31 模型迭代:阿里巴巴是如何迭代更新推荐模型的?
你好,我是王喆。
前两天,我问了我团队中推荐工程师们一个问题,“你们觉得在推荐系统领域工作,最大的挑战是什么?”。有的人说是模型调参,有的人说是工程落地,有的人说是找到下一步改进的思路。那现在听到这个问题的你,认为会是什么呢?
其实,刚才的这些回答都很好。不过,我的想法和大家稍有不同,我认为工作中最大的挑战就是,不断地优化整个推荐系统的架构,做到持续的效果提升和高质量的模型迭代。这是因为,从我们成为一名算法工程师的第一天开始就在不断面临挑战,不仅要跟别人赛跑,也要跟自己赛跑,而超越过去的自己往往是最难的。
那这节课,我就以阿里妈妈团队的经验为例,带你看一看业界一线的团队是如何实现模型的持续迭代创新,做到好上加好的。在学习这节课的时候,我再给你一点小建议,不要纠结于每个模型的细节,而是要多体会阿里的工程师是如何定位创新点的。
阿里妈妈推荐系统的应用场景
阿里妈妈是阿里巴巴集团的营销广告团队,他们负责了阿里大部分广告推荐系统的工作。下图1就是一个阿里妈妈典型的广告推荐场景。
这是我在手机淘宝上搜索了“篮球鞋”之后,App给我推荐的一个商品列表。其中,第一个搜索结果的左上角带着HOT标识,左下角还有一个比较隐蔽的灰色“广告”标识。那带有这两个标志的,就是阿里妈妈广告推荐系统推荐的商品啦。

如果让你来构建这个广告推荐模型,你觉得应该考虑的关键点是什么?
我们可以重点从它的商业目标来思考。阿里妈妈的广告大部分是按照CPC(Cost Per Click)付费的,也就是按照点击效果付费的,所以构建这个模型最重要的一点就是要准确预测每个广告商品的点击率,这样才能把高点击率的商品个性化地推荐给特定的用户,让整个广告系统的收益更高。
因此,模型怎么预测出用户爱点击的广告种类就是重中之重了。那预测广告就一定要分析和利用用户的历史行为,因为这些历史行为之中包含了用户最真实的购买兴趣。
而阿里妈妈推荐模型的主要进化和迭代的方向,也是围绕着用户历史行为的处理展开的。下面,我们就来一起看一看阿里妈妈深度推荐模型的进化过程。
阿里妈妈深度推荐模型的进化过程
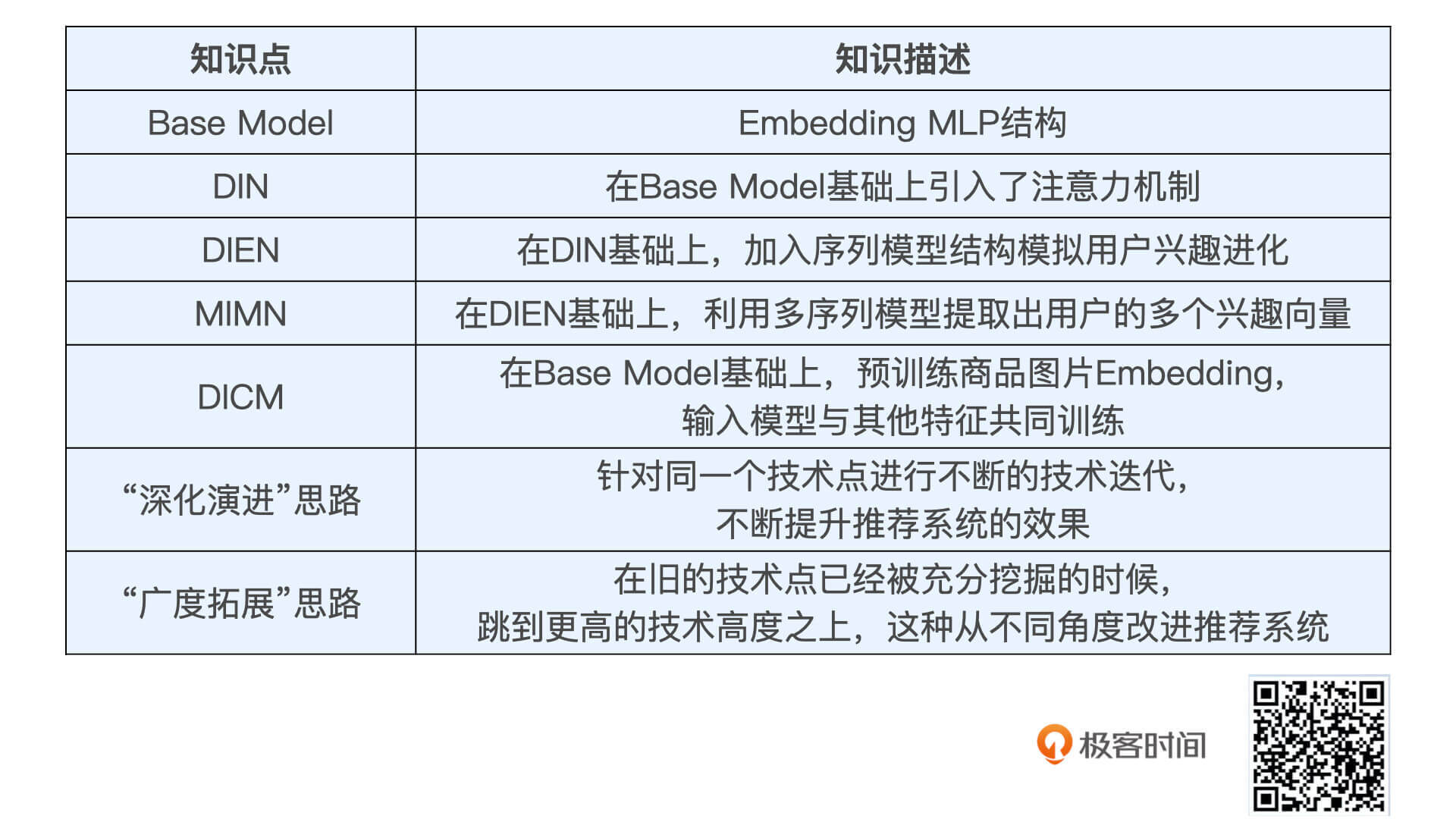
阿里妈妈深度推荐模型的起点被称为Base Model,它是一个基础版本的模型结构,就是我们之前讲过的Embedding MLP的结构,它的结构如图2所示。

Base Model的输入特征包括用户特征、广告特征、场景特征等等,我们最需要关注的,就是它处理用户行为特征的原理,也就是图中彩色的部分。
Base Model使用了SUM Pooling层将用户的所有历史购买商品Embedding进行了加和。这样一来,Base Model就会一视同仁、不分重点地把用户的历史行为都加起来,形成一个固定的用户兴趣向量。
比如说,如果一位女性用户购买过连衣裙、奶粉、婴儿车,她的兴趣向量就是全部商品Embedding的平均。
这当然是一种很粗糙的历史行为处理方式,自然就成为了阿里的工程师需要重点改进的方向。那具体该怎么改进呢?我们在第21讲中讲过,就是使用注意力机制来计算每个历史行为和当前要预测的候选广告物品之间的关系,关系紧密的权重大,关系疏远的权重低。

这样一来,如果我们要预测这位用户购买另一套女装时的CTR,在历史行为中,购买连衣裙这类商品的权重就会高,而购买奶粉这类不相关商品的权重就会低,就像图3中商品下面的进度条一样。
那通过这个例子我们又一次证明了,引入注意力机制是非常符合我们购买习惯的一种模型改进方式。
但是,模型的改进到这里就结束了吗?当然不是,我们虽然引入了注意力机制,但还没有考虑商品的购买时间啊。
举个例子来说,你前一天在天猫上买了一个键盘,今天你又在天猫上闲逛。那对推荐系统来说,是你前一天的购买经历比较重要,还是一年前的更重要呢?当然是前一天的,因为很可能因为你前一天购买了键盘,所以今天购买鼠标或者其他电脑周边的概率变大了,而这些连续事件之间的相关性,对模型来说是非常有用的知识。
于是,DIN模型就进一步进化到了DIEN模型。图4就很好地展示了DIEN的模型结构和它对应的用户历史行为样例。

其实,本质上所有的用户历史行为都是序列式的,时间维度是天然附着在每个历史商品之上的属性。既然我们在之前的模型中把这个属性丢掉了,就一定存在着信息的浪费和知识的丢失。因此在改进模型时,这自然成为了一个突破点。
DIEN正是在模型中加入了一个三层的序列模型结构,来处理用户的历史行为序列,进而抽取出用户的购买兴趣演化序列,最后预测出用户当前的购买兴趣。但是这次改进之后,模型的迭代之路似乎变得越来越难了,似乎算法工程师们把该想到的都想到了。
算法工程师这条职业道路确实是这样的,它是一个自己跟自己较劲的过程,上一轮大幅提高的优化效果,反而可能会成为这一轮改进的阻碍。这个时候,我们很可能会陷入阶段性的怀疑状态,怀疑自己还能不能找到更好的改进点。
这种自我怀疑是正常的,但更重要的是,我们能不能在阶段性的怀疑过后,重新开始冷静地分析问题,找到还没有利用过的信息资源,或者补上之前的某个技术短板,从而在现有系统中“扣出”下一个增长点。
这也是我们要从阿里工程师的工作中学习和借鉴的,下面,我们就来看看他们是怎么继续优化模型的。
2019年,阿里的工程师们提出了新的模型改进思路,也就是多通道兴趣记忆网络MIMN。因为他们发现,DIEN虽然存在着序列模型的结构,但所有的历史行为都是在一条线上演化的,而事实上,用户的兴趣演化过程完全可以多条并行。这该怎么理解呢?
我们还以样例中的这位女性用户为例,她购买女装的兴趣演化路径,完全可以跟购买婴儿物品的演化路径平行,她的兴趣向量也可以是多个,而不仅仅局限于一个。

正是基于这样的模型改进动机,MIMN相比于DIEN加入了多条平行的兴趣演化路径,最终为Embedding MLP的主模型提供了多个课选择的兴趣向量。当然,具体选择哪个,我们还是要根据当前兴趣与目标广告商品之间的注意力得分而定。通过引入兴趣演化的多通道,MIMN进一步加强了模型的表达能力,让模型挖掘数据价值的能力更强。
说了这么多,这几个模型到底有没有提升阿里妈妈推荐系统的效果呢?我们来看一看表1的离线评估结果。从中我们可以看到,阿里采用了ROC AUC作为评估指标,正如期望的那样,随着模型的一步步改进,模型的效果在淘宝数据集和亚马逊数据集上都逐渐增强。

当然,我建议所有论文中的实验效果你都应该辩证地来看,可以作为一个参考值,但不能全部相信。因为就像我常说的在,模型结构不存在最优,只要你的数据、业务特点和阿里不一样,就不能假设这个模型在你的场景下具有同样的效果,所以根据自己的数据特点来改进模型才最重要。
阿里妈妈的其他创新点
这个时候,有的同学可能会问了,阿里妈妈的同学们只是瞄着用户历史这个点去优化吗?感觉这一点的优化空间早晚会穷尽啊。我要说这个观察角度太好了,作为一名算法工程师,技术的格局和全面的视野都是非常重要的,技术的空间那么大,我们不能只盯着一个点去改进,要适当地跳出局限你的空间,去找到其他的技术短板。这样一来,我们往往会发现更好的迭代方向。
所以,阿里的工程师们除了对用户历史进行挖掘,也针对商品图片信息进行了建模,也就是所谓的 DICM(Deep Image CTR Model)。

图6中DICM的模型结构很好理解,它还是采用了Embedding MLP的主模型架构,只不过引入了用户历史购买过的商品的图片信息,以及当前广告商品的图片信息。这些商品图片还是以Embedding的形式表示,然后输入后续MLP层进行处理。
因为要引入图片信息,所以在MLP层之前,还需要利用一个预训练好的CV模型来生成这些图片的Embedding表达。简单来说,就是一个预训练图片Embedding+MLP的模型结构。
除此之外,阿里团队还在很多方向上都做了研究。比如说,同时处理CTR预估和CVR预估问题的多目标优化模型ESMM(Entire Space Multi-Task Model),基于用户会话进行会话内推荐的DSIN(Deep Session Interest Network ),可以在线快速排序的轻量级深度推荐模型COLD(Computing power cost-aware Online and Lightweight Deep pre-ranking system)等等。
我们可以用百花齐放来形容阿里团队的发展过程。你如果感兴趣,可以按照我提供的论文地址来进一步追踪学习。
我们能学到什么?
到这里,我带你从业务方面梳理了,业界一线团队进行模型迭代的过程。那我们到底能从阿里妈妈团队学到或者说借鉴到什么呢?为了帮助你彻底梳理清楚,我把阿里妈妈模型的发展过程分为横向和纵向这两个维度绘制了在下面。

横向的维度是推荐主模型的发展过程,从基础的深度模型一路走来,沿着挖掘用户行为信息的思路不断深化,我把这种发展思路叫做模型的深化演进思路。
但是深化演进的过程是一个不断挑战自己的过程,虽然我们说数据中埋藏着无穷无尽的宝藏,不可能让我们挖完,但是挖掘的难度一直在不断加大。
就像刚开始通过用深度学习模型替代传统机器学习模型,我们能取得10%这个量级的收益,加入注意力机制,加入序列模型这样大的结构改进,我们能取得1%-3%这个量级的收益,到后来,更加复杂的改进,可能只能取得0.5%甚至更低的收益。这个时候,我们就需要把视野拓宽,从其他角度看待推荐问题,找到新的切入点。
这方面,阿里给我们做了很好的示范。比如图7纵向的发展过程就是阿里团队对于一些独立问题的解决方法:多目标、多模态,包括我们之前提到的可以进行实时服务和在线学习在COLD模型。这些都是独立的技术点,但是它们对于推荐效果的提高可能丝毫不弱于主排序模型的改进。这种从不同角度改进推荐模型的思路,我称之为广度扩展。
推荐系统是一个非常复杂的系统,系统中成百上千个不同的模块共同围成了这个系统,它最终的效果也是由这几百上千个模块共同决定的。在通往资深推荐工程师的路上,你的任务是敏锐地发现这些模块中的短板,而不是总盯着最长的那块木板改进,只有高效地解决短板问题,我们才能取得最大的收益。这也是我们这门课为什么一直强调要系统性地建立知识体系的原因。
小结
今天,我带你总结了阿里妈妈团队推荐模型的发展过程。我们可以从两个维度来看阿里广告推荐模型的演进。
首先是深化演进这个迭代思路上,阿里妈妈对用户的历史行为进行了深入理解和不断挖掘,这让阿里妈妈模型从最初的Embedding MLP结构,到引入了注意力机制的DIN,序列模型的DIEN,再到能够利用多通道序列模型学习出用户多个兴趣向量的MIMN,整个发展是一脉相承的。
其次,阿里妈妈还一直在践行“广度拓展”的模型迭代思路,从多目标、多模态,以及在线学习等多个角度改进推荐模型,实现了推荐系统的整体效果的提高。
最后,我把阿里妈妈模型演进过程中所有改进模型的特点,都总结在了下面,希望可以帮助你加深印象。
课后思考
最后的最后,我希望咱们再来做一个开放型的练习:如果我让你在MIMN的基础上进一步改进模型,你觉得还有什么可供挖掘的用户行为信息吗?或者说还有什么方式能够进一步利用好用户行为信息吗?
期待在留言区看到你的创意和思考,我们下节课见!
- 张弛 Conor 👍(24) 💬(1)
思考题:我在想,当前模型在考虑用户历史行为信息时,只考虑了用户的点击行为,能否将特定的曝光行为也考虑进去呢?比如,历史曝光过得广告商品,或曝光时间较长的商品。这样做,不仅可以做更深层次的兴趣挖掘,还可以尝试去做兴趣培养。就像对于某音某手的平台,人们往往诟病的是推荐算法让人变得更极端,推荐算法能否挖掘出或识别出能够改变人兴趣或观点的item呢?
2020-12-25 - 顾小平 👍(11) 💬(1)
多模态建模是啥意思呢?有没有比较通俗的例子呢?
2021-01-23 - 那时刻 👍(10) 💬(1)
课后思考题,感觉还可以利用用户的浏览记录,搜索记录,以及用户与朋友之间推荐分享记录。
2020-12-25 - Geek_b86285 👍(5) 💬(1)
老师您好,能否讲讲你的团队在Roku搭建推荐系统过程中的经验。如何从0到1不断迭代,其中遇到过哪些问题和挑战,又是怎么解决的呢?想听听您从事这行的经验
2020-12-25 - 你笑起来真好看 👍(4) 💬(1)
使用了深度学习模型之后,比如历史点击特征,传统的机器模型需要我们手动提取特征。而深度模型值需要吧序列的itemid输入就好。是不是说 有了深度模型,传统机器学习特征工程就不需要做了呢?
2021-02-07 - 小匚 👍(3) 💬(1)
有一个问题,平时其实会推荐与购物车/收藏夹相似的商品,这部分推荐是否已经应用到实践中了?仔细看了一下文中确实是只用了历史购买信息。 个人体验会过一个月啊过半年的更新购物车内容。收藏夹的东西大部分是好友分享同时自己也感兴趣的。 还有喜欢节日购物的还是那种不敏感的。不知道这个是不是已经包含在历史特征里了。
2020-12-25 - Geek_8a732a 👍(2) 💬(1)
用户的点赞、收藏、分享行为,还有加入购物车的行为,是不是可以增加一些这类商品的权重?比如已加购物车的商品,想买还没买的,可能是品牌或者价格的因素导致用户没有下单,是不是可以推荐类似的商品。
2021-08-23 - 硕 👍(1) 💬(1)
2.还有什么方式能够进一步利用好用户行为信息?这里对于模型层面的积累比较浅薄所以没有什么思路,或许可以针对用户提前做一个分档,根据我们这儿的经验来说活跃用户和非活跃用户的行为表现存在很大差异,针对不同档位的用户分别训练不同的模型可能有更好的效果
2021-07-28 - ALAN 👍(1) 💬(1)
老师讲的非常好。这里有几个小问题,DIN网络训练时,N个商品的N是固定的吗?一般取多少?候选ID会放进去训练吗?输出的目标是什么?
2020-12-25 - 硕 👍(0) 💬(1)
1.可供挖掘的用户行为信息还是有不少的,比如用户点击浏览收藏搜索等行为,虽然不如购买这么强烈,但是胜在量大覆盖度广,比如用户近期的浏览行为可能会比1个月前的购买行为更有参考意义。同时还可以做一些用户和场景的交互,比如用户在服装类目下的活跃度购买力等特征,甚至可以单独构建模型来计算。
2021-07-28 - Yvonne 👍(0) 💬(1)
或许MIMN的多个兴趣向量如果是平行的话,可以尝试交叉?有些商品的融合属性可能比较明显,例如被曝光商品如果是“悬浮灯泡”的话,那“工具”+“艺术”这两个兴趣向量的结合就不错?
2021-05-19 - 舒光华 👍(1) 💬(0)
王喆老师,你好,最近读一篇同样来自Ali/Taobao关于Embedding-based Retrieval 的文(https://arxiv.org/abs/2106.09297), 有个关于在处理real-time signals时候的模型选择的问题想听一下看法。在图2的模型中,处理real-time behavior的时候,在采用MSA之前,采用了LSTM,而在short-term和long-term的时候并没有采用LSTM。文中没有细说为什么,提了一下说用LSTM capture evolution。我的理解是Positional Encoding也可以达到类似的效果。所以不知道为什么要采用LSTM。而且如果序列长的话,还会比较慢。当然最好的办法是直接对比一下。不过目前模型相对比较复杂,而且数据采集也比较难。所以在有机会试之前想听听你的看法。谢谢!
2022-06-23 - ꧁꫞꯭R꯭e꯭i꯭r꯭i꯭꫞꧂ 👍(0) 💬(0)
通过社交网络将用户的行为特征和亲朋好友通讯录上的行为特征做交叉
2023-02-02