08 数据获取:如何使用Scrapy框架爬取新闻数据?
你好,我是黄鸿波。
上一节课,我们对Scrapy框架有了一个整体的了解,也实际地安装了Scrapy库并搭建了一个基础的Scrapy工程。这节课,我们就继续在这个工程的基础上爬取新浪新闻中的数据,并对爬取到的数据进行解析。
使用Scrapy框架抓取数据
我们首先打开sina\sina\spider下面的sina_spider.py文件,在这个文件中,Scrapy框架给我们写了一个基础的框架代码。
import scrapy
class SinaSpiderSpider(scrapy.Spider):
name = 'sina_spider'
allowed_domains = ['sina.com.cn']
start_urls = ['http://sina.com.cn/']
def parse(self, response):
pass
这段代码主要是对整个爬虫程序做了一个简单的定义,定义了爬虫的名字为“sina_spider”,爬取的域名为“sina.com.cn”,爬取的URL是“http://sina.com.cn/”。最后它还贴心地帮我们定义了一个解析函数,这个解析函数的入参就是服务器返回的response值。现在,我们要开始分析我们要爬取的内容,并对这个函数进行改写。
页面分析
我们先以网易的国内新闻为例来分析一下。我们先看下面这个界面。

我们要分析的是界面里最新新闻这个部分。可以看到这个新闻列表中一共包含了下面这几部分:标题、摘要、时间、关键词。我们还可以看到,时间在1小时之内的会显示为“XX分钟前”,在1小时以上的会显示今天具体的某个时间点。
接着我们把页面拉到最下面。
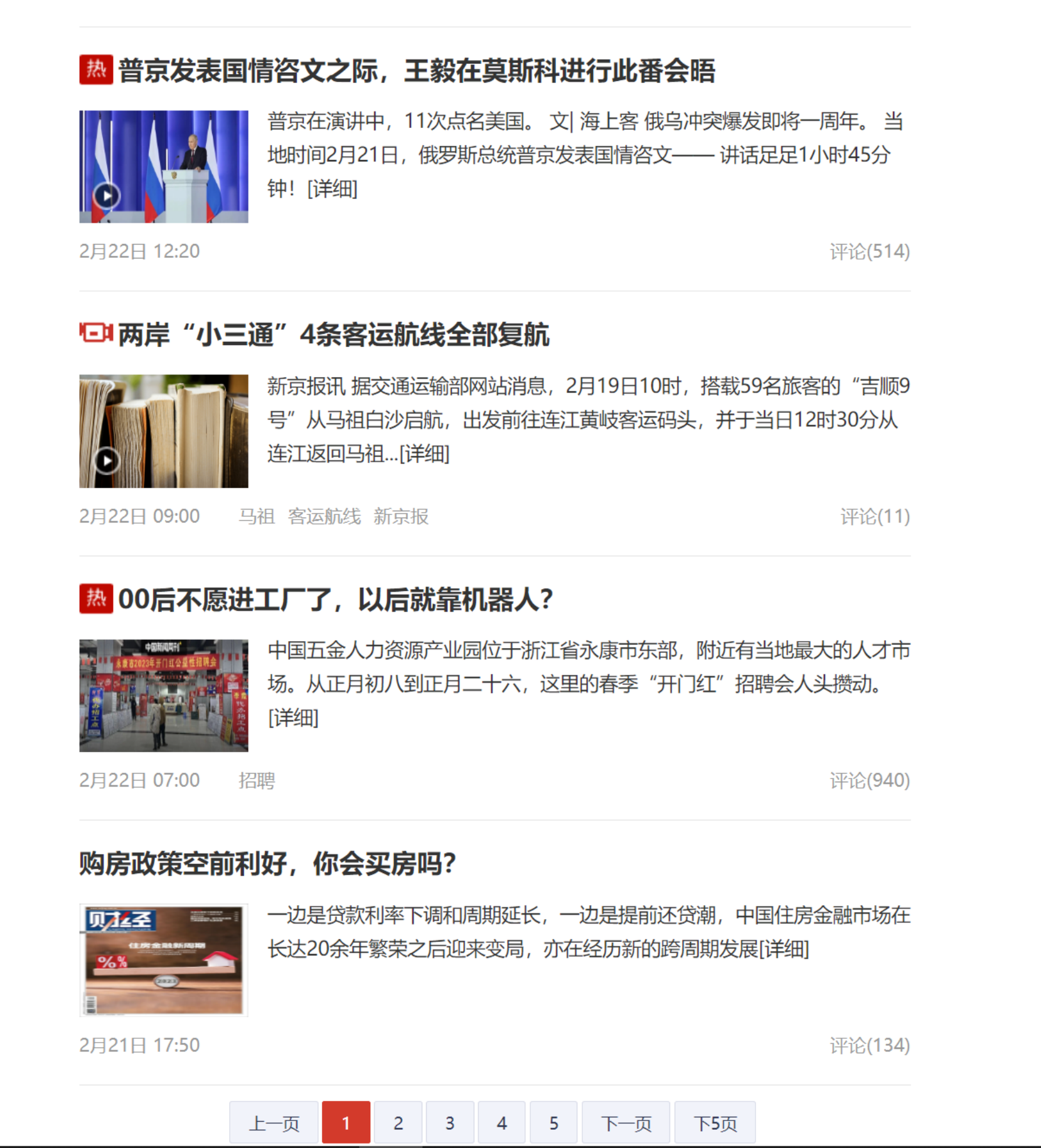
可以看到,今天之前的新闻会显示出具体的日期,并且最下面有一个导航条用来翻页。
我们随便点击一条新闻进入详情页看一下。可以看到里面包含了图片和文字,其中文字部分最上面有标题,下面有日期和时间,再下面是正文。当然,还充斥着广告和我们不需要的信息,这些我们暂时不用管。
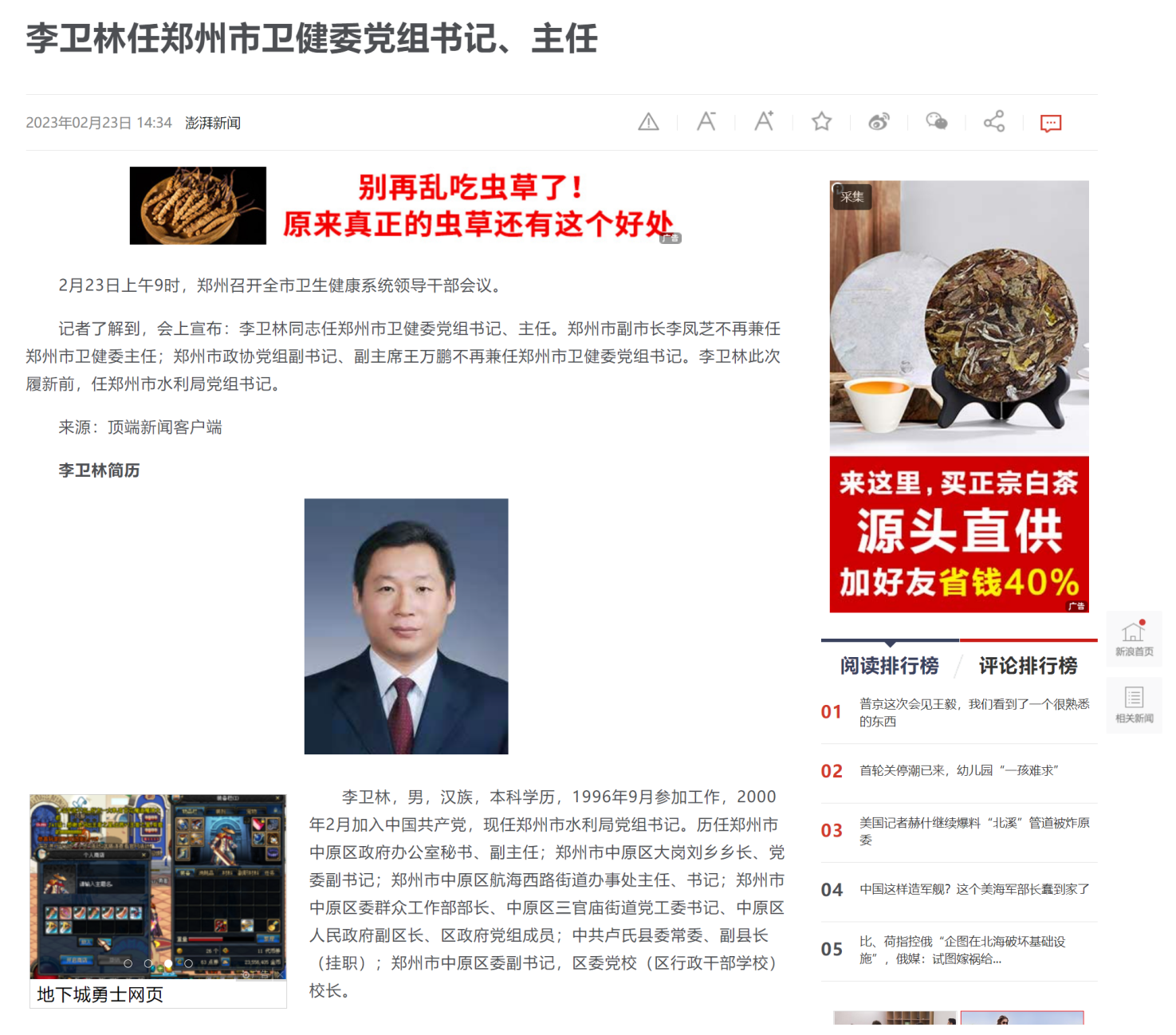
接下来我们分析一下前面的列表以及这个详情页的内容,抓取我们想要的信息。
我们知道,所有的页面从根本上来说都是由HTML页面构成的,爬虫想要爬取的内容就藏在这些HTML页面中。在Chrome浏览器中,我们按下键盘上的F12键就能够打开开发者工具模式。我们可以利用这个模式查看网页的HTML源文件、请求的信息文件以及网络返回等。我们选择上面的Element选项卡,就能看到网页的HTML源文件,如下图所示。
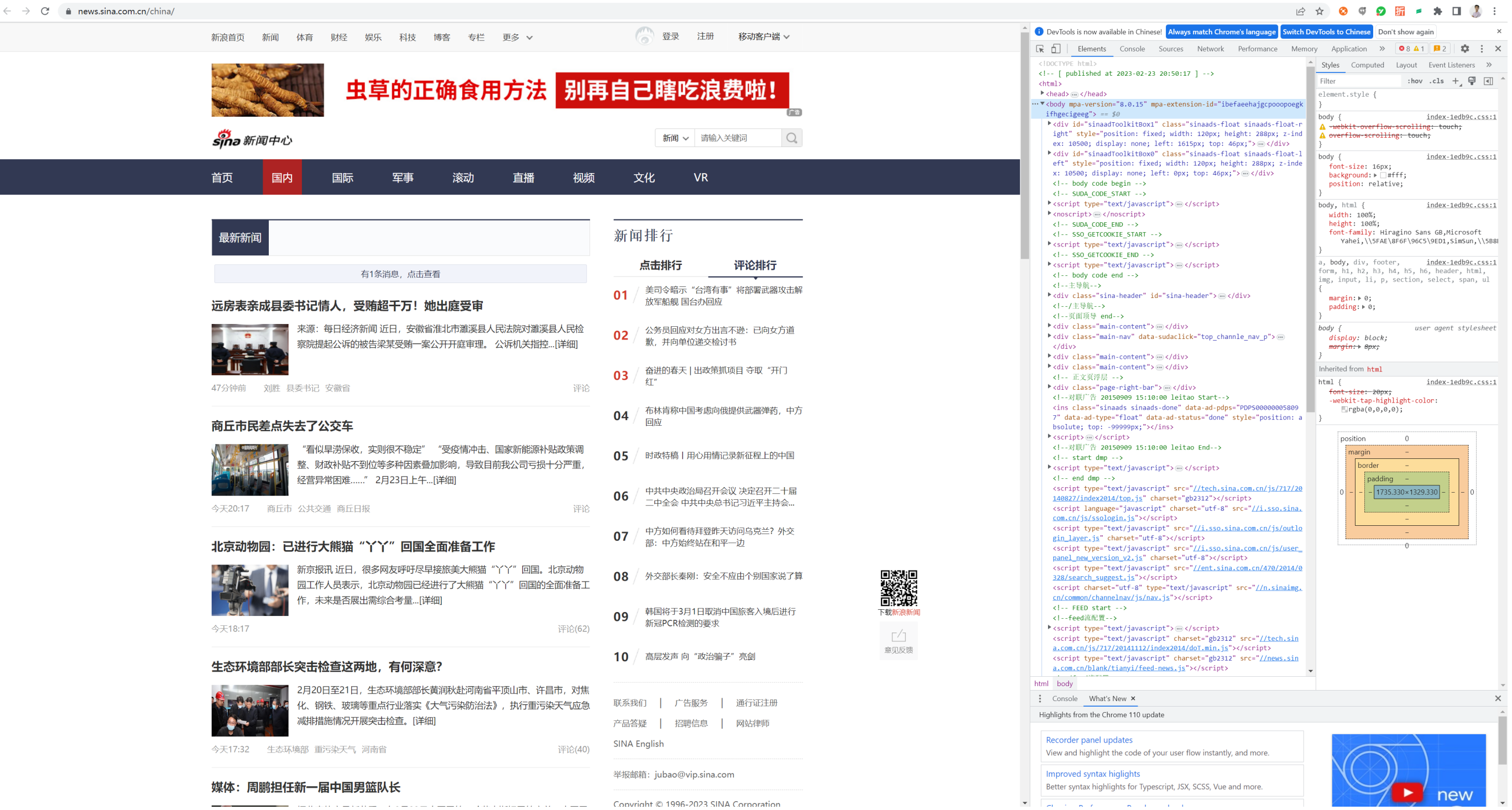
因为我们要找的是我们需要的列表,所以我们可以点击开发者工具左上角的小箭头,如下图所示。

然后用鼠标点击我们想要的列表,右侧的HTML代码就会跟着跳转到相应的部分。
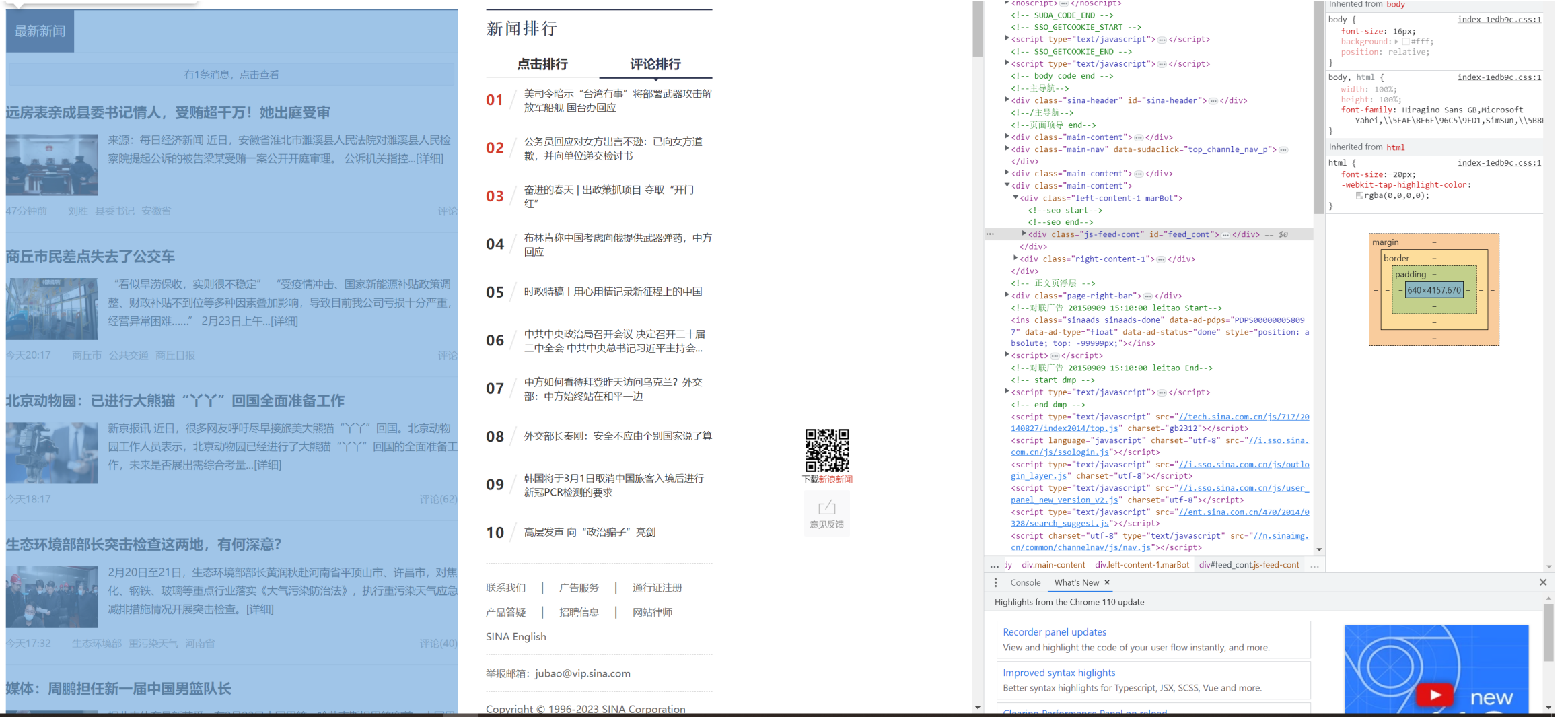
那么这个时候,我们需要找到这里面的其中一条,然后查看右面的HTML源文件。
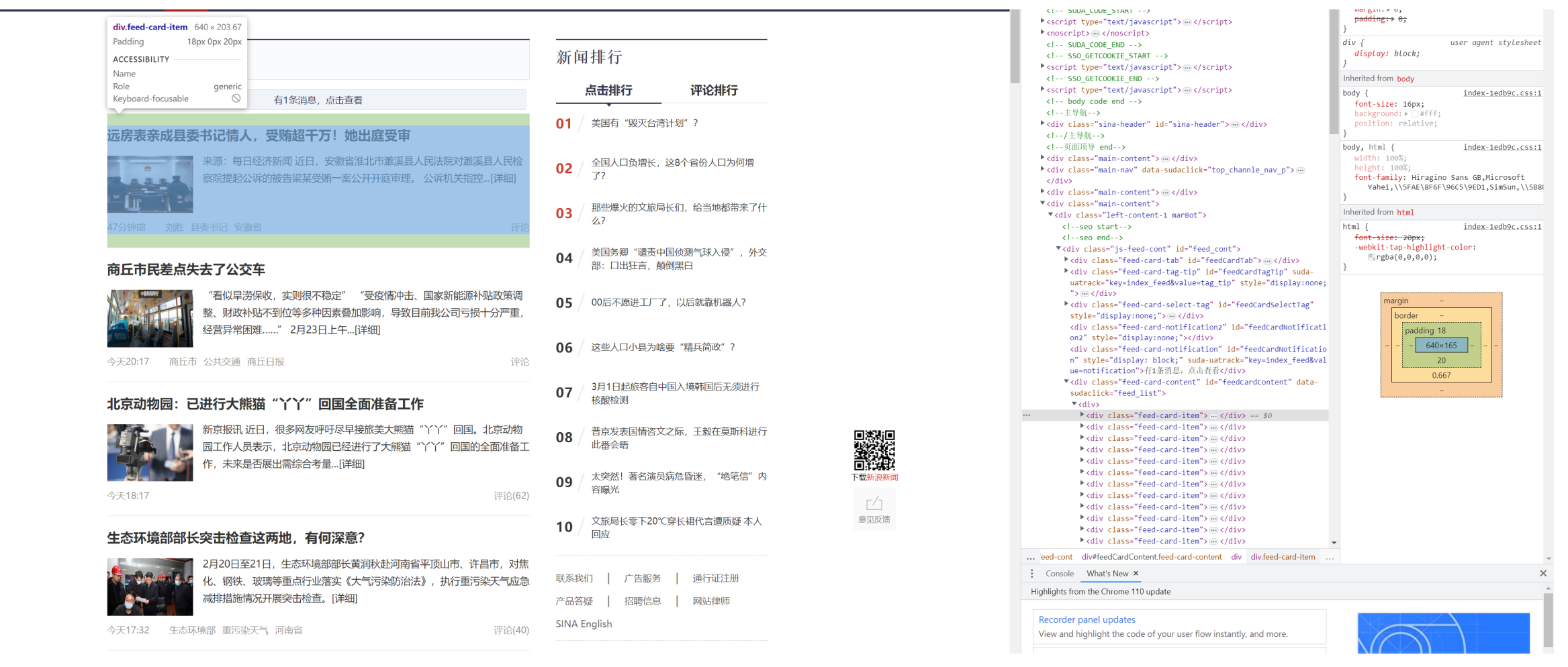
我们可以发现,实际上,在这个列表中,每一条内容都会被包含在class为“feed-card-item”的标签中,我们把这个标签展开来详细地分析一下。
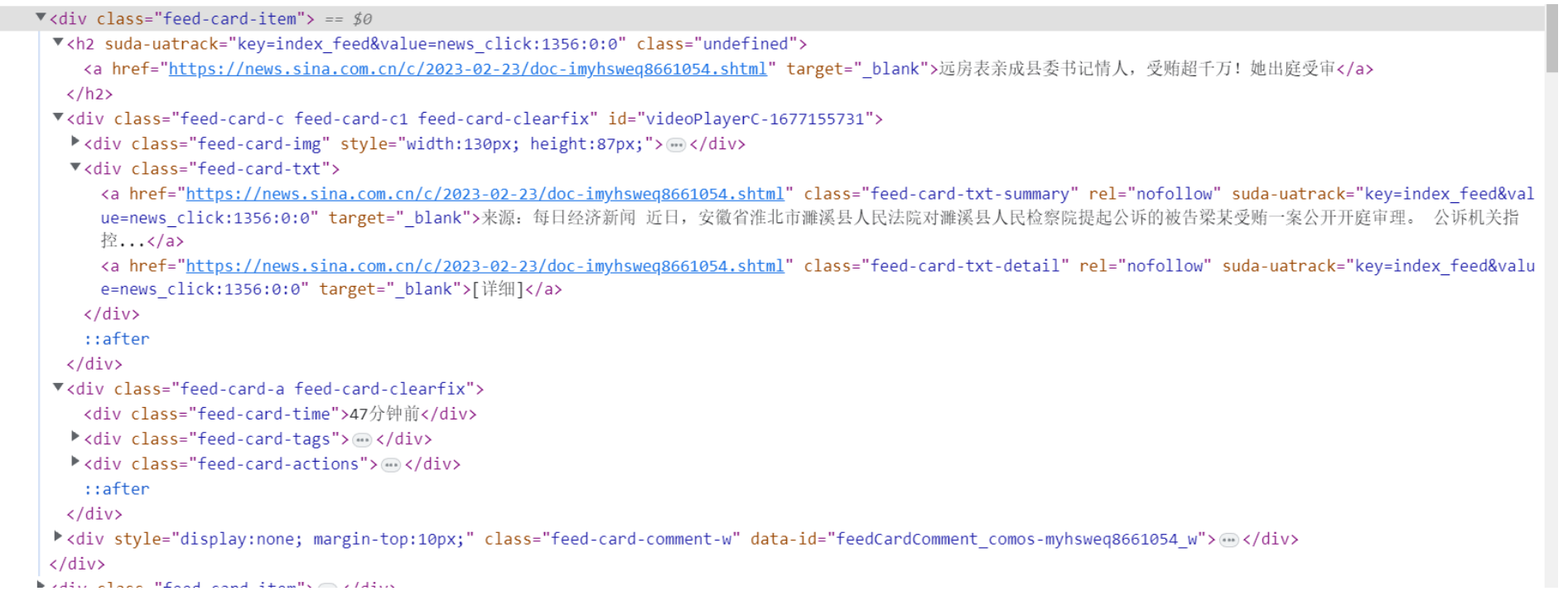
可以看到,标题被包含在h2标签里的a标签中,时间被包含在h2标签里class为feed-card-a feed-card-clearfix下面的feed-card-time中,然后这条内容的链接就是h2标签里的a标签的链接。
好了,知道了我们要的标题、时间以及对应的链接,接下来,我们就可以通过爬虫把它们拿下来了。
爬取列表
使用Scrapy拿标签,比较方便的一种方法是使用Selenium库。
Selenium是一个用于测试Web应用程序的工具,Selenium测试可以直接运行在浏览器中,就像真正的用户在操作一样。也就是说,我们可以使用Selenium库来模拟点击、上滑和下滑等操作。
要想使用这个库,首先要在开发环境中安装它。安装方法也比较简单,直接在我们的Anaconda环境中使用pip安装就好。具体做法是切换到scrapy_recommendation环境中,执行下面的命令。
安装完成后如图所示。
接下来我们就可以使用Selenium来进行浏览器页面访问工作了,我们把上面的代码改写如下。
import scrapy
from scrapy.http import Request
from selenium import webdriver
class SinaSpiderSpider(scrapy.Spider):
name = 'sina_spider'
def __init__(self):
self.start_urls = ['https://news.sina.com.cn/china/']
self.option = webdriver.ChromeOptions()
self.option.add_argument('no=sandbox')
self.option.add_argument('--blink-setting=imagesEnable=false')
def start_requests(self):
for url in self.start_urls:
yield Request(url=url, callback=self.parse)
def parse(self, response):
driver = webdriver.Chrome(chrome_options=self.option)
driver.set_page_load_timeout(30)
driver.get(response.url)
title = driver.find_elements_by_xpath("//h2[@class='undefined']/a[@target='_blank']")
time = driver.find_elements_by_xpath("//h2[@class='undefined']/../div[@class='feed-card-a "
"feed-card-clearfix']/div[@class='feed-card-time']")
for i in range(len(title)):
print(title[i].text)
print(time[i].text)
可以看到,这段代码相比上面那段代码有了非常大的改变。首先,在最上面,我们多导入了两个包。
这段代码第一行的意思是从Scrapy的http模块导入Request这个包,第二行的意思是从Selenium库导入Webdriver这个包。
Request包顾名思义,就是用来做HTTP请求。也就是说,我们在向网站服务器请求数据时,就是Request包在起作用。而Selenium下面的webdriver包是一组开源的API,用于自动化测试Web应用程序。在我们的程序中,主要是利用它来打开浏览器,以及设置打开时的一些信息。
接着,我们把这个class进行了重构,加入了__init__这个构造函数。我们可以先粗略地理解为,当我们运行这个Python文件时,就会先去执行__init__函数里面的内容。
我们将之前的start_urls加入到了__init__中,并在前面加上self。接着,我们定义了webdriver中关于Chrome浏览器的一些参数。
self.option = webdriver.ChromeOptions()
self.option.add_argument('no=sandbox')
self.option.add_argument('--blink-setting=imagesEnable=false')
我在这里加了两个参数,一个是“no=sandbox”,它表示取消沙盒模式,也就是说让它在root权限下执行。另一个参数是“–blink-setting=imagesEnable=false”,它表示不加载图片,因为我们只想要文字部分,加上这一句可以提升爬取速度和效率。
接下来,我们增加了一个start_requests()函数,这实际上也是Scrapy自带的函数,它的主要作用是定义Scrapy框架的起始请求,如果在这个起始请求中有重复的URL,它会自动进行去重操作。
然后在解析函数中,我们定义了一个driver,它调用了webdriver的chrome函数,代表这是使用Chrome浏览器来爬取的。我们还把加载页面的超时时间设置为了30秒,也就是说如果30秒还加载不出来,就去请求下一个页面,而这下一个页面就是从start_requests()函数中获得的。然后我们调用driver.get来获取response的URL,就可以拿到response信息了。
def parse(self, response):
driver = webdriver.Chrome(chrome_options=self.option)
driver.set_page_load_timeout(30)
driver.get(response.url)
title = driver.find_elements_by_xpath("//h2[@class='undefined']/a[@target='_blank']")
time = driver.find_elements_by_xpath("//h2[@class='undefined']/../div[@class='feed-card-a "
"feed-card-clearfix']/div[@class='feed-card-time']")
for i in range(len(title)):
print(title[i].text)
print(time[i].text)
在后面的代码中,我们主要又做了两件事。一个是获取title信息,一个是获取time信息。
我们使用driver.find_elements_by_xpath()函数获取HTML标签中的内容,根据我们在最前面的分析,title被存在“//h2[@class=‘undefined’]/a[@target=‘_blank’]”中,而time被存在“//h2[@class=‘undefined’]/…/div[@class=‘feed-card-a feed-card-clearfix’]/div[@class=‘feed-card-time’]”中,因此,我们可以通过driver.find_elements_by_xpath()获取到里面的内容。
要注意的是,我们获取到的内容一般是以一个list的形式存放,所以我们还需要使用for循环拿到里面的信息。
正常来讲,完成上面这段代码之后,运行main.py文件,就会得到如下图所示的结果。
可以看到,我们想要的时间和标题都已经输出出来了。
不过,虽然我们现在已经得到了时间,但是输出的格式却不统一:有的显示的是今天的某个时间,有的显示的是日期加时间。所以我们要对时间做进一步处理,可以在刚刚的for循环代码下面加上处理代码。
today = datetime.datetime.now()
eachtime = time[i].text
eachtime = eachtime.replace('今天', str(today.month) + '月' + str(today.day) + '日')
if '分钟前' in eachtime:
minute = int(eachtime.split('分钟前')[0])
t = datetime.datetime.now() - datetime.timedelta(minutes=minute)
t2 = datetime.datetime(year=t.year, month=t.month, day=t.day, hour=t.hour, minute=t.minute)
else:
if '年' not in eachtime:
eachtime = str(today.year) + '年' + eachtime
t1 = re.split('[年月日:]', eachtime)
t2 = datetime.datetime(year=int(t1[0]), month=int(t1[1]), day=int(t1[2]), hour=int(t1[3]),
minute=int(t1[4]))
print(t2)
我们再运行一下程序,得到如下结果。

可以看到,现在时间已经变成了我们想要的样子。到这里我们的列表爬取工作就完成了,接下来开始爬取详情页的信息。
爬取详情页
我们知道,如果是人为操作,需要点击相应标题进入详情页。对于爬虫程序来说也是一样的,我们需要从HTML文件中提取标题对应的链接,然后再传给爬虫程序进行数据的爬取,最后处理对应的response。
我们先来看看怎么获取我们所需要的链接。
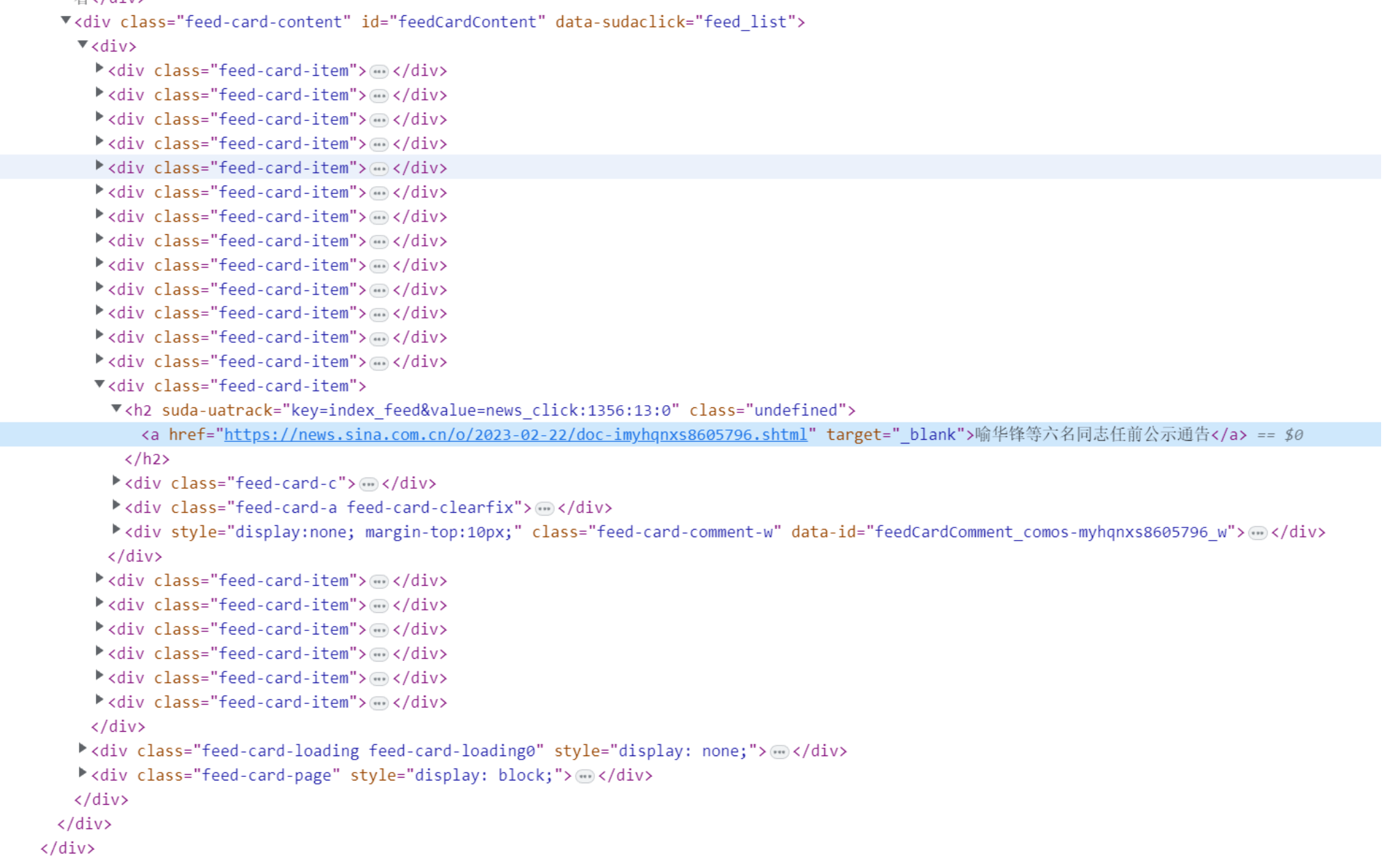
通过分析HTML源文件我们可以看到,每一个标题都在a标签中,而a标签里面的href就是它所对应的链接。所以,我们只需要取出href,就可以取出详情页的链接了。
要实现这一点,我们只需要在解析title后面加上下面这条代码。
接下来,为了获取正文信息,在Scrapy中,我们需要把request请求给yield出去,在里面放上链接。
首先,我们把需要的内容yield到下一页,传递它最好的方式就是使用ItemPipeline。可以看到我们创建Scrapy工程之后,工程目录下会自动创建一个items.py。我们打开这个文件,会发现它自带了一些代码。
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class SinaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
这段代码里导入了scrapy包,并自动帮我们创建了一个SinaItem类,这里还通过注释的方法告诉了我们这个类里面应该怎么写。我们就来照葫芦画瓢,把我们想要的字段加入进来。
代码会变成如下形式。
class SinaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
desc = scrapy.Field()
times = scrapy.Field()
type = scrapy.Field()
我们在里面定义了四个字段,分别是title、desc、times和type,分别用来表示标题、内容、时间和类型。这里的标题和时间通过列表来获取,内容是详情页里的。而类型我们默认为国内,如果后面我们需要爬取其他的类别,比如综艺、体育等,我们就不需要新建class了,只要重新在这个type字段中赋值即可。
好了,进行到这里,我们就可以回到我们的爬虫代码去引入这部分内容了。首先我们要在第一行引入我们的item文件,加入下面的代码。
然后,我们在爬虫文件的parse函数中引入SinaItem类,并在函数的末尾对其赋值我们想要的内容。
接着,我们可以在最后把item给yield出去,在代码的最后加入如下内容。
这样我们就可以顺利地把item信息和URL给yield出去了。
我们来看这个yield的写法。我们yield出去的内容有两个,分别是URL信息和item。item用Key-Value的形式传输,我们把它赋值到了Key为“name”的键值对中。
然后我们在这里还用到了一个callback函数,它实际上是回调了一个名为parse_namedetail的函数。所以,我们需要在下面建立这个函数解析我们的详情页信息。我们在parse函数的下面新建一个函数parse_namedeatal并实现它,代码如下。
def parse_namedetail(self, response):
selector = Selector(response)
desc = selector.xpath("//div[@class='article']/p/text()").extract()
item = response.meta['name']
desc = list(map(str.strip, desc))
item['desc'] = ''.join(desc)
print(item)
yield item
在这个函数中,我们首先建立了一个Selector,它主要是Response用来提取数据的。当Spider的Request得到Response之后,Spider可以使用Selector提取Response中的有用的数据。因此,这里我们传入的是上面的Response信息,也就是详情页的Response。
然后,我们使用XPath语法解析response中的HTML代码。我们先来看下有哪些XPath表达式,以便后续我们更好地使用它。

然后我们再来看一下详情页的正文部分在Chrome的开发者工具中的源代码。
放大代码部分得到如下结果。
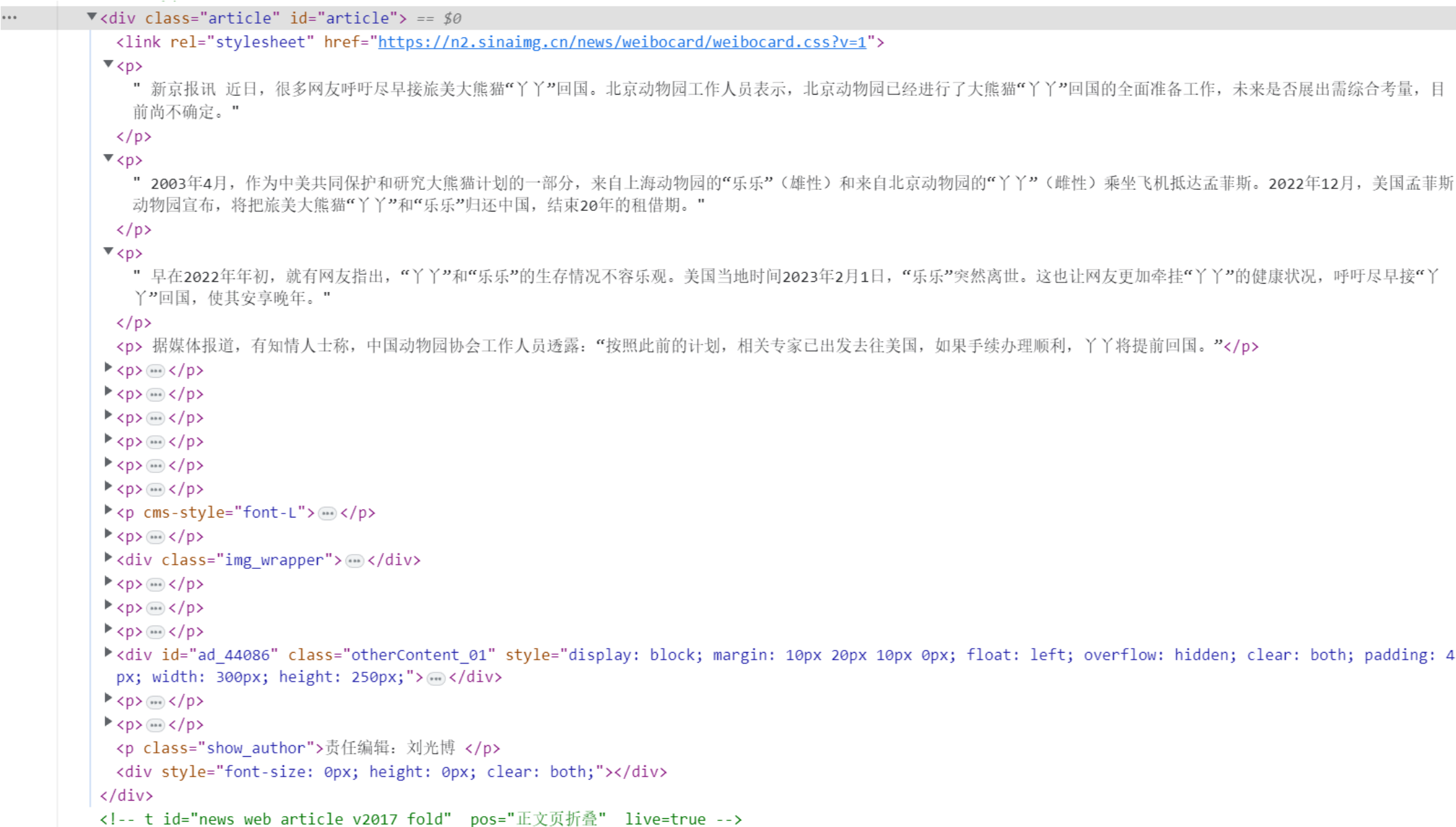
可以看到,所有的正文部分都在class为article和id为article的<div>标签中,并且每个段落都用<p>标签包裹着。也就是说,我们只需要拿到class和id的标签,并且拿到所有的p标签,就可以拿出所有的内容。因此我们可以使用下面这行代码来获取所有的正文内容。
简单解释一下,我们使用 // 标志跨节点获取到了class为article的段落下面所有p标签中的内容,并把它们提取了出来。接着,我们使用下面的代码拿到了前面传入的item信息,并把desc加入到了item中。
最后,我们再把这个item给yield出去就可以了。现在我们再运行一下代码会得到如下输出。

到这里,我们的数据爬取工作看起来就已经完成了。
但是等一等,你有没有发现一个问题,现在虽然已经能够爬取到数据,但是只能爬取一页的内容。这是远远不够的,接下来我们就用程序来实现翻页按钮的点击功能。
实际上,我们只需要在parse函数中加入如下代码即可。
try:
driver.find_element_by_xpath("//div[@class='feed-card-page']/span[@class='pagebox_next']/a").click()
except:
Break
这段代码也不难理解,就是找到翻页导航条的HTML标签,然后找到它的<a>链接,执行点击。
最后,我们要在最上面加上一个翻页操作,假设我们只需要翻5页,此时parse函数的代码如下。
def parse(self, response):
driver = webdriver.Chrome(chrome_options=self.option)
driver.set_page_load_timeout(30)
driver.get(response.url)
for i in range(5):
while not driver.find_element_by_xpath("//div[@class='feed-card-page']").text:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
title = driver.find_elements_by_xpath("//h2[@class='undefined']/a[@target='_blank']")
time = driver.find_elements_by_xpath(
"//h2[@class='undefined']/../div[@class='feed-card-a feed-card-clearfix']/div[@class='feed-card-time']")
for i in range(len(title)):
print(title[i].text)
print(time[i].text)
today = datetime.datetime.now()
eachtime = time[i].text
eachtime = eachtime.replace('今天', str(today.month) + '月' + str(today.day) + '日')
href = title[i].get_attribute('href')
if '分钟前' in eachtime:
minute = int(eachtime.split('分钟前')[0])
t = datetime.datetime.now() - datetime.timedelta(minutes=minute)
t2 = datetime.datetime(year=t.year, month=t.month, day=t.day, hour=t.hour, minute=t.minute)
else:
if '年' not in eachtime:
eachtime = str(today.year) + '年' + eachtime
t1 = re.split('[年月日:]', eachtime)
t2 = datetime.datetime(year=int(t1[0]), month=int(t1[1]), day=int(t1[2]), hour=int(t1[3]),
minute=int(t1[4]))
print(t2)
item = SinaItem()
item['type'] = 'news'
item['title'] = title[i].text
item['times'] = t2
yield Request(url=response.urljoin(href), meta={'name': item}, callback=self.parse_namedetail)
try:
driver.find_element_by_xpath("//div[@class='feed-card-page']/span[@class='pagebox_next']/a").click()
except:
Break
我们再运行程序,这时我们就可以爬取5页的内容了,在此之后,爬虫会自动停止。

这样,我们已经能够针对一个栏目来爬取数据了。在后面的课程中,我们会延续这个思路,然后把数据存储起来并做相应的处理。
总结
这节课到这里也就接近尾声了,我来给你梳理一下这节课的主要内容。
- 在Chrome浏览器中,我们可以使用 Chrome 开发者工具来查看页面上的元素、标记和属性,以及查看网络请求、响应和其他诊断信息。
- Scrapy 提供了许多内置的解析器,包括 XPath 和 CSS 选择器等,这些解析器可以帮助我们轻松地从 HTML 页面中提取所需数据。
- 在 Scrapy 中,callback 函数可以返回多个请求,并在结果返回时使用 yield 关键字传递给 Scrapy 引擎。
- item.py 文件是 Scrapy 中用于解析和存储数据的 Python 类。在 item.py 文件中,你可以定义数据模型,确定要提取的字段,并定义数据的类型和格式。
- 在爬取包含多个页面的网站时,可以使用 next_page() 方法来模拟用户操作,调用click()函数进行点击。
课后题
学完这节课,请你试着完成下面两项任务。
- 跟着我的讲解,自己实现一遍这节课所讲的内容。
- 爬取新浪网站电影板块的内容。
欢迎你在留言区与我交流讨论,你也可以把代码链接附在评论区,我会选取有代表性的代码进行点评,我们下节课见!
- Geek_ccc0fd 👍(3) 💬(1)
新安装selemium的API变了,而且xpath获取的路径有点问题,我这里获取不到一页的全部内容,我修改了一下: title = driver.find_elements(By.XPATH, "//div[@class='feed-card-item']/h2/a[@target='_blank']") time = driver.find_elements(By.XPATH,"//div[@class='feed-card-item']/h2/../div[@class='feed-card-a feed-card-clearfix']/div[@class='feed-card-time']") 然后就是翻页点击那里我这边跑下来也有问题,根据xpath会获取两个a标签,所以需要增加索引: driver.find_elements(By.XPATH,"//div[@class='feed-card-page']/span[@class='pagebox_next']/a")[0].click()
2023-05-06 - 未来已来 👍(1) 💬(2)
截止到 5月3日,新安装的 selemium 只有 find_elements 方法,老师的代码需改为: `title = driver.find_elements(By.XPATH, "//h2[@class='undefined']/a[@target='_blank']")` `time = driver.find_elements(By.XPATH, "//h2[@class='undefined']/../div[@class='feed-card-a feed-card-clearfix']/div[@class='feed-card-time']")` 以此类推
2023-05-03 - Abigail 👍(0) 💬(1)
应该设计一个简单点的例子, python 起码也要用 3.9 啊
2023-10-24 - alexliu 👍(0) 💬(1)
在运行下一页click()的时候,有可能出现ElementNotInteractableException错误,解决方案: 1、在driver.get(response.url)和click()后添加延时time.sleep(2) 2、保持chrome的窗口大小一致 self.option.add_argument("--window-size=1960,1080") try... except...部分代码如下: try: _next = driver.find_elements(By.XPATH, "//div[@class='feed-card-page']/span[@class='pagebox_next']/a") _next[0].click() _time.sleep(2) except StaleElementReferenceException as e: print(" page failed.", e) _next = driver.find_elements(By.XPATH, "//div[@class='feed-card-page']/span[@class='pagebox_next']/a") _next[0].click() _time.sleep(2) except ElementNotInteractableException as e: print(" not found page.", e) break except Exception as e: print("unkwon error: ", e)
2023-06-01 - Geek_ccc0fd 👍(0) 💬(1)
我们在parse里面可以直接使用response.xpath获取元素,和使用 driver.find_elements是同样的效果,为什么还要用selenium来做浏览器的操作呢?
2023-05-06 - 安菲尔德 👍(0) 💬(1)
请问哪有main.py文件呢,没有看到
2023-05-02 - peter 👍(0) 💬(2)
Q3:源码放在什么地方啊?能否把源码集中放到一个公共地方? 比如github等。
2023-04-26 - peter 👍(0) 💬(3)
Q1:第七课,创建环境的最后几步,不停出错,最后一个错误是:执行“scrapy genspider sina_spider sina.com.cn”,报告:lib\string.py", line 132, in substitute return self.pattern.sub(convert, self.template) TypeError: cannot use a string pattern on a bytes-like object 网上搜了,大意说是python2和python3不匹配导致的。 我是完全按照老师的步骤来安装的,安装的是pythno3,怎么会有python2呢?当然,这个文件还没有解决,进行不下去了,郁闷啊。 Q2:能否建一个微信群?遇到问题可以协商。 另外,老师能否更及时地回复留言?
2023-04-26 - GAC·DU 👍(0) 💬(1)
老师,关于代码有些疑惑,第一:为什么parse_namedetail方法不再使用driver发起http请求和获取html标签内容? 第二:desc = response.xpath("//div[@class='article']/p/text()").extract() desc = selector.xpath("//div[@class='article']/p/text()").extract() 我测试了两个代码都可以使用,那为什么不直接使用response,反而要生成一个selector?
2023-04-26 - Weitzenböck 👍(1) 💬(1)
如果出现这个错误:__init__() got an unexpected keyword argument 'chrome_options' 代码里改为 driver = webdriver.Chrome(options=self.option)具体源码是: class WebDriver(ChromiumDriver): """Controls the ChromeDriver and allows you to drive the browser.""" def __init__( self, options: Options = None, service: Service = None, keep_alive: bool = True, ) -> None: """Creates a new instance of the chrome driver. Starts the service and then creates new instance of chrome driver. :Args: - options - this takes an instance of ChromeOptions - service - Service object for handling the browser driver if you need to pass extra details - keep_alive - Whether to configure ChromeRemoteConnection to use HTTP keep-alive. """ self.service = service if service else Service() self.options = options if options else Options() self.keep_alive = keep_alive self.service.path = DriverFinder.get_path(self.service, self.options) super().__init__( DesiredCapabilities.CHROME["browserName"], "goog", self.options, self.service, self.keep_alive, )
2023-06-15 - 风轻扬 👍(0) 💬(0)
mac系统,爬取过程中,可能会报错:无法打开chromedriver,因为无法验证开发者。 如果是brew安装的chromedriver,可以执行:xattr -d com.apple.quarantine /opt/homebrew/bin/chromedriver进行可信授权。 如果不是brew安装的,需要自己找到chromedriver的安装路径,然后执行xattr -d com.apple.quarantine 你的chromedriver的路径
2024-08-22 - 悟尘 👍(0) 💬(1)
# 尝试点击下一页 try: # next_page_link = WebDriverWait(driver, 30).until( # EC.element_to_be_clickable( # (By.XPATH, "//div[@class='feed-card-page']/span[@class='pagebox_next']/a")) # ) # next_page_link.click() driver.find_elements(By.XPATH, "//div[@class='feed-card-page']/span[@class='pagebox_next']/a")[0].click() except Exception as e: print(f"Error clicking next page link: {e}") break 打出的异常是:Error clicking next page link: Message: stale element reference: stale element not found 这是因为什么?
2023-12-12 - 悟尘 👍(0) 💬(0)
为什么我的翻页不起作用呢?
2023-12-12