10 数据加工:如何将原始数据做成内容画像?
你好,我是黄鸿波。
在前面的课程中,我们已经能够使用scrapy爬取想要的数据集,下面我们更进一步,把数据集处理成内容画像。这节课我会从内容画像的定义出发,带你了解内容画像的作用,紧接着,我们把原始的数据做成内容画像,直到最基础的画像已经能够正常写入到MongoDB数据库。
内容画像的定义与作用
从通俗的角度来说,内容画像实际上就是内容的一系列标签,我们在各个维度上给用户打上各种各样的标签,就组成了内容画像。由于内容在各个维度上被打上了不同的标签,因此,我们就可以在不同的维度上对内容进行分类。
内容的来源一般分成官方、用户和互联网(例如爬虫爬取),不同的来源肯定就会使得内容的形式、质量等都有比较大的区别。
从标签和分类的角度来讲,我们可以将内容标签呈现出漏斗式。也就是说,从一个大而广的分类到垂直领域,再到细分领域,最后到关键词这个级别。在这个漏斗中,每一个层级都可以作为画像中的一个标签或者一个特征,到实际的模型中再根据需求进行取出,从而进行模型的训练。
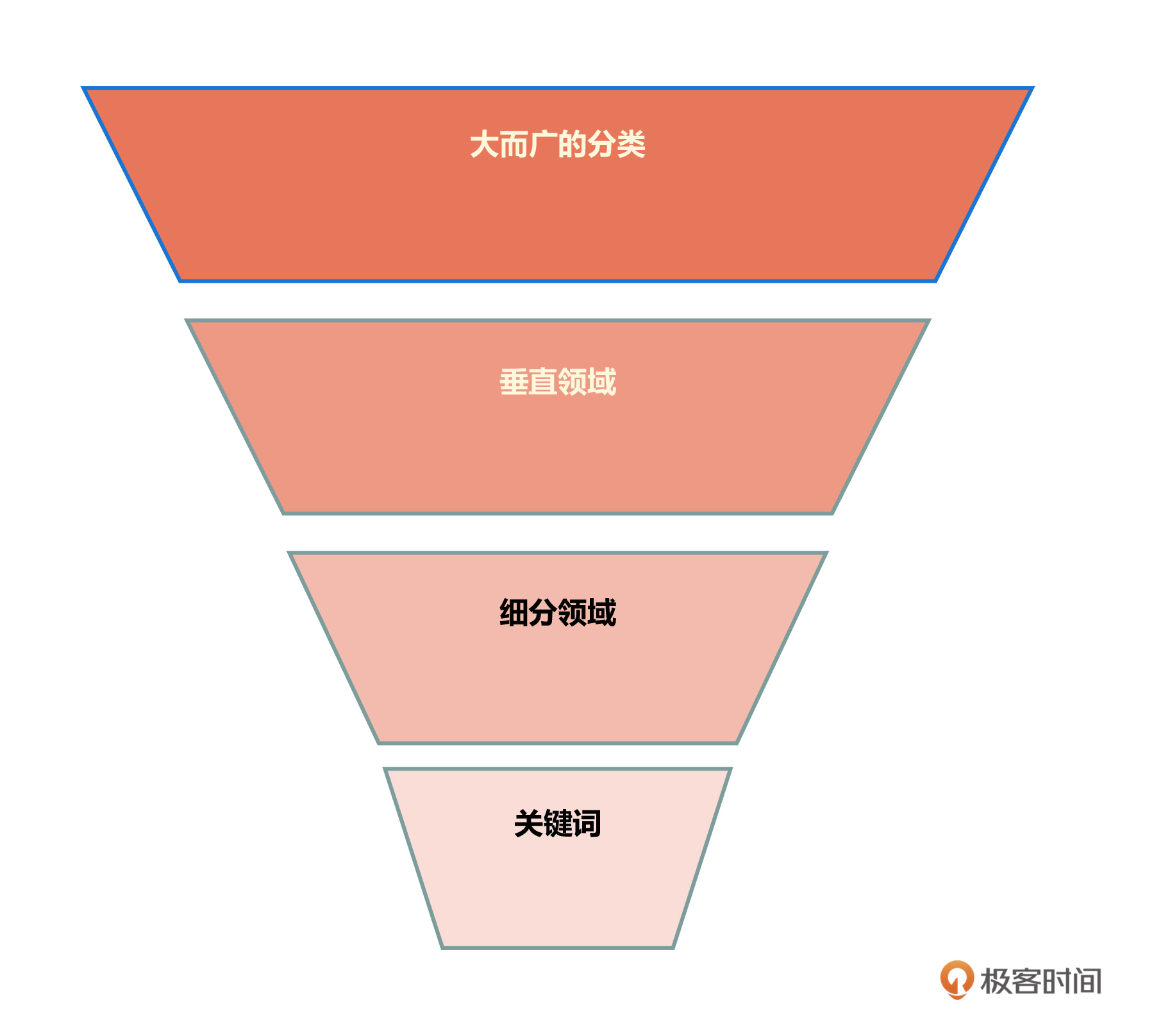
如果把内容画像平铺开来,实际上我们得到的就应该是一个大的标签库。从这个标签库中随意抓出一个标签,就能找到这个标签所对应的内容的列表。当把标签进行各种组合时,就会产生不同的列表。从理论上来讲,组合的条件越多,所描述和刻画的标签也就越精细,所对应的内容也就更加具体,这对于判断用户的喜好来说是非常重要的。
内容画像是一个推荐系统推荐效果的核心所在,当我们在构建各种推荐算法和模型的时候,需要使用到各种各样的特征,而这些特征一般来讲都是从内容画像中获取到的各个标签,然后经过一系列的处理,得到我们需要的信息,从而进行推荐算法的模型构建和推理。
推荐系统包含内容画像和用户画像两个大的画像。实际上,用户画像也可以简单理解为内容画像中多个内容的集合。根据前面的讲解我们可以知道,用户画像里一般包含着一系列的用户行为,这些行为中很大一部分就是用户所浏览的内容信息。而一个用户之所以能够点击这些内容,或者能够对这些内容感兴趣,也都是因为这些内容的标签。
对于用户来讲,这些内容的标签可以是显性的也可以是隐性的。显性指很多产品明确标记了内容标签、关键词或者其他的信息;隐性指有些标签并没有单独以标签的形式标记出来,而是用户根据自己的判断得到的,比如说标题里面的关键词、摘要里面的关键短语等。实际上,这些标签都是真实存在的,而这些标签就组成了一个个的内容画像。
另外我们可以通过内容画像找到内容之间是否有共同标签,以及内容之间是否有一定的相似性。在实际推荐系统的运行过程中,就可以利用这些相似性给用户推荐相似的文章。
把原始的数据做成内容画像
下面我们来把原始数据做成内容画像。
我们可以将原始文本数据粗略分为非结构化数据和结构化数据。我们在处理不同类型数据时所用的方法略有区别,但最终想要达到的目的都是相同的,那就是提取出它们的标签。
非结构化数据是指数据结构不规则或者不完整,没有预定义的数据模型。目前大部分的原始数据都是非结构化数据,它广义上包括了文档、文本、图片、音频、视频等等。这节课主要指的是文本信息,更确切地来讲,就是我们从新浪网上爬取的内容数据。
这种非结构化文本一般包含了关键词提取、命名实体识别、文本分类、Word Embedding等,我给你画了一个表格,里面有这些技术对应的作用,你可以对照进行学习。

下面我们把之前使用scrapy爬取的数据制作成内容画像,然后存储到MongoDB数据库中。
首先我们拿MongoDB数据库中的任意一条数据为例。

在这条数据中,一共有5个字段,分别是“_id”、“type”、“title”、“times”和“desc”。在这里我们可以发现,除了“_id”这个字段以外,其他的数据都是爬虫爬取回来的。这里“_id”这个字段,实际上就是MongoDB为这条数据建立的一个id,并且这条id在MongoDB数据库中是唯一的。
想要把我们的内容做成画像,我会从下面几个角度来考虑。
- 这个文章的标题包含了什么关键词?
- 这个文章的内容包含了什么关键词?
- 这个文章有多少个字,是长文还是短文?
- 是否需要附上一个初始的热度?
- 这个文章的类型是什么?
当然,我们所需要考虑的不仅仅只有这些,不过前期可以先按照这几个角度来做成一个简单的内容画像。
一般来讲,内容画像不属于爬虫,它属于推荐系统的一部分。因此,在这里需要创建一个新的项目,用来专门做推荐系统与模型相关的处理,包括数据处理、模型搭建、训练等等。到了后面服务端内容的时候,我们也会再建立一个与服务端相关的项目。
这里需要注意的是,建立项目的时候,你需要选择一个anaconda的环境,一般来说,我对于anaconda环境的管理原则可以分成以下三个思路。
按项目。每建立一个项目就建立一个新的anaconda环境,并且环境名与项目名进行对应或者相关。
按环境相关性。所谓的按环境相关性就是指你要把你的常用的一类放在一个环境里,比如说某个环境就是和TensorFlow相关的库,或者某个环境就是和pytorch相关的库,不同的版本建立不同的库,这样的话可以做到环境的隔离,也相对比较通用。
按项目通用性。如果项目里面用不到太多太复杂的包,可以建立一个通用的anaconda环境,然后装一些通用的库(比如说numpy、sklearn等),一些简单的机器学习和科学计算的方法都可以使用这个包来做。
在这个项目里,因为要用到的环境相对比较复杂,所以我就新建立一个环境,将其命名为“recommendation-class”,使用的Python环境为3.7,因此,我们在cmd环境下,输入下面这行代码。
创建完成后,使用下面的命令来进行激活环境。
这个时候,暂时可以先不用安装需要的库,我建议先在pycharm中创建一个recommendation-class的项目,然后关联我们的环境,如图所示。
当项目创建好之后,就会出现下面的界面。
现在我们真正进入到推荐系统的代码开发部分。在开发代码之前来先对目录做一个规划,看看我们到底都需要哪些目录。
我先把最基本的一级目录列出来。
我认为,一个最基本的推荐系统目录至少要包含表格里的这六个部分。
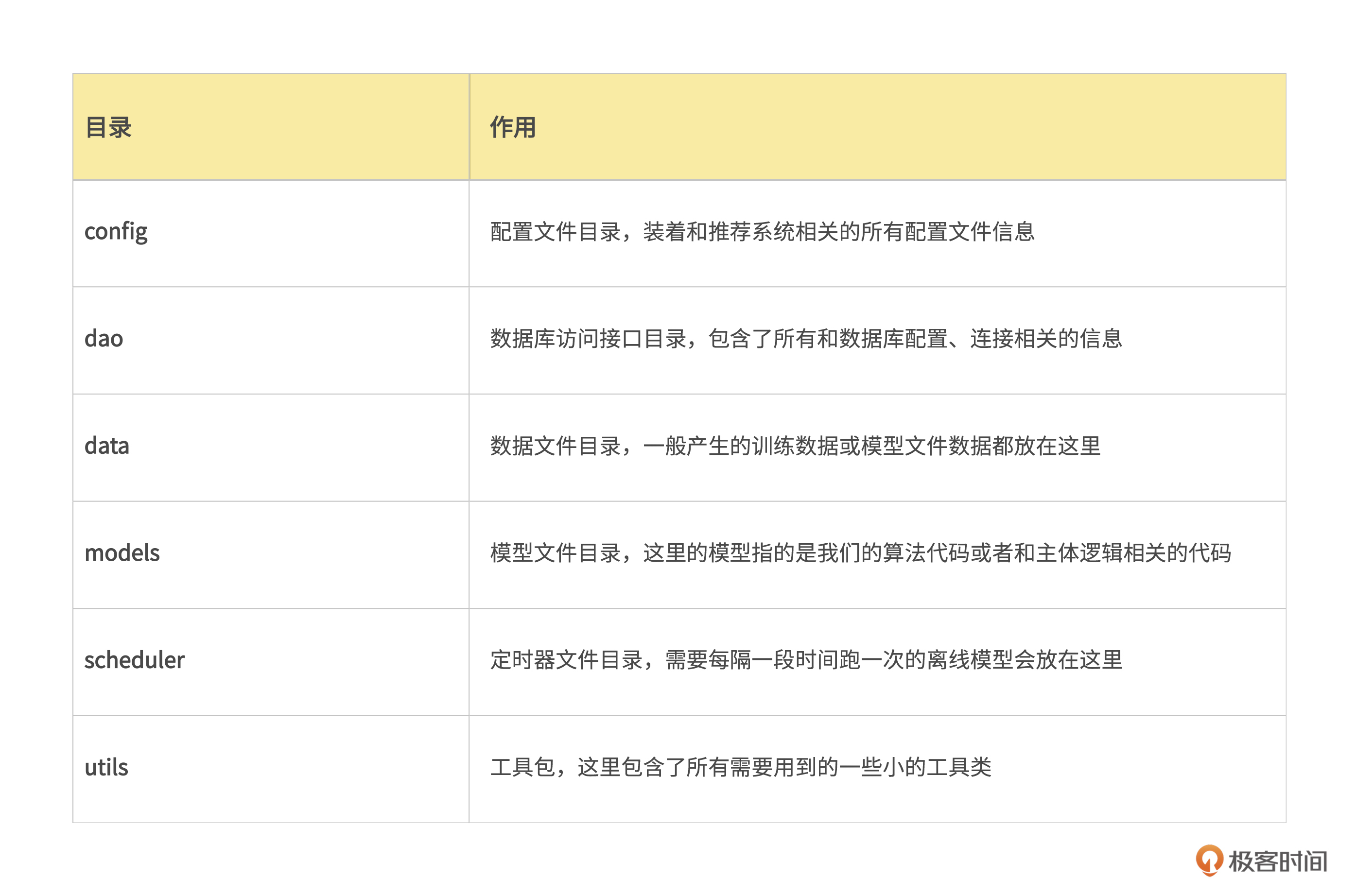
接下来要做的是制作一个内容画像,我在models目录下建立一个label目录,专门来放各种画像,然后再在lables目录建立一个content_label.py文件,专门用来编写处理与内容画像相关的代码,最后目录结构如下。
接下来我们要做的就是在这里面处理内容画像,处理的简单流程如下。
- 从MongoDB中获取数据。
- 将获取到的数据进行取关键词、字数获取、其他信息获取的操作。
- 给内容画像设置一个默认的点赞、收藏、阅读的数量。
- 设置一个默认热度,以后可以做热度改变。
- 将这些内容做成画像,插入到MongoDB数据库,数据库的collection为“content_labels”。
下面我们就来一步一步实现它。
首先,从MongoDB中导入数据,建立数据库连接。建立数据库连接的代码实际上和scrapy里面连接MongoDB的代码是一套,所以可以直接把scrapy项目中dao目录下的mongo_db.py文件直接拿过来,然后根据目前的项目,稍微做一下改动,代码如下。
import pymongo
class MongoDB(object):
def __init__(self, db):
mongo_client = self._connect('localhost', 27017, '', '', db)
self.db_scrapy = mongo_client['scrapy_data']
self.db_recommendation = mongo_client['recommendation']
def _connect(self, host, port, user, pwd, db):
mongo_info = self._splicing(host, port, user, pwd, db)
mongo_client = pymongo.MongoClient(mongo_info, connectTimeoutMS=12000, connect=False)
return mongo_client
@staticmethod
def _splicing(host, port, user, pwd, db):
client = 'mongodb://' + host + ":" + str(port) + "/"
if user != '':
client = 'mongodb://' + user + ':' + pwd + '@' + host + ":" + str(port) + "/"
if db != '':
client += db
return client
可以看到,在这里我只是做了一个非常小的改动,就是在最上边的数据库中添加了一个“recommendation”。后面所有在推荐系统中涉及MongoDB数据库的操作,都会基于“recommendation”这个库来操作。但是我仍然保留了“scrapy_data”这个库,因为读取原始数据还是要基于这个库来读取。
有了这个MongoDB连接类,就可以将其导入到content_label.py文件中,然后直接在我们的content_label.py文件中使用。
接下来,我们来看content_label.py这个文件的代码。我们先来做一个简单的内容画像,其画像的字段全部来自已知数据。
from dao.mongo_db import MongoDB
from datetime import datetime
class ContentLabel(object):
def __init__(self):
self.mongo_scrapy = MongoDB(db='scrapy_data')
self.mongo_recommendation = MongoDB(db='recommendation')
self.scrapy_collection = self.mongo_scrapy.db_scrapy['content_ori']
self.content_label_collection = self.mongo_recommendation.db_recommendation['content_label']
def get_data_from_mongodb(self):
datas = self.scrapy_collection.find()
return datas
def make_content_labels(self):
datas = self.get_data_from_mongodb()
for data in datas:
content_collection = dict()
content_collection['describe'] = data['desc']
content_collection['type'] = data['type']
content_collection['title'] = data['title']
content_collection['news_date'] = data['times']
content_collection['hot_heat'] = 10000
content_collection['likes'] = 0
content_collection['read'] = 0
content_collection['collections'] = 0
content_collection['create_time'] = datetime.utcnow()
print(content_collection)
if __name__ == '__main__':
content = ContentLabel()
content.make_content_labels()
这是一个很简单的画像的例子,当然,目前我还没有把它们插入到MongoDB数据库中,仅仅是使用print()函数将它们打印了出来。
我们来稍微解析一下这段代码。在这段代码中首先在上面引入了MongoDB的连接类,又引入了一个datetime库,你可以利用这个库来获取到当前时间并赋值到创建时间这个字段中。
在__init__()函数的定义中,我们主要是定义了与数据库连接相关的变量,主要有MongoDB连接scrapy库、MongoDB连接recommendation库(注意,这个库目前数据库里还没有,需要在数据库手动创建),以及对应的两个collection,分别是“scrapy_data”库的“content_ori”和“recommendation”库的“content_label”(这个collection目前也没有,当运行程序后会自动创建)。
self.scrapy_collection = self.mongo_scrapy.db_scrapy['content_ori']
self.content_label_collection = self.mongo_recommendation.db_recommendation['content_label']
紧接着,我们创建了一个名为“get_data_from_mongodb”的函数,这个函数主要是从scrapy库中获取到原始数据,然后将原始数据进行返回。
你可以看到,在这个函数里目前虽然只有一行数据,但是我还是单独给作为一个函数拿了出来。这样做的好处是能够很好地进行解耦,这个函数就是用作获取原始数据,职责单一。
当然,因为目前数据量比较少,所以我是直接获取了所有的数据。但是当数据量非常大的时候(比如有几万或者几十万甚至上百万数据),必须采用分页的形式来获取数据,这样可以减少数据库的开销以及程序卡顿。
然后到了内容画像中最重要的一个函数:make_content_labels()函数。我们会在这个函数中进行数据的组装,并把组装后的数据作为内容画像存储在MongoDB数据库中。
MongoDB所使用的数据格式叫BSON,BSON是一种类似于JSON的数据类型。在Python中,Dict类型和JSON类型可以相互转换。因此我们在这里新建了一个Dict()类型的变量,名为“content_collection”,然后再将所需要的内容给填充进去。我们首先从原始数据中获取到基本的信息,例如内容、类型、标题和新闻时间,然后放入到字典中。
def make_content_labels(self):
datas = self.get_data_from_mongodb()
for data in datas:
content_collection = dict()
content_collection['describe'] = data['desc']
content_collection['type'] = data['type']
content_collection['title'] = data['title']
content_collection['news_date'] = data['times']
接着,我又新建了一些初始化的特征。例如在这里我设定了初始化的热度为10000,这是为了以后可以通过热度值来进行排序。然后我又新建了点赞、阅读、收藏这三个值,初始值为0。最后我又定义了一个创建时间作为这条数据的创建时间,它可以用作后面一些模型和算法的特征。
content_collection['hot_heat'] = 10000
content_collection['likes'] = 0
content_collection['read'] = 0
content_collection['collections'] = 0
然后,我使用print先将数据打印出来看一下,得到如下结果。
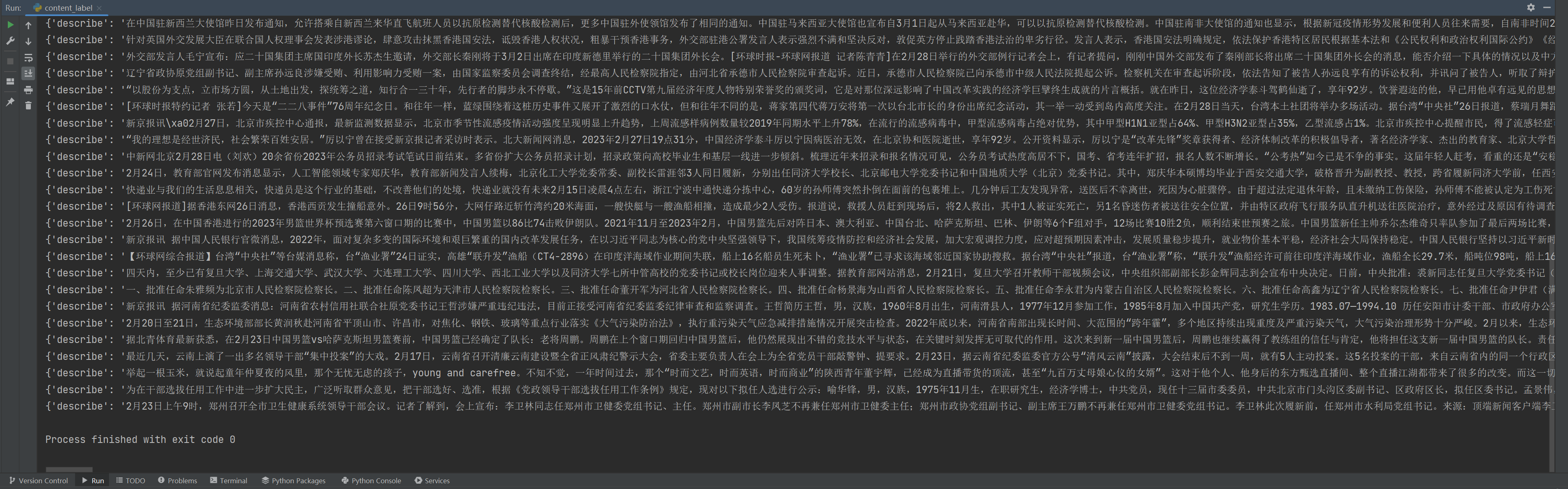
如果出现这个结果,至少说明我们的程序目前是可以正常跑通的。接下来,我们就可以再向里面加点东西。
我们可以往里面再加入一个统计字数的功能。在Python中,字数可以使用正则化加上Unicode编码的方式来进行统计。我们知道,实际上汉字也是Unicode编码中的一部分。在Unicode编码中,常用汉字的编码是从4E00到9FA5,因此将这一部分的内容统计出来即可。你可以在程序中引入re库来进行正则表达式的统计,这段函数可以写成下面的形式。
def get_words_nums(self, contents):
ch = re.findall('([\u4e00-\u9fa5])', contents)
num = len(ch)
return num
在这段函数中传入的是文本内容,也就是我们爬取到的文章正文,然后使用re.findall()函数来取得内容中Unicode编码在4E00到9FA5之间的文字。这个时候会得到一个list列表,列表里面只包含常用的中文文字,之后用len()函数对这些文字的数量进行统计,就得到了需要的中文字数。
然后,我们在make_content_labels()中加入它的函数调用即可。
现在我们可以加上MongoDB插入的部分,看看能不能正常写入到数据库中。这一步其实非常简单,只需要在make_content_labels()函数的最后加入下面这行代码即可。
我们来运行一下这段程序,运行后刷新一下MongoDB数据库,就得到了如下界面。
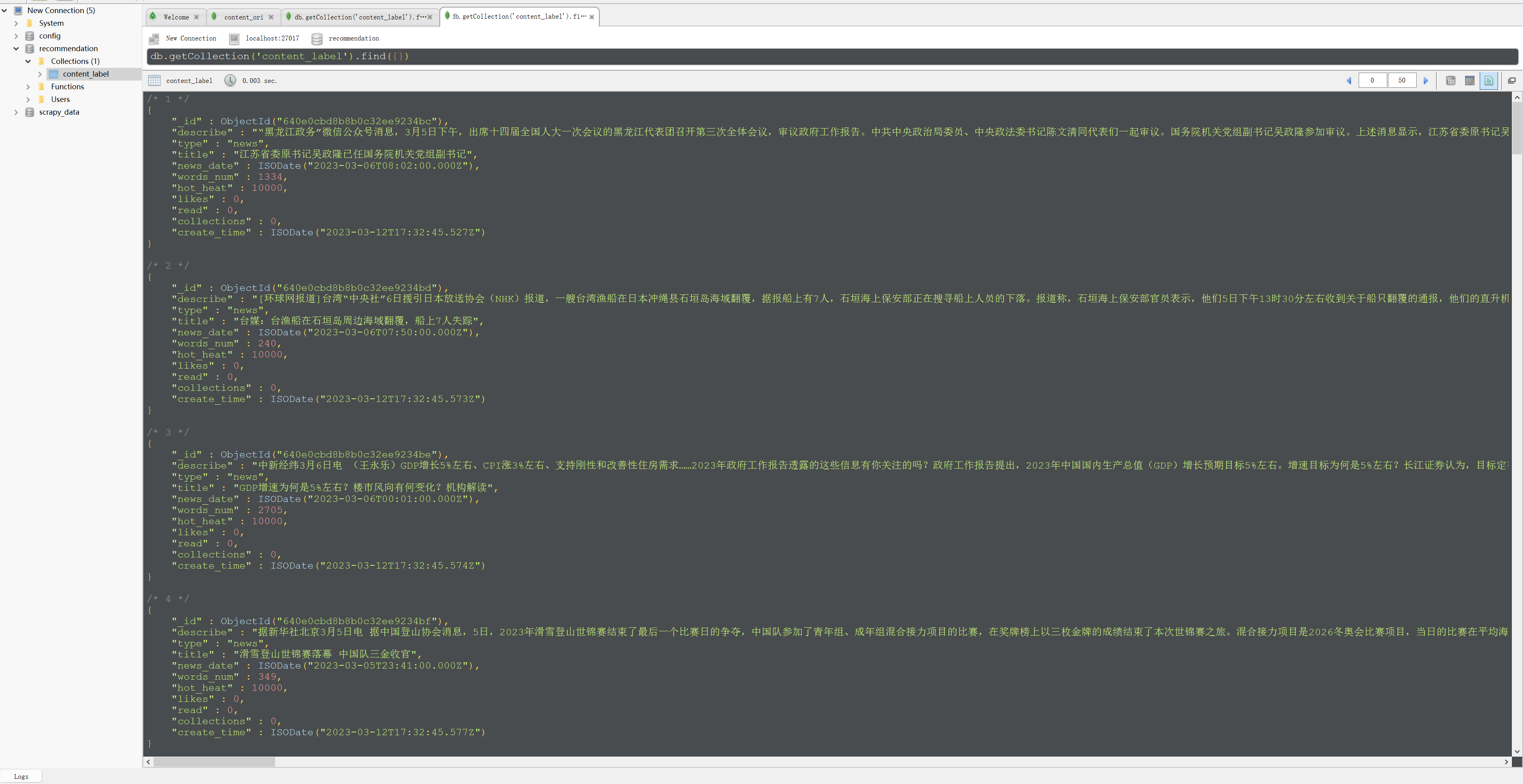
到这里就说明最基础的画像已经能够正常写入到MongoDB数据库了,在接下来的课程中我们会继续完善这个内容画像,并将其作为模型和算法的特征。
实际上这里还有一个非常关键的特征没有加上,那就是关键词。也就是提取文章和标题中的关键词,然后再加入到我们的画像中作为画像的一部分。这一部分的内容我想留作一个作业让你课后去完成,我会在GitHub里公布我们的代码和思路。
总结
我们来总结一下这节课的内容,学完这节课,希望你能够记住以下要点。
- 知道内容画像是什么,它在推荐系统中有着举足轻重的地位。
- 了解非结构化文本内容画像的生成处理方式,比如文本分类、文本聚类、关键词提取等等。
- 熟悉如何使用Python配合MongoDB来做一个简单的内容画像。
课后题
最后依旧是课后题环节,给你留了两道课后题。
- 完成并理解课程中的代码,再想想还可以挖掘哪些特征并找一个特征加入到的内容画像中。
- 在原有代码的基础上加入关键词的特征,关键词提取限定使用TF-IDF或者TextRank,也可以两者结合使用。
- Geek_ccc0fd 👍(2) 💬(5)
关于画像有个问题想请教一下老师: 我们训练样本一般是过去一段时间的数据,但是画像数据保存的最新的画像标签,这里如果直接使用样本关联画像标签的话会发生特征穿越问题,这里实际工作中是如何处理的呢?
2023-05-08 - Geek_ccc0fd 👍(1) 💬(5)
统计字数那里赋的代码是不是搞错了
2023-05-08 - Abigail 👍(0) 💬(1)
Robo 3T is now Studio 3T https://studio3t.com/download/
2023-11-01 - MWF 👍(0) 💬(1)
请问github地址是什么?
2023-08-02 - MWF 👍(0) 💬(1)
请问能否把每一讲的代码(包括网络上爬取到的数据)都上传到github供大家下载呢,因为不是每个人都会从头到尾跟进每一节,比如我主要想学习画像部分的内容,那么没安装数据库以及爬虫相关插件,就无法得到数据进行后面的内容了。
2023-08-02 - GhostGuest 👍(0) 💬(1)
文稿中热度设置错了,代码写的一万,文稿写的一千
2023-05-10 - 翡翠虎 👍(0) 💬(1)
除了关键词外,我感觉文章类型(文本分类)、国家地区也可以作为特征之一
2023-05-08 - Geek_bc9832 👍(0) 💬(0)
文章中words_num的代码好像写错了,写成keywords了
2024-12-19 - moonfeeling 👍(0) 💬(0)
关键词提取可参考这篇文章实现:https://mp.weixin.qq.com/s/Vd58Hxiocx9BkcKvnGS7ng
2024-01-04 - moonfeeling 👍(0) 💬(0)
老师好,请问下文章和标题中的关键词提取部分的代码在哪里找呢?您给的github中源码好像没有
2024-01-04 - 悟尘 👍(0) 💬(0)
def get_words_nums(self, contents): ch = re.findall('([\u4e00-\u9fa5])', contents) num = len(ch) return num 这个函数的入参应该是 data['desc'] ,即文章正文,具体代码如下: word_nums = self.get_words_nums(data['desc']) content_collection['word_num'] = word_nums
2023-12-12 - Geek_ea1710 👍(0) 💬(0)
已看
2023-05-09