05丨指标关系:你知道并发用户数应该怎么算吗?
我在性能综述的那三篇文章中,描述了各种指标,比如TPS、RPS、QPS、HPS、CPM等。我也强调了,我们在实际工作的时候,应该对这些概念有统一的认识。

这样的话,在使用过程中,一个团队或企业从上到下都具有同样的概念意识,就可以避免出现沟通上的偏差。
我说一个故事。
我以前接触过一个咨询项目。在我接触之前,性能测试团队一直给老板汇报着一个数据,那就是10000TPS。并且在每个版本之后,都会出一个性能测试报告,老板一看,这个数据并没有少于10000TPS,很好。 后来,我进去一看,他们一直提的这个10000TPS指的是单业务的订单,并且是最基础的订单逻辑。那么问题来了,如果混合起来会怎么样呢?于是我就让他们做个混合容量场景,显然,提容量不提混合,只说单接口的容量是不能满足生产环境要求的。
结果怎么样呢?只能测试到6000TPS。于是我就要去跟老板解释说系统达到的指标是6000TPS。老板就恼火了呀,同样的系统,以前报的一直是10000TPS,现在怎么只有6000TPS了?不行,你们开发的这个版本肯定是有问题的。于是老板找到了研发VP,研发VP找到了研发经理,研发经理找了研发组长,研发组长又找到了开发工程师,开发工程师找到了我。我说之前不是混合场景的结果,现在混合容量场景最多达到6000TPS,你们可以自己来测。
然后证明,TPS确实只能达到6000。然后就是一轮又一轮的向上解释。
说这个故事是为了告诉你,你用TPS也好,RPS也好,QPS也好,甚至用西夏文来定义也不是不可以,只要在一个团队中,大家都懂就可以了。
但是,在性能市场上,我们总要用具有普适性的指标说明,而不是用混乱的体系。
在这里,我建议用TPS做为关键的性能指标。那么在今天的内容里,我们就要说明白TPS到底是什么。在第3篇文章中,我提到过在不同的测试目标中设置不同的事务,也就是TPS中的T要根据实际的业务产生变化。
那么问题又来了,TPS和并发数是什么关系呢? 在并发中谁来承载”并发“这个概念呢?
说到这个,我们先说一下所谓的“绝对并发”和“相对并发”这两个概念。绝对并发指的是同一时刻的并发数;相对并发指的是一个时间段内发生的事情。
你能详细说一下这两个概念之间的区别吗?如果说不出来那简直太正常了,因为这两个概念把事情说得更复杂了。
什么是并发
下面我们就来说一下“并发”这个概念。
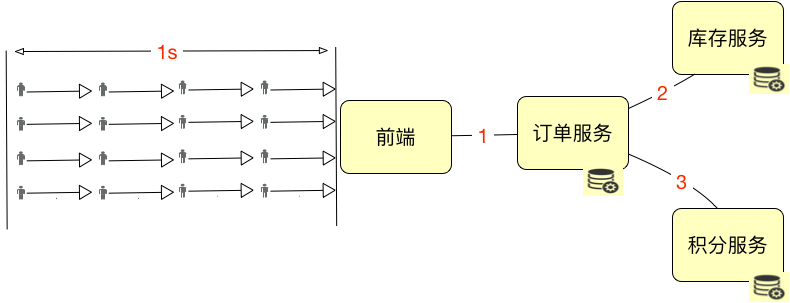
我们假设上图中的这些小人是严格按照这个逻辑到达系统的,那显然,系统的绝对并发用户数是4。如果描述1秒内的并发用户数,那就是16。是不是显而易见?
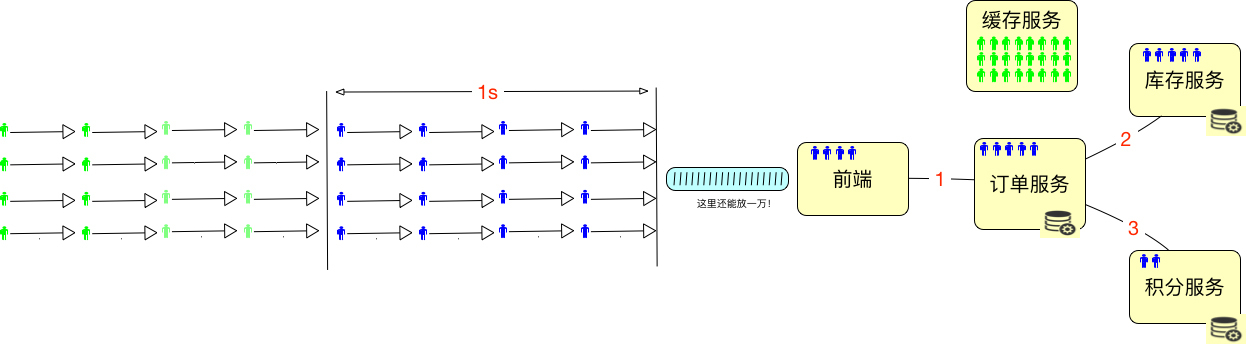
但是,在实际的系统中,用户通常是这样分配的:
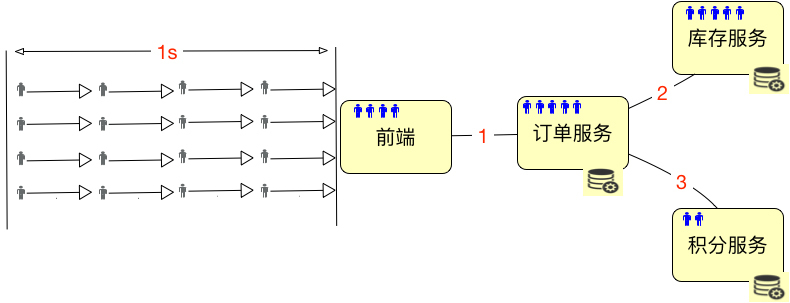
也就是说,这些用户会分布在系统中不同的服务、网络等对象中。这时候”绝对并发“这个概念就难描述了,你说的是哪部分的绝对并发呢?
要说积分服务,那是2;要说库存服务,那是5;要说订单服务,它自己是5个请求正在处理,但同时它又hold住了5个到库存服务的链接,因为要等着它返回之后,再返回给前端。所以将绝对并发细分下去之后,你会发现头都大了,不知道要描述什么了。
有人说,我们可以通过CPU啊,I/O啊,或者内存来描述绝对并发,来看CPU在同一时刻处理的任务数。如果是这样的话,绝对并发还用算吗?那肯定是CPU的个数呀。有人说CPU 1ns就可以处理好多个任务了,这里的1ns也是时间段呀。要说绝对的某个时刻,任务数肯定不会大于CPU物理个数。
所以“绝对并发”这个概念,不管是用来描述硬件细化的层面,还是用来描述业务逻辑的层面,都是没什么意义的。
我们只要描述并发就好了,不用有“相对”和“绝对”的概念,这样可以简化沟通,也不会出错。
那么如何来描述上面的并发用户数呢?在这里我建议用TPS来承载“并发”这个概念。
并发数是16TPS,就是1秒内整个系统处理了16个事务。
这样描述就够了,别纠结。
在线用户数、并发用户数怎么计算
那么新问题又来了,在线用户数和并发用户数应该如何算呢?下面我们接着来看示意图:
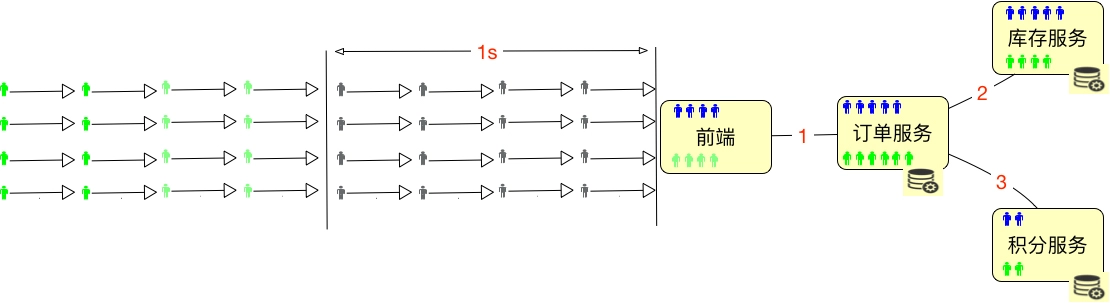
如上图所示,总共有32个用户进入了系统,但是绿色的用户并没有任何动作,那么显然,在线用户数是32个,并发用户数是16个,这时的并发度就是50%。
但在一个系统中,通常都是下面这个样子的。
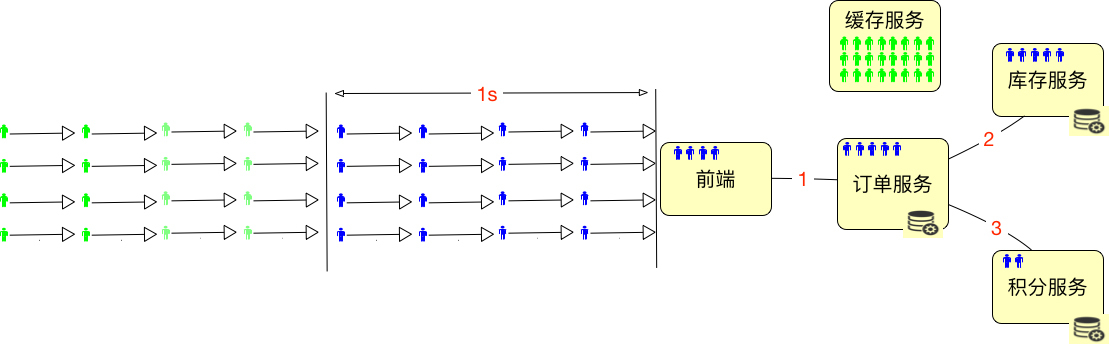
为了能hold住更多的用户,我们通常都会把一些数据放到Redis这样的缓存服务器中。所以在线用户数怎么算呢,如果仅从上面这种简单的图来看的话,其实就是缓存服务器能有多大,能hold住多少用户需要的数据。
最多再加上在超时路上的用户数。如下所示:
所以我们要是想知道在线的最大的用户数是多少,对于一个设计逻辑清晰的系统来说,不用测试就可以知道,直接拿缓存的内存来算就可以了。
假设一个用户进入系统之后,需要用10k内存来维护一个用户的信息,那么10G的内存就能hold住1,048,576个用户的数据,这就是最大在线用户数了。在实际的项目中,我们还会将超时放在一起来考虑。
但并发用户数不同,他们需要在系统中执行某个动作。我们要测试的重中之重,就是统计这些正在执行动作的并发用户数。
当我们统计生产环境中的在线用户数时,并发用户数也是要同时统计的。这里会涉及到一个概念:并发度。
要想计算并发用户和在线用户数之间的关系,都需要有并发度。
做性能的人都知道,我们有时会接到一个需求,那就是一定要测试出来系统最大在线用户数是多少。这个需求怎么做呢?
很多人都是通过加思考时间(有的压力工具中叫等待时间,Sleep时间)来保持用户与系统之间的session不断,但实际上的并发度非常非常低。
我曾经看到一个小伙,在一台4C8G的笔记本上用LoadRunner跑了1万个用户,里面的error疯狂上涨,当然正常的事务也有。我问他,你这个场景有什么意义,这么多错?他说,老板要一个最大在线用户数。我说你这些都错了呀。他说,没事,我要的是Running User能达到最大就行,给老板交差。我只能默默地离开了。
这里有一个比较严重的理解误区,那就是压力工具中的线程或用户数到底是不是用来描述性能表现的?我们通过一个示意图来说明:

通过这个图,我们可以看到一个简单的计算逻辑:
- 如果有10000个在线用户数,同时并发度是1%,那显然并发用户数就是100。
- 如果每个线程的20TPS,显然只需要5个线程就够了(请注意,这里说的线程指的是压力机的线程数)。
- 这时对Server来说,它处理的就是100TPS,平均响应时间是50ms。50ms就是根据1000ms/20TPS得来的(请注意,这里说的平均响应时间会在一个区间内浮动,但只要TPS不变,这个平均响应时间就不会变)。
- 如果我们有两个Server线程来处理,那么一个线程就是50TPS,这个很直接吧。
- 请大家注意,这里我有一个转换的细节,那就是并发用户数到压力机的并发线程数。这一步,我们通常怎么做呢?就是基准测试的第一步。关于这一点,我们在后续的场景中交待。
而我们通常说的“并发”这个词,依赖TPS来承载的时候,指的都是Server端的处理能力,并不是压力工具上的并发线程数。在上面的例子中,我们说的并发就是指服务器上100TPS的处理能力,而不是指5个压力机的并发线程数。请你切记这一点,以免沟通障碍。
在我带过的所有项目中,这都是一个沟通的前提。
所以,我一直在强调一点,这是一个基础的知识:不要在意你用的是什么压力工具,只要在意你服务端的处理能力就可以了。
示例
上面说了这么多,我们现在来看一个实例。这个例子很简单,就是:
JMeter(1个线程) - Nginx - Tomcat - MySQL
通过上面的逻辑,我们先来看看JMeter的处理情况:
summary + 5922 in 00:00:30 = 197.4/s Avg: 4 Min: 0 Max: 26 Err: 0 (0.00%) Active: 1 Started: 1 Finished: 0
summary = 35463 in 00:03:05 = 192.0/s Avg: 5 Min: 0 Max: 147 Err: 0 (0.00%)
summary + 5922 in 00:00:30 = 197.5/s Avg: 4 Min: 0 Max: 24 Err: 0 (0.00%) Active: 1 Started: 1 Finished: 0
summary = 41385 in 00:03:35 = 192.8/s Avg: 5 Min: 0 Max: 147 Err: 0 (0.00%)
summary + 5808 in 00:00:30 = 193.6/s Avg: 5 Min: 0 Max: 25 Err: 0 (0.00%) Active: 1 Started: 1 Finished: 0
summary = 47193 in 00:04:05 = 192.9/s Avg: 5 Min: 0 Max: 147 Err: 0 (0.00%)
我们可以看到,JMeter的平均响应时间基本都在5ms,因为只有一个压力机线程,所以它的TPS应该接近1000ms/5ms=200TPS。从测试结果上来看,也确实是接近的。有人说为什么会少一点?因为这里算的是平均数,并且这个数据是30s刷新一次,用30秒的时间内完成的事务数除以30s得到的,但是如果事务还没有完成,就不会计算在内了;同时,如果在这段时间内有一两个时间长的事务,也会拉低TPS。
那么对于服务端呢,我们来看看服务端线程的工作情况。

可以看到在服务端,我开了5个线程,但是服务端并没有一直干活,只有一个在干活的,其他的都处于空闲状态。
这是一种很合理的状态。但是你需要注意的是,这种合理的状态并不一定是对的性能状态。
- 并发用户数(TPS)是193.6TPS。如果并发度为5%,在线用户数就是193.6/5%=3872。
- 响应时间是5ms。
- 压力机并发线程数是1。这一条,我们通常也不对非专业人士描述,只要性能测试工程师自己知道就可以了。
下面我们换一下场景,在压力机上启动10个线程。结果如下:
summary + 11742 in 00:00:30 = 391.3/s Avg: 25 Min: 0 Max: 335 Err: 0 (0.00%) Active: 10 Started: 10 Finished: 0
summary = 55761 in 00:02:24 = 386.6/s Avg: 25 Min: 0 Max: 346 Err: 0 (0.00%)
summary + 11924 in 00:00:30 = 397.5/s Avg: 25 Min: 0 Max: 80 Err: 0 (0.00%) Active: 10 Started: 10 Finished: 0
summary = 67685 in 00:02:54 = 388.5/s Avg: 25 Min: 0 Max: 346 Err: 0 (0.00%)
summary + 11884 in 00:00:30 = 396.2/s Avg: 25 Min: 0 Max: 240 Err: 0 (0.00%) Active: 10 Started: 10 Finished: 0
summary = 79569 in 00:03:24 = 389.6/s Avg: 25 Min: 0 Max: 346 Err: 0 (0.00%)
平均响应时间在25ms,我们来计算一处,(1000ms/25ms)*10=400TPS,而最新刷出来的一条是396.2,是不是非常合理?
再回来看看服务端的线程:

同样是5个线程,现在就忙了很多。
- 并发用户数(TPS)是396.2TPS。如果并发度为5%,在线用户数就是396.2/5%=7924。
- 响应时间是25ms。
- 压力机并发线程数是10。这一条,我们通常也不对非专业人士描述,只要性能测试工程师自己知道就可以了。
如果要有公式的话,这个计算公式将非常简单:
$TPS = \frac{1000ms}{响应时间(单位ms)}*压力机线程数$
我不打算再将此公式复杂化,所以就不再用字母替代了。
这就是我经常提到的,对于压力工具来说,只要不报错,我们就关心TPS和响应时间就可以了,因为TPS反应出来的是和服务器对应的处理能力,至少压力线程数是多少,并不关键。我想这时会有人能想起来JMeter的BIO和AIO之争吧。
你也许会说,这个我理解了,服务端有多少个线程,就可以支持多少个压力机上的并发线程。但是这取决于TPS有多少,如果服务端处理的快,那压力机的并发线程就可以更多一些。
这个逻辑看似很合理,但是通常服务端都是有业务逻辑的,既然有业务逻辑,显然不会比压力机快。
应该说,服务端需要更多的线程来处理压力机线程发过来的请求。所以我们用几台压力机就可以压几十台服务端的性能了。
如果在一个微服务的系统中,因为每个服务都只做一件事情,拆分得很细,我们要注意整个系统的容量水位,而不是看某一个服务的能力,这就是拉平整个系统的容量。
我曾经看一个人做压力的时候,压力工具中要使用4000个线程,结果给服务端的Tomcat上也配置了4000个线程,结果Tomcat一启动,稍微有点访问,CS就特别高,结果导致请求没处理多少,自己倒浪费了不少CPU。
总结
通过示意图和示例,我描述了在线用户数、并发用户数、TPS(这里我们假设了一个用户只对应一个事务)、响应时间之间的关系。有几点需要强调:
- 通常所说的并发都是指服务端的并发,而不是指压力机上的并发线程数,因为服务端的并发才是服务器的处理能力。
- 性能中常说的并发,是用TPS这样的概念来承载具体数值的。
- 压力工具中的线程数、响应时间和TPS之间是有对应关系的。
这里既没有复杂的逻辑,也没有复杂的公式。希望你在性能项目中,能简化概念,注重实用性。
思考题
如果你吸收了今天的内容,不妨思考一下这几个问题:
如何理解“服务端的并发能力”这一描述?我为什么不提倡使用“绝对并发”和“相对并发”的概念呢?以及,我们为什么不推荐用CPU来计算并发数?
- zuozewei 👍(67) 💬(12)
第一个问题:如何理解“服务端的并发能力”这一描述? 首先我们从数据视角来理解,可以把服务端程序用一个模型来看待,即由「网络 API 请求」所驱动的。 服务端的领域特征是大规模的用户请求,以及 24 小时不间断的服务。但某种意义上来说更重要的原则是:坚决不能丢失用户的数据,即他认为已经完成的业务状态。服务端必须保证其业务状态的可靠性,这时业务状态才持久化写入到外存。所以对于服务端来说,存储至关重要。它不只是极大地解放了处理效率,也是服务端的性能瓶颈所在。几乎所有服务端程序扛不住压力,往往都是因为存储没有扛住压力。 在衡量服务端的性能,我们还是要服务端视角来看,主要以 TPS 为主来衡量系统的吞吐量,如果有必要用并发用户数来衡量的话,需要一个前提,即响应时间(RT),因为在系统压力不高的情况下,将思考时间(等待时间)加到场景链路中,并发用户数基本还可以增加一倍,因此用并发用户数来衡量系统的性能没太大的意义,也不专业。 第二个问题:我为什么不提倡使用“绝对并发”和“相对并发”的概念呢? 我觉得一切的前提是业务价值需要。如果没有足够的价值,那么可读性才是第一,对这种难懂的概念很反感,要知道的其会加重内部沟通的难度,得不偿失。如果没那个价值,简单才是王道。 第三个问题:我们为什么不推荐用 CPU 来计算并发数? 比如单核CPU情况,实际上是只有一个的,在一个特定时刻也只可能有一个程序跑在一个CPU上(因为寄存器只有一组),但是我们在上层观察到的却是系统上好像同时运行着那么多的程序,这实际上是操作系统用进程这个概念对CPU做的抽象。 同时如果你了解「阿姆达尔定律」,就知道多处理器并行加速,总体程序受限于程序所需的串行时间百分比,超过一定的并行度后,就很难进行进一步的速度提升了。并不符合线性关系,也无法估算的。 再说服务端程序性能依赖不仅仅是底层的硬件,其依赖的基础软件还包括:操作系统、编程语言、负载均衡、中间件、数据库或其他形式的存储等。在第一个问题中提到了几乎所有服务端程序扛不住压力,往往都是因为存储没有扛住压力。 最后,还是需要回到第一个问题,即由「网络 API 请求」所驱动的模型上来。
2019-12-25 - 葛葛 👍(26) 💬(8)
对于并发度还不太理解。请问有历史线上数据的情况如何计算并发度,没有的情况又如何估算呢?能否分别举例说明一下。
2020-01-17 - 律飛 👍(24) 💬(3)
问题一,如何理解“服务端的并发能力”这一描述。对于web项目而言,服务端是整个项目的关键,是咽喉要道,因此也是性能测试的重点。测试目的当然是要摸清这个要道能同时走多少人(注意这里的人不是在线用户数并发用户数,而是服务器能处理的事务),因此TPS最能描述服务端的并发能力。虽然老师一直强调压力机并发线程数不是关键,但是公式表明其与TPS、响应时间有着不可分割的联系,还需要好好体会并运用。很期待基准测试以及如何判断响应时间、TPS合理的后续讲解。 问题二,为什么不提倡使用“绝对并发”和“相对并发”的概念呢?老师讲得很清楚了,这两个概念对于我们关心的性能并没有太多的帮助,反而让人有点无从使用。在线人数,并发数,并发度简洁明了,很好理解,有利于沟通,是性能测试必备指标之一。 问题三,为什么不推荐用 CPU 来计算并发数?并发数是业务逻辑层面的,而CPU只是众多软硬件环节中的一环,即使可以借鉴,肯定也是很粗略的估计,在实践中使用价值不大,没有推广使用的必要。
2019-12-25 - 月亮和六便士 👍(8) 💬(13)
老师,我们一般根据日志可以拿到在线用户数,但是并发度是百分之一还是百分之十这是全靠拍脑袋算的吗?
2019-12-25 - 凯 👍(7) 💬(1)
老师,看一下以下的推导是不是正确 对公式TPS计算公式总结: TPS就是单位时间处理事务的数量, server TPS = △事务数 / △t = 线程数 * 单个线程的事务数 / △t JMeter上给的时间是单个事务的平均时间
2020-05-20 - JK 👍(7) 💬(11)
高老师您好,仍有些疑问冒昧咨询。 某项目进行接口压测,提出需满足并发800且响应时间<5秒,当时的场景设置就直接发起800线程进行负载,结果出现大量超时异常。 学习本节后,将TPS概念投射进来。假如使用TPS理解衡量并发能力的话,原文中的并发800是否等价于800TPS吗? 参照文中例子,指服务器的TPS是100,线程TPS是20,因此推算出压测只需要发起5个线程进行负载即可。 切换到开头的例子,是否可理解服务器的期望TPS是800,而单个线程TPS是0.5(接口调用的rt是2000ms),按此验算的话压测需要发起1600线程负载才能达到原定TPS(0.5*1600=800?)。而1600个线程是否等价于N个线程*循环M次呢?
2020-03-09 - hou 👍(6) 💬(1)
‘’这时对 Server 来说,它处理的就是 100TPS,平均响应时间是 50ms。50ms 就是根据 1000ms/20TPS 得来的(请注意,这里说的平均响应时间会在一个区间内浮动,但只要 TPS 不变,这个平均响应时间就不会变)。‘’ 这里不太明白一点,tps是每秒完成的事物数,还是每秒在处理的事物数,还是每秒请求的事物数? 如果按照引用文中所示,1000/20=50的响应时间,我理解为20tps为每秒完成的事物数。 在前一章例子中,在线10000人,并发度5%,算出的500个tps,又让我感觉tps是指每秒的事物并发请求数。 在我的理解中,请求数和完成请求数是不同的
2020-02-29 - 顺利 👍(6) 💬(2)
服务端线程的工作情况图在哪里看呢老师?linux服务器上还是jmeter有监控插件
2020-01-21 - 柚子 👍(5) 💬(1)
老师,我有个问题想问下,如果只知道在线用户数,不知道并发度和相应时间,怎么计算并发用户呢?
2020-04-14 - 秋刀鱼滋味 👍(5) 💬(4)
就是说算好并发度就不需要设置思考时间之类的了吗
2020-03-09 - Abe 👍(4) 💬(3)
看的不是很明白,并发度到底怎么来的。
2020-03-06 - 木头人 👍(4) 💬(6)
老师好,请问并发度是怎么算的呢? 您给的回复“通过统计每秒的业务请求数以及比例就可以知道并发度了” 请问这个可以举例吗?这个比例是什么呢?还是不太明白
2020-01-13 - 夏文兵 👍(4) 💬(2)
针对吞吐量,根据你的公式, 我没计算出跟jmeter一样的值。我用jmeter 去压测(http://example.com/),number of threads: 3, Ramp-Up:1, Loop Count:50, 平均响应时间:679ms, Throughput: 3.6/sec, 但是根据您的计算公式 1000/679 * 3 = 4.4。请高老师赐教。
2020-01-06 - 静水潜流,润物无声 👍(3) 💬(1)
老师好,请问能否这样解读:单线程并发数TPS = 1000ms/响应时间;代表1s时间内,向服务端发送的请求的最大值?压力机的线程创建链接的时候,与服务端发送的所有性能测试应该都是同步消息吧,即客户端线程需要等待当前的请求响应接收到后,才模拟发送下一条请求的消息。如果这样解读是正确的话,在绝对“某一时刻”,服务器处理的“T”的个数应该是小于或等于“压力器线程数”。请教一下老师,上面的理解是否准确,多谢!
2022-05-25 - 学员141 👍(3) 💬(1)
如果一个事务由三个接口组成 ,压测的tps应该是三个接口一起组合压测的总和吗?假设系统就N个需要进行性能的接口,那系统容量是不是就是这些接口组合后,压测的总的TPS?我有时候分不清楚怎么汇报这个,都是全部列举各个接口的tps
2021-08-31