03 Agent的常见推理模式:CoT、ReAct、Reflexion究竟是什么?
你好,我是邢云阳。
我上大学时有一位老师,他与各行各业的人都能比较专业的聊上几句,且还能推荐出相关的书籍。他曾给我们讲过,如何快速地进入一个行业领域,第一步就是先掌握这个领域的一些名词的含义。
因此我在第一节课,给你介绍了 Function Calling,在第二节课介绍了 Agent。在本节课,我将介绍 CoT、ReAct 等等这些常常在 AI 相关的场合听到的名词。在学完这三节课后,你就已经掌握了 AI Agent 理论的精髓,后续会开启实战。
CoT(Chain of Thoughts)
CoT 中文名称是思维链。最早是来自于人类向大模型提问时,无意中发现,如果加上一句 “Let’s think step by step”,大模型回答的效果就会有大幅增强。我们用 Kimi 大模型去测试一下。
首先不使用思维链:

使用思维链:
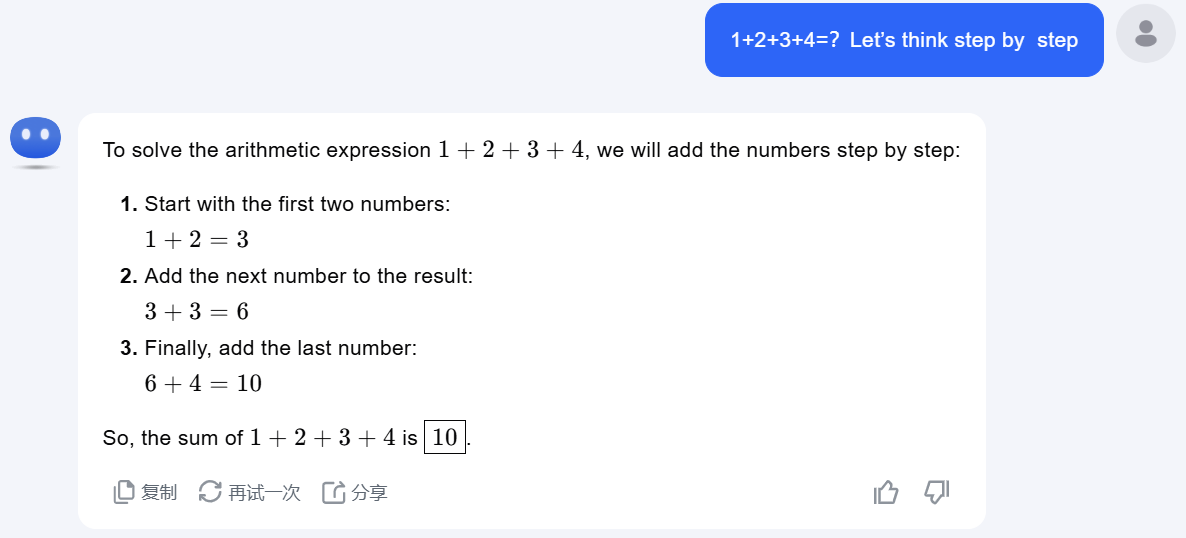
可以看到虽然使用和不使用思维链,这道题都算对了,但是,在用了思维链后,大模型把任务做了拆分并展示了每一步思考的过程。如果是一个复杂任务,或者我们想知道某个问题的具体解决步骤,那显然使用思维链效果会更好。
这其实就是让大模型不要着急回答问题,而是先推理拆解问题,然后再回答,这样一句简单的 prompt 就让大模型有了推理能力。
现如今,CoT 已经成为了业界通识,很多大模型在训练时,也已经加入了 CoT 思维。但实际上 CoT 只是单纯的链式思维推理,其会按照既定的逻辑、机械的顺序执行完每一步,并不关心每一步的结果是什么,因此容易产生幻觉。例如上文中的计算题,如果在计算1+2的时候,由于某种异常,返回了1+2=abc,则后续步骤会全错。因此我们往后学习,看一下有哪些新的方法能解决这种问题。
ReAct(Reason+Act)
ReAct 一词来自于论文《ReAct: Synergizing Reasoning and Acting in Language Models》,包含 Reason 与 Act 两个部分,其中 Reason 就是大模型推理的过程,其推理运用了 CoT 的思想;Act 是与外界环境交互的动作。
ReAct 发明的初衷是为了解决两个问题,第一,大模型执行的结果不可观测,导致出现“幻觉”;第二,大模型不能与外部环境交互,导致无法回答一些特定垂直领域或者实时问题。
我们先来结合一张图,了解一下 ReAct 的过程。
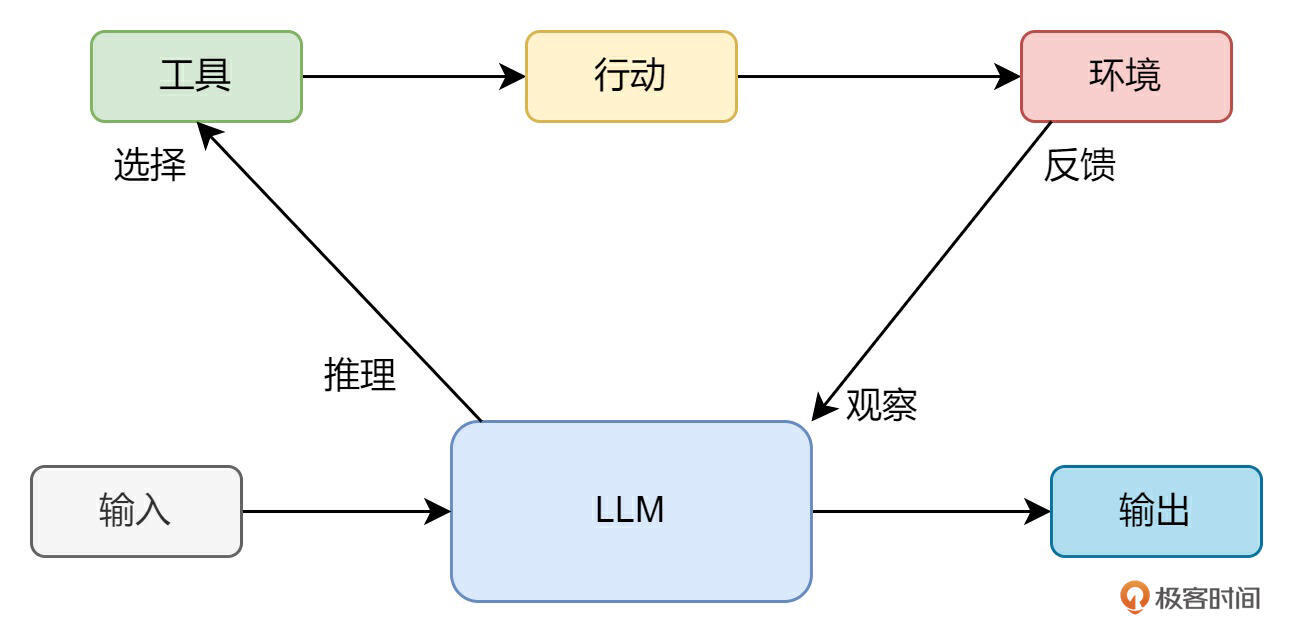
在最开始,我们输入给大模型一个任务,例如,任务为“请问济南的天气如何?”,同时将天气的 API 工具也输入给大模型。此时大模型会进行推理,得出的结论是需要调用天气预报工具来解决问题。
结合第一节课 Function Calling 相关的知识,我们知道,大模型只能选择工具,工具的执行者是人类。于是人类便开始行动,替大模型执行天气工具,并将得到的结果反馈给大模型。
此时重点来了,大模型会观察人类返回的结果,看看结果是否能满足要求。这里的观察主要是观察工具调用的结果对不对,是否有错误。当然这里指的有错误,是工具调用错误,而不是数据错误,例如工具反馈给大模型,济南的温度是 80℃,大模型是不会认为有问题的。但如果反馈给大模型的是“400 bad request”,则大模型就会认为工具调用出问题了,它会重新推理后,再次尝试调用工具。
如果大模型观察后,认为没问题,则会继续推理,思考是继续调用其他工具解决问题呢,还是答案已经能解决用户提问了呢?如果是前者,则就会继续进入选择工具、调用工具、反馈、观察的步骤;如果是后者,则大模型会直接输出答案。
我用一个连续对话为你整理一下以上过程,方便理解。
user: 济南的天气如何?+ 天气查询 API 工具(get_weather)
assistant: 经过思考,我需要调用get_weather工具
人类调用get_weather工具...
user: Observasion: 400 bad request
assistant: 看起来调用 get_weather 工具出错了,我们尝试再调用一次,我需要调用get_weather工具
人类调用get_weather工具...
user: Observasion: 济南晴,温度80℃
assistant: 我已经得到了最终答案,济南是晴天,温度80℃。
相信看到这里,你已经懂得了 ReAct的原理了。其实思想非常简单,就是在 CoT 推理方案的基础上,加上工具调用,以及工具结果观察,这样做可以极大地减少幻觉的产生。由于该方案思路简单,效果霸道,在 Agent 应用开发中,使用率非常高。
我们继续思考一下,如果我要问英国伦敦的天气如何?并给大模型提供两个服务商的天气查询 API 工具,例如一个高德地图天气,一个墨迹天气。但我只在墨迹天气开通了世界天气查询权限,高德地图天气只能查询国内的天气,你认为大模型最终能够反馈给我们正确的答案吗?如果可以,我们怎么保证,在以后的查询中,让大模型一次性就把问题答对呢?
Reflection && Reflexion
在《Language Agents with Verbal Reinforcement Learning》论文中,介绍了一种新的推理方案,名叫 Reflexion。该方案,实际上来自于一种名叫 Reflection(反思)的思路,并在此基础上做了加强设计。
所谓一日三省吾身,圣人每天都要多次反思,更何况普通人。因此为了减少大模型生成内容的“幻觉”问题,有一种名叫 Reflection 的方案上线了。方案简单易懂,如下图所示,除了用于生成内容的 Generate 大模型外,又增加了一个用于反思(检查)的 Reflect 大模型。这两个大模型的协作过程为:
- Generate 大模型收到用户的请求后,生成初始 response,并交给 Reflect 大模型。
- Reflect 会给出评估后,将评语等反馈返给 Generate 大模型。
- Generate 大模型根据评估做调整后,重新生成 response。
- 反复循环,直到达到用户设定的循环次数后,将最终的 response 返给用户。

这其实就是一个通过反思不断精益求精的问题,就好像我们在考试时,答完卷子要多检查几遍是一个道理。但是这仍然没有解决 ReAct 小节中,最后我留下的查伦敦天气的问题。因此,Reflection 的进阶版 Reflexion 出现了。
Reflexion 相比 Reflection,将反思这一步细化后,分成了如下图所示的 Evaluator(评估)和 self-reflection(自我反思)两个部分。图中剩余的另一个大模型 Actor,即为 Reflection 中的 Generator。图中还包含了 Trajectory(轨迹)以及 Experience(经验)两种记忆。

我们来串一下 Relecxion 的流程。
- 从 Actor 开始,还是根据用户提问,生成答案,但这次,Actor 继承了 ReAct 的能力,可以与外界环境交互,并观察答案,然后通过 Trajector 模块将对话记录存储在短期记忆,比如内存中。
- 之后,Evaluator 和 Self-reflection 模块开始介入,Evaluator 对对话结果做评估,检查答案是否正确。Self-reflection 则汇总评估结果,以及对话内容做总结反思,总结出经验教训后,存储到长期记忆中,比如 Redis 等等数据库。
- 等到下次再提类似问题时,可以将经验与问题同时输入给 Actor,这样有了经验做加持,Actor 就会少走弯路。
回到英国伦敦天气的例子,我们套用一下这个思路。假设第一次提问时,Actor 调用了高德地图天气 API,提示无权限,随后又调用墨迹天气 API,返回了伦敦天气阴,19 摄氏度。Evaluator 会验证 19 摄氏度是否准确,避免出现 80 摄氏度的情况。Self-reflection 会总结出:要想查询国外天气,需要调用墨迹天气 API。这样当下次提问美国纽约天气时,Actor 就会直接调用墨迹天气 API。
“前人种树,后人乘凉”,使用 Reflexion 模式,第一次可能体现不出优势,但其总结出的宝贵经验,将在后面遇到类似问题时,带来极大的降本增效的效果。
ReWOO(Reason WithOut Observation)
ReWOO 是在 ReAct 方案基础上,做的另一个方向的思考。我们知道,大模型是没有记忆的,因此人类在与大模型做多轮对话时,需要将对话历史全部发给大模型,大模型才能结合所谓的上下文做理解。例如:
第一轮提问:
user:C罗是哪个国家的运动员?
第一轮大模型回复:
assistant: 葡萄牙。
第二轮提问:
user:C罗是哪个国家的运动员?
assistant: 葡萄牙。
user: 内马尔呢?
第二轮大模型回复:
assistant: 巴西。
这样,随着轮次的增加,提问的成本会越来越高。
我们回顾 ReAct 思想,如下图所示,它实际上是大模型像挤牙膏一样,每次告诉人类一个问题解决步骤。然后人类需要将工具调用结果+对话历史,发送给大模型,反复循环,直到大模型解决问题,如果轮次特别多,就会非常消耗 token。
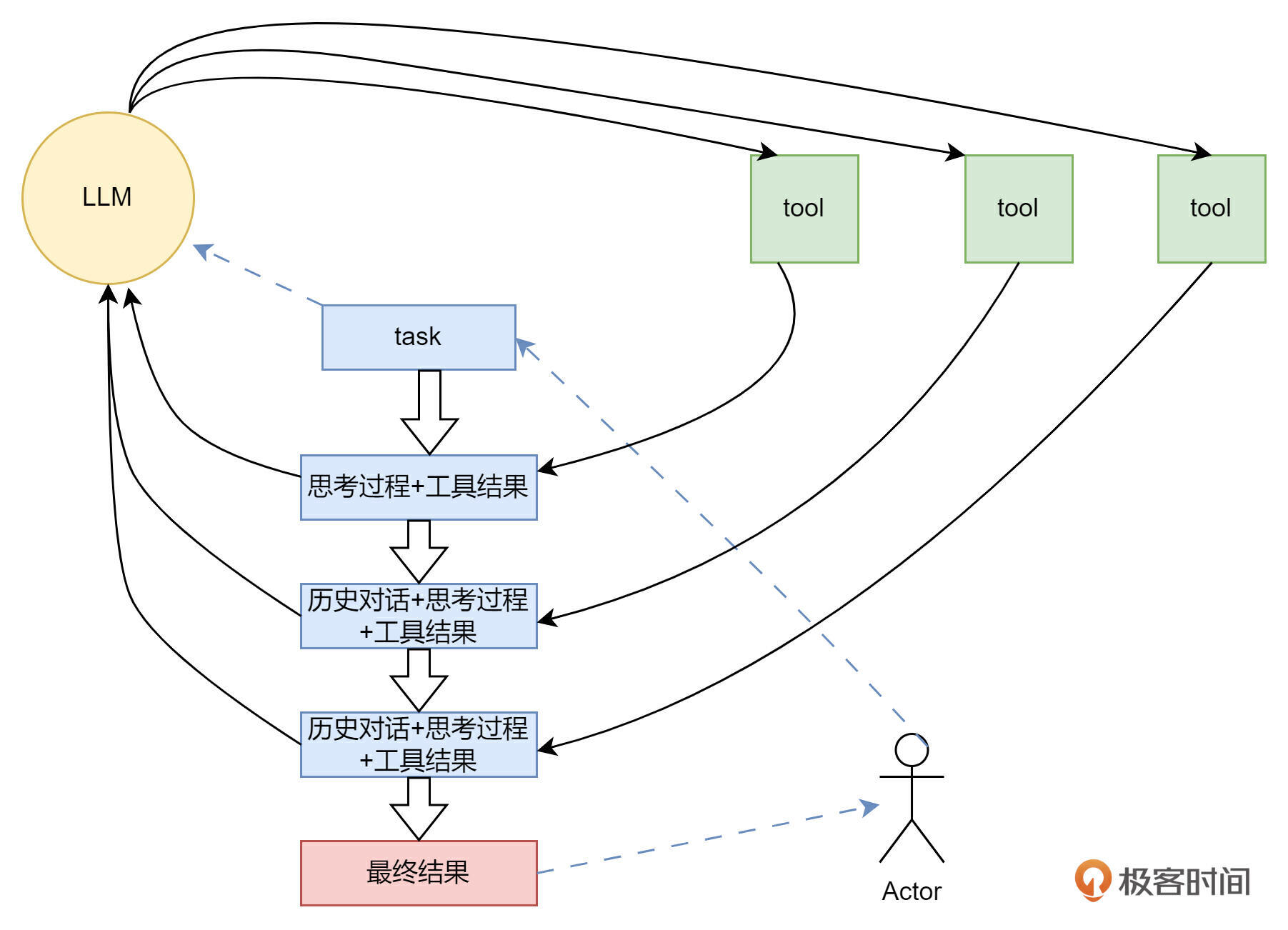
为了节省成本,论文《ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models》提出了 ReWOO 思想,即如果大模型能一次性的把所有步骤都告诉人类,人类把每个步骤对应的工具调用结果一次性返回给大模型,不就可以只提问一次就解决问题了吗?
我们来学习一下其思想。如下图所示,ReWOO 用了两个大模型,其中一个叫Planner,另一个叫 Solver。当人类提出问题时,Planner 会直接规划出问题的解决步骤,以及每一步需要调什么工具,形成一个模板,返回给人类。例如:
人类可根据模板,调用工具后,填充,然后发送给 Solver 大模型,由 Solver 大模型给出最终答案。
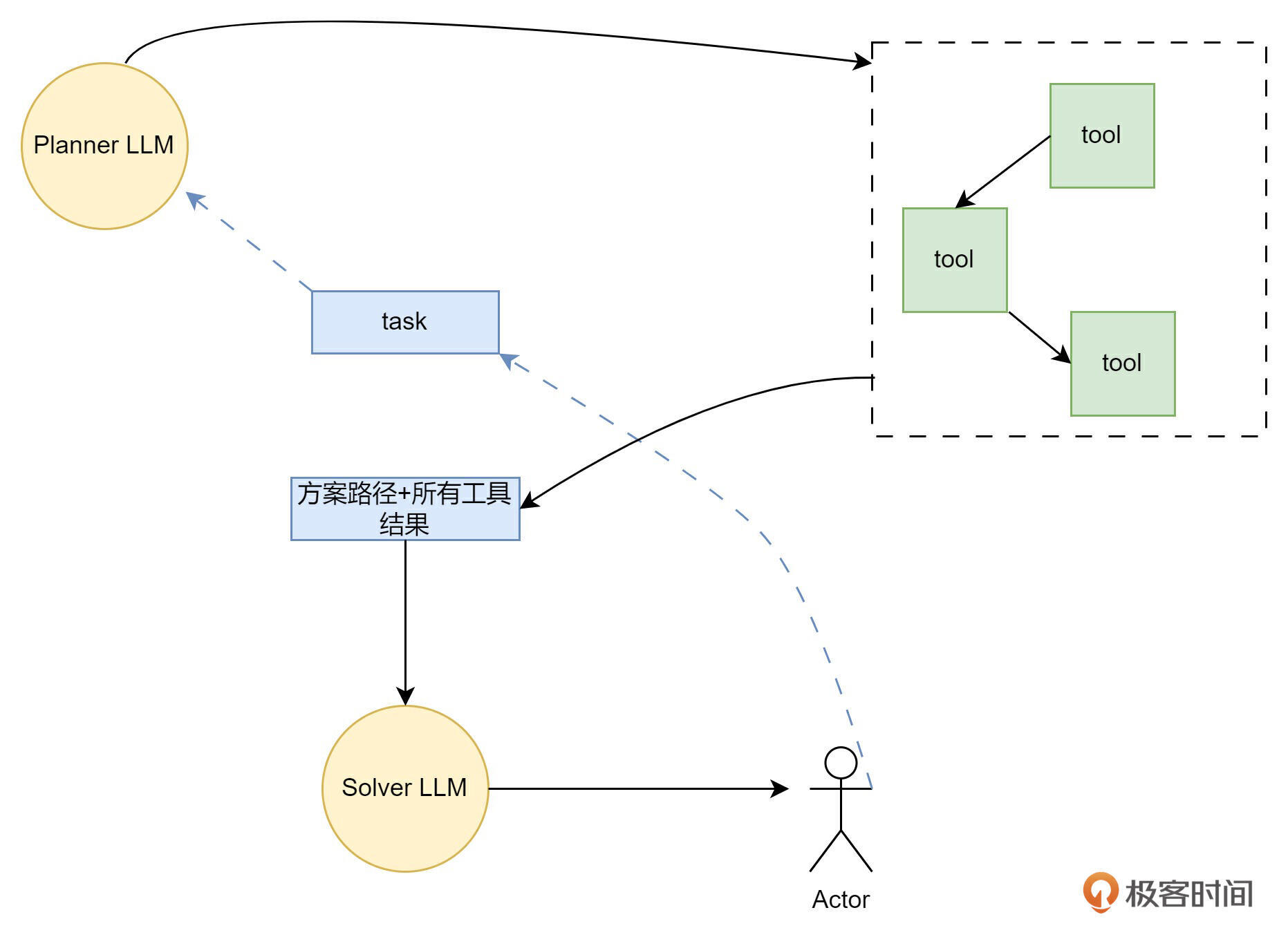
这样就避免了,每解决一个小问题,都要带上历史对话反馈一次,极大地节省了 token。
总结
今天这节课,我为你介绍了四种常见的 Agent 推理方案。四种方案见证了人类不断针对大模型和实际应用中的痛点,不断思考完善的过程。下面我们再来简单串一下方案的发展。
最早人类偶然发现,如果在与大模型对话时加上 “Let’s think step by step”,大模型就会一步步地思考,给出逻辑更加清晰的回答,于是思维链理论诞生了。发展到今日,思维链已经是人人皆知的基操了,很多大模型在训练时,也已经让大模型加入了思维链的思维。
但思维链没有解决大模型的幻觉问题,于是更加完善的理论 ReAct 诞生了。ReAct 的核心记住三个词汇,Thought、Action、Observation,即思考、执行、观察。ReAct 先用思维链的方式进行思考,拆解问题,之后选择合适的工具,最后观察工具的执行结果是否符合要求。ReAct 由于理论简单,效果霸道,对于一些多跳问题,例如:“2022年世界杯的冠军球队的主教练的妻子叫什么名字?”能得到很好的解决,因此在工程中非常常用。
但 ReAct 也不是完美的。其存在两方面问题,一是无法评估结果的正确性,以及无法总结经验教训。二是,ReAct 需要多轮对话完成,会造成 prompt 的长度越来越长,增加 token 的消耗。
为了解决这两方面问题,Reflexion 和 ReWOO 两种理论诞生了。
Reflexion 利用三个大模型协同分工,一个用来做 ReAct,一个用来检查结果,一个用来总结经验教训。这样,一方面保证了结果的准确性;另一方面,经验教训可以作为下次回答类似问题的先验知识,可以提高 ReAct 的工具命中率,增加执行效率。
ReWOO 解决了 prompt 越来越长的问题,其思想是让大模型不再挤牙膏式回答,而是一次性把规划的全部步骤返回,人类一次性调完所有工具,交给大模型,大模型直接给出结果。这样,两轮对话就可以完成问题的解决。
方案没有最好的,只有最合适的,你可以在工作中遇到实际场景时,灵活应用。
思考题
目前很多大模型通过训练已经具备思维链的思想了,无需我们再加 “Let’s think step by step”。那么你认为,大模型能通过训练具备ReAct等更高级的思想吗?
欢迎你在留言区展示你的思考过程,我们一起探讨。如果你觉得这节课的内容对你有帮助的话,也欢迎你分享给其他朋友,我们下节课再见!
- Wiggins 👍(5) 💬(2)
ReWOO 中如果大模型能一次性的把所有步骤都告诉人类,人类把每个步骤对应的工具调用结果一次性返回给大模型,不就可以只提问一次就解决问题了吗? 这段其实不是很明白,老师可以帮忙举个例子么
2024-12-19 - 大宽 👍(0) 💬(1)
那么你认为,大模型能通过训练具备 ReAct 等更高级的思想吗? 应该不能吧,React这种需要针对每次对话给出人类反馈再调整,大模型不能通过事先的知识学习到
2025-02-12