义id时,把它的数据类型设置为int整数型,并通过primary_key=True把id设置为主键。autoincrement=True是指将该字段设置为自增长属性,代表着每次插入数据时自动增加1。
换句话说,我们在往数据库里增添信息时,不需要指定id这个主键的值为多少,这样我们在新增的时候就不需要再单独设置id的值,主键的值会自动随信息的增长而增长。
你会发现定义id和定义nickname时,一个使用了语句db.Integer,另一个使用db.String(64)。这是因为它们的数据类型是不同的,id为整数型,nickname为字符串型。
我用表格的形式整理了SQLAlchemy字段类型和SQL字段类型的对应关系,供你参考。
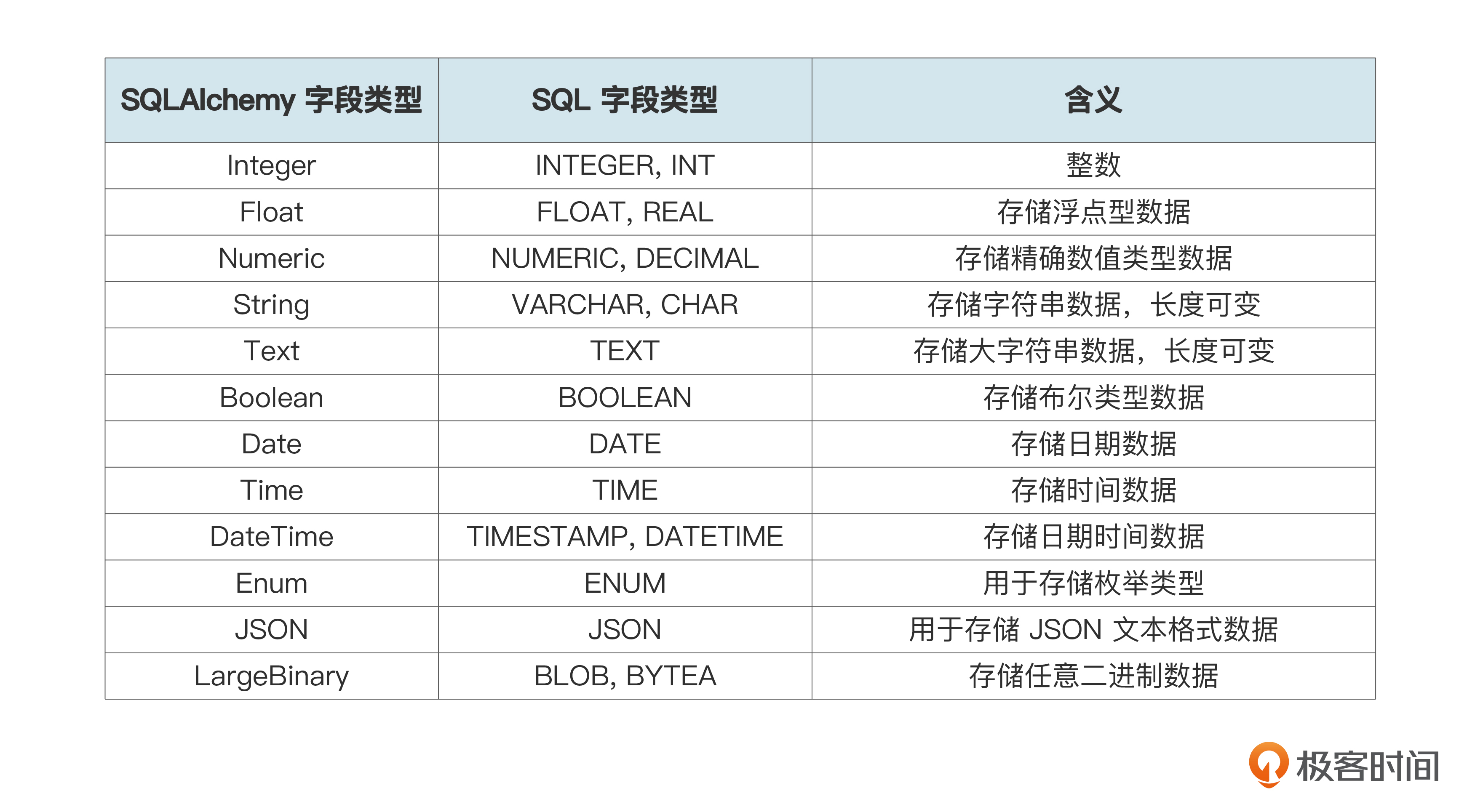
表的内容较多,但你不用刻意去记忆。效率更高的方法是:在定义过程中,需要使用哪个再查看哪个,多练习使用一阵儿,这样自然而然就记住了。
设计数据库表
我们之前讲过数据库和表的概念,还介绍了两个工具MySQL和Navicat。现在,我们用ORM简化SQL语句,通过定义类和属性就能创建数据库表。在我们实际项目开发数据库中的重点就在于如何设计数据库表。
接下来,我会以用户信息表为例,带你熟悉从数据库字段设计到创建表,再到增删改查操作的整个过程。在日常开发中 ,在设计各种业务模块使用的数据库表之前,我们通常需要先定义一个模型基类,其中包含每个数据库表都需要使用的字段,就像后面这样。
class BaseModels:
"""模型基类"""
# 创建时间
create_time = db.Column(db.DateTime, default=datetime.now)
# 记录你的更新时间
update_time = db.Column(db.DateTime, default=datetime.now, onupdate=datetime.now)
# 记录存活状态
status = db.Column(db.SmallInteger, default=1)
def add(self, obj):
db.session.add(obj)
return session_commit()
def update(self):
return session_commit()
def delete(self):
self.status = 0
return session_commit()
在模型基类中,定义三个通用的属性,分别是创建时间、更新时间、存活状态。比如在我们的用户信息表中,用户在什么时候注册、何时更新了个人信息,还有注销用户操作,这些功能的实现都需要用到前面这三个通用属性。
定义好了模型基类,我们还需要定义具体的用户数据库表。我给你做了一个思维框架图,罗列出了表中需要的字段。

在整个用户信息表中,我们首先需要设置好数据库的主键id,将其设置为随数据数量默认递增的状态。其他字段,像昵称、手机号、个性签名等等这些,都是在平台里面常用到的一些字段,我们也把它们设置为用户信息表的字段。
设置好了字段,别忘了设置好相应的数据类型。这部分的内容,我们在讲ORM和SQL语句的对比时已经讲过了,你可以查看字段对应表,自己设置匹配即可。
解决了字段和字段的数据类型的问题,我们再来看看使用ORM语句建立数据库表实现的具体代码。后面是我写的代码,之后的实践过程中你可以参考或者直接使用。
class UserInfo(BaseModels, db.Model):
"""用户信息表"""
__tablename__ = "user_info"
id = db.Column(db.Integer, primary_key=True, autoincrement=True) # 用户id
nickname = db.Column(db.String(64), nullable=False) # 用户昵称
mobile = db.Column(db.String(16)) # 手机号
avatar_url = db.Column(db.String(256)) # 用户头像路径
signature = db.Column(db.String(256)) # 签名
sex = db.Column(db.Enum('0', '1', '2'), default='0') # 1男 2 女 0 暂不填写
birth_date = db.Column(db.DateTime) # 出生日期
role_id = db.Column(db.Integer) # 角色id
last_message_read_time = db.Column(db.DateTime)
整个创建过程和前面讲的案例大同小异,相信你看过代码注释之后,就能明白它的实现过程。
项目与数据库连接
了解了数据库表的创建过程,我们还得让数据库和项目联动起来,这是日常开发里不可缺少的一个环节,不然项目是无法使用的。而联动的前提就是保证后端代码和数据库保持联通。
那怎么实现项目与数据库的链接,让程序“活”起来呢?接下来我们就分步骤来实践一下。
首先,我们先使用Navicat工具连接数据库,上节课我给你演示过如何连接,Windows和macOS连接方法大同小异,只要保证你数据库相关信息是正确的就可以。
连接成功后,你看到的界面会是下面这个样子。
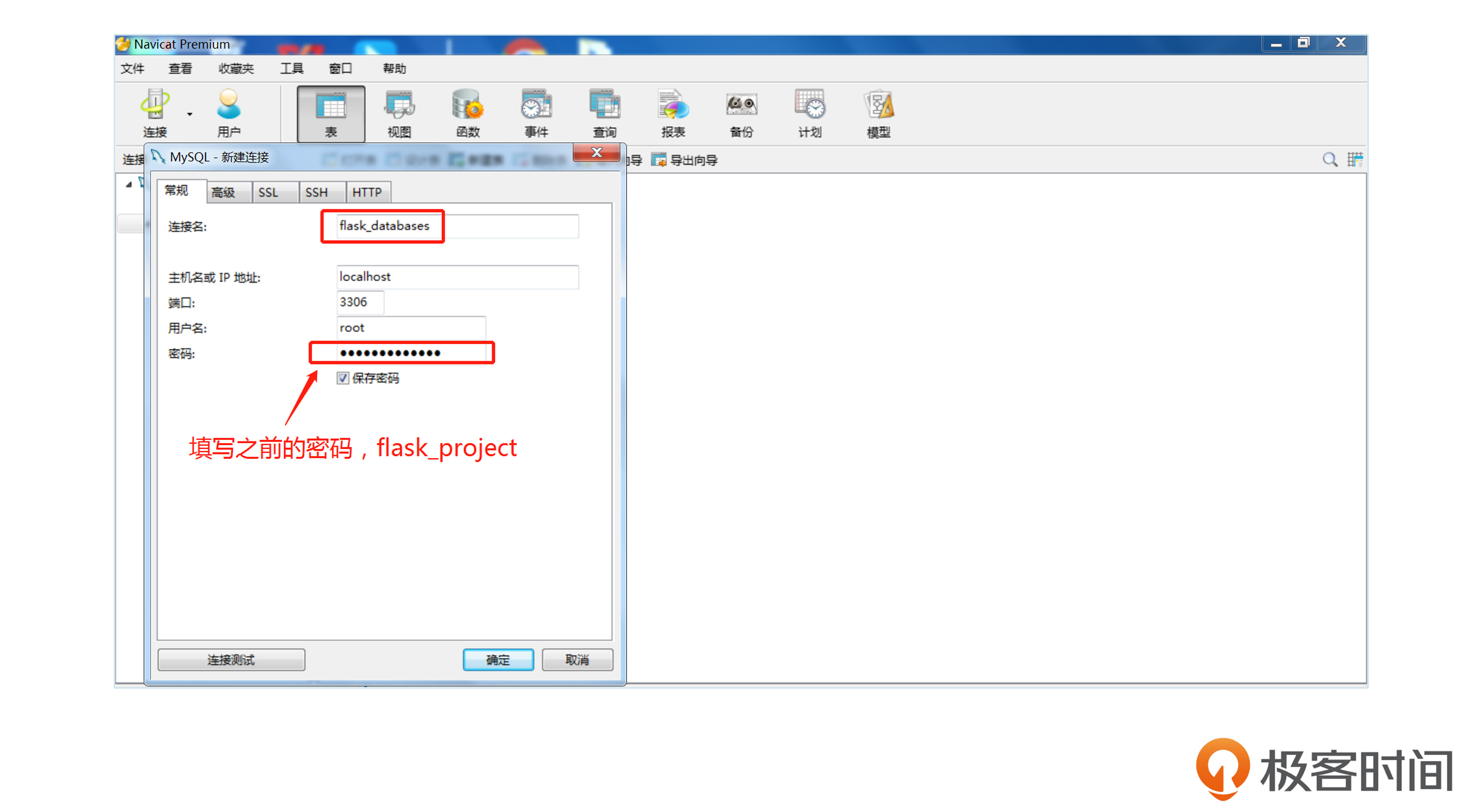
输入密码并点击确定之后,如果界面显示后面截图的界面,就表示我们安装成功了。
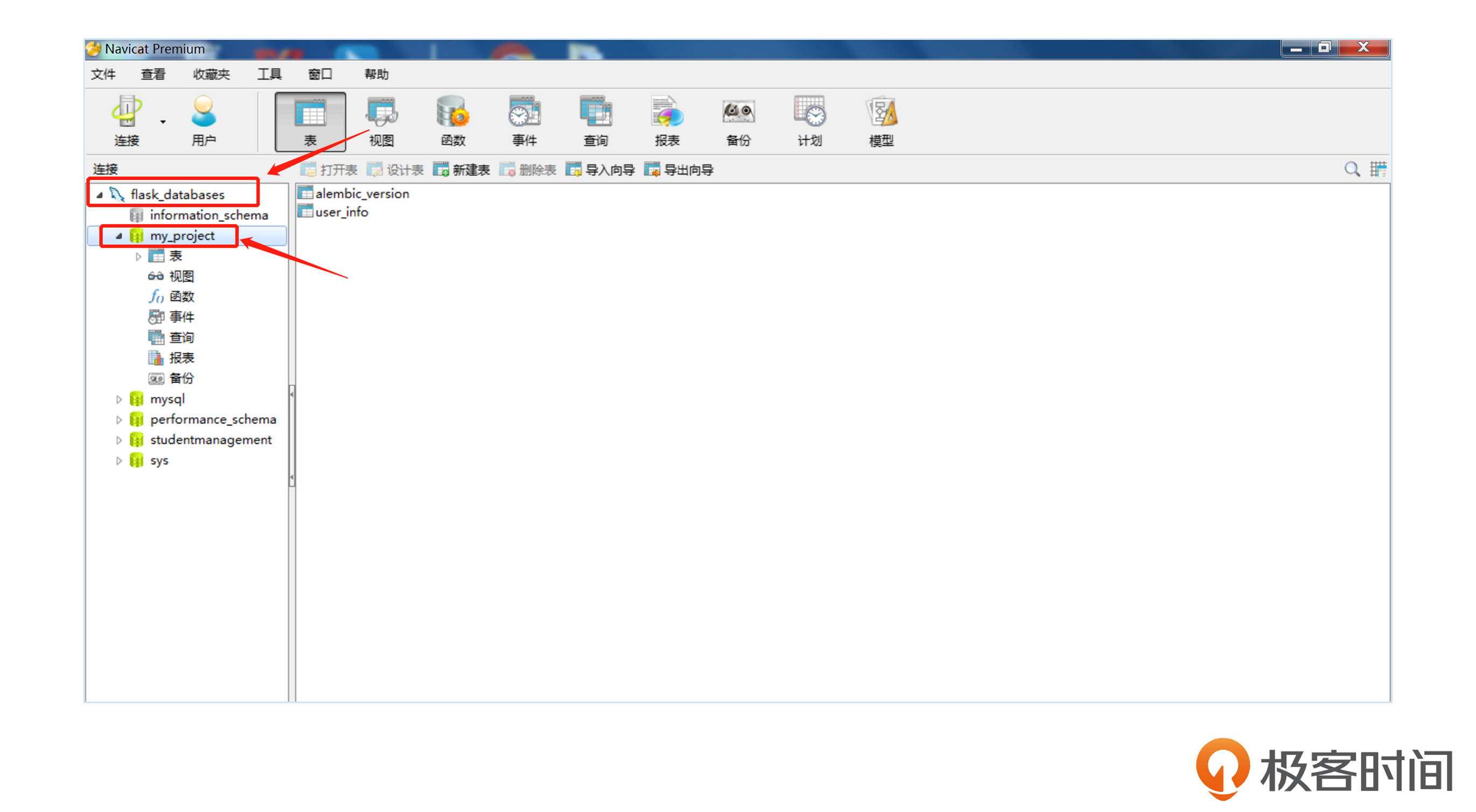
紧接着,我们在代码中进行设置和连接。我们先安装好需要的SQLAIchemy库,具体的执行命令是后面这样。
在安装成功之后,我们在practice文件下新建lb_04.py文件,它主要的作用就是在Flask应用中连接到MySQL数据库服务器。
import pymysql
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
connection = pymysql.connect(
host='127.0.0.1', # 数据库IP地址
port=3306, # 端口
user='root', # 数据库用户名
password='flask_project', # 数据库密码
database='flask_databases' # 数据库名称
)
return "恭喜,MySQL数据库已经连接上"
if __name__ == "__main__":
app.run()
前面代码里的函数hello()用于连接MySQL数据库,具体就是使用pymysql库中的connect()函数来建立连接,传递数据库服务器IP地址、端口、用户名、密码和数据库名称等参数。
如果连接成功,函数会返回一条消息,提示MySQL数据库已经连接成功;否则,就会返回错误消息。运行成功后,我们用浏览器打开http://127.0.0.1:5000,就能看到连接成功的提示。对应的启动效果如下图所示。
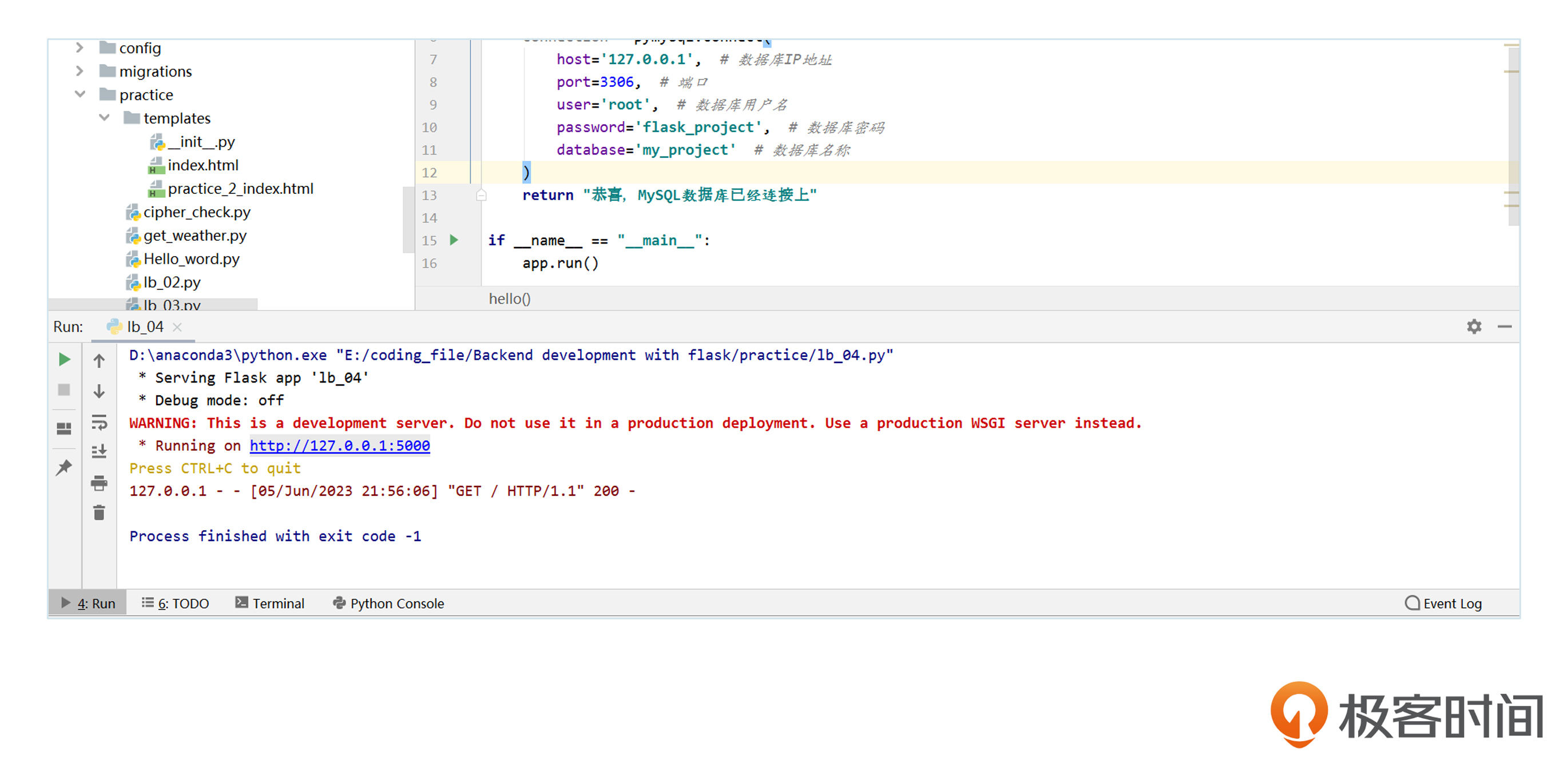
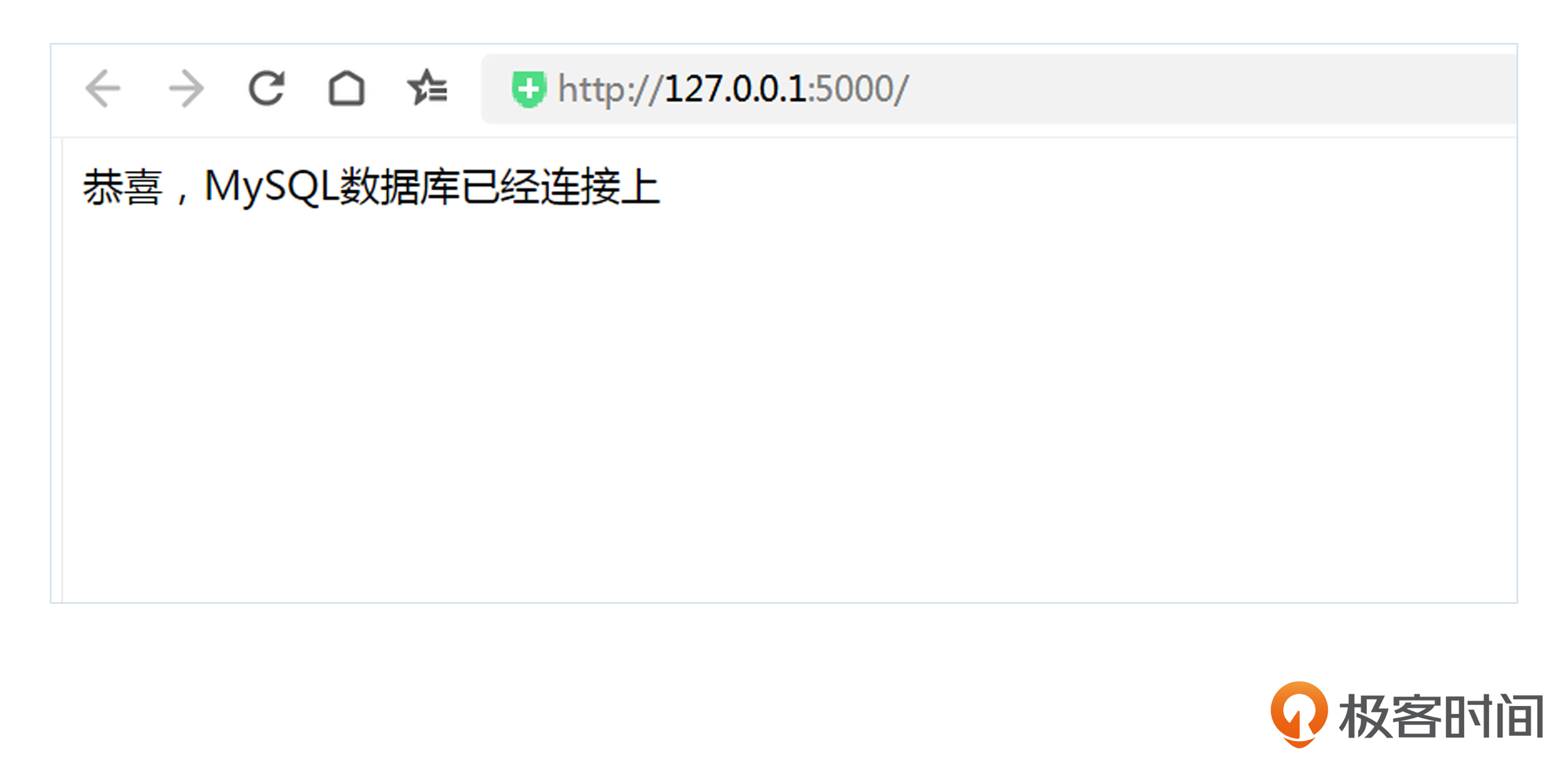 到这里,我们已经实现了数据库的连接,之后你应对项目开发过程中的数据库连接问题时,相信就能轻松解决了。
到这里,我们已经实现了数据库的连接,之后你应对项目开发过程中的数据库连接问题时,相信就能轻松解决了。
总结
又到了课程的尾声,这节课我们掌握了表的创建和数据库的连接,实现了项目与数据库的联动。接下来,我带你做个总结回顾。
相比传统SQL语句,使用ORM来创建数据库表更方便高效。ORM的实现过程一般借助SQLAlchemy扩展,SQLAlchemy提供了SQL表达式操作和ORM映射操作的工具。
整个创建表的过程分为两步:第一步,使用ORM建表。这里你需要重点关注db.Model模型基类中的内容,明确其属性含义;第二步则是创建表的列,也就是字段,我们借助db.Column()类来实现。重点就是创建表的过程里,一定要把对应字段的数据类型设定正确,这样才能避免后面的开发出问题。
在数据库表创建实践部分,我们熟悉了数据库字段设计到创建表,再到增删改查操作的全过程。这里的重点就是设计表前,我们需要在模型基类中定义三个通用属性,分别是创建时间、更新时间、存活状态。这也是在表创建过程中共用的属性。
之后我们完成了项目与数据库的连接。如何用Navicat工具连接数据库这一点,相信你已经轻车熟路了。重点在于我们通过pymysql连接数据库时,你要明确数据库配置信息参数的作用,而且要保证参数信息一定要正确,这样才能成功连接。
下节课我们还会解锁数据库操作的更多“秘籍”,敬请期待。
思考题
在项目开发中,对于平台用户删除操作,你认为该用户信息真的会从数据库中删除么?为什么?
欢迎你在留言区和我交流互动,如果这节课对你有帮助的话,别忘了分享给身边更多朋友。
- 长林啊 👍(1) 💬(1)
在项目开发中,不会对用户的信息直接从库中删除,而是通过一些字段标识进行软删除,比如国内一些应用注销账号的时候,会有一个确认期(半个月),如果在确认期内撤回注销账号,就可以很快的恢复数据;还可以对用户流失的分析提供数据支持
2023-06-20 - 因为有你心存感激 👍(0) 💬(1)
创建的模型,怎么变成数据库中的表呀?
2024-11-28 - 蜡笔小新爱看书 👍(0) 💬(1)
db.Model的db怎么实例化的?完整代码能给一下吗,还有文件的命名,最好也给出一下
2023-08-17 - 浩仔是程序员 👍(0) 💬(1)
你好,老师,这个是会自动建表,还是需要手动建表,然后再写ORM对象
2023-06-15 - ZENG 👍(0) 💬(1)
现在都是逻辑删除,多增加一个已删除字段,默认为0,比如删除了就设置为1,这样也能保留原始信息,给用户也好给公司分析也好
2023-06-12 - peter 👍(0) 💬(2)
Q1:python是动态语言,是弱类型语言,对吗? Q2:老师公司的视频网站,用什么推荐算法?
2023-06-12 - Sasori 👍(0) 💬(1)
一般开发项目的过程中是用这种orm方式调用数据库还是直接写sql 哪种办法多呀
2024-10-30