05 特征处理:如何利用Spark解决特征处理问题?
你好,我是王喆。
上节课,我们知道了推荐系统要使用的常用特征有哪些。但这些原始的特征是无法直接提供给推荐模型使用的,因为推荐模型本质上是一个函数,输入输出都是数字或数值型的向量。那么问题来了,像动作、喜剧、爱情、科幻这些电影风格,是怎么转换成数值供推荐模型使用的呢?用户的行为历史又是怎么转换成数值特征的呢?
而且,类似的特征处理过程在数据量变大之后还会变得更加复杂,因为工业界的数据集往往都是TB甚至PB规模的,这在单机上肯定是没法处理的。那业界又是怎样进行海量数据的特征处理呢?这节课,我就带你一起来解决这几个问题。
业界主流的大数据处理利器:Spark
既然要处理海量数据,那选择哪个数据处理平台就是我们首先要解决的问题。如果我们随机采访几位推荐系统领域的程序员,问他们在公司用什么平台处理大数据,我想最少有一半以上会回答是Spark。作为业界主流的大数据处理利器,Spark的地位毋庸置疑。所以,今天我先带你了解一下Spark的特点,再一起来看怎么用Spark处理推荐系统的特征。
Spark是一个分布式计算平台。所谓分布式,指的是计算节点之间不共享内存,需要通过网络通信的方式交换数据。Spark最典型的应用方式就是建立在大量廉价的计算节点上,这些节点可以是廉价主机,也可以是虚拟的Docker Container(Docker容器)。
理解了Spark的基本概念,我们来看看它的架构。从下面Spark的架构图中我们可以看到,Spark程序由Manager Node(管理节点)进行调度组织,由Worker Node(工作节点)进行具体的计算任务执行,最终将结果返回给Drive Program(驱动程序)。在物理的Worker Node上,数据还会分为不同的partition(数据分片),可以说partition是Spark的基础数据单元。

Spark计算集群能够比传统的单机高性能服务器具备更强大的计算能力,就是由这些成百上千,甚至达到万以上规模的工作节点并行工作带来的。
那在执行一个具体任务的时候,Spark是怎么协同这么多的工作节点,通过并行计算得出最终的结果呢?这里我们用一个任务来解释一下Spark的工作过程。
这个任务并不复杂,我们需要先从本地硬盘读取文件textFile,再从分布式文件系统HDFS读取文件hadoopFile,然后分别对它们进行处理,再把两个文件按照ID都join起来得到最终的结果。
这里你没必要执着于任务的细节,只要清楚任务的大致流程就好。在Spark平台上处理这个任务的时候,会将这个任务拆解成一个子任务DAG(Directed Acyclic Graph,有向无环图),再根据DAG决定程序各步骤执行的方法。从图2中我们可以看到,这个Spark程序分别从textFile和hadoopFile读取文件,再经过一系列map、filter等操作后进行join,最终得到了处理结果。

其中,最关键的过程是我们要理解哪些是可以纯并行处理的部分,哪些是必须shuffle(混洗)和reduce的部分。
这里的shuffle指的是所有partition的数据必须进行洗牌后才能得到下一步的数据,最典型的操作就是图2中的groupByKey操作和join操作。以join操作为例,我们必须对textFile数据和hadoopFile数据做全量的匹配才可以得到join后的dataframe(Spark保存数据的结构)。而groupByKey操作则需要对数据中所有相同的key进行合并,也需要全局的shuffle才能完成。
与之相比,map、filter等操作仅需要逐条地进行数据处理和转换,不需要进行数据间的操作,因此各partition之间可以完全并行处理。
此外,在得到最终的计算结果之前,程序需要进行reduce的操作,从各partition上汇总统计结果,随着partition的数量逐渐减小,reduce操作的并行程度逐渐降低,直到将最终的计算结果汇总到master节点(主节点)上。可以说,shuffle和reduce操作的触发决定了纯并行处理阶段的边界。

最后,我还想强调的是,shuffle操作需要在不同计算节点之间进行数据交换,非常消耗计算、通信及存储资源,因此shuffle操作是spark程序应该尽量避免的。
说了这么多,这里我们再用一句话总结Spark的计算过程:Stage内部数据高效并行计算,Stage边界处进行消耗资源的shuffle操作或者最终的reduce操作。
清楚了Spark的原理,相信你已经摩拳擦掌期待将Spark应用在推荐系统的特征处理上了。下面,我们就进入实战阶段,用Spark处理我们的Sparrow Recsys项目的数据集。在开始学习之前,我希望你能带着2个问题,边学边思考: 经典的特征处理方法有什么?Spark是如何实现这些特征处理方法的?
如何利用One-hot编码处理类别型特征
广义上来讲,所有的特征都可以分为两大类。第一类是类别、ID型特征(以下简称类别型特征)。拿电影推荐来说,电影的风格、ID、标签、导演演员等信息,用户看过的电影ID、用户的性别、地理位置信息、当前的季节、时间(上午,下午,晚上)、天气等等,这些无法用数字表示的信息全都可以被看作是类别、ID类特征。第二类是数值型特征,能用数字直接表示的特征就是数值型特征,典型的包括用户的年龄、收入、电影的播放时长、点击量、点击率等。
我们进行特征处理的目的,是把所有的特征全部转换成一个数值型的特征向量,对于数值型特征,这个过程非常简单,直接把这个数值放到特征向量上相应的维度上就可以了。但是对于类别、ID类特征,我们应该怎么处理它们呢?
这里我们就要用到One-hot编码(也被称为独热编码),它是将类别、ID型特征转换成数值向量的一种最典型的编码方式。它通过把所有其他维度置为0,单独将当前类别或者ID对应的维度置为1的方式生成特征向量。这怎么理解呢?我们举例来说,假设某样本有三个特征,分别是星期、性别和城市,我们用 [Weekday=Tuesday, Gender=Male, City=London] 来表示,用One-hot编码对其进行数值化的结果。

从图4中我们可以看到,Weekday这个特征域有7个维度,Tuesday对应第2个维度,所以我把对应维度置为1。而Gender分为Male和Female,所以对应的One-hot编码就有两个维度,City特征域同理。
除了这些类别型特征外,ID型特征也经常使用One-hot编码。比如,在我们的SparrowRecsys中,用户U观看过电影M,这个行为是一个非常重要的用户特征,那我们应该如何向量化这个行为呢?其实也是使用One-hot编码。假设,我们的电影库中一共有1000部电影,电影M的ID是310(编号从0开始),那这个行为就可以用一个1000维的向量来表示,让第310维的元素为1,其他元素都为0。
下面,我们就看看SparrowRecsys是如何利用Spark完成这一过程的。这里,我们使用Spark的机器学习库MLlib来完成One-hot特征的处理。
其中,最主要的步骤是,我们先创建一个负责One-hot编码的转换器,OneHotEncoderEstimator,然后通过它的fit函数完成指定特征的预处理,并利用transform函数将原始特征转换成One-hot特征。实现思路大体上就是这样,具体的步骤你可以参考我下面给出的源码:
def oneHotEncoderExample(samples:DataFrame): Unit ={
//samples样本集中的每一条数据代表一部电影的信息,其中movieId为电影id
val samplesWithIdNumber = samples.withColumn("movieIdNumber", col("movieId").cast(sql.types.IntegerType))
//利用Spark的机器学习库Spark MLlib创建One-hot编码器
val oneHotEncoder = new OneHotEncoderEstimator()
.setInputCols(Array("movieIdNumber"))
.setOutputCols(Array("movieIdVector"))
.setDropLast(false)
//训练One-hot编码器,并完成从id特征到One-hot向量的转换
val oneHotEncoderSamples = oneHotEncoder.fit(samplesWithIdNumber).transform(samplesWithIdNumber)
//打印最终样本的数据结构
oneHotEncoderSamples.printSchema()
//打印10条样本查看结果
oneHotEncoderSamples.show(10)
_(参考 com.wzhe.sparrowrecsys.offline.spark.featureeng.FeatureEngineering__中的oneHotEncoderExample函数)_
One-hot编码也可以自然衍生成Multi-hot编码(多热编码)。比如,对于历史行为序列类、标签特征等数据来说,用户往往会与多个物品产生交互行为,或者一个物品被打上多个标签,这时最常用的特征向量生成方式就是把其转换成Multi-hot编码。在SparrowRecsys中,因为每个电影都是有多个Genre(风格)类别的,所以我们就可以用Multi-hot编码完成标签到向量的转换。你可以自己尝试着用Spark实现该过程,也可以参考SparrowRecsys项目中 multiHotEncoderExample的实现,我就不多说啦。
数值型特征的处理-归一化和分桶
下面,我们再好好聊一聊数值型特征的处理。你可能会问了,数值型特征本身不就是数字吗?直接放入特征向量不就好了,为什么还要处理呢?
实际上,我们主要讨论两方面问题,一是特征的尺度,二是特征的分布。
特征的尺度问题不难理解,比如在电影推荐中有两个特征,一个是电影的评价次数fr,一个是电影的平均评分fs。评价次数其实是一个数值无上限的特征,在SparrowRecsys所用MovieLens数据集上,fr 的范围一般在[0,10000]之间。对于电影的平均评分来说,因为我们采用了5分为满分的评分,所以特征fs的取值范围在[0,5]之间。
由于fr和fs 两个特征的尺度差距太大,如果我们把特征的原始数值直接输入推荐模型,就会导致这两个特征对于模型的影响程度有显著的区别。如果模型中未做特殊处理的话,fr这个特征由于波动范围高出fs几个量级,可能会完全掩盖fs作用,这当然是我们不愿意看到的。为此我们希望把两个特征的尺度拉平到一个区域内,通常是[0,1]范围,这就是所谓归一化。
归一化虽然能够解决特征取值范围不统一的问题,但无法改变特征值的分布。比如图5就显示了Sparrow Recsys中编号在前1000的电影平均评分分布。你可以很明显地看到,由于人们打分有“中庸偏上”的倾向,因此评分大量集中在3.5的附近,而且越靠近3.5的密度越大。这对于模型学习来说也不是一个好的现象,因为特征的区分度并不高。

这该怎么办呢?我们经常会用分桶的方式来解决特征值分布极不均匀的问题。所谓“分桶(Bucketing)”,就是将样本按照某特征的值从高到低排序,然后按照桶的数量找到分位数,将样本分到各自的桶中,再用桶ID作为特征值。
在Spark MLlib中,分别提供了两个转换器MinMaxScaler和QuantileDiscretizer,来进行归一化和分桶的特征处理。它们的使用方法和之前介绍的OneHotEncoderEstimator一样,都是先用fit函数进行数据预处理,再用transform函数完成特征转换。下面的代码就是SparrowRecSys利用这两个转换器完成特征归一化和分桶的过程。
def ratingFeatures(samples:DataFrame): Unit ={
samples.printSchema()
samples.show(10)
//利用打分表ratings计算电影的平均分、被打分次数等数值型特征
val movieFeatures = samples.groupBy(col("movieId"))
.agg(count(lit(1)).as("ratingCount"),
avg(col("rating")).as("avgRating"),
variance(col("rating")).as("ratingVar"))
.withColumn("avgRatingVec", double2vec(col("avgRating")))
movieFeatures.show(10)
//分桶处理,创建QuantileDiscretizer进行分桶,将打分次数这一特征分到100个桶中
val ratingCountDiscretizer = new QuantileDiscretizer()
.setInputCol("ratingCount")
.setOutputCol("ratingCountBucket")
.setNumBuckets(100)
//归一化处理,创建MinMaxScaler进行归一化,将平均得分进行归一化
val ratingScaler = new MinMaxScaler()
.setInputCol("avgRatingVec")
.setOutputCol("scaleAvgRating")
//创建一个pipeline,依次执行两个特征处理过程
val pipelineStage: Array[PipelineStage] = Array(ratingCountDiscretizer, ratingScaler)
val featurePipeline = new Pipeline().setStages(pipelineStage)
val movieProcessedFeatures = featurePipeline.fit(movieFeatures).transform(movieFeatures)
//打印最终结果
movieProcessedFeatures.show(
_(参考 com.wzhe.sparrowrecsys.offline.spark.featureeng.FeatureEngineering中的ratingFeatures函数)_
当然,对于数值型特征的处理方法还远不止于此,在经典的YouTube深度推荐模型中,我们就可以看到一些很有意思的处理方法。比如,在处理观看时间间隔(time since last watch)和视频曝光量(#previous impressions)这两个特征的时,YouTube模型对它们进行归一化后,又将它们各自处理成了三个特征(图6中红框内的部分),分别是原特征值x,特征值的平方x^2,以及特征值的开方,这又是为什么呢?
")
其实,无论是平方还是开方操作,改变的还是这个特征值的分布,这些操作与分桶操作一样,都是希望通过改变特征的分布,让模型能够更好地学习到特征内包含的有价值信息。但由于我们没法通过人工的经验判断哪种特征处理方式更好,所以索性把它们都输入模型,让模型来做选择。
这里其实自然而然地引出了我们进行特征处理的一个原则,就是特征处理并没有标准答案,不存在一种特征处理方式是一定好于另一种的。在实践中,我们需要多进行一些尝试,找到那个最能够提升模型效果的一种或一组处理方式。
小结
这节课我们介绍了推荐系统中特征处理的主要方式,并利用Spark实践了类别型特征和数值型特征的主要处理方法,最后我们还总结出了特征处理的原则,“特征处理没有标准答案,需要根据模型效果实践出真知”。
针对特征处理的方法,深度学习和传统机器学习的区别并不大,TensorFlow、PyTorch等深度学习平台也提供了类似的特征处理函数。在今后的推荐模型章节我们会进一步用到这些方法。
最后,我把这节课的主要知识点总结成了一张表格,你可以利用它巩固今天的重点知识。
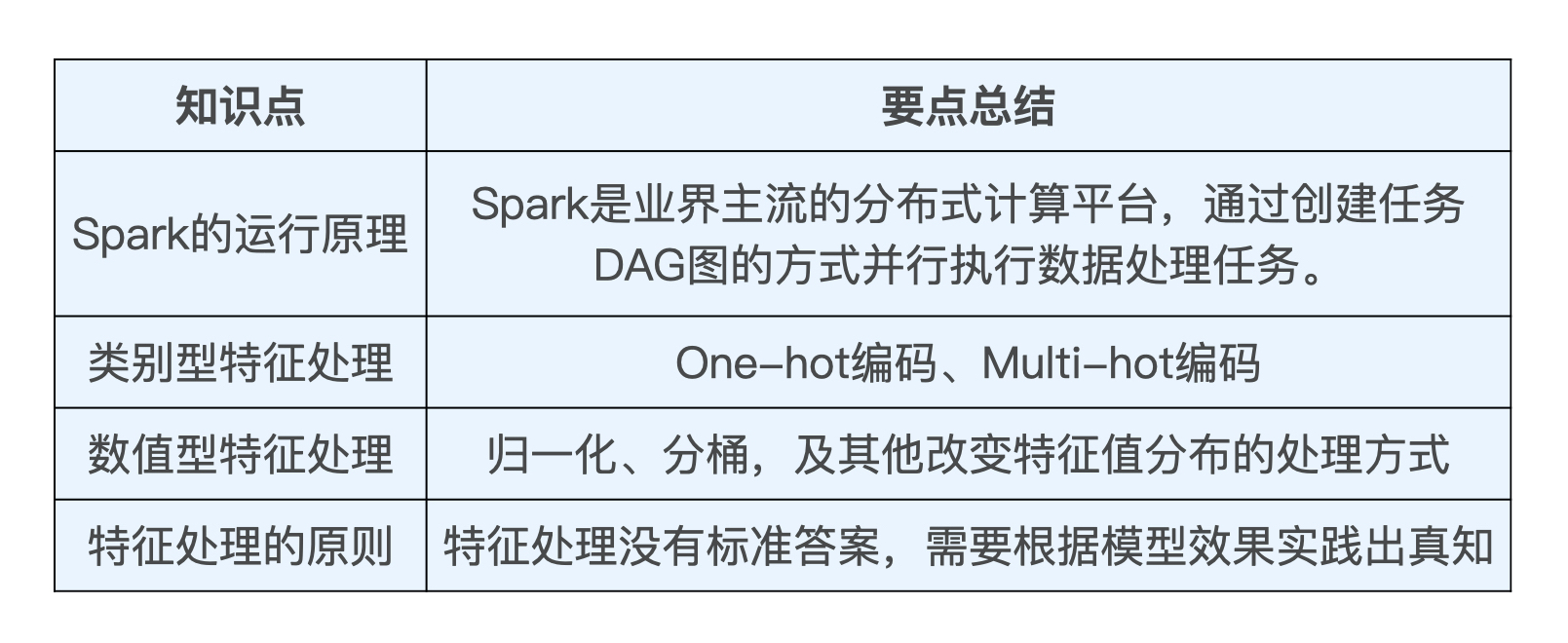
这节课是我们的第一堂实战课,对于还未进入到工业界的同学,相信通过这节课的实践,也能够一窥业界的大数据处理方法,增强自己的工程经验,让我们一起由此迈入工业级推荐系统的大门吧!
课后思考
- 请你查阅一下Spark MLlib的编程手册,找出Normalizer、StandardScaler、RobustScaler、MinMaxScaler这个几个特征处理方法有什么不同。
- 你能试着运行一下SparrowRecSys中的FeatureEngineering类,从输出的结果中找出,到底哪一列是我们处理好的One-hot特征和Multi-hot特征吗?以及这两个特征是用Spark中的什么数据结构来表示的呢?
这就是我们这节课的全部内容了,你掌握得怎么样?欢迎你把这节课转发出去。下节课我们将讲解一种更高阶的特征处理方法,它同时也是深度学习知识体系中一个非常重要的部分,我们到时候见!
- JustDoDT 👍(78) 💬(5)
Normalizer、StandardScaler、RobustScaler、MinMaxScaler 都是用让数据无量纲化 Normalizer: 正则化;(和Python的sklearn一样是按行处理,而不是按列[每一列是一个特征]处理,原因是:Normalization主要思想是对每个样本计算其p-范数,然后对该样本中每个元素除以该范数,这样处理的结果是使得每个处理后样本的p-范数(l1-norm,l2-norm)等于1。)针对每行样本向量:l1: 每个元素/样本中每个元素绝对值的和,l2: 每个元素/样本中每个元素的平方和开根号,lp: 每个元素/每个元素的p次方和的p次根,默认用l2范数。 StandardScaler:数据标准化;(xi - u) / σ 【u:均值,σ:方差】当数据(x)按均值(μ)中心化后,再按标准差(σ)缩放,数据就会服从为均值为0,方差为1的正态分布(即标准正态分布)。 RobustScaler: (xi - median) / IQR 【median是样本的中位数,IQR是样本的 四分位距:根据第1个四分位数和第3个四分位数之间的范围来缩放数据】 MinMaxScaler:数据归一化,(xi - min(x)) / (max(x) - min(x)) ;当数据(x)按照最小值中心化后,再按极差(最大值 - 最小值)缩放,数据移动了最小值个单位,并且会被收敛到 [0,1]之间
2020-10-12 - 李@君 👍(27) 💬(5)
对训练数据进行平方或者开方,是为了改变训练数据的分布。训练数据的分布被改变后,训练出来的模型岂不是不能正确拟合训练数据了。
2020-10-16 - JustDoDT 👍(18) 💬(3)
Multiple编码 顾名思义,Multiple编码特征将多个属性同时编码到一个特征中。在推荐场景中,单个用户对哪些物品感兴趣的特征就是一种Multiple编码特征,如,表示某用户对产品1、产品2、产品3、产品4是否感兴趣,则这个特征可能有多个取值,如用户A对产品1和产品2感兴趣,用户B对产品1和产品4感兴趣,用户C对产品1、产品3和产品4感兴趣,则用户兴趣特征为 用户 UserInterests A [1, 2] B [1, 4] C [1, 3, 4] Multiple编码采用类似oneHot编码的形式进行编码,根据物品种类数目,展成物品种类数目大小的向量,当某个用户感兴趣时,对应维度为1,反之为0,如下 用户 UserInterests A [1, 1, 0, 0] B [1, 0, 0, 1] C [1, 0, 1, 1] 如何使用Multiple编码呢? 我们将多个属性同时编码到同一个特征中,目的就是同时利用多个属性的特征。经过Multiple编码后的特征大小为[batch_size, num_items],记作U,构建物品items的Embedding矩阵,该矩阵维度为[num_items, embedding_size],记作V,将矩阵U和矩阵V相乘,我们就得到了大小为[batch_size, embedding_size]的多属性表示。 参考资料:https://www.codeleading.com/article/97252516619/#_OneHot_19
2020-10-12 - twzd 👍(13) 💬(3)
老师请教一下,movieIdVector列输出结果中(1001,[1],[1.0]),每一列表示什么含义啊
2020-11-10 - Geek_ddf8b1 👍(10) 💬(1)
老师 我看您FeatureEngForRecModel.scala代码中将特征写入redis是以哈希表的格式写入的,而且有些特征直接是类别型的文本数据。 这种方式线上读取特征再后续处理输入排序模型预估的时候会不会效率很低,预估打分时间较长?比如取出文本特征做onehot 或者multihot变换等等,是否可以将文本特征onehot 或者multihot处理后再写入redis? 还有特征除了以hash表形式还可以以其它数据结构存到redis,比如以probuf对象、libsvm数据格式的特征索引:特征值的字符串存到redis 您对这几种存储方式怎么看?哪种更好?
2020-12-06 - Capricornus 👍(6) 💬(1)
我使用的spark3.0的环境,脱离老师的项目,单独建立的用来学习。 1. 下载Scala支持,[下载链接](https://www.scala-lang.org/download/2.12.12.html) 2. 解压后放在指定的目录
3. 在IDEA的项目中引入,点击“+”号,根据路径添加 4. 右键项目的目录,添加框架支持 5. 添加IDEA的插件,preferences中 6. porm.xml的环境依赖vi ~/.bash_profile export PATH="$PATH:/Library/Scala/scala-2.12.12/bin"**注意:路径中不要包括中文,否则可能会出现路径不存在的问题。** 然后有两处需要更改 val oneHotEncoder = new OneHotEncoder() .setInputCols(Array("movieIdNumber")) .setOutputCols(Array("movieIdVector")) .setDropLast(false) // 官网的说法:OneHotEncoder which is deprecated in 2.3,is removed in 3.0 and OneHotEncoderEstimator is now renamed to OneHotEncoder. val movieFeatures = samples.groupBy(col("movieId")) .agg(count(lit(1)).as("ratingCount"), avg(col("rating")).as("avgRating"), functions.variance(col("rating")).as("ratingVar")) .withColumn("avgRatingVec", double2vec(col("avgRating")))2021-01-05<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_2.12</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.0.0</version> </dependency> </dependencies> - 张弛 Conor 👍(6) 💬(2)
请教老师,像在电影评分这样的离散数值(且比较稀疏)例子中,如果需要取得分桶数较多,而导致分位数附近均是同一数值的情况下,如何使用分桶的方法呢? 比如按照分桶法首先排序得到评分为5,5,4,4,4,4,4,4,3,3,3,3,2,2,1(共15个)。取桶数为3时,第一个桶内有前两个5,而后面的6个4中应该选择哪3个来分到第一个桶呢?
2020-10-14 - 神经蛙 👍(4) 💬(2)
--- 看了几位同学的留言,受益匪浅啊。希望大家多多交流~ 1.请你查阅一下 Spark MLlib 的编程手册,找出 Normalizer、StandardScaler、RobustScaler、MinMaxScaler 这个几个特征处理方法有什么不同。 Normalizer 是规范化,根据所传的p值,做p范数归一化(默认p=2)。它是作用在每个样本的向量内部的。无需训练。 eg:x:[v1,v2,v3],p1=sum(abs(vi)), 经过normalizer, x:[v1/p1,v2/p1,v3/p1] StandardScaler 标准化,将样本的每个特征的标准差变为1.或者可以设置将均值变换为0(默认setMean是False)。这里计算标准差(计算均值)是样本集的每个维度单独计算。所以需要fit操作。计算后保存每个样本标准差、均值后。对每个样本第i个维度除以第i个维度的标准差(如此计算后,该维度均值也会自动被除以标准差,经过标准差公式,则新的标准差为1)。如果setMean == True, 则在变幻是需要先减去均值之后再除以标准差。 RobustScaler 我看spark3才有,具体没弄出来,看文档大概意思是将数据变换到1/4~3/4分为之间。好像是让数据变得稠密了。 MinMaxScaler 将数据变为到[0,1]之间,也需要训练,得到每个维度的最大最小值。然后变化Y= (X-X_min)/(X_max-X_min) 2.你能试着运行一下 SparrowRecSys 中的 FeatureEngineering 类,从输出的结果中找出,到底哪一列是我们处理好的 One-hot 特征和 Multi-hot 特征吗?以及这两个特征是用 Spark 中的什么数据结构来表示的呢? 处理好的One-hot特征 movieIdVector 处理好的Multi-hot特征 vector 数据结构: SparseVector 其中的数据分别是:(类别数量,索引数组,值数组)。索引数组长度必须等于值数组长度。
2020-12-03 - fsc2016 👍(4) 💬(2)
第二个问题: One-hot特征是调用OneHotEncoderEstimator对movieId转换,生成了特征movieIdVector Multi-hot 特征是调用Vectors.sparse方法,对处理后的genreIndexes转换,生成vector。 这俩个特征都是稀疏向量表示,不是稠密向量
2020-10-16 - liput 👍(3) 💬(2)
请问老师,看到课程里面特征构造都是在offline批量计算得到特征,而在online再另外计算特征,这里经常会出现不一致的情况。想问下,在工业实践中,有什么好的方法去保证这两个地方的一致性呢?
2021-05-07 - Yvonne 👍(3) 💬(1)
谢谢老师!在读youtube论文的时候,当时没有特别理解为什么要将原值,开方,平方都放进去,解释是:In addition to the raw normalized feature ˜x, we also input powers ˜x2 and √x˜, giving the network more expressive power by allowing it to easily form super- and sub-linear functions of the feature. Feeding powers of continuous features was found to improve offline accuracy.…… 当时没能理解为什么。您提到可以用于改变分布特征,突然就理解了XD
2021-04-25 - Capricornus 👍(3) 💬(1)
+-------+-----------+-----------------+ |movieId|ratingCount|ratingCountBucket| +-------+-----------+-----------------+ | 296| 14616| 13.0| | 356| 14426| 12.0| | 318| 13826| 12.0| | 593| 13692| 12.0| | 480| 13033| 12.0| | 260| 11958| 12.0| | 110| 11637| 12.0| | 589| 11483| 12.0| | 527| 11017| 12.0| | 1| 10759| 12.0| | 457| 10736| 12.0| | 150| 10324| 12.0| | 780| 10271| 12.0| | 50| 10221| 12.0| | 592| 10028| 12.0| | 32| 9694| 12.0| | 608| 9505| 12.0| | 590| 9497| 12.0| | 380| 9364| 12.0| | 47| 9335| 12.0| +-------+-----------+-----------------+ 老师我设置的分桶数是20,为什么最大的桶标号不是19啊?
2021-01-24 - 杨佳亦 👍(3) 💬(2)
MinMaxScaler: 记录数据整体的最大/最小值为max/min, 对于Feature E,若Emax!=Emin, 则rescale后值=(Ei - Emin) / (Emax - Emin) * (max - min) + min. 若Emax == Emin, 则rescale后值=0.5*(min + max). Normalizer: 参考了其他留言才看懂了:这步做的是正则化。正则化将向量的范数缩放到单位1,即可对「样本」也可对「特征」,此处是对样本的正则化,即求样本在所有特征下的取值的P范数(l1, l2). 用通俗的话解释,l1范数计算的是每个元素在同一样本的所有特征取值之和下占的比例,l2范数计算的是每个元素与P维空间中欧氏距离的比值。 StandardScaler: 常用的数据标准化方法,即计算样本在所有特征下的均值和标准差,用数据减均值以中心化,再除以标准差以缩放至单位1. 就是一个把分布未知(通常情况下)的数据拉回到正态分布的函数。 RobustScaler: 新学到的一个方法,之前没用过。和minmaxScaler类似,即使用大、小值进行数据的缩放。具体为(x - median) / (localUpper - localLower). 其中的localLower, median, localUpper分别为数据的第一、二、三分位点。名字中带有robust,是强调用四分位点而非最大最小值等极端值可以加强模型对噪音的抗干扰力。
2020-10-16 - 海滨 👍(2) 💬(1)
Normalizer,是范式归一化操作,保证归一化之后范式为1 StandardScaler,是标准差归一化操作,保证归一化之后均值为0标准差为1 RobustScaler,是使用分位数进行鲁棒归一化操作,可以有效减少异常值的干扰 MinMaxScaler,是使用最大值和最小值进行归一化操作
2021-03-21 - 清晨 👍(2) 💬(1)
standscalar 不是改变了数据的分布吗 处理后的特征为均值为0,方差为1 为什么说没有呢?
2020-11-03