07 数据获取:什么是Scrapy框架?
你好,我是黄鸿波。
上一节课我们讲解了什么是爬虫以及爬虫的基本原理,从这节课开始,我们就要实际地去爬取一些网络上的内容,为后续推荐系统的使用做准备。
这节课我们来深入了解一下Python中的常见爬虫框架:Scrapy框架。我们将学习什么是Scrapy框架、它的特点是什么以及如何安装和使用它。
Scrapy框架概览
Scrapy是一个适用于Python的快速、高层次的屏幕抓取和Web抓取框架,用于抓取Web站点并从页面中提取结构化的数据。它也提供了多种类型爬虫的基类,如BaseSpider、Sitemap爬虫等。我们可以很方便地通过 Scrapy 框架实现一个爬虫程序,抓取指定网站的内容或图片。

下面是Scrapy框架的架构图。
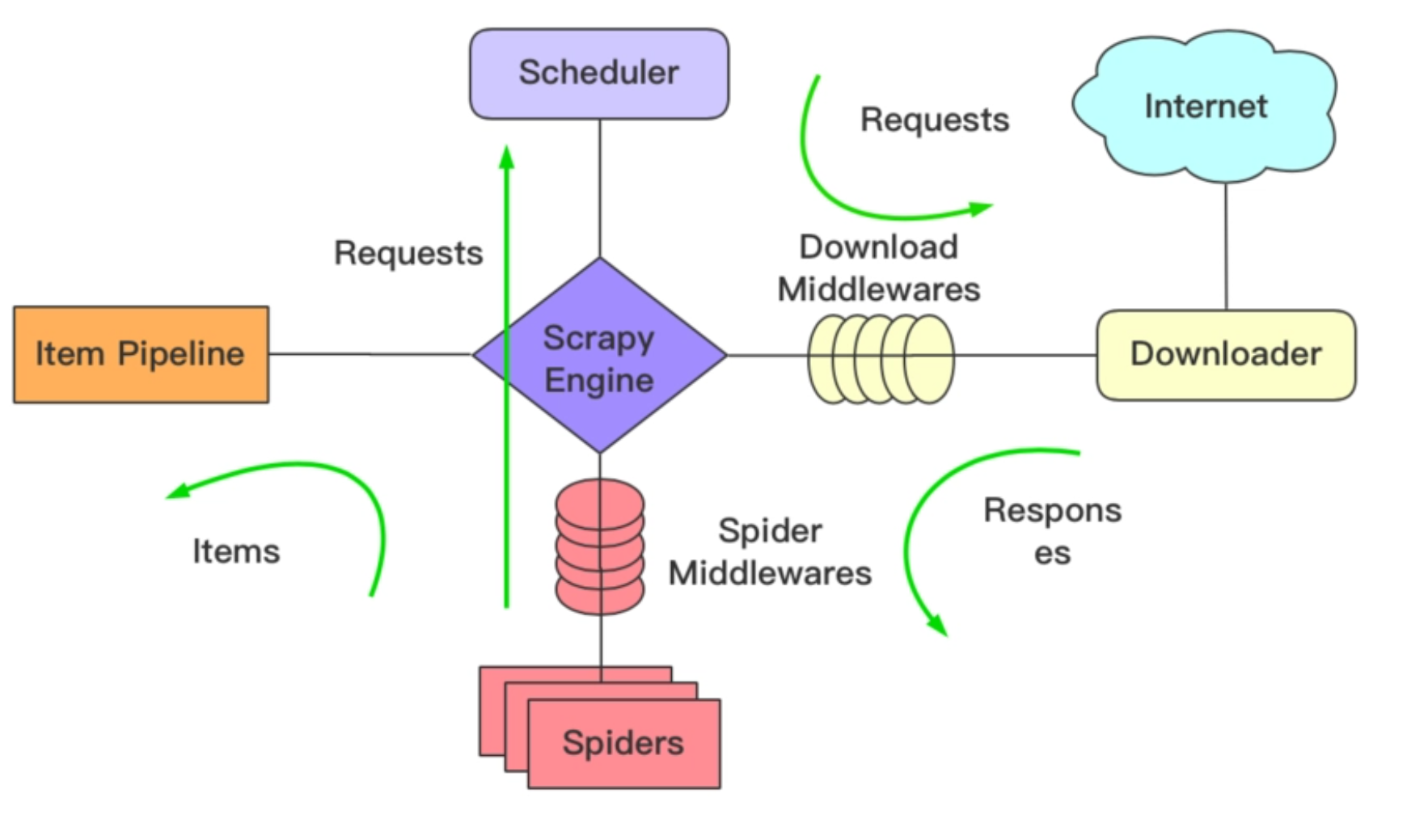
通过这张图我们可以看到,Scrapy框架总共分成了下面七个部分。
- Scrapy Engine(Scrapy引擎)。
- Scheduler(调度器)。
- Downloader(下载器)。
- Spiders(爬虫)。
- Item Pipline(管道)。
- Downloader Middlewares(下载中间件)。
- Spider Middlewares(Spider中间件)。
接下来,我们来看看这七个部分的具体含义,以及它们是如何协作的。
Scrapy Engine:Scrapy引擎是整个Scrapy框架的核心,负责所有子模块间的调度、通信和数据传递等,我们可以把它看作整个Scrapy框架的总指挥。
Spider:它负责处理所有的responses。也就是说,当爬虫程序获取到服务器端的response响应之后,接下来就会交由Spider去处理,它会根据需求提取数据和相应的URL信息,并交给引擎。值得注意的是,Spider模块虽然是Scrapy框架自带的模块,但是它仍然需要开发者自己手写代码实现。
Scheduler:调度器负责接收引擎发送过来的requests请求,并将它们放入到队列当中,在后续引擎有需要的时候再将请求返回给引擎。我们可以理解为下一步要抓取的网址由它决定,同时,在调度器里还会自动去掉重复的网址。
Downloader:下载器主要负责下载Scrapy Engine发送过来的所有requests请求,并将获取到的responses信息经 Scrapy Engine 返回给Spider处理。
Item Pipeline:管道,主要负责处理Spider中获取到的item并进行后期处理,比如对数据进行分析、过滤、存储等。
Downloader Middlewares:下载中间件,开发者可以在这里自定义扩展下载功能的组件。
Spider Middlewares:Spider中间件,可以自定义request请求和进行response过滤的组件。
了解了这七个组件的功能之后,我们来看看各组件的工作流程。在上面这张图中,我们可以看到核心的位置是引擎。也就是说基本所有的流程都和引擎相关,借助Scrapy框架爬取信息大致可以分为下面六步。
- 爬虫程序工作的时候会经由引擎向Spider提出申请,索要第一个待爬取的URL。待引擎拿到URL之后,就将这个URL传入调度程序Scheduler。
- Scheduler会将需要下载的URL加入到队列中,形成一个URL队列。当Scheduler完成请求后,会取出队列中的第一个URL,将其返回给引擎。
- 引擎拿到URL之后,会将这个URL经由Downloader Middlewares交给Downloader。完成下载后,我们会得到服务端返回来的response对象。
- 当Downloader拿到了response对象之后,接下来要做的就是把它交给引擎,然后引擎再经由Spider Middlewares将response结果交给Spider文件。
- Spider文件处理和分析response的结果,在此基础上拿到我们想要的数据,这里一般要做的就是标签解析、内容提取等工作。
- 解析完数据之后,我们要把这些数据经由Item Pipeline存储起来。无论是存文件还是存数据库,理论上都是由这一个组件来完成。
完成上面六个步骤之后,我们的第一个链接爬虫工作就结束了。紧接着,我们会循环这个操作,直至拿到我们要爬取的所有文件为止(也就是直到URL列表空了),这时我们就完成了一整套爬虫工作。
Scrapy框架的安装和使用
了解了Scrapy框架的工作原理,我们就可以更好地安装和使用 Scrapy 。
Scrapy在Python中被当作一个库来使用,要想在Python中使用Scrapy,首先我们要安装Scrapy。而要在Python中安装各种各样的库,我推荐使用Anaconda来进行Python环境的管理。
安装Anaconda环境
Anaconda是一个开源的Python发行版本,它包括Conda、Python以及一大堆安装好的工具包,比如:Numpy、Pandas等。我们可以把Anaconda看作是一个常用的扩展库的集合,我们可以使用Anaconda很轻松地管理我们的扩展库,还可以使用Anaconda创建多个虚拟环境。每个虚拟环境都是独立的,我们可以在各个环境上分别安装独立的包。
Anaconda安装包的获取方式有很多,我们首先想到的肯定是从官网下载。不过,我个人建议从清华源下载,因为在国内访问清华源速度相对较快,下载起来比较容易。我们直接百度搜索Anaconda清华源,或者输入以下网址即可。
在这里,我们下载的版本为2022.05-Windows-x86_64。

下载完成之后,我们双击安装包进行安装。
然后一路点击Next,直到选择目录那一步,你可以根据习惯选择目录,然后点击Next,出现下面的界面。
这里我建议把两个复选框都选中,上面的复选框是说要把Anaconda3加入到系统的环境变量中,下面的选项大意是使用Anaconda3作为默认的Python3.9,然后点击Install。安装完成后,我们在命令控制台输入conda,如果出现以下界面,说明安装完成了。
接下来,我们要创建一个虚拟环境。因为我们这个虚拟环境主要是用来做爬虫的,所以我们可以创建一个名为scrapy_recommendation的虚拟环境,并指定我们使用的Python版本为3.7版本。具体做法是输入如下命令。
稍等片刻,会出现下面的界面。
我们输入Y,开始安装,安装结束后,会弹出如下提示。
但是这里要注意的是,它会告诉你如果要激活你的环境,需要输入conda activate scrapy_recommendation,但是实际上在Windows中,这样输入会产生报错。
这个应该属于Anaconda的一个小Bug,因为这实际上是在Linux和Mac环境下的命令,在Windows环境下,我们直接输入activate scrapy_recommendation即可。这个时候会有如下显示。

安装Scrapy环境
现在,我们的 Anaconda 环境就已经安装好了,下一步是安装Scrapy环境。实际上要在Anaconda环境中安装Scrapy很简单,只需要执行pip install scrapy即可。
等到出现如下界面时,安装就完成了。

我们可以通过 conda list 来查看我们已有的包。
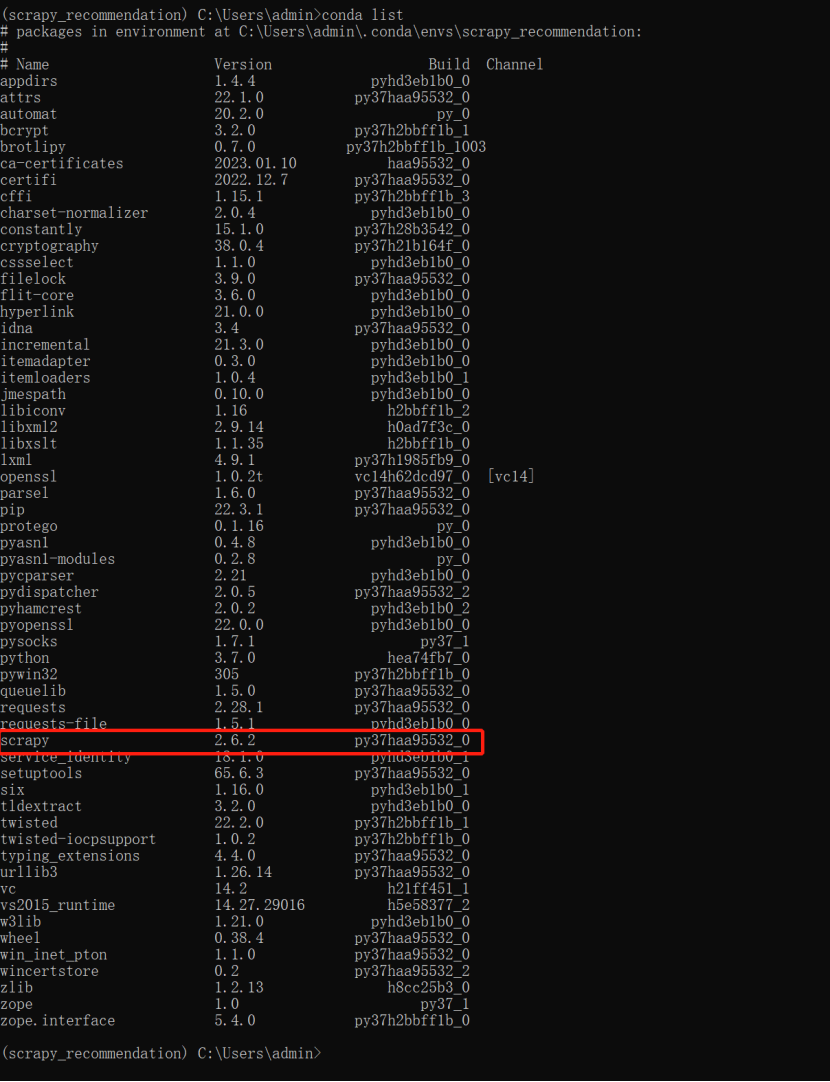
使用Scrapy创建爬虫开发环境
接下来,我们就尝试使用Scrapy创建一个爬虫开发环境。
首先,我们要确定好一个我们要搭建环境的目录,我选择了I盘的geekbang作为我要搭建环境的根目录。所以我首先要做的就是切换到这个目录下。具体做法是输入如下指令。
切换到指定目录下之后,我们就可以创建我们的Scrapy工程了。要注意的是,我们可以直接通过Scrapy的相关命令来创建爬虫工程。因为我们准备爬取新浪新闻里的新闻数据,把它作为我们后面推荐系统的原始数据。所以我们可以创建一个工程名为sina的爬虫项目,输入如下命令。
创建完成项目之后,会是下图的样子。

这个时候,我们进入到I:\geekbang目录下,会发现Scrapy帮我们创建了一个名为“sina”的目录。

我们进入到这个目录之后会发现,这个目录里,已经帮我们创建好了一个基础的Scrapy工程,如图所示。
接下来我们将项目导入到IDE环境中,然后在IDE环境里查看整体的目录结构。这里我选择了PyCharm作为我们后续所有开发的IDE。我们在PyCharm中依次点击File->open,弹出一个文件目录选择框,我们选择I:\geekbang\sina作为我们的项目根目录,如下图所示。
然后点击OK,导入我们的项目。
需要注意的是,这个时候,我们PyCharm的开发环境是默认的,我们需要将其切换到我们所创建的Anaconda的“scrapy_recommendation”环境下。
因此,我们要依次点击:
File->Settings->Project:sina->Python Interpreter,然后将Python Interpreter的目录选择为我们的Anaconda创建的scrapy_recommendation环境下的python.exe文件。然后点击OK,切换环境成功。
接下来,我们在主界面的左侧把所有的目录展开,我们来分别看一下Scrapy的各个目录以及它们的功能。
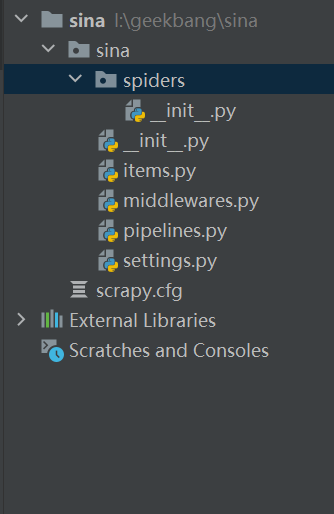
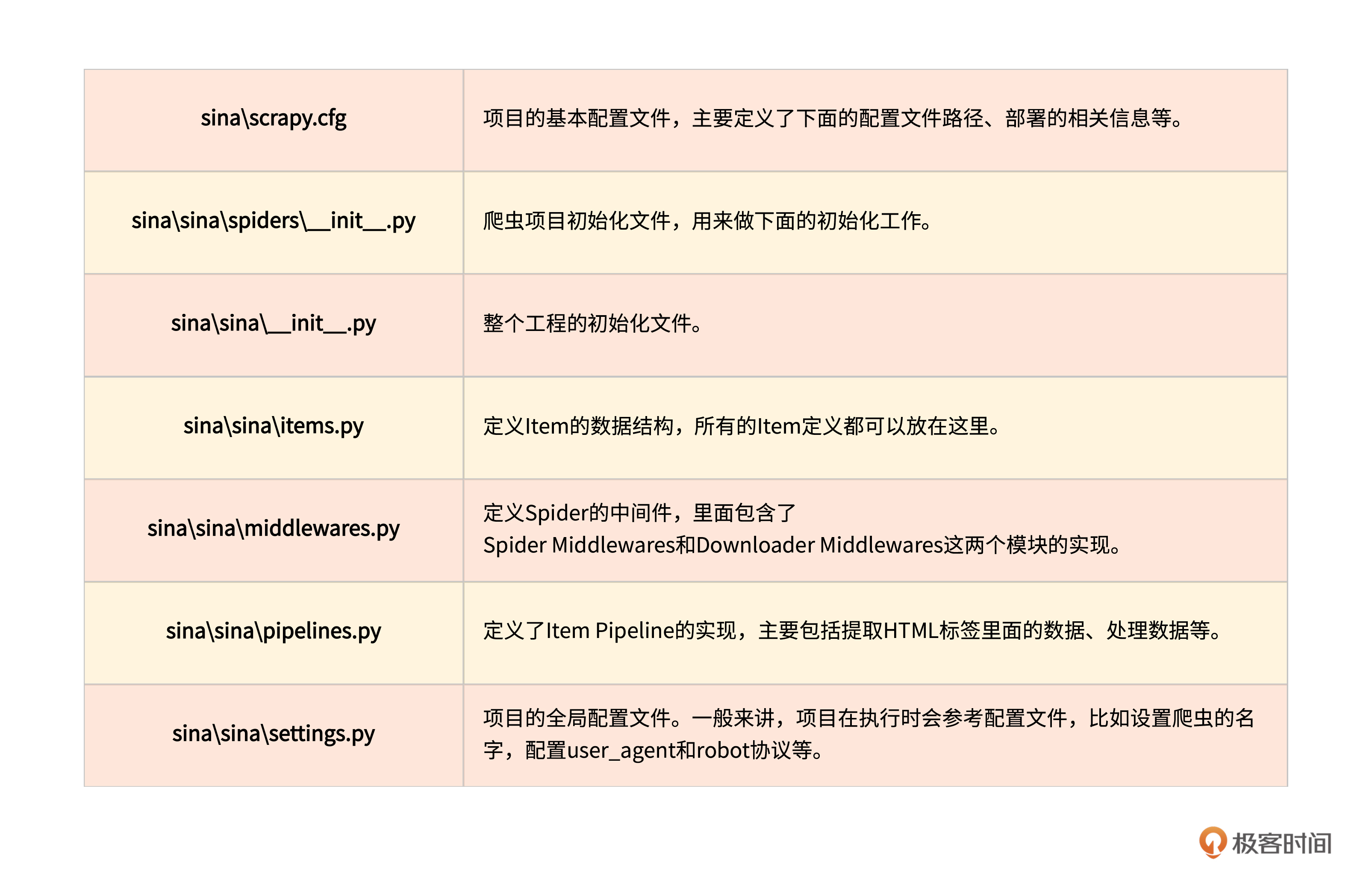
我们首先可以看到,在sina工程下面有一个同名的目录“sina”,和这个目录同一级的还有一个叫做scrapy.cfg的文件。你可以对照下面这个表格,看看这些文件的作用。
现在我们的 Scrapy 工程就创建完了。接下来我们再来创建一个爬虫程序,爬虫主要功能是爬取网站的数据。我们可以在I:\geekbang\sina目录下创建它,我们还是在cmd中切换到这个目录下,然后使用如下命令创建一个名为sina_spider的爬虫程序。
这时候命令行中显示如下。

然后我们切换到IDE中,会发现在sina\sina\spiders下面出现了一个名为sina_spider.py的文件,如图所示。
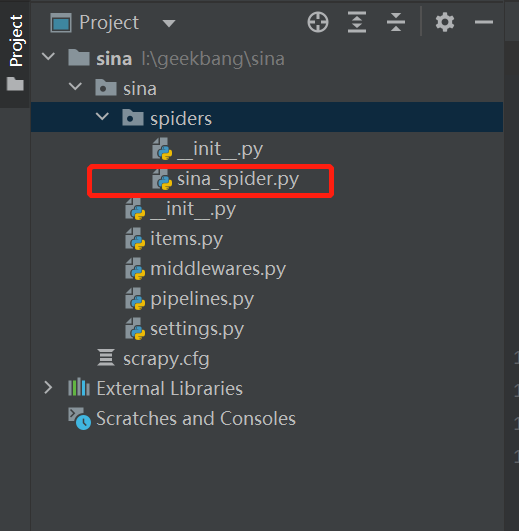
我们打开这个文件,如果出现如下代码,说明我们这个爬虫文件创建成功了。
import scrapy
class SinaSpiderSpider(scrapy.Spider):
name = 'sina_spider'
allowed_domains = ['sina.com.cn']
start_urls = ['http://sina.com.cn/']
def parse(self, response):
pass
进行到这里,一个基本的爬虫程序就创建完成了。但是现在离可以爬取数据还差一步,我们需要让我们的爬虫程序可以模拟人的操作来浏览网页。也就是说,我们要装一个插件来连接我们的Scrapy框架和浏览器界面,这里我推荐使用Chrome浏览器,我们需要下载的插件名称就是ChromeDriver,ChromeDriver插件的下载地址如下。
这个插件有很多版本,那我们是不是随便下载一个版本就可以了呢?当然不是,我们下载的版本一定要和Chrome浏览器的版本对应上。我们可以在Chrome浏览器中输入下面的命令进入设置界面。
这时候会弹出一个关于Chrome的界面,在这个界面里可以看到我们浏览器的版本。
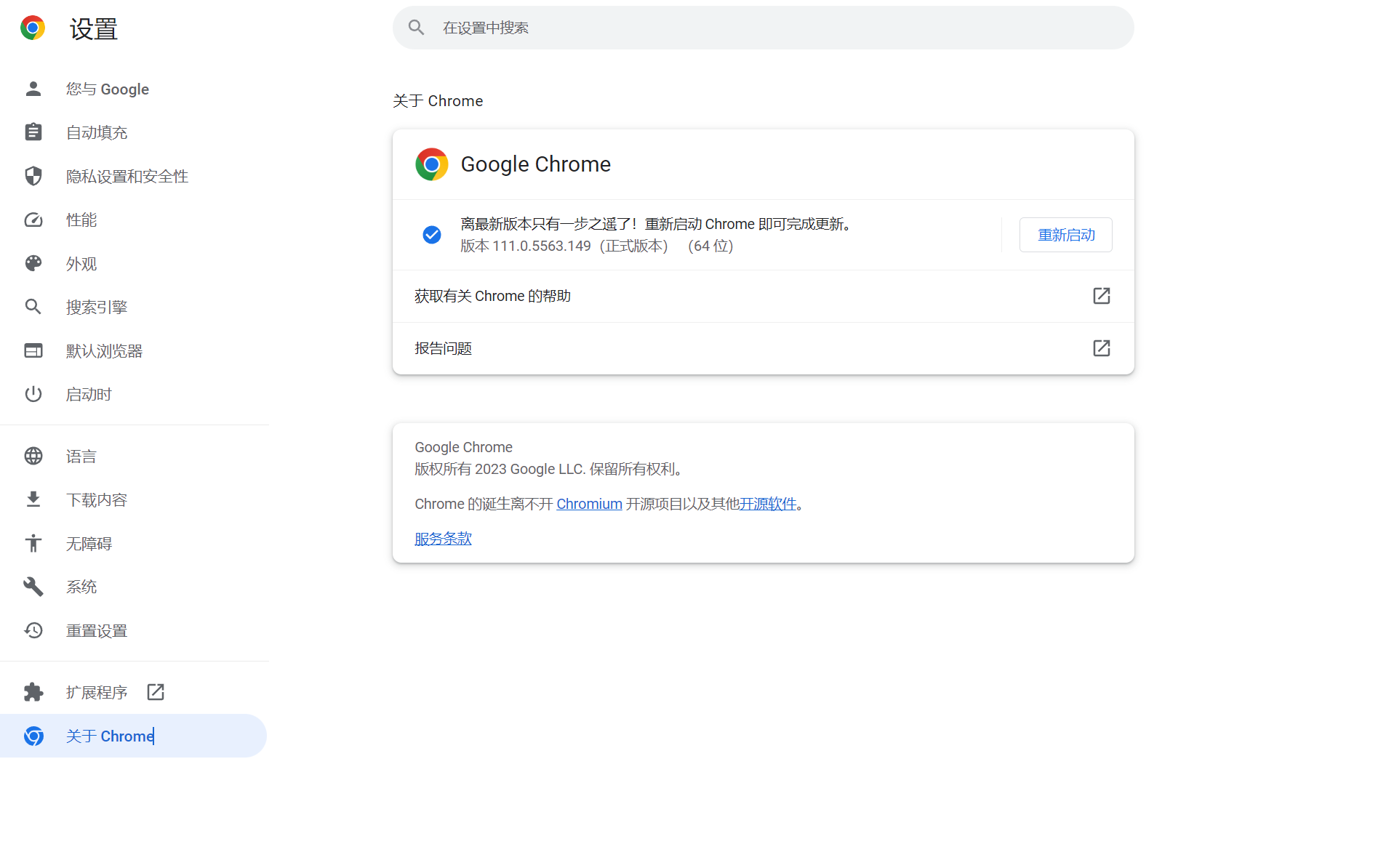
可以看到,我的版本为111.0.5563.149,所以我们回到ChromeDriver的下载界面找到110.0.5563版本进行下载,如果小版本找不到的话,就找前一个级别的版本中最后一个版本即可。
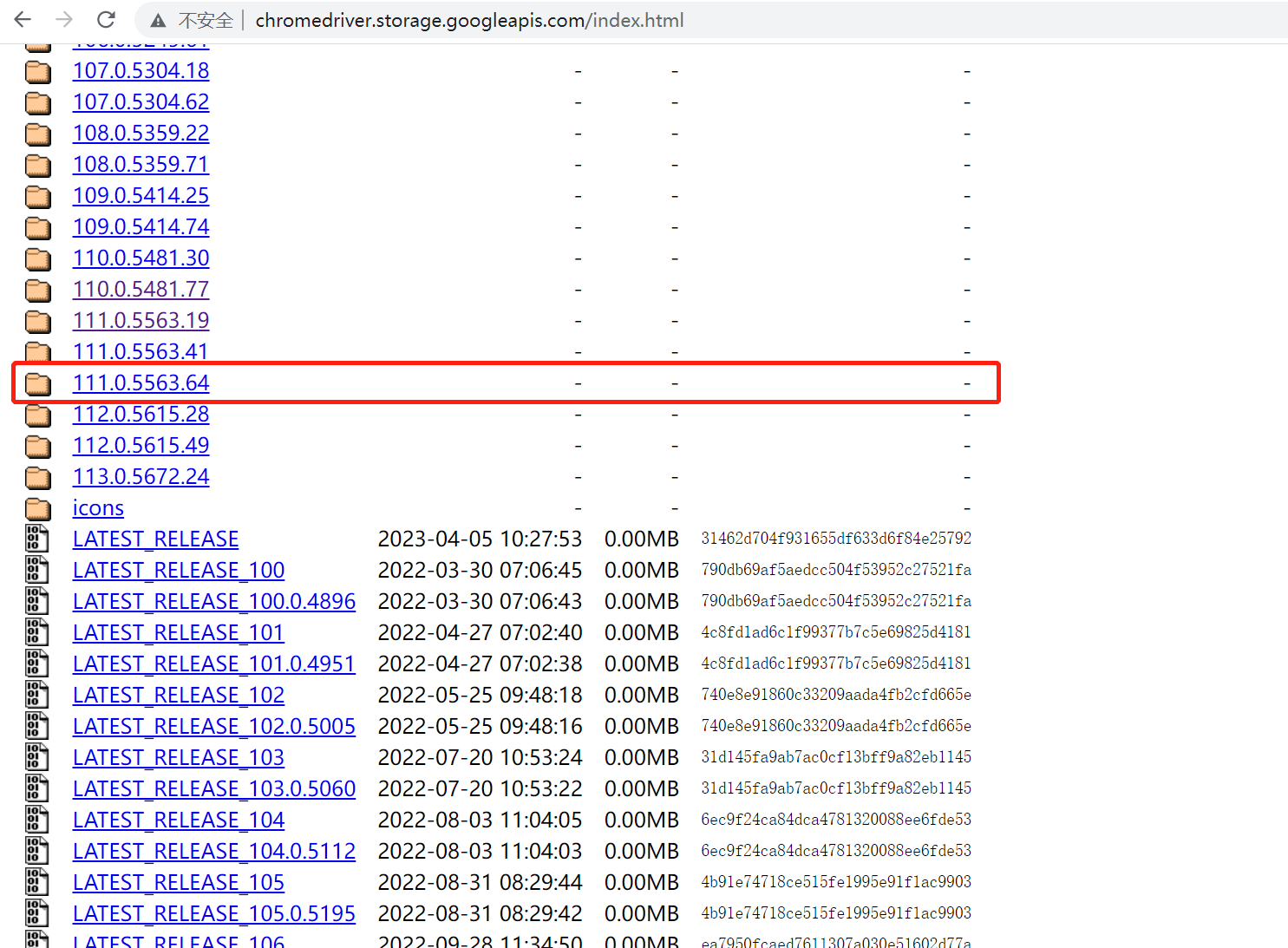
这里要注意的是,我们可能找不到完全一样的版本。如果遇到这种情况,找到上一级版本号一样的插件中的最后一个版本即可。我这里对应的是110.0.5563.64,点击下载。这里适配Windows的插件只有32位的版本,但它其实没什么影响,我们即使是64位的操作系统也可以使用,正常下载即可。
下载完成之后,解压会得到一个chromedriver.exe 的文件,要把这个文件分别复制到我们的Anaconda的scrapy_recommendation环境和Rhrome的浏览器中,如图所示。
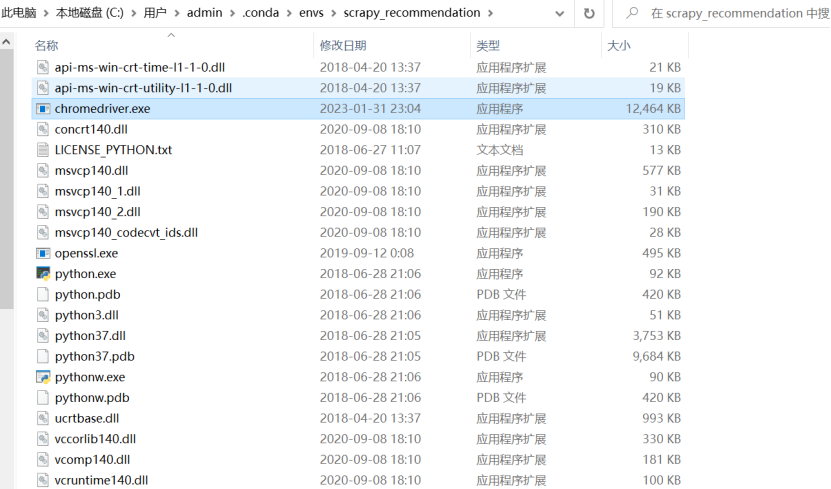
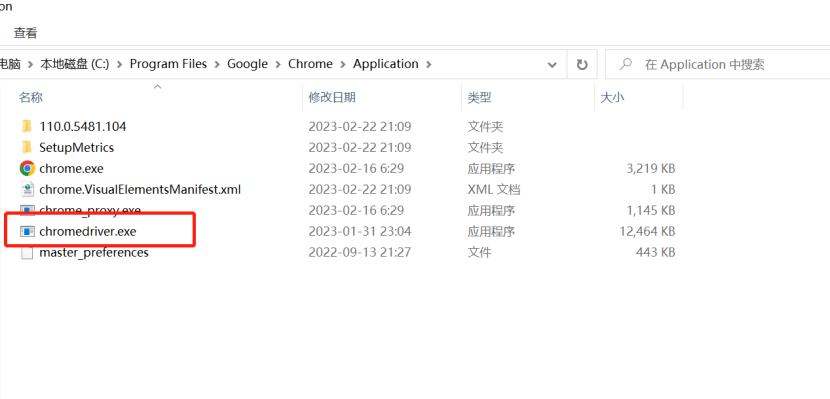
到这里,我们的ChromDriver插件就安装好了,只有安装好这个插件,我们在爬取数据的时候才能连接上浏览器。
我们知道,要运行一个程序就要写一个主文件。一般来说这个主文件是main.py文件,所以我们在项目的根目录下创建一个名为main.py的文件,然后输入如下代码。
简单解释一下这段程序。在这段程序里,我们首先从Scrapy的包里导入了cmdline这个库,然后使用cmdline.execute执行了scrapy crawl sina_spider。这里scrapy crawl是一个Scrapy的基础命令,表示启动爬虫程序,后面跟的是爬虫的名字。所以上面代码合起来的意思就是使用cmd命令启动名为“sina_spider”的爬虫程序。
如果出现如下界面,说明Scrapy的基础程序是正确的。
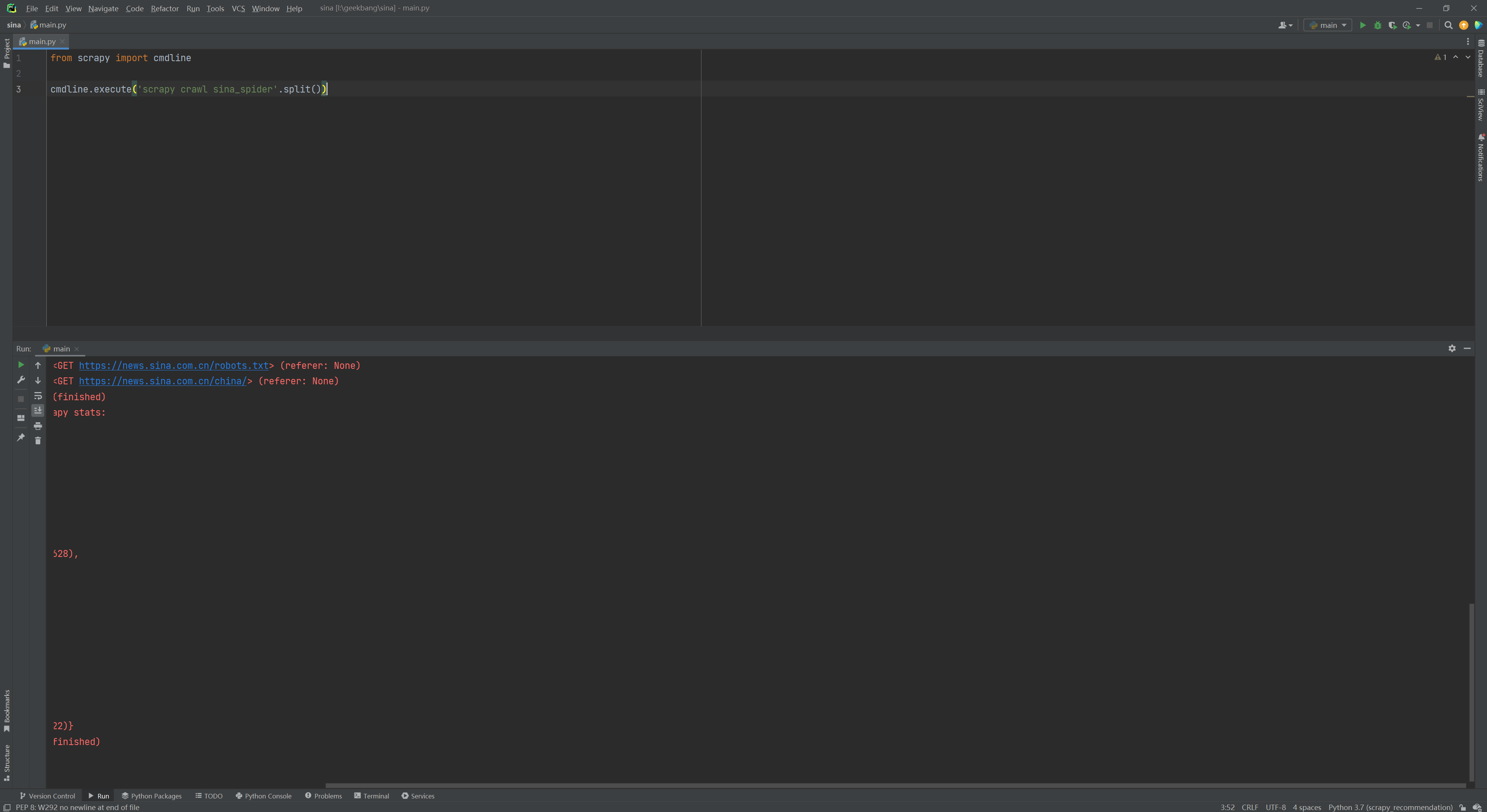
到这一步,虽然程序已经知道了要爬取的网站是sina.com.cn,现在运行也没有报错,但是似乎并没有什么结果,而且马上就关闭了。这是因为我们目前只是启动了这个爬虫程序,并没有写具体的爬虫代码,所以程序只是对sina.com.cn做了个链接,并返回了响应码200。接下来,我们就要开始正式踏上爬虫程序的编写之路了。
总结
我们来回顾一下本节课的主要知识点。
- Scrapy是一个适用于Python的快速、高层次的屏幕抓取和Web抓取框架,它可以抓取Web站点并从页面中提取结构化的数据。
- 你还应该知道Scrapy框架的原理和主要模块(Scrapy引擎、调度器、下载器、爬虫、管道、下载中间件、Spider中间件),以及它们是如何协作的。
- 最后,我们应该有能力在Anaconda环境中创建一个Scrapy环境,搭建一个最简单的Scrapy框架并把它跑起来。
课后题
学完这节课,给你留两道思考题。
- 请你自己尝试搭建一个Anaconda环境,并安装Scrapy框架相关的库。
- 请你创建一个Scrapy的框架程序并运行它。
欢迎你在留言区与我交流讨论,我们下节课再见。
- Geek_79da7f 👍(3) 💬(2)
关于安装ChromeDriver, mac上面一个命令行就解决了: brew install chromedriver
2023-09-18 - 地铁林黛玉 👍(1) 💬(4)
爬取的这些数据我们需要通过哪些方法知道是不是违法的呢?
2023-05-04 - 未来已来 👍(1) 💬(2)
遇到一个报错:Failure while parsing robots.txt. 解决:把 settings.py 文件的 `ROBOTSTXT_OBEY = True` 改为 `ROBOTSTXT_OBEY = False` 即可
2023-05-03 - peter 👍(1) 💬(3)
请教老师几个问题啊 Q1:网站后端是用Java开发的,可以用Scrapy来抓取数据吗?相当于两种语言的混合使用了。 Q2:Anaconda安装的最后一步提示是“python3.9”,为什么创建虚拟环境的时候python版本是3.7? Q3:安装的这个Anaconda,是正常的python开发环境吧。比如用来学习python,编码等。 Q4:conda list命令列出的scrapy,其build channel是py37XXX, 其中的37是python版本吗?
2023-04-24 - GhostGuest 👍(1) 💬(3)
更新建议改为一天一更,现在这节奏太慢了,前摇半天
2023-04-24 - Weitzenböck 👍(0) 💬(5)
我在执行main函数的时候出现了这个错误"UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc3 in position 93: invalid continuation byte",是不是https://sina.com.cn这个网站没有用utf-8的编码格式啊
2023-06-14 - 叶圣枫 👍(2) 💬(0)
我的macbook上会报这个错: urllib3 v2.0 only supports OpenSSL 1.1.1+, currently the 'ssl' module is compiled with 'OpenSSL 1.0.2u 20 Dec 2019 解决方案是降级urllib3: pip install urllib3==1.26.6
2024-01-12 - 悟尘 👍(2) 💬(0)
chrom 114 版本以上的 下载chromedriver在这里:https://registry.npmmirror.com/binary.html?path=chrome-for-testing/
2023-12-11 - 李 👍(0) 💬(0)
老师出现这个错误是什么原因
2024-02-18 - 悟尘 👍(0) 💬(1)
[scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://www.sina.com.cn/> from <GET https://sina.com.cn> [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.sina.com.cn/> (referer: None) 这算是连上了?
2023-12-11