06 Embedding基础:所有人都在谈的Embedding技术到底是什么?
你好,我是王喆。今天我们聊聊Embedding。
说起Embedding,我想你肯定不会陌生,至少经常听说。事实上,Embedding技术不仅名气大,而且用Embedding方法进行相似物品推荐,几乎成了业界最流行的做法,无论是国外的Facebook、Airbnb,还是在国内的阿里、美团,我们都可以看到Embedding的成功应用。因此,自从深度学习流行起来之后,Embedding就成为了深度学习推荐系统方向最火热的话题之一。
但是Embedding这个词又不是很好理解,你甚至很难给它找出一个准确的中文翻译,如果硬是翻译成“嵌入”“向量映射”,感觉也不知所谓。所以索性我们就还是用Embedding这个叫法吧。
那这项技术到底是什么,为什么它在推荐系统领域这么重要?最经典的Embedding方法Word2vec的原理细节到底啥样?这节课,我们就一起来聊聊这几个问题。
什么是Embedding?
简单来说,Embedding就是用一个数值向量“表示”一个对象(Object)的方法,我这里说的对象可以是一个词、一个物品,也可以是一部电影等等。但是“表示”这个词是什么意思呢?用一个向量表示一个物品,这句话感觉还是有点让人费解。
这里,我先尝试着解释一下:一个物品能被向量表示,是因为这个向量跟其他物品向量之间的距离反映了这些物品的相似性。更进一步来说,两个向量间的距离向量甚至能够反映它们之间的关系。这个解释听上去可能还是有点抽象,那我们再用两个具体的例子解释一下。
图1是Google著名的论文Word2vec中的例子,它利用Word2vec这个模型把单词映射到了高维空间中,每个单词在这个高维空间中的位置都非常有意思,你看图1左边的例子,从king到queen的向量和从man到woman的向量,无论从方向还是尺度来说它们都异常接近。这说明什么?这说明词Embedding向量间的运算居然能够揭示词之间的性别关系!比如woman这个词的词向量可以用下面的运算得出:
Embedding(woman)=Embedding(man)+[Embedding(queen)-Embedding(king)]
同样,图1右的例子也很典型,从walking到walked和从swimming到swam的向量基本一致,这说明词向量揭示了词之间的时态关系!这就是Embedding技术的神奇之处。

你可能会觉得词向量技术离推荐系统领域还是有一点远,那Netflix应用的电影Embedding向量方法,就是一个非常直接的推荐系统应用。从Netflix利用矩阵分解方法生成的电影和用户的Embedding向量示意图中,我们可以看出不同的电影和用户分布在一个二维的空间内,由于Embedding向量保存了它们之间的相似性关系,因此有了这个Embedding空间之后,我们再进行电影推荐就非常容易了。具体来说就是,我们直接找出某个用户向量周围的电影向量,然后把这些电影推荐给这个用户就可以了。这就是Embedding技术在推荐系统中最直接的应用。

Embedding技术对深度学习推荐系统的重要性
事实上,我一直把Embedding技术称作深度学习的“基础核心操作”。在推荐系统领域进入深度学习时代之后,Embedding技术更是“如鱼得水”。那为什么Embedding技术对于推荐系统如此重要,Embedding技术又在特征工程中发挥了怎样的作用呢?针对这两个问题,我主要有两点想和你深入聊聊。
首先,Embedding是处理稀疏特征的利器。 上节课我们学习了One-hot编码,因为推荐场景中的类别、ID型特征非常多,大量使用One-hot编码会导致样本特征向量极度稀疏,而深度学习的结构特点又不利于稀疏特征向量的处理,因此几乎所有深度学习推荐模型都会由Embedding层负责将稀疏高维特征向量转换成稠密低维特征向量。所以说各类Embedding技术是构建深度学习推荐模型的基础性操作。
其次,Embedding可以融合大量有价值信息,本身就是极其重要的特征向量 。 相比由原始信息直接处理得来的特征向量,Embedding的表达能力更强,特别是Graph Embedding技术被提出后,Embedding几乎可以引入任何信息进行编码,使其本身就包含大量有价值的信息,所以通过预训练得到的Embedding向量本身就是极其重要的特征向量。
因此我们才说,Embedding技术在深度学习推荐系统中占有极其重要的位置,熟悉并掌握各类流行的Embedding方法是构建一个成功的深度学习推荐系统的有力武器。这两个特点也是我们为什么把Embedding的相关内容放到特征工程篇的原因,因为它不仅是一种处理稀疏特征的方法,也是融合大量基本特征,生成高阶特征向量的有效手段。
经典的Embedding方法,Word2vec
提到Embedding,就一定要深入讲解一下Word2vec。它不仅让词向量在自然语言处理领域再度流行,更关键的是,自从2013年谷歌提出Word2vec以来,Embedding技术从自然语言处理领域推广到广告、搜索、图像、推荐等几乎所有深度学习的领域,成了深度学习知识框架中不可或缺的技术点。Word2vec作为经典的Embedding方法,熟悉它对于我们理解之后所有的Embedding相关技术和概念都是至关重要的。下面,我就给你详细讲一讲Word2vec的原理。
什么是Word2vec?
Word2vec是“word to vector”的简称,顾名思义,它是一个生成对“词”的向量表达的模型。
想要训练Word2vec模型,我们需要准备由一组句子组成的语料库。假设其中一个长度为T的句子包含的词有w1,w2……wt,并且我们假定每个词都跟其相邻词的关系最密切。
根据模型假设的不同,Word2vec模型分为两种形式,CBOW模型(图3左)和Skip-gram模型(图3右)。其中,CBOW模型假设句子中每个词的选取都由相邻的词决定,因此我们就看到CBOW模型的输入是wt周边的词,预测的输出是wt。Skip-gram模型则正好相反,它假设句子中的每个词都决定了相邻词的选取,所以你可以看到Skip-gram模型的输入是wt,预测的输出是wt周边的词。按照一般的经验,Skip-gram模型的效果会更好一些,所以我接下来也会以Skip-gram作为框架,来给你讲讲Word2vec的模型细节。

Word2vec的样本是怎么生成的?
我们先来看看训练Word2vec的样本是怎么生成的。 作为一个自然语言处理的模型,训练Word2vec的样本当然来自于语料库,比如我们想训练一个电商网站中关键词的Embedding模型,那么电商网站中所有物品的描述文字就是很好的语料库。
我们从语料库中抽取一个句子,选取一个长度为2c+1(目标词前后各选c个词)的滑动窗口,将滑动窗口由左至右滑动,每移动一次,窗口中的词组就形成了一个训练样本。根据Skip-gram模型的理念,中心词决定了它的相邻词,我们就可以根据这个训练样本定义出Word2vec模型的输入和输出,输入是样本的中心词,输出是所有的相邻词。
为了方便你理解,我再举一个例子。这里我们选取了“Embedding技术对深度学习推荐系统的重要性”作为句子样本。首先,我们对它进行分词、去除停用词的过程,生成词序列,再选取大小为3的滑动窗口从头到尾依次滑动生成训练样本,然后我们把中心词当输入,边缘词做输出,就得到了训练Word2vec模型可用的训练样本。

Word2vec模型的结构是什么样的?
有了训练样本之后,我们最关心的当然是Word2vec这个模型的结构是什么样的。我相信,通过第3节课的学习,你已经掌握了神经网络的基础知识,那再理解Word2vec的结构就容易多了,它的结构本质上就是一个三层的神经网络(如图5)。

它的输入层和输出层的维度都是V,这个V其实就是语料库词典的大小。假设语料库一共使用了10000个词,那么V就等于10000。根据图4生成的训练样本,这里的输入向量自然就是由输入词转换而来的One-hot编码向量,输出向量则是由多个输出词转换而来的Multi-hot编码向量,显然,基于Skip-gram框架的Word2vec模型解决的是一个多分类问题。
隐层的维度是N,N的选择就需要一定的调参能力了,我们需要对模型的效果和模型的复杂度进行权衡,来决定最后N的取值,并且最终每个词的Embedding向量维度也由N来决定。
最后是激活函数的问题,这里我们需要注意的是,隐层神经元是没有激活函数的,或者说采用了输入即输出的恒等函数作为激活函数,而输出层神经元采用了softmax作为激活函数。
你可能会问为什么要这样设置Word2vec的神经网络,以及我们为什么要这样选择激活函数呢?因为这个神经网络其实是为了表达从输入向量到输出向量的这样的一个条件概率关系,我们看下面的式子:
$$p\left(w_{O} \mid w_{I}\right)=\frac{\exp \left(v_{w_{O}}{\prime}{v}_{w_{I}}\right)}{\sum_{i=1}$$} \exp \left(v_{w_{i}}^{\prime}{ }^{\top} v_{w_{I}}\right)
这个由输入词WI预测输出词WO的条件概率,其实就是Word2vec神经网络要表达的东西。我们通过极大似然的方法去最大化这个条件概率,就能够让相似的词的内积距离更接近,这就是我们希望Word2vec神经网络学到的。
当然,如果你对数学和机器学习的底层理论没那么感兴趣的话,也不用太深入了解这个公式的由来,因为现在大多数深度学习平台都把它们封装好了,你不需要去实现损失函数、梯度下降的细节,你只要大概清楚他们的概念就可以了。
如果你是一个理论派,其实Word2vec还有很多值得挖掘的东西,比如,为了节约训练时间,Word2vec经常会采用负采样(Negative Sampling)或者分层softmax(Hierarchical Softmax)的训练方法。关于这一点,我推荐你去阅读《Word2vec Parameter Learning Explained》这篇文章,相信你会找到最详细和准确的解释。
怎样把词向量从Word2vec模型中提取出来?
在训练完Word2vec的神经网络之后,可能你还会有疑问,我们不是想得到每个词对应的Embedding向量嘛,这个Embedding在哪呢?其实,它就藏在输入层到隐层的权重矩阵WVxN中。我想看了下面的图你一下就明白了。

你可以看到,输入向量矩阵WVxN的每一个行向量对应的就是我们要找的“词向量”。比如我们要找词典里第i个词对应的Embedding,因为输入向量是采用One-hot编码的,所以输入向量的第i维就应该是1,那么输入向量矩阵WVxN中第i行的行向量自然就是该词的Embedding啦。
细心的你可能也发现了,输出向量矩阵$W'$也遵循这个道理,确实是这样的,但一般来说,我们还是习惯于使用输入向量矩阵作为词向量矩阵。
在实际的使用过程中,我们往往会把输入向量矩阵转换成词向量查找表(Lookup table,如图7所示)。例如,输入向量是10000个词组成的One-hot向量,隐层维度是300维,那么输入层到隐层的权重矩阵为10000x300维。在转换为词向量Lookup table后,每行的权重即成了对应词的Embedding向量。如果我们把这个查找表存储到线上的数据库中,就可以轻松地在推荐物品的过程中使用Embedding去计算相似性等重要的特征了。

Word2vec对Embedding技术的奠基性意义
Word2vec是由谷歌于2013年正式提出的,其实它并不完全是原创性的,学术界对词向量的研究可以追溯到2003年,甚至更早的时期。但正是谷歌对Word2vec的成功应用,让词向量的技术得以在业界迅速推广,进而使Embedding这一研究话题成为热点。毫不夸张地说,Word2vec对深度学习时代Embedding方向的研究具有奠基性的意义。
从另一个角度来看,Word2vec的研究中提出的模型结构、目标函数、负采样方法、负采样中的目标函数在后续的研究中被重复使用并被屡次优化。掌握Word2vec中的每一个细节成了研究Embedding的基础。从这个意义上讲,熟练掌握本节课的内容是非常重要的。
Item2Vec:Word2vec方法的推广
在Word2vec诞生之后,Embedding的思想迅速从自然语言处理领域扩散到几乎所有机器学习领域,推荐系统也不例外。既然Word2vec可以对词“序列”中的词进行Embedding,那么对于用户购买“序列”中的一个商品,用户观看“序列”中的一个电影,也应该存在相应的Embedding方法。

于是,微软于2015年提出了Item2Vec方法,它是对Word2vec方法的推广,使Embedding方法适用于几乎所有的序列数据。Item2Vec模型的技术细节几乎和Word2vec完全一致,只要能够用序列数据的形式把我们要表达的对象表示出来,再把序列数据“喂”给Word2vec模型,我们就能够得到任意物品的Embedding了。
Item2vec的提出对于推荐系统来说当然是至关重要的,因为它使得“万物皆Embedding”成为了可能。对于推荐系统来说,Item2vec可以利用物品的Embedding直接求得它们的相似性,或者作为重要的特征输入推荐模型进行训练,这些都有助于提升推荐系统的效果。
小结
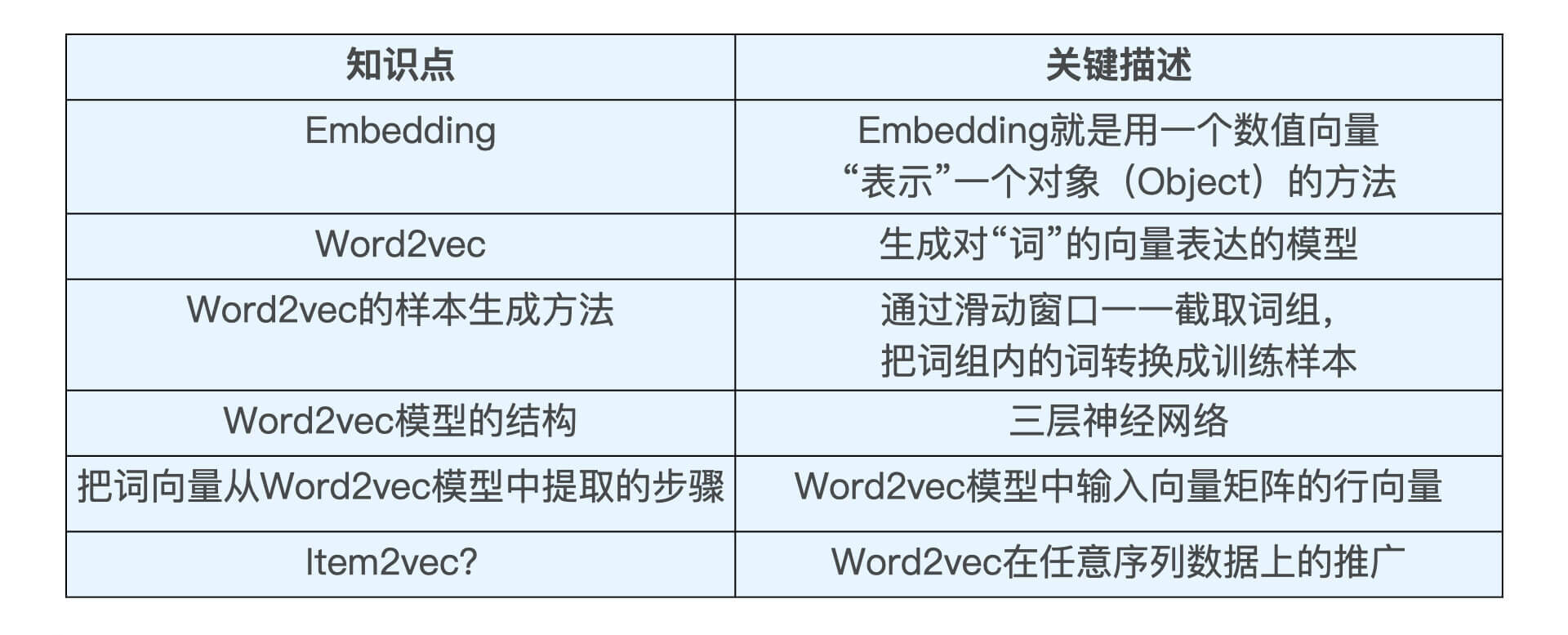
这节课,我们一起学习了深度学习推荐系统中非常重要的知识点,Embedding。Embedding就是用一个数值向量“表示”一个对象的方法。通过Embedding,我们又引出了Word2vec,Word2vec是生成对“词”的向量表达的模型。其中,Word2vec的训练样本是通过滑动窗口一一截取词组生成的。在训练完成后,模型输入向量矩阵的行向量,就是我们要提取的词向量。最后,我们还学习了Item2vec,它是Word2vec在任意序列数据上的推广。
我把这些重点的内容以表格的形式,总结了出来,方便你随时回顾。
这节课,我们主要对序列数据进行了Embedding化,那如果是图结构的数据怎么办呢?另外,有没有什么好用的工具能实现Embedding技术呢?接下来的两节课,我就会一一讲解图结构数据的Embedding方法Graph Embedding,并基于Spark对它们进行实现。
课后思考
在我们通过Word2vec训练得到词向量,或者通过Item2vec得到物品向量之后,我们应该用什么方法计算他们的相似性呢?你知道几种计算相似性的方法?
如果你身边的朋友正对Embedding技术感到疑惑,也欢迎你把这节课分享给TA,我们下节课再见!
- 神经蛙 👍(60) 💬(1)
最近刚好看了看Word2Vec,先列一下看了的资料: 1.Numpy实现的基础版 Word2vec https://github.com/YelZhang/word2vec_numpy/blob/495c2bce99fcdfe281bce0918a6765efd3179b07/wordtovec.py 2.公式推导 https://zhuanlan.zhihu.com/p/136247620 https://zhuanlan.zhihu.com/p/108987941 3.Google Word2vec c源码详解 https://blog.csdn.net/jeryjeryjery/article/details/80245924 https://blog.csdn.net/google19890102/article/details/51887344 https://github.com/zhaozhiyong19890102/OpenSourceReading/blob/master/word2vec/word2vec.c **理解有问题的话,麻烦大家指出来,互相进步~** 说一下看了的理解,Google的源码中Skip-gram,中间词预测周围词是一个循环,每次的优化目标词只有一个周围词中的一个。CBOW是将周围词的向量加和求平均作为上下文词向量,来预测中心词。 为什么会出现层次Softmax和负采样的优化方法? 需要先摆一下前向传播和反向传播公式: -- 略去了下标,以及矩阵乘法的先后。 词表长度V,Embedding长度N 输入:X(shape:(1,V)),输入到隐层矩阵W1(shape: V,N), 隐层到输出矩阵W2(shape: N,V) 前向传播: H=X * W1 (shape:1,N) U=H * W2 (shape:1,V) Y=softmax(U) 这里计算Softmax,参与计算的是V个元素。 反向传播: Loss= -sum(y * logY) Loss对W2偏导=(Y-1)*H Loss对W1偏导=(Y-1)*W2*x (由于X是one-hot向量,相乘后实际只有一行是非0) W1更新时只更新一行,W2更新时更新整个矩阵。 原因: 1.前向传播时计算softmax开销大 2.反向传播时更新W2矩阵开销大 于是就有了对Sofmax这里的优化。最近主要看了负采样。 负采样: 每次训练时,需要预测的目标词给分成2类。一类是目标词,另一类是非目标词(个数可人工指定)(负采样而来,采样词频高的词,TensorFlow里面是这样,与原论文不同)。此时就是个二分类问题,Loss就变了。变成了Sigmod的形式。这样在前向传播不用计算Softmax,反向传播时将每次更新的向量变成了很少的几个,而不是原始的V。降低开销。 关于W1和W2哪被用来做词向量,一般是W1。 这里我有点疑惑,用层次Softmax或者负采样优化方法会不会对W2的效果产生影响?因为更新时没有用到所有数据,所以用W1作为词向量?
2020-12-04 - wolong 👍(28) 💬(9)
老师您好,我这边有个问题。假如我们是做商品推荐,假如商品频繁上新,我们的物品库会是一个动态的,Embedding技术如何应对?
2020-10-14 - 张弛 Conor 👍(26) 💬(2)
计算向量间相似度的常用方法:https://cloud.tencent.com/developer/article/1668762
2020-10-15 - Geek_3c29c3 👍(12) 💬(1)
老师,想问一下,业界利用embedding召回时: 1、是用用户embedding与item embedding的相似性召回还是先计算用户之间的相似性TOPN,然后生成一个user-item矩阵,看看最相似的用户买的多的item得分就更高?; 2、业界用embedding召回如何评价优劣?数据集会划分训练集和验证集吗,来验证购买率,召回率等指标;如果划分,是按照时间划分还是按照用户来划分啊?
2020-10-23 - 张弛 Conor 👍(11) 💬(7)
老师,有两个问题想请教一下: 1.为什么深度学习的结构特点不利于稀疏特征向量的处理呢? 2.既然输出向量是Multi-hot,那用softmax这种激活函数是否不太好呢?Softmax有输出相加和为一的限制,对于一对多的任务是不是不太合适呢?
2020-10-15 - 夜枭 👍(9) 💬(1)
王老师,关于item2vec有一些业务上的疑问,比如用户的点击item序列,这个item的候选集大概得是一个什么规模才能够线上推荐使用呢,目前在做的item量级比较大的话利用spark处理时耗时也会时间长,导致召回的文章并不能很快的更新,几乎是天级别的,不知道您做业务时是怎么权衡更新的频率和数据量这样一个关系的
2021-01-21 - 阳光明媚 👍(9) 💬(1)
常用的相似度度量有余弦距离和欧氏距离,余弦距离可以体现数值的相对差异,欧式距离体现数值的绝对差异;例如,衡量用户点击次数的相似度,欧氏距离更好,衡量用户对各类电影的喜好的相似度,用余弦距离更好。
2021-01-12 - Vinny 👍(9) 💬(2)
老师你好,想请教您个可能与这张内容关联不太大的问题,我是搞nlp的,但是之前在知乎上面看推荐的 user embedding lookup表问题。 像 user id 可能有很多 上千万个,lookup 表的维度就会特别大,而且一些长尾的id 出现交互的次数过少,可能学不到什么好的embedding。 那么工业界是怎么解决这个问题的呢? 之前在知乎上面看一些笼统的说法,比如用hash 让多个id对应一个embdding之类的(但是没有解释这么做的合理性),想请教一下这方面有没有什么推荐的好论文,想去研究下 谢谢!
2020-12-02 - Dikiwi 👍(8) 💬(1)
相似性一般用欧式距离,cosine距离; 线上快速召回一般有用ANN,比如LSH算法进行近似召回。
2020-10-14 - Sam 👍(7) 💬(2)
业界常用 余弦相似度方式,文本相似度TD-IDF方式, 想了解更多:https://cloud.tencent.com/developer/article/1668762 对word2vec的学习 Word2Vec是词嵌入模型之一,它是一种浅层的神经网络模型,它有两种网络结构:CBOW和Skip-gram。 CBOW:根据上下文出现的词语预测当前词的生成概率; Skip-gram:根据当前词预测上下文各个词的概率。 注意:在CBOW中,还需要将各个输入词所计算出的隐含单元求和。 Softmax激活函数 输出层使用Softmax激活函数,可以计算出每个单词的生成概率。具体公式f(x) = e^x / sum( e^x_i ),它运用的是极大似然。 由于Softmax激活函数种存在归一化项的缘故,从公式可以看出,需要对词汇表中的所有单词进行遍历,使得每次迭代过程非常缓慢,时间复杂度为O(V),由此产生了Hierarchical Softmax(层次Softmax) 和 Negative Sampling(负采样)两种改进方法。 Negative Sampling(负采样): 每次训练时,需要预测的目标词给分成2类。一类是目标词,另一类是非目标词(个数可人工指定)(负采样而来,采样词频高的词,TensorFlow里面是这样,与原论文不同)。此时就是个二分类问题,Loss就变了。变成了Sigmod的形式。这样在前向传播不用计算Softmax,反向传播时将每次更新的向量变成了很少的几个,而不是原始的V,降低开销。(详细可见评论区) Hierarchical Softmax(分层Softmax): 它不需要去遍历所有的节点信息,时间复杂度变为O(log(V))。 基本原理:根据标签(label)和频率建立霍夫曼树;(label出现的频率越高,Huffman树的路径越短);Huffman树中每一叶子结点代表一个label; 参考:https://blog.csdn.net/qq_35290785/article/details/96706599 embedding和PCA的本质区别: 引用老师的留言:我觉得理解非常正确,embedding虽然有降维的目的,但初衷是希望在最终的vector中保存物品相关性的信息,甚至依次进行运算。而PCA就是单纯找出主成分进行降维,二者的设计动机差别是比较大的。
2021-03-09 - 浣熊当家 👍(7) 💬(3)
请问下老师,同样作为降维的手段,embedding和PCA的本质区别,可不可以理解为, embedding可以得到更为稠密的向量,并且降维后的各维度没有主次排序之分, 而PCA降维后的向量稠密度并不会增加, 而是得到主成分的排序。 所以如果为了提高模型计算的聚合的速度,就要选择embedding, 如果想降低模型的复杂度和防止过拟合,应该选择PCA。
2020-10-29 - AstrHan 👍(6) 💬(4)
物品embedding和用户embedding如何一起训练,让他们在同一个空间里呢,我理解这样才可以进行物品和用户的相似度计算。
2020-11-25 - 大龄小学生 👍(6) 💬(3)
老师,维度过高为什么不用降维,而用embedding
2020-10-22 - Jay Kay 👍(5) 💬(1)
老师有个问题,item2vec所谓的相似性是拟合的一种隐式的共现么?毕竟感觉通过行为序列得到的embedding没有办法反应语义上的相似性。不知道这样的理解对不对。
2021-03-04 - 轩 👍(4) 💬(3)
老师您好,昨天的提出的一些问题都得到了您的回复,非常感谢。 关于冷启动物品的embedding,我有一些思路,不知是否可行?可业界中也没看到类似做法? 具体而言,拿冷启动物品的标题描述等文字信息喂进rnn吐出embedding,训练好这个rnn之后,就可以冷启动物品入库之时,通过模型获得embedding了,不依赖于用户行为。 至于论据,搜索等都是基于标签标题描述所做,这些文字信息是人类语言关于物品的编码,转换成embedding编码也是可行的? 训练的话,end2end训练,拿点击序列去预测下一个点击。或是拿有充分历史行为的物品训练,预测cosine similarity,应该都可以train这个rnn吧? 之前我负责的业务场景是新闻视频类信息流推荐,内容都很新,大量的冷启动,这是一直以来的一个想法。 由于种种原因,短时间内我没有实践机会了,可经过一段时间的学习,发现对于冷启动好像业界并没有这样做?或是这个想法有些问题?
2021-01-07