20 学习路径:借助ChatGPT学习和实践eBPF
你好,我是倪朋飞。
上一讲我带你回顾了 Cilium 的发展历程并探讨了它的工作原理。作为 eBPF 在云原生网络领域应用的典范,Cilium 用高效的 eBPF 程序替换 Linux 内核网络协议栈中的连接跟踪、NAT 转换、安全策略和路由转发等功能,从而显著提升了网络处理的性能。Cilium 项目在 CNCF 和 eBPF 基金会的加持下,推动了 eBPF 技术在内核社区的快速发展以及在云原生领域的更广泛应用。
无论是 Linux 内核和 eBPF 技术本身,还是以 Cilium、Falco 等为代表的各类 eBPF 实践应用都还在快速发展着。在学习和实践这类快速发展的技术时,我想你一定会经常碰到旧有的代码在系统和应用更新之后无法正常工作的问题,甚至是我们专栏中的某些案例在内核升级到 6.x 之后也需要做一些特定的修改才能正常工作。
为了帮你及时获得这类问题的解决方法,我们专栏从一开始便创建了微信群,方便你在碰到问题时可以及时交流。不过即便是这样,很多不常见问题的解决也有可能需要比较长的时间,也有很多敏感的应用场景是不能在微信群中公开讨论的。那么,在碰到这类问题的时候,有没有更高效的方法可以更及时获取帮助呢?
ChatGPT 的诞生为这些问题带来了全新的解决思路。基于海量的训练数据和出色的自然语言交互能力,ChatGPT 不仅在通用自然语言处理方法表现出色,在很多知识领域也能够给出非常详细和清晰的回答,从而可以在一定程度上代替搜索引擎提供更清晰和更相关的回答。
那么,ChatGPT 究竟是怎么工作的?如何用好 ChatGPT 来学习新技术,又如何在 eBPF 的学习和实践过程中利用 ChatGPT 呢?今天,我就带你一起来看看如何借助 ChatGPT 来解决学习和实践 eBPF 中碰到的各种问题。
ChatGPT 简介
ChatGPT 是 OpenAI 在 2022 年 11 月发布的一款聊天机器人应用,全称是聊天生成预训练转换器(Chat Generative Pre-trained Transformer,简称 ChatGPT)。ChatGPT 以人类自然对话方式交互,一经发布便迅速获得了广泛关注,在撰写创作、推理转换、总结提取、编程调试等各类自然语言场景中表现出色,不仅成为当前最热门的技术话题,更是引发和推动了新一波的人工智能创业浪潮。
ChatGPT 在 GPT-3.5 系列的基础上进行微调得到,它的背后结合了生成预训练转换器(Generative Pre-trained Transformer,简称GPT)和人类反馈的强化学习(Reinforcement Learning from Human Feedback,简称RLHF),其心智能力甚至可以达到七岁儿童的能力。在此基础上,OpenAI 还发布了规模更大、能力更强的 GPT-4,以及速度更快的 ChatGPT Plus、被誉为新一代应用商店的 ChatGPT 插件和函数调用等一系列的增强产品,使得 ChatGPT 在处理实时数据方面具有更广泛的应用场景。
提示:如果你对 ChatGPT 的工作原理感兴趣,我推荐你去看一下 OpenAI 创始成员 Andrej Karpthy 在微软 Build 2023 开发者大会上的演讲 State of GPT。由于 ChatGPT 原理并不是我们课程的重点,这儿就不再过多展开。
当然了,ChatGPT 作为一个新生的产品也还存在很多的问题,比如不了解 2021 年之后的事件,有时候会生成看起来合理但实际上完全错误的结果,支持的上下文信息有限等。这些都是在使用 ChatGPT 过程中需要特别注意的。
如何使用 ChatGPT 学习 eBPF
在使用 ChatGPT 之前,你要知道 ChatGPT 跟人类相比是存在很大的认知差异的。ChatGPT 本质上只是基于一个标记序列预测下一个标记,它并不清楚自己的知识边界,不知道自己擅长什么,不能纠正自身错误,也不能保证成功。所以,用好 ChatGPT 的关键就是给它提供一个清晰明确的提示语(Prompt),明确告诉 ChatGPT 你想要的信息以及相关的上下文和限制。
通常来说,我推荐你在写 ChatGPT 提示语时考虑下面这几个技巧:
- 提供一个清晰具体的提示语,给模型设定具体的角色和任务,限定模型的知识边界。
- 让模型分步骤解答,明确推导过程,减少推理错误。
- 把复杂任务拆解成简单的小任务,每次只提交一个简单的小任务,避免任务信息的丢失。
- 使用外部工具(比如 ChatGPT 插件)提供相关的上下文信息,弥补 ChatGPT 知识有限的缺陷。
以今天的主题“如何学习 eBPF”为例,我们可以对比一下这些提示语技巧的效果。
首先,直接问 ChatGPT “如何学习 eBPF?”,你将获得类似下面的回复:

接下来,借助刚才提到的技巧,把提示语改进成下面的格式:
作为一名 Linux 内核和 eBPF 的专家,我们希望您能担任 eBPF 的讲师,向初学者教授 eBPF 的相关知识。您将需要利用您的专业知识,创造出引人入胜且内容丰富的教学内容,以指导学生一步步理解和解决学习过程中可能遇到的问题。你的第一个任务是制定学习 eBPF 技术的详细计划。
再次去问 ChatGPT 就可以获得更详细和更具体的学习计划:

这次的回答将学习过程划分为五个具体的学习阶段,每个阶段都列出了详细的学习目标、学习内容和实践内容,可以说正是我们想要的答案。顺着这个计划,再把每个阶段的内容分步提交给 ChatGPT,就可以获得一个完整的学习计划了。
提示:你可以点击这里和这里继续这两个对话,进一步对比它们的效果。这两个对话都是基于默认的 GPT-3.5 模型,如果你有订阅 ChatGPT Plus,切换到 GPT-4 模型后会得到更好的结果。
如何使用 ChatGPT 解决学习过程中的疑惑
除了制定学习计划,在学习新技术过程中碰到的任何问题,你也都可以借助 ChatGPT 帮你答疑解惑。不过,你需要注意的是,ChatGPT 的训练数据截止到 2021 年,如果你的问题涉及到这之后的任何信息,它都是无法回答的。这时候,你就需要借助搜索引擎或者插件先去查询到相关的上下文信息之后,把上下文信息和问题一同发给 ChatGPT,这样它也就具备了回答实时信息的能力。
以几天前微信群中的一个问题为例,使用新版本内核 6.1.0 的时候,kfree_skb 是不能作为 kprobe 函数的。这是为什么呢?直接去问 ChatGPT 这个问题,它会给出下面的回答:
问题:Linux 内核 6.1.0 中为什么没有 kfree_skb 这个 kprobe 函数?
回答:我很抱歉,但是截至我最后一次更新(2021年9月)时,Linux 内核的版本还没有达到6.1.0。我无法获取此之后的信息。在我最后一次更新时,Linux 内核版本为 5.x,所以我无法准确回答您关于6.1.0版本的问题。
然而,我可以告诉你一般性的原因,为什么某个函数在新的内核版本中可能不存在:
- 函数被重命名或重新实现:为了改善代码的可读性或者执行效率,开发人员可能会更改函数的名称或者重写其实现方式。
- 函数被废弃:如果一个函数的功能被其它的函数或者模块取代,或者这个函数存在安全性问题,那么开发人员可能会选择废弃这个函数。
- 代码重构:在大型软件项目中,经常会进行代码重构,以改进代码结构,提高可维护性,或者增加新的功能。在这个过程中,一些函数可能会被移除,或者与其他函数合并。
对于
kfree_skb这个特定的函数,如果在新的内核版本中你找不到它,我推荐你查看近期的 Linux 内核的更新日志、commit 记录或者相关的开发者邮件列表,这些都可能包含你需要的信息。这些信息可以帮助你了解这个函数是否被重命名,或者它的功能是否被移至其它函数中。
可以看到,ChatGPT 并不能直接回答,而只是提供了一些一般性的原因。这时,我们可以去查一下 6.1.0 内核的源码,把 kfree_skb 的定义一同发给 ChatGPT,比如像下面这样去提问:
这是我在 6.1.0 内核中找到的相关源码:
----------
void __fix_address
kfree_skb_reason(struct sk_buff *skb, enum skb_drop_reason reason);
/**
* kfree_skb - free an sk_buff with 'NOT_SPECIFIED' reason
* @skb: buffer to free
*/
static inline void kfree_skb(struct sk_buff *skb)
{
kfree_skb_reason(skb, SKB_DROP_REASON_NOT_SPECIFIED);
}
----------
根据这个源码,重新回答为什么 kfree_skb 不能用作 kprobe 函数?
这时候,ChatGPT 的回复如下所示:
你提供的代码片段显示,
kfree_skb现在是一个静态内联函数,它调用了kfree_skb_reason函数。在内核编程中,静态内联函数有一些特殊的性质。内联函数(inline function)是 C 语言的一个功能,它允许编译器将函数体的代码直接插入到函数调用的地方,从而避免了函数调用的开销。这样可以提高程序的执行速度,但可能会增加程序的总体大小。由于内联函数的代码是直接嵌入到其他代码中的,所以它们不会有自己的函数入口,也就不能被单独地定位或者引用。
static关键字表示这个函数只能在它所在的源文件中使用,不会被其他源文件引用。这样可以避免命名冲突,并且可以给编译器提供更多的优化机会。在 Linux 内核中,kprobe(内核探测)是一种动态跟踪技术,它可以在运行时插入探测点,从而收集内核的执行信息。每个探测点对应于一个特定的函数入口或者返回点。但是,由于静态内联函数没有单独的函数入口,所以它们不能被作为 kprobe 的目标。
所以,如果
kfree_skb是一个静态内联函数,那么你不能在它上面设置一个 kprobe。如果你想跟踪kfree_skb的执行,你应该在kfree_skb_reason函数上设置 kprobe。
可以看到,这时候的答案就非常清楚了。它最后还建议了在 kfree_skb_reason 函数上设置 kprobe(你可以点击这里继续这个对话)。
当然,如果你订阅了 ChatGPT Plus,也可以让插件帮你去阅读源码,然后再去回答你的问题:

如何使用 ChatGPT 生成 eBPF 程序
除了学习计划和答疑解惑,你也可以让 ChatGPT 帮你生成简单的 eBPF 程序,作为 eBPF 程序开发的参考。不过,需要注意的是,ChatGPT 对 Linux 内核、bpftrace、BCC 等详细的实现细节并不是特别了解。在没有足够上下文的情况下,ChatGPT 的输出往往会有各种各样的问题,并不能输出可直接运行的程序。
正如上一节提到的,这时候就需要给 ChatGPT 提供足够的上下文信息。如下面的例子所示,你可以开启 ChatGPT 插件 WebPilot,先让 ChatGPT 去学习相关的文档之后,再去实现你的任务(你可以点击这里继续这个对话)。你可以这样提问:
作为一名 Linux 内核和 eBPF 的专家,我希望你能担任 eBPF 资深研发工程师,开发特定应用场景的 eBPF 程序。
在正式开始之前,请根据 https://raw.githubusercontent.com/iovisor/bpftrace/master/docs/reference_guide.md 和 https://raw.githubusercontent.com/iovisor/bpftrace/master/docs/tutorial_one_liners_chinese.md 这两篇的内容学习 bpftrace 的详细使用方法。
学习完毕后,回复OK。
接着,你会得到如下的回复:
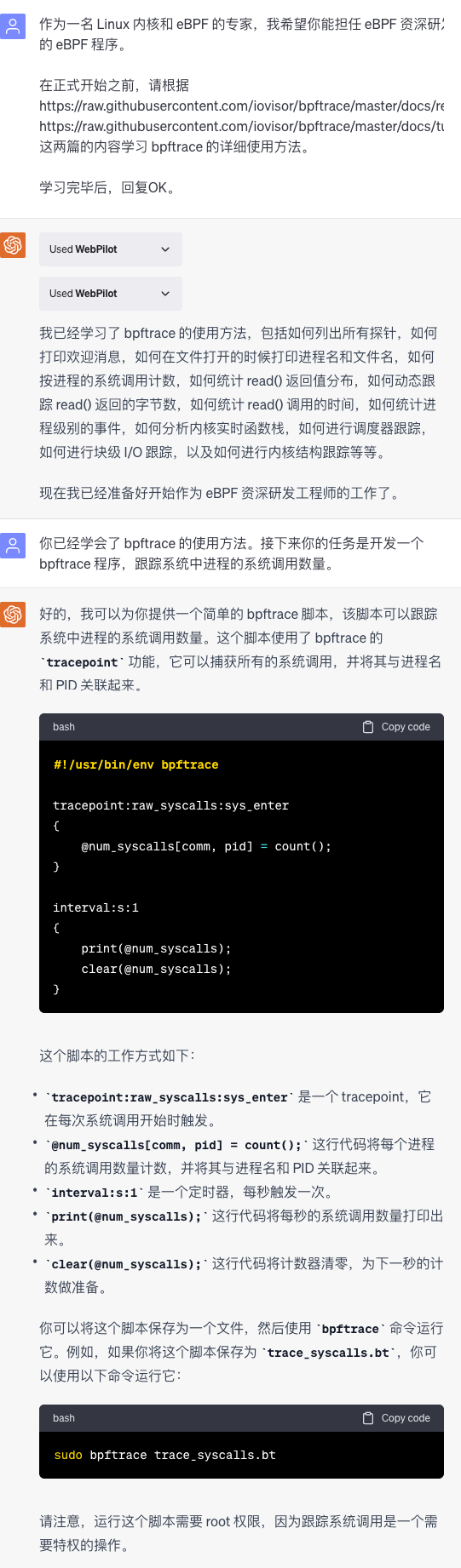
你会发现,直接使用 ChatGPT 插件的方式虽然非常方便,但也有一定的限制,比如不够灵活、很难把大量数据通过同一个对话传递给 ChatGPT 等。
事实上,ChatGPT 每个模型所支持的上下文信息都是有限的(详细信息可以参考官方文档),在实践中更常用的方法是通过嵌入(Embedding)把原始文档转换成词向量,然后从中筛选出跟提示词最相关的上下文信息,之后再跟原始提示词合并在一起向 ChatGPT 提问。这个步骤的过程如下图所示:
 这些方法在诸如 LangChain 和 Semantic Kernel 等主流的大语言模型开发框架中都已经支持,ChatPDF、ChatDoc 等与文档进行聊天的应用也都是基于这个思路实现的。比如,使用 LangChain 来实现这个过程的简化逻辑如下所示(完整的代码可以在 GitHub ebpf-apps 中找到):
这些方法在诸如 LangChain 和 Semantic Kernel 等主流的大语言模型开发框架中都已经支持,ChatPDF、ChatDoc 等与文档进行聊天的应用也都是基于这个思路实现的。比如,使用 LangChain 来实现这个过程的简化逻辑如下所示(完整的代码可以在 GitHub ebpf-apps 中找到):
# 0. 初始化模型
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
llm = ChatOpenAI(model="gpt-4", temperature=0)
# 1. 文档加载、分割及向量化
documents = DirectoryLoader("./doc/",
glob="**/*.md",
silent_errors=True,
use_multithreading=True,
loader_cls=TextLoader,
).load()
text_splitter = CharacterTextSplitter(chunk_size=4096, separator="\n")
docs = []
for d in documents:
splits = text_splitter.split_text(d.page_content)
docs.extend(splits)
store = Chroma.from_texts(docs, embeddings)
# 2. 初始化RetrievalQA LLM链
chain = RetrievalQA.from_chain_type(
llm=llm, chain_type="refine", retriever=store.as_retriever())
# 3. 调用LLM链
msg = '作为一名 Linux 内核和 eBPF 的专家,你的任务是开发一个 bpftrace 程序,跟踪系统中进程的系统调用数量。'
print(chain.run(msg))
默认的提示语输出如下所示:
在给出的文档库中,并没有提供额外的信息来改进原始答案。因此,原始答案仍然有效:
你可以使用以下 bpftrace 命令来跟踪系统中进程的系统调用数量:
bash bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'这个命令的工作原理如下:
tracepoint:raw_syscalls:sys_enter是一个探针,它在每次进入系统调用时触发。@[comm] = count();是一个动作,它在每次触发探针时执行。这个动作将当前进程的名字(comm)作为键,将系统调用的数量作为值,存储在一个名为@的 map 中。count()函数用于计数,每次调用都会增加计数器的值。- 当你按 Ctrl-C 结束 bpftrace 程序时,它会自动打印出 map 的内容,即每个进程的系统调用数量。
此外,你还可以使用更复杂的 bpftrace 脚本来跟踪更多的信息,例如调用栈、调度器事件、块级 I/O 事件以及内核结构。你可以查阅 bpftrace 的参考手册以获取更多信息。
根据输出你可以发现,它的输出实际上就来源于提供的参考文档,并加入了详细的解释和更多的参考链接。
小结
在今天的课程中,我带你了解了如何利用 ChatGPT 学习以 eBPF 为代表的新技术并解决碰到的各种疑惑。ChatGPT 以出色的自然语言交互能力和强大的知识背景,从一诞生就风靡全球。不仅在撰写创作、推理转换、总结提取、编程调试等诸多领域获得广泛应用,还催生了很多 AI 助手产品和不同领域的大型语言模型。
从学习 eBPF 技术的角度来看,ChatGPT 不仅可以帮助我们制定学习和实践计划,还能方便地解答疑惑、生成代码。此外,结合丰富的插件和文档语义搜索功能,你还可以让 ChatGPT 学习并了解最新信息,以帮助你解决 ChatGPT 不曾了解的问题。
今天的这一讲就到这里了。我将继续关注 eBPF 的发展,并为你带来更多与 eBPF 相关的内容。预计下次的更新将于 9 月份推出。如你对我们未来课程内容有任何建议,请在评论区留言,期待你与我们共同完善和构建一个贴近实践的 eBPF 知识体系。
思考题
在这一讲的最后,我想邀请你来聊一聊:
最近学习和应用 eBPF 时,你是否尝试过使用 ChatGPT 解决遇到的问题?如果是的话,你有什么经验可以分享给大家?相较于传统的微信群聊、网络搜索等方式,ChatGPT 在哪些方面具有明显优势?又存在哪些缺点呢?
欢迎在留言区和我讨论,也欢迎把这节课分享给你的同事、朋友。让我们一起在实战中演练,在交流中进步。
- Geek_644bec 👍(0) 💬(1)
老师微信群信息在哪,前面没看到呢
2024-02-25