大模型时代的AI for Security
你好,我是何为舟。
今天我们来聊聊大模型,以及大模型会对安全领域产生哪些影响。一定程度上来说,我是不太想公开来聊这个话题的。大模型仍然处于发展初期,未来的形态充满着变数和不确定性,现阶段看似合理的认知和理解,在不久的将来可能会变得可笑和愚昧。因此,本节内容仅做参考,有不同的观点欢迎表达交流。
在正式开始之前,也建议你先对大模型的基础原理有大致了解,最好自己动手尝试过制作一些基于大模型的机器人或Agent应用,这样能够更好地理解大模型在安全领域的应用场景。
大模型与传统模型的差异
AI for Security这个命题显然不是大模型时代才有的,从AI诞生起,安全从业者们就开始尝试使用各种各样的AI算法来解决规则体系的复杂性问题。你一定在各种各样的安全大会和PR稿上见到过各种AI成功应用的案例(我也这么干过),但在我看来,没有哪个案例是真正因为AI起到了质变效果的。
导致这个现象的主要矛盾在于安全是具备强对抗属性的,攻击者总是会根据防守形态做出调整,就相当于AI遇到的是一个持续在变化的样本分布。这需要我们构建出一种能够快速迭代的AI框架,而实时生成带标签的训练数据难度较高(部分案例有尝试用无监督算法来弥补),因此很难达到理想效果。
那为什么大模型会给安全从业者带来这么大的轰动呢?我认为最直接的原因是“不用训练”了。当ChatGPT首次问世以来,可以0-shot回答各类问题,确实让我们对AI的理解产生了很大的迭代。过去还得苦哈哈地准备各种训练数据、玄学调参,现在只需要简单编写Prompt,就能够得到看似不错的结果,这就是大模型和传统模型的最直接差异。
大模型不适合干什么
在探讨大模型能够在哪些安全场景发挥作用时,我想先简单聊聊大模型不适合干什么。因为我感觉很多安全人员在用大模型的时候,并不是觉得大模型好用,而是纯粹不懂算法,而恰好大模型把算法的使用门槛大幅降低了。
个人认为,大模型并不适合处理传统有监督模型擅长处理的分类、打标等问题。对于这类问题,通常是有强准召率和鲁棒性要求的,即使出现一些误判,也要具备可解释和可调整的空间。而大模型恰恰是不具备这种特质的:一方面,大模型是生成式模型,自带了较强的随机性,发挥并不稳定,对同一个问题可能产生不同的判断;另一方面,大模型是预训练模型,尽管可以进行微调,但实测下来少量训练数据对结果的影响度并不高。
除了模型能力上的局限性,大模型的高额使用成本,也意味着其并不适合去执行密集型的数据处理工作。业界有利用大模型训练小模型,从而弥补成本劣势的尝试,但就我看来,多少有一点本末倒置了。
大模型适合干什么
尽管对于明确性的任务,大模型表现并不好,但安全领域其实有着大量的模糊性工作(如告警运营、漏洞修复等)。而大模型的生成式和预训练,恰恰在应对这类工作时表现出了优越的性能。下面就具体介绍一下我认为比较合适的几个场景。
面向安全人员的告警运营助手
运营工作是长期困扰安全人员的一个事情,处理起来枯燥乏味,但却需要极强的专业能力和经验支撑,才能高质量完成。实际的操作过程,基本是安全人员根据一条告警或者线索,展开排查工作,查询各种关联数据,判断合理性,给出最终决策。所有人都希望这个过程能够自动化,所以业界推出了SOAR这种产品概念,但实际效果不尽如人意。其根本难点在于,处理过程看似重复,但深入到细节却各不一样,靠人工编排来穷举所有的运营过程,几乎不可能。
而大模型带来了想象的空间,尤其是AI Agent的概念,兼顾任务规划、功能执行、结果处理等运营过程的必备流程。以现阶段的LLM能力,应当可以打造成一个运营助手,主要功能包括:记录运营过程、给出运营建议、执行额外的查询操作、总结运营结果等。整体流程如下:
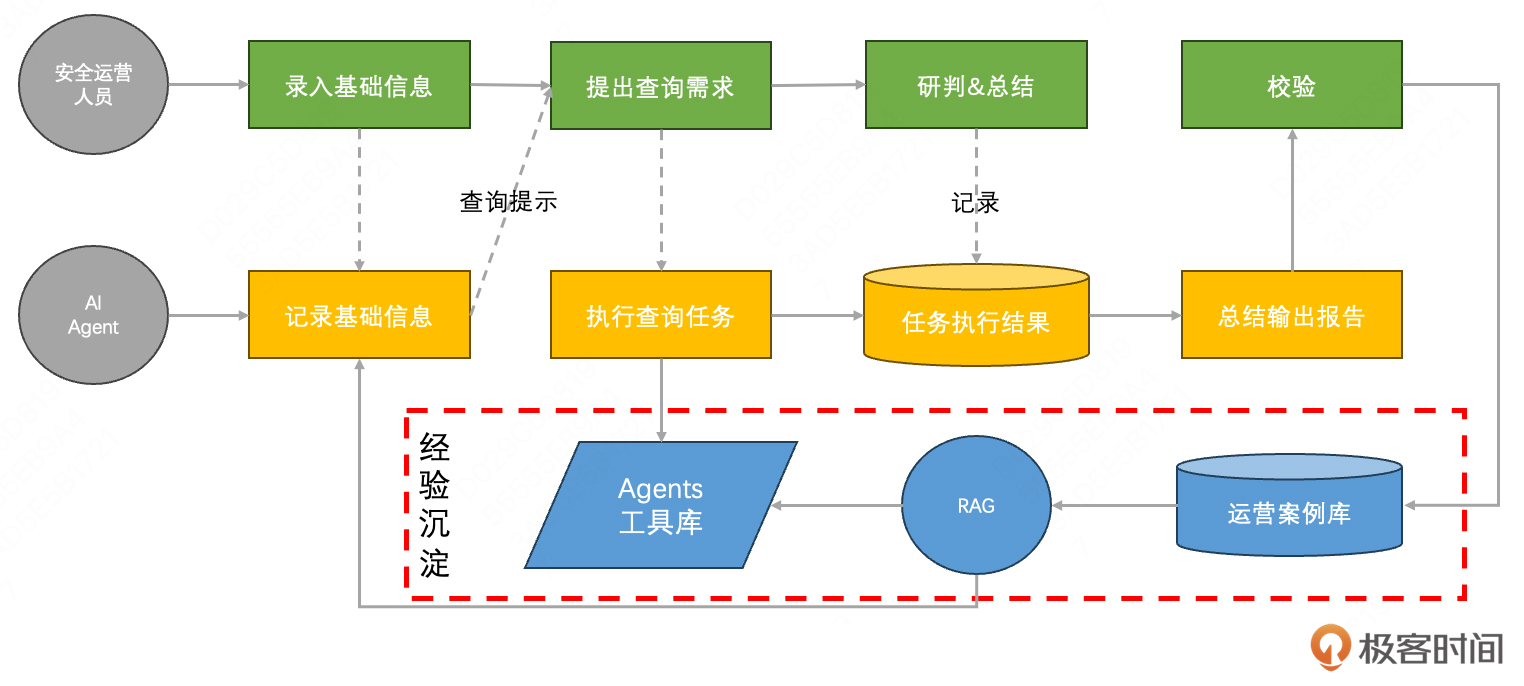 这里面的主要难点,一方面在于工具库的实现会相当复杂(可以参考SIEM需要对接各种安全工具的痛苦);另一方面,它并不为高等级的安全人员提效,而是提供一种总结经验和案例的渠道,然后用于指导低等级的安全人员来完成运营工作。
这里面的主要难点,一方面在于工具库的实现会相当复杂(可以参考SIEM需要对接各种安全工具的痛苦);另一方面,它并不为高等级的安全人员提效,而是提供一种总结经验和案例的渠道,然后用于指导低等级的安全人员来完成运营工作。
面向研发人员的漏洞修复助手
指导研发人员修复漏洞,同样是一个折磨人的工作。当你向研发人员提出一个漏洞工单的时候,他们可能会以不懂安全为由,要求你提供具体的修复方案。尽管行业内通常都会尝试提供FAQ,让研发人员自己去学习,但就我认知到情况,研发人员通常不那么“听话”,不乐意去完成这类安全相关的“分外”工作。安全和研发的矛盾基本来源于此。
而大模型似乎可以成为连接两者的桥梁。通过海量数据的预训练,大模型具备了极宽的知识储备,既能够写出简单的代码,也能够理解安全的诉求。其工作流程如下:
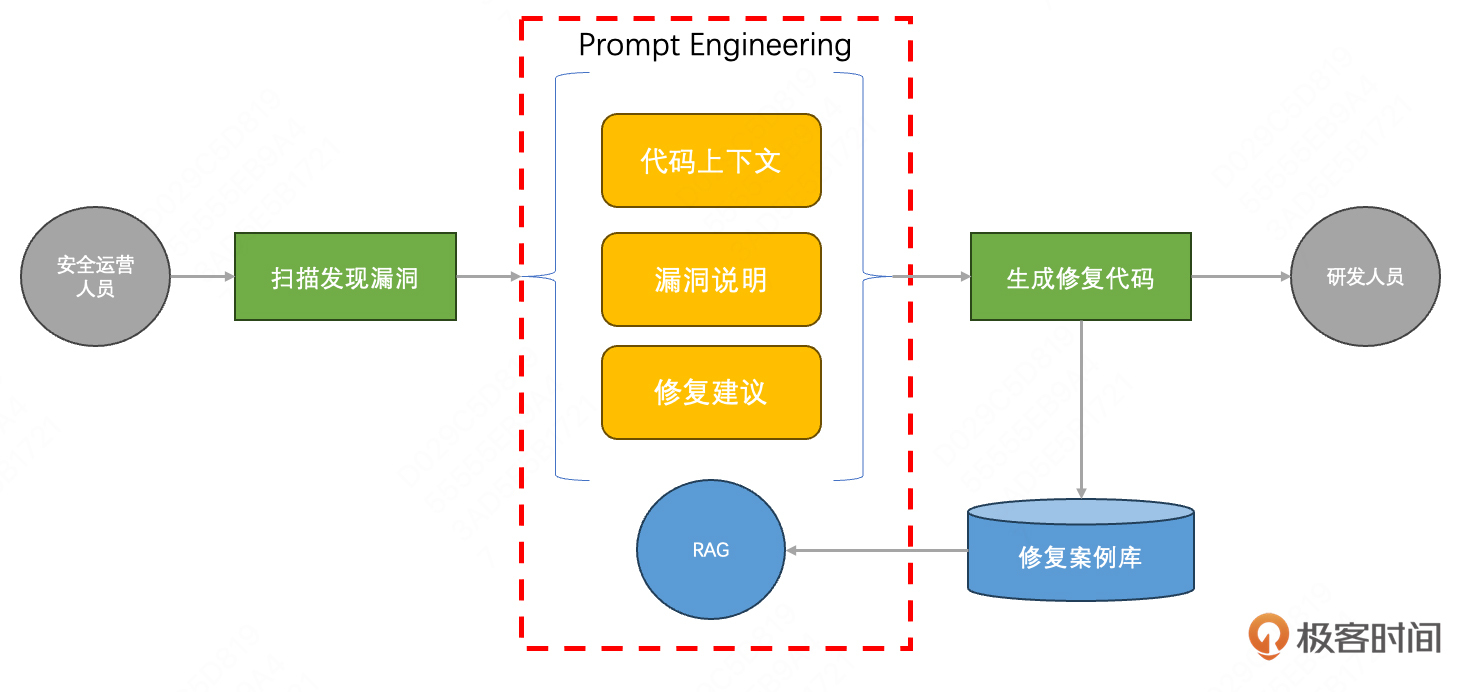
值得强调的是,我仍然不建议使用大模型去处理漏洞扫描的工作,那本质上是一种分类问题,基于规则的扫描器和传统有监督算法更适合处理。生成修复代码这种生成型的任务,才是大模型最擅长的领域。
配合扫描器完成深度的漏洞挖掘
漏洞挖掘的过程通常是一个安全人员和工具配合的过程。比如Fuzz技术,会需要安全人员设计初始种子和变异策略,来实现更高的代码覆盖度,从而挖掘隐藏较深的漏洞。这个设计过程相对依靠经验,所以过去很难被自动化。
而大模型其实就是替代人工经验的一种有效尝试。2024年底,Google的Project Zero团队,就利用大模型辅助其Fuzz工具,成功挖掘出了SQLite、OpenSSL等知名开源项目中的0day漏洞。实现原理也非常直接,就是在传统的Fuzz过程中,将人工调整的过程变更为大模型的Prompt。这一定程度上代表着大模型在漏洞挖掘这一方向上的成功实践。
总结
今天我主要讲了对大模型的理解,并且列举了几个大模型在安全领域比较适用的场景。总结来说,我认为运用大模型的时候要讲究几个技巧:
- 大模型不是万能的,对于二分类或者多分类场景,并不适合使用大模型。仅当输出比较广泛的时候,才能够发挥大模型生成式的最大效用。
- 任务有相对固定的输入和输出模式,但中间过程有需要依赖人工经验的地方,通常这里就是大模型的勇武之地。如开发应用的输入是需求,输出是代码,具体怎么写,过去依靠人,现在可以依靠大模型。
- 现阶段的大模型并不能帮助高级人员提效,但可以总结高级人员的经验,从而辅助其他人员更好地完成任务。
最后我想说,目前是一个动荡的年代,大模型的技术发展与日俱新,今天的成功经验也许会变成明天的无厘头笑话。但这并没有什么可畏惧的,唯有与之俱新,保持学习和尝试,才能跟上时代的步伐,不被时代所淘汰。
如果你有新的想法,欢迎在留言区一起和我分享和交流,我们下一节见。