13 基于关键词的召回:如何使用关键词吸引用户?
你好,我是黄鸿波。
在讲解了基于时间的召回和基于热度的召回后,今天我们进入到基于规则召回的最后一种——基于关键词的召回,我将本节课分为了下面两个大的部分。
- 基于关键词的召回。
- 提取关键词的几种获取方式。 那么话不多说,我们直接开始本节课的内容。
基于关键词的召回
对于任何一篇文章、段落、标题等,只要是以文字形式展现的内容,我们都能够通过一系列的词语组合起来代表一篇文章的主旨,而这一系列的词语就是文章的关键词。
文章的标题是一篇文章最精辟的概括,摘要是一篇文章的主旨,正文是文章的详细信息。对于一篇文章来说,我们最先看到的是关键词,其次是摘要,然后才是文章正文的本身。因此,在做关键词提取和文章的特征时,我们一般需要分开来做关键词的提取和保存。
基于关键词的召回往往与用户画像或搜索关键词息息相关。在用户画像中实际上也会有用户常看的内容关键词的集合,甚至还可以对这些关键词的出现频率进行排序,从而来确定这些关键词的重要性。而在基于关键词召回的算法中,我们可以将文章的关键词和用户画像中用户标签的关键词进行结合,从而进行基于关键词的召回。
除了用户画像外,用户的搜索内容往往是基于关键词召回的关键所在。一般来讲,一旦用户搜索了一个关键词,说明用户对这个关键词表示的内容是非常感兴趣的。因此,我们在做推荐的时候就需要尽可能把关键词相关的内容给展示出来,从而增加用户的黏性和点击率。
在与用户搜索内容结合的时候,一般来讲,我们会采取多种不同的方式来结合。最简单直接的方式是关键词与热度结合。
当用户在进行关键词搜索时,我们在后台就可以知道用户目前搜索的关键词是什么,然后将关键词放到内容画像中进行搜索,这个时候我们可能会找到一个、多个或者根本没有相关关键词的内容。当有多个和该关键词相关的内容之后,我们就可以将这些内容按照热度降序进行排列,然后展现给用户。
当与之匹配的关键词内容只有一个或者没有时,我们就得用另外一种形式对内容进行补充:结合协同过滤或基于关键词相似度的embedding召回。
这两块的召回部分会在后面的课程中详细讲解,在这里我先来说一下大致的原理。我们在操作的时候如果发现召回的内容非常少,这个时候有两种策略:不给用户推荐和给用户推荐相似的内容。
如果我们要推荐相似内容,我们实际上最简单的方法就是去找关键词的相似关键词,或者直接拿这个关键词与我们关键词库的每一个词做距离计算,找到距离最相机的几个关键词,然后再将这些关键词作为目标关键词进行关键词召回,这样就能够召回更多的内容进行推荐。
你能看到,关键词召回需要联合其他形式才能起到最好的效果。
提取关键词的几种常见算法
说完关键词召回怎么做之后,我们进入到提取关键词的算法部分。
TF-IDF算法
要了解TF-IDF算法,需要先澄清三个概念:词频、去停用词和逆文档频率。以文档$D$为例,用$\omega$来表示一个关键词,可用以下公式统计出$\omega$在文档$D$中出现的频率,即“词频(Term Frequency, TF)”。
$TF_{\omega,D_{i}}=\frac{count(\omega)}{D_{i}}$
下面这个公式就是上面公式的文字化表示。

我们经常会发现,用词频算法提取的词往往是“的”“是”“在”这类词,这类词即为“停用词”。在进行关键词提取的任务中,去停用词是一个非常必要的前提条件,只有做完去停用词之后,统计出来的结果才是相对准确的。
假定文档题目是《中国人均收入调查》,那么提取的关键词很有可能是“中国”“收入”“GDP”等词,而这类词虽然是这篇文章中的关键词,但并不能代表整篇文章的特性,因为这类词在其他的文章中也是高频词。那么怎么才能找到一个词,它既是关键词又能代表这篇文章的特性呢?这个时候我们需要一个新的名词,即“逆文档频率”(Inverse Document Frequency,IDF),文档总数$n$与词$\omega$所出现文件数$doc(\omega,D)$比值的对数,可以表示为下面这个公式。
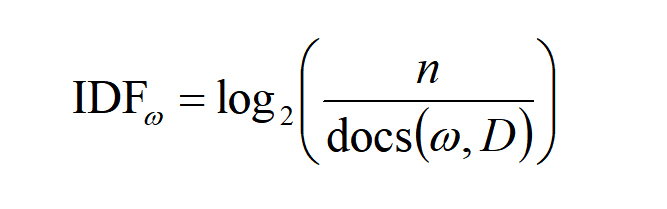
下面这个公式就是上面公式的文字化表示。
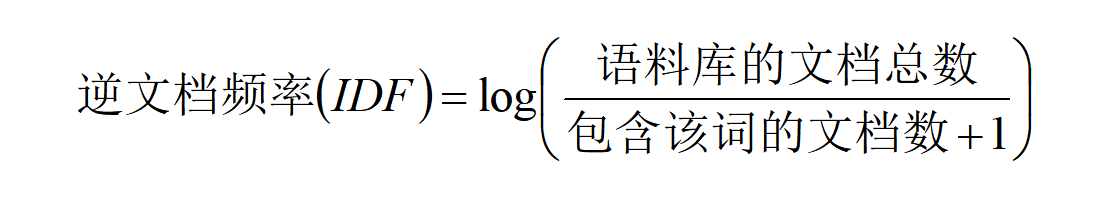
从上面公式可以看出,如果一个词越常见(如“中国”“收入”“GDP”),那么其逆文档频率就会越小。也就是说,逆文档频率越大,关键词在其他的文档中出现概率越小,意味着越是这篇文章的关键词。为了避免逆文档频率大到所有的文档都不包含该关键词,上述公式的分母加上1。
那么,一篇文档的TF-IDF值就与一个词在文档中出现的次数成正比,与该词在其他文档中出现的次数成反比。
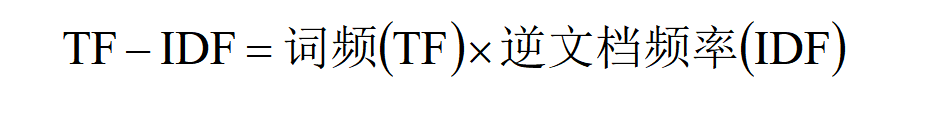
因此,TF-IDF算法即对关键词的TF-IDF值做降序排序,最后取前N个关键词作为最终的结果。
TextRank算法
与TF-IDF不同,TextRank在进行关键词提取时能够考虑到相邻词语之间的语义关系,而TF-IDF只是针对每个词的词频进行统计,并没有充分考虑词之间的语义信息。这就衍生出TextRank的另外一个优势:脱离语料库。
脱离语料库是指TextRank并不需要像TF-IDF一样使用语料库进行训练,而是直接针对单篇文章就可以进行关键词的提取,因此TextRank算法对于小批量数据来说是一个非常理想的选择。
从原理上来讲,TextRank算法是基于PageRank算法衍生出来的。其核心思想是通过词之间的相邻关系构建网络,然后用PageRank迭代计算每个节点的rank值,排序rank值即可得到关键词。
TextRank算法是一个无向图的算法。所谓的无向是指两个词之间的边是无向的,这也是TextRank算法与PageRank算法最大的区别。
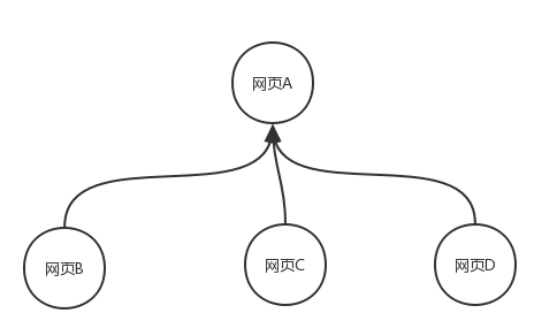
我们先简要地介绍一下PageRank算法。PageRank算法是Google用来计算网页权重值的一种算法,在PageRank算法中,如果一个链接的权重值越大,说明这个链接就越重要。假设现在有四个网页分别为网页A、网页B、网页C和网页D,在这四个网页中,所有除了网页A的网页都只链接到了网页A,那么A的PR(PageRank)值就是网页B、网页C和网页D的PageRank值的总和,如图所示。
可以用下面这个公式来表示。
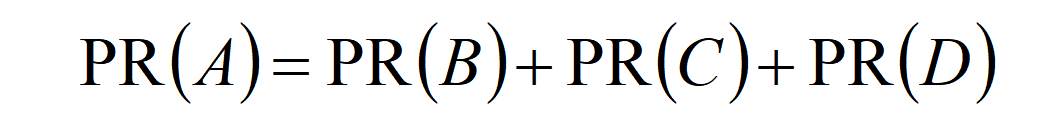
如果我们重新定义一下这四个网页的指向关系,网页B指向网页A和网页C、网页C指向网页A,网页D指向其他的所有网页,那么就有下图。
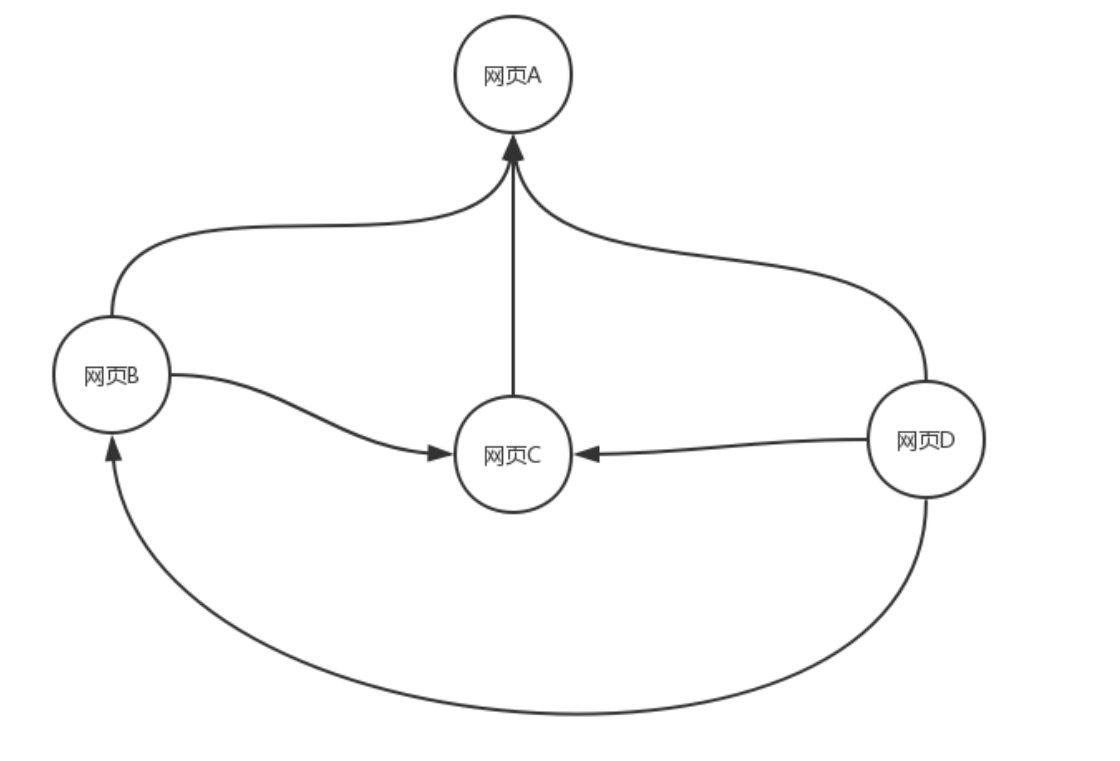
网页B有两个向外的链接,其中一个链接到了网页A,因此,网页A对于网页B的PR值为$\frac{PR(B)}{2}$;网页C只有1个向外的链接(即网页A),因此,网页C对于网页A的PR值为$\frac{PR©}{1}$;网页D有3个向外的链接,其中一个链接到了网页A,因此,网页D对于网页A的PR值为$\frac{PR(D)}{3}$。由此得到网页A的总的PR值为下面这个公式。
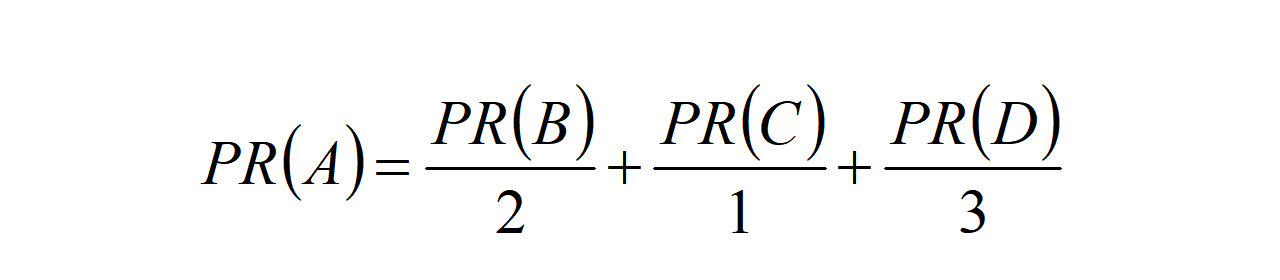
在实际PR值的计算中我们还要考虑到,当用户到达某个页面之后,是否还会继续通过这个页面向前。因此我们需要在PR值的计算中增加一项阻尼系数$d$,因此我们可以得到下面这个PR算法的推广公式。
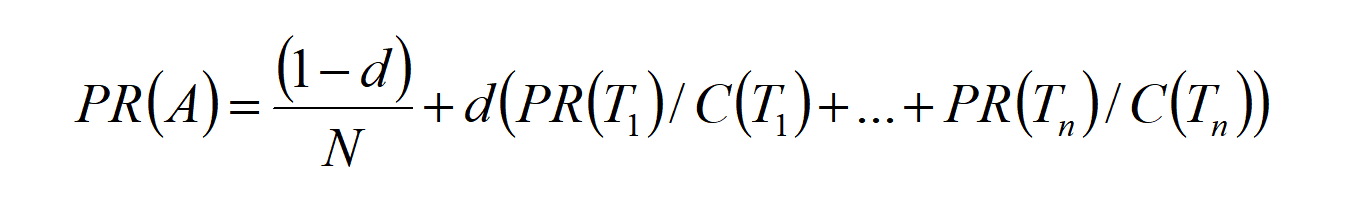
其中d为阻尼系数,表示在任意时刻,用户到达某页面后并继续向后浏览的概率;$PR(T_{i})$代表页面$T_{i}$的PR值;$C(T_{i})$代表页面$T_{i}$指向其他页面的边的个数。
当然,这只是PR值计算的最基本的形式,在实际Google的PR算法中还有很多其他的变形以及其他系数,并且每隔一段时间这个系数和公式还会有微调。然后Google利用PR算法,当用户在Google上进行搜索时,就会计算与搜索关键词相关联的网页并计算出这些网页的PR值,然后将计算出来的PR值倒序排序,根据PR值从大到小的结果展示给用户。
TextRank算法实际上是PageRank算法的一个变体,其中最大的变化在于PageRank算法是基于网页,而TextRank算法是基于词;另外PageRank算法中网页之间是一个有向关系,也就是说网页之间是有很明确的方向性,而TextRank算法是一个无向图,也就是说我们在表示两个词之间的权重时,对于两个词来讲是相同的。
因此,我们可以类比PageRank算法来说明一下TextRank提取关键词的具体思路。
- 对整个文本进行句子切分。
- 将待提取关键词的文本语句进行数据清洗,包括去停用词、无用词和标点符号、然后对其进行分词处理,形成候选关键词。
- 构建候选关键词的图,这个图可以表示为G(V,E),其中V是由第2步生成的结果集,采用共现结果的方式;E是由两个节点之间的边组成,可以把E看出V×V的集合;图中任意两个点之间的权重$V_{i}$和$V_{j}$之间边的权重可以表示为$W_{ij}$。对于给定的点$V_{i}$来说, $In(V_{i})$为 指向该点的点集合, $Out(V_{i})$为点$V_{i}$指向的点集合。由此,我们可以通过下面这个公式算出点$V_{i}$的权重值。
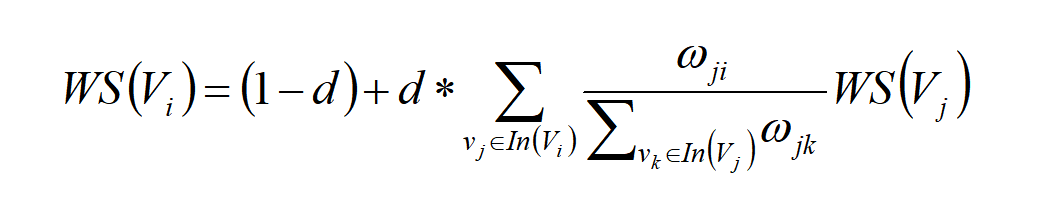
- 根据第三步中给出的公式,初始化各个节点的权重,然后迭代计算各个节点的权重,直至收敛。在这里的收敛是指经过N轮迭代,使得得到一个相对稳定的误差,而这个误差小于某个规定的阈值之内(一般我们将这个阈值设置为0.001)。
- 对上述得到的各个节点的权重进行倒序排序,从而得到这个文本中最重要的N个词,作为候选关键词。
- 将第五步得到的候选关键词在原始的文本中进行标记,如果形成了相邻的词组,则组成一个多词关键词。
到这里,使用TextRank算法得到关键词的整套流程也就结束了。
两种算法联合提取关键词
前面的实现全部基于一种算法,但是在真正的企业工程化中,我们往往使用多种算法进行联合关键词提取。
在进行关键词提取之前,首先要对自己准备提取关键词的文本有比较全面的了解。虽然每个算法都能进行关键词提取,但是针对不同的文本内容及文本量来说,每种关键词提取算法的表现是不同的。
比如,当文本量大到可组成一个数据集时,我们可以考虑使用TF-IDF算法作为关键词提取的主要算法;但是如果文本量相对比较少(或者针对某一篇文章来进行关键词提取),那么常见做法就是使用TextRank算法。
单独使用一种算法的话,关键词提取的准确率会大打折扣,那么最好的做法就是联合使用几种算法,常见的做法是TF-IDF+TextRank。
不同算法关注的重点不同,就会导致结果差异比较大。例如针对下面同样一段文本,我们使用TF-IDF和TextRank来做一个对比。
北京时间5月28日消息,据《北京青年报》官微透露,北京中赫国安归化球员李可将入选新一期国家队的大名单。而他将成为国足历史首位归化国脚,目前相关手续应该已经得到落实,意味着李可具备代表中国队参赛的资格。北京时间5月28日消息,据《北京青年报》官微透露,北京中赫国安归化球员李可将入选新一期国家队的大名单。而他将成为国足历史首位归化国脚,目前相关手续应该已经得到落实,意味着李可具备代表中国队参赛的资格。
对这段文本进行数据清洗后,得到如下文本。
北京时间5月28日消息,据《北京青年报》官微透露,北京中赫国安归化球员李可将入选新一期国家队的大名单。而他将成为国足历史首位归化国脚,目前相关手续应该已经得到落实,意味着李可具备代表中国队参赛的资格。北京时间5月28日消息,据《北京青年报》官微透露,北京中赫国安归化球员李可将入选新一期国家队的大名单。而他将成为国足历史首位归化国脚,目前相关手续应该已经得到落实,意味着李可具备代表中国队参赛的资格。
然后使用开源jieba库编写的整体算法进行处理,代码如下。
import jieba
import jieba.analyse
from segment import Segment
class Model(object):
def __init__(self):
self.seg = Segment("../common/data/stopword.txt", "../common/data/user_dict.txt")
def process_text(self, text):
words_list = self.seg.cut(text)
words_list = ' '.join(words_list)
return words_list
def get_keyword(self, words_list, param, use_pos=True):
if use_pos:
# 选定部分词性
allow_pos = ('n', 'nr', 'nr1', 'nr2', 'ns', 'nsf', 'nt', 'nz', 'nl', 'ng', 'nr', 'vn')
else:
allow_pos = ()
if param == 'tfidf':
tfidf_keywords = jieba.analyse.extract_tags(words_list, topK=10, withWeight=False, allowPOS=allow_pos)
return tfidf_keywords
elif param == 'textrank':
textrank_keywords = jieba.analyse.textrank(words_list, topK=10, withWeight=False, allowPOS=allow_pos)
return textrank_keywords
def keyword_interact(self, tfidf_keyword, textrank_keyword):
return list(set(tfidf_keyword).intersection(set(textrank_keyword)))
def keyword_topk(self, tfidf_keyword, textrank_keyword, k):
combine = list(tfidf_keyword)
for word in textrank_keyword:
combine.append(word)
return list(set(combine))
if __name__ == "__main__":
model = Model()
text = '北京时间5月28日消息,据《北京青年报》官微透露,北京中赫国安归化球员李可将入选新一期国家队的大名单。而他将成为国足历史首位归化国脚,目前相关手续应该已经得到落实,意味着李可具备代表中国队参赛的资格。北京时间5月28日消息,据《北京青年报》官微透露,北京中赫国安归化球员李可将入选新一期国家队的大名单。而他将成为国足历史首位归化国脚,目前相关手续应该已经得到落实,意味着李可具备代表中国队参赛的资格。'
words_list = model.process_text(text)
tfidf_keyword = model.get_keyword(words_list, param='tfidf')
print('tfidf_keyword', tfidf_keyword)
textrank_keyword = model.get_keyword(words_list, param='textrank')
print("textrank_keyword", textrank_keyword)
keyword_interact = model.keyword_interact(tfidf_keyword, textrank_keyword)
print('keyword_interact', keyword_interact)
keyword_topk = model.keyword_topk(tfidf_keyword, textrank_keyword, 3)
print('keyword_topk', keyword_topk)
使用TFIDF算法提取的关键词如下。
使用TextRank算法提取的关键词如下。
在企业中有两种方法联合算法,一种是取两种算法的交集(即这两种算法都认为是关键词的部分),那么我们认为这个关键词一定就能代表文章;另外一种是用两种算法的交集与每种算法的Top3关键词求并集,这样做默认了每种算法的前三个关键词都是真正的关键词。
方法一:两种算法的交集,我们可以得出的结果关键词集合如下。
方法二:两种算法的交集与每种算法的Top3关键词求并集,我们可以得出的结果关键词集合如下。
从结果可以看出,方法一(取算法交集)的效果会更好一些。但是实际上在企业中,效果的好坏要根据实际的文本类型进行实验才能得出,而不是通过其他人的实验结果简单粗暴地做出结论。
总结
到这里,这节课就已经接近尾声了,我们来对今天的课程做一个简单的总结。学完今天的课程,你应该知道下面这三个要点。
- 什么是基于关键词的召回算法。
- 基于关键词的召回算法一般是如何实现的。
- 提取关键词中两种常见的算法:TF-IDF和TextRank算法,以及这两种算法的实现原理。
课后题
最后你布置两个小作业。
- 使用关键词提取技术提取我们爬取的文章内容。
- 想一想,我们还可以用关键词召回算法配合哪些算法进行使用。
- peter 👍(1) 💬(1)
关键词的获取,是否有现成的可用的工具?就是说拿来就能用、基本不用开发。比如我要搭建一个推荐系统,也用到了关键词获取,导入一个库然后调用其API就可以直接获取;或者运行一个工具软件,可以直接获取;或者某个平台提供该服务。等等。
2023-05-16 - Weitzenböck 👍(0) 💬(2)
老师,能提供一下stopword.txt和user_dict.txt,而且我在运行代码的时候出现了定义Segment
2023-09-05 - Weitzenböck 👍(0) 💬(1)
这个课程真的是一点代码和资料的github都没有吗?
2023-09-05 - Geek_ccc0fd 👍(0) 💬(2)
我装的jieba==0.42.1可以直接对句子提取关键词,分词的部分已经封装在jieba代码里面了,修改了一下关键词提取代码: import jieba from jieba.analyse import extract_tags from jieba.analyse import textrank class KeywordModel(object): def __init__(self): jieba.load_userdict('../data/user_dict.csv') jieba.analyse.set_stop_words('../data/stopWord.txt') def get_keywords(self, sentence, type, topK=10, pos=('ns', 'n', 'vn', 'v')): """ 获取关键词 :param sentence: 文本 :param type: 使用哪种关键词算法,可选:tfidf,textrank :param topK: 获取topK关键词 :param pos: 分词保留的词性类型,eg:('ns', 'n', 'vn', 'v') :return: """ if type == 'tfidf': tfidf_keywords = extract_tags(sentence, topK=topK, allowPOS=pos) return tfidf_keywords elif type == 'textrank': textrank_keywords = textrank(sentence, topK=topK, allowPOS=pos) return textrank_keywords def keyword_interact(self, tfidf_keyword, textrank_keyword): """ 关键词交集 :param tfidf_keyword: :param textrank_keyword: :return: """ return list(set(tfidf_keyword).intersection(set(textrank_keyword))) def keyword_combine(self, tfidf_keyword, textrank_keyword): """ 关键词并集 :param tfidf_keyword: :param textrank_keyword: :param k: :return: """ combine = list(tfidf_keyword) for word in textrank_keyword: combine.append(word) return list(set(combine)) def keyword_combine_topk(self, tfidf_keyword, textrank_keyword, k): """ 关键词topk并集 :param tfidf_keyword: :param textrank_keyword: :param k: :return: """ combine = list(tfidf_keyword[:k]) for word in textrank_keyword[:k]: combine.append(word) return list(set(combine))
2023-05-16 - 翡翠虎 👍(0) 💬(2)
有常用的停用词表吗
2023-05-15 - Juha 👍(2) 💬(0)
老师,这里的from segment import Segment,segment怎么安装呀,通过pip install segment的这个包没有Segment
2024-02-28 - Geek_33ecd9 👍(0) 💬(0)
https://github.com/ipeaking/scrapy_sina 这个github没有MongoDB相关的代码呀?
2024-11-18