特别放送 知识回顾(下)
你好,我是黄鸿波。
这节课是我们最后一部分的知识回顾,我将带你整体过一遍最后三章的内容。如果你对课程有任何的建议,欢迎在评论区留言,我来对课程进行迭代。话不多说,我们正式开始这节课的内容。
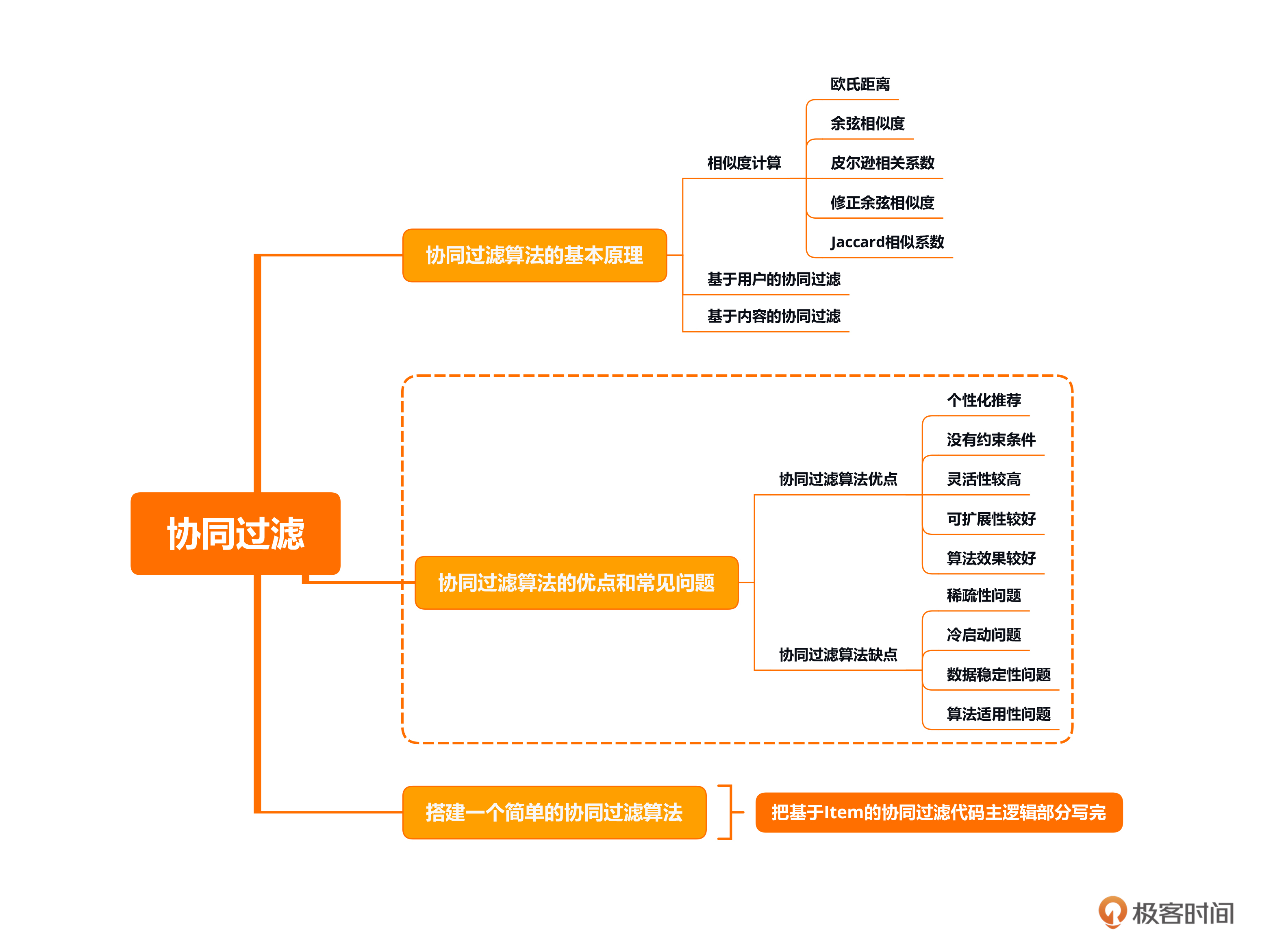
本节课的重点在于熟悉协同过滤算法的基本原理、优点及常见问题,并能够通过Python实现一个简单的协同过滤算法。本节课是召回算法章节的第一节课,在本章我们都会围绕算法和模型进行讲解。
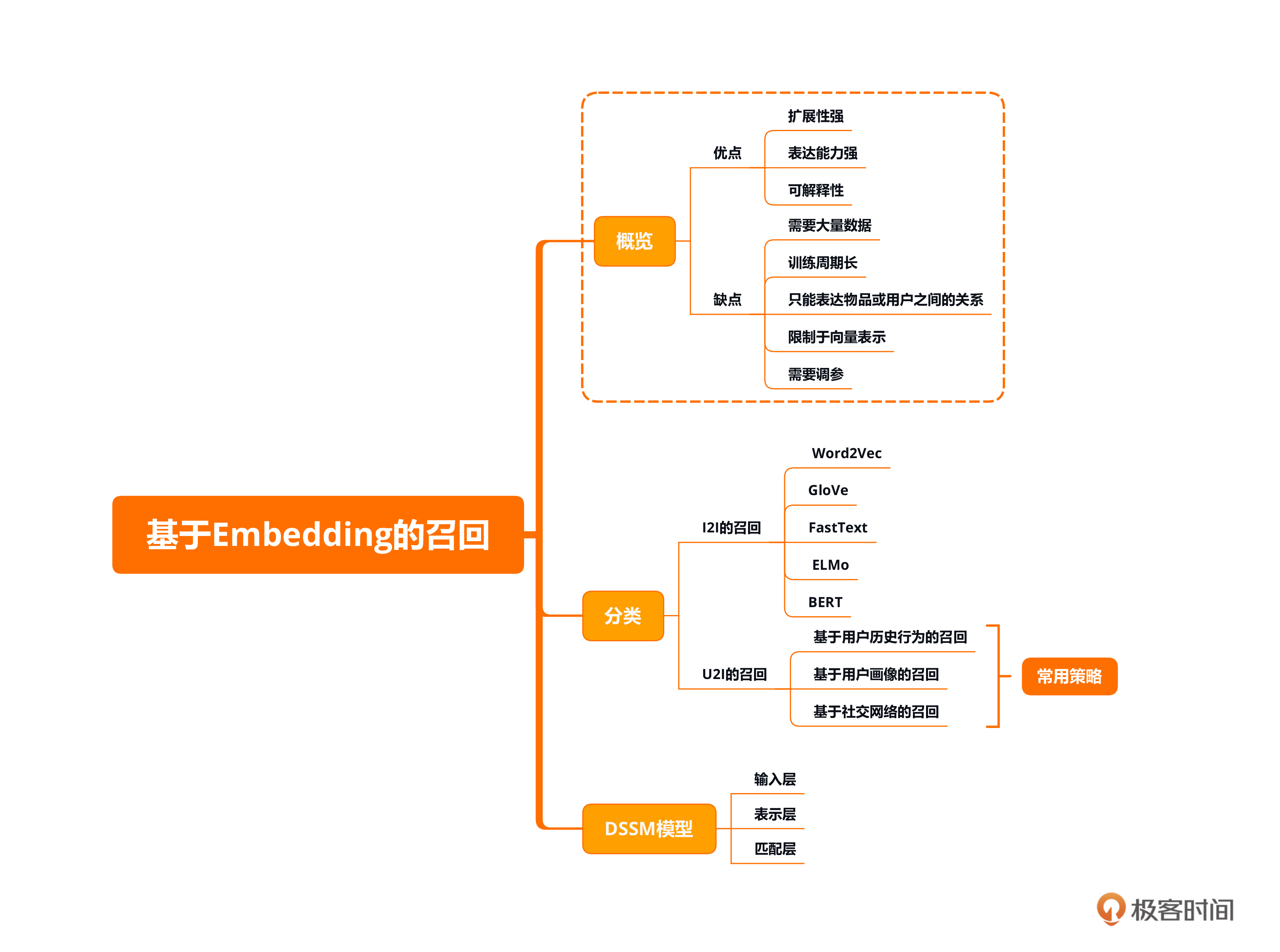
本节课的重点在于了解基于Embedding的召回算法和DSSM模型。基于Embedding的召回中最核心的就是I2I和U2I,你需要对二者有大致了解。此外,DSSM模型主要包含User塔和Item塔,你需要对输入层、表示层和匹配层也有一定的了解。
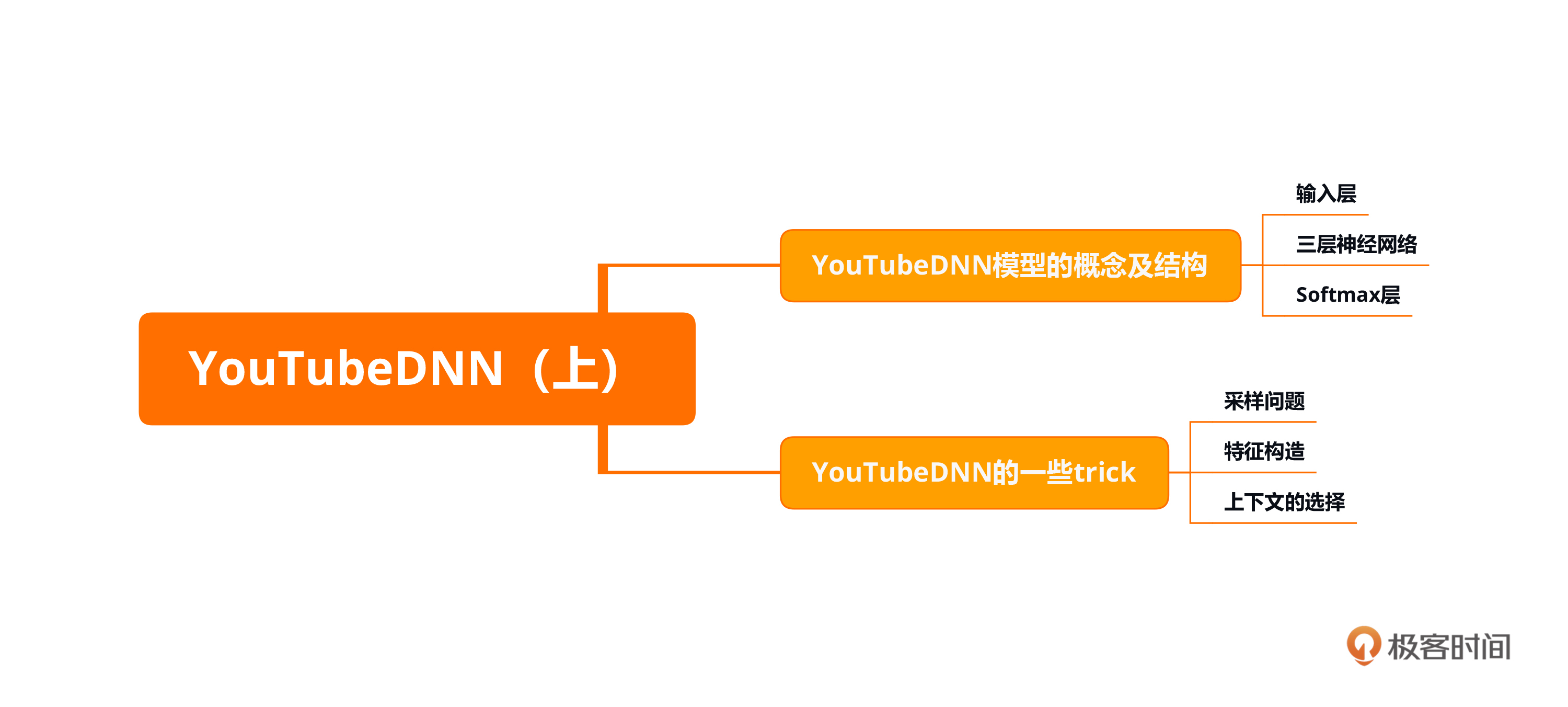
本节课的重点在于了解YoutubeDNN模型的概念以及结构,它主要分成三层:输入层、DNN层和Softmax输出层。同时我们讲解了一些trick,比如对数据集的采样、负样本的生成加快训练速度、特征构造以及上下文选择等。
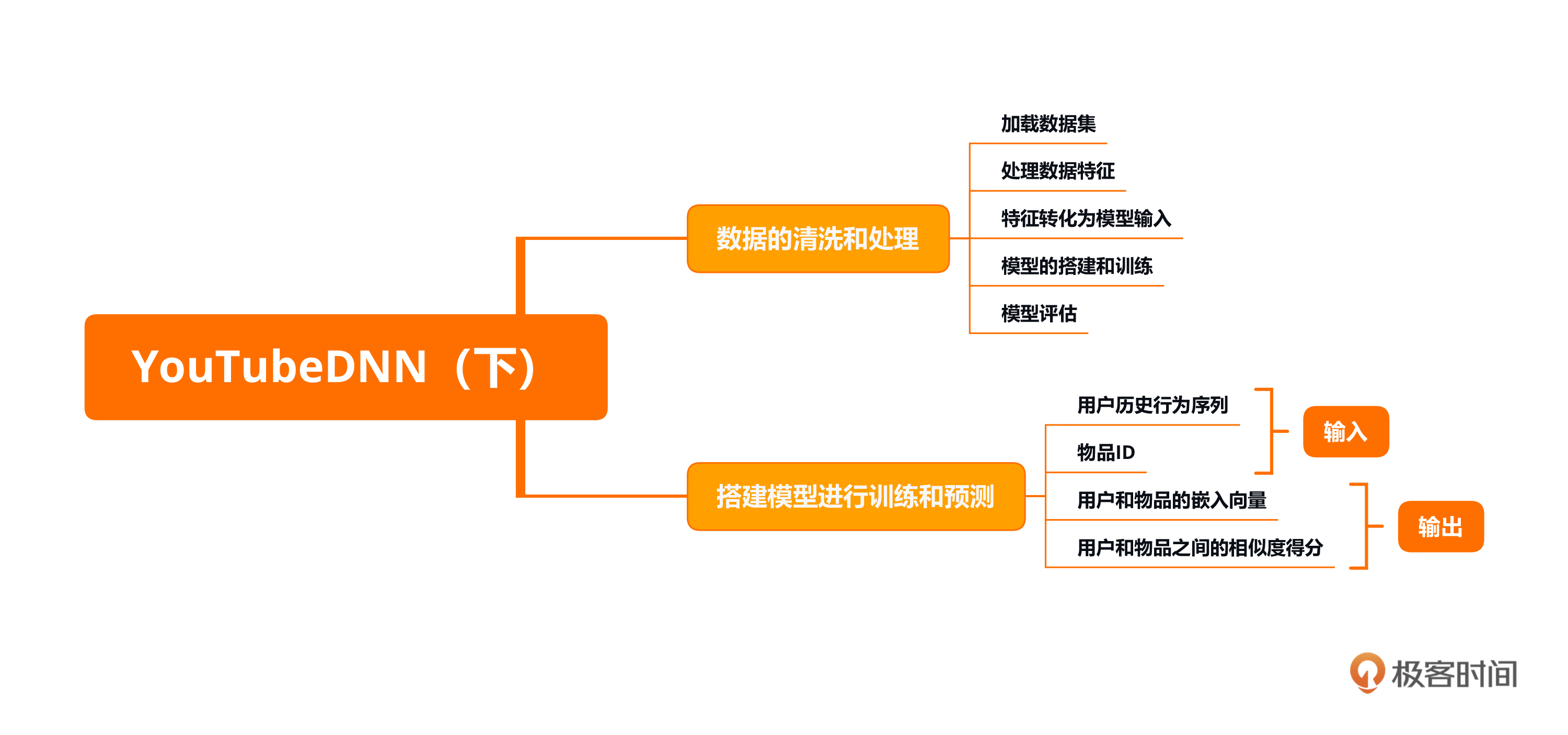
本节课承接上一节,用代码来实现YoutubeDNN模型。我们分成了两个步骤,第一个步是对数据的清洗和处理,第二个步是搭建模型然后把数据放进去进行训练和预测。
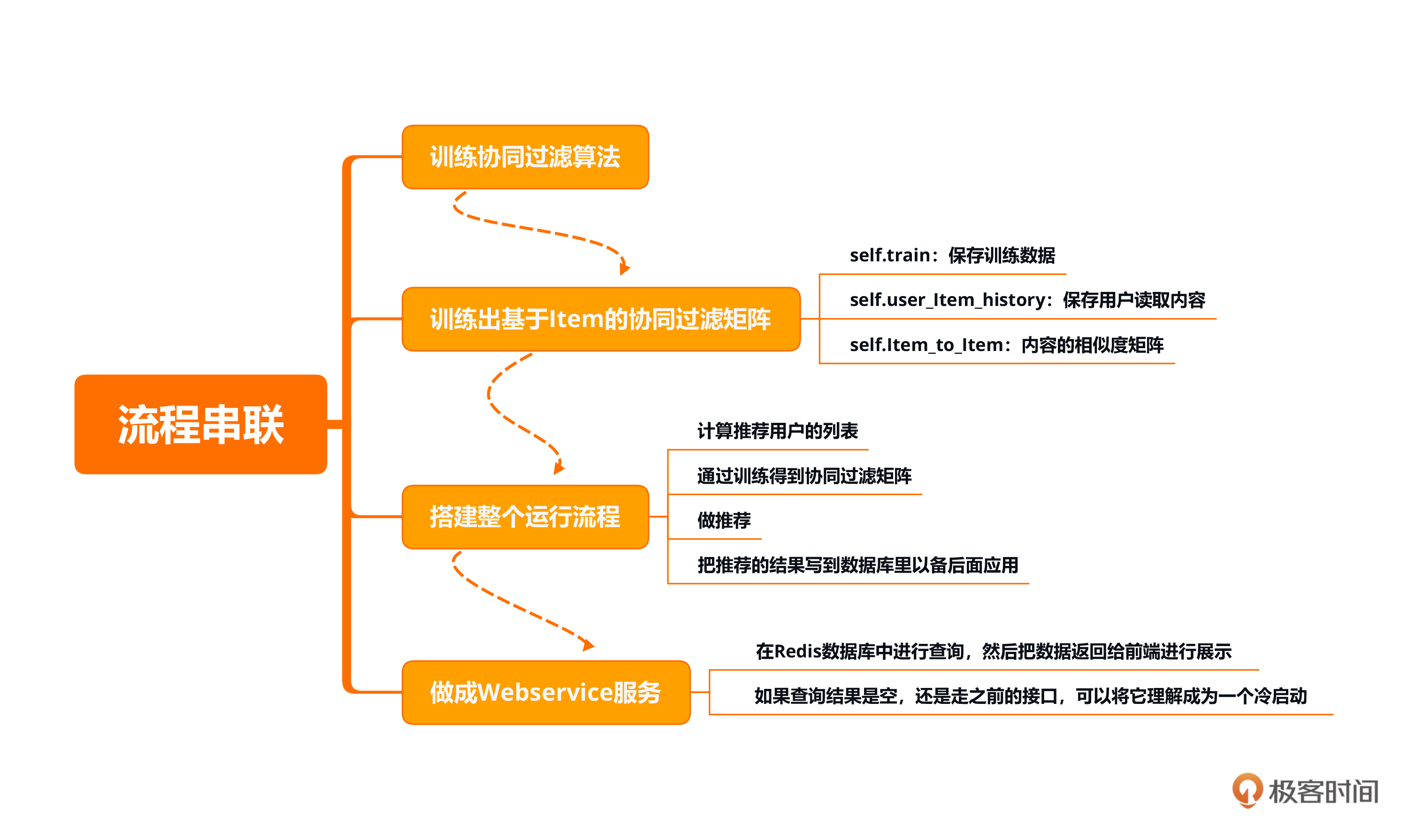
本节课是一个流程串讲,我们先是训练协同过滤算法,紧接着使用协同过滤算法训练出基于Item的协同过滤矩阵。然后再利用协调过滤矩阵,将用户ID传入进去预测出每一个用户的Item list。最后,将预测出来的结果存入到Redis数据库并通过Webservice做成接口。
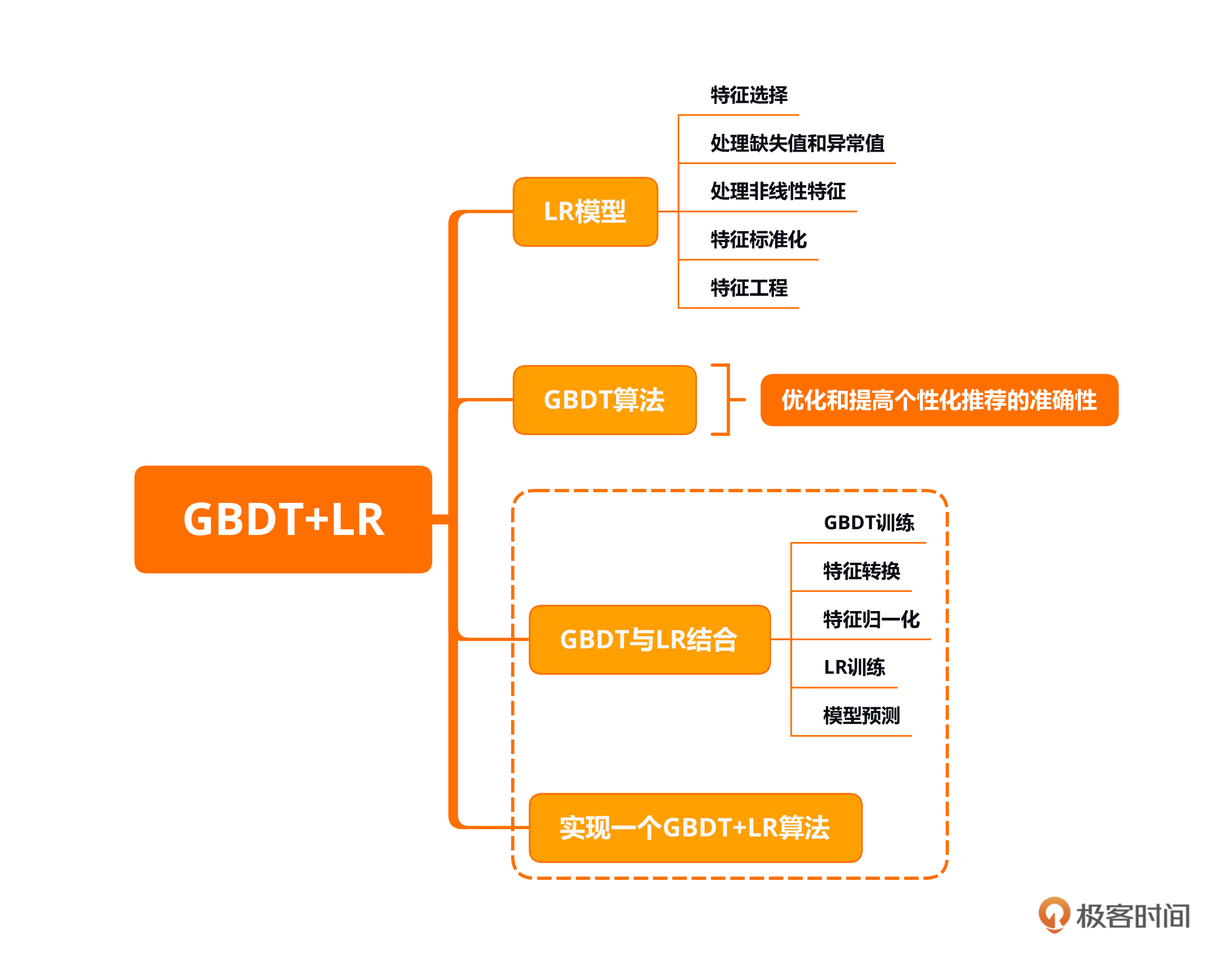
本节课的重点在于了解LR与GBDT的概念,同时学习二者的结合。GBDT+LR模型在推荐系统中应用最为广泛的就是点击率预估问题,即根据用户的历史行为和当前的环境,预测用户是否会对推荐的商品产生兴趣并进行点击的概率。你也需要掌握如何使用Python在公开数据集上实现一个GBDT+LR。
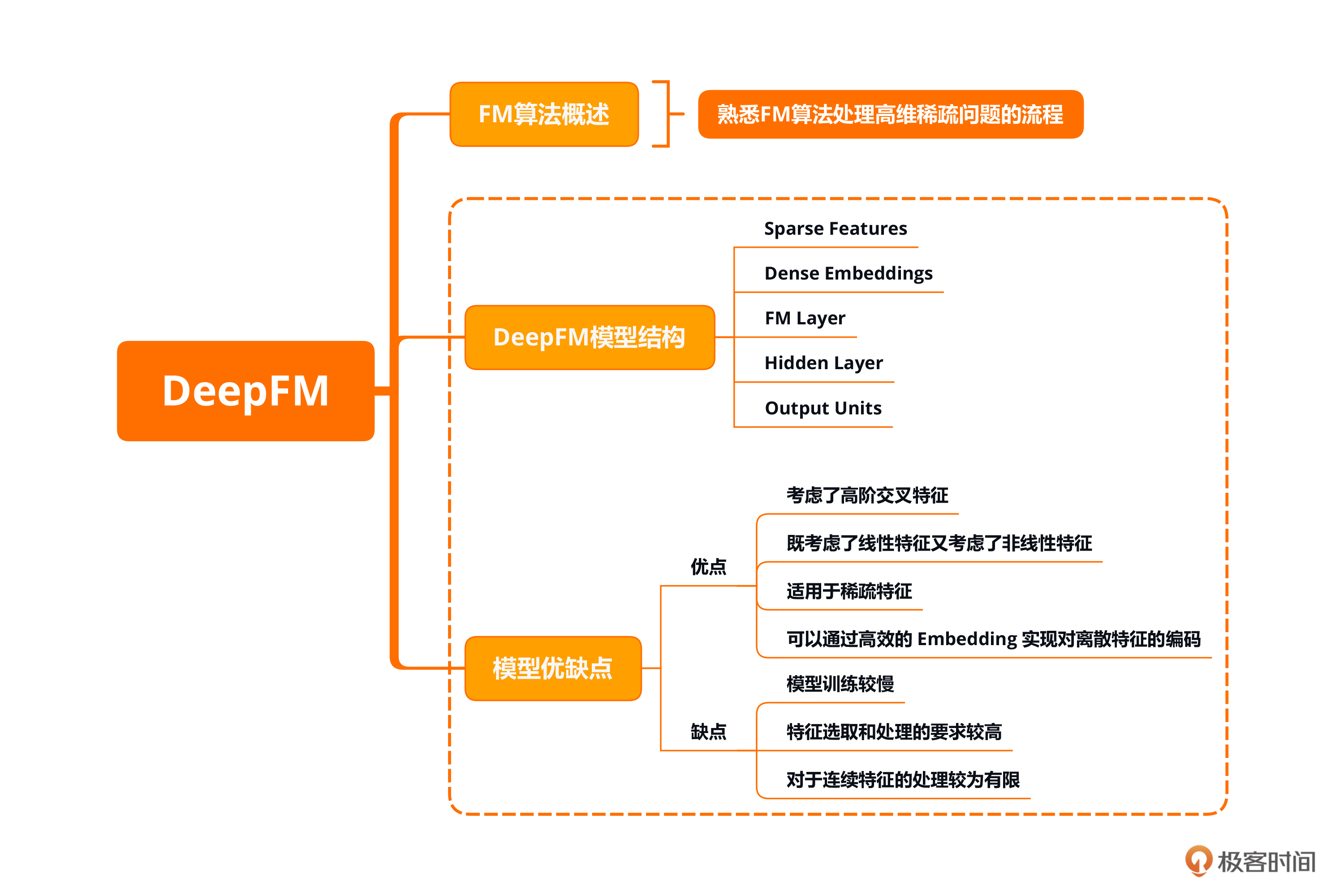
本节课的重点在了解FM算法的概念并掌握DeepFM模型的结构。DeepFM模型一共分为了Sparse Features、Dense Embeddings、FM Layer、Hidden Layer以及Output Units五个层,你应该熟悉每层的作用。
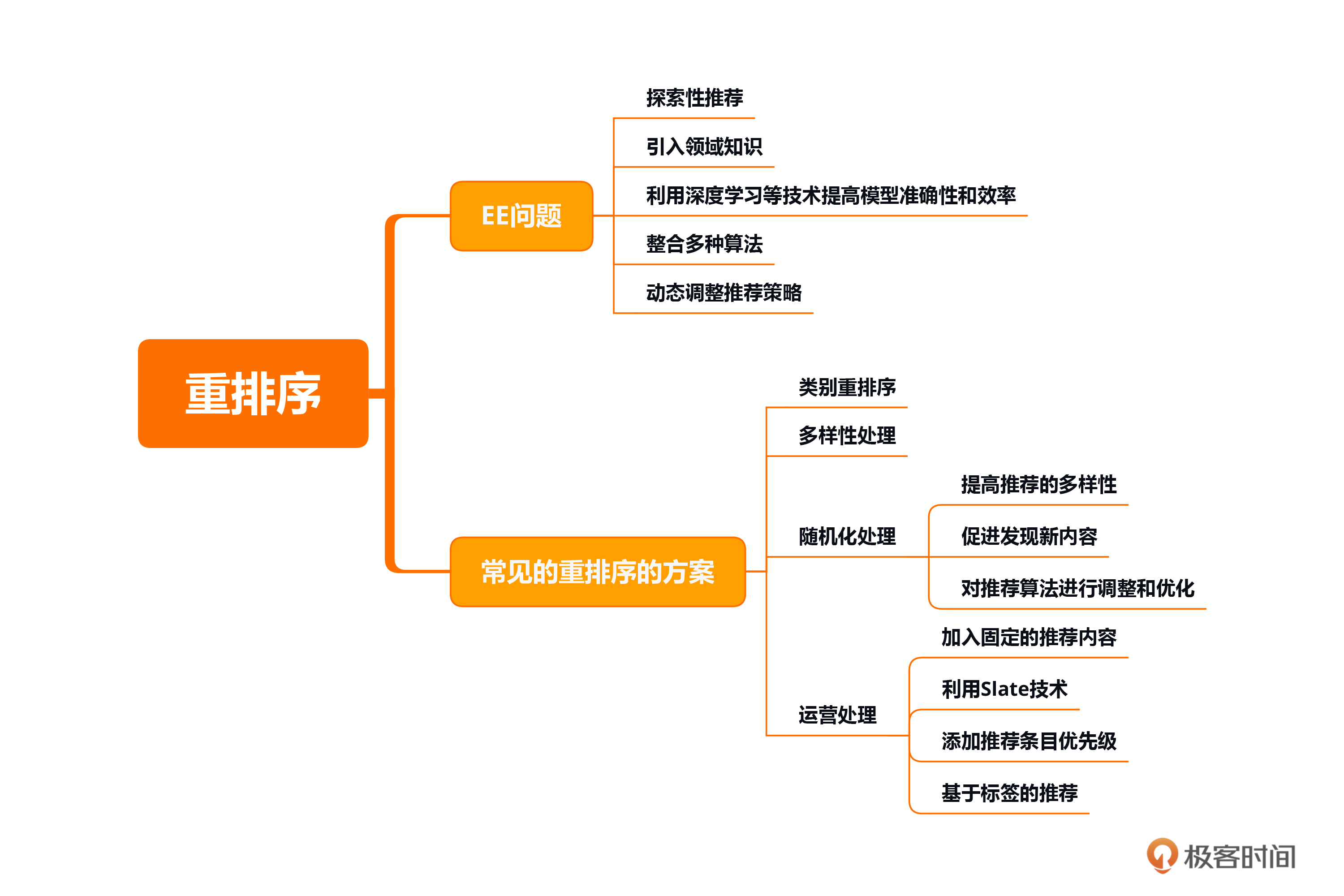
本节课的重点在于了解推荐系统中的重排序和排序后处理的概念及作用,注意EE问题的解决方案思路。常见的重排序方案一般有类别的重排序、多样性处理、随机化处理、运营处理等,你需要熟悉它们各自的操作流程和注意事项。
27|部署:如何在Linux上配合定时任务部署推荐系统服务?
本节课重点在于对Linux有一个整体的认知,其中Crontab命令是一种用于定期执行某项任务的命令。在它的命令中第一个星号表示分钟,第二个星号表示小时,第三个星号表示日,第四个星号表示月,而第五个星号表示星期。同时你需要熟悉在一个推荐系统中哪部分需要定时任务,以及如何去设置它。
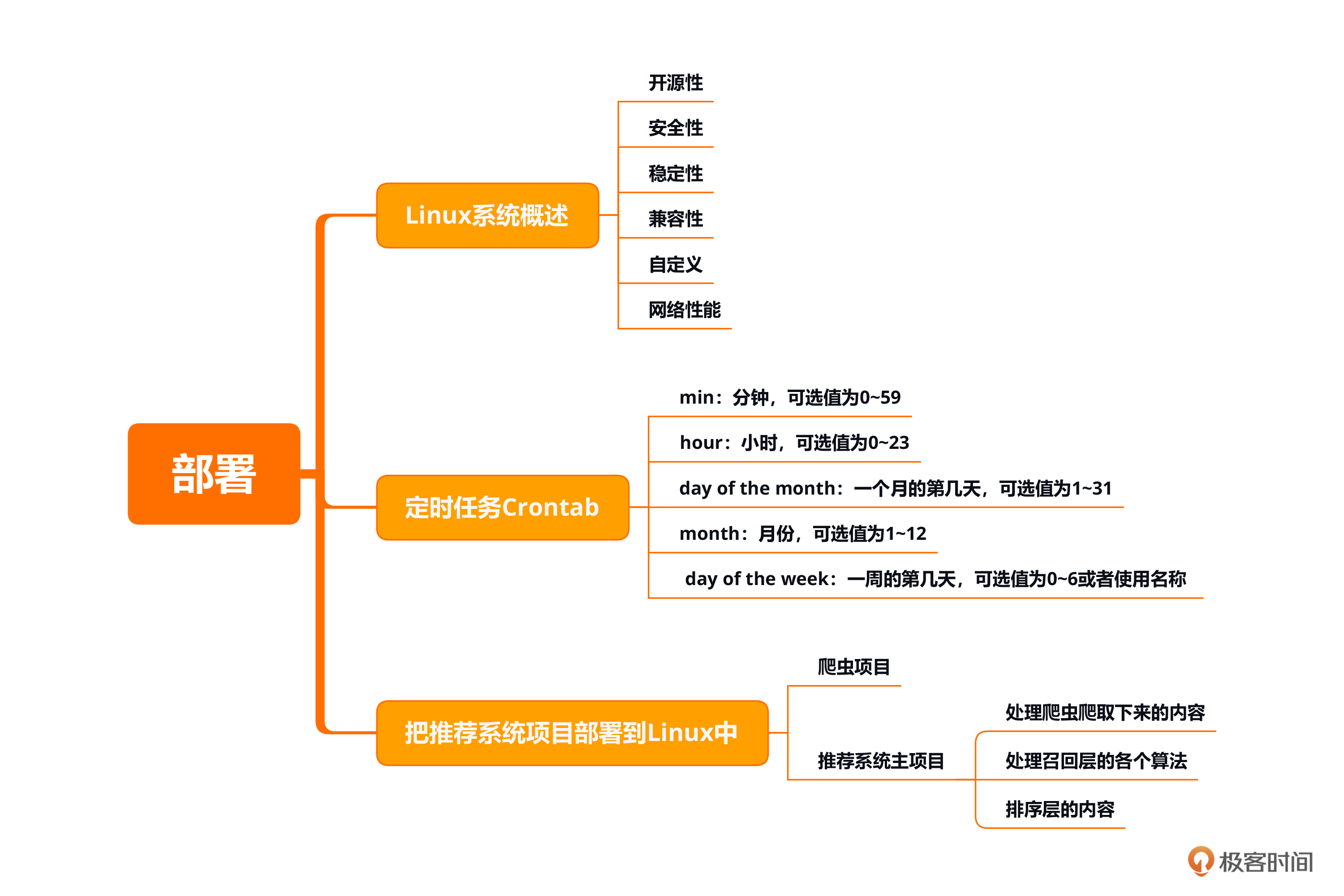
本节课的重点在于掌握Kafka在推荐系统中的用法,并能够在Service项目中引入Kafka进行消费和数据处理。Kafka的5个核心组件分别是Producer、Broker、Consumer、Partition和Topic,你需要熟悉各个组件的作用。
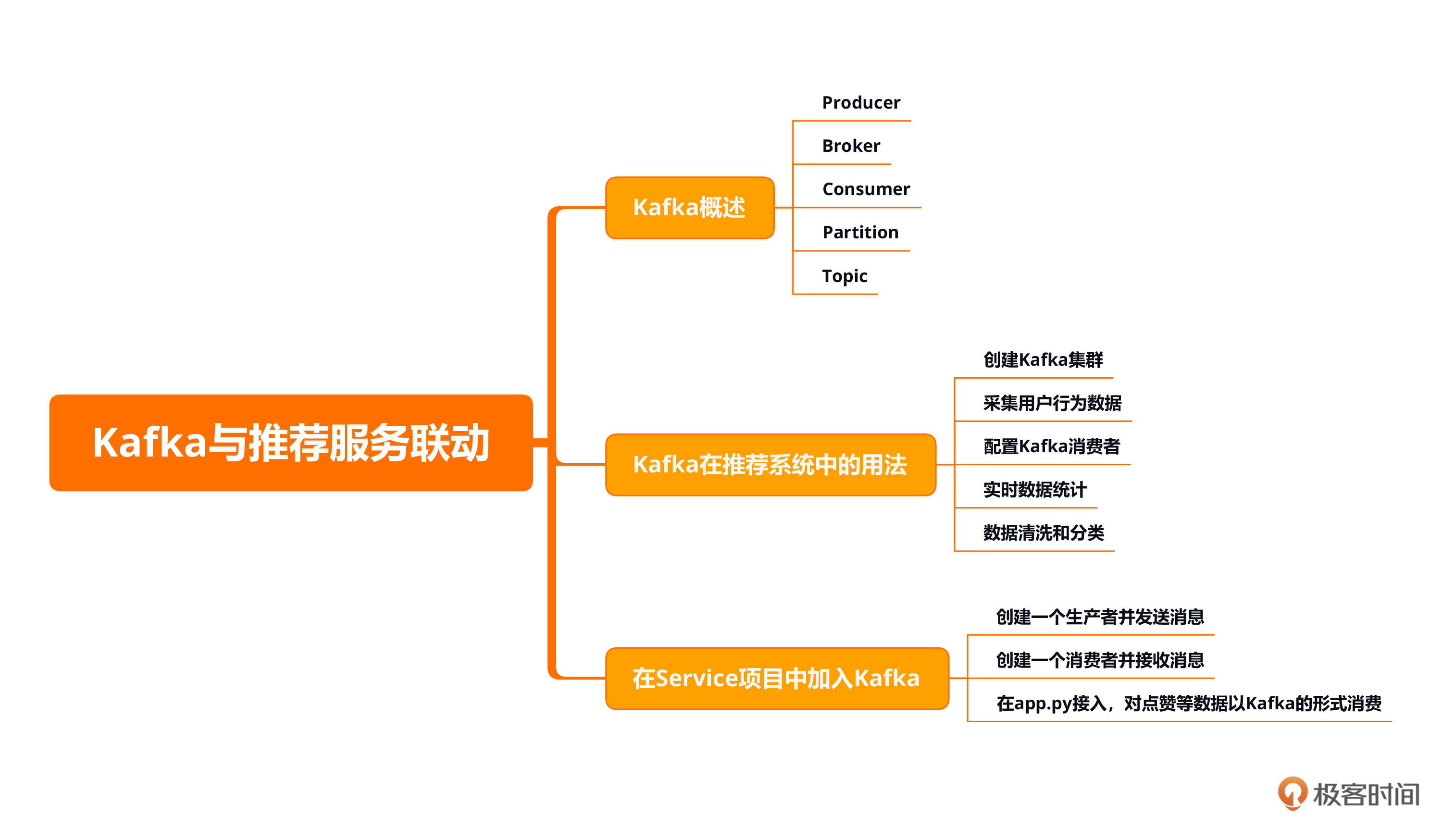
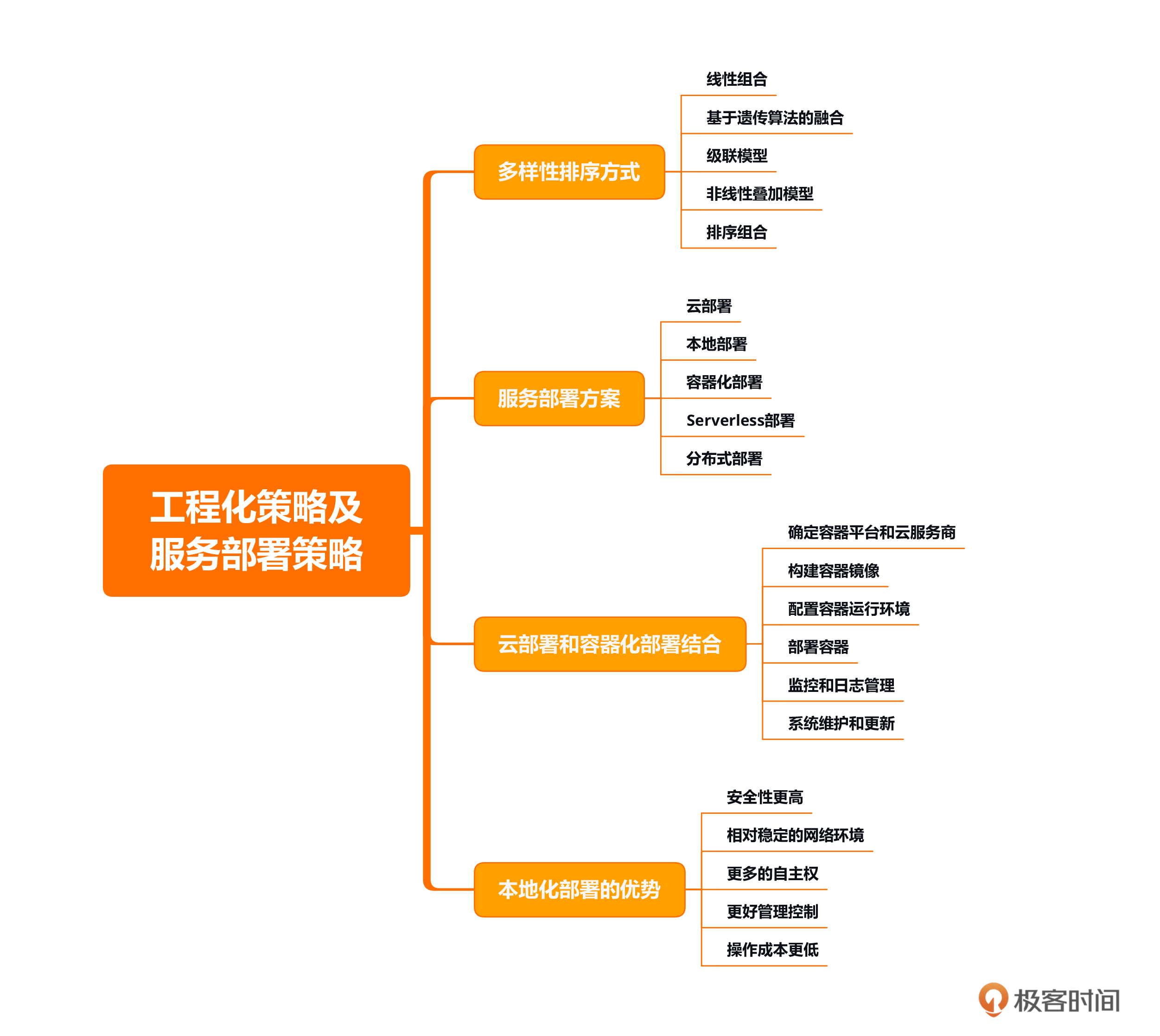
本节课的重点在于学习推荐列表的组成策略,一个企业级的推荐系统列表是由运营推荐位+多样性排序算法位+最新内容位组成。推荐系统的部署方案有云部署、本地化部署、容器化部署、Serverless部署、分布式部署等等,一般情况下我们会采用多种部署方案结合的方式进行推荐系统部署。
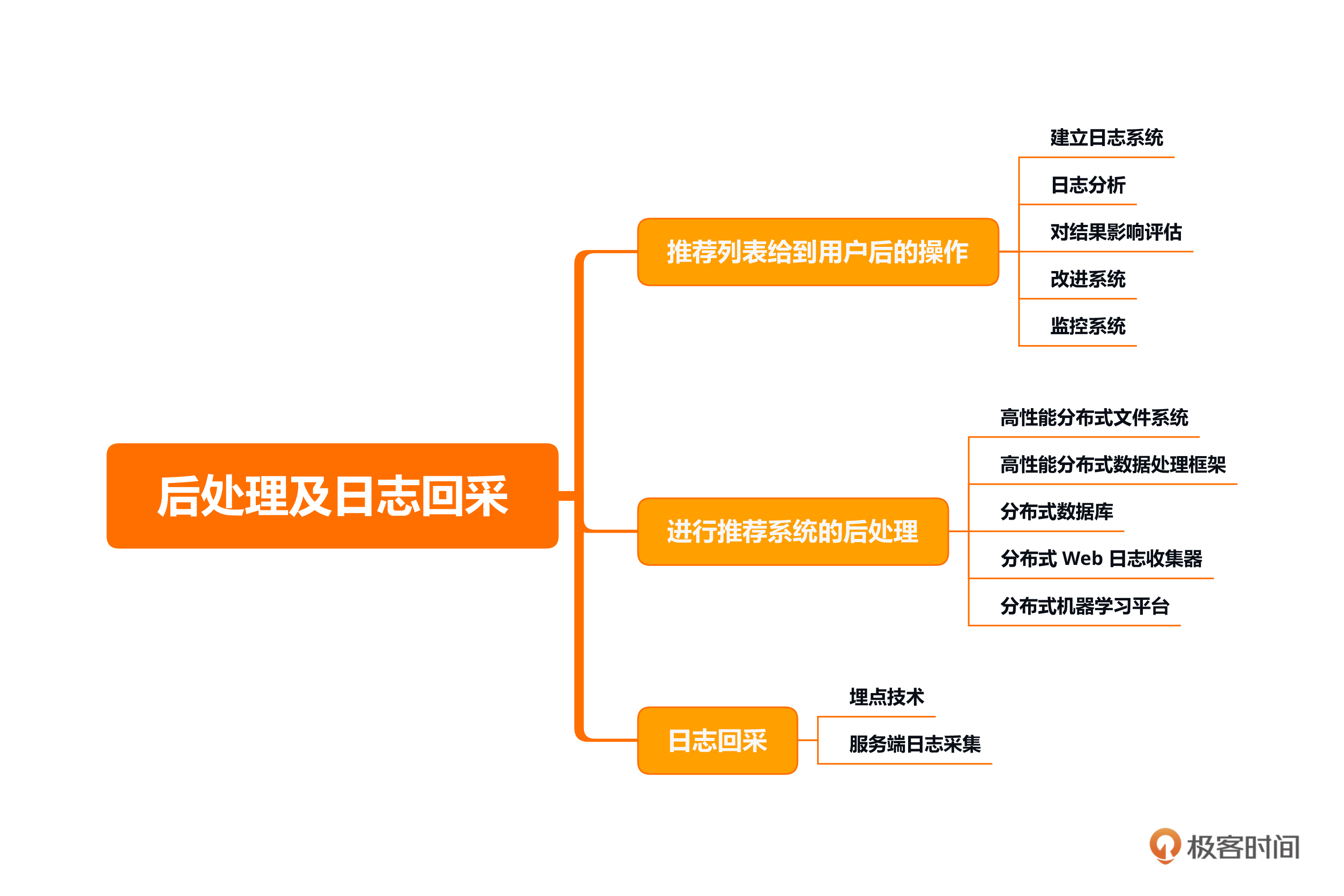
本节课重点在于掌握推荐列表给到用户后的操作,知道如何进行推荐系统的后处理以及如何进行日志回采。具体来说,推荐系统后处理主要包括用户反馈、用户行为收集、日志分析、改进系统、监控系统等。进行日志采集时,主要使用的方法是埋点技术和服务端日志采集。
到这里,我们的三节知识回顾课程也就结束了,如果你觉得这节课对你有帮助,欢迎分享给有需要的朋友!
- 19984598515 👍(0) 💬(2)
源码呢老师
2023-06-30