31丨关联规则挖掘(下):导演如何选择演员?
上次我给你讲了关联规则挖掘的原理。关联规则挖掘在生活中有很多使用场景,不仅是商品的捆绑销售,甚至在挑选演员决策上,你也能通过关联规则挖掘看出来某个导演选择演员的倾向。
今天我来带你用Apriori算法做一个项目实战。你需要掌握的是以下几点:
- 熟悉上节课讲到的几个重要概念:支持度、置信度和提升度;
- 熟悉与掌握Apriori工具包的使用;
- 在实际问题中,灵活运用。包括数据集的准备等。
如何使用Apriori工具包
Apriori虽然是十大算法之一,不过在sklearn工具包中并没有它,也没有FP-Growth算法。这里教你个方法,来选择Python中可以使用的工具包,你可以通过https://pypi.org/ 搜索工具包。
 这个网站提供的工具包都是Python语言的,你能找到8个Python语言的Apriori工具包,具体选择哪个呢?建议你使用第二个工具包,即efficient-apriori。后面我会讲到为什么推荐这个工具包。
这个网站提供的工具包都是Python语言的,你能找到8个Python语言的Apriori工具包,具体选择哪个呢?建议你使用第二个工具包,即efficient-apriori。后面我会讲到为什么推荐这个工具包。
首先你需要通过pip install efficient-apriori 安装这个工具包。
然后看下如何使用它,核心的代码就是这一行:
其中data是我们要提供的数据集,它是一个list数组类型。min_support参数为最小支持度,在efficient-apriori工具包中用0到1的数值代表百分比,比如0.5代表最小支持度为50%。min_confidence是最小置信度,数值也代表百分比,比如1代表100%。
关于支持度、置信度和提升度,我们再来简单回忆下。
支持度指的是某个商品组合出现的次数与总次数之间的比例。支持度越高,代表这个组合出现的概率越大。
置信度是一个条件概念,就是在A发生的情况下,B发生的概率是多少。
提升度代表的是“商品A的出现,对商品B的出现概率提升了多少”。
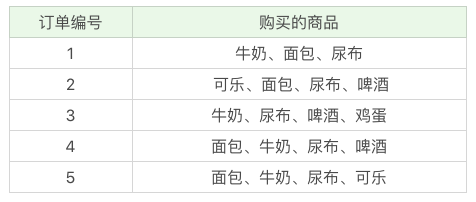
接下来我们用这个工具包,跑一下上节课中讲到的超市购物的例子。下面是客户购买的商品列表:
具体实现的代码如下:
from efficient_apriori import apriori
# 设置数据集
data = [('牛奶','面包','尿布'),
('可乐','面包', '尿布', '啤酒'),
('牛奶','尿布', '啤酒', '鸡蛋'),
('面包', '牛奶', '尿布', '啤酒'),
('面包', '牛奶', '尿布', '可乐')]
# 挖掘频繁项集和频繁规则
itemsets, rules = apriori(data, min_support=0.5, min_confidence=1)
print(itemsets)
print(rules)
运行结果:
{1: {('啤酒',): 3, ('尿布',): 5, ('牛奶',): 4, ('面包',): 4}, 2: {('啤酒', '尿布'): 3, ('尿布', '牛奶'): 4, ('尿布', '面包'): 4, ('牛奶', '面包'): 3}, 3: {('尿布', '牛奶', '面包'): 3}}
[{啤酒} -> {尿布}, {牛奶} -> {尿布}, {面包} -> {尿布}, {牛奶, 面包} -> {尿布}]
你能从代码中看出来,data是个List数组类型,其中每个值都可以是一个集合。实际上你也可以把data数组中的每个值设置为List数组类型,比如:
data = [['牛奶','面包','尿布'],
['可乐','面包', '尿布', '啤酒'],
['牛奶','尿布', '啤酒', '鸡蛋'],
['面包', '牛奶', '尿布', '啤酒'],
['面包', '牛奶', '尿布', '可乐']]
两者的运行结果是一样的,efficient-apriori 工具包把每一条数据集里的项式都放到了一个集合中进行运算,并没有考虑它们之间的先后顺序。因为实际情况下,同一个购物篮中的物品也不需要考虑购买的先后顺序。
而其他的Apriori算法可能会因为考虑了先后顺序,出现计算频繁项集结果不对的情况。所以这里采用的是efficient-apriori这个工具包。
挖掘导演是如何选择演员的
在实际工作中,数据集是需要自己来准备的,比如今天我们要挖掘导演是如何选择演员的数据情况,但是并没有公开的数据集可以直接使用。因此我们需要使用之前讲到的Python爬虫进行数据采集。
不同导演选择演员的规则是不同的,因此我们需要先指定导演。数据源我们选用豆瓣电影。
先来梳理下采集的工作流程。
首先我们先在https://movie.douban.com搜索框中输入导演姓名,比如“宁浩”。
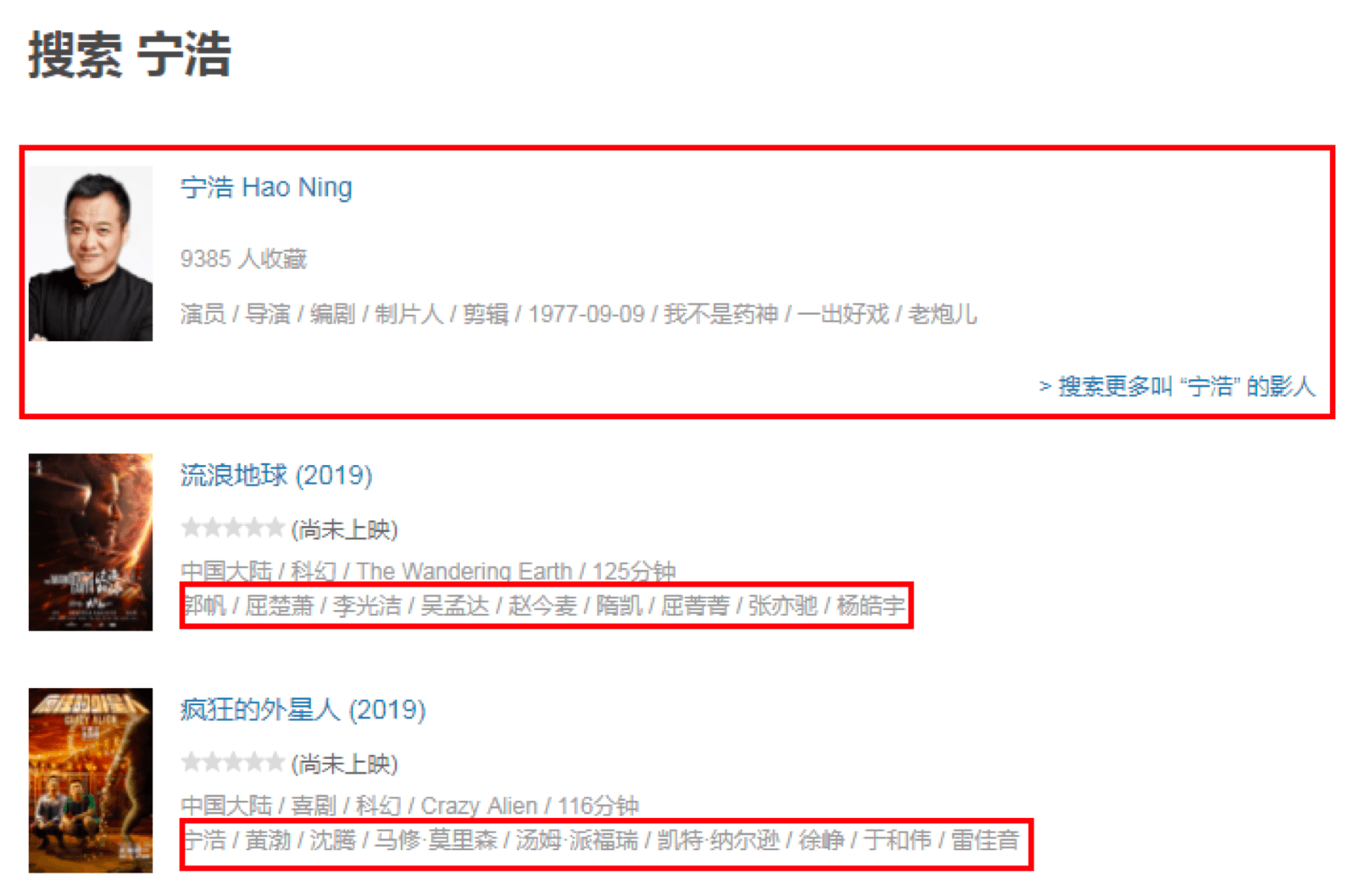 页面会呈现出来导演之前的所有电影,然后对页面进行观察,你能观察到以下几个现象:
页面会呈现出来导演之前的所有电影,然后对页面进行观察,你能观察到以下几个现象:
- 页面默认是15条数据反馈,第一页会返回16条。因为第一条数据实际上这个导演的概览,你可以理解为是一条广告的插入,下面才是真正的返回结果。
- 每条数据的最后一行是电影的演出人员的信息,第一个人员是导演,其余为演员姓名。姓名之间用“/”分割。
有了这些观察之后,我们就可以编写抓取程序了。在代码讲解中你能看出这两点观察的作用。抓取程序的目的是为了生成宁浩导演(你也可以抓取其他导演)的数据集,结果会保存在csv文件中。完整的抓取代码如下:
# -*- coding: utf-8 -*-
# 下载某个导演的电影数据集
from efficient_apriori import apriori
from lxml import etree
import time
from selenium import webdriver
import csv
driver = webdriver.Chrome()
# 设置想要下载的导演 数据集
director = u'宁浩'
# 写CSV文件
file_name = './' + director + '.csv'
base_url = 'https://movie.douban.com/subject_search?search_text='+director+'&cat=1002&start='
out = open(file_name,'w', newline='', encoding='utf-8-sig')
csv_write = csv.writer(out, dialect='excel')
flags=[]
# 下载指定页面的数据
def download(request_url):
driver.get(request_url)
time.sleep(1)
html = driver.find_element_by_xpath("//*").get_attribute("outerHTML")
html = etree.HTML(html)
# 设置电影名称,导演演员 的XPATH
movie_lists = html.xpath("/html/body/div[@id='wrapper']/div[@id='root']/div[1]//div[@class='item-root']/div[@class='detail']/div[@class='title']/a[@class='title-text']")
name_lists = html.xpath("/html/body/div[@id='wrapper']/div[@id='root']/div[1]//div[@class='item-root']/div[@class='detail']/div[@class='meta abstract_2']")
# 获取返回的数据个数
num = len(movie_lists)
if num > 15: #第一页会有16条数据
# 默认第一个不是,所以需要去掉
movie_lists = movie_lists[1:]
name_lists = name_lists[1:]
for (movie, name_list) in zip(movie_lists, name_lists):
# 会存在数据为空的情况
if name_list.text is None:
continue
# 显示下演员名称
print(name_list.text)
names = name_list.text.split('/')
# 判断导演是否为指定的director
if names[0].strip() == director and movie.text not in flags:
# 将第一个字段设置为电影名称
names[0] = movie.text
flags.append(movie.text)
csv_write.writerow(names)
print('OK') # 代表这页数据下载成功
print(num)
if num >= 14: #有可能一页会有14个电影
# 继续下一页
return True
else:
# 没有下一页
return False
# 开始的ID为0,每页增加15
start = 0
while start<10000: #最多抽取1万部电影
request_url = base_url + str(start)
# 下载数据,并返回是否有下一页
flag = download(request_url)
if flag:
start = start + 15
else:
break
out.close()
print('finished')
代码中涉及到了几个模块,我简单讲解下这几个模块。
在引用包这一段,我们使用csv工具包读写CSV文件,用efficient_apriori完成Apriori算法,用lxml进行XPath解析,time工具包可以让我们在模拟后有个适当停留,代码中我设置为1秒钟,等HTML数据完全返回后再进行HTML内容的获取。使用selenium的webdriver来模拟浏览器的行为。
在读写文件这一块,我们需要事先告诉python的open函数,文件的编码是utf-8-sig(对应代码:encoding=‘utf-8-sig’),这是因为我们会用到中文,为了避免编码混乱。
编写download函数,参数传入我们要采集的页面地址(request_url)。针对返回的HTML,我们需要用到之前讲到的Chrome浏览器的XPath Helper工具,来获取电影名称以及演出人员的XPath。我用页面返回的数据个数来判断当前所处的页面序号。如果数据个数>15,也就是第一页,第一页的第一条数据是广告,我们需要忽略。如果数据个数=15,代表是中间页,需要点击“下一页”,也就是翻页。如果数据个数<15,代表最后一页,没有下一页。
在程序主体部分,我们设置start代表抓取的ID,从0开始最多抓取1万部电影的数据(一个导演不会超过1万部电影),每次翻页start自动增加15,直到flag=False为止,也就是不存在下一页的情况。
你可以模拟下抓取的流程,获得指定导演的数据,比如我上面抓取的宁浩的数据。这里需要注意的是,豆瓣的电影数据可能是不全的,但基本上够我们用。
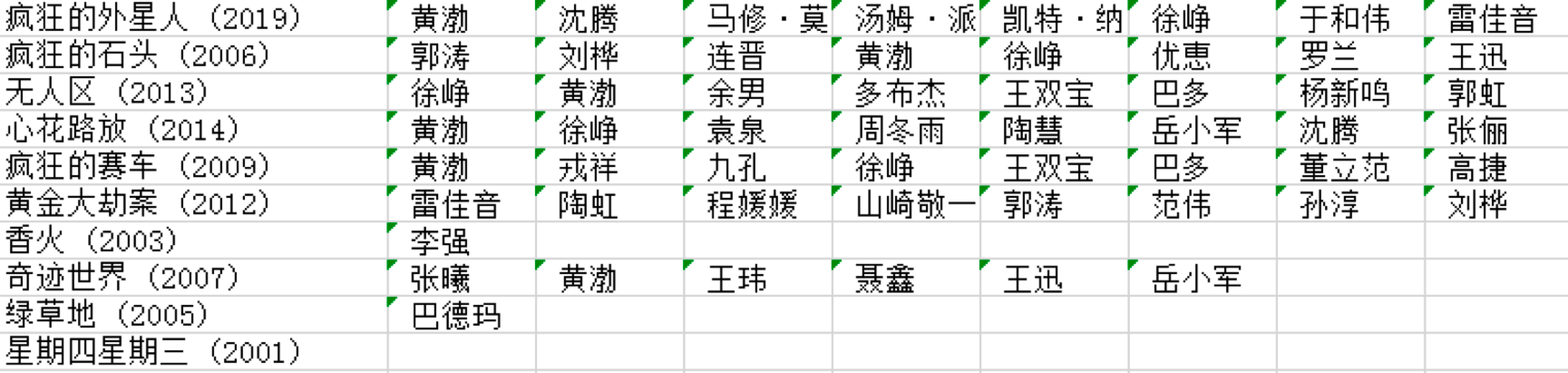 有了数据之后,我们就可以用Apriori算法来挖掘频繁项集和关联规则,代码如下:
有了数据之后,我们就可以用Apriori算法来挖掘频繁项集和关联规则,代码如下:
# -*- coding: utf-8 -*-
from efficient_apriori import apriori
import csv
director = u'宁浩'
file_name = './'+director+'.csv'
lists = csv.reader(open(file_name, 'r', encoding='utf-8-sig'))
# 数据加载
data = []
for names in lists:
name_new = []
for name in names:
# 去掉演员数据中的空格
name_new.append(name.strip())
data.append(name_new[1:])
# 挖掘频繁项集和关联规则
itemsets, rules = apriori(data, min_support=0.5, min_confidence=1)
print(itemsets)
print(rules)
代码中使用的apriori方法和开头中用Apriori获取购物篮规律的方法类似,比如代码中都设定了最小支持度和最小置信系数,这样我们可以找到支持度大于50%,置信系数为1的频繁项集和关联规则。
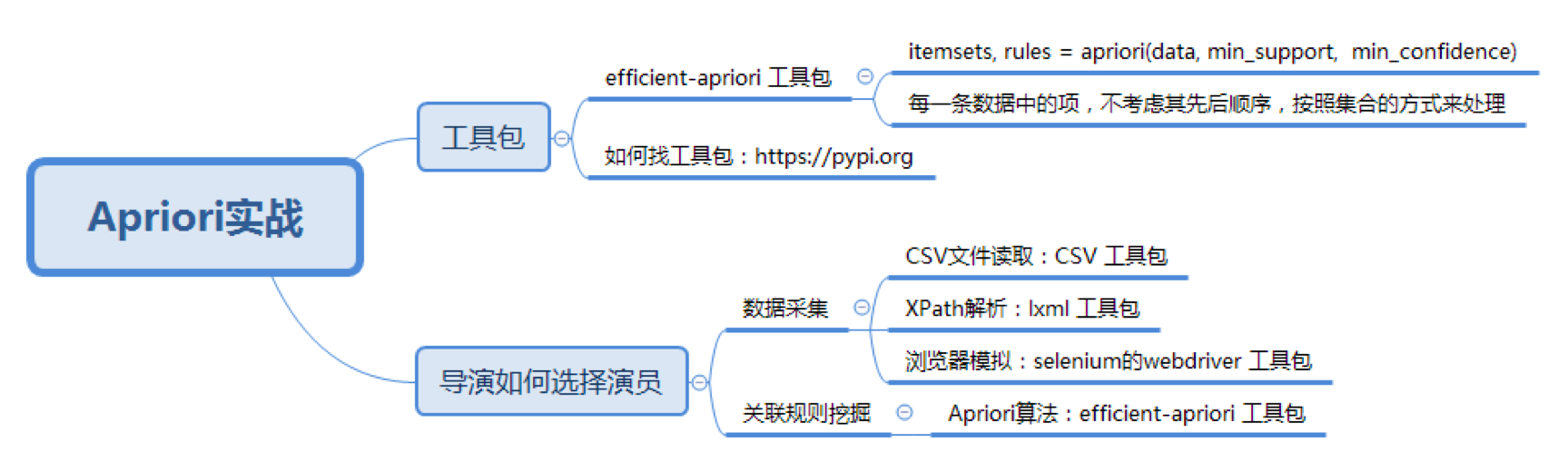
这是最后的运行结果:
你能看出来,宁浩导演喜欢用徐峥和黄渤,并且有徐峥的情况下,一般都会用黄渤。你也可以用上面的代码来挖掘下其他导演选择演员的规律。
总结
Apriori算法的核心就是理解频繁项集和关联规则。在算法运算的过程中,还要重点掌握对支持度、置信度和提升度的理解。在工具使用上,你可以使用efficient-apriori这个工具包,它会把每一条数据中的项(item)放到一个集合(篮子)里来处理,不考虑项(item)之间的先后顺序。
在实际运用中你还需要灵活处理,比如导演如何选择演员这个案例,虽然工具的使用会很方便,但重要的还是数据挖掘前的准备过程,也就是获取某个导演的电影数据集。
 最后给你留两道思考题吧。请你编写代码挖掘下张艺谋导演使用演员的频繁项集和关联规则,最小支持度可以设置为0.1或0.05。另外你认为Apriori算法中的最小支持度和最小置信度,一般设置为多少比较合理?
最后给你留两道思考题吧。请你编写代码挖掘下张艺谋导演使用演员的频繁项集和关联规则,最小支持度可以设置为0.1或0.05。另外你认为Apriori算法中的最小支持度和最小置信度,一般设置为多少比较合理?
欢迎你在评论区与我分享你的答案,也欢迎点击“请朋友读”,把这篇文章分享给你的朋友或者同事。
- mickey 👍(13) 💬(2)
最小支持度为0.1: { 1: {('倪大红',): 2, ('刘德华',): 2, ('姜文',): 2, ('巩俐',): 5, ('李雪健',): 2, ('章子怡',): 3, ('葛优',): 2, ('郭涛',): 2, ('陈道明',): 2}, 2: {('倪大红', '巩俐'): 2, ('巩俐', '郭涛'): 2}} [{倪大红} -> {巩俐}, {郭涛} -> {巩俐}] 最小支持度为0.05: 太多了。。。。 结论:不管男一号选谁,女一号必须是巩俐。
2019-03-05 - third 👍(11) 💬(1)
个人的直觉感觉,这个应该跟数据集的大小和特点有关。
2019-02-22 - 滢 👍(7) 💬(2)
选的张艺谋爬取数据,开始的时候设置min_support = 0.5 没有分析出项集,还以为是数据有错,结果发现是支持度设的太高来,没有达到条件的。好尴尬~ #第二步:用Apriori算法进行关联分析 #数据加载 director = '张艺谋' #写CSV文件 path = '/Users/apple/Desktop/GitHubProject/Read mark/数据分析/geekTime/data/' file_name = path + director +'.csv' print(file_name) lists = csv.reader(open(file_name, 'r', encoding='utf-8-sig')) data =[] for names in lists: name_new = [] for name in names: name_new.append(name.strip()) if len(name_new[1:]) >0: data.append(name_new[1:]) print('data--',data) #挖掘频繁项集合关联规则 items,rules = apriori(data,min_support=0.05,min_confidence=1) print(items) print(rules) 输出结果: {1: {('倪大红',): 3, ('傅彪',): 2, ('刘佩琦',): 2, ('刘德华',): 2, ('姜文',): 2, ('孙红雷',): 3, ('巩俐',): 9, ('李保田',): 3, ('李曼',): 2, ('李雪健',): 5, ('杨凤良',): 2, ('牛犇',): 2, ('章子怡',): 3, ('葛优',): 3, ('赵本山',): 2, ('郭涛',): 2, ('闫妮',): 2, ('陈道明',): 2}, 2: {('倪大红', '巩俐'): 2, ('傅彪', '李雪健'): 2, ('刘佩琦', '巩俐'): 2, ('孙红雷', '赵本山'): 2, ('巩俐', '李保田'): 2, ('巩俐', '杨凤良'): 2, ('巩俐', '葛优'): 2, ('巩俐', '郭涛'): 2, ('李保田', '李雪健'): 2}} [{傅彪} -> {李雪健}, {刘佩琦} -> {巩俐}, {赵本山} -> {孙红雷}, {杨凤良} -> {巩俐}, {郭涛} -> {巩俐}]
2019-04-20 - 一 青(๑• . •๑)ゝ 👍(5) 💬(1)
老师,FP-growth 在python有集成吗,,想用fp-growth试试
2019-10-25 - Geeky_Ben 👍(2) 💬(1)
请问一下各位大神,为什么我这个代码只把每一页的第一个电影的资料下载下来。我反复核对了很多次,跟导师的一样... 苦恼~~@@ from efficient_apriori import apriori from lxml import etree import time from selenium import webdriver from webdriver_manager.chrome import ChromeDriverManager import csv driver = webdriver.Chrome(ChromeDriverManager().install()) director = u'宁浩' file_name = './' + director + '.csv' base_url = 'https://movie.douban.com/subject_search?search_text='+director+'&cat=1002&start=' out = open(file_name,'w',newline = '',encoding='utf-8-sig') csv_write = csv.writer(out,dialect='excel') flags = [] def download(request_url): driver.get(request_url) time.sleep(1) html = driver.find_element_by_xpath("//*").get_attribute("outerHTML") html = etree.HTML(html) movie_lists = html.xpath("/html/body/div[@id='wrapper']/div[@id='root']/div[1]//div[@class='item-root']/div[@class='detail']/div[@class='title']/a[@class='title-text']") name_lists = html.xpath("/html/body/div[@id='wrapper']/div[@id='root']/div[1]//div[@class='item-root']/div[@class='detail']/div[@class='meta abstract_2']") num = len(movie_lists) if num > 15: movie_lists = movie_lists[1:] name_lists = name_lists[1:] for (movie,name_list) in zip(movie_lists,name_lists): if name_list.text is None: continue print(name_list.text) names = name_list.text.split('/') if names[0].strip() == director and movie.text not in flags: names[0] = movie.text flags.append(movie.text) csv_write.writerow(names) print('OK') print(num) if num >= 14: return True else: return False start = 0 while start <10000: request_url = base_url + str(start) flag = download(request_url) if flag: start = start + 15 else: break out.close() print('Finished')
2020-07-03 - JustDoDT 👍(2) 💬(1)
Python3.6 遇到如下错误及解决方案: 运行时报错: ModuleNotFoundError: No module named 'dataclasses' 是因为efficient_apriori 依赖 dataclasses 安装 dataclasses 即可 pip install dataclasses
2020-04-08 - 普罗米修斯 👍(2) 💬(1)
如果要使用FP-Growth这个算法,是直接使用FP-Growth这个包吗?
2019-04-11 - 滢 👍(2) 💬(1)
老师能推荐几本有关 概率论、统计学、运筹学的书嘛 ,感觉大学的课本比较枯燥
2019-03-11 - third 👍(2) 💬(1)
感觉:1,张艺谋喜欢用那些组合的人 2.某些组合出现的匹配率 最小支持度为0.1,{1: {(' 巩俐 ',): 9, (' 李雪健 ',): 5}} 最小支持度为0.05,{1: {(' 葛优 ',): 3, (' 巩俐 ',): 9, (' 姜文 ',): 2, (' 郭涛 ',): 2, (' 李雪健 ',): 5, (' 陈维亚 ',): 2, (' 张继钢 ',): 2, (' 刘德华 ',): 2, (' 倪大红 ',): 3, (' 傅彪 ',): 2, (' 牛犇 ',): 2, (' 孙红雷 ',): 2, (' 闫妮 ',): 2, (' 陈道明 ',): 2, (' 赵本山 ',): 2, (' 杨凤良 ',): 2, (' 章子怡 ',): 3, (' 李保田 ',): 3, (' 刘佩琦 ',): 2}, 2: {(' 巩俐 ', ' 李保田 '): 2, (' 巩俐 ', ' 刘佩琦 '): 2, (' 葛优 ', ' 巩俐 '): 2, (' 李雪健 ', ' 傅彪 '): 2, (' 李雪健 ', ' 李保田 '): 2, (' 巩俐 ', ' 郭涛 '): 2, (' 陈维亚 ', ' 张继钢 '): 2, (' 巩俐 ', ' 杨凤良 '): 2, (' 巩俐 ', ' 倪大红 '): 2}} [{ 刘佩琦 } -> { 巩俐 }, { 傅彪 } -> { 李雪健 }, { 郭涛 } -> { 巩俐 }, { 张继钢 } -> { 陈维亚 }, { 陈维亚 } -> { 张继钢 }, { 杨凤良 } -> { 巩俐 }]
2019-02-22 - 听妈妈的话 👍(1) 💬(1)
我觉得mtime网上的电影信息更加全面,就从上面爬取的信息 最小支持度为0.1: {1: {('倪大红',): 3, ('孙红雷',): 3, ('巩俐',): 9, ('李保田',): 4, ('李雪健',): 4, ('章子怡',): 3, ('葛优',): 3, ('赵本山',): 3}, 2: {('巩俐', '李保田'): 3}} [] 最小支持度为0.05: {1: {('丁嘉丽',): 2, ('倪大红',): 3, ('傅彪',): 2, ('刘佩琦',): 2, ('刘德华',): 2, ('姜文',): 2, ('孙红雷',): 3, ('巩俐',): 9, ('张艺谋',): 2, ('李保田',): 4, ('李雪健',): 4, ('牛犇',): 2, ('窦骁',): 2, ('章子怡',): 3, ('葛优',): 3, ('董立范',): 2, ('赵本山',): 3, ('郑恺',): 2, ('郭涛',): 2, ('闫妮',): 2, ('陈道明',): 2, ('齐达内·苏阿内',): 2}, 2: {('倪大红', '巩俐'): 2, ('傅彪', '李雪健'): 2, ('刘佩琦', '巩俐'): 2, ('孙红雷', '赵本山'): 2, ('巩俐', '李保田'): 3, ('巩俐', '葛优'): 2, ('巩俐', '郭涛'): 2, ('李保田', '李雪健'): 2, ('李雪健', '赵本山'): 2, ('牛犇', '董立范'): 2}} [{傅彪} -> {李雪健}, {刘佩琦} -> {巩俐}, {郭涛} -> {巩俐}, {董立范} -> {牛犇}, {牛犇} -> {董立范}]
2019-03-23 - mickey 👍(1) 💬(2)
安装工具包报错,请问怎样解决? E:\DevelopTool\Python\Python27\Scripts>pip install efficient-apriori DEPRECATION: Python 2.7 will reach the end of its life on January 1st, 2020. Please upgrade your Python as Python 2.7 won't be maintained after that date. A future versio ill drop support for Python 2.7. Collecting efficient-apriori Using cached https://files.pythonhosted.org/packages/d2/7b/71c12582b2e1b561e76cf52239bcece4ced6aac9c93974b7fdede5f407e7/efficient_apriori-0.4.5.tar.gz Complete output from command python setup.py egg_info: Traceback (most recent call last): File "<string>", line 1, in <module> File "c:\users\wujian\appdata\local\temp\pip-install-p5k8a3\efficient-apriori\setup.py", line 15, in <module> from efficient_apriori import __version__ File "c:\users\wujian\appdata\local\temp\pip-install-p5k8a3\efficient-apriori\efficient_apriori\__init__.py", line 9, in <module> from efficient_apriori.apriori import apriori File "c:\users\wujian\appdata\local\temp\pip-install-p5k8a3\efficient-apriori\efficient_apriori\apriori.py", line 12 def apriori(transactions: typing.List[tuple], min_support: float=0.5, ^ SyntaxError: invalid syntax ---------------------------------------- Command "python setup.py egg_info" failed with error code 1 in c:\users\wujian\appdata\local\temp\pip-install-p5k8a3\efficient-apriori\
2019-03-01 - Geek_hve78z 👍(1) 💬(1)
1)最小支持度设置为0.1 {1: {('倪大红',): 3, ('孙红雷',): 3, ('巩俐',): 9, ('李保田',): 3, ('李雪健',): 4, ('章子怡',): 3, ('葛优',): 3}} [] 2)最小支持度设置为0.05 {1: {('倪大红',): 3, ('傅彪',): 2, ('刘佩琦',): 2, ('刘德华',): 2, ('姜文',): 2, ('孙红雷',): 3, ('巩俐',): 9, ('李保田',): 3, ('李雪健',): 4, ('杨凤良',): 2, ('牛犇',): 2, ('章子怡',): 3, ('葛优',): 3, ('赵本山',): 2, ('郭涛',): 2, ('闫妮',): 2, ('陈道明',): 2}, 2: {('倪大红', '巩俐'): 2, ('傅彪', '李雪健'): 2, ('刘佩琦', '巩俐'): 2, ('孙红雷', '赵本山'): 2, ('巩俐', '李保田'): 2, ('巩俐', '杨凤良'): 2, ('巩俐', '葛优'): 2, ('巩俐', '郭涛'): 2, ('李保田', '李雪健'): 2}} [{傅彪} -> {李雪健}, {刘佩琦} -> {巩俐}, {赵本山} -> {孙红雷}, {杨凤良} -> {巩俐}, {郭涛} -> {巩俐}]
2019-02-24 - third 👍(1) 💬(2)
对于Xpath的query的删除,来找到需要查找的内容,表示艰难。 自己总结的是, 1.保留div[1] 2.删除名字比较长的class 3.保留// 4.注意看右边的结果 不知道该怎么删,有什么技巧吗?
2019-02-22 - 白夜 👍(1) 💬(1)
最小支持度可以设置的小,而如果最小支持度小,置信度就要设置的相对大一点,不然即使提升度高,也有可能是巧合。这个参数跟数据量以及项的数量有关。 理解对吗? # -*- coding: utf-8 -*- from efficient_apriori import apriori import csv import pprint director = u'张艺谋' file_name = './'+director+'.csv' lists = csv.reader(open(file_name, 'r', encoding='utf-8-sig')) # 数据加载 data = [] for names in lists: name_new = [] for name in names: # 去掉演员数据中的空格 name_new.append(name.strip()) data.append(name_new[1:]) # 挖掘频繁项集和关联规则 itemsets, rules = apriori(data, min_support=0.05, min_confidence=0.5) #data 是我们要提供的数据集,它是一个 list 数组类型。min_support 参数为最小支持度,在 efficient-apriori 工具包中用 0 到 1 的数值代表百分比,比如 0.5 代表最小支持度为 50%。min_confidence 是最小置信度,数值也代表百分比,比如 1 代表 100%。 pprint.pprint(itemsets) print(rules)
2019-02-22 - jion 👍(0) 💬(1)
你好,我想问一下文中计算的结果格式,1:代表啥然后字典里面('徐峥',): 5代表啥,可否对结果分析一下? {1: {('徐峥',): 5, ('黄渤',): 6}, 2: {('徐峥', '黄渤'): 5}} [{徐峥} -> {黄渤}]
2021-03-10