38丨数据可视化实战:如何给毛不易的歌曲做词云展示?
今天我们做一个数据可视化的项目。
我们经常需要对分析的数据提取常用词,做词云展示。比如一些互联网公司会抓取用户的画像,或者每日讨论话题的关键词,形成词云并进行展示。再或者,假如你喜欢某个歌手,想了解这个歌手创作的歌曲中经常用到哪些词语,词云就是个很好的工具。最后,只需要将词云生成一张图片就可以直观地看到结果。
那么在今天的实战项目里,有3个目标需要掌握:
- 掌握词云分析工具,并进行可视化呈现;
- 掌握Python爬虫,对网页的数据进行爬取;
- 掌握XPath工具,分析提取想要的元素 。
如何制作词云
首先我们需要了解什么是词云。词云也叫文字云,它帮助我们统计文本中高频出现的词,过滤掉某些常用词(比如“作曲”“作词”),将文本中的重要关键词进行可视化,方便分析者更好更快地了解文本的重点,同时还具有一定的美观度。
Python提供了词云工具WordCloud,使用pip install wordcloud安装后,就可以创建一个词云,构造方法如下:
wc = WordCloud(
background_color='white',# 设置背景颜色
mask=backgroud_Image,# 设置背景图片
font_path='./SimHei.ttf', # 设置字体,针对中文的情况需要设置中文字体,否则显示乱码
max_words=100, # 设置最大的字数
stopwords=STOPWORDS,# 设置停用词
max_font_size=150,# 设置字体最大值
width=2000,# 设置画布的宽度
height=1200,# 设置画布的高度
random_state=30# 设置多少种随机状态,即多少种颜色
)
实际上WordCloud还有更多的构造参数,代码里展示的是一些主要参数,我在代码中都有注释,你可以自己看下。
创建好WordCloud类之后,就可以使用wordcloud=generate(text)方法生成词云,传入的参数text代表你要分析的文本,最后使用wordcloud.tofile(“a.jpg”)函数,将得到的词云图像直接保存为图片格式文件。
你也可以使用Python的可视化工具Matplotlib进行显示,方法如下:
需要注意的是,我们不需要显示X轴和Y轴的坐标,使用plt.axis(“off”)可以将坐标轴关闭。
了解了如何使用词云工具WordCloud之后,我们将专栏前15节的标题进行词云可视化,具体的代码如下:
#-*- coding:utf-8 -*-
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
from PIL import Image
import numpy as np
# 生成词云
def create_word_cloud(f):
print('根据词频计算词云')
text = " ".join(jieba.cut(f,cut_all=False, HMM=True))
wc = WordCloud(
font_path="./SimHei.ttf",
max_words=100,
width=2000,
height=1200,
)
wordcloud = wc.generate(text)
# 写词云图片
wordcloud.to_file("wordcloud.jpg")
# 显示词云文件
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
f = '数据分析全景图及修炼指南\
学习数据挖掘的最佳学习路径是什么?\
Python基础语法:开始你的Python之旅\
Python科学计算:NumPy\
Python科学计算:Pandas\
学习数据分析要掌握哪些基本概念?\
用户画像:标签化就是数据的抽象能力\
数据采集:如何自动化采集数据?\
数据采集:如何用八爪鱼采集微博上的“D&G”评论?\
Python爬虫:如何自动化下载王祖贤海报?\
数据清洗:数据科学家80%时间都花费在了这里?\
数据集成:这些大号一共20亿粉丝?\
数据变换:大学成绩要求正态分布合理么?\
数据可视化:掌握数据领域的万金油技能\
一次学会Python数据可视化的10种技能'
运行结果:
 你能从结果中看出,还是有一些常用词显示出来了,比如“什么”“要求”“这些”等,我们可以把这些词设置为停用词,编写remove_stop_words函数,从文本中去掉:
你能从结果中看出,还是有一些常用词显示出来了,比如“什么”“要求”“这些”等,我们可以把这些词设置为停用词,编写remove_stop_words函数,从文本中去掉:
# 去掉停用词
def remove_stop_words(f):
stop_words = ['学会', '就是', '什么']
for stop_word in stop_words:
f = f.replace(stop_word, '')
return f
然后在结算词云前调用f = remove_stop_words(f)方法,最后运行可以得到如下的结果:
 你能看出,去掉停用词之后的词云更加清晰,更能体现前15章的主要内容。
你能看出,去掉停用词之后的词云更加清晰,更能体现前15章的主要内容。
给毛不易的歌词制作词云
假设我们现在要给毛不易的歌词做个词云,那么需要怎么做呢?我们先把整个项目的流程梳理下:
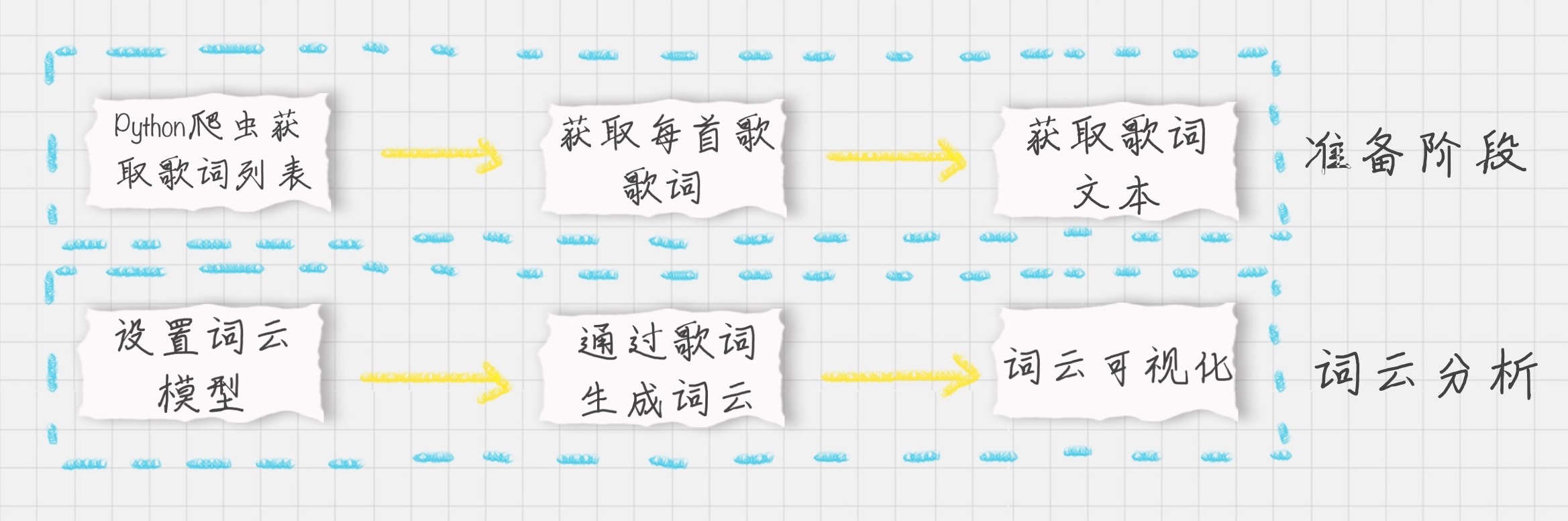
- 在准备阶段:我们主要使用Python爬虫获取HTML,用XPath对歌曲的ID、名称进行解析,然后通过网易云音乐的API接口获取每首歌的歌词,最后将所有的歌词合并得到一个变量。
- 在词云分析阶段,我们需要创建WordCloud词云类,分析得到的歌词文本,最后可视化。
基于上面的流程,编写代码如下:
# -*- coding:utf-8 -*-
# 网易云音乐 通过歌手ID,生成该歌手的词云
import requests
import sys
import re
import os
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
from PIL import Image
import numpy as np
from lxml import etree
headers = {
'Referer' :'http://music.163.com',
'Host' :'music.163.com',
'Accept' :'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'User-Agent':'Chrome/10'
}
# 得到某一首歌的歌词
def get_song_lyric(headers,lyric_url):
res = requests.request('GET', lyric_url, headers=headers)
if 'lrc' in res.json():
lyric = res.json()['lrc']['lyric']
new_lyric = re.sub(r'[\d:.[\]]','',lyric)
return new_lyric
else:
return ''
print(res.json())
# 去掉停用词
def remove_stop_words(f):
stop_words = ['作词', '作曲', '编曲', 'Arranger', '录音', '混音', '人声', 'Vocal', '弦乐', 'Keyboard', '键盘', '编辑', '助理', 'Assistants', 'Mixing', 'Editing', 'Recording', '音乐', '制作', 'Producer', '发行', 'produced', 'and', 'distributed']
for stop_word in stop_words:
f = f.replace(stop_word, '')
return f
# 生成词云
def create_word_cloud(f):
print('根据词频,开始生成词云!')
f = remove_stop_words(f)
cut_text = " ".join(jieba.cut(f,cut_all=False, HMM=True))
wc = WordCloud(
font_path="./wc.ttf",
max_words=100,
width=2000,
height=1200,
)
print(cut_text)
wordcloud = wc.generate(cut_text)
# 写词云图片
wordcloud.to_file("wordcloud.jpg")
# 显示词云文件
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
# 得到指定歌手页面 热门前50的歌曲ID,歌曲名
def get_songs(artist_id):
page_url = 'https://music.163.com/artist?id=' + artist_id
# 获取网页HTML
res = requests.request('GET', page_url, headers=headers)
# 用XPath解析 前50首热门歌曲
html = etree.HTML(res.text)
href_xpath = "//*[@id='hotsong-list']//a/@href"
name_xpath = "//*[@id='hotsong-list']//a/text()"
hrefs = html.xpath(href_xpath)
names = html.xpath(name_xpath)
# 设置热门歌曲的ID,歌曲名称
song_ids = []
song_names = []
for href, name in zip(hrefs, names):
song_ids.append(href[9:])
song_names.append(name)
print(href, ' ', name)
return song_ids, song_names
# 设置歌手ID,毛不易为12138269
artist_id = '12138269'
[song_ids, song_names] = get_songs(artist_id)
# 所有歌词
all_word = ''
# 获取每首歌歌词
for (song_id, song_name) in zip(song_ids, song_names):
# 歌词API URL
lyric_url = 'http://music.163.com/api/song/lyric?os=pc&id=' + song_id + '&lv=-1&kv=-1&tv=-1'
lyric = get_song_lyric(headers, lyric_url)
all_word = all_word + ' ' + lyric
print(song_name)
#根据词频 生成词云
create_word_cloud(all_word)
运行结果:
 这个过程里有一些模块,我需要说明下。
这个过程里有一些模块,我需要说明下。
首先我编写get_songs函数,可以得到指定歌手页面中热门前50的歌曲ID,歌曲名。在这个函数里,我使用requests.request函数获取毛不易歌手页面的HTML。这里需要传入指定的请求头(headers),否则获取不到完整的信息。然后用XPath解析并获取指定的内容,这个模块中,我想获取的是歌曲的链接和名称。
其中歌曲的链接类似 /song?id=536099160 这种形式,你能看到字符串第9位之后,就是歌曲的ID。
有关XPath解析的内容,我在第10节讲到过,如果你忘记了,可以看一下。一般来说,XPath解析 99%的可能都是以//开头,因为你需要获取所有符合这个XPath的内容。我们通过分析HTML代码,能看到一个关键的部分:id=‘hotsong-list’。这个代表热门歌曲列表,也正是我们想要解析的内容。我们想要获取这个热门歌曲列表下面所有的链接,XPath解析就可以写成//*[@id=‘hotsong-list’]//a。然后你能看到歌曲链接是href属性,歌曲名称是这个链接的文本。
获得歌曲ID之后,我们还需要知道这个歌曲的歌词,对应代码中的get_song_lyric函数,在这个函数里调用了网易云的歌词API接口,比如http://music.163.com/api/song/lyric?os=pc&id=536099160&lv=-1&kv=-1&tv=-1。
你能看到歌词文件里面还保存了时间信息,我们需要去掉这部分。因此我使用了re.sub函数,通过正则表达式匹配,将[]中数字信息去掉,方法为re.sub(r’[\d:.[]]’,’’,lyric)。
最后我们还需要设置一些歌词中常用的停用词,比如“作词”“作曲”“编曲”等,编写remove_stop_words函数,将歌词文本中的停用词去掉。
最后编写create_word_cloud函数,通过歌词文本生成词云文件。
总结
今天我给你讲了词云的可视化。在这个实战中,你能看到前期的数据准备在整个过程中占了很大一部分。如果你用Python作为数据采集工具,就需要掌握Python爬虫和XPath解析,掌握这两个工具最好的方式就是多做练习。
我们今天讲到了词云工具WordCloud,它是一个很好用的Python工具,可以将复杂的文本通过词云图的方式呈现。需要注意的是,当我们需要使用中文字体的时候,比如黑体SimHei,就可以将WordCloud中的font_path属性设置为SimHei.ttf,你也可以设置其他艺术字体,在给毛不易的歌词做词云展示的时候,我们就用到了艺术字体。
你可以从GitHub上下载字体和代码:https://github.com/cystanford/word_cloud。
 最后给你留一道思考题吧。我抓取了毛不易主页的歌词,是以歌手主页为粒度进行的词云可视化。实际上网易云音乐也有歌单的API,比如http://music.163.com/api/playlist/detail?id=753776811。你能不能编写代码对歌单做个词云展示(比如歌单ID为753776811)呢?
最后给你留一道思考题吧。我抓取了毛不易主页的歌词,是以歌手主页为粒度进行的词云可视化。实际上网易云音乐也有歌单的API,比如http://music.163.com/api/playlist/detail?id=753776811。你能不能编写代码对歌单做个词云展示(比如歌单ID为753776811)呢?
欢迎你在评论区与我分享你的答案,也欢迎点击“请朋友读”,把这篇文章分享给你的朋友或者同事。
- third 👍(4) 💬(2)
from wordcloud import WordCloud import matplotlib.pyplot as plt import requests headers = { 'Referer': 'http://music.163.com', 'Host': 'music.163.com', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'User-Agent': 'Chrome/10' } def getsong(headers): url = 'http://music.163.com/api/playlist/detail?id=753776811' res = requests.request('GET', url, headers=headers) page = res.json() tracks=page['result']['tracks'] list = [] for i in range(len(tracks)): Name = tracks[i]["name"] list.append(Name) return list def create_WordCloud(list): print("根源词频计算词云") wc = WordCloud( font_path="simhei.ttf", max_words=100, # 设置最大字数 width=2000, # 设置画布宽度 height=1200, # 设置画布高度 random_state=100 ) wordcloud = wc.generate(list) # 写词云图片 wordcloud.to_file("作业.jpg") # 显示词云文件 plt.imshow(wordcloud) # 不需要显示X/Y轴,用off将坐标轴关闭 plt.axis("off") plt.show() # 去掉停用词以及中英文混合的词 def remove_stop_words(f): stop_words = ['(伴奏)', '(Demo版)', '(必胜客新春版)'] mixed_words = ['Bonus Track:一荤一素', 'Bonus Track:给你给我'] for stop_word in stop_words: f = f.replace(stop_word, '') for mixed_word in mixed_words: f = f.replace(mixed_word, mixed_word[12:]) return f gerlists = getsong(headers) # 获取歌单是list类型直接转化为转换为str lists_str = " ".join(gerlists) lists = remove_stop_words(lists_str) create_WordCloud(lists)
2019-03-20 - Geek_hve78z 👍(3) 💬(1)
(2)将歌单的歌曲对应的歌词作词云展示 import requests import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt #得到指定歌单页面的 全部歌曲的歌曲ID,歌曲名 def get_songs(playlist_id): page_url='http://music.163.com/api/playlist/detail?id='+playlist_id #获取网页HTML res=requests.request('GET',page_url,headers=headers) # 输出歌单中歌曲数量 print(len(res.json()['result']['tracks'])) # 设置热门歌曲的ID,歌曲名称 song_ids=[] song_names=[] for i in range(len(res.json()['result']['tracks'])): names=res.json()['result']['tracks'][i]['name'] ids=res.json()['result']['tracks'][i]['id'] song_names.append(names) song_ids.append(ids) print(names,' ',ids) return song_names,song_ids # 得到某一首歌的歌词 def get_song_lyric(headers,lyric_url): res = requests.request('GET', lyric_url, headers=headers) if 'lrc' in res.json(): lyric = res.json()['lrc']['lyric'] new_lyric = re.sub(r'[\d:.[\]]','',lyric) return new_lyric else: return '' print(res.json()) #生成词云 def create_word_cloud(f): print('根据词频 生成词云') f=remove_stop_words(f) cut_text=' '.join(jieba.cut(f,cut_all=False,HMM=True)) wc = WordCloud( font_path="./wc.ttf", max_words=100, width=2000, height=1200, ) print(cut_text) wordcloud = wc.generate(cut_text) # 写词云图片 wordcloud.to_file("wordcloud.jpg") # 显示词云文件 plt.imshow(wordcloud) plt.axis("off") plt.show() # 设置歌单ID,【毛不易 | 不善言辞的深情】为753776811 playlist_id='753776811' [song_names,song_ids]=get_songs(playlist_id) #所有歌词 all_word='' # 获取每首歌歌词 for (song_id, song_name) in zip(song_ids, song_names): # 歌词 API URL lyric_url = 'http://music.163.com/api/song/lyric?os=pc&id=' + str(song_id) + '&lv=-1&kv=-1&tv=-1' lyric = get_song_lyric(headers, lyric_url) all_word = all_word + ' ' + lyric print(song_name) #根据词频,生成词云 create_word_cloud(all_word)
2019-03-13 - 滢 👍(2) 💬(1)
课后作业:语言Python3.6 import requests import matplotlib.pyplot as plt from wordcloud import WordCloud #创建请求头 headers = { 'Referer':'http://music.163.com', 'Host':'music.163.com', 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/Webp,image/apng,*/*;q=0.8', 'User-Agent':'Chrome/10' } #获取歌单 def get_song_name(req_url): res = requests.request('GET',req_url,headers=headers) if 'tracks' in res.json()['result']: tracks = res.json()['result']['tracks'] names = [] for i in range(len(tracks)): name = tracks[i]['name'] names.append(name) return names else: return '' #过滤停用词 def remove_stop_words(text): stop_words = ['(伴奏)','Bonus Track:','(Demo版)'] for stop_word in stop_words: text = text.replace(stop_word,'') return text path = '/Users/apple/Desktop/GitHubProject/Read mark/数据分析/geekTime/data/' #获得词云 def create_wordcloud(text): #移除过滤词 text = remove_stop_words(text) wc = WordCloud( font_path = "/Library/Fonts/Arial Unicode.ttf", max_words = 100, width = 2000, height = 1200 ) wordcloud = wc.generate(text) wordcloud.to_file(path + 'wordcloud_homework.jpg') plt.imshow(wordcloud) plt.axis('off') plt.show() #处理歌单,形成词云 request_url = 'http://music.163.com/api/playlist/detail?id=753776811' content_list = get_song_name(request_url) content = " ".join(content_list) print('歌单信息---',content) create_wordcloud(content) -------------- 歌单信息--- 别再闹了 在无风时 那时的我们 从无到有 一江水 借 消愁 不染 盛夏 哎哟 无问 一荤一素 南一道街 芬芳一生 请记住我 项羽虞姬 给你给我 想你想你 意料之中 平凡的一天 像我这样的人 感觉自己是巨星 如果有一天我变得很有钱 借 (伴奏) 消愁 (伴奏) 盛夏 (伴奏) 哎哟 (伴奏) 想你想你 (伴奏) 南一道街 (伴奏) 给你给我 (伴奏) 芬芳一生 (伴奏) 一荤一素 (伴奏) 平凡的一天 (伴奏) 像我这样的人 (伴奏) 如果有一天我变得很有钱 (伴奏) 如果有一天我变得很有钱 (必胜客新春版) Bonus Track:一荤一素 (Demo版) Bonus Track:给你给我 (Demo版) --------------- 图片无法展示,希望极客实践的PM能提出改进方案,前端和后台实现一下(😂😂),祝专栏越做越好
2019-04-24 - 一语中的 👍(2) 💬(1)
以http://music.163.com/api/playlist/detail?id=753776811中歌单为例做词云展示 #-*- coding:utf-8 -*- from wordcloud import WordCloud import matplotlib.pyplot as plt import requests def getSonglists(url, headers): #根据歌单API获取歌曲列表 #将页面信息转换为json格式便于通过字典取值 r = requests.get(url, headers=headers) page_json = r.json() tracks = page_json["result"]["tracks"] lists = [] for i in range(len(tracks)): listName = tracks[i]["name"] lists.append(listName) return lists #生成词云 def create_WordCloud(lists): print("根源词频计算词云") wc = WordCloud( font_path = "C:\Windows\Fonts\simhei.ttf", #设置中文字体 max_words = 100, #设置最大字数 width = 2000, #设置画布宽度 height = 1200, #设置画布高度 random_state = 100 ) wordcloud = wc.generate(lists) #写词云图片 wordcloud.to_file("wordcloud.jpg") #显示词云文件 plt.imshow(wordcloud) #不需要显示X/Y轴,用off将坐标轴关闭 plt.axis("off") plt.show() #去掉停用词以及中英文混合的词 def remove_stop_words(f): stop_words = ['(伴奏)', '(Demo版)', '(必胜客新春版)'] mixed_words = ['Bonus Track:一荤一素', 'Bonus Track:给你给我'] for stop_word in stop_words: f = f.replace(stop_word, '') for mixed_word in mixed_words: f = f.replace(mixed_word, mixed_word[12:]) return f if __name__ == "__main__": headers = { 'Referer': 'http://music.163.com', 'Host': 'music.163.com', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'User-Agent': 'Chrome/10' } url = "http://music.163.com/api/playlist/detail?id=753776811" gerLists = getSonglists(url, headers) #获取歌单是list类型,转换为str,那么就不再需要用jieba分词 lists_str = " ".join(gerLists) lists = remove_stop_words(lists_str) create_WordCloud(lists)
2019-03-11 - Geeky_Ben 👍(1) 💬(3)
老师,为什么我的结果显示 cannot open resource
2020-08-06 - Geek_l0anid 👍(1) 💬(1)
# -*- coding:utf-8 -*- # 网易云音乐 通过歌手ID,生成该歌手的词云 import requests import os import re import sys from wordcloud import WordCloud import matplotlib.pyplot as plt from PIL import Image import numpy as np import jieba from lxml import etree headers = { 'Referer': 'http://music.163.com', 'Host': 'music.163.com', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'User-Agent': 'Chrome/10' } # 获取到歌单的信息 def get_song_list(headers,song_list_url): res = requests.request("GET",song_list_url,headers=headers) if 'result' in res.json(): all_song_list = "" for song_list in res.json()['result']['tracks']: all_song_list = all_song_list + song_list['name'] print(all_song_list) return all_song_list else: return '' # 创建词云展示 def wordcloud(f): print("根据词频结果进行词云展示!") cut_text = " ".join(jieba.cut(f,cut_all=False,HMM=True)) wc = WordCloud( font_path="./wc.ttf", max_words=100, width=2000, height=1200, ) wordcloud = wc.generate(cut_text) wordcloud.to_file("song_list_wordcloud.jpg") # 词云展示 plt.imshow(wordcloud) plt.axis("off") plt.show() # 获取歌单 song_list_id = '753776811' song_list_url = 'http://music.163.com/api/playlist/detail?id=' + song_list_id all_song_list_new = get_song_list(headers,song_list_url) wordcloud(all_song_list_new)
2019-09-22 - 陈炫宏 👍(0) 💬(1)
API是怎么找到的?
2021-03-11 - 如果 👍(0) 💬(1)
老师你好,请问下header里的Accept参数是怎么来的
2020-06-11 - GS 👍(0) 💬(1)
https://github.com/leledada/jupyter/tree/master/wordcloud
2019-12-15 - GS 👍(0) 💬(1)
if 'lrc' in res.json(): try: lyric = res.json()['lrc']['lyric'] new_lyric = re.sub(r'[\d:.[\]]','',lyric) return new_lyric except: print('发生了异常-----------------------------------',lyric_url) return '' else: return ''
2019-12-13 - GS 👍(0) 💬(1)
解析歌词的时候最好是用try except 包起来,不然遇到异常就不走了
2019-12-13 - #Yema 👍(0) 💬(2)
lyric_url = 'http://music.163.com/api/song/lyric?os=pc&id=' + str(song_id) + '&lv=-1&kv=-1 老师能解释一下这个url是从哪找到的吗?为什么在浏览器抓包里面没有找到这个api,我找到的api是一个异步需要向api传csrf_token才能拿到歌词
2019-12-12 - 志 👍(0) 💬(1)
思考题关键代码部分: import time id_list = [] name_list = [] # 得到某一歌单里的每一首歌ID和歌名 def get_song_list(headers,list_url): res = requests.request('GET', list_url, headers=headers) if 'result' in res.json(): for item in res.json()['result']['tracks']: # 读取json数据中的每一个ID和name id_list.append(item['id']) name_list.append(item['name']) print(item['id']," ",item['name']) time.sleep(1) # 设置停留时间,防止“bad handshake” return id_list,name_list else: return '' print(res.json()) # 设置歌单链接 list_url = 'https://music.163.com/api/playlist/detail?id=753776811' # 获得歌单每一首歌的ID和name get_song_list(headers,list_url) all_word_list = '' # 获取每首歌歌词 for (song_id, song_name) in zip(id_list, name_list): # 歌词 API URL lyric_url = 'http://music.163.com/api/song/lyric?os=pc&id=' + str(song_id) + '&lv=-1&kv=-1&tv=-1' lyric = get_song_lyric(headers, lyric_url) all_word_list = all_word_list + ' ' + lyric print(song_name) # 去掉停用词 remove_stop_words(all_word_list) # 根据词频 生成词云 create_word_cloud(all_word_list)
2019-03-11 - 跳跳 👍(3) 💬(0)
#需要注意的有两点 #1.歌单返回的是json文件,get_songs需要参考get_songs_lyri获取 #2.list_url中间是str类型,注意类型转换 #emmm,代码太长放不下了,删除了一部分和老师一样的函数 # -*- coding:utf-8 -*- # 网易云音乐 通过歌单ID,生成该歌单的词云 import requests import sys import re import os from wordcloud import WordCloud import matplotlib.pyplot as plt import jieba from PIL import Image import numpy as np from lxml import etree def get_songs(songlist): list_url='https://music.163.com/api/playlist/detail?id='+songlist res = requests.request('GET', list_url, headers=headers) if 'result' in res.json(): for item in res.json()['result']['tracks']: # 读取json数据中的每一个ID和name song_ids.append(item['id']) song_names.append(item['name']) print(item['id']," ",item['name']) time.sleep(1) # 设置停留时间,防止“bad handshake” return song_ids,song_names else: return '' print(res.json()) # 设置歌单 songlist = '753776811' [song_ids, song_names] = get_songs(songlist) # 所有歌词 all_word = '' # 获取每首歌歌词 for (song_id, song_name) in zip(song_ids, song_names): # 歌词 API URL list_url = 'http://music.163.com/api/song/lyric?os=pc&id=' + str(song_id) + '&lv=-1&kv=-1&tv=-1' lyric = get_song_lyric(headers, list_url) all_word = all_word + ' ' + lyric print(song_name) # 根据词频 生成词云 create_word_cloud(all_word)
2019-03-13 - 赵晓叶 👍(1) 💬(0)
print(len(res.json()['result']['tracks'])) KeyError: 'result' 总是报这个错
2023-09-06