25 技术解析:HTTPS跟踪详解(下)
你好,我是倪朋飞。
上一讲我带你一起回顾了 HTTP 和 HTTPS 协议的工作原理,并以套接字 eBPF 程序为例带你学习了如何使用 eBPF 程序跟踪 HTTP 网络包。由于 HTTP 网络包传输的数据是明文的,所以我们可以直接从套接字中读取到 HTTP 请求和响应的具体内容。而 HTTPS 则不同,由于 TLS 加密的过程发生在用户态,从内核态看到的总是加密后的数据。所以,要跟踪 HTTPS 网络包,就必须要从用户态跟踪入手了。
那么, 该如何使用 eBPF 用户态程序跟踪 HTTPS 呢,今天,我就带你一起去看看这个问题。
如何确定用户态跟踪点
既然要使用用户态程序跟踪 HTTPS,那么我想进入你脑海的第一个问题就是有哪些用户态跟踪点可以使用呢?没错,这正是我们需要解决的第一个问题。
用户态不同于内核,每个应用程序的源码、编程语言、运行时等都不同,所以在选择跟踪点时需要考察它们有哪些共同的部分,这样跟踪共同的模块才可以涵盖更广的应用场景,避免为每一个应用再去做适配(当然,通用性也是 eBPF 的一个目标)。
对于我们今天的主题 HTTPS 来说,跟踪的主要难点在于 TLS 加密,而你一定听说过 TLS 加密协议最流行的开源库——OpenSSL。OpenSSL 是一个功能强大的开源加密库,广泛应用于加密通信、证书管理和数据安全中。
应用程序开发者通常以动态链接的方式借助 OpenSSL 库来实现加密通信。你可以使用 ldd 命令查看程序依赖库的列表,从而确认应用程序是否使用了 OpenSSL。比如,curl、nginx 等都是使用 OpenSSL 的典型应用。
$ ldd /usr/sbin/nginx | grep ssl
libssl.so.3 => /lib/x86_64-linux-gnu/libssl.so.3 (0x000079ffab4f7000)
$ ldd /usr/bin/curl | grep ssl
libssl.so.3 => /lib/x86_64-linux-gnu/libssl.so.3 (0x00007574d135c000)
当然了,只知道应用使用了 OpenSSL 库还不够,用户态跟踪还需要知道具体的挂载点,也就是应用中所调用的函数。参考 OpenSSL 文档,典型的 TLS 通信过程如下图所示:
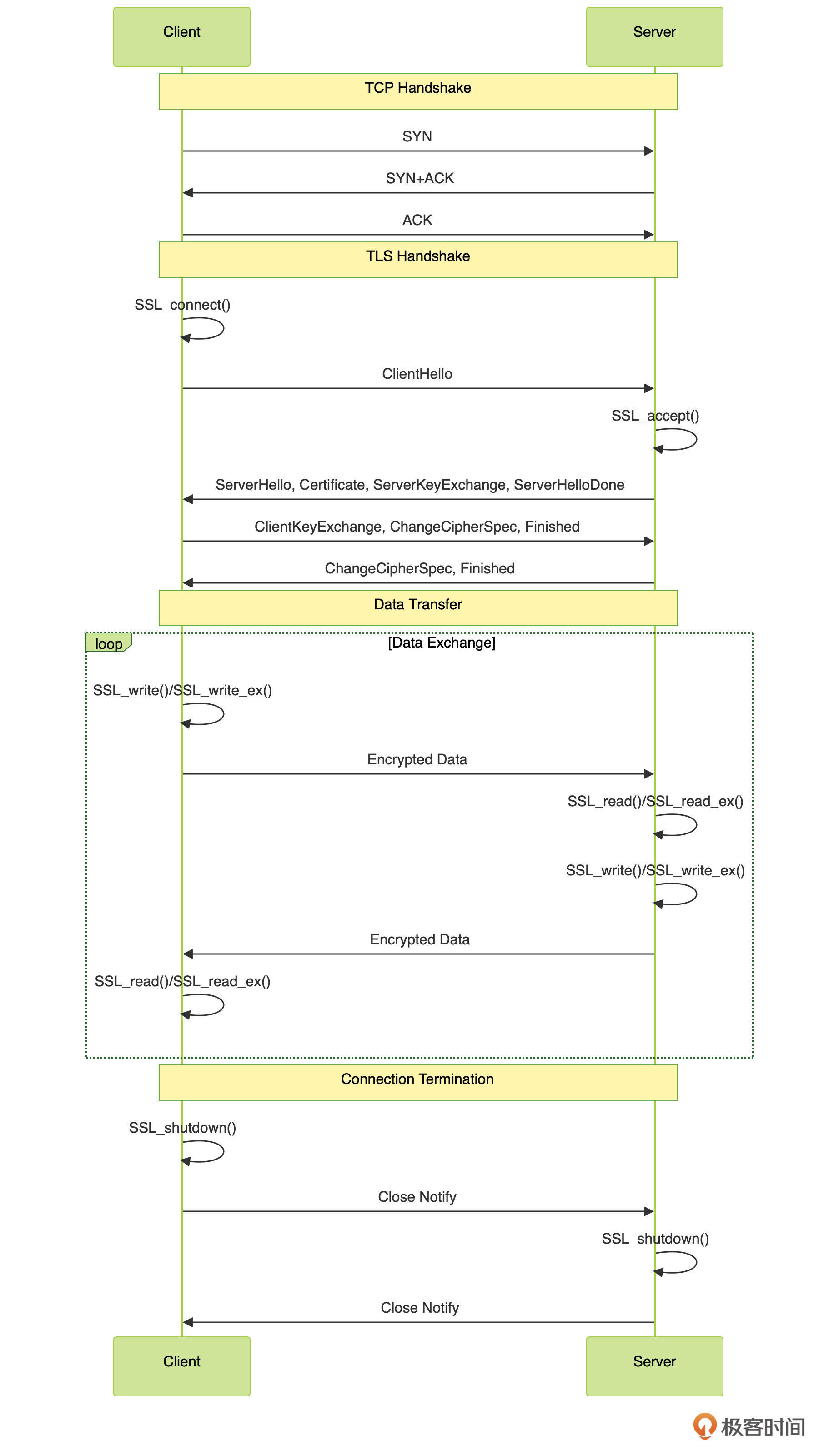
从上图中你可以发现,典型的 TLS 通信过程包括 TCP 握手、TLS 握手、数据传输以及连接终止等过程。我们课程的主题是跟踪 HTTPS 网络包,所以需要特别关注数据传输部分,也就是对应的 SSL_read/SSL_write 系列函数,它们也将是我们 eBPF 程序所需要的跟踪点。
参考 SSL_read 和 SSL_write 的开发文档,它们的定义格式如下所示:
int SSL_read_ex(SSL *ssl, void *buf, size_t num, size_t *readbytes);
int SSL_read(SSL *ssl, void *buf, int num);
int SSL_write_ex(SSL *ssl, const void *buf, size_t num, size_t *written);
int SSL_write(SSL *ssl, const void *buf, int num);
这其中:
ssl表示已经建立的 SSL 连接;buf表示读取或者写入数据的缓冲区,这也正是我们想要的数据;num表示要读取或者写入数据的最大长度(单位是字节);- 带 ex 后缀的函数还额外支持
readbytes和written指针参数,分别表示操作完成后实际读取的字节数和实际写入的字节数。
到这里,用户态应用的跟踪点就非常清楚了,接下来我们就可以开始正式的 eBPF 程序开发了。
如何用 eBPF 跟踪 HTTPS 网络包
同上篇中的 HTTP 网络包跟踪一样,我们这节课继续使用 libbpf 来构造 HTTPS 的网络跟踪 eBPF 程序,这包括内核态 eBPF 程序和用户态的前端程序。
还记得用户态 eBPF 程序详细的开发步骤吗?不记得也没关系,你可以查看我们课程第 09 讲的内容,回顾如何使用 eBPF 用户态跟踪排查应用程序。
内核态 eBPF 程序
先来看内核态 eBPF 程序的开发。
用户态函数的跟踪包括 uprobe 和 uretprobe 两类,分别用于跟踪函数入口(比如跟踪入口参数)和函数返回(比如跟踪返回值)的场景。对于我们要跟踪的 SSL_read/SSL_write 函数,都带有一个 void *buf 参数,那是不是只用 uprobe 就可以直接从 buf 中读取我们想要的数据了呢?
答案是否定的,只有在 SSL_read() 函数的内部才会从 SSL 连接读取数据并保存到 buf 中,而在函数调用的入口处是无法读到 buf 未来的数据的。所以,我们需要在 uretprobe 中读取数据。但是,uretprobe 能直接读取的只有返回值,那怎么读到入口参数呢?我想你一定想到了,那就是借助一个 BPF 映射,在 uprobe 中把入口参数存入 BPF 映射中,再到 uretprobe 中读出来。
为了方便用户态跟踪程序的开发,Libbpf 提供了 BPF_UPROBE 和 BPF_URETPROBE 这两个宏,可以很方便地用来定义 uprobe 和 uretprobe 处理函数。BPF_UPROBE/BPF_URETPROBE 的使用方法跟 BPF_KPROBE/BPF_KRETPROBE 是完全一样的,它们的签名格式如下所示:
/* BPF_UPROBE and BPF_URETPROBE are identical to BPF_KPROBE and BPF_KRETPROBE,
* but are named way less confusingly for SEC("uprobe") and SEC("uretprobe")
* use cases.
*/
#define BPF_UPROBE(name, args...) BPF_KPROBE(name, ##args)
#define BPF_URETPROBE(name, args...) BPF_KRETPROBE(name, ##args)
/*
* BPF_KPROBE serves the same purpose for kprobes as BPF_PROG for
* tp_btf/fentry/fexit BPF programs. It hides the underlying platform-specific
* low-level way of getting kprobe input arguments from struct pt_regs, and
* provides a familiar typed and named function arguments syntax and
* semantics of accessing kprobe input paremeters.
*
* Original struct pt_regs* context is preserved as 'ctx' argument. This might
* be necessary when using BPF helpers like bpf_perf_event_output().
*/
#define BPF_KPROBE(name, args...) \
name(struct pt_regs *ctx); \
static __always_inline typeof(name(0)) \
____##name(struct pt_regs *ctx, ##args); \
typeof(name(0)) name(struct pt_regs *ctx) \
{ \
_Pragma("GCC diagnostic push") \
_Pragma("GCC diagnostic ignored \"-Wint-conversion\"") \
return ____##name(___bpf_kprobe_args(args)); \
_Pragma("GCC diagnostic pop") \
} \
static __always_inline typeof(name(0)) \
____##name(struct pt_regs *ctx, ##args)
/*
* BPF_KRETPROBE is similar to BPF_KPROBE, except, it only provides optional
* return value (in addition to `struct pt_regs *ctx`), but no input
* arguments, because they will be clobbered by the time probed function
* returns.
*/
#define BPF_KRETPROBE(name, args...) \
name(struct pt_regs *ctx); \
static __always_inline typeof(name(0)) \
____##name(struct pt_regs *ctx, ##args); \
typeof(name(0)) name(struct pt_regs *ctx) \
{ \
_Pragma("GCC diagnostic push") \
_Pragma("GCC diagnostic ignored \"-Wint-conversion\"") \
return ____##name(___bpf_kretprobe_args(args)); \
_Pragma("GCC diagnostic pop") \
} \
static __always_inline typeof(name(0)) ____##name(struct pt_regs *ctx, ##args)
由于 SSL_read/SSL_write 函数的前面三个参数和返回值定义格式都是一样的,所以它们的跟踪程序逻辑可以共享,比如可以为它们定义公共的处理函数,具体的代码如下:
SEC("uprobe/SSL_read")
int BPF_UPROBE(probe_SSL_read_entry, void *ssl, void *buf, int num)
{
return SSL_rw_entry(ctx, ssl, buf, num);
}
SEC("uprobe/SSL_write")
int BPF_UPROBE(probe_SSL_write_entry, void *ssl, void *buf, int num)
{
return SSL_rw_entry(ctx, ssl, buf, num);
}
SEC("uretprobe/SSL_read")
int BPF_URETPROBE(probe_SSL_read_exit)
{
return SSL_rw_exit(ctx, 0); // 0表示读
}
SEC("uretprobe/SSL_write")
int BPF_URETPROBE(probe_SSL_write_exit)
{
return SSL_rw_exit(ctx, 1); // 1表示写
}
SSL_rw_entry() 要做的事情比较简单,就是把入口参数存入 BPF 映射中(比如使用哈希映射),具体代码如下:
// 用于存储SSL读写缓冲区的哈希映射
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 1024);
__type(key, __u32); // tid
__type(value, __u64); // buf地址
} bufs SEC(".maps");
// 存储SSL读写缓冲区的地址到哈希映射
static int SSL_rw_entry(struct pt_regs *ctx, void *ssl, void *buf, int num)
{
u64 pid_tgid = bpf_get_current_pid_tgid();
u32 tid = (u32) pid_tgid;
bpf_map_update_elem(&bufs, &tid, (u64 *) & buf, BPF_ANY);
return 0;
}
把 SSL 读取和写入数据的缓冲区地址存入哈希映射后,SSL_rw_exit() 要做的事情自然就是从哈希映射中拿出缓冲区地址、读取缓冲区数据,最后再通过 perf event 把数据传输给用户态,具体的代码如下:
static int SSL_rw_exit(struct pt_regs *ctx, int rw)
{
u64 pid_tgid = bpf_get_current_pid_tgid();
u32 pid = pid_tgid >> 32;
u32 tid = (u32) pid_tgid;
// 从哈希映射中读取SSL读写缓冲区的地址
u64 *bufp = bpf_map_lookup_elem(&bufs, &tid);
if (!bufp) {
return 0;
}
// 从寄存器中读取函数调用的返回值
int len = PT_REGS_RC(ctx);
if (len <= 0) {
return 0;
}
// 分配一个数据缓冲区
__u32 zero = 0;
struct event_t *event = bpf_map_lookup_elem(&data_buffer_heap, &zero);
if (!event) {
return 0;
}
// 元数据填充
event->rw = rw;
event->pid = pid;
event->uid = bpf_get_current_uid_gid();
bpf_get_current_comm(&event->comm, sizeof(event->comm));
// 读取SSL读写缓冲区的数据
event->len = (size_t)MAX_BUF_LENGTH < (size_t)len ? (size_t) MAX_BUF_LENGTH : (size_t) len;
if (bufp != NULL) {
bpf_probe_read_user(event->buf, event->len,
(const char *)*bufp);
}
bpf_map_delete_elem(&bufs, &tid);
// 将数据缓冲区的数据发送到perf event
bpf_perf_event_output(ctx, &events, BPF_F_CURRENT_CPU, event,
sizeof(struct event_t));
return 0;
}
将上述代码保存到 https_trace.bpf.c 文件中,执行下面的 clang 和 bpftool 命令,编译 eBPF 字节码并生成对应的脚手架头文件。
clang -g -O2 -target bpf -c https_trace.bpf.c -D__TARGET_ARCH_x86_64 -I/usr/include/x86_64-linux-gnu -I. -o https_trace.bpf.o
bpftool gen skeleton https_trace.bpf.o > https_trace.skel.h
完整的 eBPF 代码请参考 GitHub https_trace.bpf.c
用户态前端程序
有了 eBPF 程序生成的脚手架头文件之后,用户态程序的开发也就比较直观了。忽略异常处理和通用 eBPF 程序都需要的公共代码外,主要的代码如下所示:
// 查找OpenSSL库的路径
char *libssl_path = find_library_path("libssl.so");
if (!libssl_path) {
fprintf(stderr, "Failed to find libssl.so\n");
return 1;
}
// 加载BPF程序
skel = https_trace_bpf__open_and_load();
if (!skel) {
fprintf(stderr, "Failed to open and load BPF skeleton\n");
return 1;
}
// 创建buffer并绑定事件处理回调
pb = perf_buffer__new(bpf_map__fd(skel->maps.events), 16,
handle_event, NULL, NULL, NULL);
if (!pb) {
fprintf(stderr, "Failed to create perf buffer\n");
goto cleanup;
}
// 挂载uprobe到OpenSSL库
printf("Attaching uprobe to %s\n", libssl_path);
// SSL_read
LIBBPF_OPTS(bpf_uprobe_opts, uprobe_ropts,.func_name = "SSL_read");
skel->links.probe_SSL_read_entry =
bpf_program__attach_uprobe_opts(skel->progs.probe_SSL_read_entry,
-1, libssl_path, 0, &uprobe_ropts);
LIBBPF_OPTS(bpf_uprobe_opts, uprobe_ropts_ret,.func_name =
"SSL_read",.retprobe = true);
skel->links.probe_SSL_read_exit =
bpf_program__attach_uprobe_opts(skel->progs.probe_SSL_read_exit, -1,
libssl_path, 0, &uprobe_ropts_ret);
// SSL_write
LIBBPF_OPTS(bpf_uprobe_opts, uprobe_wopts,.func_name = "SSL_write");
skel->links.probe_SSL_write_entry =
bpf_program__attach_uprobe_opts(skel->progs.probe_SSL_write_entry,
-1, libssl_path, 0, &uprobe_wopts);
LIBBPF_OPTS(bpf_uprobe_opts, uprobe_wopts_ret,.func_name =
"SSL_write",.retprobe = true);
skel->links.probe_SSL_write_exit =
bpf_program__attach_uprobe_opts(skel->progs.probe_SSL_write_exit,
-1, libssl_path, 0,
&uprobe_wopts_ret);
// 从Buffer中读取数据
printf("Tracing HTTPS traffic... Hit Ctrl-C to end.\n");
while (!exiting) {
err = perf_buffer__poll(pb, 100);
if (err == -EINTR) {
err = 0;
break;
}
if (err < 0) {
fprintf(stderr, "Error polling perf buffer: %d\n", err);
break;
}
}
从这段代码可以看出用户态的前端程序跟上一讲的 HTTP 跟踪步骤是类似的,需要注意的有两点:
- 第一,eBPF 程序的挂载方式不同,上一讲是挂载到原始套接字,而这儿是挂载到动态链接库 libssl.so。
- 第二,用户态跟踪需要挂载到具体的动态链接库或者可执行文件上,这些文件的路径可能不是唯一的,所以可以在程序中动态查找它们的路径。
find_library_path()的实现如下所示:
// 查找库的路径
char *find_library_path(const char *libname)
{
char cmd[256];
static char path[256];
snprintf(cmd, sizeof(cmd), "ldconfig -p | grep %s", libname);
FILE *fp = popen(cmd, "r");
if (!fp) {
fprintf(stderr, "Failed to run command: %s\n", cmd);
return NULL;
}
// 格式: libssl3.so (libc6,x86-64) => /lib/x86_64-linux-gnu/libssl3.so
if (fgets(path, sizeof(path) - 1, fp) != NULL) {
char *p = strrchr(path, '>');
if (p && *(p + 1) == ' ') {
memmove(path, p + 2, strlen(p + 2) + 1);
char *end = strchr(path, '\n');
if (end) {
*end = '\0';
}
pclose(fp);
return path;
}
}
pclose(fp);
return NULL;
}
完整的用户态代码请参考 GitHub https_trace.c
将用户态程序保存到 https_trace.c,并将其编译之后以 root 用户运行。打开另外一个终端,并运行 curl https://baidu.com 命令,回到 eBPF 程序终端,你将看到如下的输出:
====================================
curl write
GET / HTTP/1.1
Host: baidu.com
User-Agent: curl/7.81.0
Accept: */*
====================================
curl read
HTTP/1.1 302 Moved Temporarily
Server: bfe/1.0.8.18
Date: Sun, 11 Aug 2024 12:51:57 GMT
Content-Type: text/html
Content-Length: 161
Connection: keep-alive
Location: http://www.baidu.com/
<html>
<head><title>302 Found</title></head>
<body bgcolor="white">
<center><h1>302 Found</h1></center>
<hr><center>bfe/1.0.8.18</center>
</body>
</html>
恭喜你,你已经成功跟踪到了 HTTPS 请求的详细内容。有了这个跟踪程序,以后你再也不用担心无法对 HTTPS 进行抓包的问题了。
小结
今天,我带你一起梳理了 OpenSSL 的基本工作原理,并以用户态 eBPF 程序为例带你学习了如何跟踪 HTTPS 网络包。由于应用程序对 HTTPS 数据的加解密都会调用 SSL_read/SSL_write 函数,所以只需要跟踪这两个函数就可以获取我们想要的明文数据。
当然,OpenSSL 虽然是最流行的开源加密库,却也并非唯一的选择。LibreSSL、BoringSSL、GnuTLS、NSS 等开源库也有许多用户。因此,要完整跟踪所有应用的 HTTPS 请求,还需要跟踪和支持其他主流的加密库。把这些加密库都实现起来也还是有一定的困难的,好在 eBPF 技术还有庞大的开源社区,你所需要的功能已经有开源项目帮你实现了。eCapture 就是这样一个项目,你可以在需要时直接拿过来使用。
思考
在前面的例子中,我们访问百度网站,可以看到完美跟踪了请求和响应数据,但在访问其他网站的时候却不是。比如,访问谷歌网站可以看到如下的输出:
====================================
curl write
PRI * HTTP/2.0
SM
====================================
curl write
d
====================================
curl write
�
====================================
curl write
��A��皂�C�z�%�Pë��S*/*
====================================
curl read
d
====================================
curl write
====================================
curl read
====================================
curl read
�dn��)�cǏ
�s�AW!�c_�I|���Mjq��@�!�IjJ�)-����g�������%c�G��<}
D������}�4kl2���_���XjҲ,"���B�>�����r���)��~��J�&�+I��b�?Յ��%d��/�S�[R)V/q����Vԁ�U�U���IҚ�qIҚ�}�Z�bV��):SZ.0�Z�
��9栫���DV����9lZz���m_J*Cli@�p"��Jbѿd��i~�Z�ҁf�Eq��ţX����1>��~VŀM� vgws\��@��!j�:JD��0@����z�cԏ�����œO@� Yɤ��?��4����#�M� S�������L�?jR8��
====================================
curl read
�<HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8">
<TITLE>301 Moved</TITLE></HEAD><BODY>
<H1>301 Moved</H1>
The document has moved
<A HREF="https://www.google.com/">here</A>.
</BODY></HTML>
====================================
curl read
====================================
curl read
�
我想邀请你来聊一聊:
- 同样都是访问 HTTPS 网站,为什么这次的输出变多了,还有很多的乱码?
- 如何改进跟踪程序,让它更好支持这类访问请求?
期待你在留言区和我讨论,也欢迎把这节课分享给你的同事、朋友。让我们一起在实战中演练,在交流中进步。
- wty 👍(0) 💬(0)
访问谷歌有乱码是因为有梯子吗?
2025-01-20