15 原理:可定制 API Agent 原理详解
你好,我是邢云阳。
在前两节课中,我们通过高德地图 API,在 GPTs 和 Dify 两个平台上体验了零代码构建 Agent 应用,相信你对产品设计思路已经有了较为清晰的理解。那本节课,我们就扒一扒 Dify 的部分代码,探讨一下其 API Agent 是如何实现的。
由于 Dify 的代码是用 Python 编写的,因此本节课会涉及到一些 Python 内容。对于不熟悉 Python 的同学,倒也不必担心,重点学习套路即可。毕竟现在是 AI 时代,使用 Cursor、通义灵码等工具,可以轻松理解和生成代码。不过我还是建议你抽空学习一下 Python,因为它是目前做 AI 开发的最佳实践。另外,由于本课程是采用的文字形式而不是视频,因此不可能将源代码全部贴在文章中,只能是截取部分重点的代码片段。因此你可以下载一份源代码在本地,对照着文章一起看,效果会更好。
ReAct 模板
在使用 Dify Agent 的过程中,我们知道其支持 Function Calling 和 ReAct 两种方法。Function Calling 属于大模型的标准化能力,不用太关注。我们可以着重看一下ReAct 方案,看一下其 ReAct 模板与我们前面章节课程中使用的模板有何区别。
进入 Dify 源码根目录,依次进入 api -> core -> agent -> prompt 文件夹,可以看到一个 template.py 的文件。这里面存放的就是 Dify Agent 的 prompt 模板。
在该文件的第一行,就定义了名为 ENGLISH_REACT_COMPLETION_PROMPT_TEMPLATES 的模板变量。内容如下:
ENGLISH_REACT_COMPLETION_PROMPT_TEMPLATES = """Respond to the human as helpfully and accurately as possible.
{{instruction}}
You have access to the following tools:
{{tools}}
Use a json blob to specify a tool by providing an action key (tool name) and an action_input key (tool input).
Valid "action" values: "Final Answer" or {{tool_names}}
Provide only ONE action per $JSON_BLOB, as shown:
```
{
"action": $TOOL_NAME,
"action_input": $ACTION_INPUT
}
```
Follow this format:
Question: input question to answer
Thought: consider previous and subsequent steps
Action:
```
$JSON_BLOB
```
Observation: action result
... (repeat Thought/Action/Observation N times)
Thought: I know what to respond
Action:
```
{
"action": "Final Answer",
"action_input": "Final response to human"
}
```
Begin! Reminder to ALWAYS respond with a valid json blob of a single action. Use tools if necessary. Respond directly if appropriate. Format is Action:```$JSON_BLOB```then Observation:.
{{historic_messages}}
Question: {{query}}
{{agent_scratchpad}}
Thought:"""
如果你看过前面课程,在第一眼看到这份 prompt 时,一定会发现,这份 prompt 在很多地方出现了 JSON 字眼或者使用了 JSON 格式。没错,我在之前的课程中讲过,我们使用的模板在输出 Action、Action Input 等值的时候,都是用的字符串的格式,因此需要使用正则表达式去做拆解工作。而这份 prompt 是使用了 JSON 格式,对于输出格式的稳定性会有很大的提高。
除此之外,模板在开头加了一个 {{instruction}},这一部分便是提示词部分,可以为大模型设置人设,规范其边界行为等。最后还有一个 {{historic_messages}},用于存放历史对话。此处的历史对话不是指的我们与大模型进行 ReAct 多轮对话时的历史对话,而是指的多次向大模型提问时的历史对话。例如:
在之后的实战课程中,我们也使用这个模板,用代码的方式看看效果。
OpenAPI 解析
Agent 的“大脑”部分搞定后,我们来看一下工具部分。API Agent 最大的特点就是工具全部使用 OpenAPI 的形式进行配置。我们拿一个 OpenAPI 的例子,先看一下其结构。
OpenAPI 结构
openapi: 3.1.0
info:
title: 高德地图
description: 获取 POI 的相关信息
version: v1.0.0
servers:
- url: https://restapi.amap.com/v5/place
paths:
/text:
get:
description: 根据POI名称,获得POI的经纬度坐标
operationId: get_location_coordinate
parameters:
- name: keywords
in: query
description: POI名称,必须是中文
required: true
schema:
type: string
- name: region
in: query
description: POI所在的区域名,必须是中文
required: false
schema:
type: string
deprecated: false
components:
schemas: {}
这是我们之前用过的高德地图的 OpenAPI,其大体分为 openapi、info、servers、paths、componentes 等几个模块。
openapi 表示使用的 openapi 的版本号;info 是对整个openapi 文档的总体描述;servers 中的 url 是文档中所有路由的 url 前缀;paths 中便是存放的各条路由了,其中包括了路由名称、HTTP Method、作用描述、操作函数以及参数等信息;components 模块定义的是整个文档的可重用元素,例如如果两条路由都用到了同一个参数,可以将参数描述提取出来放置到这里,避免重复写两遍。
OpenAPI 解析
OK,了解了 OpenAPI 的基本结构后,我们看一下 Dify 解析 OpenAPI 结构的代码是怎么写的。
进入到 api -> services -> tools 目录,有一个 api_tools_manage_service.py 文件,其定义了用于管理工具的类 ApiToolManageService。在该类中,有一个方法 parser_api_schema,作用是将 OpenAPI 文档解析成预先定义好的 tool bundle 结构。
parser_api_schema 是通过调用 auto_parse_to_tool_bundle 方法进行文档解析。该方法的核心代码如下所示:
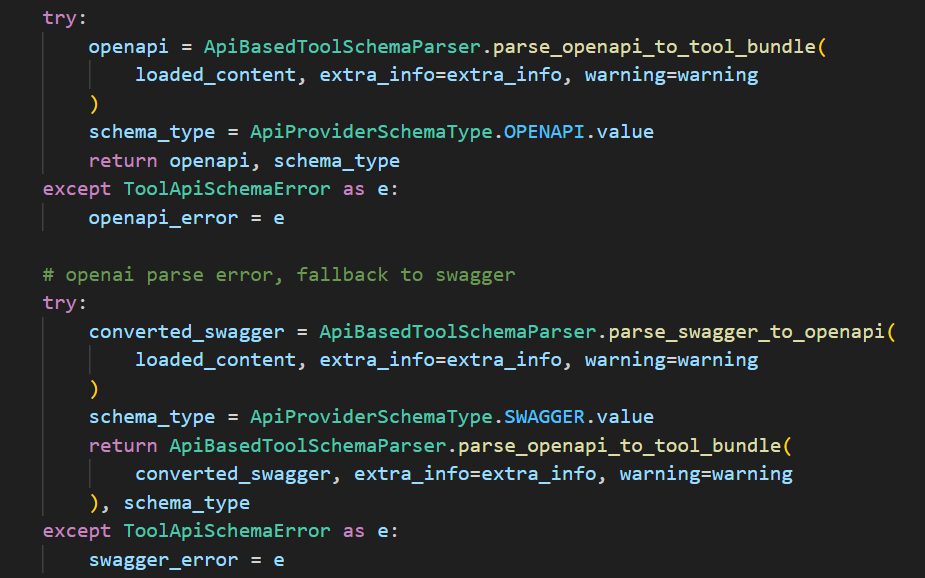
首先会按照 OpenAPI 的规范去解析文档,如果解析失败了,则怀疑用户是按照 Swagger 的规范输入的文档。因此会先按照 Swagger 规范将文档转换成 OpenAPI,之后再来进行 OpenAPI 的解析。
讲到这里,可能有些同学不是太了解 Swagger 与 OpenAPI 的关系,我简单解释一下。Swagger 是 OpenAPI 的前身,最初由 SmartBear 开发,最新版本是 Swagger 2.0。之后 SmartBear 将其捐赠给了 Linux 基金会,并更名为了 OpenAPI。OpenAPI 目前的版本是 3.x,相比 Swagger 在一些字段上会有不同,比如对于 requestBody 的处理,Swagger 是在 Parameters 中使用 in: body 表示,但 OpenAPI 则独立了一个 requestBody 块。再比如前面讲过的 components,其定义也和 Swagger 标准不同。
回到代码中,Swagger 转 OpenAPI 的代码逻辑,比较易懂,简单看一下。首先定义了一个如下图所示的非常简洁的 OpenAPI 的格式。
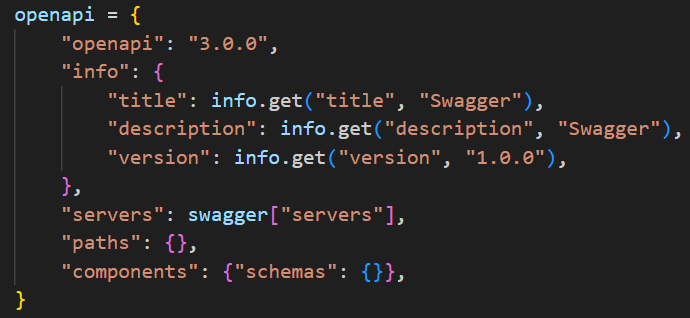
之后提取了 Swagger 文档中的 info、servers 和 paths 部分,并相应地填充到 OpenAPI 文档的相同字段中。这是由于这两种规范在这两个部分上的结构基本一致,因此可以直接进行一对一的字段映射。
但接下来 Dify 做了如下代码所示的操作,其尝试从 Swagger 中提取 requestBody 并赋值到 OpenAPI 的 requestBody。

我猜测 Dify 是考虑到了有的用户对于这两种标准的规则可能会出现混淆,担心有的用户在 Swagger 文档中用了 requestBody,因此才设计了这样的代码处理方式。
最后,就是处理 components 部分了,需要从 Swagger 文档的 definitions 转换成 components。好在其内部结构都是一样的,因此可以直接拷贝。代码如下:

这一部分完成后,就得到了 OpenAPI,可以继续进行 OpenAPI 的解析了。OpenAPI 的解析也非常简单,直接按字段进行提取即可。由于 python 具备字典数据类型,因此在做解析这样的工作时,代码会非常直观易懂。我截一小段,你来感受一下,有兴趣的话你可以去看一下源码。
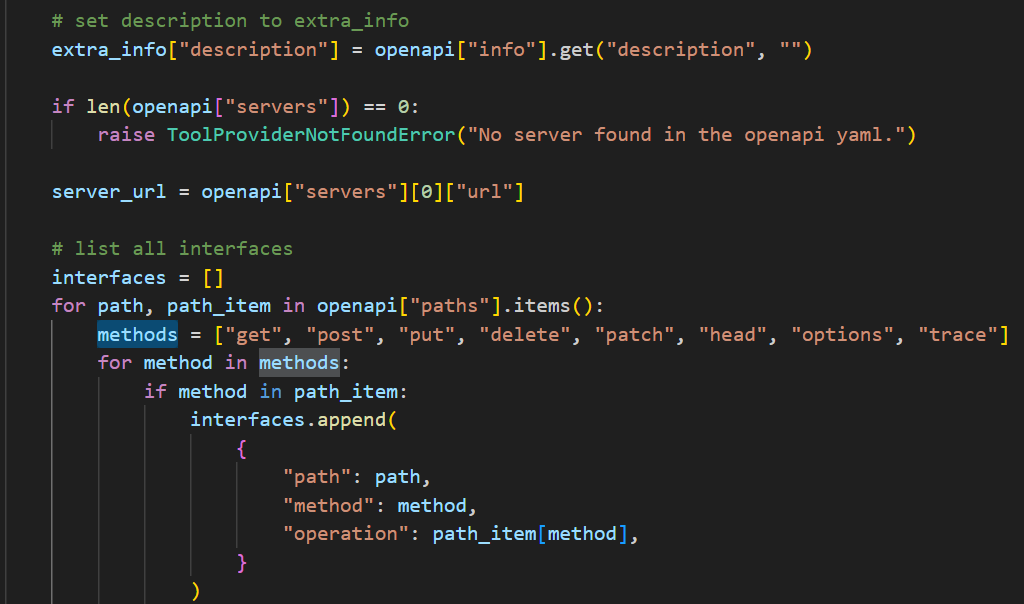
OutputParser
在搞定了 OpenAPI 解析这一块的内容后,就需要继续解析大模型的返回了。在上一节的使用篇中,我们知道 Dify Agent 只支持流式响应。因此其在代码中,封装了一个方法,专门用于处理流式响应中的每一个 chunk。代码位于 api/core/agent/output_parser 文件夹的 cot_output_parser.py 中。
其代码比较复杂,但原理相对好懂。简单说一下就是代码定义了一个光标,然后从 reponse 的第 0 个字符开始,一个字符一个字符地向后读取并处理。处理的规则来自于 ReAct 模板中定义的大模型的返回格式,也就是如下格式:
在三个反引号之中包含着 JSON 串。
当读取的字符遇到反引号的情况:则将其先存到缓存中,并将计数器 + 1。当计数器等于 3 时,设置 in_code 标志位为 True,表示进入到三个反引号之间了。这样后续读取到的字符会全部添加到缓存中。直到再次遇到三个反引号,表示代码块结束了,此时会调用相关方法处理块内的 JSON 内容,并将 in_code 标志位置为 False。
类似的,代码还会检测是否匹配到了{}大括号以及是否匹配到了 action、thought 等,分别会进行处理,从而最终将 action 以及 action_input 后面的值拆解出来。
工具执行
有了 action 和 action_input 后,人类就知道该调用什么工具以及工具的入参是什么了。之前我们反复强调,大模型只能选择工具,不能执行工具,工具的执行还是要靠人类来完成。对于本章讲解的 API Agent 来说,API 工具是用户配置进来的,我们事先无法知道,用户的 API 是什么样的,是使用 GET 还是 POST?有没有 API Key?API Key 放在 header 中还是 URL 中?因此需要写一个通用的工具执行方法,来覆盖所有的场景。我们看一下 Dify 是如何做的。
进入 api -> core -> tools -> tool 目录,有一个 api_tool.py 文件。它定义了一个 _invoke 方法,就是通用 HTTP 工具。代码如下:
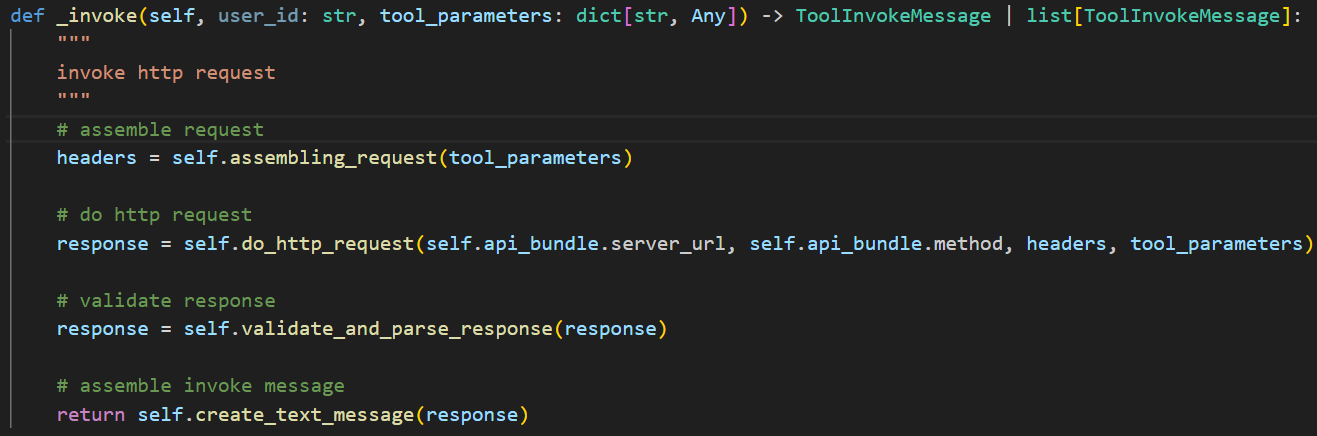
这段代码包含四个方法,首先调用 assembling_request 方法从参数中取得 API Key 的信息,并组装好 HTTP 请求头。
接下来调用 do_http_request 方法,这是一个通用 HTTP 请求方法,根据传入的 method 确定进行何种请求。
在得到 response 后,调用 validate_and_parse_response 方法,通过判断返回码来确定请求是否成功。
最后通过 create_text_message 方法将 response 以文本形类型存放到一个定义好的消息结构中返回。这是由于 Dify 支持多模态大模型,返回的消息有可能是文本、图片、链接等等,因此做了一个统一的消息结构,便于传递。
OK,以上就是 API Agent 从大脑,到输入输出,再到工具执行的全部主体逻辑了。懂了主体逻辑后,其他还有一些小的细节就是锦上添花了。
轮次限制
在之前的课程中,我曾在课后思考题中设置过一个问题。假设工具执行的结果不对等原因,导致大模型一直无法得到 Final Answer 该怎么办?Dify 给了我们答案,那就是设置轮次限制。
即大模型与人类的对话,最多只能持续多少轮,如果到了最大轮次数还得不到最终答案,就强行结束对话。这一点非常重要,会避免 Agent 陷入死循环,白白浪费大量的 token。
Token 消耗统计
我们知道无论是 Function Calling 还是 ReAct,都是一个多轮对话的过程。但对于用户来说,这个过程是黑盒的,用户看到的只有最开始的输入和大模型最终给的输出。因此准确地统计 token 的消耗,可以让用户了解使用 Agent 的真实情况。Dify 在代码中会在每一次大模型返回后,抽取 usage 字段后的值,进行累加,从而得到真实的 token 消耗。
总结
本节课,我们对 Dify Agent 的代码进行了简单梳理分析,一起学习了其对于每一个模块的处理手法,下面我们做个简单回顾。
- OpenAPI解析:按照 OpenAPI 的结构规则,提取字段。如果解析失败,则怀疑用户是不是按 Swagger 规则配置的,增加一步从 Swagger 转 OpenAPI 的过程。
- OutPutParser:不管大模型是以流式还是非流式格式返回。都要按照 ReAct 模板中规定的输出格式进行解析。如果是字符串形式就用正则,如果是 JSON就使用 JSON 反序列化。
- 工具执行:OpenAPI 定义的是 API 的规范,因此工具需要使用 HTTP 方法。在无法提前预知用户会配什么 API 的前提下,需要写一个通用 HTTP 处理方法。
- 轮次限制:为了避免 Agent 一直得不到 Final Answer 陷入死循环,需要做对话轮次限制。
- Token消耗统计:统计与大模型对话的每一轮 token 消耗,并作累加,得到一次调用 Agent 的真实 token 消耗。
在学习了这种产品的代码该怎么设计之后,从下一节课开始,我将用两个课时的时间,带你一起用 Go 语言来实现一下 API Agent。但在实践之前,我还是想要重申开头的观点,在 AI 时代,不要将代码看得过重,而是要重点学习思想、套路,因为未来会不断卷出越来越强大好用的工具来辅助编程。
思考题
Dify 除了 Agent 之外,还有工作流功能,该功能可以让用户通过拖拉拽的方式进行自定义编排,可以实现单 Agent 完成不了的更加复杂的场景功能,尽可能地减少幻觉的产生。有兴趣的话你可以体验一下工作流的功能。
欢迎你在留言区分享你的体验心得,我们一起来讨论。如果你觉得这节课的内容对你有帮助的话,也欢迎你分享给其他朋友,我们下节课再见!