04 如何快速搭建Prometheus系统?
你好,我是秦晓辉。
前面三讲我们介绍了监控系统的一些基本概念,这一讲我们开始进入实操环节,部署监控系统。业界可选的开源方案很多,随着云原生的流行,越来越多的公司开始拥抱云原生,而云原生标配的监控系统显然就是 Prometheus,而且Prometheus的部署非常简单,所以这一讲我们就先来自己动手搭建Prometheus。
通用架构回顾
还记得我们上一讲介绍的监控系统通用架构吗?我们可以回顾一下。
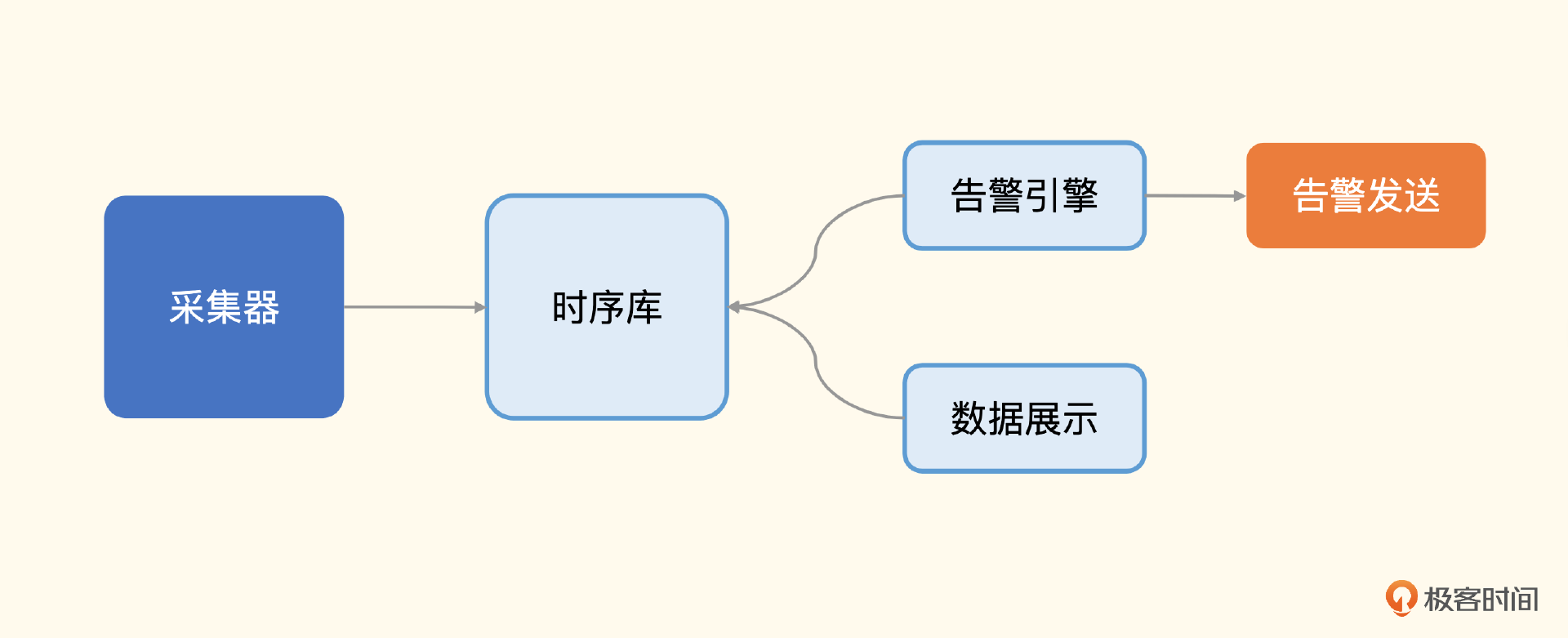
之所以说 Prometheus 比较容易搭建,是因为它把服务端组件,包括时序库、告警引擎、数据展示三大块,整合成了一个进程,组件的数量大幅减少。Prometheus生态的采集器就是各种Exporter,告警发送靠的是 AlertManager 组件,下面我们先来部署 Prometheus 模块。
部署 Prometheus
因为生产环境大概率是Linux的,所以我们选择Linux下的发布包,把Prometheus 和 Alertmanager 两个包都下载下来。
注:Prometheus 的下载地址:https://prometheus.io/download/
下载之后解压缩,使用 systemd 托管启动,你可以参考下面的命令。
mkdir -p /opt/prometheus
wget https://github.com/prometheus/prometheus/releases/download/v2.37.1/prometheus-2.37.1.linux-amd64.tar.gz
tar xf prometheus-2.37.1.linux-amd64.tar.gz
cp -far prometheus-2.37.1.linux-amd64/* /opt/prometheus/
# service
cat <<EOF >/etc/systemd/system/prometheus.service
[Unit]
Description="prometheus"
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
ExecStart=/opt/prometheus/prometheus --config.file=/opt/prometheus/prometheus.yml --storage.tsdb.path=/opt/prometheus/data --web.enable-lifecycle --enable-feature=remote-write-receiver --query.lookback-delta=2m --web.enable-admin-api
Restart=on-failure
SuccessExitStatus=0
LimitNOFILE=65536
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=prometheus
[Install]
WantedBy=multi-user.target
EOF
systemctl enable prometheus
systemctl start prometheus
systemctl status prometheus
这里需要重点关注的是 Prometheus 进程的启动参数,我在每个参数下面都做出了解释,你可以看一下。
--config.file=/opt/prometheus/prometheus.yml
指定 Prometheus 的配置文件路径
--storage.tsdb.path=/opt/prometheus/data
指定 Prometheus 时序数据的硬盘存储路径
--web.enable-lifecycle
启用生命周期管理相关的 API,比如调用 /-/reload 接口就需要启用该项
--enable-feature=remote-write-receiver
启用 remote write 接收数据的接口,启用该项之后,categraf、grafana-agent 等 agent 就可以通过 /api/v1/write 接口推送数据给 Prometheus
--query.lookback-delta=2m
即时查询在查询当前最新值的时候,只要发现这个参数指定的时间段内有数据,就取最新的那个点返回,这个时间段内没数据,就不返回了
--web.enable-admin-api
启用管理性 API,比如删除时间序列数据的 /api/v1/admin/tsdb/delete_series 接口
如果正常启动,Prometheus 默认会在 9090 端口监听,访问这个端口就可以看到 Prometheus 的 Web 页面,输入下面的 PromQL 可以查到一些监控数据。
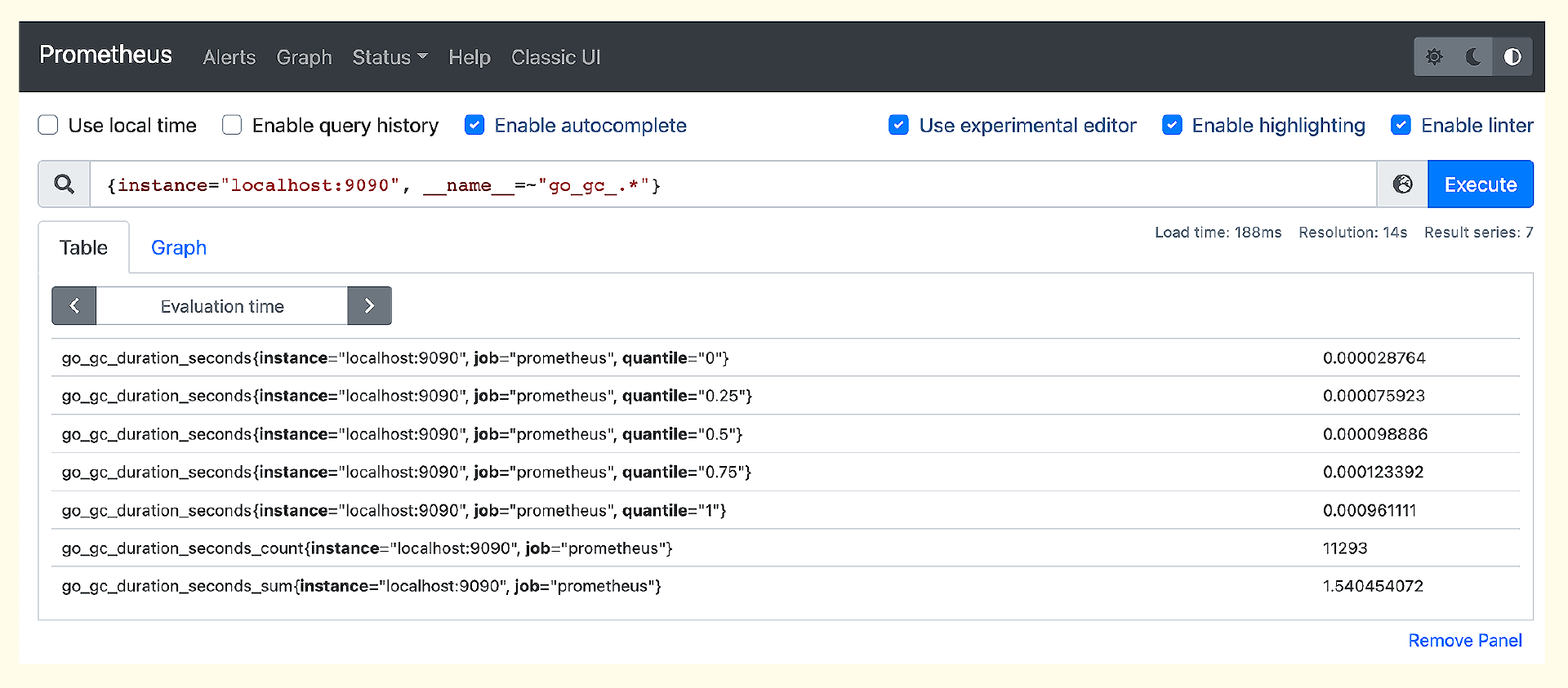
这个数据是从哪里来的呢?其实是 Prometheus 自己抓取自己的,Prometheus 会在 /metrics 接口暴露监控数据,你可以访问这个接口看一下输出。同时Prometheus在配置文件里配置了抓取规则,打开 prometheus.yml 就可以看到了。
localhost:9090是暴露监控数据的地址,没有指定接口路径,默认使用 /metrics,没有指定 scheme,默认使用 HTTP,所以实际请求的是 http://localhost:9090/metrics。了解了 Prometheus 自监控的方式,下面我们来看一下机器监控。
部署 Node-Exporter
Prometheus生态的机器监控比较简单,就是在所有的目标机器上部署 Node-Exporter,然后在抓取规则中给出所有 Node-Exporter 的地址就可以了。
首先,下载 Node-Exporter。你可以选择当下比较稳定的版本 1.3.1,下载之后解压就可以直接运行了,比如使用 nohup(生产环境建议使用 systemd 托管) 简单启动的话,可以输入下面这一行命令。
Node-Exporter 默认的监听端口是9100,我们可以通过下面的命令看到 Node-Exporter 采集的指标。
然后把 Node-Exporter 的地址配置到 prometheus.yml 中即可。修改了配置之后,记得给 Prometheus 发个 HUP 信号,让 Prometheus 重新读取配置:kill -HUP <prometheus pid>。最终 scrape_configs 部分变成下面这段内容。
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node_exporter'
static_configs:
- targets: ['localhost:9100']
其中 targets 是个数组,如果要监控更多机器,就在 targets 中写上多个 Node-Exporter 的地址,用逗号隔开。之后在 Prometheus 的 Web 上(菜单位置Status -> Targets),就可以看到相关的 Targets 信息了。
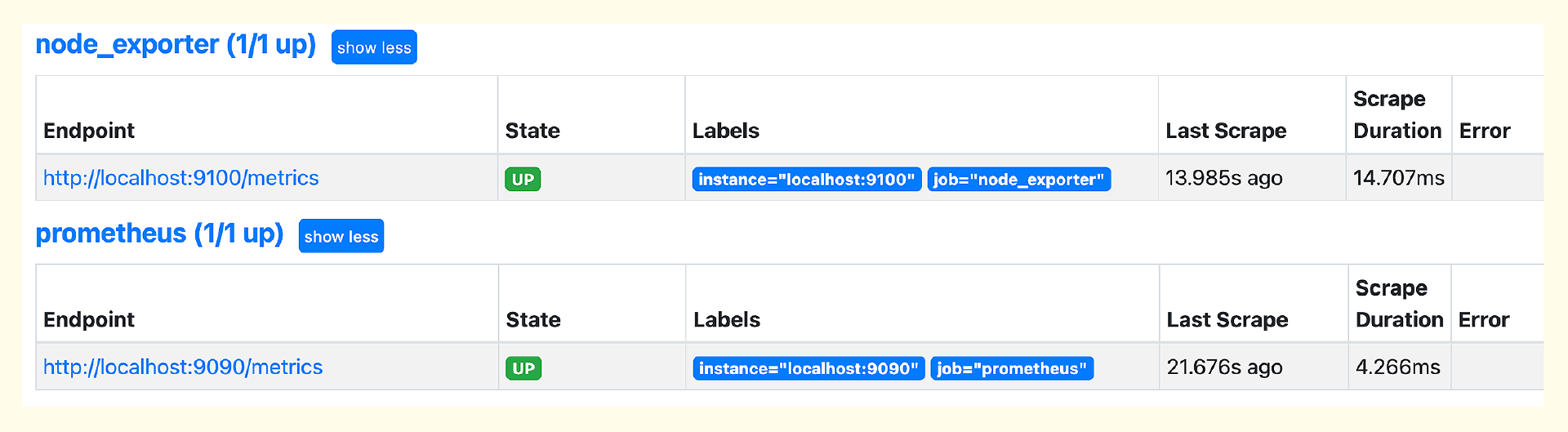
在查询监控数据的框里输入 node,就会自动提示很多 node 打头的指标。这些指标都是 Node-Exporter 采集的,选择其中某一个就可以查到对应的监控数据,比如查看不同硬盘分区的余量大小。
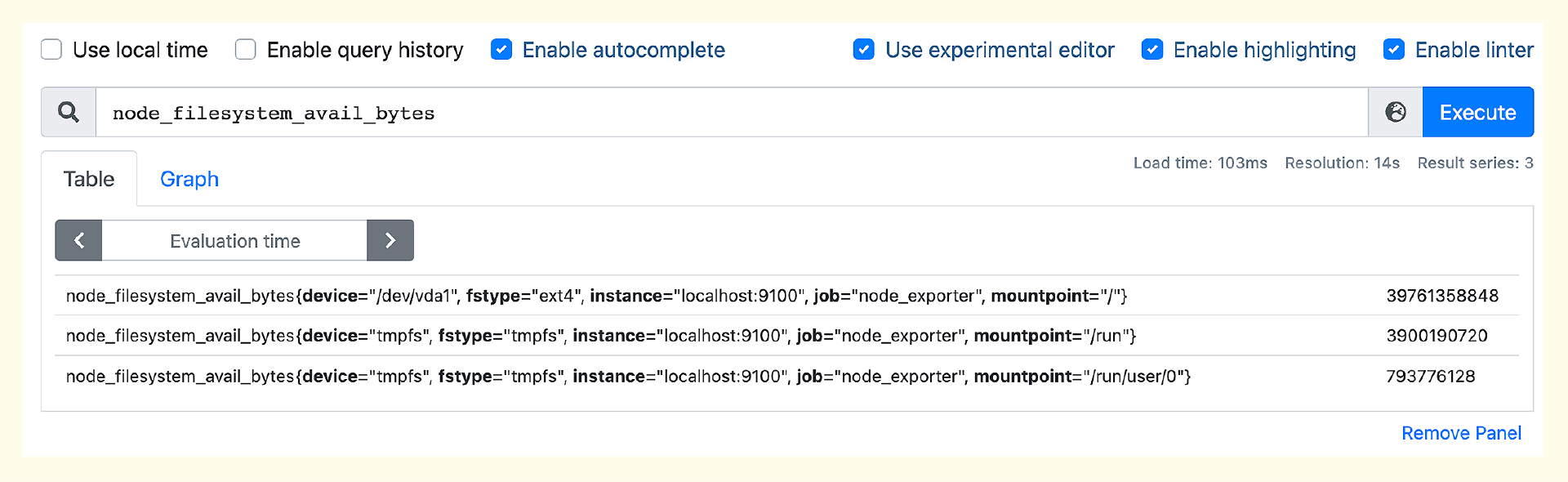
Node-Exporter 默认内置了很多 collector,比如 cpu、loadavg、filesystem 等,可以通过命令行启动参数来控制这些 collector,比如要关掉某个 collector,使用 --no-collector.<name>,如果要开启某个 collector,使用 --collector.<name>。具体可以参考 Node-Exporter 的 README。Node-Exporter 默认采集几百个指标,有了这些数据,我们就可以演示告警规则的配置了。
配置告警规则
Prometheus 进程内置了告警判断引擎,prometheus.yml 中可以指定告警规则配置文件,默认配置中有个例子。
我们可以把不同类型的告警规则拆分到不同的配置文件中,然后在 prometheus.yml 中引用。比如 Node-Exporter 相关的规则,我们命名为 node_exporter.yml,最终这个rule_files就变成了如下配置。
我设计了一个例子,监控 Node-Exporter 挂掉以及内存使用率超过1%这两种情况。这里我故意设置了一个很小的阈值,确保能够触发告警。
groups:
- name: node_exporter
rules:
- alert: HostDown
expr: up{job="node_exporter"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: Host down {{ $labels.instance }}
- alert: MemUtil
expr: 100 - node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 > 1
for: 1m
labels:
severity: warn
annotations:
summary: Mem usage larger than 1%, instance:{{ $labels.instance }}
最后,给 Prometheus 进程发个 HUP 信号,让它重新加载配置文件。
之后,我们就可以去 Prometheus 的 Web 上(Alerts菜单)查看告警规则的判定结果了。
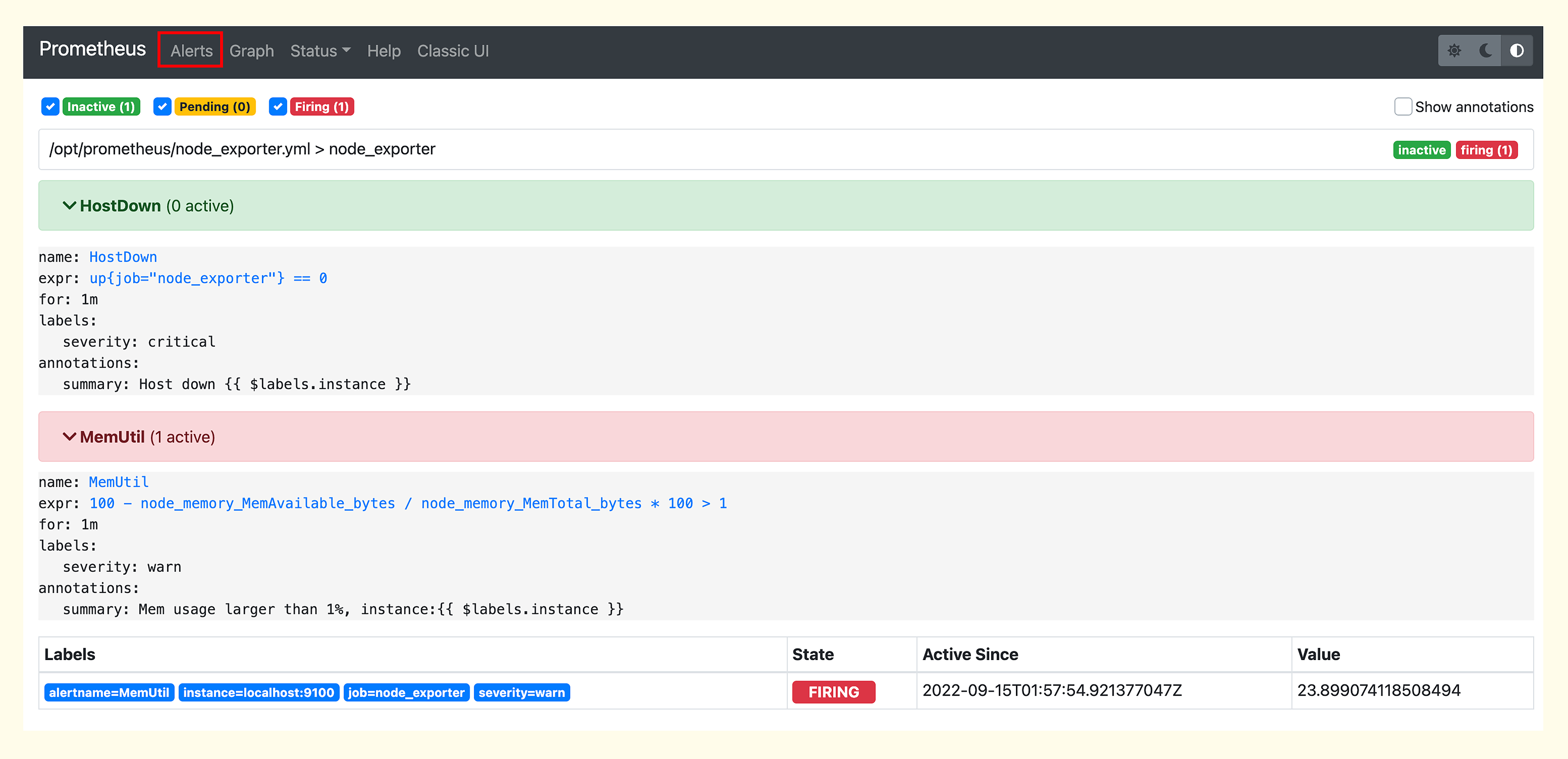
我们从图中可以看出,告警分成3个状态,Inactive、Pending、Firing。HostDown这个规则当前是Inactive状态,表示没有触发相关的告警事件,MemUtil这个规则触发了一个事件,处于Firing状态。那什么是Pending状态呢?触发过阈值但是还没有满足持续时长( for 关键字后面指定的时间段)的要求,就是Pending状态。比如 for 1m,就表示触发阈值的时间持续1分钟才算满足条件,如果规则判定执行频率是10秒,就相当于连续6次都触发阈值才可以。
在页面上我们看到告警了,就是一个巨大的进步,如果我们还希望在告警的时候收到消息通知,比如邮件、短信等,就需要引入 AlertManager 组件了。
部署 Alertmanager
部署 Prometheus 的时候,我们已经顺便把 Alertmanager 的包下载下来了,下面我们就安装一下。安装过程很简单,把上面的 prometheus.service 拿过来改一下给 Alertmanager 使用即可,下面是我改好的 alertmanager.service。
[Unit]
Description="alertmanager"
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/alertmanager/alertmanager
WorkingDirectory=/usr/local/alertmanager
Restart=on-failure
SuccessExitStatus=0
LimitNOFILE=65536
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=alertmanager
[Install]
WantedBy=multi-user.target
我把 Alertmanager 解压到 /usr/local/alertmanager 目录,通过ExecStart可以看出,直接执行二进制就可以,实际Alertmanager会读取二进制同级目录下的 alertmanager.yml 配置文件。我使用163邮箱作为SMTP发件服务器,下面我们来看下具体的配置。
global:
smtp_from: 'username@163.com'
smtp_smarthost: 'smtp.163.com:465'
smtp_auth_username: 'username@163.com'
smtp_auth_password: '这里填写授权码'
smtp_require_tls: false
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 1m
repeat_interval: 1h
receiver: 'email'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
- name: 'email'
email_configs:
- to: 'ulricqin@163.com'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
首先配置一个全局SMTP,然后修改 receivers。receivers 是个数组,默认例子里有个 web.hook,我又加了一个 email 的 receiver,然后配置 route.receiver 字段的值为 email。email_configs中的 to 表示收件人,多个人用逗号分隔,比如 to: 'user1@163.com, user2@163.com',最后收到的邮件内容大概是这样的,你可以看一下我给出的样例。
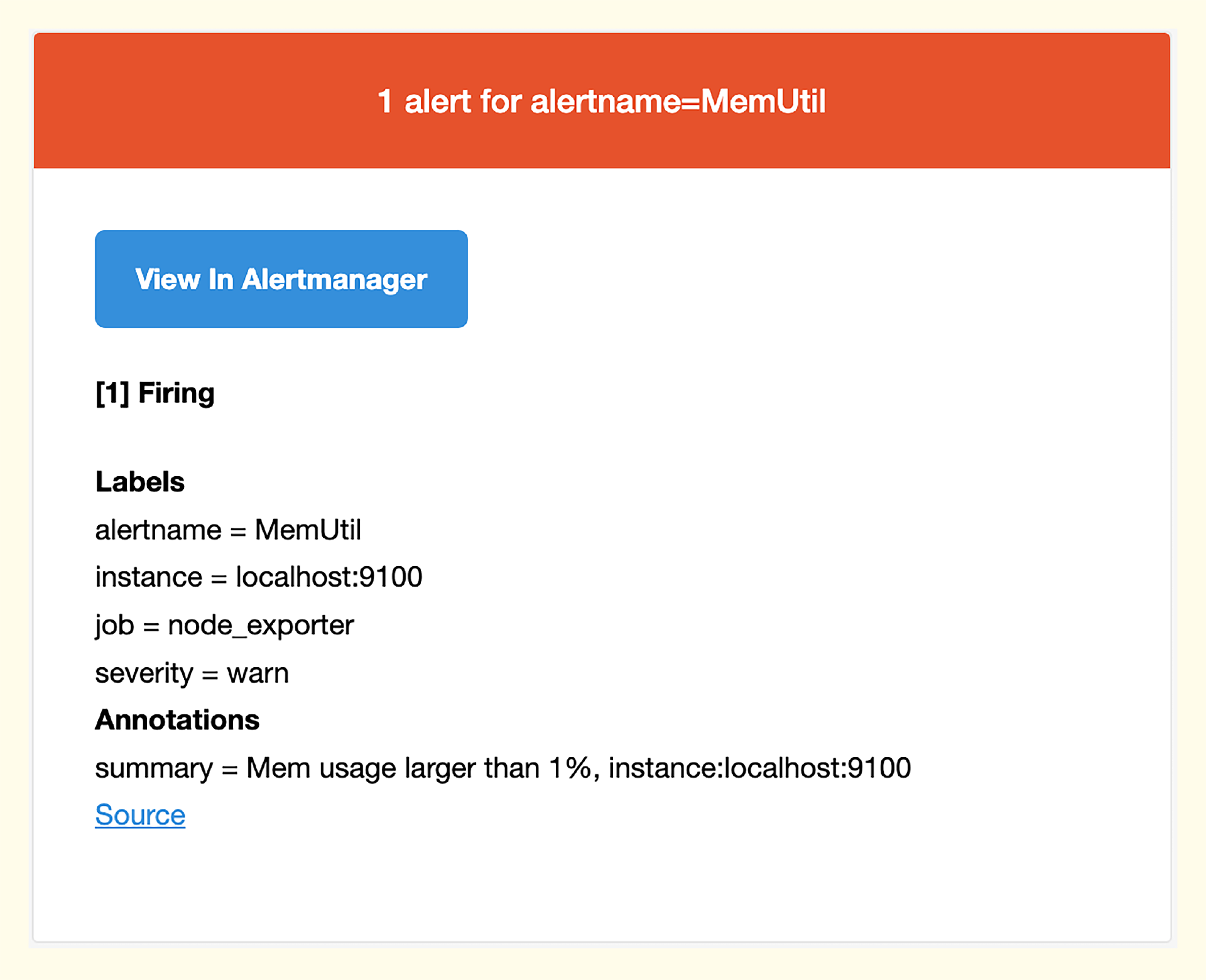
收到告警邮件,就说明这整个告警链路走通了。最后我们再看一下数据可视化的问题。Prometheus 自带的看图工具,是给专家用的,需要对指标体系非常了解,经验没法沉淀,而且绘图工具单一,只有折线图。如果你希望有一个更好用的UI工具,可以试试 Grafana。
部署 Grafana
Grafana 是一个数据可视化工具,有丰富的图表类型,视觉效果很棒,插件式架构,支持各种数据源,是开源监控数据可视化的标杆之作。Grafana可以直接对接Prometheus,大部分使用Prometheus的用户,也都会使用Grafana,下面我们就来部署一下。
我们可以先把 Grafana 下载下来,它分为两个版本,企业版和开源版,开源版本遵照AGPLV3协议,只要不做二次开发商业化分发,是可以直接使用的。我这里就下载了开源版本,选择 tar.gz 包,下载之后解压缩,执行 ./bin/grafana-server 即可一键启动,Grafana默认的监听端口是3000,访问后就可以看到登录页面了,默认的用户名和密码都是 admin。
要看图首先要配置数据源,在菜单位置:Configuration -> Data sources,点击 Add data source 就能进入数据源类型选择页面,选择Prometheus,填写Prometheus的链接信息,主要是URL,点击 Save & test 完成数据源配置。
Grafana提供了和Prometheus看图页面类似的功能,叫做Explore,我们可以在这个页面点选指标看图。
但Explore功能不是最核心的,我们使用Grafana,主要是使用Dashboard看图。Grafana社区有很多人制作了各式各样的大盘,以JSON格式上传保存在了 grafana.com,我们想要某个Dashboard,可以先去这个网站搜索一下,看看是否有人分享过,特别方便。因为我们已经部署了Node-Exporter,那这里就可以直接导入Node-Exporter的大盘,大盘ID是1860,写到图中对应的位置,点击Load,然后选择数据源点击Import即可。
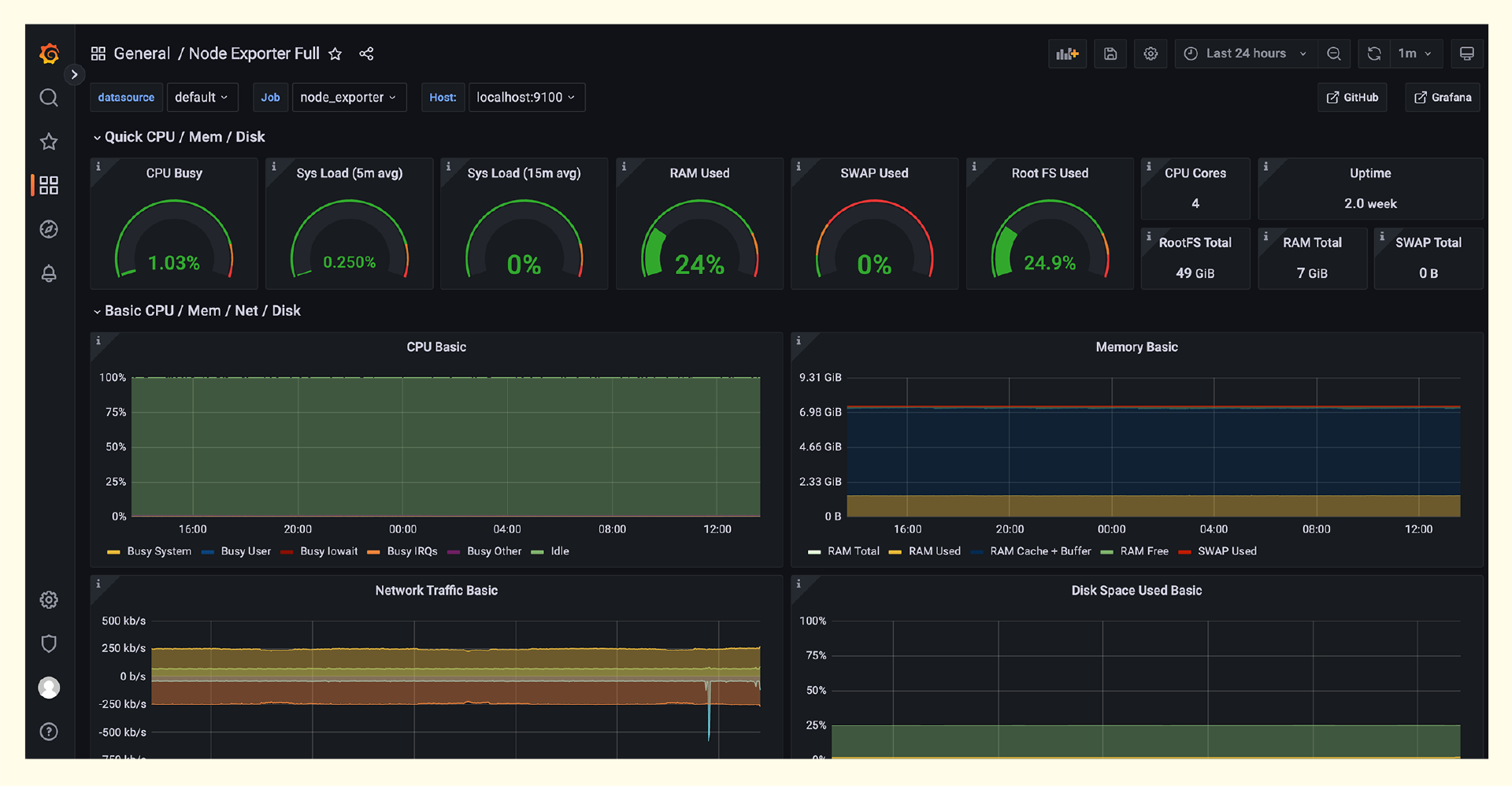
导入成功的话会自动打开Dashboard,Node-Exporter的大盘长这个样子。
走到这个监控看图的部分,我们也走完了整个流程。下面我们对这节课的内容做一个简单总结。
小结
本讲的核心内容就是演示Prometheus生态相关组件的部署。如果你在课程中是一步一步跟我操作下来的,相信你对Prometheus这套生态就有了入门级的认识。学完这些内容我们再来看一下 Prometheus 的架构图,和监控系统通用架构图相互做一个印证,加深理解。

图上有两个部分我们没有讲到,一个是Pushgateway组件,另一个是Service discovery部分。这里我再做一个简单的补充。
- Pushgateway:用于接收短生命周期任务的指标上报,是PUSH的接收方式。因为Prometheus主要是PULL的方式拉取监控数据,这就要求在拉取的时刻,监控对象得活着,但是很多短周期任务,比如cronjob,可能半秒就运行结束了,就没法拉取了。为了应对这种情况,才单独做了Pushgateway组件作为整个生态的补充。
- Service discovery:我们演示抓取数据时,是直接在 prometheus.yml 中配置的多个 Targets。这种方式虽然简单直观,但是也有弊端,典型的问题就是如果 Targets 是动态变化的,而且变化得比较频繁,那就会造成管理上的灾难。所以 Prometheus 提供了多种服务发现机制,可以动态获取要监控的目标,比如 Kubernetes 的服务发现,可以通过调用 kube-apiserver 动态获取到需要监控的目标对象,大幅降低了抓取目标的管理成本。
最后,我把这一讲的内容整理了一张脑图,供你理解和记忆。

互动时刻
监控数据的获取,有推(PUSH)拉(PULL)两种模式,不是非黑即白的,不同的场景选择不同的方式,本讲我们在介绍Pushgateway模块时提到了一些选型的依据,你知道推拉两种模式的其他优缺点和适用场景吗?欢迎留言分享,也欢迎你把今天的内容分享给你身边的朋友,邀他一起学习。我们下节课再见!
点击加入课程交流群
- 凡人 👍(2) 💬(2)
秦老师,你好,文章中 有两个小细节问题 1. 文章中没有提到 需要修改 prometheus.yml 中的 # - alertmanager:9093。 2. 163邮箱的smtp协议 非ssl端口号是25 (https://note.youdao.com/ynoteshare/index.html?id=f9fef46114fb922b45460f4f55d96853)
2023-01-29 - 隆哥 👍(1) 💬(1)
①部署了prometheus,无法通过IP+9090访问,有可能是防火墙没有关闭,我使用的是CentOS系列 systemctl stop firewalld.service systemctl disable firewalld.service ②添加node_exporter在Status -> Targets无法查看,prometheus修改配置需要每次重新加载读取 systemctl restart prometheus ③如何添加报警规则 请在应用目录prometheus下创建一个rules文件夹,然后在文件夹中添加node_exporter.yml [root@bogon prometheus]#mkdir -p rules && cd rules && vim node_exporter.yml 添加规则内容之后,配置prometheus.yml,这样子目录更美观,新重启服务systemctl restart prometheus rule_files: - "rules/node_exporter.yml" ④为什么我grafana控制面板有时候图标会出现断层呢? 如果觉得教程麻烦,提供一键docker-compose剧本 version: '3' networks: monitor: driver: bridge services: prometheus: image: prom/prometheus container_name: prometheus hostname: prometheus restart: always volumes: - /data/prometheus/data:/prometheus - /data/prometheus/rules:/etc/prometheus/rules - /data/prometheus/conf/prometheus.yml:/etc/prometheus/prometheus.yml ports: - "9090:9090" networks: - monitor alertmanager: image: prom/alertmanager container_name: alertmanager hostname: alertmanager restart: always volumes: - /data/alertmanager/config/alertmanager.yml:/etc/alertmanager/alertmanager.yml depends_on: - prometheus ports: - "9093:9093" networks: - monitor node-exporter: image: quay.io/prometheus/node-exporter container_name: node-exporter hostname: node-exporter restart: always environment: TZ: Asia/Shanghai volumes: depends_on: - prometheus ports: - "9100:9100" networks: - monitor grafana: image: grafana/grafana container_name: grafana hostname: grafana restart: always volumes: - /data/grafana/data:/var/lib/grafana depends_on: - prometheus ports: - "3000:3000" networks: - monitor
2023-01-16 - hshopeful 👍(15) 💬(2)
关于 pull 和 push 模式,个人的一些理解,有错误或遗漏的,希望老师指正: pull 模式的优点: 1、pull 模式很容易判断监控对象的存活性,push 模式很难 2、pull 模式的监控配置在服务端,比较容易统一控制,push 模式的监控配置在客户端,需要引入类似配置中心的组件,由客户端去拉取监控配置,从配置变更到配置生效的难易程度和时效性,pull 模式占优 3、pull 模式可以按需获取监控指标,push 模式只能被动接收监控指标,当然 push 模式也可以在服务端增加指标过滤规则 4、pull 模式下,应用与监控系统的耦合比较低,push 模式下,应用于监控系统的耦合性较高 push 模式的优点: 1、针对移动端的监控,只能使用 push 模式,不能使用 pull 模式 2、push 模式支持天然的水平扩展,pull 模式水平扩展比较复杂 3、push 模式适合短生命周期任务,pull 模式不适合 4、pull 模式依赖服务发现模块,push 模式不依赖 5、push 模式只用保证网络的正向联通(能够发送数据到服务端),比较简单,而 pull 模式需要保证网络的反向联通(服务端能够抓取多种多样的客户端暴露的接口),相对复杂 6、pull 模式需要暴露端口,安全性存在隐患,而 push 模式不存在 7、在聚合场景和告警场景下,push 模式的时效性更好
2023-01-16 - Amosヾ 👍(3) 💬(1)
关于告警有一些建议和疑问: 1、告警分级(提示、严重、致命)全部邮件推送很难体现优先级,尤其是致命告警应该电话处理 2、目前社区是否有成熟的告警推送工具,比如企业微信机器人、钉钉机器人,这些需要自行编码实现?电话告警该如何实现呢?
2023-01-22 - April 👍(2) 💬(2)
Prometheus没有提供很多管理上的API,又不想引入Service Discovery, 在targets变化后直接操作prometheus.conf有什么更为简单的方式吗?
2023-01-16 - 那时刻 👍(1) 💬(1)
请问老师,在k8s里部署prometheus,有哪些比较好的方式呢。
2023-01-17 - 隆哥 👍(1) 💬(2)
为啥不用docker形式来做实践呢,我觉得systemctl这种托管还是对主机入侵比较大。
2023-01-16 - Geek_df0d4d 👍(0) 💬(1)
请问生产上有什么prometheus的高可用方案吗
2023-04-06 - 孙宇翔 👍(0) 💬(3)
老师您好,我想监控像摄像机这类设备的在线、离线,还有流量等数据,普罗米修斯是否合适,配置里面该怎么设置,完全没头绪。。。
2023-03-02 - Matthew 👍(0) 💬(2)
老师,文章中提到的几个软件安装包,都需要从 github 上下载,但是下载速度太慢。能否提供下国内镜像源的地址呢?
2023-02-06 - Matthew 👍(0) 💬(4)
github 下载太慢,有啥好办法吗?
2023-02-03 - leeeo 👍(0) 💬(1)
源码编译prometheus可以去掉ui部分吗?
2023-02-03 - 顶级心理学家 👍(0) 💬(1)
秦老师,有个问题是关于exporter多实例的问题。 我们环境是prometheus operator,例如 redis采用redis-exporter采集。这样就造成多个redis实例,实现成了多个exporter 来采集。redis exporter有案例支持一个exporter采集多个实例,但是没能实现。 目前就是一个exporter 启动多个container,用不同端口采集多个redis实例,这样container会随着redis实例增多而庞大。 想听听您的建议和想法。
2023-01-18 - 俺木饭 三克油😂😂 👍(0) 💬(1)
老师问下如何做prom 和各类exporter之间的认证?比如公司安全需求所有接口需要做鉴权
2023-01-17 - 小飞同学 👍(0) 💬(2)
咨询下grafana端口外网通过ip无法访问可能是什么原因呢?3000端口在安全组已经放开了,防火墙也方阿奎了,另外Prometheus9090端口是正常用的。http://ip:3000/login Request URL: http://39.107.88.69:3000/login Referrer Policy: strict-origin-when-cross-origin Provisional headers are shown Learn more Upgrade-Insecure-Requests: 1
2023-01-17