24 技术解析:HTTPS跟踪详解(上)
你好,我是倪朋飞。
上一讲我带你回顾了 eBPF 在 2023 年的旅程。过去一年,Linux 内核不仅大幅增强了 eBPF 的功能特性,新增了通用迭代器、uprobe 多挂载、套接字销毁、自定义对象、红黑树数据结构等一系列的新特性,eBPF 的生态系统和实践也是遍地开花,很多开源项目都在去年达到了生产可用的稳定版本。特别是在云原生监控领域,由于无需对应用程序进行任何修改,eBPF 就成为无侵入监控方案的最佳选择。而在云原生这类典型的分布式系统中,HTTP/HTTPS 等网络请求的跟踪又尤为重要,它们是我们了解分布系统中多个系统组件如何通过网络进行交互的核心。
那么,如何对 HTTP 网络包进行跟踪,又如何跟踪加密的 HTTPS 网络包呢?今天,我就带你一起去看看这两个问题。 由于篇幅比较长,本次课程的内容将分为两篇,今天的内容是上篇。
HTTP/HTTPS 协议回顾
要进行 HTTP/HTTPS 的跟踪,就需要首先了解它们的工作原理,特别是网络包的数据结构。你还记得 HTTP/HTTPS 协议是怎么工作的吗?你可以停下回忆一下再来继续下面的内容。
有没有想起来呢?没有想起来也没关系,接下来我带你一起回忆一下。
HTTP 协议
HTTP 是超文本传输协议(HyperText Transfer Protocol)的简称,是用于分布式协作的应用层协议。HTTP 工作在 TCP/IP 模型之上,通常使用 80 端口,是万维网数据通信的基础。
如下图所示,展示了一个典型的 HTTP 通信过程。

客户端跟服务器建立 TCP 连接之后,就可以以“请求-响应”的模式进行数据交互了。HTTP 协议规定了请求和响应的数据格式,请求的格式如下图所示,包括请求行、头部和正文。
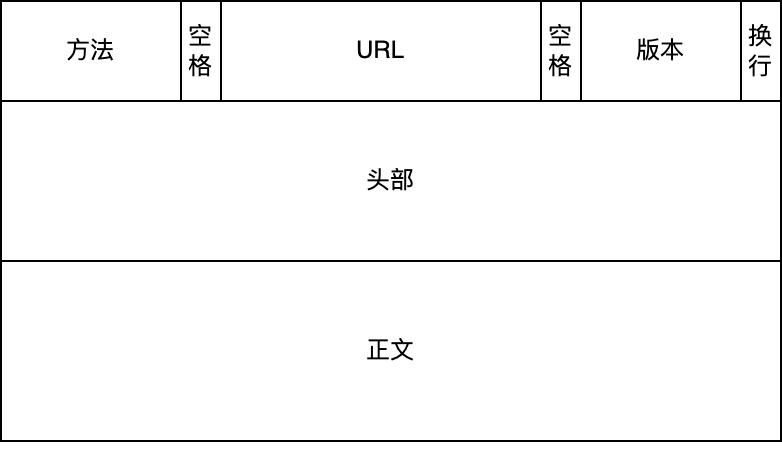
而 HTTP 响应的格式也是类似的,如下图所示,包括状态行、头部和正文。
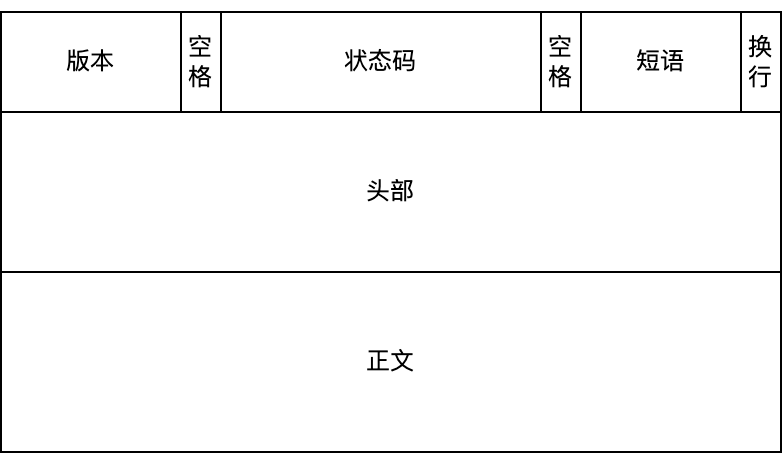
正如上面的数据格式所示,HTTP 在应用层以纯文本的形式进行通信,它所传输的数据都是明文的,所以就有可能会被窃听或者篡改。为了解决这个安全问题,HTTPS 就应运而生了。接下来,我们再来一起回忆一下 HTTPS 的工作原理。
HTTPS 协议
HTTPS 协议是 HTTP 的安全版本,它在 HTTP 基础之上使用加密协议对通信进行加密,并增加了数据的完整性校验和身份验证等安全特性。HTTPS 协议通常使用 443 端口,它使用 TLS(Transport Layer Security,传输层安全性,简称 TLS)对数据进行加密保护。
增加了 TLS 之后,HTTPS 的通信过程就比 HTTP 增加了额外的 TLS 握手过程,并确保应用数据都被加密后再进行网络传输。如下图所示,就展示了 HTTP 与 HTTPS 网络通信的不同。
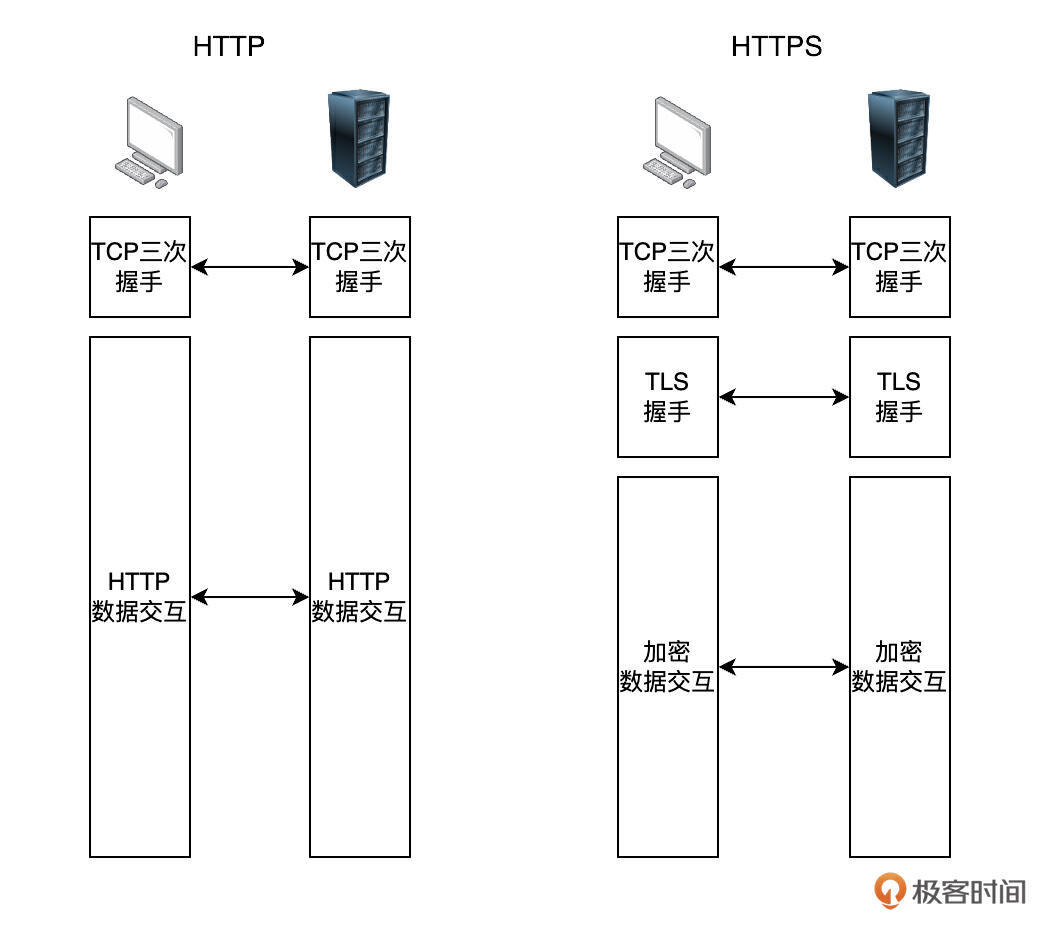
至于 TLS 握手的具体过程以及它是如何对数据进行加密的,这些内容并不是我们课程的重点。这儿就不进行展开了。如果你对它的工作原理感兴趣的话,可以阅读这篇博客了解更详细的内容。
由于 HTTPS 对应用数据进行了加密,通过诸如 tcpdump 等工具进行网络抓包就无法看到具体的内容了(而 tcpdump 是可以直接看到 HTTP 数据内容的)。那么,eBPF 是不是可以帮我们跟踪到具体的数据内容呢?答案是肯定的。只要我们选择合适的跟踪点,且跟踪点上的数据已经解密过了,那么数据的内容对 eBPF 程序来说自然也就是透明的了。
回顾了相关的基础知识以后,接下来就进入今天的主题,即如何通过 eBPF 来跟踪 HTTP 和 HTTPS 网络包。
如何用 eBPF 跟踪 HTTP 网络包
首先,我们先来看一下 HTTP 网络包的跟踪。
由于 HTTP 网络包传输的数据是明文的,所以你既可以借助传统的网络抓包工具(比如 tcpdump、wireshark 等)来跟踪,也可以利用 eBPF 来跟踪。
第一种方法,使用 tcpdump 工具。你可以给 tcpdump 命令增加 -A 参数直接显示网络包的内容,命令格式如下所示:
第二种方法,使用 eBPF 进行跟踪。要使用 eBPF,就需要首先选择一个跟踪点以及相应的 eBPF 程序类型。结合我们课程第 06 讲讲到的各类 eBPF 程序和刚才回顾的 HTTP 工作原理,要对 HTTP 进行跟踪也有很多种方法。这其中,最容易想到是下面这三种。
- 第一种,使用套接字过滤程序,在套接字上直接跟踪网络数据包的内容。
- 第二种,使用系统调用跟踪点,在应用程序发出的系统调用上跟踪网络数据包的内容。
- 第三种,使用用户态跟踪点,在应用程序收发 HTTP 请求的用户态函数上跟踪网络数据包的内容。
这几种方法使用哪种好呢?很显然,套接字过滤程序直接对套接字进行跟踪,比系统调用跟踪和用户态跟踪更简单,也不需要跟具体的系统调用点和用户态程序绑定,因而也更通用。
选定了跟踪方法之后,接下来就是如何开发这个套接字过滤程序了。参考 Linux 内核对套接字过滤程序的定义,它的参数格式为 struct __sk_buff,也就是套接字缓冲区,所以我们的 eBPF 程序就可以定义为如下的格式:
怎么样从 skb 中读取 HTTP 数据呢?根据上一节的回顾内容,既然 HTTP 是基于 TCP 的,那么它的内容自然也就封装在 TCP 数据中,即网络包的数据结构如下图所示:

从 skb 中依次读取帧头、IP 头和 TCP 头之后,根据它们的长度就可以计算出 HTTP 数据的起始位置,而 HTTP 数据的长度也可以根据 IP 包的总长度计算出来(IP 包长度- IP 头长度 - TCP 头长度),具体代码如下所示:
// 只跟踪 IP 协议的数据包
__u16 h_proto;
bpf_skb_load_bytes(skb, offsetof(struct ethhdr, h_proto), &h_proto, 2);
if (h_proto != bpf_htons(ETH_P_IP)) {
return 0;
}
// 只跟踪 TCP 协议的数据包
__u8 ip_proto;
bpf_skb_load_bytes(skb, ETH_HLEN + offsetof(struct iphdr, protocol),
&ip_proto, 1);
if (ip_proto != IPPROTO_TCP) {
return 0;
}
// 计算IP头部长度(ihl单位为4字节,所以需要乘以4)
struct iphdr iph;
bpf_skb_load_bytes(skb, ETH_HLEN, &iph, sizeof(iph));
__u32 ip_total_length = iph.tot_len;
__u32 iph_len = iph.ihl;
iph_len = iph_len << 2;
// 根据TCP数据偏移(doff)计算TCP头部长度(doff单位为4字节,所以需要乘以4)
struct tcphdr tcph;
bpf_skb_load_bytes(skb, ETH_HLEN + sizeof(iph), &tcph, sizeof(tcph));
__u32 tcp_hlen = tcph.doff;
tcp_hlen = tcp_hlen << 2;
// 只跟踪 TCP 80 端口的数据包(注意需要转换字节序)
if (tcph.source != bpf_htons(80) && tcph.dest != bpf_htons(80)) {
return 0;
}
// 计算 HTTP payload的偏移和长度
__u32 payload_offset = ETH_HLEN + iph_len + tcp_hlen;
__u32 payload_length = bpf_ntohs(ip_total_length) - iph_len - tcp_hlen;
// HTTP 报文最短为7个字节
if (payload_length < 7) {
return 0;
}
这其中:
ethhdr、iphdr、tcphdr分别是帧头、IP 头和 TCP 头的内核数据结构;bpf_skb_load_bytes()是一个常用的 BPF 辅助函数,用于从 skb 中读取指定长度的网络数据;iphdr.ihl定义了 IP 头长度,tcphdr.doff定义了 TCP 头长度,他们的单位都是 4 字节,所以在计算长度时都需要乘以 4(等同于代码中的位移操作<< 2)。
到这里,我们就计算出了 HTTP 数据的偏移 payload_offset 和 payload_length,接下来就可以读取真正的 HTTP 数据了。不过,考虑到其他协议的网络包可能也会使用 80 端口,在读取真正的 HTTP 数据包时,最好对其内容也做进一步的校验。
根据上一节回顾的 HTTP 协议格式,HTTP 请求的前几个字符总是 HTTP 方法(比如 GET、PUT 等),而 HTTP 响应的前几个字符总是 HTTP 版本(比如 HTTP/1.1),所以只需要读取前几个字符就可以验证内容是不是 HTTP 了,代码如下所示:
// 只跟踪 GET、POST、PUT、DELETE 方法的数据包
// HTTP 开头的数据包是服务器端的响应
char start_buffer[7] = { };
bpf_skb_load_bytes(skb, payload_offset, start_buffer, 7);
if (bpf_strncmp(start_buffer, 3, "GET") != 0 &&
bpf_strncmp(start_buffer, 4, "POST") != 0 &&
bpf_strncmp(start_buffer, 3, "PUT") != 0 &&
bpf_strncmp(start_buffer, 6, "DELETE") != 0 &&
bpf_strncmp(start_buffer, 4, "HTTP") != 0) {
return 0;
}
确认内容的确是 HTTP 之后,你就可以放心读取具体的内容了。
// 限制只读前100字节
#define MAX_LENGTH 100
char payload[MAX_LENGTH];
__u32 read_length = payload_length > MAX_LENGTH ? MAX_LENGTH : payload_length;
bpf_skb_load_bytes(skb, payload_offset, payload, read_length);
到这里,我们已经在 eBPF 内核态读取到了 HTTP 的详细内容。为了让用户态看到这些内容,还需要增加一个 BPF 映射,把数据从内核态送到用户态。这儿可以使用环形缓冲区映射(Ring Buffer),代码如下所示:
// 定义缓冲区数据格式
struct event_t {
__u32 saddr;
__u32 daddr;
__u16 sport;
__u16 dport;
__u32 payload_length;
__u8 payload[MAX_LENGTH];
};
// 定义环形缓冲区映射
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 256 * 1024);
} events SEC(".maps");
// 读取HTTP信息并将其提交到环形缓冲区
event = bpf_ringbuf_reserve(&events, sizeof(*event), 0);
event->sport = bpf_ntohs(tcph.source);
event->dport = bpf_ntohs(tcph.dest);
event->payload_length = payload_length;
__u32 read_length = payload_length > MAX_LENGTH ? MAX_LENGTH : payload_length;
bpf_skb_load_bytes(skb, payload_offset, event->payload, read_length);
bpf_skb_load_bytes(skb, ETH_HLEN + offsetof(struct iphdr, saddr), &event->saddr, 4);
bpf_skb_load_bytes(skb, ETH_HLEN + offsetof(struct iphdr, daddr), &event->daddr, 4);
bpf_ringbuf_submit(event, 0);
到这儿内核态的代码就全部完成了,当然还需要用户态程序加载、挂载 eBPF 字节码并把 HTTP 内容从环形缓冲区映射中读出来。还记得具体该怎么做吗?如果没有印象,可以第 08 讲中回顾一下详细的步骤。
将上述代码保存到 http_trace.bpf.c 文件中,执行下面的 clang 和 bpftool 命令,编译 eBPF 字节码并生成对应的脚手架头文件。
clang -g -O2 -target bpf -c http_trace.bpf.c -D__TARGET_ARCH_x86_64 -I/usr/include/x86_64-linux-gnu -I. -o http_trace.bpf.o
bpftool gen skeleton http_trace.bpf.o > http_trace.skel.h
完整的 eBPF 代码请参考 GitHub http_trace.bpf.c
然后,引入上述命令中生成的脚手架头文件,开发用户态程序。忽略异常处理和通用 eBPF 程序都需要的公共代码外,主要的代码如下所示:
#include "http_trace.skel.h"
// 输出 HTTP 请求和响应信息(注意:长度截断至MAX_LENGTH)
static int handle_event(void *ctx, void *data, size_t data_sz)
{
const struct event_t *e = data;
char saddr[16] = { }, daddr[16] = { };
inet_ntop(AF_INET, &e->saddr, saddr, sizeof(saddr));
inet_ntop(AF_INET, &e->daddr, daddr, sizeof(daddr));
printf("%s:%d -> %s:%d (length: %d)\n%s\n\n", saddr, e->sport, daddr,
e->dport, e->payload_length, e->payload);
return 0;
}
int main(int argc, char **argv)
{
struct http_trace_bpf *skel;
struct ring_buffer *rb = NULL;
// 加载BPF程序
skel = http_trace_bpf__open_and_load();
// 创建ring buffer并绑定事件处理回调
rb = ring_buffer__new(bpf_map__fd(skel->maps.events), handle_event, NULL, NULL);
// 将eBPF程序挂载到原始套接字
int sock = open_raw_sock("eth0");
int prog_fd = bpf_program__fd(skel->progs.http_trace);
if (setsockopt(sock, SOL_SOCKET, SO_ATTACH_BPF, &prog_fd, sizeof(prog_fd)))
{
fprintf(stderr, "Failed to attach eBPF prog\n");
goto cleanup;
}
// 循环等待从ring buffer中读取数据
while ((err = ring_buffer__poll(rb, 100)) >= 0) ;
cleanup: // 释放资源
ring_buffer__free(rb);
http_trace_bpf__destroy(skel);
}
完整的用户态代码请参考 GitHub http_trace.c
将其编译之后以 root 用户运行。打开另外一个终端,并运行 curl http://baidu.com 命令,回到 eBPF 程序终端,你将看到如下的输出:
$ ./http_trace
192.168.1.2:42290 -> 39.156.66.10:80 (length: 73)
GET / HTTP/1.1
Host: baidu.com
User-Agent: curl/7.81.0
Accept: */*
39.156.66.10:80 -> 192.168.1.2:42290 (length: 305)
HTTP/1.1 200 OK
Date: Sun, 07 Jul 2024 06:54:50 GMT
Server: Apache
Last-Modified: Tue, 12 Jan 201
而如果你访问的不是 HTTP 80 端口,比如 curl https://baidu.com,eBPF 程序则不会输出任何内容。
那么,你可能也在想,这个程序是不是稍微修改一下端口就可以跟踪 HTTPS 请求了呢?我们来修改一下刚才的 eBPF 程序,试一下就知道了。参考下面的代码,把端口号从 80 改成 443,并注释掉检查 HTTP 内容的代码。
...
// 只跟踪 TCP 443 端口的数据包
if (tcph.source != bpf_htons(443) && tcph.dest != bpf_htons(443)) {
return 0;
}
// 计算HTTPS payload偏移/长度的方法同HTTP
__u32 payload_offset = ETH_HLEN + iph_len + tcp_hlen;
__u32 payload_length = bpf_ntohs(ip_total_length) - iph_len - tcp_hlen;
if (payload_length < 7) {
return 0;
}
// 数据内容不可见,故而无法过滤内容
// char start_buffer[7] = { };
// bpf_skb_load_bytes(skb, payload_offset, start_buffer, 7);
// if (bpf_strncmp(start_buffer, 3, "GET") != 0 &&
// bpf_strncmp(start_buffer, 4, "POST") != 0 &&
// bpf_strncmp(start_buffer, 3, "PUT") != 0 &&
// bpf_strncmp(start_buffer, 6, "DELETE") != 0 &&
// bpf_strncmp(start_buffer, 4, "HTTP") != 0) {
// return 0;
// }
...
完整的用户态代码请参考 GitHub https_trace_bad.c
将其编译之后以 root 用户运行。打开另外一个终端,并运行 curl https://baidu.com 命令,回到 eBPF 程序终端,你将看到如下的输出:
192.168.1.2:40658 -> 39.156.66.10:443 (length: 517)
39.156.66.10:443 -> 192.168.1.2:40658 (length: 2880)
39.156.66.10:443 -> 192.168.1.2:40658 (length: 764)
0�+0~
|Any use of this Certificate constitutes acceptance of the Relying Party Agreement l
192.168.1.2:40658 -> 39.156.66.10:443 (length: 126)
39.156.66.10:443 -> 192.168.1.2:40658 (length: 764)
0�+0~
|Any use of this Certificate constitutes acceptance of the Relying Party Agreement l
39.156.66.10:443 -> 192.168.1.2:40658 (length: 51)
192.168.1.2:40658 -> 39.156.66.10:443 (length: 102)
39.156.66.10:443 -> 192.168.1.2:40658 (length: 386)
}ãܰz�r̗�Ea{��N{�K~S3/G��XB��Ԃ�qi���J���8�=�O5�>B����H����d�.��nLC�c:��R=��Z'�A�[{V�4
192.168.1.2:40658 -> 39.156.66.10:443 (length: 31)
从输出你可以发现,这次不仅输出的内容变多了,而且也没法看到具体的 HTTPS 请求和响应内容了。其实,输出变多是由于 HTTPS 比 HTTP 多了 TLS 握手导致的,而乱码或者内容空白则是因为我们读取到的是不可见字符。
这些输出也说明我们无法通过套接字过滤程序去跟踪 HTTPS 的网络数据。由于 TLS 加密的过程发生在用户态,从内核态看到的总是加密后的数据。所以,要跟踪 HTTPS 网络包,就必须要从用户态跟踪入手了。那么, 该如何跟踪呢?我将在下篇中详细为你介绍。
小结
今天,我带你一起回顾了 HTTP 和 HTTPS 协议的工作原理,并以套接字 eBPF 程序为例带你学习了如何使用 eBPF 程序跟踪 HTTP 网络包。由于 HTTP 网络包传输的数据是明文的,所以我们可以直接从套接字中读取到 HTTP 请求和响应的具体内容。实际上,只要是未加密的网络数据,我们都可以使用类似的方法在内核中直接通过 eBPF 读取到明文网络数据,从而就可以实现对分布式系统网络调用的透明跟踪。
而当数据加密之后又该怎么办呢?别急,我将在下篇中为你揭晓。
思考
最后,我想邀请你来聊一聊:
- 针对 HTTP 请求这种明文网络数据的跟踪都有哪些可行的方案?eBPF 相比它们有哪些优势?
- 课程中的 eBPF 程序实现了简单的 HTTP 请求跟踪功能,假如你要实现一个 HTTP 防火墙,可以根据 URL 黑白名单过滤请求,那又该如何设计 eBPF 程序呢?
期待你在留言区和我讨论,也欢迎把这节课分享给你的同事、朋友。让我们一起在实战中演练,在交流中进步。
- 进击的Lancelot 👍(0) 💬(0)
按照上述文章中的代码编写,在加载 ebpf 程序时会产生错误信息: 139: (85) call bpf_skb_load_bytes#26 R4 invalid zero-sized read: u64=[0,99] processed 159 insns (limit 1000000) max_states_per_insn 1 total_states 12 peak_states 12 mark_read 5 -- END PROG LOAD LOG -- libbpf: prog 'http_trace': failed to load: -13 libbpf: failed to load object 'http_trace_bpf' libbpf: failed to load BPF skeleton 'http_trace_bpf': -13 Failed to open and load BPF skeleton 产生这个错误信息的原因是因为 bpf_skb_load_bytes 的第四个参数必须是常量类型,而 read_length 是变量。这里分享一下找到这个原因的过程: 1. 在对应版本的内核当中找到这个错误信息 invalid zero-sized read,通过错误信息定位到 kfunc:check_mem_size_reg 2. 通过 bpftrace 追踪 check_mem_size_reg 返回值非零时的 kstack 。执行 sudo bpftrace -e 'kretprobe:check_mem_size_reg /retval != 0/ { print(kstack());}', 得到以下调用栈: check_func_arg+1013 check_helper_call.isra.0+514 do_check+2778 do_check_common+486 bpf_check+1934 bpf_prog_load+1733 __sys_bpf+1381 __x64_sys_bpf+26 x64_sys_call+6552 do_syscall_64+127 entry_SYSCALL_64_after_hwframe+120 3. 通过阅读代码或者 faddr2line 找到 check_func_arg+1013 对应的位置, 即以下代码: case ARG_CONST_SIZE: err = check_mem_size_reg(env, reg, regno, false, meta); 4. 通过 ARG_CONST_SIZE 可以找到 bpf_arg_type 定义,进而找到 bpf_func_proto。 通过注释,可以知道 bpf_func_proto 是用来帮助 verifier 对一个 ebpf helper func 进行验证的 5. 通过 bpf_func_proto 和对应的 helper bpf_skb_load_bytes 可以找到以下定义: static const struct bpf_func_proto bpf_skb_load_bytes_proto = { .func = bpf_skb_load_bytes, .gpl_only = false, .ret_type = RET_INTEGER, .arg1_type = ARG_PTR_TO_CTX, .arg2_type = ARG_ANYTHING, .arg3_type = ARG_PTR_TO_UNINIT_MEM, .arg4_type = ARG_CONST_SIZE, }; 至此可以确定 bpf_skb_load_bytes 要求第四个参数 len 的类型必须是常量类型
2024-12-31