01 背景信息:监控需求以及开源方案的横评对比
你好,我是秦晓辉。
今天我们就正式开始监控系统的学习之旅了,作为课程的第一讲,我想先让你了解一下监控相关的背景信息,对监控系统有一个整体性的了解。所以今天我们会先聊一聊监控的需求来源,也就是说监控系统都可以用来做什么,然后再跳出监控,从可观测性来看,监控与日志、链路之间的关系以及它们各自的作用。最后我们会介绍开源社区几个有代表性的方案以及它们各自的优缺点,便于你之后做技术选型。
掌握这些背景信息,是我们学习监控系统的基础。下面我们就先来了解一下监控的需求来源。
监控需求来源
最初始的需求,其实就是一句话:系统出问题了我们能及时感知到。当然,随着时代的发展,我们对监控系统提出了更多的诉求,比如:
- 通过监控了解数据趋势,知道系统在未来的某个时刻可能出问题,预知问题。
- 通过监控了解系统的水位情况,为服务扩缩容提供数据支撑。
- 通过监控来给系统把脉,感知到哪里需要优化,比如一些中间件参数的调优。
- 通过监控来洞察业务,提供业务决策的数据依据,及时感知业务异常。
目前监控系统越来越重要,同时也越来越完备。不但能够很好地解决上面这几点诉求,还沉淀出了很多监控系统中的稳定性相关的知识。当然,这得益于对监控体系的持续运营,特别是一些资深工程师的持续运营的成果。
可观测性三大支柱
我们所说的监控系统,其实只是指标监控,通常使用折线图形态呈现在图表上,比如某个机器的CPU利用率、某个数据库实例的流量或者网站的在线人数,都可以体现为随着时间而变化的趋势图。

指标监控只能处理数字,但它的历史数据存储成本较低,实时性好,生态庞大,是可观测性领域里最重要的一根支柱。聚焦在指标监控领域的开源产品有Zabbix、Open-Falcon、Prometheus、Nightingale等。
除了指标监控,另一个重要的可观测性支柱是日志。从日志中可以得到很多信息,对于了解软件的运行情况、业务的运营情况都很关键。比如操作系统的日志、接入层的日志、服务运行日志,都是重要的数据源。
从操作系统的日志中,可以得知很多系统级事件的发生;从接入层的日志中,可以得知有哪些域名、IP、URL 收到了访问,是否成功以及延迟情况等;从服务日志中可以查到 Exception 的信息,调用堆栈等,对于排查问题来说非常关键。但是日志数据通常量比较大,不够结构化,存储成本较高。
处理日志这个场景,也有很多专门的系统,比如开源产品ELK和Loki,商业产品Splunk和Datadog,下面是在 Kibana 中查询日志的一个页面。

可观测性最后一大支柱是链路追踪。随着微服务的普及,原本的单体应用被拆分成很多个小的服务,服务之间有错综复杂的调用关系,一个问题具体是哪个模块导致的,排查起来其实非常困难。
链路追踪的思路是以请求串联上下游模块,为每个请求生成一个随机字符串作为请求ID。服务之间互相调用的时候,把这个ID逐层往下传递,每层分别耗费了多长时间,是否正常处理,都可以收集起来附到这个请求ID上。后面追查问题时,拿着请求ID就可以把串联的所有信息提取出来。链路追踪这个领域也有很多产品,比如 Skywalking、Jaeger、Zipkin 等,都是个中翘楚。下面是Zipkin的一个页面。

虽然我们把可观测性领域划分成了3大支柱,但实际上它们之间是有很强的关联关系的。比如我们经常会从日志中提取指标,转存到指标监控系统,或者从日志中提取链路信息来做分析,这在业界都有很多实践。
我们这个课程会聚焦在指标监控领域,把这个领域的相关知识讲透,希望可以帮助你在工作中快速落地实践。下面我们就来一起梳理一下业界常见的开源解决方案。
业界方案横评
了解业界典型方案的一些优缺点,对选型有很大帮助。这里我们主要是评价开源方案,其实业内还有很多商业方案,特别是像IBM Tivoli这种产品,更是在几十年前就出现了,但是因为是商业产品,接触的人相对较少,这里就不点评了。
老一代整体方案的代表 Zabbix
Zabbix是一个企业级的开源解决方案,擅长设备、网络、中间件的监控。因为前几年使用的监控系统主要就是用来监控设备和中间件的,所以Zabbix在国内应用非常广泛。
Zabbix核心由两部分构成,Zabbix Server与可选组件Zabbix Agent。Zabbix Server可以通过SNMP、Zabbix Agent、JMX、IPMI等多种方式采集数据,它可以运行在Linux、Solaris、HP-UX、AIX、Free BSD、Open BSD、OS X等平台上。
Zabbix还有一些配套组件,Zabbix Proxy、Zabbix Java Gateway、Zabbix Get、Zabbix WEB等,共同组成了Zabbix整体架构。
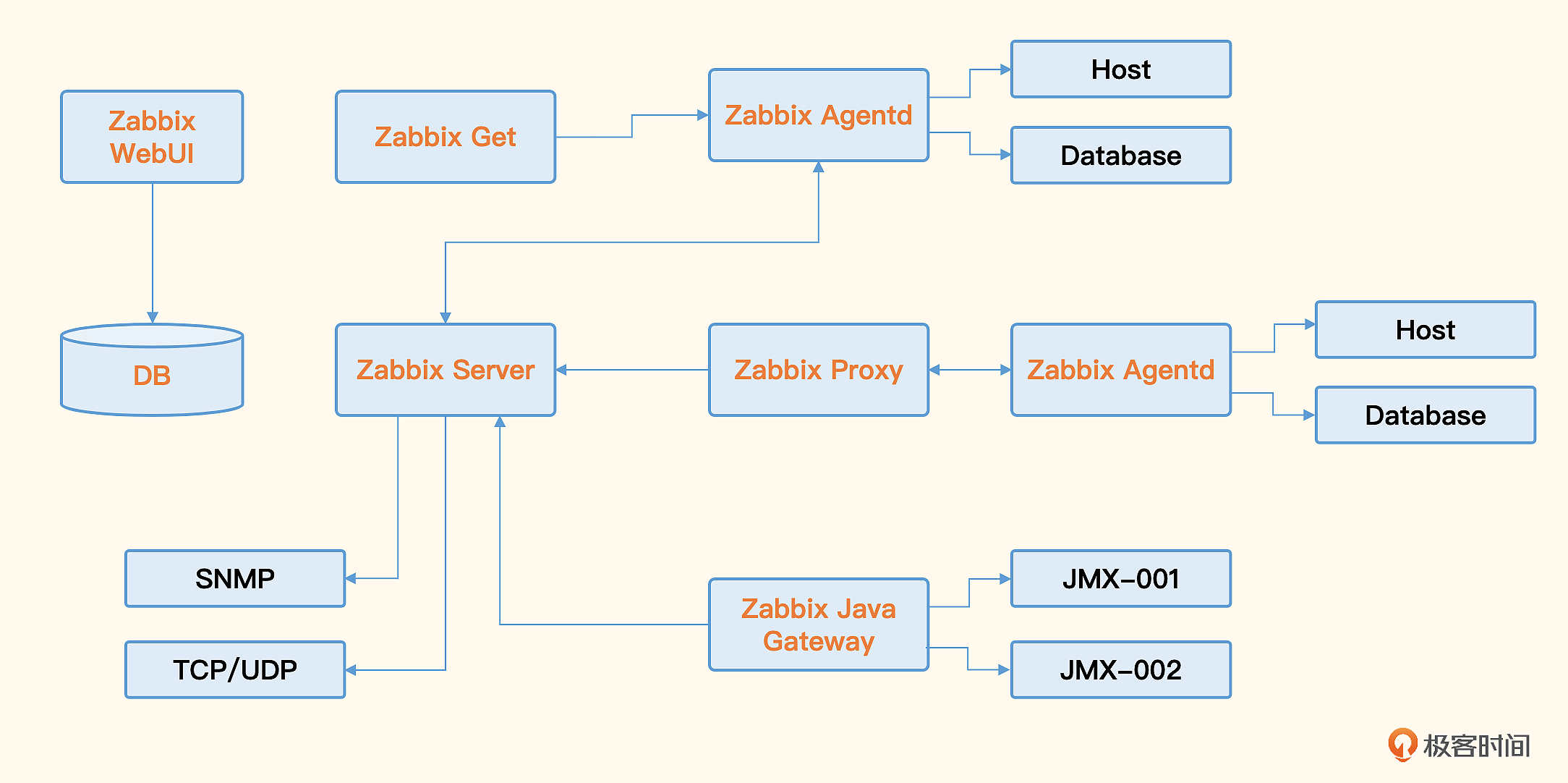
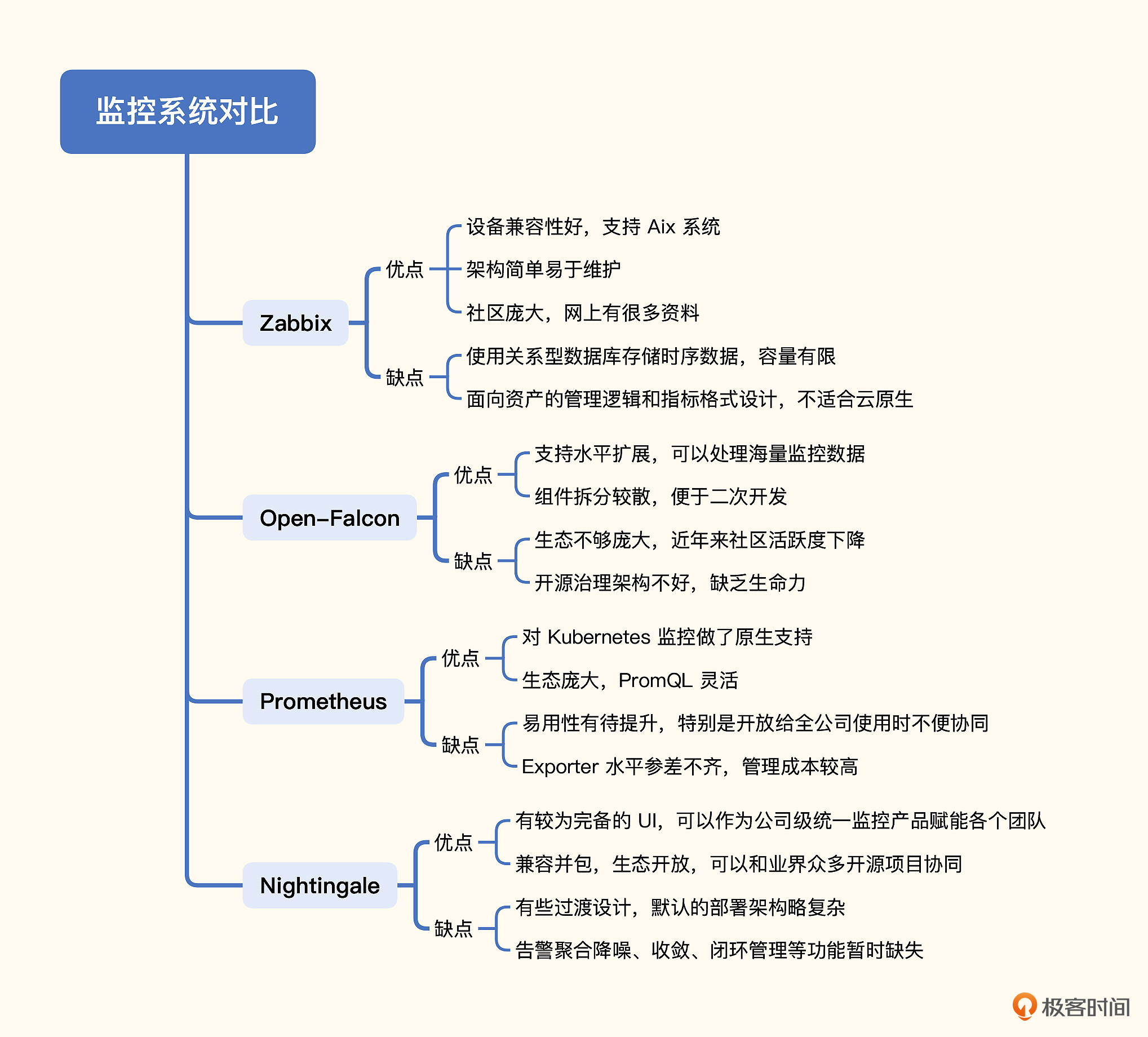
Zabbix的优点
- 对各种设备的兼容性较好,Agentd不但可以在Windows、Linux上运行,也可以在Aix上运行。
- 架构简单,使用数据库做时序数据存储,易于维护,备份和转储都比较容易。
- 社区庞大,资料多。Zabbix大概是2012年开源的,因为发展的时间比较久,在网上可以找到海量的资源。
Zabbix的缺点
- 使用数据库做存储,无法水平扩展,容量有限。如果采集频率较高,比如10秒采集一次,上限大约可以监控600台设备,还需要把数据库部署在一个很高配的机器上,比如SSD或者NVMe的盘才可以。
- Zabbix面向资产的管理逻辑,监控指标的数据结构较为固化,没有灵活的标签设计,面对云原生架构下动态多变的环境,显得力不从心。
老一代国产代表 Open-Falcon
Open-Falcon出现在Zabbix之后,开发的初衷就是想要解决Zabbix的容量问题。Open-Falcon最初来自小米,14年开源,当时小米有3套Zabbix,1套业务性能监控系统perfcounter。Open-Falcon的初衷是想做一套大一统的方案,来解决这个乱局。你可以看一下Open-Falcon的架构图。

Open-Falcon基于RRDtool做了一个分布式时序存储组件Graph。这种做法可以把多台机器组成一个集群,大幅提升海量数据的处理能力。前面负责转发的组件是Transfer,Transfer对监控数据求取一个唯一ID,再对ID做哈希,就可以生成监控数据和Graph实例的对应关系,这就是Open-Falcon架构中最核心的分片逻辑。
结合我们给出的架构图来看,告警部分是使用Judge模块来做的,发送告警事件的是Alarm模块,采集数据的是Agent,负责心跳的模块是HBS,负责聚合监控数据的模块是Aggregator,负责处理数据缺失的模块是Nodata。当然,还有用于和用户交互的Portal/Dashboard模块。
Open-Falcon把组件拆得比较散,组件比较多,部署起来相对比较麻烦。不过每个组件的职能单一,二次开发会比较容易,很多互联网公司都是基于Open-Falcon做了二次开发,比如美团、快网、360、金山云、新浪微博、爱奇艺、京东、SEA等。
Open-Falcon的优点
- 可以处理大规模监控场景,比Zabbix的容量要大得多,不仅可以处理设备、中间件层面的监控,也可以处理应用层面的监控,最终替换掉了小米内部的perfcounter和三套Zabbix。
- 组件拆分得比较散,大都是用Go语言开发的,Web部分是用Python,易于做二次开发。
Open-Falcon的缺点
- 生态不够庞大,是小米公司在主导,很多公司做了二次开发,但是都没有回馈社区,有一些贡献者,但数量相对较少。
- 开源软件的治理架构不够优秀,小米公司的核心开发人员离职,项目就停滞不前了,小米公司后续也没有大的治理投入,相比托管在基金会的项目,缺少了生命力。
新一代整体方案代表 Prometheus
Prometheus的设计思路来自Google的Borgmon,师出名门,就像Borgmon是为Borg而生的,而Prometheus就是为Kubernetes而生的。它针对Kubernetes做了直接的支持,提供了多种服务发现机制,大幅简化了Kubernetes的监控。
在Kubernetes环境下,Pod创建和销毁非常频繁,监控指标生命周期大幅缩短,这导致类似Zabbix这种面向资产的监控系统力不从心,而且云原生环境下大都是微服务设计,服务数量变多,指标量也呈爆炸态势,这就对时序数据存储提出了非常高的要求。
Prometheus 1.0的版本设计较差,但从2.0开始,它重新设计了时序库,性能、可靠性都有大幅提升,另外社区涌现了越来越多的Exporter采集器,非常繁荣。你可以看一下Prometheus的架构图。

Prometheus的优点
- 对Kubernetes支持得很好,目前来看,Prometheus就是Kubernetes监控的标配。
- 生态庞大,有各种各样的Exporter,支持各种各样的时序库作为后端的Backend存储,也有很好的支持多种不同语言的SDK,供业务代码嵌入埋点。
Prometheus的缺点
- 易用性差一些,比如告警策略需要修改配置文件,协同起来比较麻烦。当然了,对于IaC落地较好的公司,反而认为这样更好,不过在国内当下的环境来看,还无法走得这么靠前,大家还是更喜欢用Web界面来查看监控数据、管理告警规则。
- Exporter参差不齐,通常是一个监控目标一个Exporter,管理起来成本比较高。
- 容量问题,Prometheus默认只提供单机时序库,集群方案需要依赖其他的时序库。
新一代国产代表 Nightingale
Nightingale 可以看做是 Open-Falcon 的一个延续,因为开发人员是一拨人,不过两个软件的定位截然不同,Open-Falcon 类似 Zabbix,更多的是面向机器设备,而Nightingale 不止解决设备和中间件的监控,也希望能一并解决云原生环境下的监控问题。
但是在 Kubernetes 环境下,Prometheus 已经大行其道,再重复造轮子意义不大,所以 Nightingale 的做法是和 Prometheus 做良好的整合,打造一个更完备的方案。当下的架构,主要是把 Prometheus 当成一个时序库,作为 Nightingale 的一个数据源。如果不使用 Prometheus 也没问题,比如使用 VictoriaMetrics 作为时序库,也是很多公司的选择。

Nightingale的优点
- 有比较完备的UI,有权限控制,产品功能比较完备,可以作为公司级统一的监控产品让所有团队共同使用。Prometheus一般是每个团队自己用自己的,比较方便。如果一个公司用同一套Prometheus系统来解决监控需求会比较麻烦,容易出现我们上面说的协同问题,而Nightingale在协同方面做得相对好一些。
- 兼容并包,设计上比较开放,支持对接 Categraf、Telegraf、Grafana-Agent、Datadog-Agent 等采集器,还有Prometheus生态的各种Exporter,时序库支持对接 Prometheus、VictoriaMetrics、M3DB、Thanos 等。
Nightingale的缺点
- 考虑到机房网络割裂问题,告警引擎单独拆出一个模块下沉部署到各个机房,但是很多中小公司无需这么复杂的架构,部署维护起来比较麻烦。
- 告警事件发送缺少聚合降噪收敛逻辑,官方的解释是未来会单独做一个事件中心的产品,支持Nightingale、Zabbix、Prometheus等多种数据源的告警事件,但目前还没有放出。
上面我介绍了4种典型方案,每种方案各有优缺点,如果你的主要需求是监控设备,推荐你使用Zabbix;如果你的主要需求是监控Kubernetes,可以选择Prometheus+Grafana;如果你既要兼顾传统设备、中间件监控场景,又要兼顾Kubernetes,做成公司级方案,推荐你使用 Nightingale。
小结
最后,我们来回顾一下这一讲的主要内容。
这一讲我们了解了监控产品的需求来源,即监控问题域,从最开始的一句话需求——及时感知系统出现的问题,到现在希望预知问题,并且可以洞察业务经营数据,越来越多的诉求让我们意识到监控的重要性。
指标监控是可观测性三大支柱产品之一,除了指标监控之外,还有日志监控和链路追踪。这三者并不是独立的,它们之间联系紧密,共同辅助我们衡量系统内外部的健康状况。其中指标监控因历史数据存储成本较低,实时性好,生态庞大,是可观测性领域里最重要的一根支柱,也是我们关注的重点。
最后我们对指标监控领域的多个开源解决方案做了横评对比,帮助你做技术方案的选型。针对指标监控的几个开源方案的优缺点比较,我做了一个脑图,帮助你对比记忆。
互动时刻
指标监控领域还有很多其他的解决方案,你还知道哪些其他产品?欢迎留言分享,你可以简单说一下产品名字、适用场景、优缺点,三个臭皮匠顶个诸葛亮,我们一起讨论,互相帮助。也欢迎你把今天的内容分享给你身边的朋友,邀他一起学习。我们下一讲再见!
点击加入课程交流群
- 顶级心理学家 👍(20) 💬(5)
秦总,IaC 落地 概念不是很清楚,想深入了解下,感谢👍
2023-01-09 - StackOverflow 👍(18) 💬(2)
监控不同指标要配置一堆exporter维护起来也很麻烦
2023-01-09 - 无聊的上帝 👍(7) 💬(2)
老师你好,在工作中遇到了日志监控和链路追踪很难落地的问题. 被挑战的点如下,请教老师这种局可有破解方法? 1. ELK成本较高,价值性较低.出现问题研发直接看pod的log.代码质量确实高,线上环境从未遇见严重bug. 2. 链路追踪的价值是什么,能给业务带来哪些提升?
2023-01-11 - 陈陈陈陈陈👅 👍(7) 💬(1)
目前的困境是告警泛滥,希望能减少不必要的告警指标,但又会顾虑正式这些指标的缺失导致问题的发生
2023-01-10 - 怀朔 👍(7) 💬(2)
全球的化节点部署或者多机房的机房部署。 运维维护往往其实还是多套数据,同一个展示 或者多个数据 多地方展示 因为要考虑的权限 容量 告警聚合收敛等问题
2023-01-09 - LiangDu 👍(5) 💬(5)
希望老师提供完善的告警规则和grafana仪表盘文件,对很多小白来说这两块才是核心。
2023-01-09 - Geek_e2uyqd 👍(3) 💬(1)
多套监控系统维护确实是个问题 目前还没太好的方案
2023-01-09 - peter 👍(2) 💬(2)
请教老师几个问题: Q1:生产环境中日志是开启的吗? 出了问题以后,通过日志来定位问题。但是,生产环境中一般不能开启日志吧。如果不开启的话,怎么利用日志来定位问题呢。好像是个矛盾的事情。 Q2:大厂开发人员是怎么查看日志的? 对于日志,开发人员是直接用Editplus一类的软件来打开看吗?还是说会用专门的工具软件来查看日志文件?如果用工具软件,用开源的软件还是公司自研的软件? Q3:open-falcon架构图中怎么没有server? Zabbix有server,Open-falcon是基于Zabbix发展起来的,按理说也应该有一个server,但架构图中看不出来哪个部分是server。 Q3:Prometheus两个问题 1 没有采用k8s的网站系统,可以用Prometheus吗? 2 Prometheus可以完成全面的监控吗? 包括机器、网络、应用、各个中间件等。 Q4:指标监控数据一般怎么存储的?存在MySQL中吗?
2023-01-10 - 奥特虾不会写代码 👍(2) 💬(4)
老师你好,想请教一下对于网络连通性受限的场景下除了 Pushgateway 还有更好的方案不,因为 Pushgateway 使用下来的体验确实不尽如人意,公有云厂商的云主机也是通过类似于Pushgateway 的机制对外推送指标吗?
2023-01-10 - Hello Strong 👍(2) 💬(1)
两三年前因为公司需要,做过一次监控平台的选型,此前在用的就是zabbix,对k8s支持主要靠一些不太热门的插件模块,感觉灵活度太低。选型主要是Prometheus和在用的elk日志平台,前者作为tsdb非常适合指标数据,性能也强。后者的缺点也是前者的优点,但elastic在对采集源的支持度上其实还是可以的,k8s、各种数据中间件、队列、web gateway等都有,这点和Prometheus体系相比不会差太多,图形化方面grafana和kibana也都ok,告警组件方面如果不付费,elastic主要靠一些开源第三方项目的支持,这点不如Prometheus。最后选择了elk方案,原因有点无奈,一方面是Prometheus数据存储的高可用原因,还要再引入其他存储,另一方面elk是已经长期在用的日志平台,各方面都相对熟悉,而且能投入的硬件资源也有限,在数据规模不大的情况下用同一套能满足。
2023-01-10 - LEON 👍(2) 💬(2)
老师,我是纯纯小白Exporter 是什么意思?
2023-01-09 - 嘉言 👍(1) 💬(1)
老师,告警规则文件,一般在哪里可以找到
2024-10-27 - 晴空万里 👍(1) 💬(1)
老师好 我们部门准备做一个监控平台 不知道这种切入点在哪里?老师的课程有用,市面上很少这种课程
2023-02-20 - 不经意间 👍(1) 💬(2)
目前我这边也存在传统的服务器监控和基于k8s的云原生服务的监控。 看看zabbix也支持了k8s的pod自动发现,有点犹豫要不要继续支持zabbix(其实zabbix最核心的还是自动发现对于一些指标的采集),我目前还用exporter在zabbix上利用promql做指标的自动发现和处理。其实其他的也行,就看值不值得这么折腾。还有就是zabbix是支持单个指标的ttl的,不过好像prom设计理念中就不需要数据的长时间存储?(2年即以上时间) 不过现在也用了prom,直接上搭配的thanos和minio。
2023-01-11 - 运维夜谈 👍(1) 💬(1)
一直在想能不能基于Prometheus、Loki、skywalking,集成一个统一的管理平台,能实现监控部署的界面化操作,还能节省exporter部署的麻烦
2023-01-11