21 设计实战(一): 一个金融交易业务的自动化测试设计
你好,我是柳胜。
一提到金融业,可能你第一时间想到的就是钱。没错,存款、转账都是普通人最常接触的金融业务。不过在专业金融人士那里,钱的形态和流动方式也更加复杂,有交易、投资、期货、股票、基金等等金融模型。
从测试角度来看,金融业软件有两个特点:第一,对数据精准性要求非常高,不能出错,bug的成本极大;第二,软件的设计要求有很强的金融领域知识,也很复杂。
所以,金融行业对软件的交付质量要求高,对软件测试非常重视,自动化测试的投入也很大。而自动化测试设计的过程,其实也是对复杂业务梳理的过程。
挑战随之而来,用我们的Job模型,能不能让金融系统的复杂业务变得简单?今天我们就一起结合例子来看一看。
一个转账案例
我们来看后面这个转账案例。
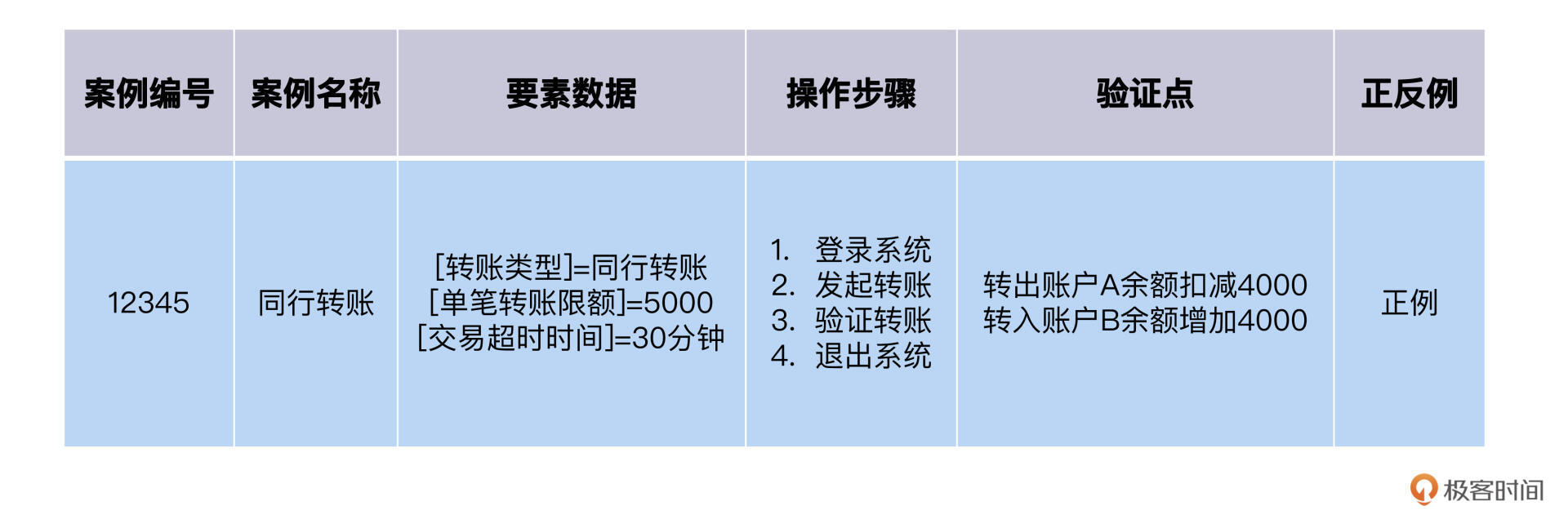
这是一个类型为正例的测试案例。金融业测试里,要设计很多的测试案例,正例是那些预期能够正常完成业务的测试案例,而反例是由于违背了业务规则,预期无法成功完成业务的测试案例。
在我们的测试案例里,交易账户都是正常的状态,交易额度也在安全额度之内,预期结果是能够正常完成转账交易,所以类型是正例。
Job数据建模
了解了案例情况,我们想用Job模型来为它建模,该怎么做呢?
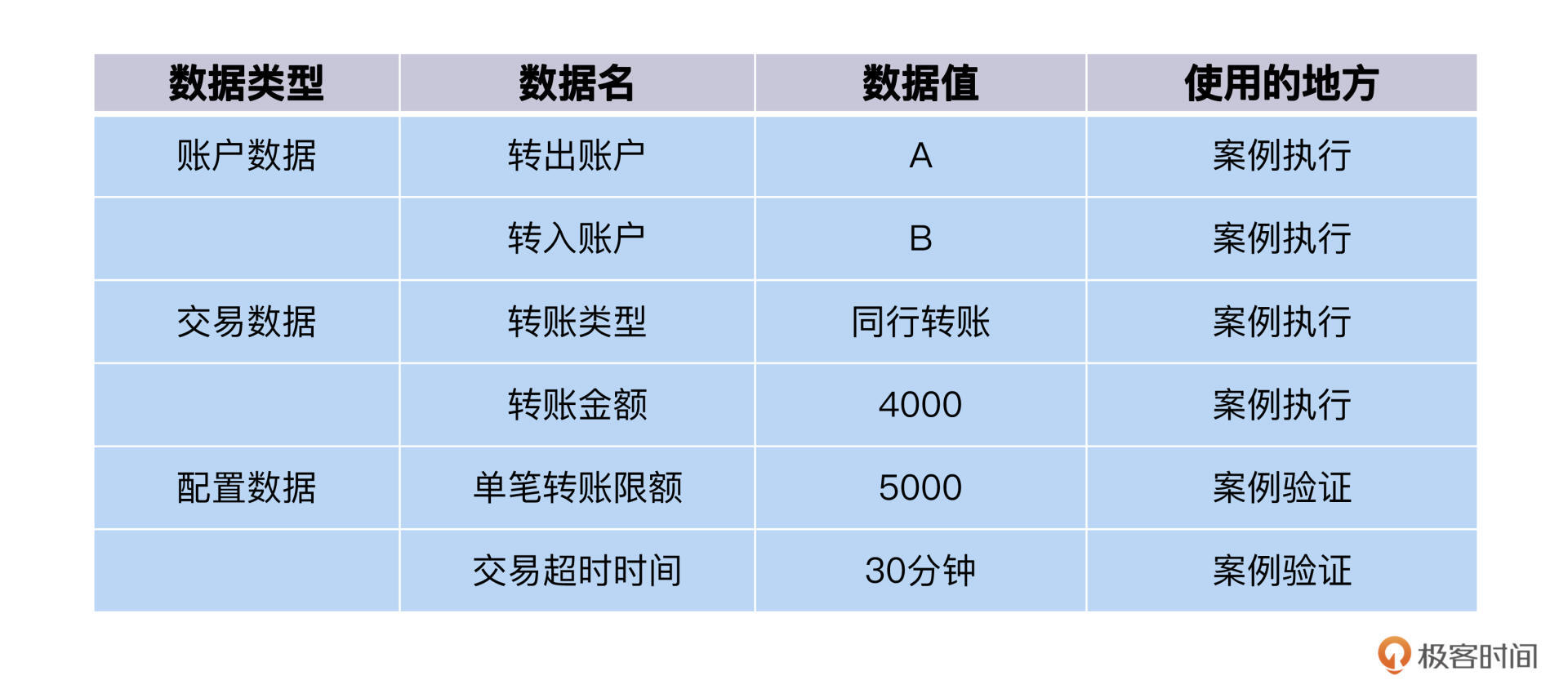
金融业务里最关键的要素就是数据,我们可以从数据角度来理一下测试案例。
这里的数据有账户数据,包括转出账户A和转入账户B;还有交易数据,包括转账类型同行转账和转账金额4000;另外,还有配置数据,单笔转账限额5000和交易超时时间30分钟等。
我们Job模型有三个传递数据的地方,分别是JobInput、TestData和TestConfig。
Input是从Job外部传递进来的数据,TestData是Job自带的测试数据源,能够多组数据循环运行Job,TestConfig是Job会引用到的比较固定的配置数据。
想一想,账户数据和交易数据,需要放在JobInput里,还是TestData里呢?这个要看我们自动化测试整体设计。
如果我们每次测试运行都要创建新的测试账户,那转账Job就可以从Input里获得其他Job创建好的账户信息;反之,测试账户是存量的数据,那我们应该把它放在TestData里,实现“多份数据,一份代码”,这样才能提高转账Job的ROI。
而单笔转账限额和交易超时时间,我们把它放在TestConfig里。表格更新如下:
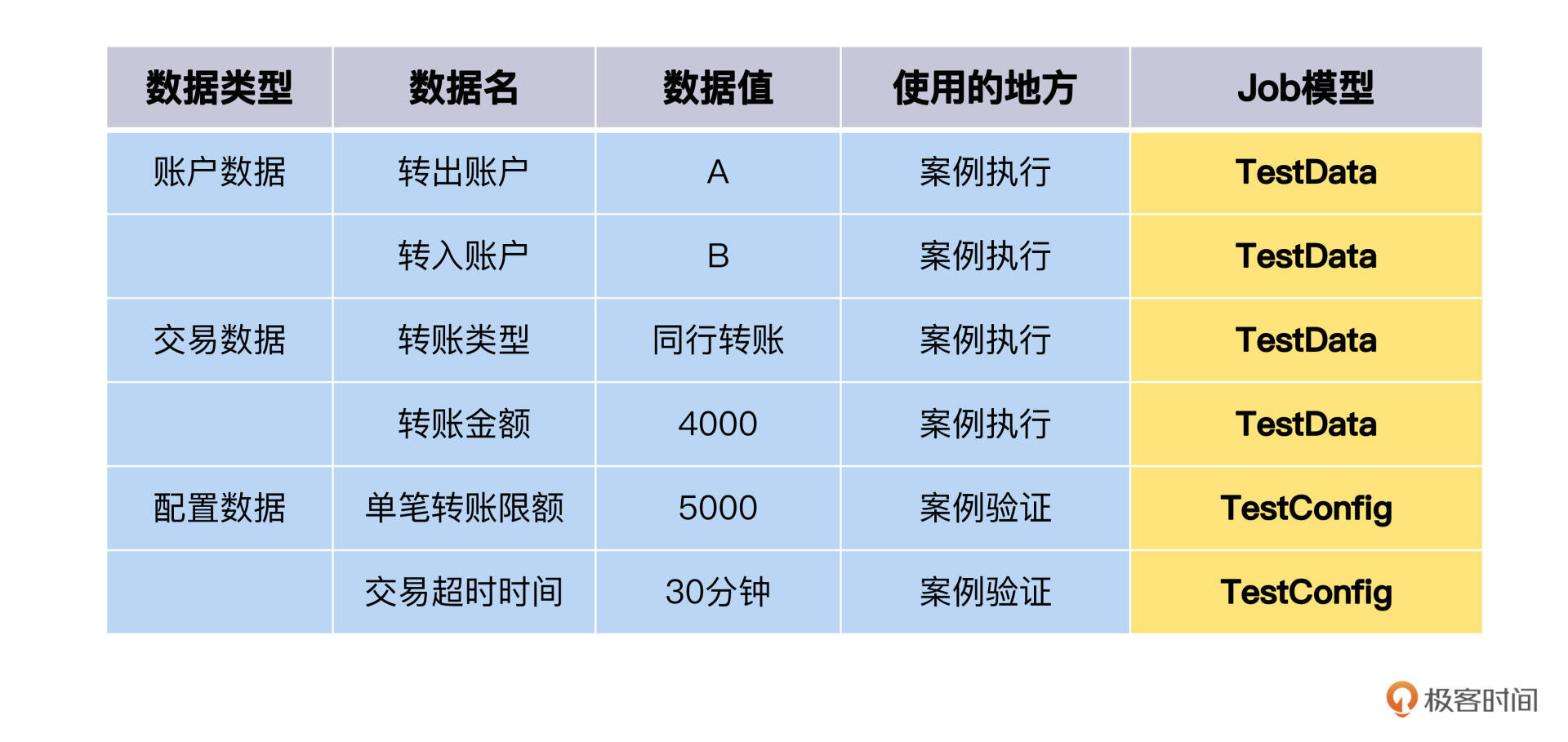
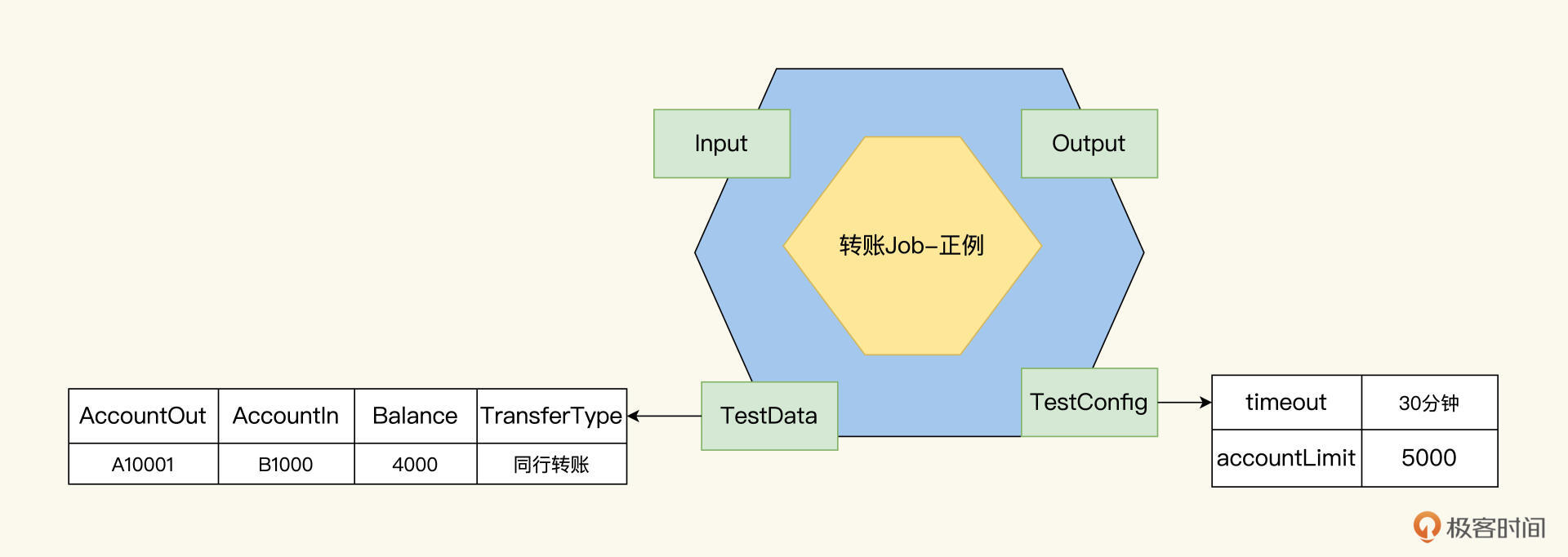
Job模型建模如下:
Job行为分解
数据研究完了,我们再来看梳理一下测试案例的操作步骤。
1.登录系统 2.发起转账 3.验证转账 4.退出系统
登录系统和退出系统这两个行为是通用的,为了提高Job的ROI,我们可以把登录系统和退出系统独立出来2个Job。而发起转账和验证这2个步骤,是作为1个Job,还是分割成2个Job呢。这取决于转账和验证的步骤复杂度,在刚开始时,我们不要过度工作over work,可以把转账+验证先作为一个Job。
这样的话,转账Job就分解成了3个子Job:登录,转账和验证,退出。在Web上实现的话,我们选择用Selenium作为开发工具。
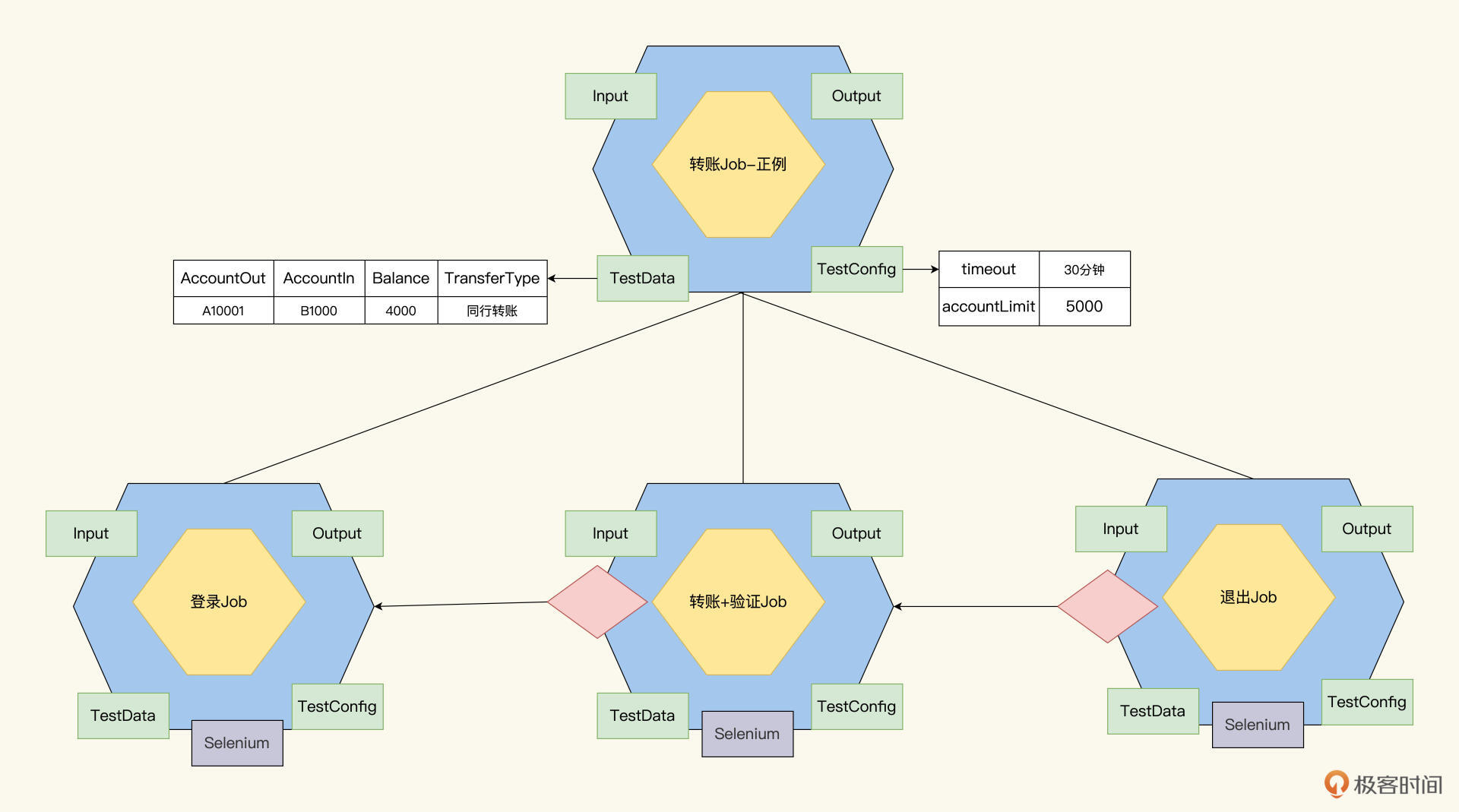
因为子Job继承了父Job的属性,现在3个子Job应该可以从TestData里拿到账户信息,登录Job用A账户进行登录,转账验证Job使用A账户给B账户转账4000,退出Job退出A账户。
现在自动化测试开发人员就可以用Selenium工具进行开发了!
Job扩展
自动化测试开发人员开发出这3个Job后,就完成了转账自动化测试第一个版本。能实现跑起来的基础目标。
但要想让它稳定运行,我们还需要理清楚金融业务的关联性。比如,银行账户是有复杂的配置的,光账户状态就有几十种,比如时效、锁定、冻结、挂失等等。想要让转账测试运行成功,测试账户必须在正常的状态下,有转账的权限,而且还要有足够的余额等等这些条件。
这些都是转账业务成功运行的前提条件,如果不满足这些条件,直接开始运行转账Job,可能会遇到各种“错误”。但这些“错误”是正常的预期,所以,诊断它们只会浪费你的时间。
数据验证
怎么办?为了保证转账Job的稳定运行,我们可以增加一个ValidateJob来验证数据。让转账Job的依赖指向ValidateJob,如果ValidateJob运行通过,转账Job才会运行;否则,转账Job就不必运行。
ValidateJob负责做数据验证,我们可以用Great Expectation 来完成这个验证。
Greate Expecation是一个Python的数据验证框架,它支持多种数据源,内嵌规则引擎。为了让你直观了解它的使用过程,我为你准备了后面的流程图。
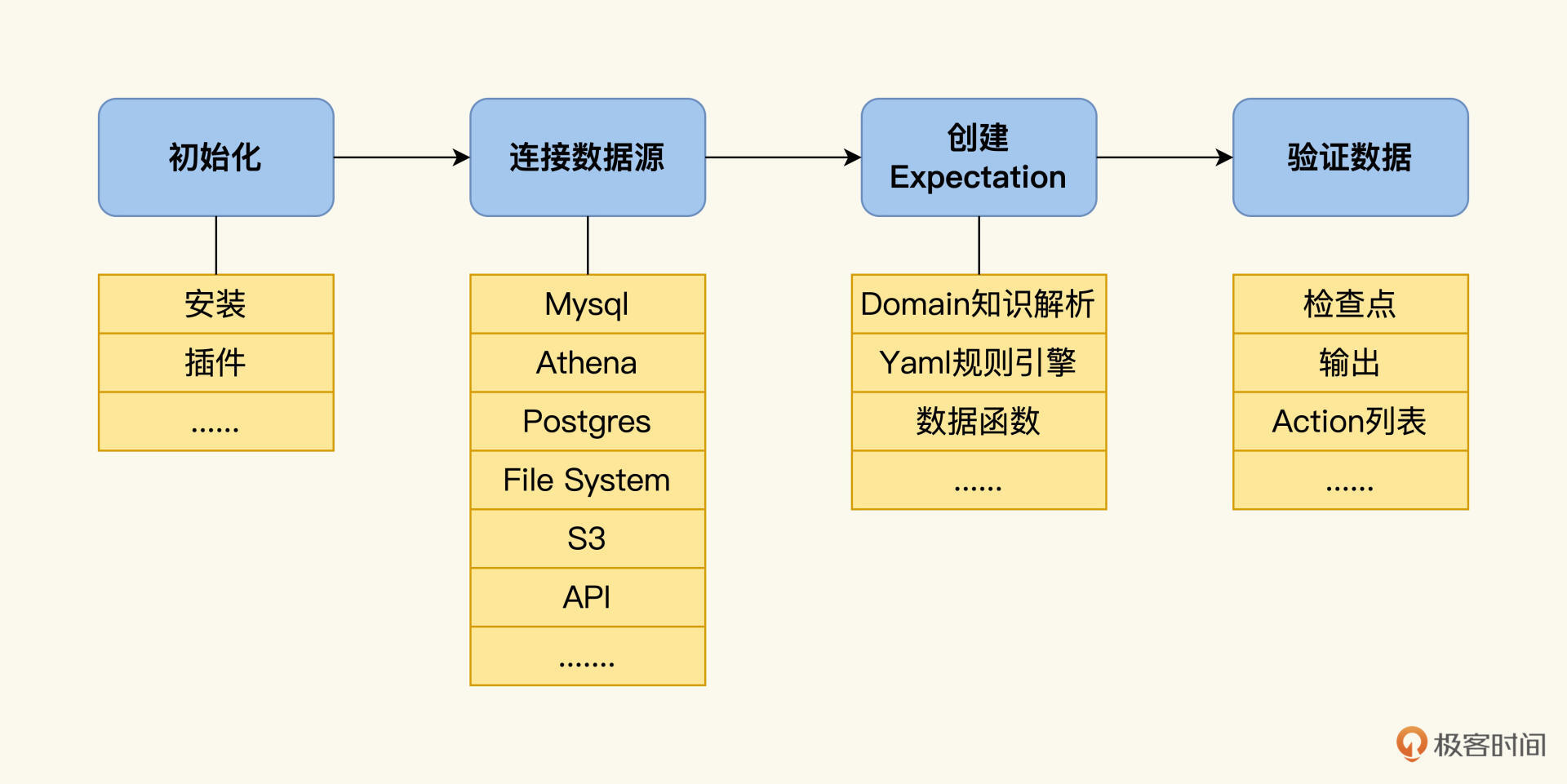
我们的账户存在MySQL数据库里,可以在greate_expectation.yaml里配置数据库信息:
datasource_yaml = r"""
name: my_mssql_datasource
class_name: Datasource
execution_engine:
class_name: SqlAlchemyExecutionEngine
connection_string: mssql+pyodbc://sheng.liu:Welcome1@<HOST>:<PORT>/<DATABASE>?driver=<DRIVER>&charset=utf&autocommit=true
#要验证数据集是Account表
table: account
然后,就可以在Jupyter Notebook里开发数据验证代码了:
#验证账户信息
batch.load(greate_expectation.yaml)
#验证规则1:账户的State字段不为空,而且是Active状态
batch.expect_column_values_to_be_equal('State','Active')
#验证规则2:账户余额必须大于4000
batch.expect_column_values_greater_than("balance",4000)
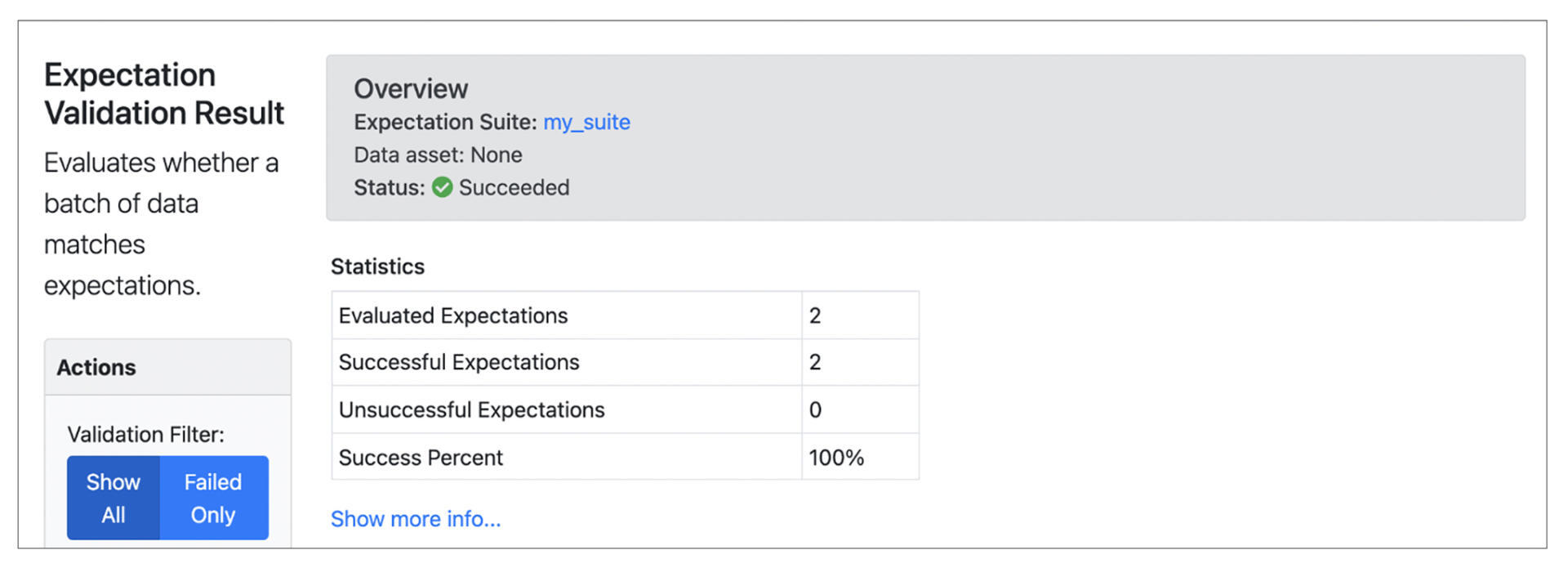
运行代码,Great Expectation会从数据库里读取账户数据,进行数据验证,2条规则都通过,整个Job运行成功,会产生下面的报告。
现在,我们把Validate数据Job添加到Job设计图里,更新如下。
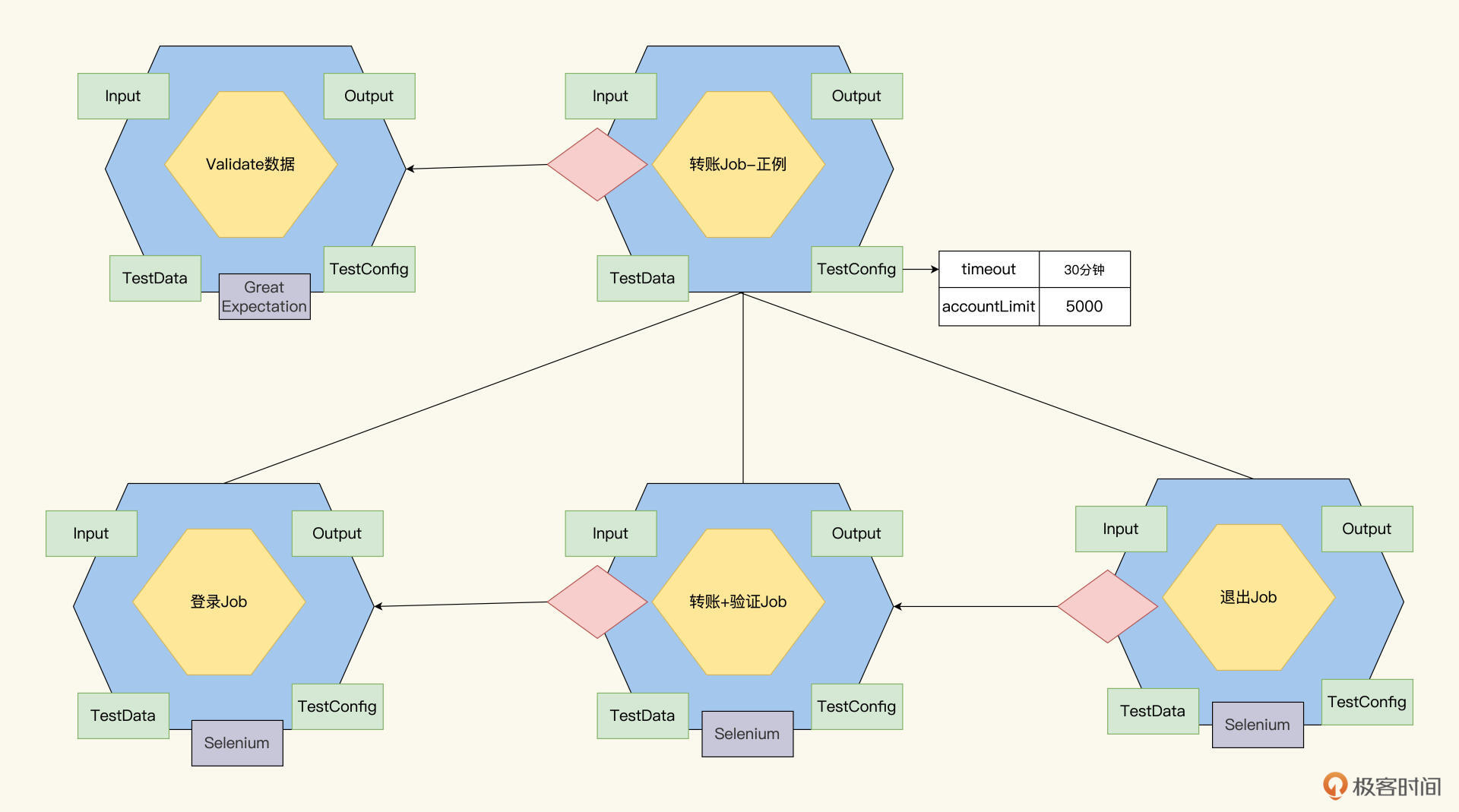
这样,每次转账Job运行之前,都会先运行Validate数据Job。只有数据都准备好了,转账Job才会运行。在这个机制的保护下,转账Job的运行结果成功或失败,就更可信了。
反例测试
有了ValidateJob之后,我们可以考虑反例测试了。这里反例的逻辑是这样的:如果账户数据是异常的情况下,转账Job是会失败的,要是交易依然成功,那就是一个安全漏洞。
因为这种漏洞在金融业务里很可能带来巨大的经济损失,所以,在金融测试里,反例测试也是很重要的测试案例。
不同的反例条件,转账执行失败的结果也是不一样的,它们有一个对应关系。 我列了一个条件-结果表格,这样你能一目了然。
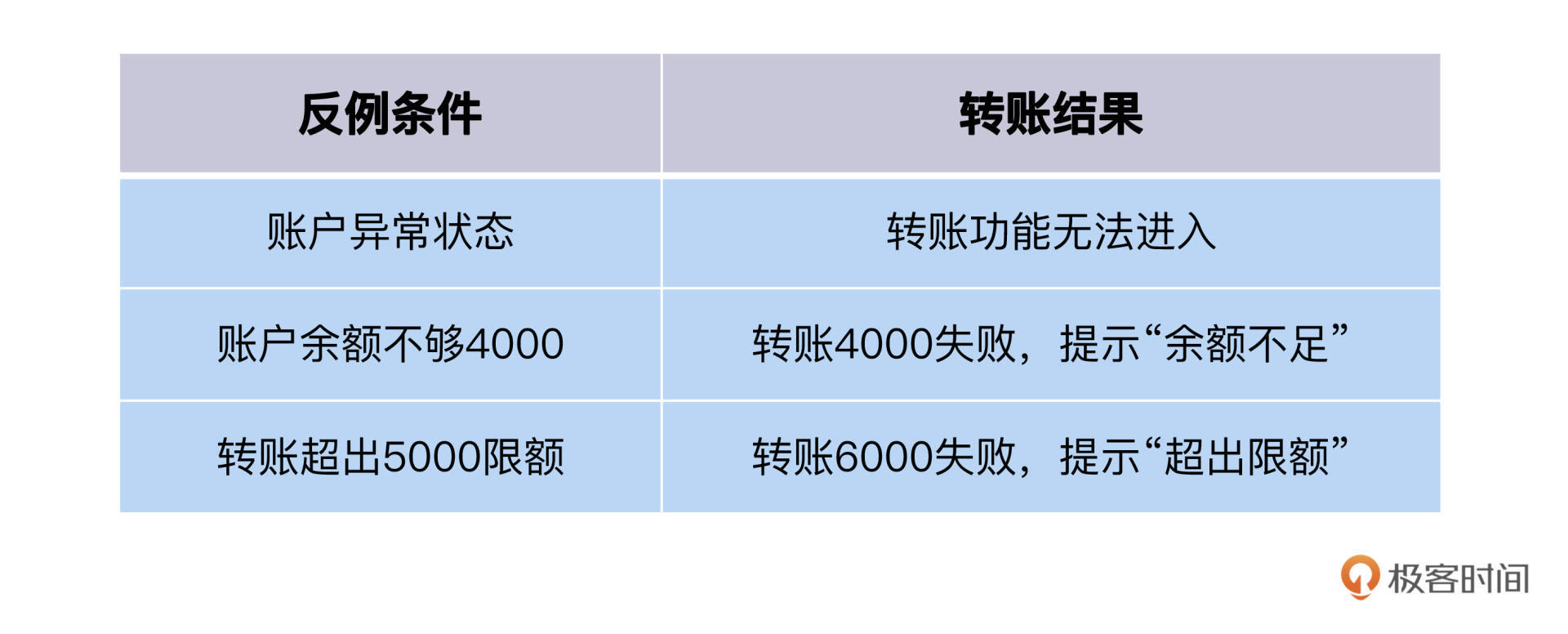
那自动化设计里,反例测试该怎么做?
你可能在第一时间想到的办法是,开发一个“转账Job-反例”,在这个反例Job里,把上面表格里的条件和结果,作为测试案例里的Given条件和Then预期输出。
这就引出了下一个问题,这个反例Job的数据从哪里来?其实,这种情况下,我们就可以利用Job模型的Input、Output机制,让ValidateJob验证数据之后,把数据通过Output分发到转账正例和转账反例的Job中去。
Greate expectation有一个Action的机制,根据规则匹配的结果,即可触发不同的Action,配置文件如下:
validation_operators:
action_list_operator:
class_name: ActionListValidationOperator
action_list:
- name: StateNotSatisfied # 状态不符合
action:
class_name: Output
output: "State not satisified"
- name: BalanceNotSatisfied # 余额不符合
action:
class_name: Output
output: "Balance not satisified"
现在我们再次重构Job设计树,就会得到下面这个设计结构。我们在跟转账正例Job平行的层级,再加上一个转账反例Job。不难看出,正例和反例的数据都来自于一个ValidateJob的输出。
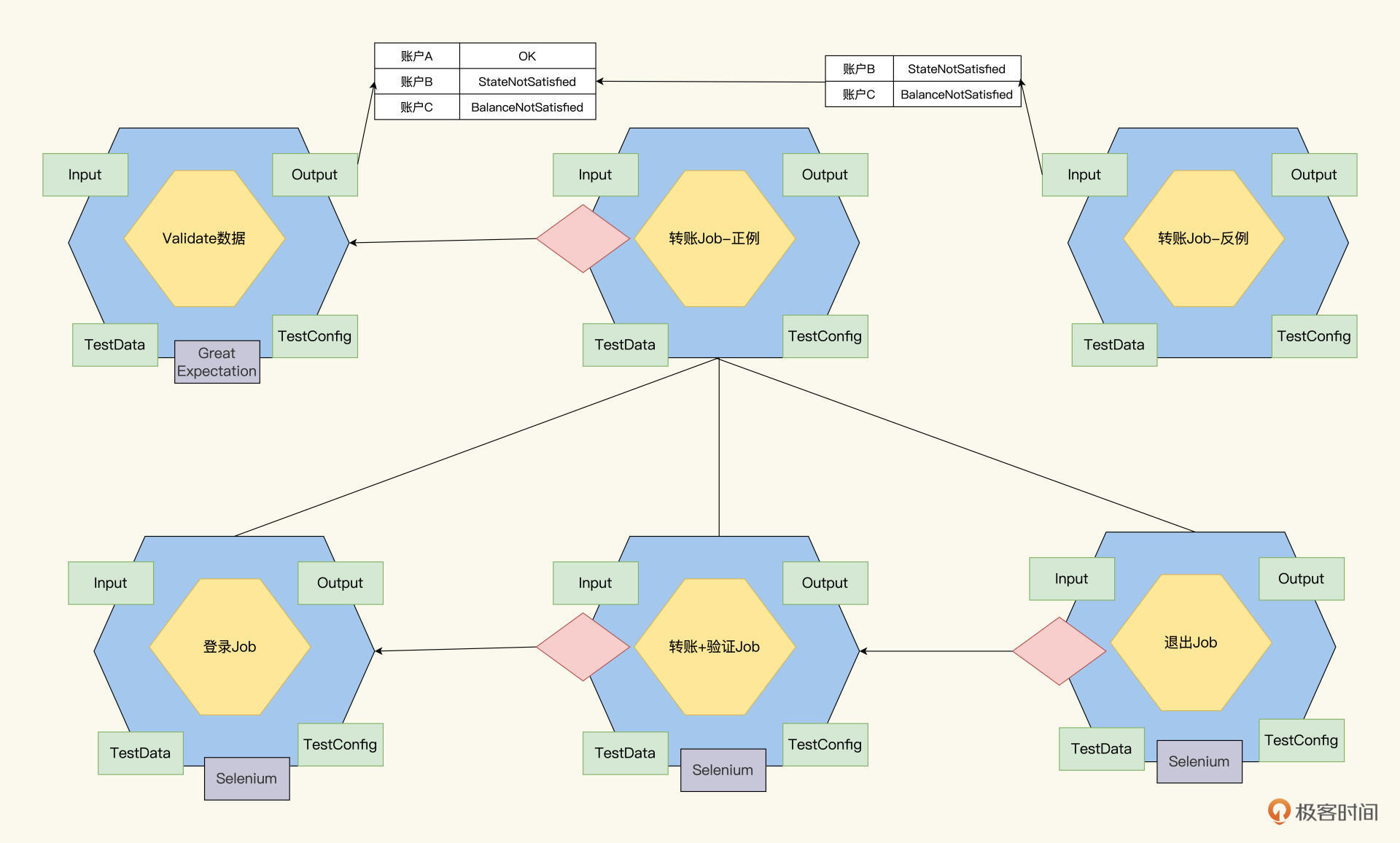
ValidateJob专门负责账户的合法性验证,使用Greate Expectation工具,内嵌规则引擎,来加载和解析账户数据,并把账户数据分组通过Output输出。然后,转账的正例Job拿到合法的数据,反例Job拿到非法的数据。
我给你打个比方,帮助你理解一下这个工作原理。其实这个场景就像生产线,第一个工人只管生产螺丝钉,他很专业,可以生产不同型号的螺丝钉,他不需要知道谁会使用这些螺丝钉。他需要做的就是,做好螺丝钉后,就把他们放到传送带上;而第二个工人是造飞机的,他会从传送带上拿到飞机螺丝钉,然后开始自己的任务;第三个工人是造汽车的,他拿到汽车的螺丝钉也开启自己的任务了。
这样分工,每个工人都在干自己的专业工作,又通过传送带和其它工人完成了协作。放在软件设计上,就满足了高内聚,低耦合的设计原则。
好,咱们接着推演后续可能会怎样发展。如果哪一天,ValidateJob里面越来越复杂了,一个人无法完成,需要分解给10个人去做。那么只需要保持ValidateJob接口不变,在ValidateJob下面分解成10个子Job就可以。
就像生产线上,生产螺丝钉的人手不够用了,他是招8个人还是10个人,分成几个小组,这些都是这个小组内部的事,只要这一组,还是跟以前一样,对外提供不同型号的螺丝钉就可以了。
好,让我们回顾一下整个过程。我们从一个银行转账正例案例开始,向下细化成3个Selenium Job,又平行引入了数据验证Job和反例Job。
到这里,你是不是对怎么应用Job模型更熟练了呢?我们利用这个模型,根据业务需要来扩展Job树。具体扩展方向有两种,一种是向下去下钻,将测试场景分解细化;另一种是向上聚合抽象,把场景归类合并到一起,形成一个更大的场景。
最后,我们设计好了正例和反例Job,就能聚合一起,生成一个转账的正反测试Job。
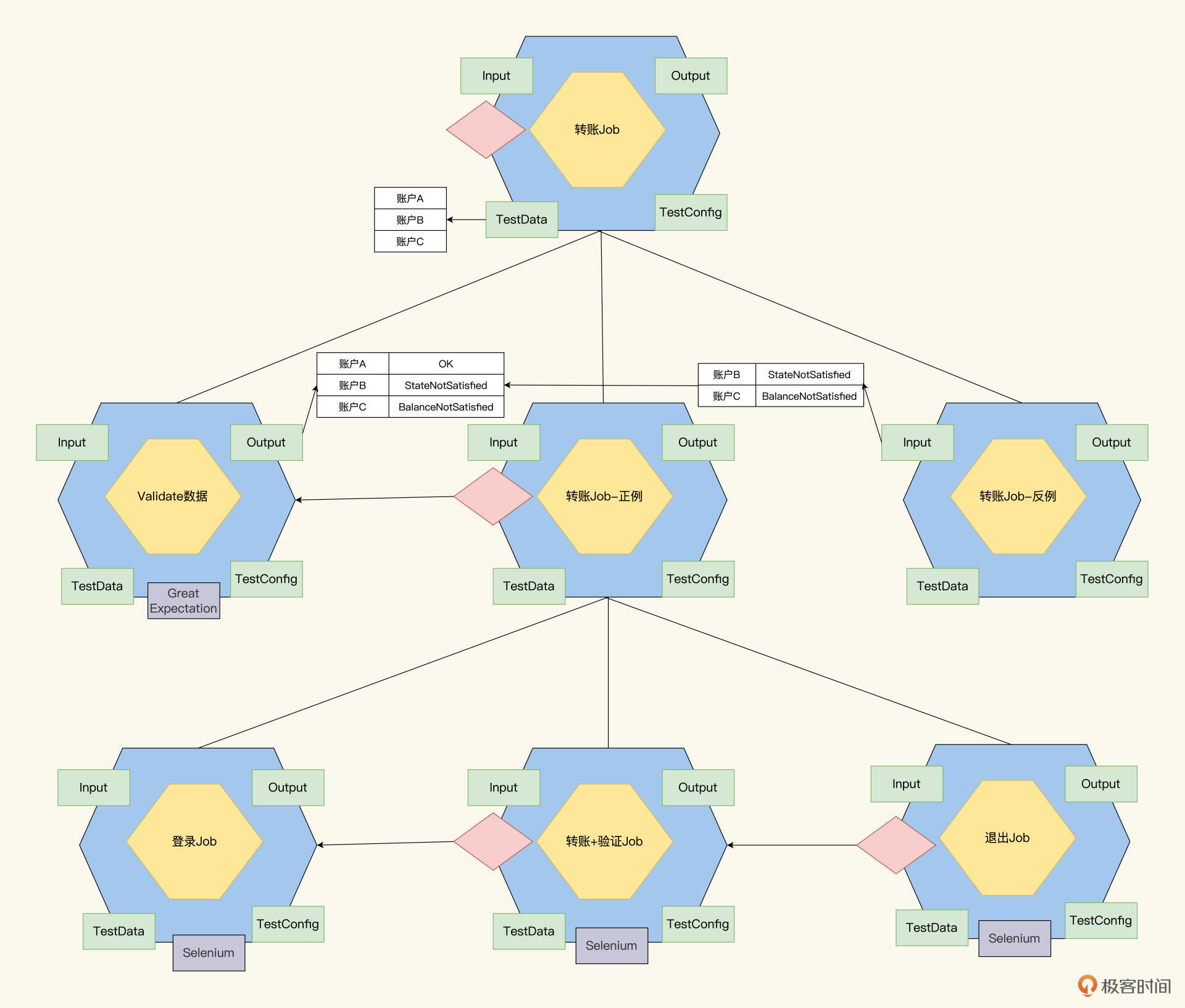
其实这个Job树并不是“终点”,我们还可以根据业务的复杂度再进行细化。
金融系统里,数据验证是一个精细的工作,确保无误。在手机端、Web端、API,甚至DB都要验证数据。根据这个需求,我们可以把转账+验证Job,进一步分解,分解后的情况如下。
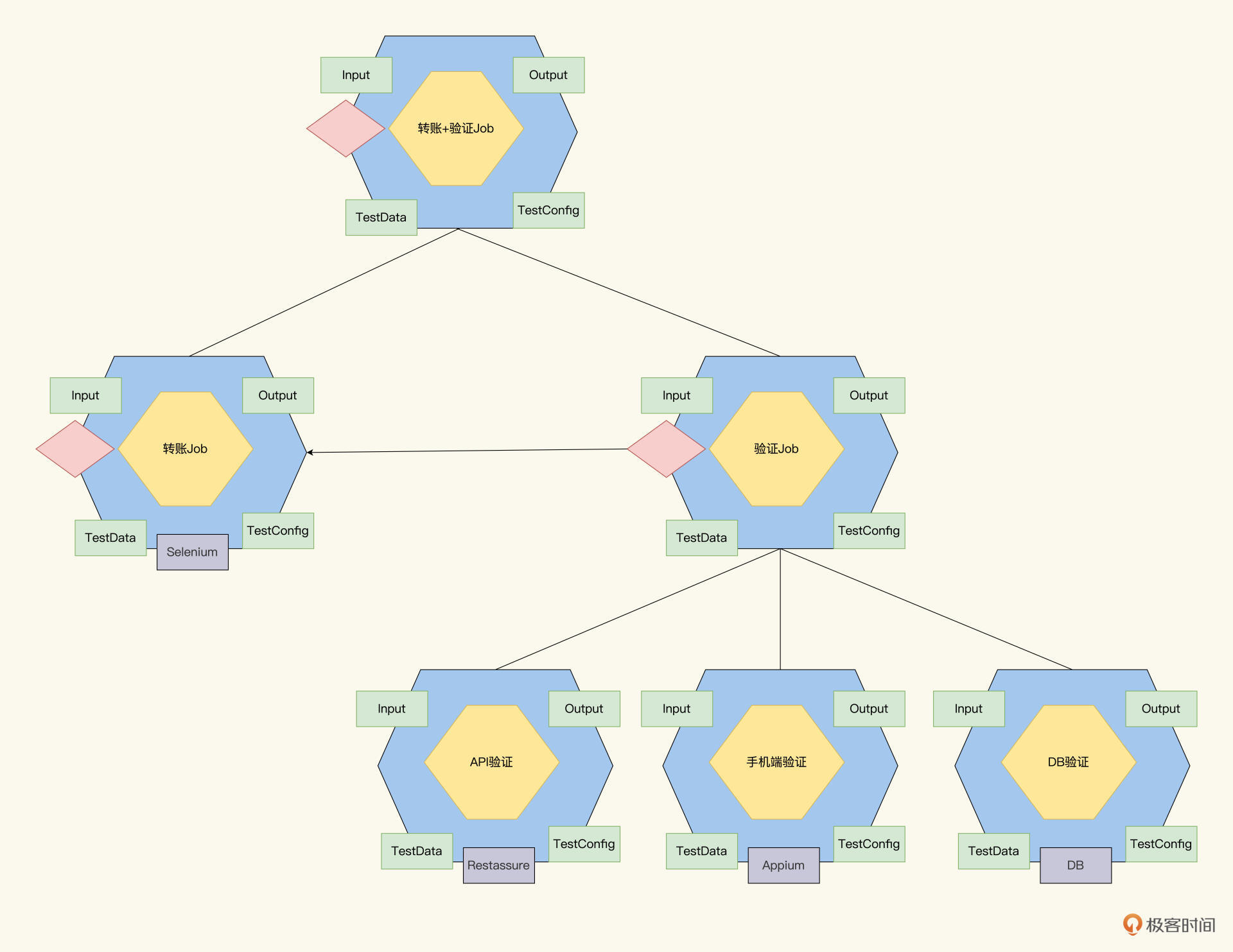
你可能还有疑惑,不知道要怎么判断,我们是否得到了一个足够细化的最终结果。其实判断起来也不难,终点就是业务逻辑梳理清楚后,这棵Job树的所有叶子结点,都明确了实现工具。这样,我们就可以推进分工,进入开发实现阶段了。
我在反例Job里,没有标注蓝色的实现工具,你可以考虑一下怎么细化。
小结
在今天的例子里,我们通过Job树的设计,梳理了金融业务的数据流动和验证。而且由于金融业务的特殊性,尤其是对数据精准性的要求。我还带你认识了一款数据验证框架Greate Expecation。它是基于Python语言的框架,能够从数据源里获得数据,进行规则验证,输出结果,而且在Jupyter Notebook里开发,交互性和效率都很好。
这整个的建模过程,经历了从整体到局部,从概要到细节的推演。其实,直到这棵Job树的叶子结点都有了选型好的工具、可开发的Job,我们的交易案例设计才算清楚了,这也是业务梳理完毕的信号。
每一个叶子结点的Job就是一个开发任务,有接口、有数据、有配置,开发工作任务列表就出来了。而且,通过Job之间的依赖关系,我们也可以得出一个有优先顺序的开发执行计划,谁在前,谁在后。
今天这一讲,为了让表达更形象,我们沿用了树形图来推演设计。在实际工作中,我们可以把这个设计保存在YAML或XML文件里,方便去做验证和二次开发,我会在设计篇最后一讲说说这块的实现思路。
下一讲,我们会继续锻炼自动化设计思维,探索如何利用Job模型实现自动化部署管线的设计,敬请期待。
思考题
你的项目里有没有涉及数据验证测试,你是怎么做的?
欢迎你在留言区和我交流互动,也推荐你把今天学的内容分享给更多同事、朋友。
- 侯海佳 👍(3) 💬(1)
先验证接口返回结果,再验证数据库里的值,有时需要验证关联系统数据库表的数据。关注动态数据和中间数据。有时新增字段长度不够。有时需要通过mock验证数据多样性。有时通过模拟外部消息协助个性业务流程走完。尽量不依赖历史数据,而是从头开始通过接口造数据。
2022-05-10 - 羊羊 👍(1) 💬(1)
现在项目中,数据验证的部分都是放在了测试框架的setup部分来完成,复用率不高。 在测试数据准备和验证方面,老师提供了很好的思路,谢谢。
2022-08-02 - 追风筝的人 👍(1) 💬(1)
grafana 监控面板和中间件集群,K8S集群 cpu , memory,disk io, network io入和出 , 请求错误率,时延等数据的验证
2022-06-01 - woJA1wCgAA3aj6p1ELWENTCq8KX2zC2w 👍(0) 💬(1)
实现了各类数据源的连接和库表的数据读取使用
2022-05-09 - ifelse 👍(0) 💬(0)
学习打卡
2024-02-25