23丨SVM(下):如何进行乳腺癌检测?
讲完了SVM的原理之后,今天我来带你进行SVM的实战。
在此之前我们先来回顾一下SVM的相关知识点。SVM是有监督的学习模型,我们需要事先对数据打上分类标签,通过求解最大分类间隔来求解二分类问题。如果要求解多分类问题,可以将多个二分类器组合起来形成一个多分类器。
上一节中讲到了硬间隔、软间隔、非线性SVM,以及分类间隔的公式,你可能会觉得比较抽象。这节课,我们会在实际使用中,讲解对工具的使用,以及相关参数的含义。
如何在sklearn中使用SVM
在Python的sklearn工具包中有SVM算法,首先需要引用工具包:
SVM既可以做回归,也可以做分类器。
当用SVM做回归的时候,我们可以使用SVR或LinearSVR。SVR的英文是Support Vector Regression。这篇文章只讲分类,这里只是简单地提一下。
当做分类器的时候,我们使用的是SVC或者LinearSVC。SVC的英文是Support Vector Classification。
我简单说一下这两者之前的差别。
从名字上你能看出LinearSVC是个线性分类器,用于处理线性可分的数据,只能使用线性核函数。上一节,我讲到SVM是通过核函数将样本从原始空间映射到一个更高维的特质空间中,这样就使得样本在新的空间中线性可分。
如果是针对非线性的数据,需要用到SVC。在SVC中,我们既可以使用到线性核函数(进行线性划分),也能使用高维的核函数(进行非线性划分)。
如何创建一个SVM分类器呢?
我们首先使用SVC的构造函数:model = svm.SVC(kernel=‘rbf’, C=1.0, gamma=‘auto’),这里有三个重要的参数kernel、C和gamma。
kernel代表核函数的选择,它有四种选择,只不过默认是rbf,即高斯核函数。
- linear:线性核函数
- poly:多项式核函数
- rbf:高斯核函数(默认)
- sigmoid:sigmoid核函数
这四种函数代表不同的映射方式,你可能会问,在实际工作中,如何选择这4种核函数呢?我来给你解释一下:
线性核函数,是在数据线性可分的情况下使用的,运算速度快,效果好。不足在于它不能处理线性不可分的数据。
多项式核函数可以将数据从低维空间映射到高维空间,但参数比较多,计算量大。
高斯核函数同样可以将样本映射到高维空间,但相比于多项式核函数来说所需的参数比较少,通常性能不错,所以是默认使用的核函数。
了解深度学习的同学应该知道sigmoid经常用在神经网络的映射中。因此当选用sigmoid核函数时,SVM实现的是多层神经网络。
上面介绍的4种核函数,除了第一种线性核函数外,其余3种都可以处理线性不可分的数据。
参数C代表目标函数的惩罚系数,惩罚系数指的是分错样本时的惩罚程度,默认情况下为1.0。当C越大的时候,分类器的准确性越高,但同样容错率会越低,泛化能力会变差。相反,C越小,泛化能力越强,但是准确性会降低。
参数gamma代表核函数的系数,默认为样本特征数的倒数,即gamma = 1 / n_features。
在创建SVM分类器之后,就可以输入训练集对它进行训练。我们使用model.fit(train_X,train_y),传入训练集中的特征值矩阵train_X和分类标识train_y。特征值矩阵就是我们在特征选择后抽取的特征值矩阵(当然你也可以用全部数据作为特征值矩阵);分类标识就是人工事先针对每个样本标识的分类结果。这样模型会自动进行分类器的训练。我们可以使用prediction=model.predict(test_X)来对结果进行预测,传入测试集中的样本特征矩阵test_X,可以得到测试集的预测分类结果prediction。
同样我们也可以创建线性SVM分类器,使用model=svm.LinearSVC()。在LinearSVC中没有kernel这个参数,限制我们只能使用线性核函数。由于LinearSVC对线性分类做了优化,对于数据量大的线性可分问题,使用LinearSVC的效率要高于SVC。
如果你不知道数据集是否为线性,可以直接使用SVC类创建SVM分类器。
在训练和预测中,LinearSVC和SVC一样,都是使用model.fit(train_X,train_y)和model.predict(test_X)。
如何用SVM进行乳腺癌检测
在了解了如何创建和使用SVM分类器后,我们来看一个实际的项目,数据集来自美国威斯康星州的乳腺癌诊断数据集,点击这里进行下载。
医疗人员采集了患者乳腺肿块经过细针穿刺(FNA)后的数字化图像,并且对这些数字图像进行了特征提取,这些特征可以描述图像中的细胞核呈现。肿瘤可以分成良性和恶性。部分数据截屏如下所示:
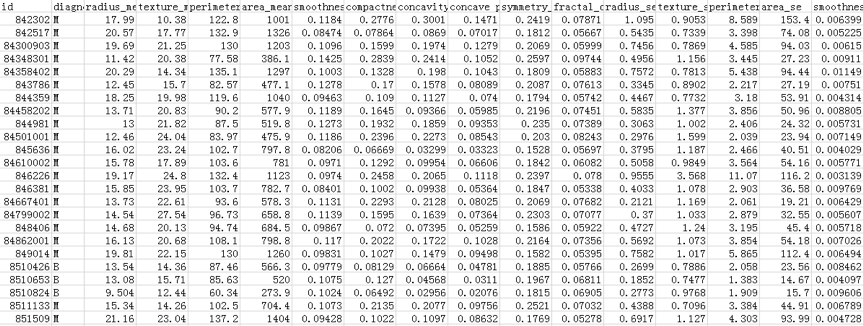 数据表一共包括了32个字段,代表的含义如下:
数据表一共包括了32个字段,代表的含义如下:
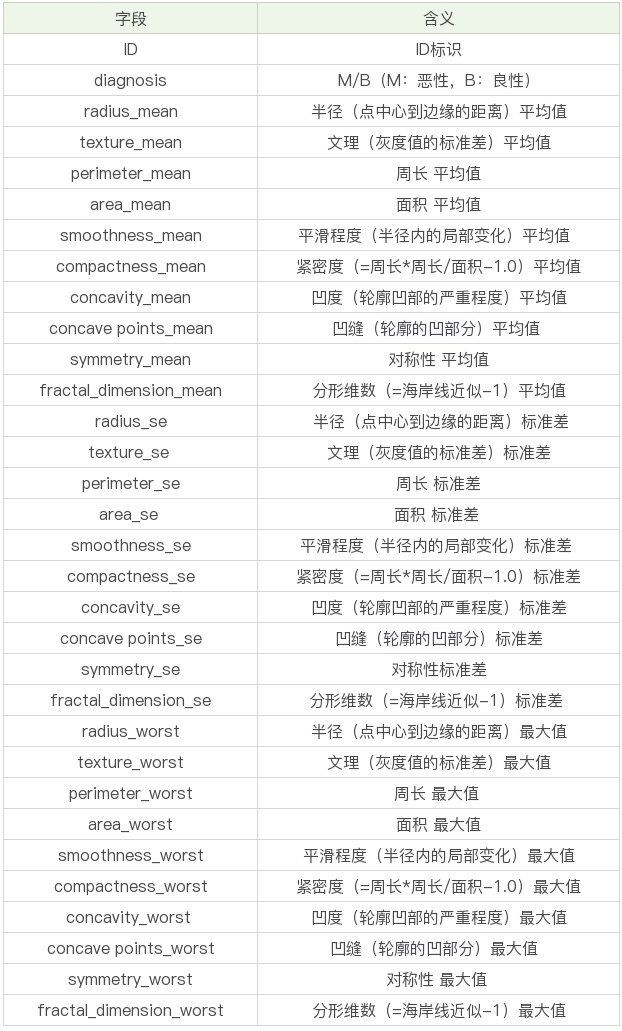
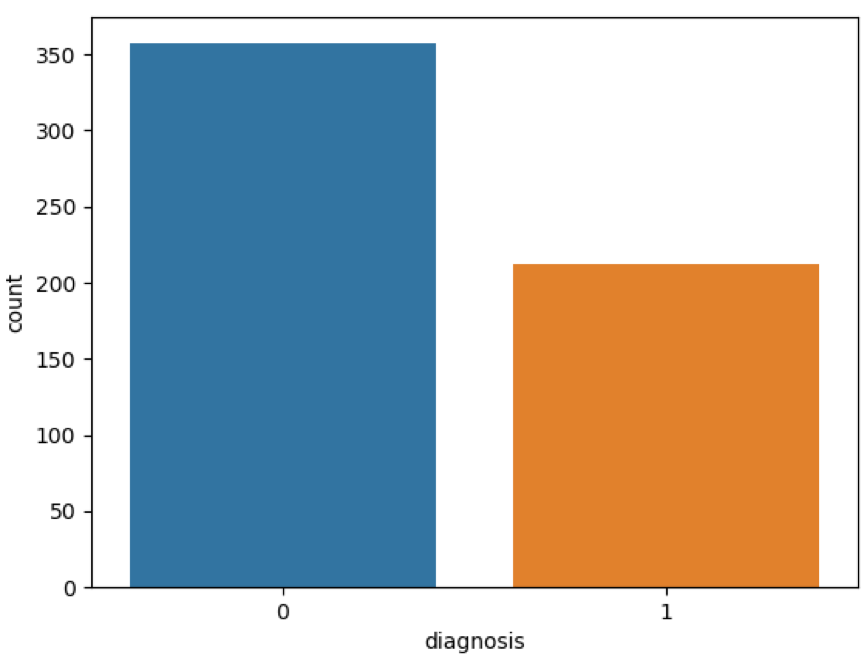
上面的表格中,mean代表平均值,se代表标准差,worst代表最大值(3个最大值的平均值)。每张图像都计算了相应的特征,得出了这30个特征值(不包括ID字段和分类标识结果字段diagnosis),实际上是10个特征值(radius、texture、perimeter、area、smoothness、compactness、concavity、concave points、symmetry和fractal_dimension_mean)的3个维度,平均、标准差和最大值。这些特征值都保留了4位数字。字段中没有缺失的值。在569个患者中,一共有357个是良性,212个是恶性。
好了,我们的目标是生成一个乳腺癌诊断的SVM分类器,并计算这个分类器的准确率。首先设定项目的执行流程:
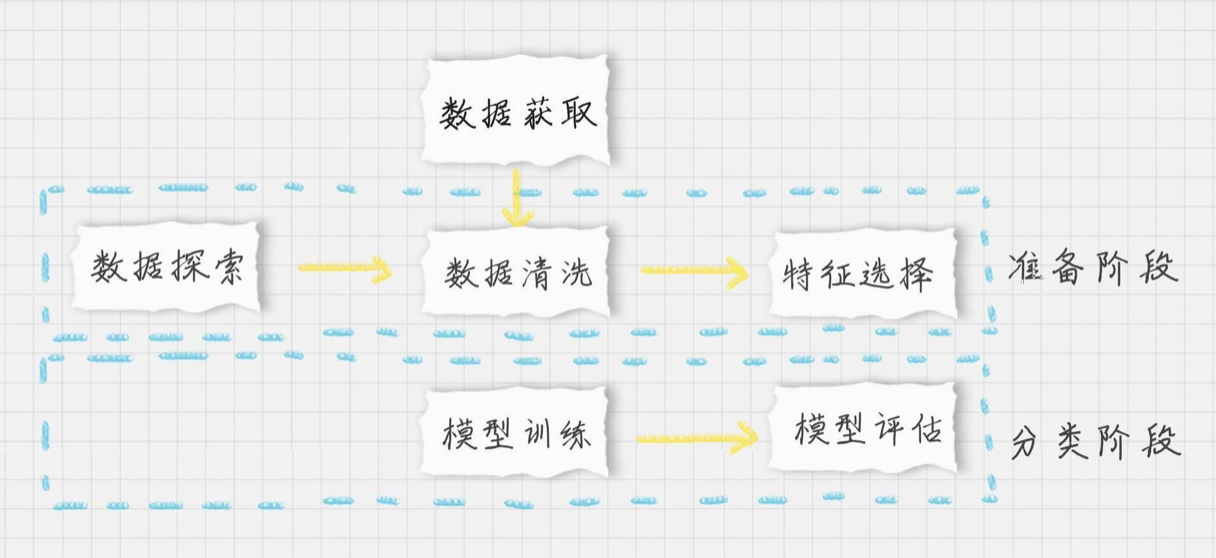
- 首先我们需要加载数据源;
- 在准备阶段,需要对加载的数据源进行探索,查看样本特征和特征值,这个过程你也可以使用数据可视化,它可以方便我们对数据及数据之间的关系进一步加深了解。然后按照“完全合一”的准则来评估数据的质量,如果数据质量不高就需要做数据清洗。数据清洗之后,你可以做特征选择,方便后续的模型训练;
- 在分类阶段,选择核函数进行训练,如果不知道数据是否为线性,可以考虑使用SVC(kernel=‘rbf’) ,也就是高斯核函数的SVM分类器。然后对训练好的模型用测试集进行评估。
按照上面的流程,我们来编写下代码,加载数据并对数据做部分的探索:
# 加载数据集,你需要把数据放到目录中
data = pd.read_csv("./data.csv")
# 数据探索
# 因为数据集中列比较多,我们需要把dataframe中的列全部显示出来
pd.set_option('display.max_columns', None)
print(data.columns)
print(data.head(5))
print(data.describe())
这是部分的运行结果,完整结果你可以自己跑一下。
Index(['id', 'diagnosis', 'radius_mean', 'texture_mean', 'perimeter_mean',
'area_mean', 'smoothness_mean', 'compactness_mean', 'concavity_mean',
'concave points_mean', 'symmetry_mean', 'fractal_dimension_mean',
'radius_se', 'texture_se', 'perimeter_se', 'area_se', 'smoothness_se',
'compactness_se', 'concavity_se', 'concave points_se', 'symmetry_se',
'fractal_dimension_se', 'radius_worst', 'texture_worst',
'perimeter_worst', 'area_worst', 'smoothness_worst',
'compactness_worst', 'concavity_worst', 'concave points_worst',
'symmetry_worst', 'fractal_dimension_worst'],
dtype='object')
id diagnosis radius_mean texture_mean perimeter_mean area_mean \
0 842302 M 17.99 10.38 122.80 1001.0
1 842517 M 20.57 17.77 132.90 1326.0
2 84300903 M 19.69 21.25 130.00 1203.0
3 84348301 M 11.42 20.38 77.58 386.1
4 84358402 M 20.29 14.34 135.10 1297.0
接下来,我们就要对数据进行清洗了。
运行结果中,你能看到32个字段里,id是没有实际含义的,可以去掉。diagnosis字段的取值为B或者M,我们可以用0和1来替代。另外其余的30个字段,其实可以分成三组字段,下划线后面的mean、se和worst代表了每组字段不同的度量方式,分别是平均值、标准差和最大值。
# 将特征字段分成3组
features_mean= list(data.columns[2:12])
features_se= list(data.columns[12:22])
features_worst=list(data.columns[22:32])
# 数据清洗
# ID列没有用,删除该列
data.drop("id",axis=1,inplace=True)
# 将B良性替换为0,M恶性替换为1
data['diagnosis']=data['diagnosis'].map({'M':1,'B':0})
然后我们要做特征字段的筛选,首先需要观察下features_mean各变量之间的关系,这里我们可以用DataFrame的corr()函数,然后用热力图帮我们可视化呈现。同样,我们也会看整体良性、恶性肿瘤的诊断情况。
# 将肿瘤诊断结果可视化
sns.countplot(data['diagnosis'],label="Count")
plt.show()
# 用热力图呈现features_mean字段之间的相关性
corr = data[features_mean].corr()
plt.figure(figsize=(14,14))
# annot=True显示每个方格的数据
sns.heatmap(corr, annot=True)
plt.show()
这是运行的结果:
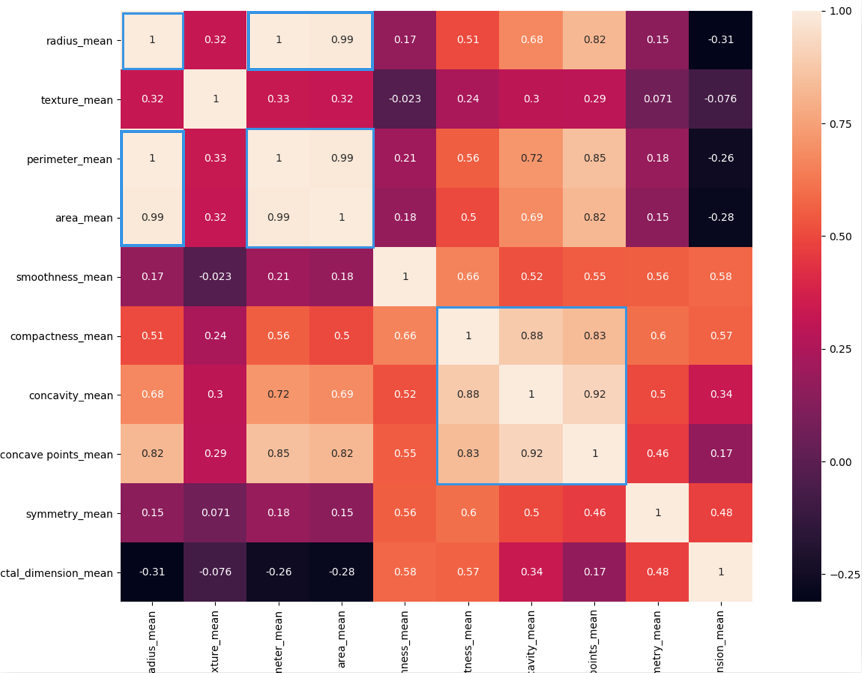 热力图中对角线上的为单变量自身的相关系数是1。颜色越浅代表相关性越大。所以你能看出来radius_mean、perimeter_mean和area_mean相关性非常大,compactness_mean、concavity_mean、concave_points_mean这三个字段也是相关的,因此我们可以取其中的一个作为代表。
热力图中对角线上的为单变量自身的相关系数是1。颜色越浅代表相关性越大。所以你能看出来radius_mean、perimeter_mean和area_mean相关性非常大,compactness_mean、concavity_mean、concave_points_mean这三个字段也是相关的,因此我们可以取其中的一个作为代表。
那么如何进行特征选择呢?
特征选择的目的是降维,用少量的特征代表数据的特性,这样也可以增强分类器的泛化能力,避免数据过拟合。
我们能看到mean、se和worst这三组特征是对同一组内容的不同度量方式,我们可以保留mean这组特征,在特征选择中忽略掉se和worst。同时我们能看到mean这组特征中,radius_mean、perimeter_mean、area_mean这三个属性相关性大,compactness_mean、daconcavity_mean、concave points_mean这三个属性相关性大。我们分别从这2类中选择1个属性作为代表,比如radius_mean和compactness_mean。
这样我们就可以把原来的10个属性缩减为6个属性,代码如下:
# 特征选择
features_remain = ['radius_mean','texture_mean', 'smoothness_mean','compactness_mean','symmetry_mean', 'fractal_dimension_mean']
对特征进行选择之后,我们就可以准备训练集和测试集:
# 抽取30%的数据作为测试集,其余作为训练集
train, test = train_test_split(data, test_size = 0.3)# in this our main data is splitted into train and test
# 抽取特征选择的数值作为训练和测试数据
train_X = train[features_remain]
train_y=train['diagnosis']
test_X= test[features_remain]
test_y =test['diagnosis']
在训练之前,我们需要对数据进行规范化,这样让数据同在同一个量级上,避免因为维度问题造成数据误差:
# 采用Z-Score规范化数据,保证每个特征维度的数据均值为0,方差为1
ss = StandardScaler()
train_X = ss.fit_transform(train_X)
test_X = ss.transform(test_X)
最后我们可以让SVM做训练和预测了:
# 创建SVM分类器
model = svm.SVC()
# 用训练集做训练
model.fit(train_X,train_y)
# 用测试集做预测
prediction=model.predict(test_X)
print('准确率: ', metrics.accuracy_score(test_y,prediction))
运行结果:
准确率大于90%,说明训练结果还不错。完整的代码你可以从GitHub上下载。
总结
今天我带你一起做了乳腺癌诊断分类的SVM实战,从这个过程中你应该能体会出来整个执行的流程,包括数据加载、数据探索、数据清洗、特征选择、SVM训练和结果评估等环节。
sklearn已经为我们提供了很好的工具,对上节课中讲到的SVM的创建和训练都进行了封装,让我们无需关心中间的运算细节。但正因为这样,我们更需要对每个流程熟练掌握,通过实战项目训练数据化思维和对数据的敏感度。
 最后给你留两道思考题吧。还是这个乳腺癌诊断的数据,请你用LinearSVC,选取全部的特征(除了ID以外)作为训练数据,看下你的分类器能得到多少的准确度呢?另外你对sklearn中SVM使用又有什么样的体会呢?
最后给你留两道思考题吧。还是这个乳腺癌诊断的数据,请你用LinearSVC,选取全部的特征(除了ID以外)作为训练数据,看下你的分类器能得到多少的准确度呢?另外你对sklearn中SVM使用又有什么样的体会呢?
欢迎在评论区与我分享你的答案,也欢迎点击“请朋友读”,把这篇文章分享给你的朋友或者同事,一起来交流,一起来进步。
- Geek_dancer 👍(46) 💬(2)
默认SVC训练模型,6个特征变量,训练集准确率:96.0%,测试集准确率:92.4% 默认SVC训练模型,10个特征变量,训练集准确率:98.7% ,测试集准确率:98.2% LinearSVC训练模型, 6个特征变量, 训练集准确率:93.9%,测试集准确率:92.3% LinearSVC训练模型, 10个特征变量, 训练集准确率:99.4%,测试集准确率:96.0% 结论: 1. 增加特征变量可以提高准确率,可能是因为模型维度变高,模型变得更加复杂。可以看出特征变量的选取很重要。 2. 训练集拟合都比较好,但是测试集准确率出现不同程度的下降。 3. 模型训练的准确率与人类水平之间偏差可以通过增加特征变量或采用新的训练模型来降低;模型训练的准确率与测试集测试的准确率之间的方差可以通过正则化,提高泛化性能等方式来降低。
2019-02-27 - 滢 👍(14) 💬(1)
利用SVM做分类,特征选择影响度大,要想SVM分类准确,人工处理数据这一步很重要
2019-04-18 - hlz-123 👍(11) 💬(1)
首先要说,老师的课讲得非常好,深奥的算法和理论通过生动有趣的例子让人通俗易懂,兴趣盎然。 老师的本课案例中,对特征数据都做了Z-Score规范化处理(正态分布),准确率在90%以上,如果数据不做规范化处理,准确率在88%左右,我的问题: 1、数据规范化处理,是不是人为地提供了准确率?实际情况,数据不一定是正态分布。 2、模型建好后,在实际应用中去评估某个案例时,该案例数据是不是也要规范化,这样做是不是很麻烦并且数据对比不是很直观呢?
2019-03-16 - Rickie 👍(7) 💬(1)
思考题: 使用全部数据进行训练得到的准确率为0.9766,高于示例中的准确率。是否是由于多重共线性,使得测试结果偏高?
2019-02-05 - 明翼 👍(4) 💬(3)
老师我利用了结果和特征的相关性,选择特征,发现结果更好: # 特征选择 按照结果和数据相关性选择特征准确率0.9707602339181286 features_remain = ['radius_mean','perimeter_mean','area_mean','concave points_mean','radius_worst','perimeter_worst','area_worst','concave points_worst']
2019-11-10 - Ricky 👍(2) 💬(1)
谢谢,提2个问题, 1)在实际应用中如何平衡特征变量和准确率的关系?有没有方法论? 增加特征变量意味着增加运算时间,提高准确率,但是这个得失怎么把握?同时如何评估会增加多少运算时间,一个一个尝试似乎比较费劲吧 2)此文的案例是选用平均值,丢弃了最大值和标准差,这个是多少案例的通用做法么? 谢谢
2020-04-15 - 恬恬 👍(2) 💬(2)
对比几组feature后,发现用feature_worst进行训练,效果更好。 1)SVC(kernel='linear')的测试集准确率为:99.42%; 2) LinearSVC()的测试集准确率为:97.07% 2)SVC()的测试集准确率为:96.49% 觉得建模过程中,特征选择很重要,不同的数据集划分,正负样本是否平衡也会对结果有一定的影响,所以最好是可以采用交叉验证来训练模型。这个地方多次测试SVC(kernel='linear')和LinearSVC(),感觉还是会存在2个百分点左右的差异,这两个都算是线性分类,是因为采用了不同的线性核函数吗?还是其他参数或是方法差异的原因呢?
2020-03-31 - 滢 👍(2) 💬(1)
语言Python3.6 没有z-score规范化数据以及规范化后两种情况前提预测准确率,使用LinearSVC,选取所有mean属性 import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.model_selection import train_test_split from sklearn import svm from sklearn import metrics from sklearn.preprocessing import StandardScaler #导入数据 path = '/Users/apple/Desktop/GitHubProject/Read mark/数据分析/geekTime/data/' data = pd.read_csv(path + 'breast_cancer/data.csv') #数据探索 pd.set_option('display.max_columns', None) print(data.columns) print(data.head(5)) print(data.describe()) #将特征字段进行分组 features_mean = list(data.columns[2:12]) features_se = list(data.columns[12:22]) features_worst = list(data.columns[22:32]) #数据清洗 #删除ID列 data.drop('id',axis=1,inplace=True) #将良性B替换为0,将恶性替换为1 data['diagnosis'] = data['diagnosis'].map({'B':0,'M':1}) #将肿瘤诊断结果可视化 sns.countplot(data['diagnosis'],label='count') plt.show() #计算相关系数 corr = data[features_mean].corr() plt.figure(figsize=(14,14)) #用热力图呈现相关性,显示每个方格的数据 sns.heatmap(corr,annot=True) plt.show() #特征选择,选择所有的mean数据 feature_remain = ['radius_mean', 'texture_mean', 'perimeter_mean', 'area_mean', 'smoothness_mean', 'compactness_mean', 'concavity_mean', 'concave points_mean', 'symmetry_mean', 'fractal_dimension_mean'] #抽取30%特征选择作为测试数据,其余作为训练集 train,test = train_test_split(data,test_size=0.3) #抽取特征选择作为训练和测试数据 train_data = train[feature_remain] train_result = train['diagnosis'] test_data = test[feature_remain] test_result = test['diagnosis'] #创建SVM分类器 model = svm.LinearSVC() #用训练集做训练 model.fit(train_data,train_result) #用测试集做预测 prediction = model.predict(test_data) #准确率 print('准确率:', metrics.accuracy_score(prediction,test_result)) #规范化数据,再预估准确率 z_score = StandardScaler() train_data = z_score.fit_transform(train_data) test_data = z_score.transform(test_data) #用新数据做训练 new_model = svm.LinearSVC() new_model.fit(train_data,train_result) #重新预测 new_prediction = new_model.predict(test_data) #准确率 print('准确率:',metrics.accuracy_score(new_prediction,test_result))
2019-04-18 - Ronnyz 👍(1) 💬(1)
选取全部特征: SVM分类器准确率: 0.9824561403508771 cross_val_score的准确率为:0.9727 linearSVM分类器的准确率: 0.9766081871345029 cross_val_score的准确率为:0.9652 选取mean相关特征: SVM分类器准确率: 0.9239766081871345 cross_val_score的准确率为:0.9321 linearSVM分类器的准确率: 0.9298245614035088 cross_val_score的准确率为:0.9247 数据结果上看: SVM的结果要好于linearSVM; 选取多特征的结果要好于选取少特征的结果
2019-11-14 - third 👍(1) 💬(1)
第二个,准确率 0.935672514619883。 感觉还蛮好用的,只是不是很熟练的使用各个算法做分类和回归
2019-02-18 - Python 👍(1) 💬(1)
老师可以用PCA进行特征选择吗?如果可以,那和你这种手动的方法比有什么差别
2019-02-04 - 晨曦 👍(0) 💬(1)
老师,如果这个病症改为不得病,轻症,重症三个分类,不是二分类问题,对应改成分类序号,0,1,2。那么这套算法是不是也不算错
2021-01-23 - 邹洲 👍(0) 💬(1)
# coding=utf-8 import pandas as pd import seaborn as sns import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler #导入sklearn中的SVM库 from sklearn import svm, metrics #构造线性分类模型 model = svm.SVC(kernel="rbf",C=1.0,gamma="auto") model2 = svm.LinearSVC() """ kernel : linear:线性模型,当模型为linearsvm时,就表明没有kernel参数 poly:多项式模型 rbf:高斯函数 sigmoid:sigmoid核函数 C:目标函数的惩罚系数 gamma :核函数系数 """ #实战开始--加载数据 data = pd.read_csv('data.csv',engine='python') # pd.set_option('display.max_columns',None) #查看一下数据信息 # print(data.columns) # print(data.info()) # print(data.head(5)) # print(data['diagnosis'].value_counts()) #数据处理 #id字段对于分类无用,删除即可 data.drop('id',axis=1,inplace=True) #diagnosis字段为字符型,组需转换为数值型0 1 data['diagnosis'] = data['diagnosis'].map({'M':1,'B':0}) feature_mean = data.columns[1:11] feature_se = data.columns[11:21] feature_max = data.columns[21:31] #统计一下肿瘤人数情况 sns.countplot(data['diagnosis'],label='Count') # plt.show() #查看各个特征的相关度 corr = data[feature_mean].corr() plt.figure(figsize=(14,14)) sns.heatmap(corr,annot=True) # plt.show() feature_sel = ['radius_mean','texture_mean','smoothness_mean','compactness_mean','symmetry_mean','fractal_dimension_mean'] train_data,test_data = train_test_split(data,test_size=0.3) train_feature = train_data[feature_sel] train_label = train_data['diagnosis'] test_feature = test_data[feature_sel] test_label = test_data['diagnosis'] #开始训练数据和测试数据 #采用Z-Score规范化处理,保证每一个特征维度的数据均值为0,方差为1 ss = StandardScaler() train_feature = ss.fit_transform(train_feature) test_feature = ss.transform(test_feature) #开始预测 model.fit(train_feature,train_label) model2.fit(train_feature,train_label) predict_label = model.predict(test_feature) predict_label2 = model2.predict(test_feature) #准确度 -- 每次运行不一样 print("高斯准确率:",metrics.accuracy_score(test_label,predict_label)) print("线性准确度:",metrics.accuracy_score(test_label,predict_label2))
2020-08-26 - 朱一江 👍(0) 💬(1)
我们所测的准确率是与train_y进行比较的吗
2020-08-22 - 鱼非子 👍(0) 💬(1)
import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn import svm from sklearn import metrics data = pd.read_csv("./data.csv") pd.set_option('display.max_columns', None) # print(data.head(5)) # print(data.columns) # print(data.describe()) features_mean = list(data.columns[2:12]) features_se = list(data.columns[12:22]) features_worst = list(data.columns[22:32]) data.drop("id",axis=1,inplace=True) data['diagnosis'] = data['diagnosis'].map({'M':1,'B':0}) # print(data.head(5)) sns.countplot(data['diagnosis'],label="Count") plt.show() corr = data[features_mean].corr() plt.figure(figsize=(14,14)) sns.heatmap(corr,annot=True) plt.show() features_remain = ['radius_mean','texture_mean', 'smoothness_mean','compactness_mean','symmetry_mean', 'fractal_dimension_mean'] X_train, X_test, y_train, y_test = train_test_split(data[features_remain], data['diagnosis'], test_size=0.3,random_state=0) # 采用Z-Score规范化数据,保证每个特征维度的数据均值为0,方差为1 ss = StandardScaler() X_train = ss.fit_transform(X_train) X_test = ss.transform(X_test) model = svm.SVC() model.fit(X_train,y_train) prediction = model.predict(X_test) print("准确率:",metrics.accuracy_score(prediction,y_test)) 准确率: 0.9239766081871345
2020-03-04