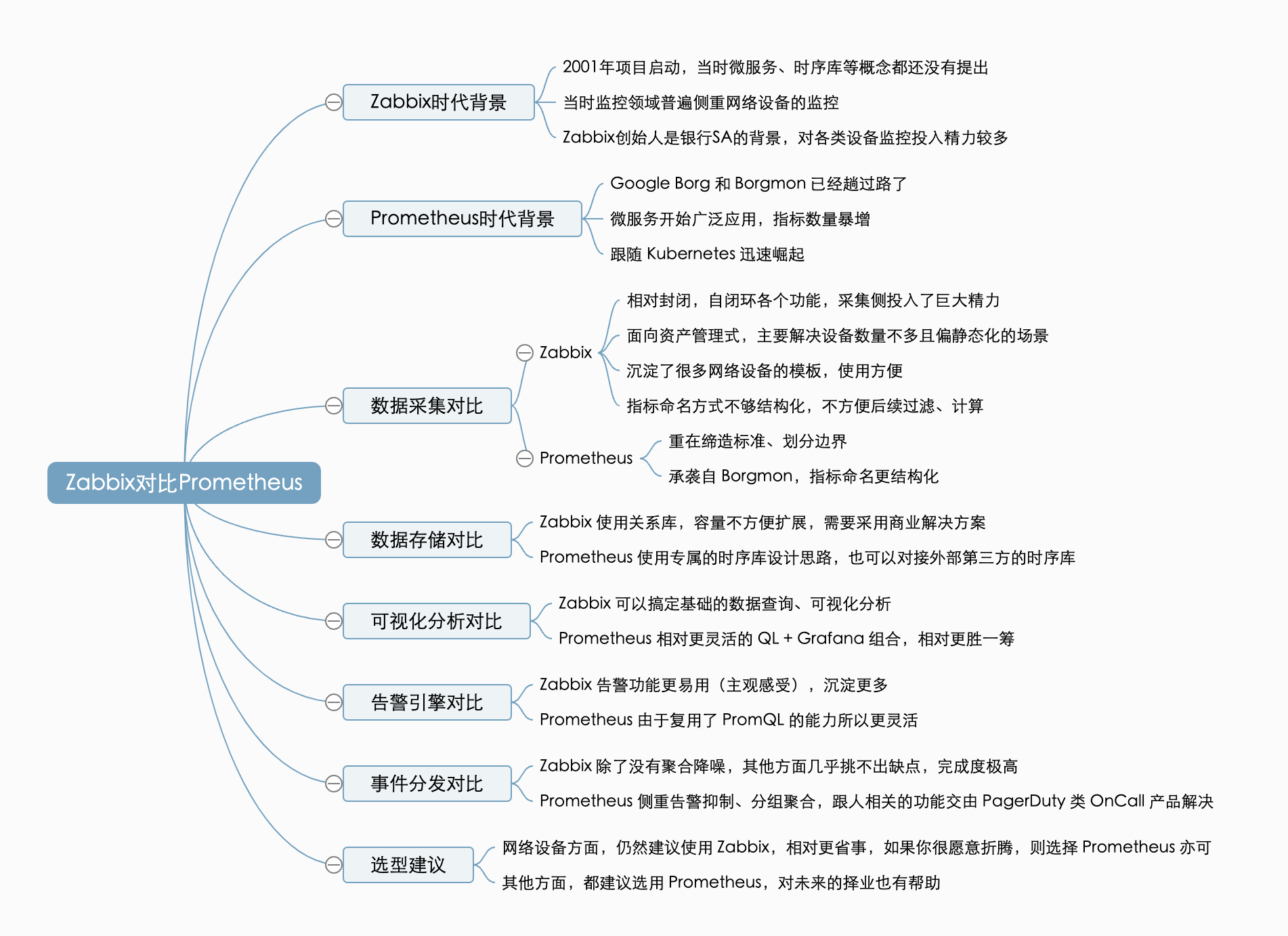
加餐 两个时代的王者,Zabbix 和 Prometheus 设计对比
你好,我是秦晓辉。
社区经常有小伙伴来询问 Zabbix 和 Prometheus 的选型问题,这节课我来介绍一下两个系统的设计理念,搞懂了它们的设计理念和折中思考,选型的烦恼自然迎刃而解。
注意,这里所谓的 Prometheus 不止是 Prometheus 软件本身,而是整个 Prometheus 生态,比如绘图工具 Grafana、分布式时序库 VictoriaMetrics、各类 Exporter,都可以看做是广义 Prometheus 生态的一部分。
我会从两个项目的时代背景开始聊起,进而深入到数据采集、存储、可视化、告警、事件分发等多个方面的对比,希望对你有所帮助。
Zabbix 的时代背景
Zabbix 项目于 2001 年启动,至今已经二十多年了,Zabbix 的发展历程在其官网可查。

Zabbix 的很多设计逻辑是由其所在时代决定的,那么,那是一个怎样的时代呢?
1998 年左右,国内的四大门户网站刚刚成立,那是一个只要会写 HTML 就能挣大钱的时代。微服务?那都是 2005 年之后的事情了。监控的核心诉求就是监控服务器、各类网络设备,至于服务器上运行的各类单体应用,远没有现在的关注度高。Zabbix 的创始人 Alexei Vladishev,曾是银行的 SA,他显然是把玩过各类设备和品牌型号的,因为即便是传统企业使用的 AIX 小机,Zabbix 也是支持的。
那个时候监控领域可用的开源组件还比较少,MRTG 于 1995 年推出,RRDTool 于 1999 年推出,Cacti 项目则是 2001 年和 Zabbix 类似时间启动。Zabbix 选择了当时看起来非常稳妥的语言:PHP + C,存储则选择了 MySQL 或 Postgres:因为当时即便是时序库的概念都尚未被提出,更别说用时序库了(时序库的开源代表 InfluxDB 项目 2013 年才启动)。什么感觉?满满的时代感!
Zabbix 重点解决服务器和网络设备的监控需求,就当时而言,显得理所当然。尤其是网络设备的监控,至今为止,开源监控领域仍然是 Zabbix 的体验最好,无出其右。其资产管理式的数据接入方式,SA 们非常喜欢和习惯。当然,这也是因为服务器和网络设备的数量通常不多(尤其是 2000 年左右),一旦监控对象和指标的数量剧增,甚至指标具备高流失率的情况下,Zabbix 就显得捉襟见肘了,新的时代需要新的方案——Prometheus 应运而生。
Prometheus 的时代背景
讲 Prometheus 之前得先讲 Google。Google 巨大的体量众所周知,在 2008 年左右(或之前)Google 开发了 Borg 集群管理系统,用于管理其大规模的服务容器,后来的 Kubernetes 姑且可以看作是 Borg 的开源实现。Borg 中的监控系统是 Borgmon,用于监控 Borg 中运行的海量服务,Prometheus 诞生自 2012 年,其灵感就是来自 Borgmon,姑且可以看作是 Borgmon 的开源实现。
2012 年互联网发展如火如荼,当时的 Google 已经有几十万台物理机,微服务盛行,研发人员对服务监控埋点的意识已经大幅提升,导致指标量暴增。而此时的开源社区找不到特别像样的服务监控产品,虽然 Zabbix 已经很流行,但是 Zabbix 偏设备监控;虽然 StatsD + Graphite 应用较多,但是系统设计和系统容量都不尽人意。Prometheus 于 2012 年开始开发,2015 年对外发布,2016 年加入 CNCF 基金会,产品卡位精准,边界清晰,CNCF 加持,迅速流行。
Prometheus 为何如此流行?一个开源项目的成功会有很多因素,Prometheus 也不例外。姑且不论时代、定位、社区治理、宣传等方面,仅就 Prometheus 产品设计而言,我觉得最核心的因素是 Prometheus 缔造了一个指标采集和查询的标准。下面我们就从数据采集开始,对 Zabbix 和 Prometheus 做详细对比。
数据采集对比
整体而言,Zabbix 生态相对封闭,在一个体系里闭环监控的方方面面,那么数据采集自然也闭环在内,而且 Zabbix 在这个方面投入了极大的精力。反观 Prometheus,仅仅是设计了一个数据抓取的标准,具体的采集工作交由各类 Exporter 来实现,非常轻量,而且通过复用庞大的社区开发力量,迅速完善了起来。下面我们详细拆解来看。
Zabbix 数据采集设计
Zabbix 的数据采集是围绕 Host 展开的,Host 是 Zabbix 里的一等公民。Host 可以是一个服务器,也可以是一个网络设备,甚至可以是一个 JMX 服务。不同的 Host 要采集哪些数据,是要在服务端配置的,如果每个 Host 分别配置不同的采集规则就会很麻烦,于是 Zabbix 设计了 Template、宏 等机制,Host 绑定 Template 就可以自动应用模板内的采集规则,省去了重复配置的麻烦。如果某个配置项和 Template 不同,还可以使用 宏 机制做覆盖,当然也可以为某个 Host 配置专属的采集规则,极为灵活。
当然了,数据采集的前提是客户端原本就提供这类数据,比如 JMX 暴露了各类 MBean 的信息,网络设备通过 SNMP 暴露了各类指标信息,Zabbix-agent 也默认支持一些 CPU、内存等信息的采集。每个信息都有一个 Key 来唯一标识,所谓的服务端的采集配置,核心就是指定不同的 Host 要采集哪些 Key。
比如 Zabbix-agent 提供了一个 system.uptime 的 Key,用于采集机器的启动时长,服务端给某些 Host 指定这个 Key,就可以拉取到对应的 Host 的启动时长数据了,很容易理解吧?实际不止这么简单,Key 不仅仅是一个固定字符串,还需要用参数的方式来支持不同的采集需求,比如 system.cpu.load[, ] 就支持 cpu 和 mode 两个参数:cpu 参数用于指定是采集单个 CPU 还是所有 CPU 整体,mode 用于指定是 1 分钟、5 分钟、还是 15 分钟的平均值。而且有时参数是很难枚举的,比如磁盘挂载点、网卡接口等,不同的机器很是不同,此时就需要引入自动发现机制,即 Zabbix 中的 LLD(Low Level Discovery)。
另外,某个 Key 可能采集到的数据因为格式各异需要二次处理,没法直接入库,所以 Zabbix 还支持对数据的二次 Preprocessing、Mapping 等功能;为了复用 Key 的采集结果,Zabbix 还支持主 item 等逻辑。可以说,Zabbix 在数据采集上可是花费了巨大的精力。
由于数据采集的代码是固化在 agent 中的,显然 agent 不可能一上来就想那么齐全,把所有的数据采集需求全做了,所以 Zabbix-agent 支持用户写脚本,自定义一些采集 Key。但是脚本这种方式,显然就不太优雅了,而且占用的资源也比较多。后来 Zabbix-agent 升级为 Zabbix-agent2后,就内置了一些常用数据库、中间件的采集,另外也支持对接各类 Exporter,完善程度大幅提升。但是,Zabbix 的指标标识是一个不太结构化的字符串,即便可以接入各类 Exporter,后续的过滤、聚合查询、指标之间的计算,都没有 Prometheus 来的方便。
纵观 Zabbix 的采集设计,有如下特点。
- 面向资产管理式。添加机器、绑定监控项、对机器做分组、有权限控制,是一种面向资产的管理方式,主要解决资产数量不多而且偏静态化的场景;
- 对服务器和网络设备的监控有很多经验沉淀。体现为各种设备型号的 Template,以及对各类操作系统的支持;
- 指标命名方式不够结构化,不方便后续的过滤、计算,而且历史包袱较重,很多功能相互依赖,估计很难改了。
Prometheus 数据采集设计
相比 Zabbix 在采集层面投入的巨大精力,Prometheus 则采用了更轻量的方式。只是定义了一个数据格式规范,提供了不同语言的 SDK 以及有限的几个 Exporter 作为样例,至于各类开源组件的监控,基本都是交给社区自行实现的。
相比 Zabbix,虽说 Prometheus 做得更少,却做得更好,主要体现为如下几点。
- Prometheus 定义的指标格式沿袭自 Google Borgmon,更为结构化,查询过滤、聚合、计算都更为方便;
- 边界分工定义得当。让程序研发人员自己搞定指标的采集,因为没有人比他们更清楚自己的程序。虽说 Zabbix 中对数据的 Process、Mapping 等逻辑,都需要 Prometheus 采集侧自行搞定,但研发人员对此也没有怨言,因为这些逻辑可以看做是程序自身的一部分,至于后面是哪个监控系统来采集,无关紧要;
- Prometheus 一开始就提供语言级的 SDK,推荐研发人员像 Google 服务暴露
/varz接口那样暴露/metrics接口,显然不止是解决设备、中间件、数据库的监控,还要解决业务应用的监控,相比 Zabbix 其受众更广。
当然,Prometheus 在操作系统和网络设备的支持方面,没有 Zabbix 沉淀的多,这点要注意。比如网络设备并不是 Prometheus 无法监控,而是不同的设备型号 OID 不同,需要不同的采集模板。而这块大都已经用 Zabbix 做了,大家就不太有动力去整理 snmp_exporter 的采集配置了。
数据采集完了就要存储起来,接下来我们对比一下 Zabbix 和 Prometheus 的存储设计。
数据存储对比
Zabbix 使用关系型数据库存储历史数据,把历史数据分成 History 和 Trends,History 是明细数据,Trends 是采样数据。对监控数据而言,数据越久远价值越低,通常短期数据用来查问题,而历史数据只要知道个大概趋势即可,所以历史数据会采样存储。比如原始数据 1 分钟采集一次,每小时采集 60 个数据点,Trends 会每小时采样一次,仅保留每小时内的 max、min、avg、count,存储成本大幅降低。
使用 MySQL、Postgres 存储数据,可以享有关系型数据库自身的先天能力,比如日常运维、备份恢复都比较方便,有大量的 DBA 人才。但是容量上限取决于单机硬件,这也限制了 Zabbix 整体的容量上限,当然,像 TiDB、OceanBase 等分布式数据库都是兼容 MySQL 协议的,如果成本允许可以考虑使用这些商业数据库。
Prometheus 的存储就简单多了,进程本身就具备数据存储能力,即内置时序库。由于时序数据特征明显,每个数据点就是一个时间戳+一个值,通常时间戳之间的差值是固定的,值的波动较小或差值类似,所以时序数据应用压缩算法之后,压缩比可以做到很高。默认情况下,Prometheus 明细数据会存储 15 天(可配),对于排障这个场景,足够用了。
实际上,国内稍大一些的企业,大都直接使用 VictoriaMetrics 作为时序库,VictoriaMetrics 比 Prometheus 的性能更好,而且提供集群方案。即便是单机版的 VictoriaMetrics,每秒处理百万数据点也非常轻松。如果你没有历史包袱,新上的项目我会建议你无脑选择 VictoriaMetrics。
数据有了,下一步就是可视化分析+告警,我们先来对比一下数据可视化能力。
可视化分析对比
以我这些年和社区、客户交流来看,监控数据可视化分析核心有如下诉求。
- 查询特定的数据
- 对数据做二次计算
- 从数据中提炼有价值的信息
- 数据呈现的美观
我们挨个来看两个产品的满足度。
首先查询特定的数据,这个场景是用户脑子里清楚自己想要查的是什么,比如是哪个机器、哪个指标等,两个产品都可以轻松满足。
对于数据的二次计算这个点,Prometheus 支持得更好。其 Query Language(即 PromQL) 的灵活度极高,新时代的监控系统,Query Language 基本是标配了,相信大家都是有共识的。
从数据中提炼有价值的信息,这点听起来比较虚,实际是一个更高维的东西。通常来讲,冷冰冰的零散的数据,价值是比较小的。从数据中可以看到一些最大最小值,看到一些统计类的结果,就从数据上升到了特征,通过分析一批数据的特征,可以得到一些零散结论,根据这些零散结论,可以得到最终的决策依据。听起来比较抽象,我们以故障定位场景举例,可以总结出如下的“信息层级”。

要想从数据中提取有价值的信息,灵活的仪表盘以及图表之间的跳转是必须的(当然,更重要的是配置仪表盘的那个人)。Zabbix 内置了仪表盘,Prometheus 直接不提供仪表盘能力。看起来 Zabbix 更强大一些,但是 Prometheus 可以搭配 Grafana 使用,由于 Prometheus 的数据更为结构化,方便聚合、图表跳转,Prometheus + Grafana 生态反倒更胜一筹。
至于美观方面,作为技术人应该不是太看重,但是公司里通常有一些视觉老板,他们决定了你的薪水,哄他们开心还是很有必要的。Zabbix 浓浓的 RRDTool 风格,一看就是上个时代的产物,Grafana 在这方面完胜。
监控数据有两个重要使用场景,可视化和告警,聊完了可视化分析,我们再来看看告警方面。
告警引擎对比
所谓告警引擎,指的是根据告警规则做数据判断并生成告警事件的那部分逻辑。告警引擎通常周期性运行,根据用户配置的查询语句(语句中通常带有阈值条件)去查询时序库,查到了就说明有问题要生成告警事件。
Zabbix 的告警引擎内置在 Zabbix-Server 里,Prometheus 的告警引擎内置在 Prometheus 进程里,VictoriaMetrics 的告警引擎是 vmalert。Prometheus、VictoriaMetrics 都可以使用 Nightingale 作为统一的高可用告警引擎,同时对接多套时序库。
告警引擎最核心追求的应该是灵活性,支持 Query Language 的 Prometheus 生态确实具备更好的灵活性,可以写出很复杂的 PromQL。不过大部分场景下,告警规则都相对简单,很多用户更关注的是易用性。Zabbix 的告警规则可以作为 Template 的一部分,和采集规则联动,绑定到机器上就自动生效,很受普通用户的欢迎。另外 Zabbix 的告警可以和宏变量打通,对机器粒度的控制比较方便,也是很多用户喜欢 Zabbix 的原因。
举个例子:假设给 DBA 的 100 台机器配置 CPU 使用率超过 90% 的告警,但是 DBA 的 100 台机器中包含 2 台 Redis 的机器,比较特殊,希望 CPU 超过 80% 就告警。在 Zabbix 中,通过宏变量,给这俩机器配置不同的宏阈值就可以了,非常直观。而在 Prometheus 中,通常是通过标签来实现过滤,因为实例名通常都是 IP 地址,不太适合做正则过滤。
你可能会配置如下两个规则。
假设后面 service=“mysql” 的机器和 service=“mongo” 的机器,其阈值都不同,那么就需要配置多个规则,而且还要修改默认值 90% 那条规则,把特殊的机器排除掉。
当然,终归是可以解决的。但是,有的时候打标签不方便,因为标签会影响时序数据,标签改变,时序数据就断了,就会产生新的时序数据,而数据中断可能会导致告警引擎触发恢复通知(告警引擎以为数据不符合阈值了,实际是对应的指标中断了),这个时候就会非常难受。
整体来看,Prometheus 的告警引擎更灵活,Zabbix 的告警功能更易用。不过“易用”是个很主观的词,真正选型的时候你要自行评估。
告警引擎产生事件之后,就是最终的分发环节,下面我们来做二者的最后一个维度的对比:事件分发对比。
事件分发对比
告警事件产生之后,通常根据事件属性做分派,不同的事件发给不同的人,不同级别的事件可能采用不同的通知媒介。
整体来看,Zabbix 对通知媒介、接收者的管理非常完备、交互也很丝滑,而且支持告警认领和升级,但是不支持告警抑制和分组聚合。而 Prometheus 使用的 Alertmanager 更擅长告警抑制和分组聚合,对通知媒介和接收者的管理相对粗糙,也不支持告警认领和升级,Prometheus 应是觉得这部分功能本就应该交给 PagerDuty 之类的产品来做,不属于它的功能范畴。
Zabbix 的设计亮点如下。
- 通知媒介单拎出来管理,用户可以很方便自定义一个新的通知媒介;
- 用户和通知媒介关联,用户信息中配置结构化的 SENDTO 属性。比如要发邮件,用户信息中就要配置邮件地址;要发企微应用消息,用户信息中就要配置企微账号。而且不同的媒介可以配置生效时段、生效的事件级别、启用与否,真的是非常灵活了;
- 分派规则,即 Trigger Action,支持对事件的各个属性做过滤,支持多环节升级通知。虽说用起来挺复杂,但确实功能丰富;
- 告警事件支持认领、Update 进度,有种工单的既视感。如果你没有专门的告警响应中心,就用 Zabbix 这套也能解决大部分需求了。
Prometheus 的设计亮点如下。
- 标签抑制很灵活,通常用于高级别抑制低级别的场景,设计逻辑清晰、用户容易理解;
- 聚合分组可以起到较好的告警降噪效果,把同类事件放到一起发送,就是最简单可用的降噪机制。
Prometheus 没有用户的概念,没法方便做到不同的告警发给不同的人。当然,你可以配置不同的 receiver,大不了直接写用户的联系方式呗,也凑合可行。但是用户少还行,大公司用户多,用一套 Alertmanager 来管理绝对是灾难。
通常有两个办法来解决,一个方法是不同的团队自己用自己的 Prometheus + Alertmanager,另一个是统一把告警事件转发给 PagerDuty 这样的 OnCall 产品,在 OnCall 平台上做统一分发。我推荐第二种方式,因为 OnCall 平台不止是对接 Alertmanager,还可以接收云监控、日志监控、Zabbix 等各类监控系统的事件,做统一排班、分派、认领、升级,还能和 IM 良好集成。
Zabbix 和 Prometheus 几大维度的对比,到此就都对比完了。下面我们做一个总结,顺便聊聊如何选型。
总结
总体来看,Zabbix 生态相对封闭,针对监控这个场景的方方面面都有相关功能设计,整体设计非常完整。但是 Zabbix 起步太早,历史包袱较重,很难应对大规模微服务和 Kubernetes 这样的动态环境,当然也是因为 Zabbix 起步早,沉淀了很多模板,细节打磨得极好。Prometheus 起步较晚,吸收了 Borgmon 的精华,可以搞定微服务和 Kubernetes 的监控,而且非常注重功能边界的划分,哪些功能自己做、哪些功能交给社区来做,规划清晰,高内聚低耦合。
至于如何选型,我的建议是能用 Prometheus 生态搞定的都可以交给 Prometheus 来做,网络设备监控比较驳杂又相对独立,通常只有网工去管理相关的告警规则,做网络设备维护,其他人顶多就是看看数据,用 Zabbix 就挺合适。
这节课内容较多,我总结了一张脑图,供你复习参考。欢迎在评论区分享你对于 Zabbix 与 Prometheus 的使用感受,咱们一起交流进步。